Abstract
There are two problems with traditional knowledge distillation methods in industrial anomaly detection: first, traditional methods mostly use feature alignment between the same layers. The second is that similar or even identical structures are usually used to build teacher-student models, thus limiting the ability to represent anomalies in multiple ways. To address these issues, this work proposes a Hierarchical Knowledge Transfer (HKT) framework for detecting industrial surface anomalies. First, HKT utilizes the deep knowledge of the highest feature layer in the teacher’s network to guide student learning at every level, thus enabling cross-layer interactions. Multiple projectors are built inside the model to facilitate the teacher in transferring knowledge to each layer of the student. Second, the teacher-student structural symmetry is decoupled by embedding Convolutional Block Attention Modules (CBAM) in the student network. Finally, based on HKT, a more powerful anomaly detection model, HKT+, is developed. By adding two additional convolutional layers to the teacher and student networks of HKT, HKT+ achieves enhanced detection capabilities at the cost of a relatively small increase in model parameters. Experiments on the MVTec AD and BeanTech AD(BTAD) datasets show that HKT+ achieves state-of-the-art performance with average area under the receiver operating characteristic curve (AUROC) scores of 98.69% and 94.58%, respectively, which outperforms most current state-of-the-art methods.
1. Introduction
In modern industrial manufacturing, quickly and accurately detecting and locating anomalies is crucial for ensuring product quality. With the successful application of deep learning models, particularly Convolutional Neural Networks (CNNs), in various computer vision fields, many deep learning-based anomaly detection methods [1] for industrial scenarios have emerged. These methods have shown great potential in various practical applications, such as large-scale industrial manufacturing, video surveillance, and medical diagnosis. However, in real-world industrial scenarios, the scarcity of defect samples, high annotation costs, and lack of prior knowledge about defects can render supervised methods ineffective. Therefore, most of the current research focuses on unsupervised anomaly detection methods [2,3,4,5]. This means that the training set only contains normal samples, while the test set includes both normal and anomalous samples. This makes constructing fast and accurate anomaly detection methods highly challenging.
In recent years, unsupervised approaches based on knowledge distillation [6,7] have garnered widespread attention due to their outstanding performance and lower resource consumption. These methods [6,8,9] employ student-teacher (S-T) models to transfer meaningful knowledge from other computer vision tasks pre-trained on natural datasets. Specifically, a partial layer of a backbone network pre-trained on a large-scale dataset is usually selected as the fixed-parameter teacher model. During training, the teacher model imparts the knowledge of extracting normal sample features to the student model. Conversely, during inference, the features extracted from normal samples by the teacher and student networks are similar, while the features extracted from abnormal samples are quite distinct. By comparing the differences in the feature maps generated by the two networks, it is possible to determine whether the test image is abnormal and locate the anomaly. Bergmann et al. [10] pioneered the introduction of the T-S architecture to abnormality detection, which significantly outperforms other benchmark methods. However, the model only uses the output of the last layer of the teacher network as a feature for knowledge distillation. To enhance knowledge transfer, STPM [11] utilizes multi-scale features distilled under different network layers. In this case, for normal samples, the features extracted from the student network are more similar to those extracted from the teacher network. In contrast, for abnormal samples, the extracted features differ more. However, these methods are prone to produce redundant features at multiple scales. To solve this problem, RD4AD [12,13] further proposes the Multi-scale Feature Fusion (MFF) module and One-Class Bottleneck (OCB) to form embeddings, which enable a single pair of T-S networks to reconstruct features efficiently. However, the student network in RD4AD needs to receive inputs from the instructor network, which makes it easy for the instructor network to leak anomaly information to the student network during testing.
The study found that although these knowledge distillation-based anomaly detection methods show potential in industrial scenarios, these methods usually adopt similar or even identical structures for constructing S-T models, thus limiting the ability of S-T networks to represent anomalies in diverse ways. In addition, most of these approaches use the same inter-level feature alignment (e.g., Teacher Layer 4→Student Layer 4), which results in deep semantic knowledge in the teacher network not being efficiently transferred to the student network. For a clearer description, knowledge distillation-based anomaly detection methods can be briefly categorized by knowledge transfer, as shown in Figure 1. Figure 1a represents an approach to knowledge transfer using only the deepest levels of the teacher and student [14]; Figure 1b represents the T-S network for knowledge transfer through multi-scale [11]; Figure 1c represents the approach of reverse distillation paradigm [12,13]; While HKT/HKT+ utilizes the deepest features of the teacher network to supervise the learning at each stage of the student network, which is distinctly different from previous knowledge transfer methods. This is shown in Figure 1d.
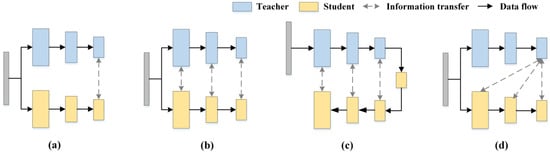
Figure 1.
Knowledge transfer methods in knowledge distillation. (a) Deepest-layer knowledge transfer. (b) Multi-scale transfer architecture. (c) Reverse distillation paradigm. (d) HKT/HKT+.
Currently, exploring efficient knowledge transfer techniques tailored for anomaly detection remains a research priority. To address the above-mentioned issues, the following improvements are introduced:
- A knowledge transfer framework for anomaly detection, termed HKT, is proposed, as illustrated in Figure 2. This method utilizes the deep features extracted from the teacher network to guide the feature extraction at each stage of the student network, which is significantly different from the traditional knowledge transfer methods that operate only between corresponding layers. This cross-layer transfer method can effectively improve the imitation ability of the student network.
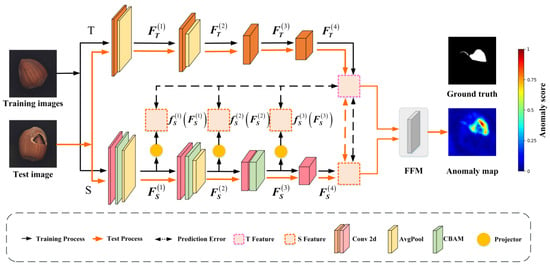 Figure 2. The architecture of HKT and the knowledge transfer mechanism between S and T.
Figure 2. The architecture of HKT and the knowledge transfer mechanism between S and T. - A lightweight yet effective attentional mechanism, the CBAM [15], is introduced between the student’s convolutional layers. CBAM enhances both the channel and spatial dimensions and strengthens anomaly-sensitive regions by cascading them. These further increase the difference in anomaly representations between the teacher network and the student network, thus improving the anomaly detection accuracy of HKT. In addition, the CBAM module is lightweight and suitable for real-time tasks.
- A more robust anomaly detection model, HKT+, is developed on top of HKT. By adding two convolutional layers to the teacher and student networks of HKT, HKT+ achieves stronger detection at the cost of relatively small model parameters and increased computational complexity.
- Extensive experiments and analyses on the anomaly detection datasets MVTec AD [16,17] and BTAD [18] demonstrate that both HKT and HKT+, as lightweight models, outperform most state-of-the-art anomaly detection methods.
2. Materials and Methods
2.1. Framework
The overall architecture of HKT is illustrated in Figure 2. It consists of a Teacher network (T), a Student network (S), and a Feature Fusion Module (FFM). Specifically, the Teacher network T has been pre-trained on an image classification dataset. In contrast, the Student network S is trained solely on normal images under the guidance of the Teacher. The Teacher network T adopts a CNN architecture, extracting deep features from input images through a four-stage convolutional process, and guides the Student network S via projectors. The Student network progressively extracts features from input images through its four-stage convolutional process. Since the structure of S is similar to that of T, the features extracted by the student and the teacher should be highly correlated when S tries to fit the output of T accurately.
However, the shallow features of S are not in the same space as the deep features extracted by the teacher. Therefore, three projectors are designed in the student part to map their features into the teacher’s space. With the assistance of these projectors, knowledge is efficiently transferred from T to S. Finally, the FFM integrates feature maps from both networks to generate pixel-wise anomaly scores for anomaly detection.
2.2. T-S Network
The teacher network employs the Patch Description Network (PDN) [14], which contains only four convolutional layers. This significantly reduces network depth while maintaining its effectiveness as a feature extractor. The PDN is fully convolutional and can be applied to images of varying sizes, generating all feature vectors in a single forward pass. By incorporating average pooling layers after the first and second convolutional layers, the PDN substantially reduces computational costs.
The student network S shares a similar architecture to the teacher network T but introduces attention mechanisms in its first three stages. Additionally, to ensure feature dimensions at each stage of the student network match those of the teacher network, an interpolation function is integrated as a projector in each stage. Furthermore, for CNN architectures, deeper networks with more convolutional layers generally exhibit stronger feature extraction capabilities. To leverage this, both the teacher network T and student network S in HKT are enhanced with two additional convolutional layers, resulting in a more powerful anomaly detection network named HKT+. The specific architectures of the teacher and student networks in HKT and HKT+ are shown in Figure 3. Here, (a) denotes the teacher structure of HKT; (b) denotes the student structure of HKT; (c) denotes the teacher structure of HKT+; and (d) denotes the student structure of HKT+. Based on HKT, the number of kernels in the hidden convolutional layers of HKT+ teachers and students is doubled. HKT+ also inserts a 1 × 1 convolution after the second pooling layer and the last convolutional layer in HKT. The main difference between HKT/HKT+ teachers and students is whether CBAM is added or not.
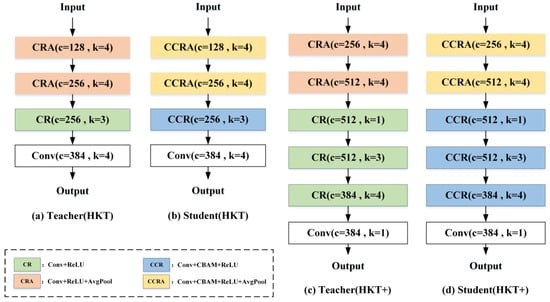
Figure 3.
Detailed structure of the HKT/HKT+ network.
2.3. Attention Mechanism
The introduction of the attention mechanism [19,20] helps student network S to focus on the guidance provided by teacher network T from its initial stages, thereby mimicking the teacher’s final output. However, in the field of anomaly detection, traditional attention mechanisms are often limited by unidimensionality or computational redundancy. CBAM, with its two-dimensional attention synergy, computational efficiency, and anomaly sensitivity optimization capability, is ideal for the structure of the student network in this study. In particular, the channel attention module of CBAM learns the importance of weights on the channel dimension to enhance the response of critical channels. The spatial attention module learns importance weights on the spatial dimension to focus on critical regions. Moreover, the small number of parameters of CBAM has the advantage of being lightweight and suitable for real-time tasks.
The flowchart of the CBAM structure is shown in Figure 4. The output of the channel attention module is formulated as follows:
where is the input feature map; AvgPool and MaxPool denote the full-drama average pooling and maximum pooling operations, respectively; and represent the two fully connected layers, respectively; represents the ReLU activation function, and σ denotes the sigmoid activation function.
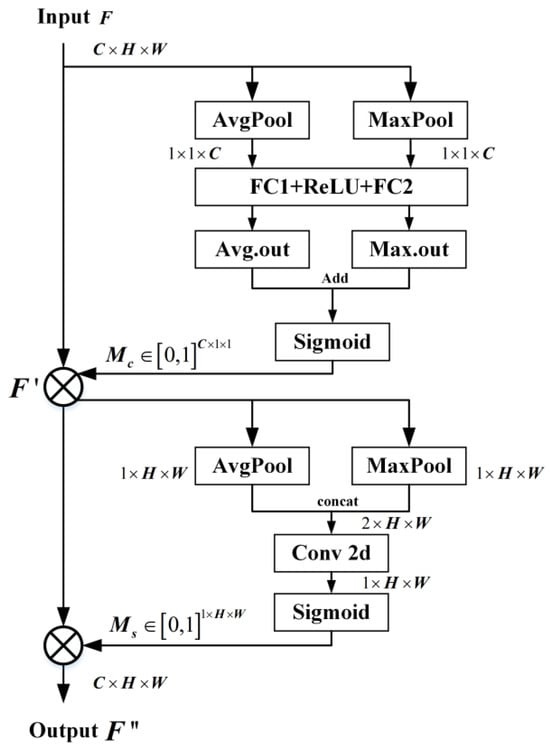
Figure 4.
The flowchart of the CBAM module.
The output of the spatial attention module is formulated as follows:
where denotes a 7 × 7 convolution operation and denotes the stitching of the average pooling and maximum pooling results along the channel axis.
CBAM is applied after the convolutional layers of the first three stages (for simplicity, the last stage of S does not include the attention mechanism). With channel attention and spatial attention , the feature map output is . CBAM can effectively focus on important features while suppressing less useful features, thus enhancing the ability of the student network, S, to mimic the teacher’s network, T.
Additionally, the introduction of CBAM creates an obvious architectural difference between the student network S and the teacher network T, which enhances the distinctiveness of their anomaly representations. Notably, CBAM inherently focuses on the guidance provided by the teacher network T. By incorporating CBAM both solves the problem of identical T-S architectures and, at the same time, forces the student network to mimic the important regions emphasized by the teacher. This effectively improves the student network S’s ability to extract features from normal data and amplifies the disparity between features of anomalous and normal data extracted by S, thereby enhancing anomaly detection performance.
2.4. Projector and Loss
Since the student network S and the teacher network T share a similar 4-stage CNN architecture, their final outputs, and , are in the same feature space and have the same dimensions. However, the features extracted by the student network at stages 1, 2, and 3 (, , and ) are not in the same feature space as . To facilitate knowledge transfer, we constructed three projectors, , , and , which use nearest neighbor interpolation to downsample the features, , , and , respectively. This ensures that the resulting outputs, , , and , match the dimensions of .
HKT supervises the learning of a network of students through multi-stage losses, as defined in the following:
At stage 4, the student network is in the same feature dimension as the teacher network at the final output layer, with global semantic alignment. Therefore, the loss function of the student network S can be defined as follows:
If the student input feature map for each layer is , the projection operation can be formalized as follows:
where denotes the 1 × 1 convolutional kernel weights used to adjust the first three levels of the student’s channel dimensions to 384 dimensions (i.e., the teacher’s channel dimensions) and denotes a nearest neighbor interpolation operation that adjusts the spatial dimensions from to the target dimension (i.e., the teacher’s size).
Assuming the total loss of the student network S at stages 1, 2, and 3 is , it is defined as follows:
Then, the total loss of this student is as follows:
Here, is a hyperparameter. is usually set to 0.5.
2.5. Feature Fusion Module
During the testing phase, the mean squared error (MSE) between corresponding elements of the Teacher’s and Student’s outputs is calculated to quantify their feature discrepancies, as defined in Equation (4). The architecture of the Feature Fusion Module (FFM) in HKT is illustrated in Figure 5.
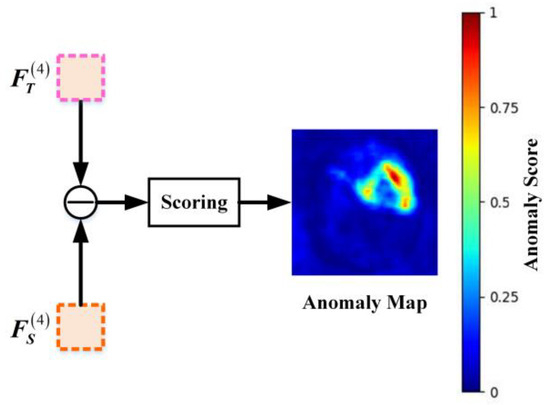
Figure 5.
Detailed structure of the FFM module.
The FFM integrates semantic discrepancies between the Teacher network T and Student network S. By aggregating these discrepancies; the FFM assigns an anomaly score to each pixel of the input image based on the magnitude of the differences, ultimately generating a pixel-wise anomaly map.
3. Experiments
3.1. Datasets
In this study, the following two commonly used public industrial anomaly detection datasets are selected to evaluate the HKT/HKT+ model.
- MVTec AD Dataset
This dataset is designed for benchmarking anomaly localization algorithms and includes a total of 5354 high-resolution images of industrial products, covering 15 different categories. Each category’s training set contains only defect-free images, while the test set includes both normal images and various types of anomaly images. Defect types include surface defects (such as scratches and dents), structural defects (such as deformation of object parts), and defects involving missing parts. The distribution of the MVTec AD samples is shown in Table 1.

Table 1.
Sample distributions for fifteen categories in MVTec AD.
- BTAD Dataset
This dataset specializes in object detection and semi-supervised learning tasks. It is commonly used in manufacturing and anomaly detection studies. The dataset includes RGB images of three different industrial products (Class 1, Class 2, and Class 3), totaling 2540 images. It includes 1799 images for training and 741 images for testing. The distribution of BTAD samples is shown in Table 2.
Table 2.
Sample distributions for the three categories in the BTAD dataset.
3.2. Implementation Details
All experiments in this study were conducted using an NVIDIA GeForce RTX 4090 GPU. Following the reference [14], the teacher network employs the PDN structure pre-trained with WideResNet-101 [5] on the ImageNet dataset [21], which has strong feature representation capabilities, and the detailed flowchart is shown in Figure 3a. The student network’s parameters were randomly initialized. To expedite training, the input high-resolution raw images were scaled to 256 × 256 × 3 pixels for both training and testing. The network was trained using the Adam optimizer [22], with an initial learning rate of 0.0001, a weight decay coefficient of 0.00001, a batch size of 1, and 50,000 training iterations.
3.3. Evaluation Criteria
For image-level anomaly detection, the Area Under the Receiver Operating Characteristic Curve AUROC [23], the number of parameters, and Floating-Point Operations (FLOPs) are used as evaluation metrics.
AUROC measures the relative values of the True Positive Rate (TPR) and the False Positive Rate (FPR) at different thresholds and evaluates the best potential segmentation results based on normal and abnormal pixels. AUROC comprehensively captures the overall performance of the model in the classification task and takes the value ranging from 0 to 1. Its physical significance can be interpreted as follows: if AUROC = 0.5 indicates that the model performance is equivalent to random guessing and cannot provide effective predictive value for practical applications if AUROC is greater than 0.9, the model is usually considered to have industrial-grade practical value. If AUROC tends to 1, it indicates that the model has perfect classification ability and can accurately perform classification. That is, the larger the AUROC value, the better the model performance. The number of parameters is used to assess the degree of model lightweight. One GFLOPs is equal to one billion (=109) floating point operations per second, which is used to quantify the computational complexity of the model.
3.4. Experimental Results and Analysis
To evaluate the performance of the algorithms proposed in this paper, this study compares the performance of the algorithms with the current leading anomaly detection methods on two classical defect datasets, including DRAEM [24], STPM [11], RD4AD [12], MKD [25], US [10], FABLE [26], CSFlow [27], CFlow-AD [28] and SCL [29] Among these methods, DRAEM is based on reconstruction. CSFlow and CFlow-AD are flow-based methods, SCL adopts a self-supervised learning method, and the rest are based on feature knowledge distillation theory. We have also constructed two different sizes of feature-based T-S models; the former is lightweight, and the latter is medium-sized. Its derived anomaly detection methods are HKT and HKT+.
3.4.1. Performance on Dataset MVTec AD
The detection accuracy of HKT and HKT+ was compared with classical anomaly detection methods on the MVTec AD dataset using AUROC as the evaluation metric. As shown in Table 3, HKT and HKT+ achieve average AUROC values of 97.34% and 98.69% across all 15 categories, respectively. These results significantly outperform other knowledge distillation-based methods, demonstrating the effectiveness of the distillation mechanism proposed in this study. Furthermore, HKT+ exhibits higher AUROC than HKT due to its deeper feature-based teacher-student network architecture.
Table 3.
Comparison of detection performance on the MVTec AD dataset using AUROC as the metric.
For the five texture anomaly categories (Carpet, Grid, Leather, Tile, and Wood), HKT+ achieves AUROC values exceeding 98.5% for all classes, with no notable underperforming categories. Specifically, Leather attains a perfect 100% AUROC, while Grid and Tile approach near-perfect detection (99.8% and 99.7%, respectively). HKT achieves a competitive average AUROC of 98.99% for texture anomalies, whereas HKT+ further elevates this to 99.46%, surpassing all baseline methods.
Among the 10 object categories, HKT+ achieves AUROC values above 97% for all classes, with six categories exceeding 98% and four categories surpassing 99%. However, for Cable and Transistor, HKT+ yields relatively lower AUROC scores (~94%), underperforming compared to FABLE and US. This indicates potential areas for refinement in HKT+’s knowledge distillation framework, particularly for complex structural anomalies.
3.4.2. Performance on Dataset BTAD
To validate the generality and generalization ability of the model, the performance of HKT+ is further evaluated on the BTAD dataset. HKT+ is compared with four state-of-the-art methods: STPM [11], RD4AD [12], EfficientAD [14], and FABLE [26]. The results are illustrated in Figure 6. At least two key observations can be drawn: First, for anomalies across all three categories, HKT+ achieved an average AUROC exceeding 94.5%, outperforming all other methods whose average AUROC remained below this threshold. Notably, EfficientAD ranked second with an AUROC of 94.39%, demonstrating the superior performance of HKT+ on this dataset. Second, for the more challenging Category 2 anomalies, HKT+ exhibited exceptional robustness, achieving an AUROC above 87%, whereas the highest AUROC among other methods was only 85.45%.
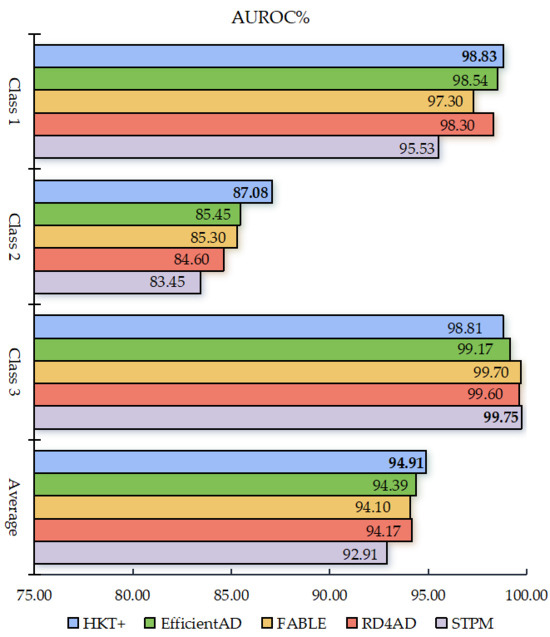
Figure 6.
Comparison of anomaly detection performance based on the BTAD datasets.
3.4.3. Visualized Results
Figure 7 shows the typical anomaly samples, corresponding ground truth, and HKT detection results for the 18 categories included in the MVTech AD and BTAD datasets.
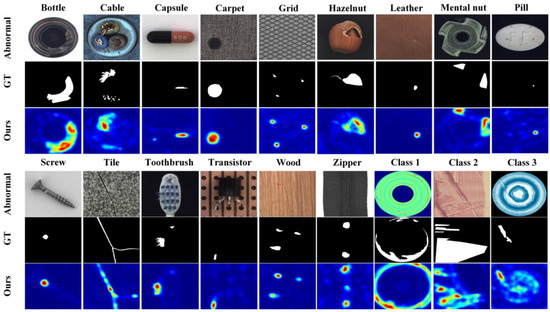
Figure 7.
Typical anomalous images from the MVTec AD dataset and BTAD dataset, along with their corresponding ground truth and the detection results from HKT.
This figure shows that HKT accurately detects most of the anomalies in the test samples. However, a few anomalies may be missed. For example, in the Toothbrush sample, only one of the two defects was detected. There may also be false positives, such as in the Zipper and Class 3 samples, where normal parts are mistakenly identified as anomalies. Additionally, there can be inaccurate localization, such as in Class 2, where the anomaly was not precisely located. All these observations indicate that while HKT has strong anomaly detection capabilities, there is still room for improvement.
3.5. Complexity
The computational complexity (GFLOPs), number of parameters, and AUROC performance of HKT and HKT+ are compared with three state-of-the-art anomaly detection methods (DRAEM, US, RD4AD) on the MVTec AD dataset. The results are summarized in Table 4.
Table 4.
Comparison of HKT and HKT+ with other typical lightweight anomaly detection methods on the MVTec AD dataset.
In terms of model size, HKT and HKT+ exhibit the smallest parameter counts, with approximately 3 M and 8 M parameters, respectively. This compact architecture enables seamless deployment in storage-constrained environments, significantly enhancing the method’s applicability and flexibility. Regarding computational efficiency, HKT and HKT+ require only 20 GFLOPs and 63 GFLOPs, respectively, substantially lower than most comparative methods. Such efficiency allows them to operate with reduced computational time and energy consumption in resource-limited scenarios. Most critically, HKT and HKT+ achieve impressive AUROC performance (97.34% and 98.69% on average), demonstrating competitive detection accuracy. By balancing lightweight design and high performance—two traditionally conflicting objectives—HKT provides a novel and promising solution for industrial anomaly detection with significant potential for real-world applications.
3.6. Ablation Study
For CNN architectures, deep networks with more convolutional layers typically exhibit stronger feature extraction capabilities. Consequently, HKT+ increases both the number of convolutional layers and the number of kernels in the hidden convolutional layers for both the teacher and student networks built on HKT. The depth extension variables of the HKT+ network were initially tested, and the results are presented in Table 5. If the depth had been increased without adding any other modules, the AUROC of HKT+ rises from 96.71% to 97.43% compared to HKT. However, the number of parameters (2.69 M → 8.02 M) and the computational cost (15.31 → 52.03 GFLOPs) of HKT+ increase significantly. This indicates that merely increasing the depth of the network can also substantially enhance performance, but it results in a greater computational burden.
Table 5.
Performance Comparison of HKT/HKT+ without CBAM and without Cross-Layer Knowledge Migration.
In HKT/HKT+, the student network S has a similar architecture to the teacher network T, with the difference being the additional attention module CBAM. Moreover, to enhance the simulation capability of S, the projection loss is introduced between it and the teacher network. To validate the effectiveness of these two components, tests were conducted using HKT+ as an example, and the results are shown in Table 6.
Table 6.
The effect of adding different modules on the detection accuracy of HKT+.
As can be seen from the table, the performance of HKT is significantly lower when neither component is used, or only one of them is used compared to using both components at the same time. This indicates that Attention Mechanism and Projection Loss enhance the student’s performance from two different perspectives, and their effects are additive. HKT+ increases the number of parameters by 0.06 M (8.02 → 8.08) and GFLOPs by 0.04 (52.03 → 52.07) when only CBAM is added. However, AUROC increased by 0.8% (97.43% → 98.23%). This indicates that CBAM effectively focuses on key feature regions through the channel-space attention mechanism, suppresses extraneous noise, and significantly enhances the sensitivity of the model to local anomalies. It significantly improves the model performance at a very low computational cost. Without adding CBAM and only adding cross-layer loss , the AUROC of HKT+ is improved to 97.71%, and the number of parameters and GFLOP are increased to 8.47 M and 63.18, respectively. This loss promotes cross-layer semantic fusion, solves the problem of severing the shallow texture information from the high-level semantic information, and optimizes the ability to locate complex defects but at a certain computational cost.
4. Discussion
4.1. HKT+ Performance Analysis
Analyzing the comprehensive performance, HKT+ significantly outperforms other mainstream methods in terms of AUROC and lightness on the MVTec AD dataset. The near or perfect detection in texture category tasks such as Carpet, Leather, and Hazelnut indicates that the model is extremely sensitive to the anomalies of uniform texture and regular structure. The excellent performance in object categories such as Bottle and Metal nut verifies the effectiveness of cross-layer knowledge migration for global semantic fusion. In addition, the HKT+ model accounts for lightweight design. Not only is the number of parameters and computational cost significantly lower than comparative methods such as RD4AD, but AUROC leadership is achieved at the same time. In terms of module design, the CBAM attention mechanism is added to the student module, which breaks the disadvantage of teacher-student isomorphism structurally and suppresses noise interference functionally by focusing on critical regions through channel space attention. Layered interactions in the teacher-student network are facilitated by cross-layer knowledge transfer loss , which enhances the ability to localize complex defects. In texture-object mixing tasks (e.g., Tile, Zipper), the AUROC of HKT+ exceeds 99% in all cases. It is shown that the model effectively balances local details and global semantics for various defect types in industrial scenarios.
The low performance of some categories is due to the complexity of the structure and the smallness of the defects.
For example, the defect patterns of the Cable are mostly long structures (e.g., insulation breakage, core breakage); the Transistor has complex internal structures with tiny defects such as broken pins and package defects. It shows that the lightweight design of HKT+ may have limitations in detecting complex structures and tiny defects. Therefore, the extraction of deep semantic features by the HKT+ model needs to be optimized. In addition, visual analysis revealed that HKT+ also suffers from detection errors. For example, Class 2 and Zipper normal regions are misclassified as defects, which may be due to the over-sensitivity of spatial attention caused by the high texture background, which cannot effectively suppress the response of normal regions. Some defects on the Toothbrush are overlooked due to subtle breaks or deformations in the toothbrush bristles, which require finer pixel-level analysis.
To address these issues, we will continue to improve HKT+ in the future. Specifically, first, the attention mechanism will be improved by combining channel attention and pixel-level attention to enhance the localization accuracy of complex structural defects. Second, the generation and discrimination process of anomalous features will be optimized by drawing on the normalized flow design of CSFlow or the reconstruction design of DRAEM.
4.2. Balance Between Computing Resources and Performance
HKT prioritizes lightweight, low resource consumption, and ease of deployment. HKT+ trades computational costs for higher detection accuracy. But even so, HKT+ is lighter than most anomaly detection methods. HKT+ is better suited for scenarios that require high detection accuracy, such as cloud analytics, semiconductor wafers, and quality inspection of high-value products.
In real-world deployments, comprehensive decisions need to be made based on hardware conditions, real-time requirements, complexity of defect types, and data size. Example. For hybrid scenarios (e.g., one part of the production line requires real-time inspection, and another part requires high-precision review), a layered strategy can be used: HKT for initial screening and HKT+ for reviewing critical aspects to balance efficiency and accuracy.
5. Conclusions
Aiming at the problems of similar structure of teacher-student models and monotonicity of knowledge migration in traditional knowledge distillation anomaly detection networks, this paper proposes a cross-layer knowledge transfer method, HKT, for industrial anomaly detection. In HKT, the teacher guides the student network through multiple projectors. Utilizing the deep features in the teacher’s network to guide the features of the students in each layer can effectively improve the overall performance. Introducing the attention mechanism CBAM between convolutional layers can enhance the fusion of spatial semantic information. Experiments on the industrial surface defect datasets MVTec AD and BTAD datasets show that the proposed method achieves AUROC values of 98.69% and 94.58%, respectively. HKT is lightweight and suitable for deployment in resource-constrained scenarios such as edge devices and embedded systems. HKT+ has a higher deployment cost than HKT, but its detection accuracy exceeds that of most anomaly detection methods. It is suitable for applications that require very high detection accuracy.
HKT is an important benchmark for future anomaly detection research. In practice, HKT+ will be applied to devices such as high-performance embedded systems and FPGAs.
Author Contributions
Conceptualization, J.X.; methodology, J.X. and S.J.; software, J.X.; validation, J.X. and S.J.; formal analysis, J.X.; investigation, J.X. and S.J.; resources, J.X.; data curation, J.X.; writing—original draft preparation, J.X.; writing—review and editing, J.X. and S.J.; visualization, J.X.; supervision, S.J.; project administration, J.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this paper are public datasets. The MVTec AD dataset is a public dataset that is openly available at https://www.mvtec.com/company/research/datasets/mvtec-ad/downloads (accessed on 26 March 2025). The BTAD dataset is also public and can be accessed at https://avires.dimi.uniud.it/papers/btad/btad.zip (accessed on 26 March 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Liu, J.; Xie, G.; Wang, J.; Li, S.; Wang, C.; Zheng, F.; Jin, Y. Deep industrial image anomaly detection: A survey. Mach. Intell. Res. 2023, 21, 104–135. [Google Scholar]
- Yang, Q.; Guo, R. An Unsupervised Method for Industrial Image Anomaly Detection with Vision Transformer-Based Autoencoder. Sensors 2024, 24, 2440. [Google Scholar] [CrossRef] [PubMed]
- Tao, X.; Gong, X.; Zhang, X.Y.; Yan, S.; Adak, C. Deep learning for unsupervised anomaly localization in industrial images: A survey. IEEE Trans. Instrum. Meas. 2022, 71, 1–21. [Google Scholar] [CrossRef]
- Liu, J.; Xie, G.; Chen, R.; Li, X.; Wang, J.; Liu, Y.; Wang, C.; Zheng, F. Real3d-ad: A dataset of point cloud anomaly detection. arXiv 2023, arXiv:2309.13226. [Google Scholar]
- Roth, K.; Pemula, L.; Zepeda, J.; Scholkopf, B.; Brox, T.; Gehler, P. Towards total recall in industrial anomaly detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2021; pp. 14298–14308. [Google Scholar]
- Wang, L.; Yoon, K.-J. Knowledge distillation and student teacher learning for visual intelligence: A review and new outlooks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 3048–3068. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Lyu, X.; Guo, X. Knowledge distillation with attention mechanism for anomaly detection. In Proceedings of the International Conference on Signal Processing and Computer Science, Guilin, China, 25–27 August 2023. [Google Scholar]
- Li, Z.; Ge, Y.; Wang, X.; Yue, X.; Meng, L. Industrial anomaly detection via teacher student network. In Proceedings of the 2023 International Conference on Advanced Mechatronic Systems (ICAMechS), Melbourne, Australia, 4–7 September 2023; pp. 1–5. [Google Scholar]
- Cai, F.; Xia, S. Mixed distillation for unsupervised anomaly detection. In Proceedings of the 2023 18th International Conference on Machine Vision and Applications (MVA), Hamamatsu, Japan, 23–25 July 2023; pp. 1–5. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2020, Seattle, WA, USA, 13–19 June 2019; pp. 4182–4191. [Google Scholar]
- Wang, G.; Han, S.; Ding, E.; Huang, D. Student-teacher feature pyramid matching for anomaly detection. In Proceedings of the British Machine Vision Conference, Online, 22–25 November 2021. [Google Scholar]
- Deng, H.; Li, X. Anomaly detection via reverse distillation from one-class embedding. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9727–9736. [Google Scholar]
- Nguyen, V.-D.; Bach, H.H.; Trang, L.H. An improved reverse distillation model for unsupervised anomaly detection. In Proceedings of the 2023 17th International Conference on Ubiquitous Information Management and Communication (IMCOM), Seoul, Republic of Korea, 3–5 January 2023; pp. 1–6. [Google Scholar]
- Batzner, K.; Heckler, L.; König, R. Efficientad: Accurate visual anomaly detection at millisecond-level latencies. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, Hawaii, USA, 3–8 January 2024; pp. 127–137. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Bergmann, P.; Batzner, K.; Fauser, M.; Sattlegger, D. Carsten Steger: The MVTec Anomaly Detection Dataset: A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. Int. J. Comput. Vis. 2021, 129, 1038–1059. [Google Scholar] [CrossRef]
- Bergmann, P.; Fauser, M.; Sattlegger, D. Carsten Steger: MVTec AD—A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9584–9592. [Google Scholar] [CrossRef]
- Mishra, P.; Verk, R.; Fornasier, D.; Piciarelli, C.; Foresti, G.L. Vt-adl: A vision transformer network for image anomaly detection and localization. In Proceedings of the 2021 IEEE 30th International Symposium on Industrial Electronics (ISIE), Kyoto, Japan, 20–23 June 2021; pp. 1–6. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Silva, A.L.V.E.; Simões, F.; Kowerko, D.; Schlosser, T.; Battisti, F.; Teichrieb, V. Attention modules improve image level anomaly detection for industrial inspection: A differnet case study. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2023; pp. 8231–8240. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. CoRR 2014, abs/1412.6980. [Google Scholar]
- Ling, C.X.; Huang, J.; Zhang, H. Auc: A statistically consistent and more discriminating measure than accuracy. In Proceedings of the International Joint Conference on Artificial Intelligence, Acapulco, Mexico, 9–15 August 2003. [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skocaj, D. Draem—A discriminatively trained reconstruction embedding for surface anomaly detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 10–17 October 2021; pp. 8310–8319. [Google Scholar]
- Salehi, M.; Sadjadi, N.; Baselizadeh, S.; Rohban, M.H.; Rabiee, H.R. Multiresolution knowledge distillation for anomaly detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2020; pp. 14897–14907. [Google Scholar]
- Thomine, S.; Snoussi, H.; Soua, M. Fable: Fabric anomaly detection automation process. In Proceedings of the 2023 International Conference on Control, Automation and Diagnosis (ICCAD), Rome, Italy, 10–12 May 2023; pp. 1–6. [Google Scholar]
- Rudolph, M.; Wehrbein, T.; Rosenhahn, B.; Wandt, B. Fully Convolutional Cross-Scale-Flows for Image-based Defect Detection. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 1829–1838. [Google Scholar] [CrossRef]
- Gudovskiy, D.; Ishizaka, S.; Kozuka, K. CFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 1819–1828. [Google Scholar] [CrossRef]
- Wang, P.; Yao, H.; Yu, W. SCL-VI: Self-supervised context learning for visual inspection of industrial defects. arXiv 2023, arXiv:2311.06504. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).