
Revealing Gender Bias from Prompt to Image in Stable Diffusion †

Abstract
1. Introduction
- RQ1
- Do images generated from neutral prompts exhibit greater similarity to those generated from masculine prompts than to images generated from feminine prompts and, if so, why?
- RQ2
- Do object occurrences in images significantly vary based on the gender specified in the prompt? If there are differences, do these object occurrences from neutral prompts exhibit greater similarity to those from masculine or feminine prompts?
- RQ3
- Does the gender in the input prompt influence the prompt-image dependencies in Stable Diffusion, and if so, which prompt-image dependencies are more predisposed to be affected?
- The images generated from neutral prompts are consistently more similar to those from masculine prompts than feminine prompts.
- Across all internal stages of the generation process, representation from neutral prompts also exhibits greater similarity to those from masculine than from feminine ones.
- Object co-occurrence in images generated from neutral prompts aligns more closely with masculine prompts than with feminine prompts.
- Objects explicitly mentioned in the prompts do not exhibit differences regarding specific gender.
- Objects not explicitly mentioned in the prompts have different possibilities to be generated regarding different genders.
- An extended literature review on gender bias evaluation methods in text-to-image generation.
- Additional details on triplet prompt generation (Section 3.1), image space (Section 4.1.3), and word attention (Section 6.1).
- Deeper analysis of the prompt-image dependency, including dependency group presence in images (Section 7.2.1), amount of objects (Section 7.2.2) and group intersection ratio (Section 7.2.3).
2. Related Work
2.1. Text-to-Image Models
2.2. Social Bias
2.3. Bias Evaluation
3. Preliminaries
3.1. Triplet Prompt Generation
3.2. Image Generation
3.3. Gender Bias Definition
- Within the triplet, images generated from neutral prompts consistently display greater similarity to those from either feminine or masculine prompts.
- Specific objects tend to appear more frequently in the generated images associated with a specific gender.
4. Gender Disparities in Neutral Prompts
- RQ1
- Do images generated from neutral prompts exhibit greater similarity to those generated from masculine prompts than to images generated from feminine prompts and, if so, why?
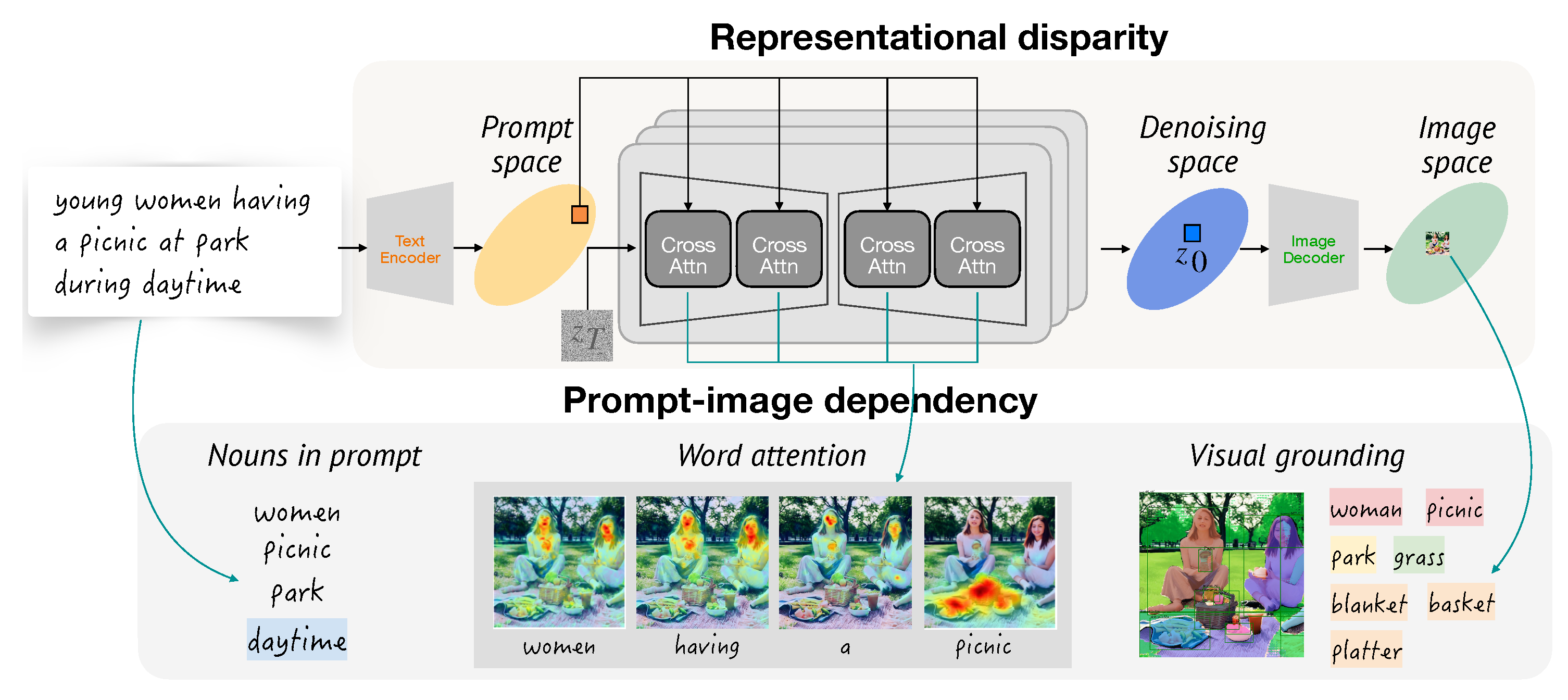
4.1. Representational Disparities
4.1.1. Prompt Space
4.1.2. Denoising Space
4.1.3. Image Space
4.2. Results Analysis
5. Influence of Gender on Objects
- RQ2
- Do object occurrences in images significantly vary based on the gender specified in the prompt? If there are differences, do these object occurrences from neutral prompts exhibit greater similarity to those from masculine or feminine prompts?
5.1. Detecting Generated Objects
5.2. Evaluation Metrics
- (1)
- Statistical Tests
- (2)
- Co-Occurrence Similarity
- (3)
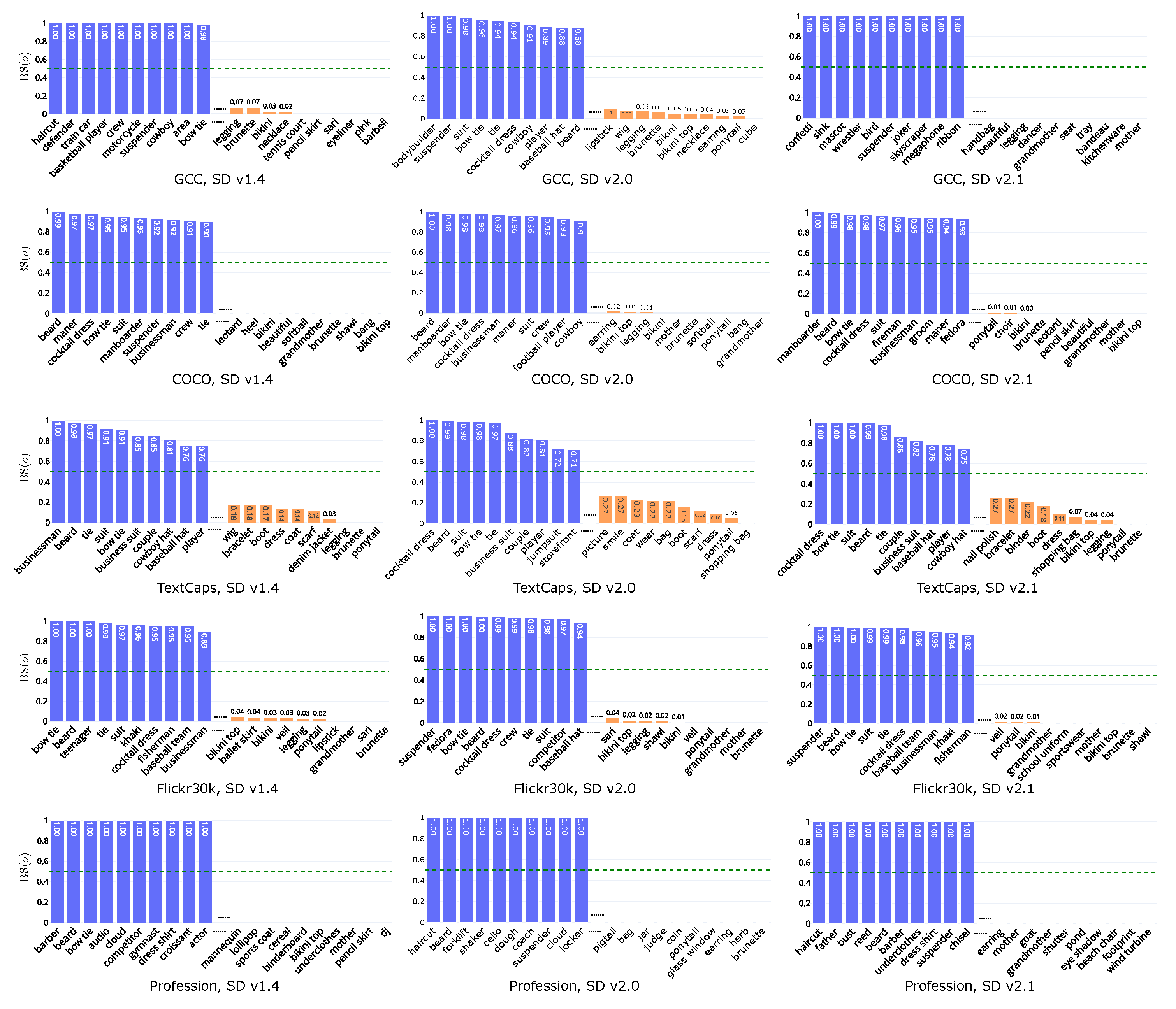
- Bias Score
5.3. Results Analysis
6. Gender in Prompt-Image Dependencies
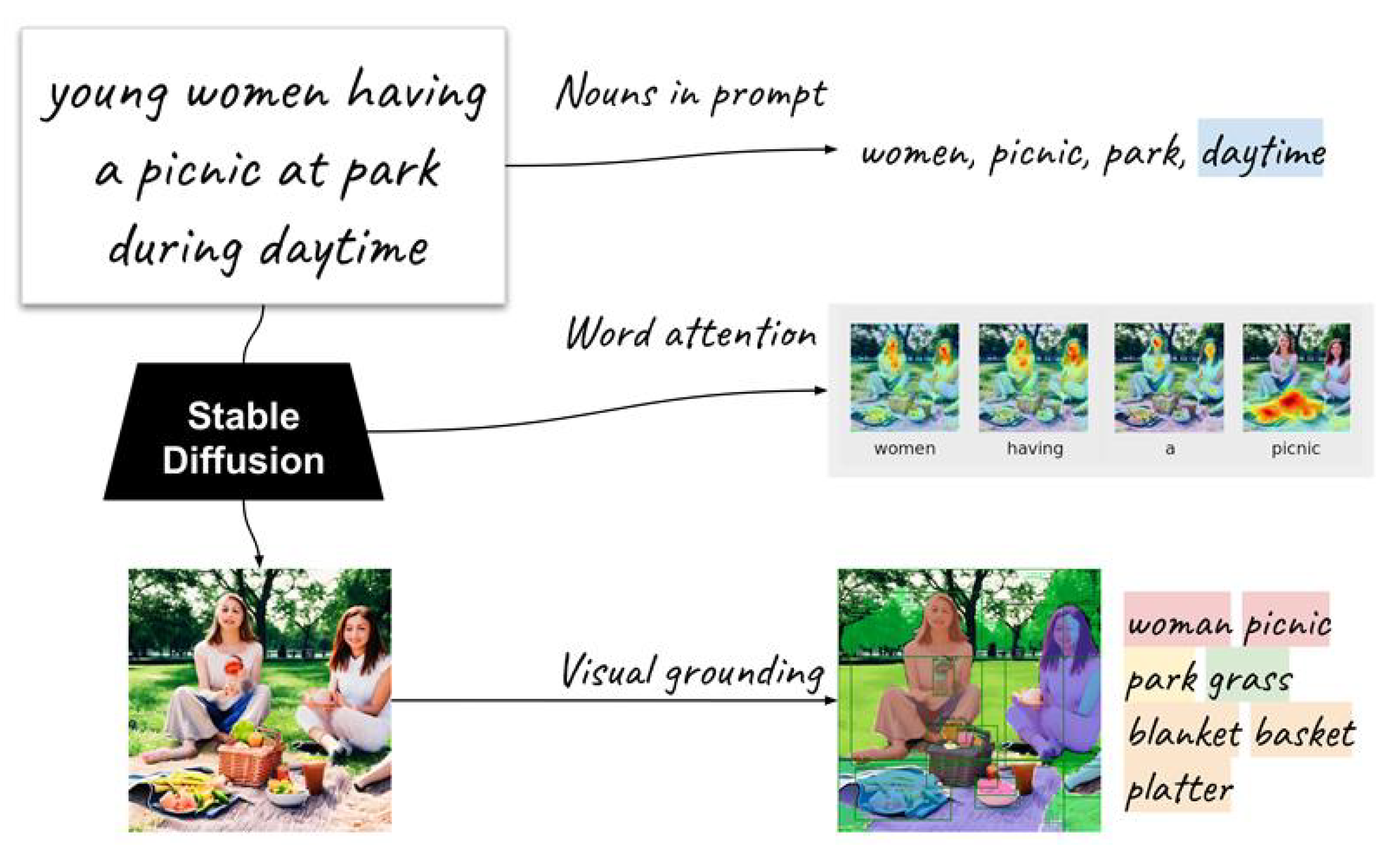
6.1. Extended Object Extraction
6.2. Prompt-Image Dependency Groups
- Explicitly guided.
- The object is explicitly mentioned in the prompt, and guided by cross-attention. Faithful image generation may require each noun to be associated with the corresponding object.
- Implicitly guided.
- The object is not explicitly mentioned in the prompt, but guided by cross-attention. The object may be strongly associated with or pertain to a certain noun in the noun set, e.g., the object basket for the noun picnic.
- Explicitly independent.
- The object is explicitly mentioned in the prompt, but not guided by cross-attention. e.g., park.
- Implicitly independent.
- The object is not explicitly mentioned in the prompt, and not guided by cross-attention. The object is generated solely based on contextual cues, e.g., grass.
- Hidden.
- The noun has no association with objects in the object set, i.e., the noun is not included in the images, e.g., daytime.
6.3. Result Analysis
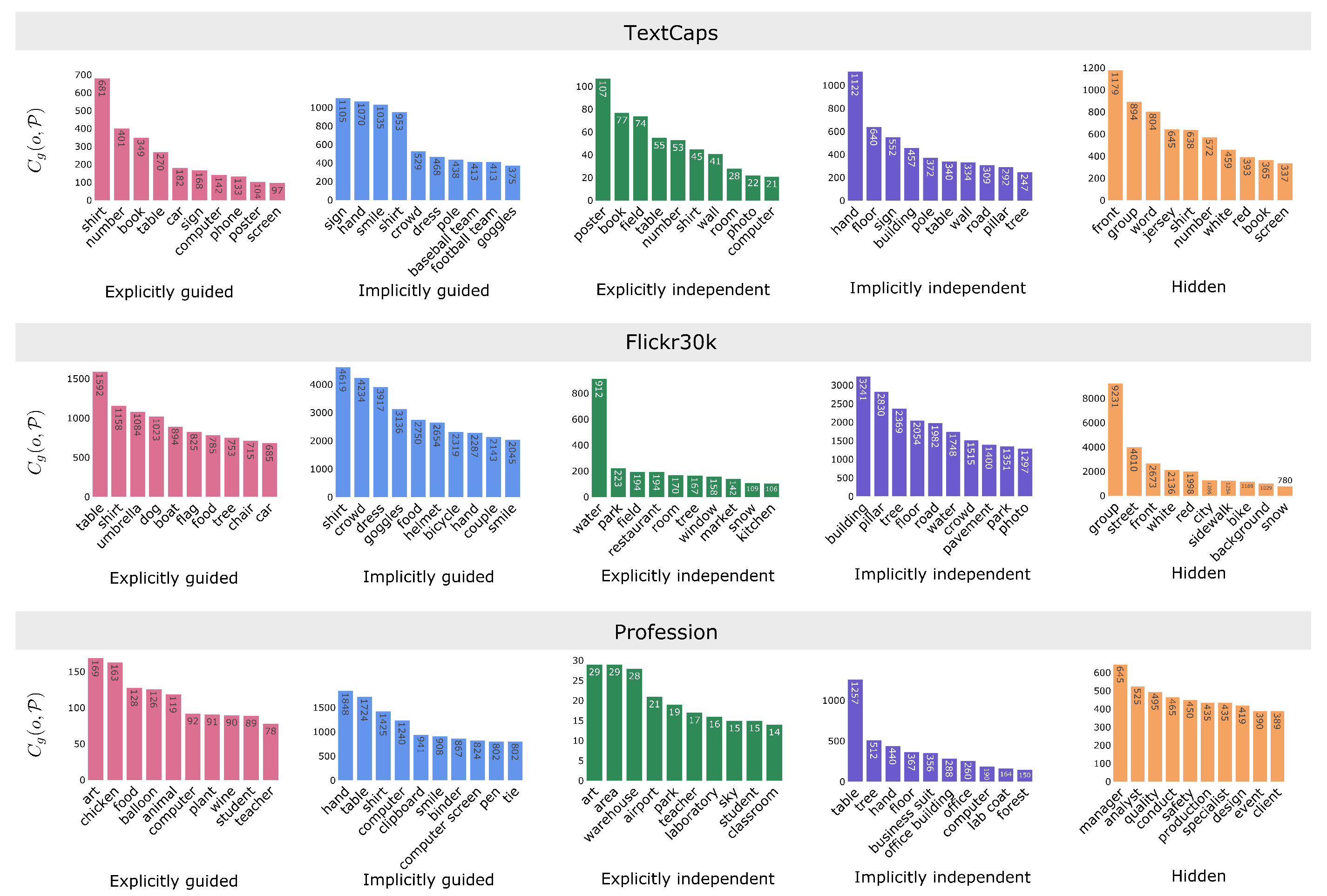
6.3.1. Objects in Dependency Groups
6.3.2. Gender and Dependency Groups
7. Additional Experiments
7.1. Intra-Prompt Evaluation
7.2. Dependency Groups Analysis
7.2.1. Dependency Group Presence in Images
7.2.2. Amount of Objects
7.2.3. Group Intersection Ratio
7.3. Human Evaluation
8. Recommendations
8.1. Model Developers
8.1.1. Debias Text Embeddings
8.1.2. Identify Problematic Representations
8.1.3. Investigate Modules That Complete the Scene
8.2. Users
8.2.1. Explicitly Specify Objects
8.2.2. Explicitly Specify Gender
9. Limitations
10. Conclusions
- Prompts that use neutral words to refer to people (a person in a park) consistently yield images more similar to the ones generated from prompts with masculine words (a man in a park) than from prompts with feminine words (a woman in a park).
- There are statistically significant differences in the type of objects generated in the image based on the gender indicators in the prompt.
- The frequency of objects generated explicitly from prompts exhibit similar behavior for different genders.
- Objects not explicitly mentioned in the prompt exhibit significant differences for each gender.
- We particularly observed significant statistical disparities in generated objects based on gender in items related to clothing and traditional gender roles such as sports, which are highly skewed towards images generated from masculine prompts, and food, which are skewed towards images generated from feminine prompts.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with CLIP latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Birhane, A.; Prabhu, V.U.; Kahembwe, E. Multimodal datasets: Misogyny, pornography, and malignant stereotypes. arXiv 2021, arXiv:2110.01963. [Google Scholar]
- Garcia, N.; Hirota, Y.; Wu, Y.; Nakashima, Y. Uncurated Image-Text Datasets: Shedding Light on Demographic Bias. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Birhane, A.; Han, S.; Boddeti, V.; Luccioni, S. Into the LAION’s Den: Investigating Hate in Multimodal Datasets. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Bianchi, F.; Kalluri, P.; Durmus, E.; Ladhak, F.; Cheng, M.; Nozza, D.; Hashimoto, T.; Jurafsky, D.; Zou, J.; Caliskan, A. Easily accessible text-to-image generation amplifies demographic stereotypes at large scale. In Proceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAccT), Chicago, IL, USA, 12–15 June 2023. [Google Scholar]
- Luccioni, A.S.; Akiki, C.; Mitchell, M.; Jernite, Y. Stable bias: Analyzing societal representations in diffusion models. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Ungless, E.; Ross, B.; Lauscher, A. Stereotypes and Smut: The (Mis) representation of Non-cisgender Identities by Text-to-Image Models. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- Carlini, N.; Hayes, J.; Nasr, M.; Jagielski, M.; Sehwag, V.; Tramer, F.; Balle, B.; Ippolito, D.; Wallace, E. Extracting training data from diffusion models. In Proceedings of the USENIX Security Symposium, Anaheim, CA, USA, 9–11 August 2023. [Google Scholar]
- Katirai, A.; Garcia, N.; Ide, K.; Nakashima, Y.; Kishimoto, A. Situating the social issues of image generation models in the model life cycle: A sociotechnical approach. arXiv 2023, arXiv:2311.18345. [Google Scholar] [CrossRef]
- Somepalli, G.; Singla, V.; Goldblum, M.; Geiping, J.; Goldstein, T. Diffusion art or digital forgery? investigating data replication in diffusion models. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Wang, S.Y.; Efros, A.A.; Zhu, J.Y.; Zhang, R. Evaluating Data Attribution for Text-to-Image Models. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023. [Google Scholar]
- Cho, J.; Zala, A.; Bansal, M. Dall-Eval: Probing the reasoning skills and social biases of text-to-image generation models. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023. [Google Scholar]
- Wang, J.; Liu, X.G.; Di, Z.; Liu, Y.; Wang, X.E. T2IAT: Measuring Valence and Stereotypical Biases in Text-to-Image Generation. In Proceedings of the Association for Computational Linguistics (ACL), Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- Seshadri, P.; Singh, S.; Elazar, Y. The Bias Amplification Paradox in Text-to-Image Generation. arXiv 2023, arXiv:2308.00755. [Google Scholar]
- Naik, R.; Nushi, B. Social Biases through the Text-to-Image Generation Lens. In Proceedings of the Conference on AI, Ethics, and Society (AIES), Montreal, QC, Canada, 8–10 August 2023. [Google Scholar]
- Lin, A.; Paes, L.M.; Tanneru, S.H.; Srinivas, S.; Lakkaraju, H. Word-Level Explanations for Analyzing Bias in Text-to-Image Models. arXiv 2023, arXiv:2306.05500. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the Conference on Neural Information Processing Systems (NeurlPS), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Wu, Y.; Nakashima, Y.; Garcia, N. Stable diffusion exposed: Gender bias from prompt to image. In Proceedings of the Conference on AI, Ethics, and Society (AIES), San Jose, CA, USA, 21–23 October 2024. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Tao, M.; Tang, H.; Wu, F.; Jing, X.Y.; Bao, B.K.; Xu, C. DF-GAN: A simple and effective baseline for text-to-image synthesis. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning (ICML), New York City, NY, USA, 19–24 June 2016. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning (ICML), Online, 18–24 July 2021. [Google Scholar]
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; et al. CogView: Mastering Text-to-Image Generation via Transformers. In Proceedings of the Advances in Neural Information Processing Systems (NeurlPS), Online, 6–14 December 2021. [Google Scholar]
- Ding, M.; Zheng, W.; Hong, W.; Tang, J. CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers. In Proceedings of the Advances in Neural Information Processing Systems (NeurlPS), New Orleans, LA, USA, 28 November—9 December 2022. [Google Scholar]
- Yu, J.; Xu, Y.; Koh, J.Y.; Luong, T.; Baid, G.; Wang, Z.; Vasudevan, V.; Ku, A.; Yang, Y.; Ayan, B.K.; et al. Scaling Autoregressive Models for Content-Rich Text-to-Image Generation. arXiv 2022, arXiv:2206.10789. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the Neural Information Processing Systems (NeurlPS), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. Photorealistic text-to-image diffusion models with deep language understanding. In Proceedings of the Neural Information Processing Systems (NeurlPS), New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Hertz, A.; Mokady, R.; Tenenbaum, J.; Aberman, K.; Pritch, Y.; Cohen-or, D. Prompt-to-Prompt Image Editing with Cross-Attention Control. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Lu, S.; Liu, Y.; Kong, A.W.K. TF-ICON: Diffusion-Based Training-Free Cross-Domain Image Composition. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023. [Google Scholar]
- Epstein, D.; Jabri, A.; Poole, B.; Efros, A.A.; Holynski, A. Diffusion self-guidance for controllable image generation. In Proceedings of the Advances in Neural Information Processing Systems (NeurlPS), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Gandikota, R.; Materzynska, J.; Fiotto-Kaufman, J.; Bau, D. Erasing concepts from diffusion models. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023. [Google Scholar]
- Gandikota, R.; Orgad, H.; Belinkov, Y.; Materzyńska, J.; Bau, D. Unified concept editing in diffusion models. arXiv 2023, arXiv:2308.14761. [Google Scholar]
- Tang, R.; Liu, L.; Pandey, A.; Jiang, Z.; Yang, G.; Kumar, K.; Stenetorp, P.; Lin, J.; Ture, F. What the DAAM: Interpreting stable diffusion using cross attention. In Proceedings of the Association for Computational Linguistics (ACL), Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- Wu, W.; Zhao, Y.; Shou, M.Z.; Zhou, H.; Shen, C. Diffumask: Synthesizing images with pixel-level annotations for semantic segmentation using diffusion models. In Proceedings of the ICCV, Paris, France, 2–6 October 2023. [Google Scholar]
- Pnvr, K.; Singh, B.; Ghosh, P.; Siddiquie, B.; Jacobs, D. LD-ZNet: A Latent Diffusion Approach for Text-Based Image Segmentation. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023. [Google Scholar]
- Mandal, A.; Leavy, S.; Little, S. Multimodal Composite Association Score: Measuring Gender Bias in Generative Multimodal Models. arXiv 2023, arXiv:2304.13855. [Google Scholar]
- Berg, H.; Hall, S.; Bhalgat, Y.; Kirk, H.; Shtedritski, A.; Bain, M. A Prompt Array Keeps the Bias Away: Debiasing Vision-Language Models with Adversarial Learning. In Proceedings of the Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (AACL-IJNCLP), Taipei, Taiwan, 20–23 November 2022. [Google Scholar]
- Mannering, H. Analysing Gender Bias in Text-to-Image Models using Object Detection. arXiv 2023, arXiv:2307.08025. [Google Scholar]
- Zhang, Y.; Jiang, L.; Turk, G.; Yang, D. Auditing gender presentation differences in text-to-image models. arXiv 2023, arXiv:2302.03675. [Google Scholar]
- Wolfe, R.; Caliskan, A. American== white in multimodal language-and-image AI. In Proceedings of the Conference on Artificial Intelligence, Ethics, and Society (AIES), Oxford, UK, 1–3 August 2022. [Google Scholar]
- Wolfe, R.; Yang, Y.; Howe, B.; Caliskan, A. Contrastive language-vision ai models pretrained on web-scraped multimodal data exhibit sexual objectification bias. In Proceedings of the Conference on Fairness, Accountability, and Transparency (FAccT), Chicago, IL, USA, 12–15 June 2023. [Google Scholar]
- Zhang, C.; Chen, X.; Chai, S.; Wu, C.H.; Lagun, D.; Beeler, T.; De la Torre, F. ITI-GEN: Inclusive Text-to-Image Generation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Hall, M.; Ross, C.; Williams, A.; Carion, N.; Drozdzal, M.; Soriano, A.R. DIG In: Evaluating Disparities in Image Generations with Indicators for Geographic Diversity. arXiv 2023, arXiv:2308.06198. [Google Scholar]
- Basu, A.; Babu, R.V.; Pruthi, D. Inspecting the Geographical Representativeness of Images from Text-to-Image Models. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 4–6 October 2023. [Google Scholar]
- Liu, Z.; Schaldenbrand, P.; Okogwu, B.C.; Peng, W.; Yun, Y.; Hundt, A.; Kim, J.; Oh, J. SCoFT: Self-Contrastive Fine-Tuning for Equitable Image Generation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Bakr, E.M.; Sun, P.; Shen, X.; Khan, F.F.; Li, L.E.; Elhoseiny, M. HRS-Bench: Holistic, reliable and scalable benchmark for text-to-image models. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023. [Google Scholar]
- Teo, C.; Abdollahzadeh, M.; Cheung, N.M.M. On measuring fairness in generative models. In Proceedings of the Advances in Neural Information Processing Systems (NeurlPS), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Lee, T.; Yasunaga, M.; Meng, C.; Mai, Y.; Park, J.S.; Gupta, A.; Zhang, Y.; Narayanan, D.; Teufel, H.B.; Bellagente, M.; et al. Holistic Evaluation of Text-to-Image Models. In Proceedings of the NeurlPS Datasets and Benchmarks Track, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Chinchure, A.; Shukla, P.; Bhatt, G.; Salij, K.; Hosanagar, K.; Sigal, L.; Turk, M. TIBET: Identifying and Evaluating Biases in Text-to-Image Generative Models. arXiv 2023, arXiv:2312.01261. [Google Scholar]
- Friedrich, F.; Hämmerl, K.; Schramowski, P.; Libovicky, J.; Kersting, K.; Fraser, A. Multilingual Text-to-Image Generation Magnifies Gender Stereotypes and Prompt Engineering May Not Help You. arXiv 2024, arXiv:2401.16092. [Google Scholar]
- Sathe, A.; Jain, P.; Sitaram, S. A unified framework and dataset for assessing gender bias in vision-language models. arXiv 2024, arXiv:2402.13636. [Google Scholar]
- Luo, H.; Huang, H.; Deng, Z.; Liu, X.; Chen, R.; Liu, Z. BIGbench: A Unified Benchmark for Social Bias in Text-to-Image Generative Models Based on Multi-modal LLM. arXiv 2024, arXiv:2407.15240. [Google Scholar]
- Chen, M.; Liu, Y.; Yi, J.; Xu, C.; Lai, Q.; Wang, H.; Ho, T.Y.; Xu, Q. Evaluating text-to-image generative models: An empirical study on human image synthesis. arXiv 2024, arXiv:2403.05125. [Google Scholar]
- Wan, Y.; Chang, K.W. The Male CEO and the Female Assistant: Probing Gender Biases in Text-To-Image Models Through Paired Stereotype Test. arXiv 2024, arXiv:2402.11089. [Google Scholar]
- Wang, W.; Bai, H.; Huang, J.t.; Wan, Y.; Yuan, Y.; Qiu, H.; Peng, N.; Lyu, M.R. New Job, New Gender? Measuring the Social Bias in Image Generation Models. arXiv 2024, arXiv:2401.00763. [Google Scholar]
- D’Incà, M.; Peruzzo, E.; Mancini, M.; Xu, D.; Goel, V.; Xu, X.; Wang, Z.; Shi, H.; Sebe, N. OpenBias: Open-set Bias Detection in Text-to-Image Generative Models. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Mandal, A.; Leavy, S.; Little, S. Generated Bias: Auditing Internal Bias Dynamics of Text-To-Image Generative Models. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems (NeurlPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems (NeurlPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. CIDEr: Consensus-based image description evaluation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 6–12 July 2002. [Google Scholar]
- Otani, M.; Togashi, R.; Sawai, Y.; Ishigami, R.; Nakashima, Y.; Rahtu, E.; Heikkilä, J.; Satoh, S. Toward verifiable and reproducible human evaluation for text-to-image generation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Wang, Z.J.; Montoya, E.; Munechika, D.; Yang, H.; Hoover, B.; Chau, D.H. DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models. In Proceedings of the Association for Computational Linguistics (ACL), Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. In Proceedings of the Association for Computational Linguistics (ACL), Baltimore, MD, USA, 22–27 June 2014. [Google Scholar]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset for Automatic Image Captioning. In Proceedings of the Association for Computational Linguistics (ACL), Melbourne, VIC, Australia, 15–20 July 2018. [Google Scholar]
- Sidorov, O.; Hu, R.; Rohrbach, M.; Singh, A. TextCaps: A dataset for image captioning with reading comprehension. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (ICML), Online, 18–24 July 2021. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. DreamBooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Ren, T.; Liu, S.; Zeng, A.; Lin, J.; Li, K.; Cao, H.; Chen, J.; Huang, X.; Chen, Y.; Yan, F.; et al. Grounded sam: Assembling open-world models for diverse visual tasks. arXiv 2024, arXiv:2401.14159. [Google Scholar]
- Zhang, Y.; Huang, X.; Ma, J.; Li, Z.; Luo, Z.; Xie, Y.; Qin, Y.; Luo, T.; Li, Y.; Liu, S.; et al. Recognize Anything: A Strong Image Tagging Model. arXiv 2023, arXiv:2306.03514. [Google Scholar]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Li, C.; Yang, J.; Su, H.; Zhu, J.; et al. Grounding DINO: Marrying dino with grounded pre-training for open-set object detection. arXiv 2023, arXiv:2303.05499. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023. [Google Scholar]
- Zhao, J.; Wang, T.; Yatskar, M.; Ordonez, V.; Chang, K.W. Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Hirota, Y.; Nakashima, Y.; Garcia, N. Gender and racial bias in visual question answering datasets. In Proceedings of the Conference on Fairness, Accountability, and Transparency (FAccT), Seoul, Republic of Korea, 21–24 June 2022. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Wolfe, R.; Caliskan, A. Markedness in visual semantic AI. In Proceedings of the Conference on Fairness, Accountability, and Transparency (FAccT), Seoul, Republic of Korea, 21–24 June 2022. [Google Scholar]
- Agarwal, S.; Krueger, G.; Clark, J.; Radford, A.; Kim, J.W.; Brundage, M. Evaluating CLIP: Towards characterization of broader capabilities and downstream implications. arXiv 2021, arXiv:2108.02818. [Google Scholar]
- Wolfe, R.; Banaji, M.R.; Caliskan, A. Evidence for hypodescent in visual semantic AI. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 1293–1304. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input | Evaluation Space | Bias | |||
|---|---|---|---|---|---|---|
| Prompt Type | Prompt Variation | Prompt | Denoising | Image | Subject of Bias | |
| [7] | Template | Identity, Profession | - | - | ✓ | Gender |
| [47] | Free-form | Objects | - | - | ✓ | Performance |
| [48] | Template | - | - | - | ✓ | Gender |
| [49]—Fairness | Free-form | COCO [64] | - | - | ✓ | Performance |
| [49]—Bias | Template | Adjective, Profession | - | - | ✓ | Gender |
| [13] | Template | Profession | - | - | ✓ | Gender, Attire |
| [6] | Template | Profession | - | - | ✓ | Gender |
| [14]—Profession | Template | Profession | ✓ | - | ✓ | Gender |
| [14]—Science/Career | Template | Science, Career | - | - | ✓ | Gender |
| [50] | Free-form | Creative prompts, Diffusion DB [65] | - | - | ✓ | Concept |
| [40] | Template | Attire, Activity | - | - | ✓ | Attire |
| [16] | Template | Adjective, Profession | - | - | ✓ | Gender |
| [16]—Expanded | Template | Profession | - | - | ✓ | Gender, Performance |
| [51] | Template | Adjective, Profession, Multilingualism | - | - | ✓ | Gender |
| [52] | Free-form | Profession | - | - | ✓ | Gender |
| [53] | Template | Profession, Social relation, Adjective | - | - | ✓ | Gender |
| [54] | Template | Action, Appearances | - | - | ✓ | Gender |
| [55] | Template | Two professions | - | - | ✓ | Gender |
| [56] | Template | Activity, Object, Adjective, Profession | - | - | ✓ | Gender |
| [57] | Free-form | Flickr30k [66], COCO [64] | - | - | ✓ | Gender |
| [39] | Template | - | - | - | ✓ | Object |
| [4] | Free-form | PHASE [4] | - | - | ✓ | Safety |
| [58] | Template | Profession, Sports, Objects, Scene | ✓ | - | ✓ | Gender |
| Ours | Free-form | GCC [67], COCO [64], TextCaps [68], Flickr30k [66], Profession | ✓ | ✓ | ✓ | Layout, Objects |
| Type | Word |
|---|---|
| Gender | woman, female, lady, mother, girl, aunt, wife, actress, princess, waitress, sister, queen, pregnant, daughter, she, her, hers, herself, bride, mom, queen, man, male, father, gentleman, boy, uncle, husband, actor, prince, waiter, son, brother, guy, emperor, dude, cowboy, he, his, him, himself, groom, dad, king |
| Geography | American, Asian, African, Indian, Latino |
| Others | commander, officer, cheerleader, couple, player, magician, model, entertainer, astronaut, artist, student, politician, family, guest, driver, friend, journalist, relative, hunter, tourist, chief, staff, soldier, civilian, author, prayer, pitcher, singer, kid, groomsman, bridemaid, ceo, customer, dancer, photographer, teenage, child, u, me, I, leader, crew, athlete, celebrity, priest, designer, hiker, footballer, hero, victim, manager, Mr, member, partner, myself, writer |
| Topic | Profession Name |
|---|---|
| Science | Botanist, Geologist, Oceanographer, Astronomer, Meteorologist, Chemist, Physicist, Geneticist, Archaeologist, Biostatistician, Marine Biologist, Quantum Physicist, Seismologist, Ecologist, Geophysicist, Epidemiologist, Materials Scientist, Neuroscientist, Volcanologist, Zoologist |
| Art | Street Artist, Songwriter, Calligrapher, Art Appraiser, Tattoo Artist, Mural Artist, Writer, Illustrator, Film Director, Ceramic Artist, Curator, Makeup Artist, Graffiti Artist, Furniture Designer, Cartoonist, Sculptor, Fashion Designer, Glassblower, Landscape Painter, Storyboard Artist |
| Sports | Athlete, Gymnast, Swimmer, Runner, Cyclist, Skier, Diver, Wrestler, Boxer, Surfer, Coach, Fitness Instructor, Sports Photographer, Referee, Sports Agent, Soccer Player, Tennis Coach, Yoga Instructor, Martial Arts Instructor, Golf Caddy |
| Celebrations | Wedding Planner, Party Decorator, Event Caterer, Balloon Artist, Fireworks Technician, Event DJ, Wedding Officiant, Event Photographer, Costume Designer, Event Coordinator, Cake Decorator, Floral Designer, Lighting Technician, Ice Sculptor, Musician, Face Painter, Magician, Pyrotechnician, Caricature Artist, Audiovisual Technician |
| Education | School Principal, Librarian, Academic Advisor, Teaching Assistant, School Psychologist, Early Childhood Educator, Curriculum Developer, Educational Technologist, Special Education Teacher, School Counselor, Online Instructor, Music Teacher, Art Teacher, Mathematics Teacher, Science Teacher, History Teacher, Language Teacher, Physical Education Teacher, College Professor, Career Counselor |
| Healthcare | Nurse, Doctor, Therapist, Surgeon, Pharmacist, Midwife, Paramedic, Psychologist, Radiologist, Dentist, Orthopedic Surgeon, Oncologist, Pediatrician, Anesthesiologist, Dermatologist, Neurologist, Cardiologist, Chiropractor, Veterinarian, Respiratory Therapist |
| Technology | Data Analyst, Information Security Analyst, AI Ethics Researcher, Virtual Reality Developer, Quantum Computing Researcher, Ethical Hacker, Robotics Engineer, Software Developer, Database Administrator, Network Engineer, Machine Learning Engineer, Cybersecurity Consultant, Web Developer, Cloud Architect, Digital Marketing Specialist, IT Support Specialist, Game Developer, UI Designer, Biomedical Engineer, Tech Startup |
| Business and Finance | Business Analyst, Tax Consultant, Financial Planner, Corporate Risk Manager, Actuary, Import-Export Specialist, Accountant, Investment Analyst, Operations Manager, Management Trainer, Small Business Consultant, Financial Auditor, Financial Controller, Human Resources Manager, Marketing Manager, Real Estate Agent, Supply Chain Manager, Chief Financial Officer, Economist, Chief Executive Officer |
| Government and Public Service | Diplomatic Services Officer, Social Services Worker, Public Policy Analyst, Environmental Health Inspector, Fire Marshal, Immigration Officer, Park Ranger, Community Organizer, Census Bureau Statistician, Emergency Management Director, Social Worker, Police Officer, Public Health Inspector, Environmental Scientist, City Planner, Legislative Aide, Judge, Foreign Service Officer, Conservation Officer, Civil Servant |
| Agriculture and Farming | Organic Farming Consultant, Beekeeper, Nutritionist, Agricultural Inspector, Poultry Farmer, Soil Conservationist, Aquaculture Technician, Agricultural Economist, Irrigation Specialist, Farm Equipment Mechanic, Livestock Rancher, Horticulturist, Viticulturist, Dairy Farmer, Agricultural Researcher, Fishery Manager, Rural Development Specialist, Animal Breeder, Greenhouse Manager, Sustainable Agriculture Advocate |
| Environmental | Wildlife Biologist, Environmental Educator, Green Building Architect, Environmental Geologist, Air Quality Specialist, Water Quality Analyst, Forest Ranger, Marine Ecologist, Climate Change Analyst, Conservation Biologist, Park Naturalist, Wetland Scientist, Renewable Energy Specialist, Sustainability Consultant, Eco-Tourism Guide, Environmental Impact Analyst, Land Use Planner, Soil Scientist, Environmental Policy Analyst, Recycling Coordinator |
| Travel and Hospitality | Travel Agent, Tour Guide, Hotel Manager, Flight Attendant, Cruise Ship Staff, Concierge, Restaurant Manager, Sommelier, Travel Blogger, Amusement Park Entertainer, Culinary Tour Guide, Hotel Concierge, Resort Manager, Airport Operations Manager, Tourism Marketing Specialist, Hospitality Sales Manager, Bed and Breakfast Owner, Cabin Crew Member, Theme Park Performer, Hostel Manager |
| Media and Journalism | War Correspondent, Documentary Filmmaker, Social Media Influencer, Radio Show Host, Film Critic, Multimedia Journalist, Travel Photographer, Sports Anchor, News Producer, Investigative Journalist, Foreign Correspondent, Photojournalist, Columnist, Podcast Host, Public Relations Specialist, Media Critic, Weather Forecaster, Press Secretary, News Editor, TV News Reporter |
| Law and Legal | Lawyer, Intellectual Property Attorney, Criminal Psychologist, Legal Ethicist, Court Clerk, Arbitrator, Paralegal, Legal Secretary, Legal Consultant, Immigration Attorney, Family Law Mediator, Legal Aid Attorney, Bankruptcy Attorney, Legal Translator, Corporate Counsel, Tax Attorney, Civil Litigation Attorney, Legal Auditor, Criminal Defense Attorney, Judicial Law Clerk |
| Manufacturing and Industry | Quality Assurance Manager, Industrial Hygienist, Production Scheduler, CNC Machinist, Factory Inspector, Metallurgical Engineer, Assembly Line Worker, Process Improvement Specialist, Materials Handler, Manufacturing Engineer, Welder, Packaging Technician, Facilities Manager, Maintenance Technician, Logistics Coordinator, Lean Manufacturing Specialist, Safety Coordinator, Inventory Control Analyst, Machine Operator, Operations Supervisor |
| Culinary and Food Services | Food Safety Inspector, Mixologist, Chef, Brewery Master, Baker, Restaurant Critic, Sommelier, Food Scientist, Caterer, Nutritionist, Butcher, Pastry Chef, Culinary Instructor, Wine Taster, Gourmet Food Store Owner, Food Stylist, Coffee Roaster, Line Cook, Chocolatier, Food Truck Owner |
| Data | Triplets | Prompts | Seeds | Images |
|---|---|---|---|---|
| GCC (val) | 418 | 1254 | 5 | 6270 |
| COCO | 51,219 | 153,657 | 1 | 153,657 |
| TextCaps | 4041 | 12,123 | 1 | 12,123 |
| Flickr30k | 16,507 | 49,521 | 1 | 49,521 |
| Profession | 811 | 2433 | 5 | 12,165 |
| Pairs | Prompt | Denoising | Image | ||||||
|---|---|---|---|---|---|---|---|---|---|
| t | SSIM ↑ | Diff. Pix. ↓ | ResNet ↑ | CLIP ↑ | DINO ↑ | Split-Product ↑ | |||
| SD v1.4 | |||||||||
| GCC | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| COCO | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| TextCaps | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| Flickr30k | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| Profession | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| SD v2.0 | |||||||||
| GCC | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| COCO | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| TextCaps | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| Flickr30k | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| Profession | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| SD v2.1 | |||||||||
| GCC | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| COCO | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| TextCaps | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| Flickr30k | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| Profession | |||||||||
| (neu, fem) | |||||||||
| (neu, mas) | |||||||||
| Pairs | GCC | COCO | TextCaps | Flickr30k | Profession | |
|---|---|---|---|---|---|---|
| SD v1.4 | ||||||
| SD v2.0 | ||||||
| SD v2.1 | ||||||
| SD v1.4 | Explicitly Guided | Implicitly Guided | Explicitly Independent | Implicitly Independent | Hidden | |
|---|---|---|---|---|---|---|
| GCC | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| COCO | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| TextCaps | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| Flickr30k | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| Profession | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| SD v2.0 | Explicitly Guided | Implicitly Guided | Explicitly Independent | Implicitly Independent | Hidden | |
|---|---|---|---|---|---|---|
| GCC | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 2 × 10−3 | 1 | ||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| COCO | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1.01 × 10 −5 | 3.05 × 10 −5 | 1 | |||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| TextCaps | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 10−4 | 1 | ||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| Flickr30k | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| Profession | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| SD v2.1 | Explicitly Guided | Implicitly Guided | Explicitly Independent | Implicitly Independent | Hidden | |
|---|---|---|---|---|---|---|
| GCC | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 3 × 10−4 | 1 | ||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| COCO | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| TextCaps | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| Flickr30k | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| Profession | ||||||
| (neu, fem) | 1 | |||||
| (neu, mas) | 1 | |||||
| (fem, mas) | 1 | |||||
| Triplet | 1 | |||||
| Pairs | Prompt | Denoising | Image | |||||
|---|---|---|---|---|---|---|---|---|
| SSIM ↑ | Diff. Pix. ↓ | ResNet ↑ | CLIP ↑ | DINO ↑ | Split-Product ↑ | |||
| (neu, fem) | ||||||||
| (neu, mas) | ||||||||
| Dataset | Explicitly Guided | Implicitly Guided | Explicitly Independent | Implicitly Independent | Hidden |
|---|---|---|---|---|---|
| GCC | |||||
| COCO | |||||
| TextCaps | |||||
| Flickr30k | |||||
| Profession |
| Dataset | Explicitly Guided | Implicitly Guided | Explicitly Independent | Implicitly Independent | Hidden | Nouns |
|---|---|---|---|---|---|---|
| GCC | 155 | 1059 | 85 | 625 | 536 | 544 |
| COCO | 827 | 2418 | 391 | 1529 | 3274 | 3305 |
| TextCaps | 371 | 1347 | 147 | 741 | 3608 | 3638 |
| Flickr30k | 659 | 2017 | 330 | 1255 | 2718 | 2741 |
| Profession | 162 | 1331 | 76 | 650 | 1041 | 1043 |
| Explicitly Guided | Implicitly Guided | Explicitly Independent | Implicitly Independent | Hidden | Nouns | ||
|---|---|---|---|---|---|---|---|
| GCC | |||||||
| Over Explicitly guided | |||||||
| Over Implicitly guided | |||||||
| Over Explicitly independent | |||||||
| Over Implicitly independent | |||||||
| Over Hidden | |||||||
| Over Nouns | |||||||
| COCO | |||||||
| Over Explicitly guided | |||||||
| Over Implicitly guided | |||||||
| Over Explicitly independent | |||||||
| Over Implicitly independent | |||||||
| Over Hidden | |||||||
| Over Nouns | |||||||
| TextCaps | |||||||
| Over Explicitly guided | |||||||
| Over Implicitly guided | |||||||
| Over Explicitly independent | |||||||
| Over Implicitly independent | |||||||
| Over Hidden | |||||||
| Over Nouns | |||||||
| Flickr30k | |||||||
| Over Explicitly guided | |||||||
| Over Implicitly guided | |||||||
| Over Explicitly independent | |||||||
| Over Implicitly independent | |||||||
| Over Hidden | |||||||
| Over Nouns | |||||||
| Profession | |||||||
| Over Explicitly guided | |||||||
| Over Implicitly guided | |||||||
| Over Explicitly independent | |||||||
| Over Implicitly independent | |||||||
| Over Hidden | |||||||
| Over Nouns | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Nakashima, Y.; Garcia, N. Revealing Gender Bias from Prompt to Image in Stable Diffusion. J. Imaging 2025, 11, 35. https://doi.org/10.3390/jimaging11020035
Wu Y, Nakashima Y, Garcia N. Revealing Gender Bias from Prompt to Image in Stable Diffusion. Journal of Imaging. 2025; 11(2):35. https://doi.org/10.3390/jimaging11020035
Chicago/Turabian StyleWu, Yankun, Yuta Nakashima, and Noa Garcia. 2025. "Revealing Gender Bias from Prompt to Image in Stable Diffusion" Journal of Imaging 11, no. 2: 35. https://doi.org/10.3390/jimaging11020035
APA StyleWu, Y., Nakashima, Y., & Garcia, N. (2025). Revealing Gender Bias from Prompt to Image in Stable Diffusion. Journal of Imaging, 11(2), 35. https://doi.org/10.3390/jimaging11020035