1. Introduction
Railways contribute significantly to economic growth, especially in developing countries [
1]. Moreover, railway transportation systems are a more environmentally friendly mode, with less noise pollution and energy consumption compared to airways, roads, and waterways [
2,
3]. Railway tracks play a crucial role in ensuring the safe and efficient operation of railway transportation [
4]. However, railway track defects are a common cause of train accidents, which can lead to injuries, fatalities, and significant economic losses. Therefore, the regular inspection of railway tracks is essential to identify and address potential defects [
5]. Traditional railway track inspection methods involve visual and manual inspection by human experts or using specialized vehicles equipped with sensors. However, these methods are time-consuming, costly, and may not always be effective at detecting defects [
6,
7].
There are alternative methods to detect damage and monitor the railway tracks. Loveday [
8] explores a method to detect axial stress in railway tracks by using guided waves. Hashmi et al. [
9] replaced the manual fault identification on the railway, which is performed by a railway engineer with on-the-fly feature extraction. This feature extraction is based on a deep learning model to generate spectrograms that can ensure they are less time-consuming and prone to error than traditional systems. Three deep learning models, including Convolutional 1D, Convolutional 2D, and Long-Short Term Memory (LSTM), are used to analyze different lengths of audio samples.
Computer vision is another technique that can be applied to railway track inspection and monitoring. There are a number of approaches proposed for inspecting and monitoring railway tracks using computer vision techniques. Ruvo et al. [
10] present a Visual Inspection System for railway maintenance that can detect and track the rail head in a video sequence, reducing the area to be analyzed by using FPGA technology, which is highly flexible and configurable as it is based on classifiers that can be easily reconfigured for different types of rails. Ritika and Rao [
11] propose a method to detect track anomalies, such as vegetation overgrowth and sun kinks, using a camera mounted on a moving locomotive and a simulated image pipeline. The Inception V3 model is used for the binary classification of vegetation overgrowth and sun kinks, and the trained model is tested on professionally simulated track videos. Although the model shows that the proposed method can classify track anomalies with high precision, the method relies on a camera mounted on a moving locomotive, which may not be feasible in all situations or for all types of tracks. Moreover, the simulated images used for training the model may not perfectly represent real-world track anomalies, which could affect the accuracy of the model. Gasparini et al. [
12] proposed a vision-based framework for detecting obstacles on railways during the night using RGB or thermal images. The framework uses a rail drone equipped with cameras and external light sources to collect data. The collected data are used to train a deep learning model that can accurately detect obstacles. The experiments show that the proposed approach is suitable for implementation on a self-powered drone. Nonetheless, the use of drones to collect data is limited by their unpredictable position and short battery life. Gasparini et al. [
13] proposed another framework for the automatic inspection of railways during the night using thermal images. The framework consists of three modules for detecting, localizing, and classifying anomalies. The authors also introduce a new dataset called Vesuvio, which was acquired from a rail drone specifically created for anomaly detection tasks in a railway scenario during the night. However, the power consumption of light sources used for night vision is limited to rail drones that are self-powered. Acquisition cameras with a high spatial resolution are needed to detect even small-sized objects. Gibert et al. [
14] proposed a new method for fastener detection in railway tracks using a combination of linear Support Vector Machine (SVM) classifiers and a histogram of oriented gradients features to improve the classification margin. The system can inspect ties for missing or defective rail fastener problems for missing and broken components with grayscale images. Even though these two methods show high accuracy for classification, they are only applicable for grayscale image datasets. In 2016, Gibert et al. [
15] proposed an algorithm for the automated inspection of railway tracks using deep convolutional neural networks and a multi-task learning framework to classify different natural color images of materials and fasteners. The proposed algorithm achieved high accuracy in detecting fasteners and ties, demonstrating its effectiveness in detecting different types of fasteners and materials. However, the proposal for the method does not discuss the computational requirements, which could be a limitation in practical applications. Liu et al. [
16] present a method to improve the performance of rail fastener defect inspection for multiple railways to ensure the safety of railway operation, including a fastener region location method based on an online learning strategy and a fastener defect recognition method based on a deep convolutional neural network. One limitation of the proposed method is that the increase in the maximum queue length of the online template library improves the detection rate but reduces the detection speed, thus affecting the system’s efficiency. Eunus et al. [
4] introduced a novel Deep Learning (DL) algorithm named ECARRNet for automatic fault detection in railway tracks. This method aims to reduce accidents on railway tracks, save lives, and prevent disasters.
All the above works rely on Convolutional Neural Networks (CNNs). However, CNNs struggle with capturing long-range dependencies due to their local receptive field limitations [
17]. Images with thin structures, complex spatial layouts, or multiple views tend to exhibit long-range dependencies [
18,
19]. Capturing long-range dependencies is crucial for the tasks that handle the complex and interconnected-structure images [
20]. Vision Transformer (ViT) [
21] is one method that can effectively handle this type of image. Vision Transformers are currently applied to various visual inspection tasks such as road tunnel defect classification [
22] and structural condition assessment [
23]. In this study, we employ Vision Transformer instead of CNNs for the railway track inspection task. ViT is a deep learning model architecture that is designed for image recognition tasks. Traditional CNN uses a set of convolutional filters to extract image features, which are then processed by fully connected layers to produce a final prediction. ViT replaces the convolutional layers of CNN with a self-attention [
24] mechanism. It processes the input image directly by dividing an image into a sequence of non-overlapping patches of equal size. Then, each patch is embedded linearly in a low-dimensional feature space. These embedded patches form the input sequence for Transformer blocks. In the Transformer blocks, the self-attention mechanism is used to monitor all input patches and capture their dependencies. The output of the self-attention mechanism is then passed through a feedforward neural network to produce the block’s final output. The output of the last block is then fed to a classification head, which produces the final prediction. In addition to patch embeddings, ViT includes positional embeddings that provide information about the spatial location of each patch. This enables the model to encode the spatial relationships between patches in an image and capture the long-range dependencies, enabling stronger global context modeling [
25,
26,
27]. Additionally, ViT can handle images of any size because it processes image patches independently. This makes ViT more adaptable than CNNs, which require the image to be resized or cropped to a fixed size. Furthermore, ViT has shown promising results not only on large datasets but also on small datasets [
28]. Moreover, ViT has demonstrated state-of-the-art (SOTA) performance on a variety of image classification tasks, outperforming CNNs on certain benchmark datasets [
21].
This paper proposes a novel transformer-based deep learning approach, called RailTrack-DaViT, for detecting defects in railway track images. Railway track images inherently contain long-range dependencies due to the extended, curved geometry of the tracks themselves. Capturing global context and relationships between distant regions is crucial for the classification task. The key contributions are listed as follows:
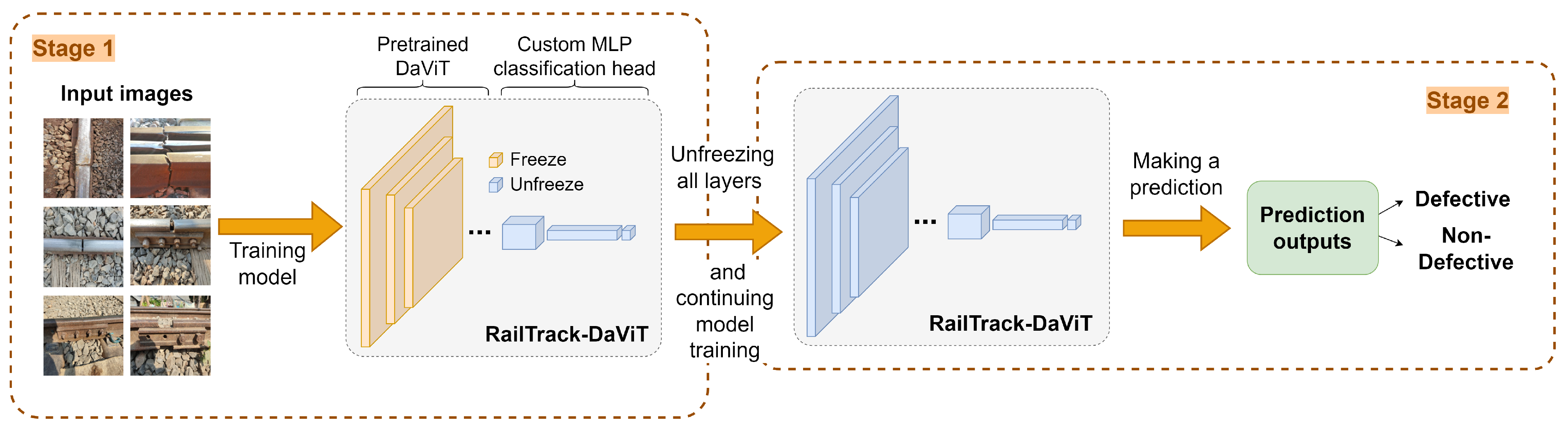
RailTrack-DaViT is a novel approach that applies a Vision Transformer (ViT) to railway track defect binary classification. RailTrack-DaViT is not only able to capture long-range dependencies but also effectively models both global and local information in railway track images.
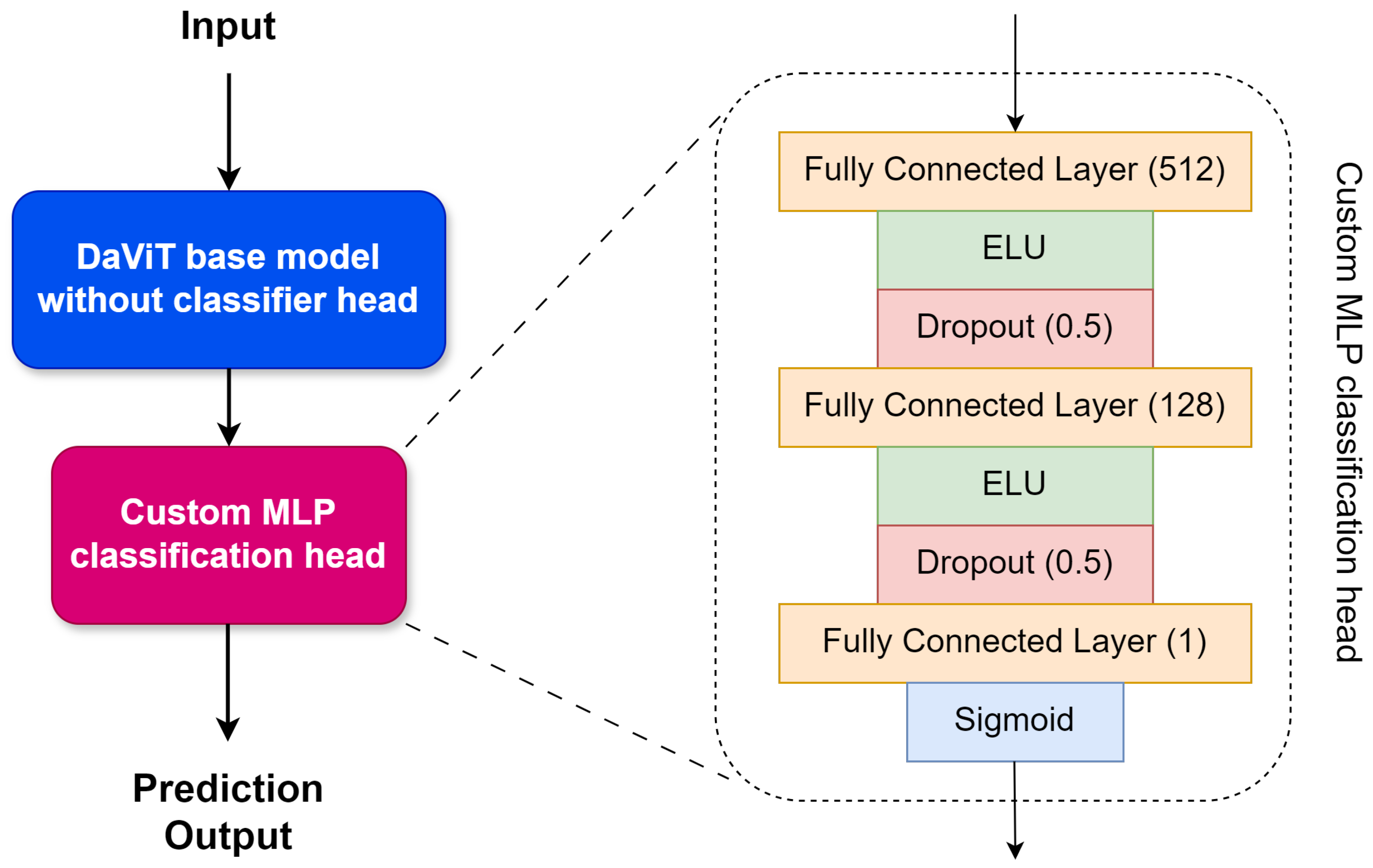
RailTrack-DaViT incorporates a customized classification head and training pipeline that can be effectively trained and tested on datasets containing limited data. These modifications enable RailTrack-DaViT to achieve greater stability and quicker adaptation to unseen images during the fine-tuning process compared to baseline methods.
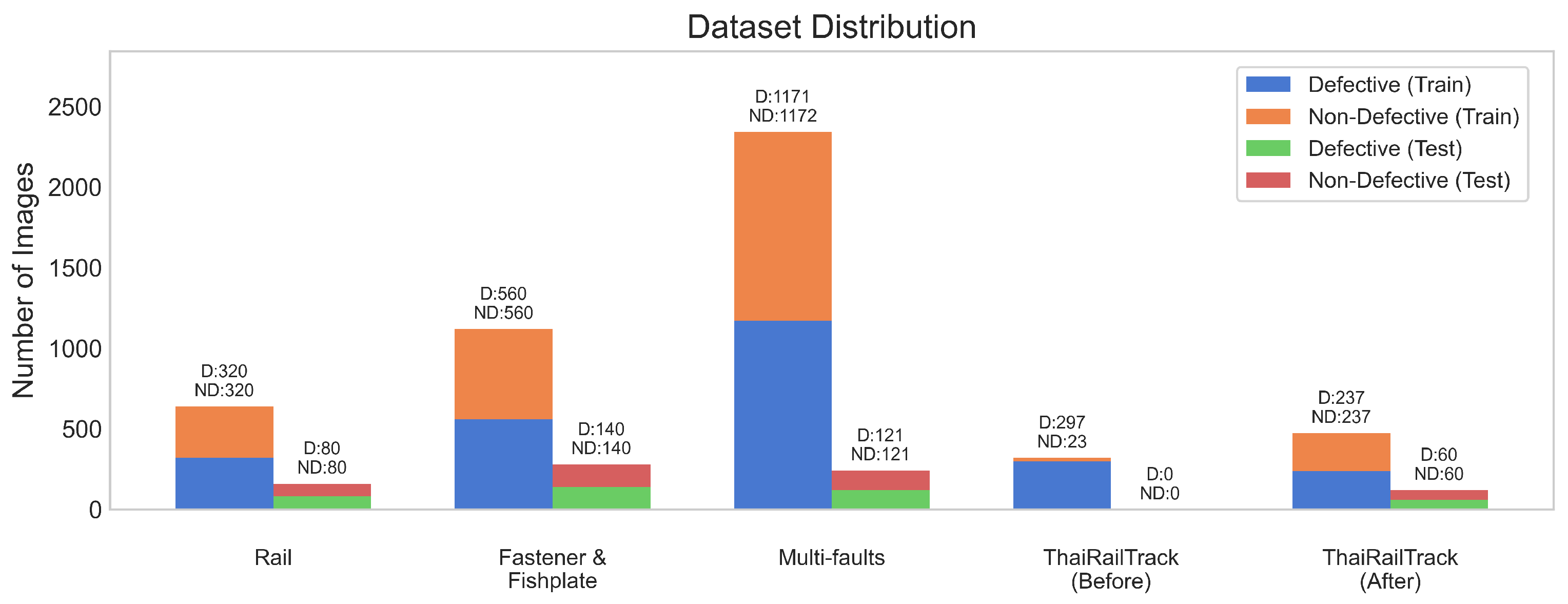
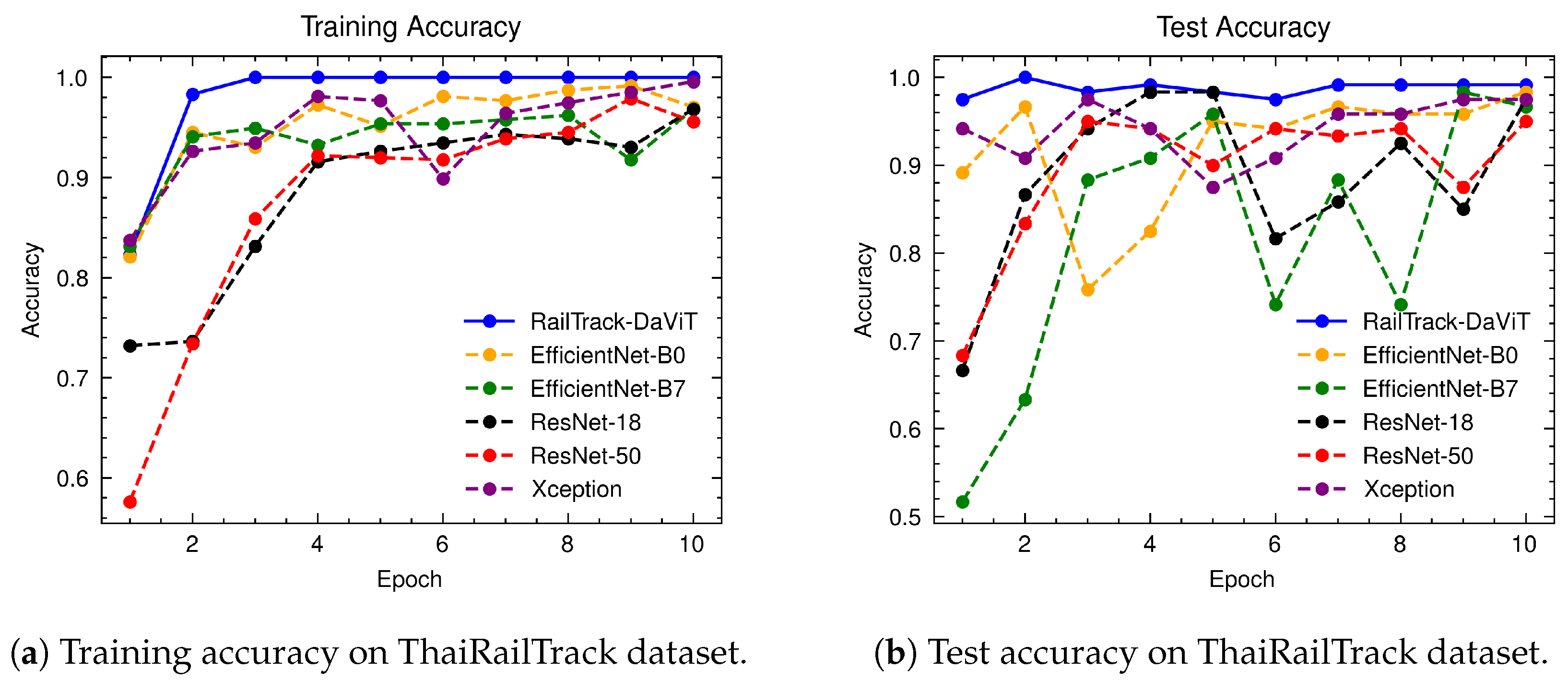
The ThaiRailTrack dataset is constructed by collecting Thai railway track images from two sources: the National Science and Technology Development Agency (NSTDA) and the Passenger Service Department (Operation) of the State Railway of Thailand.
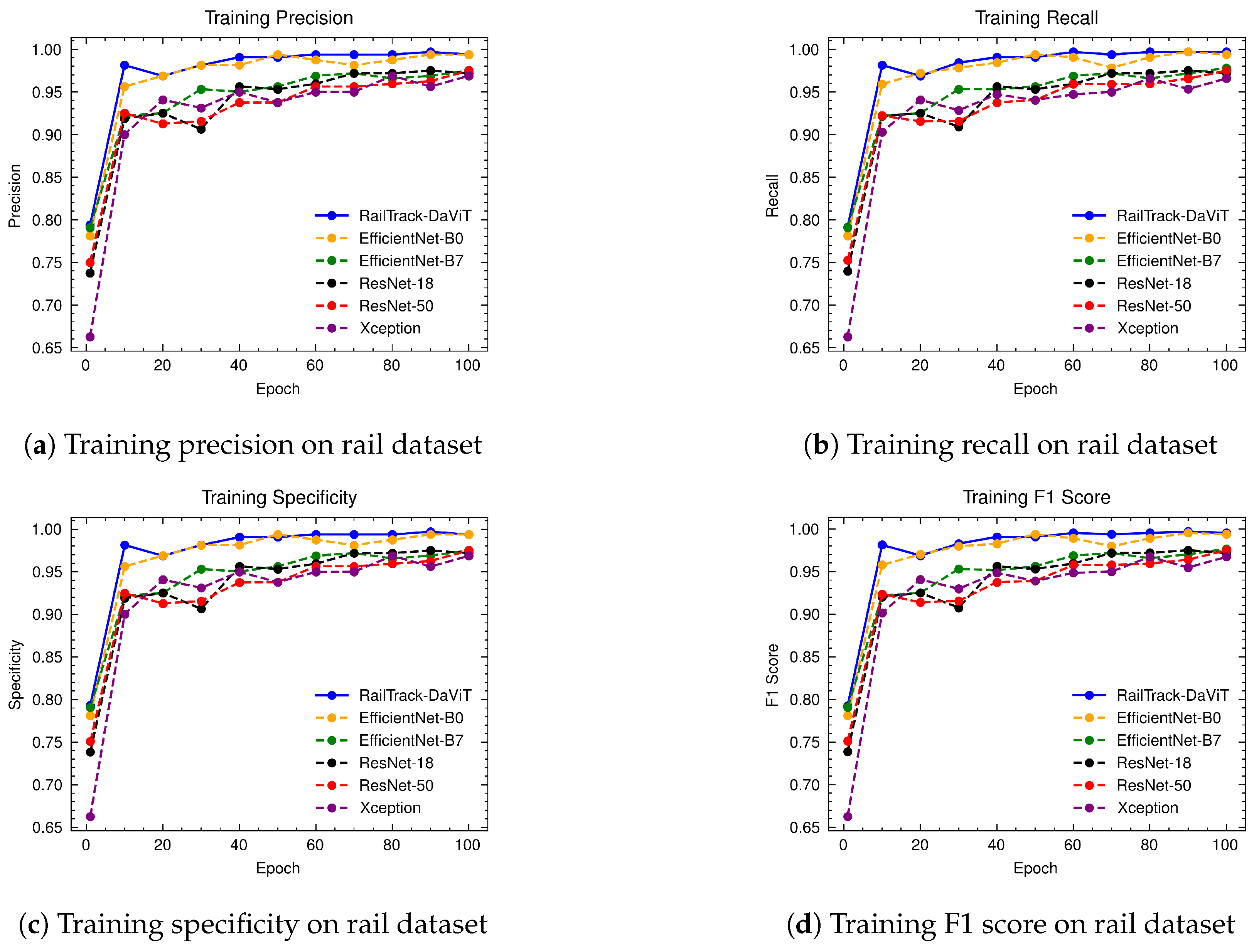
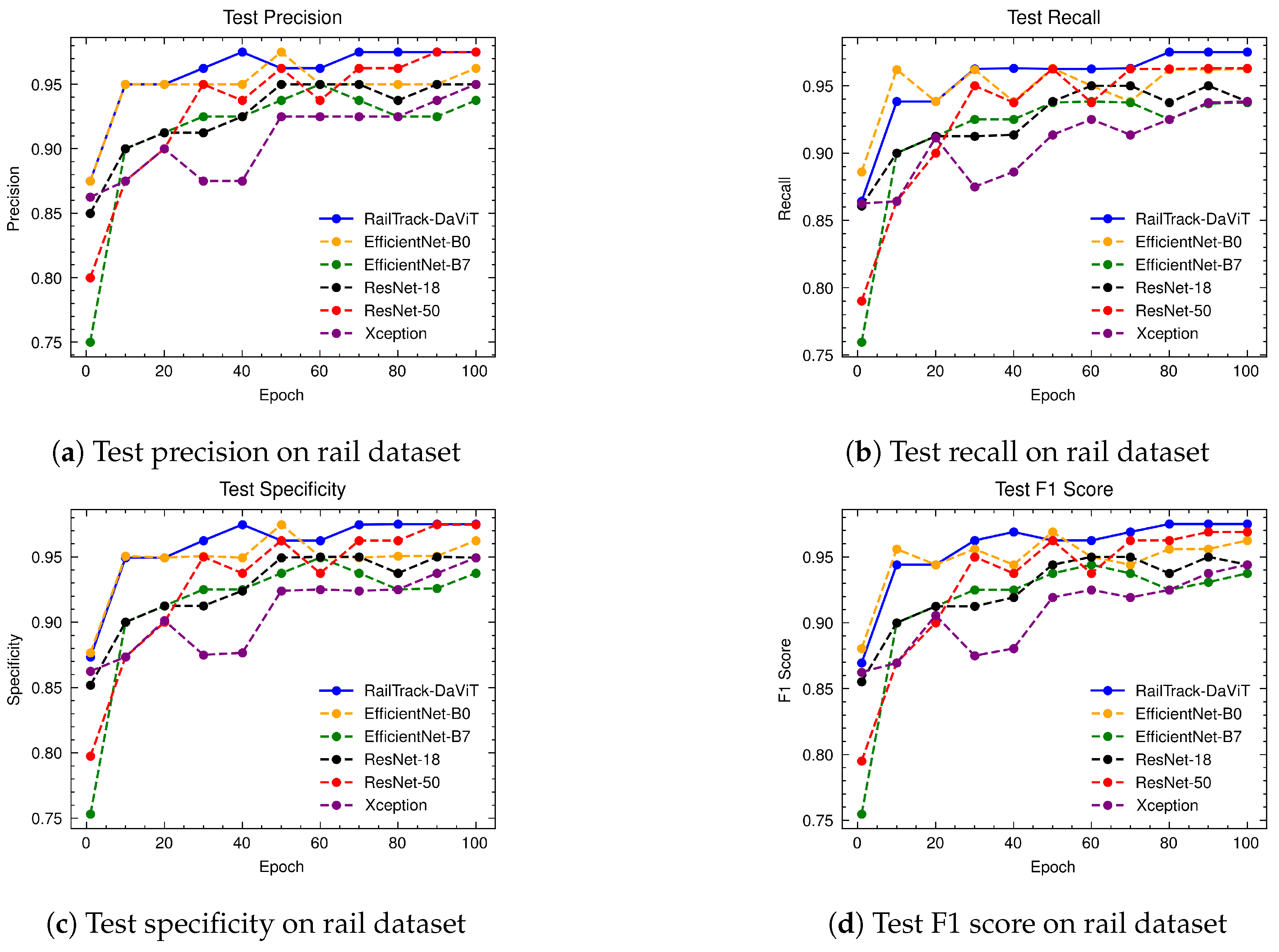
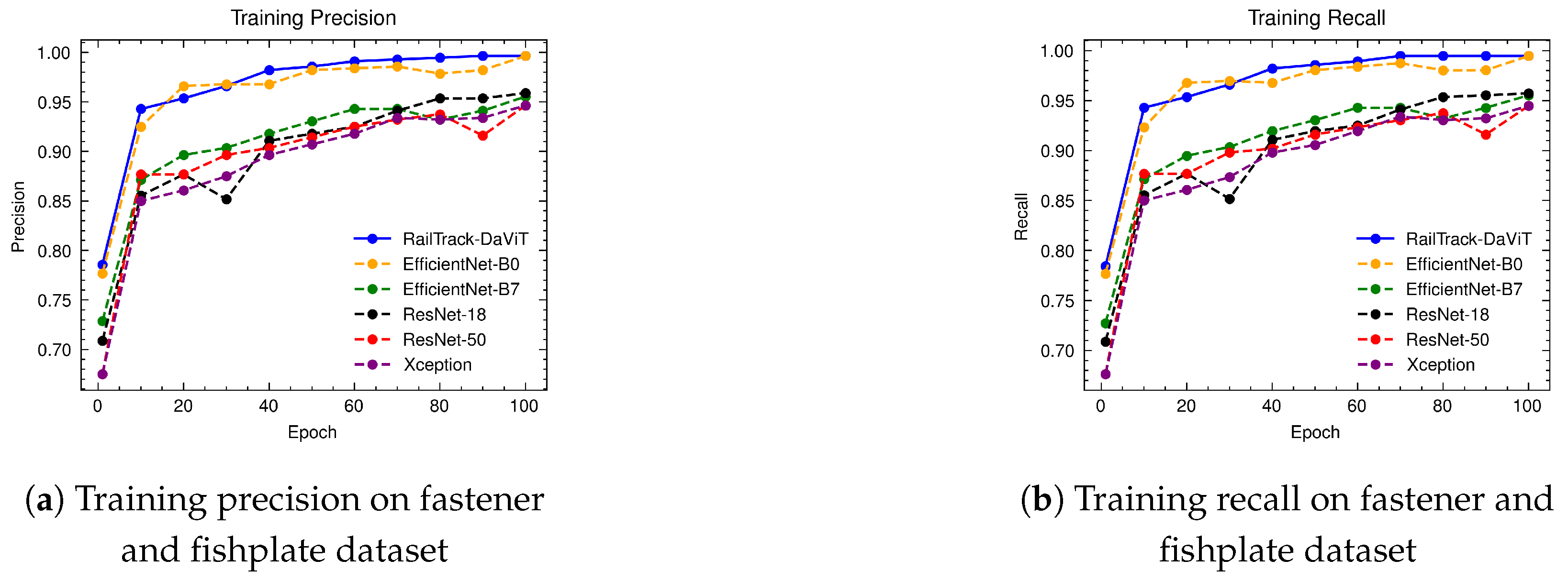
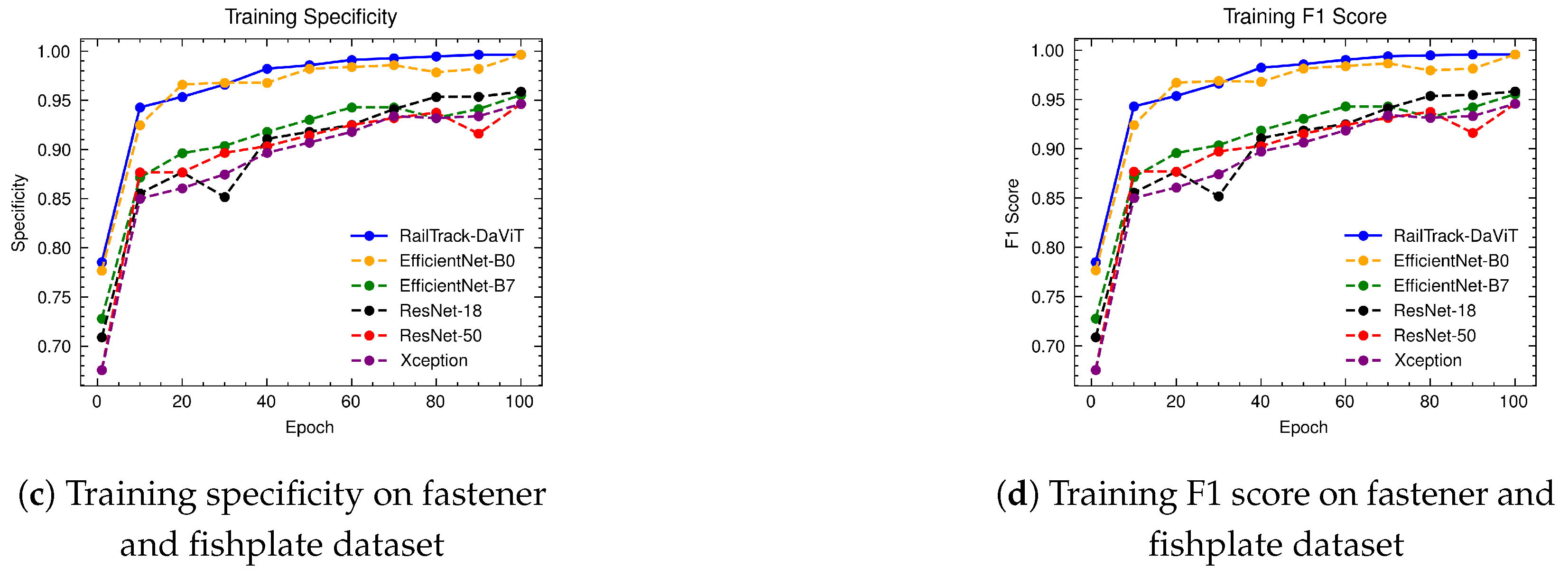
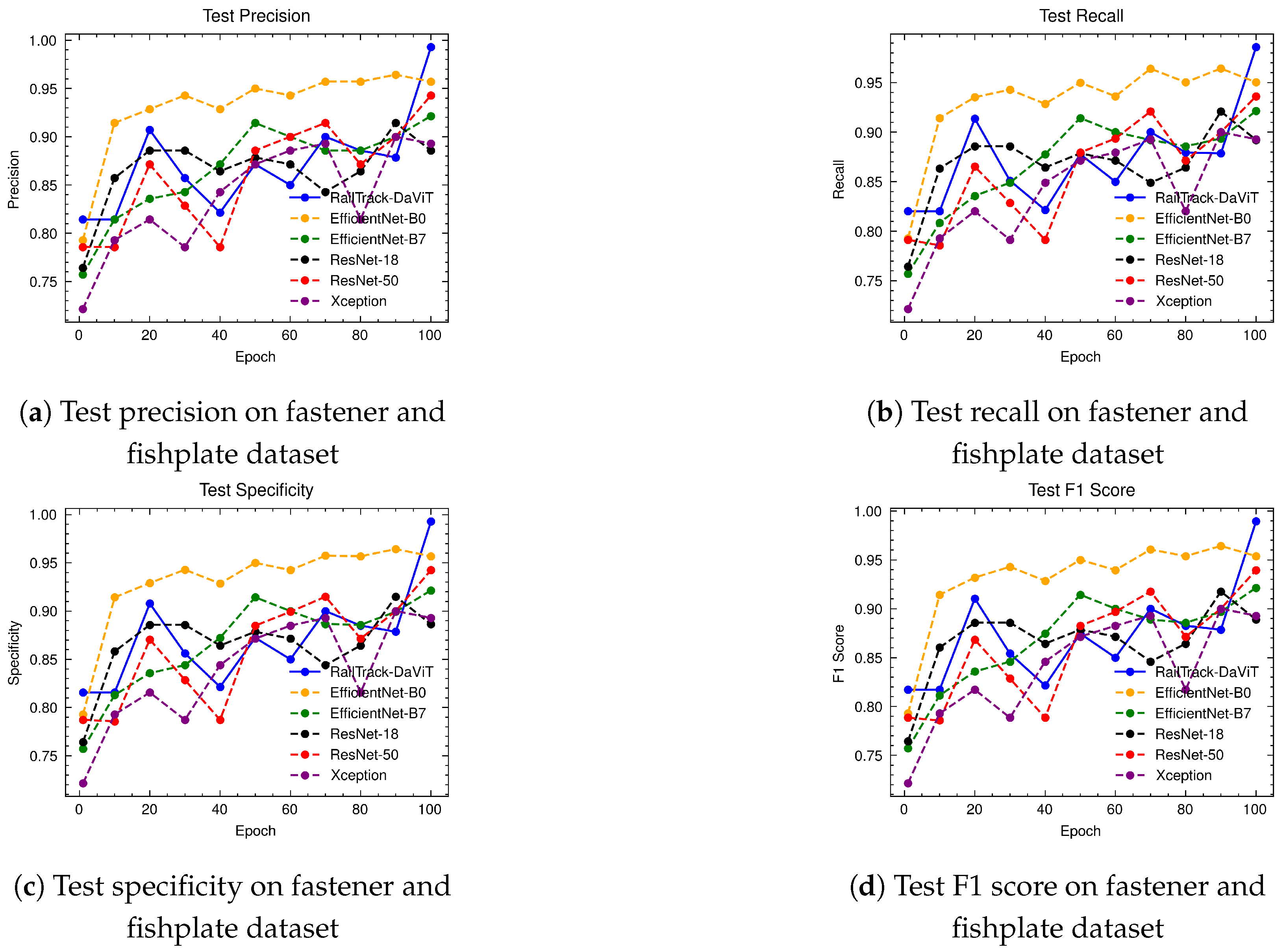
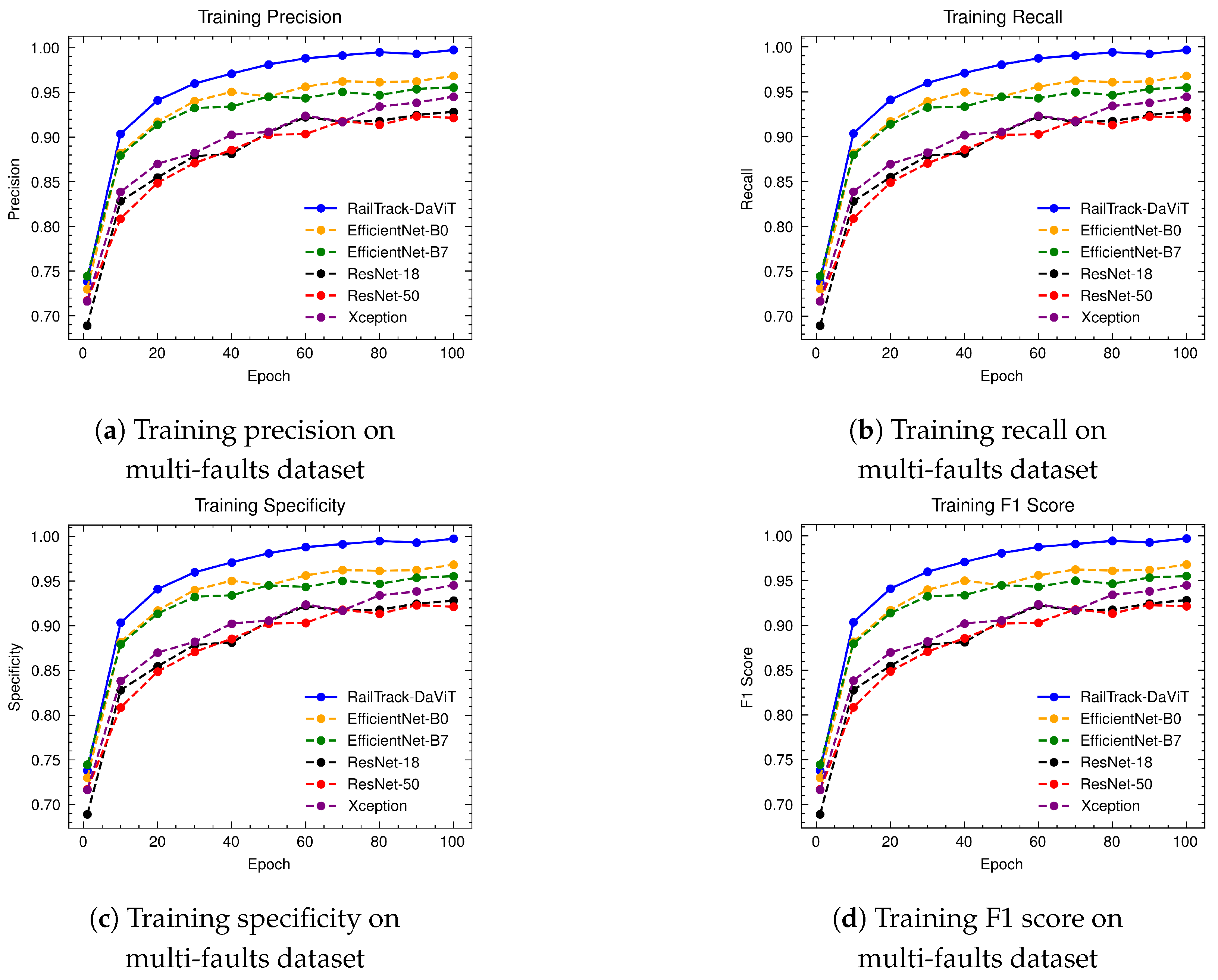
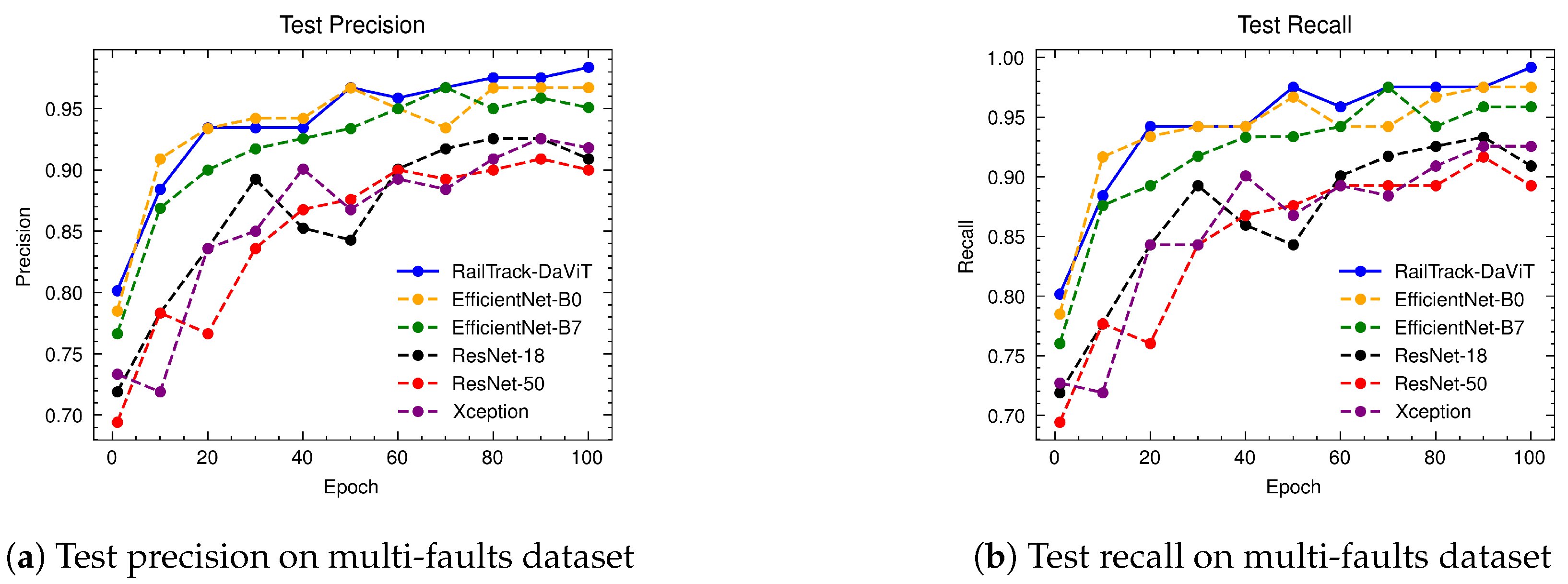
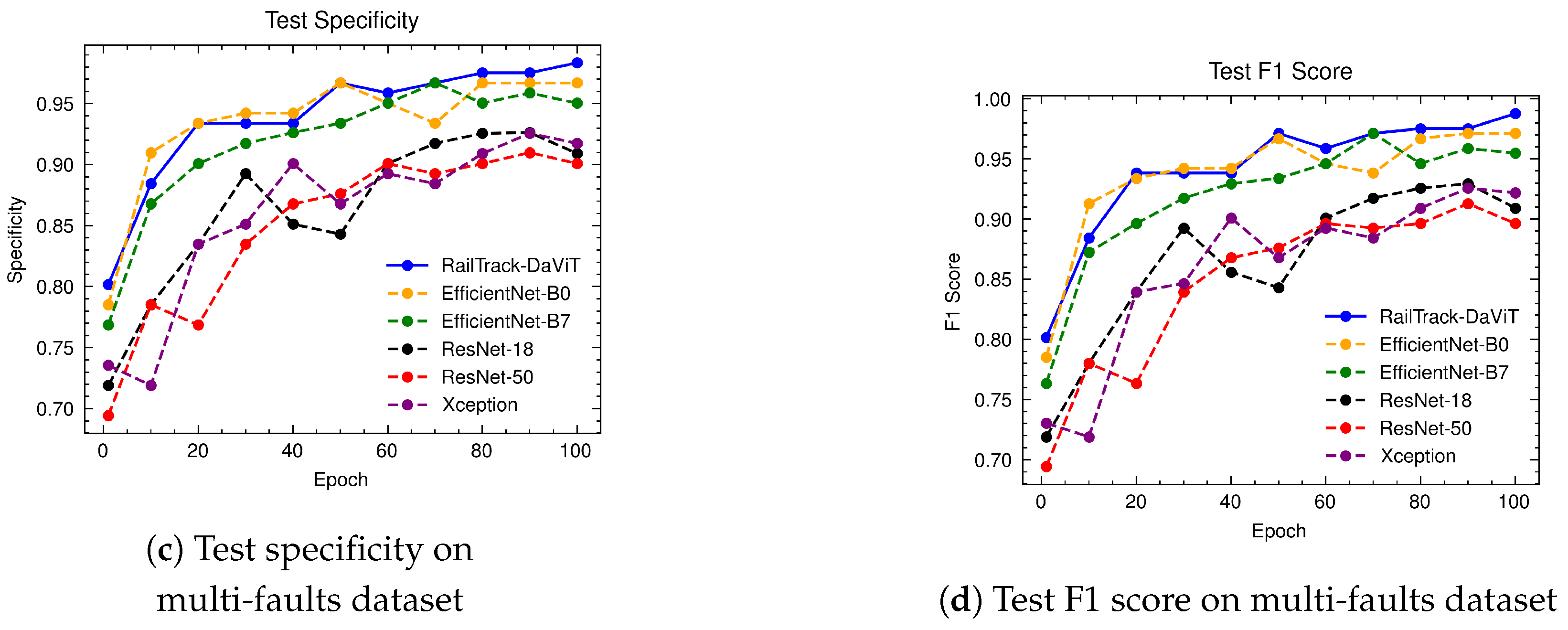
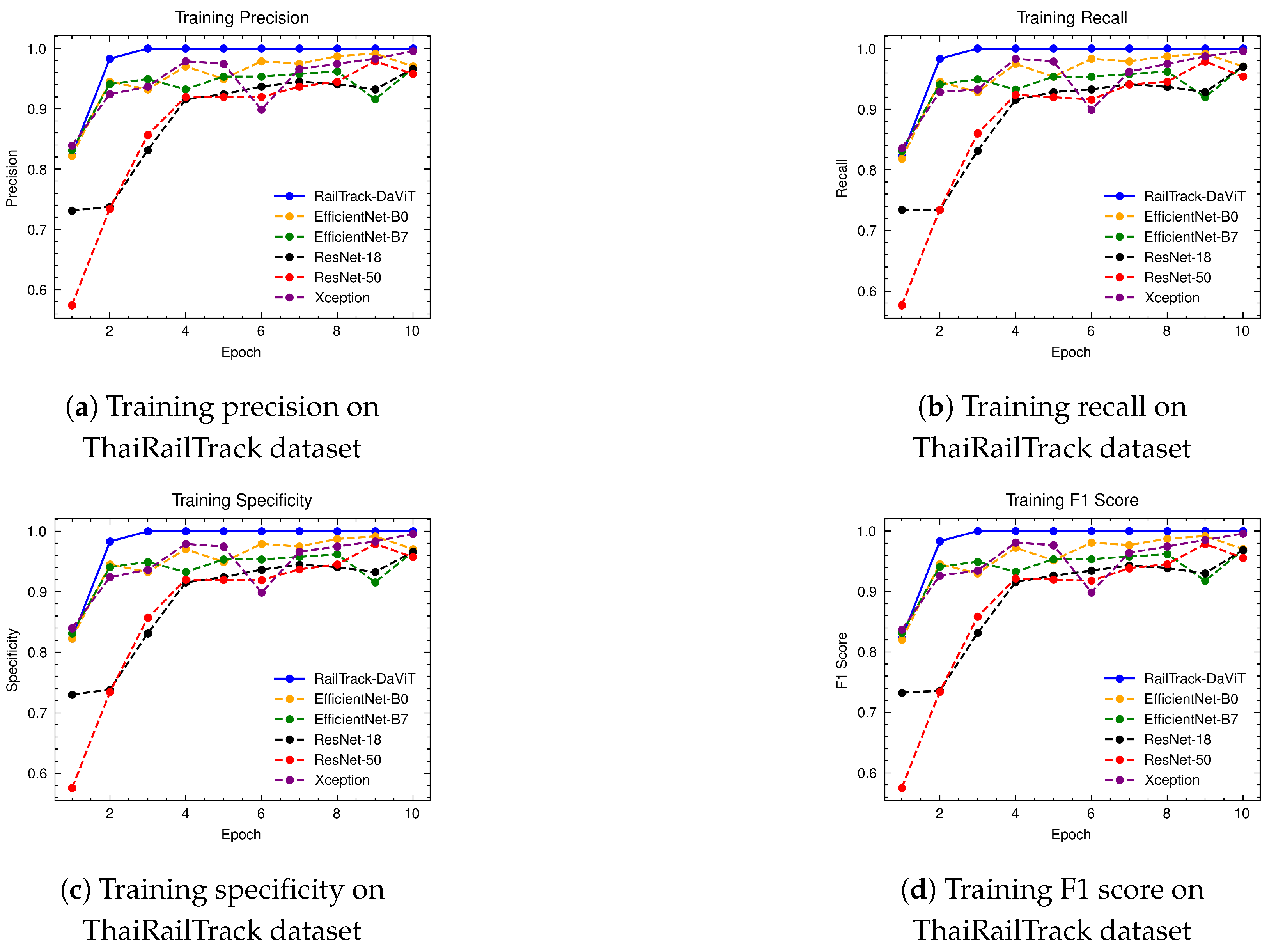
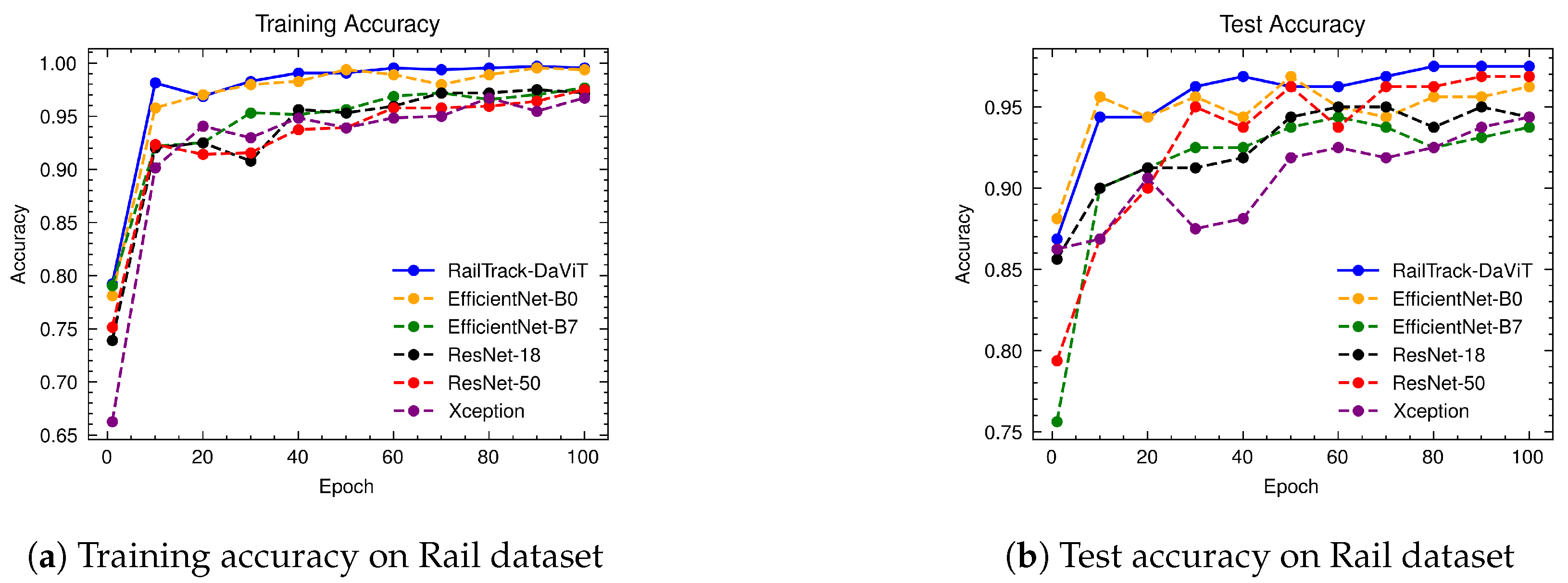
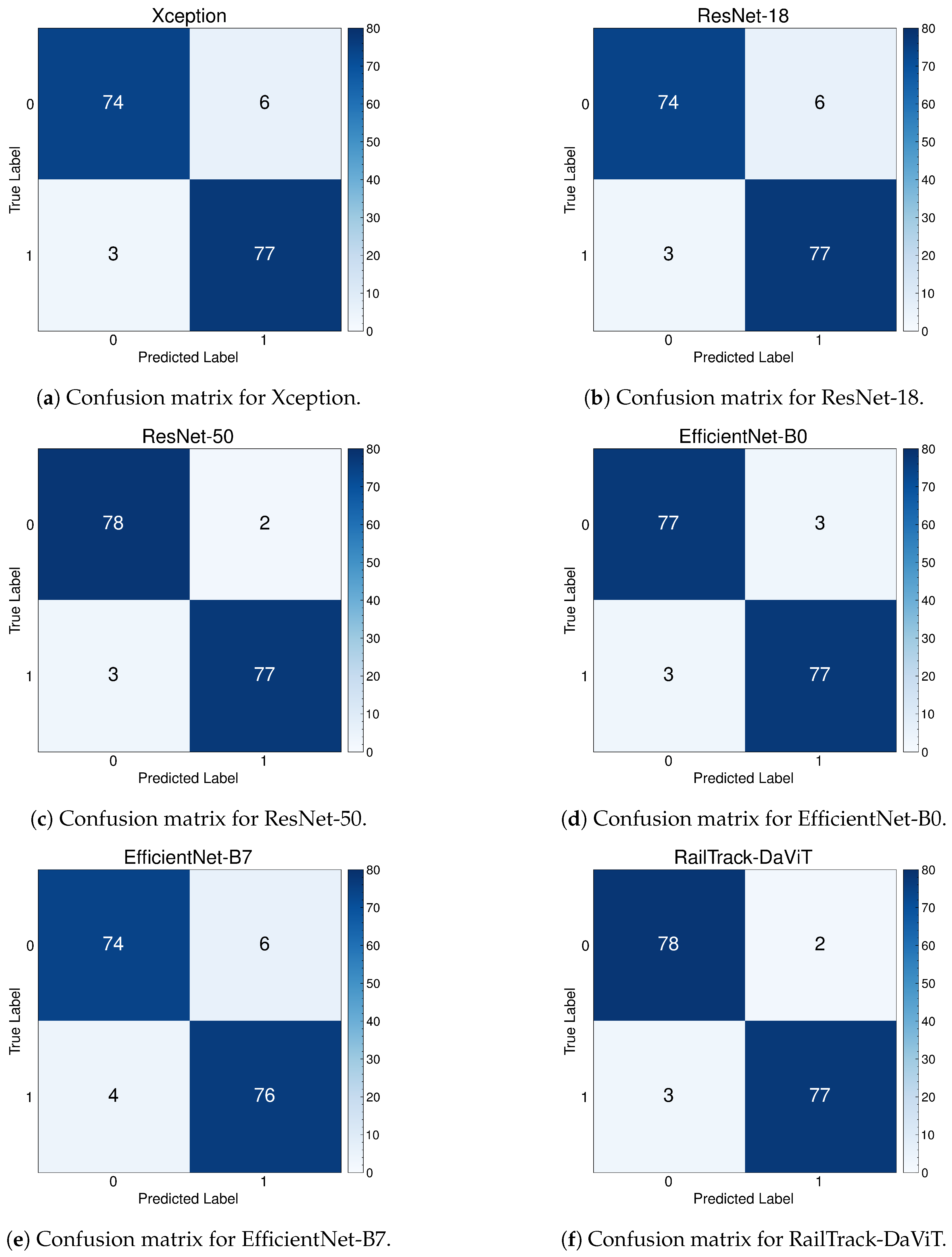
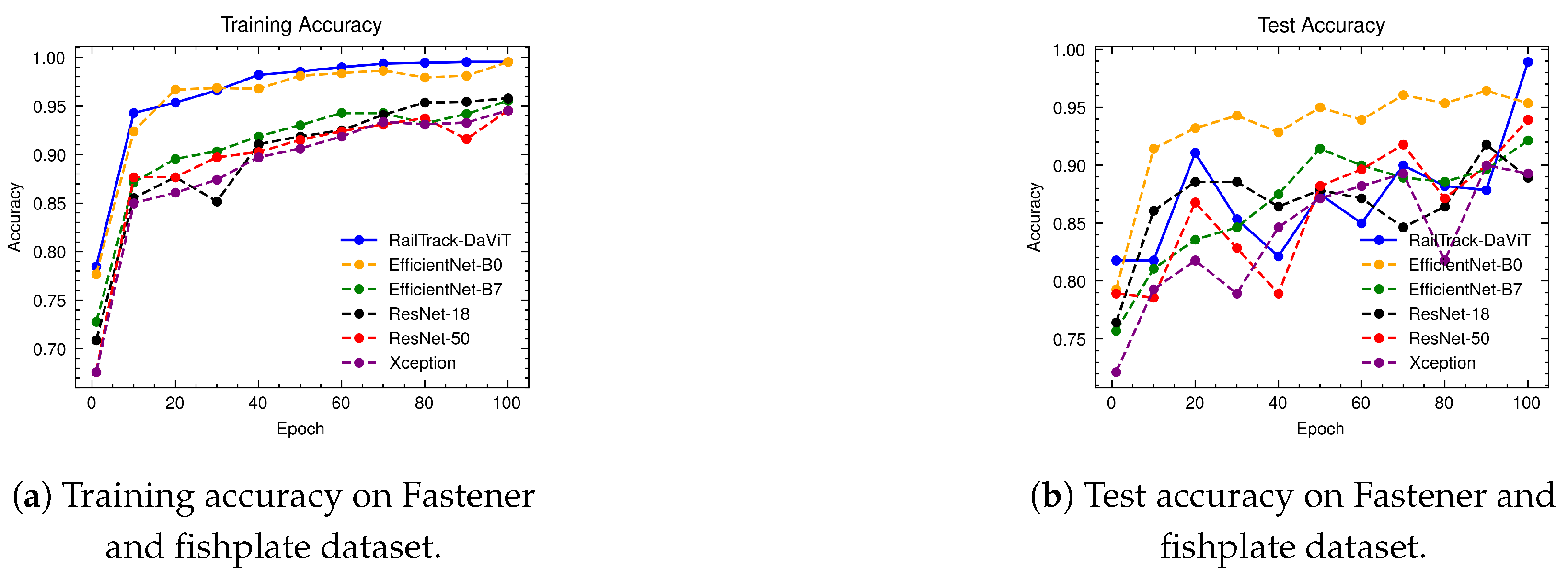
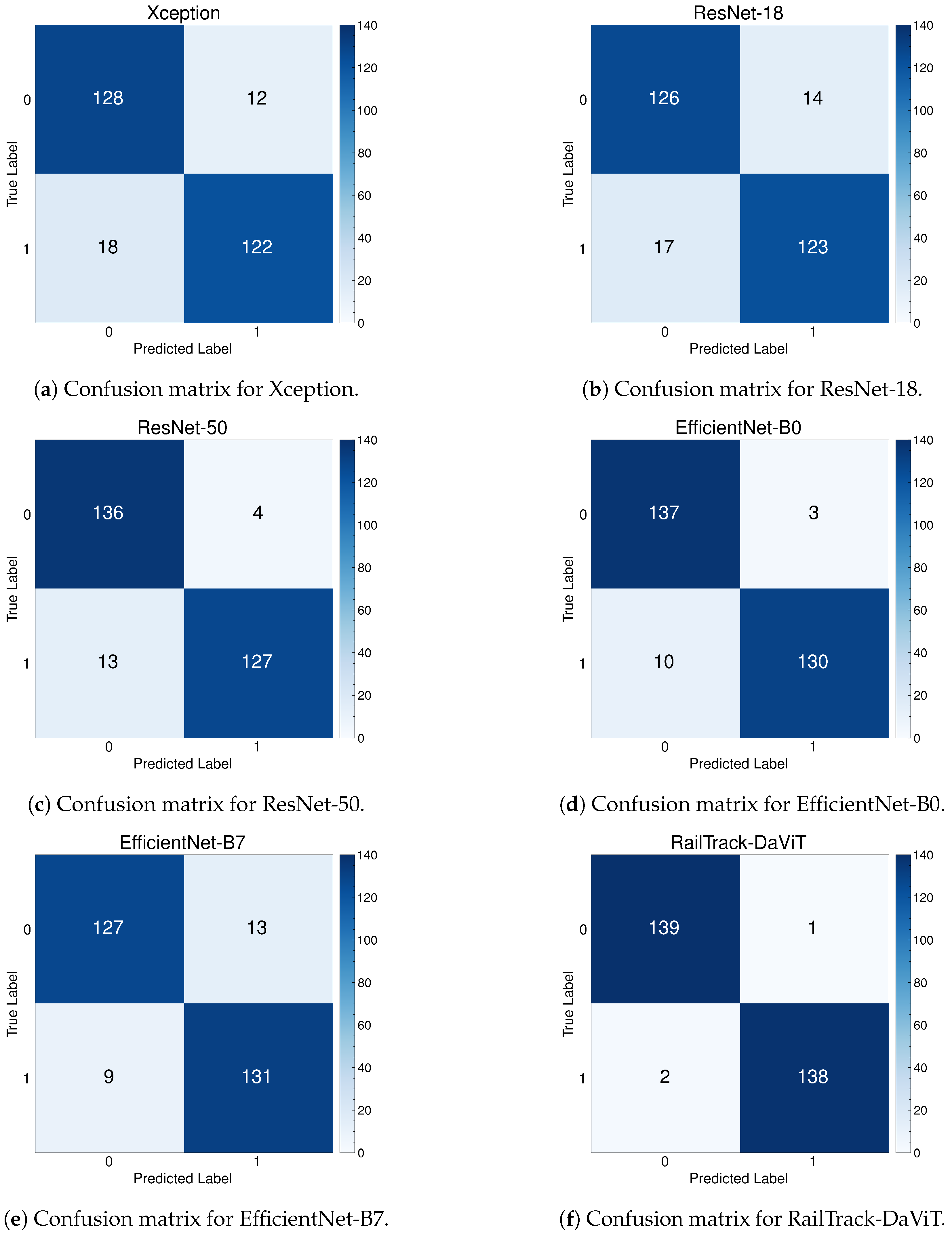
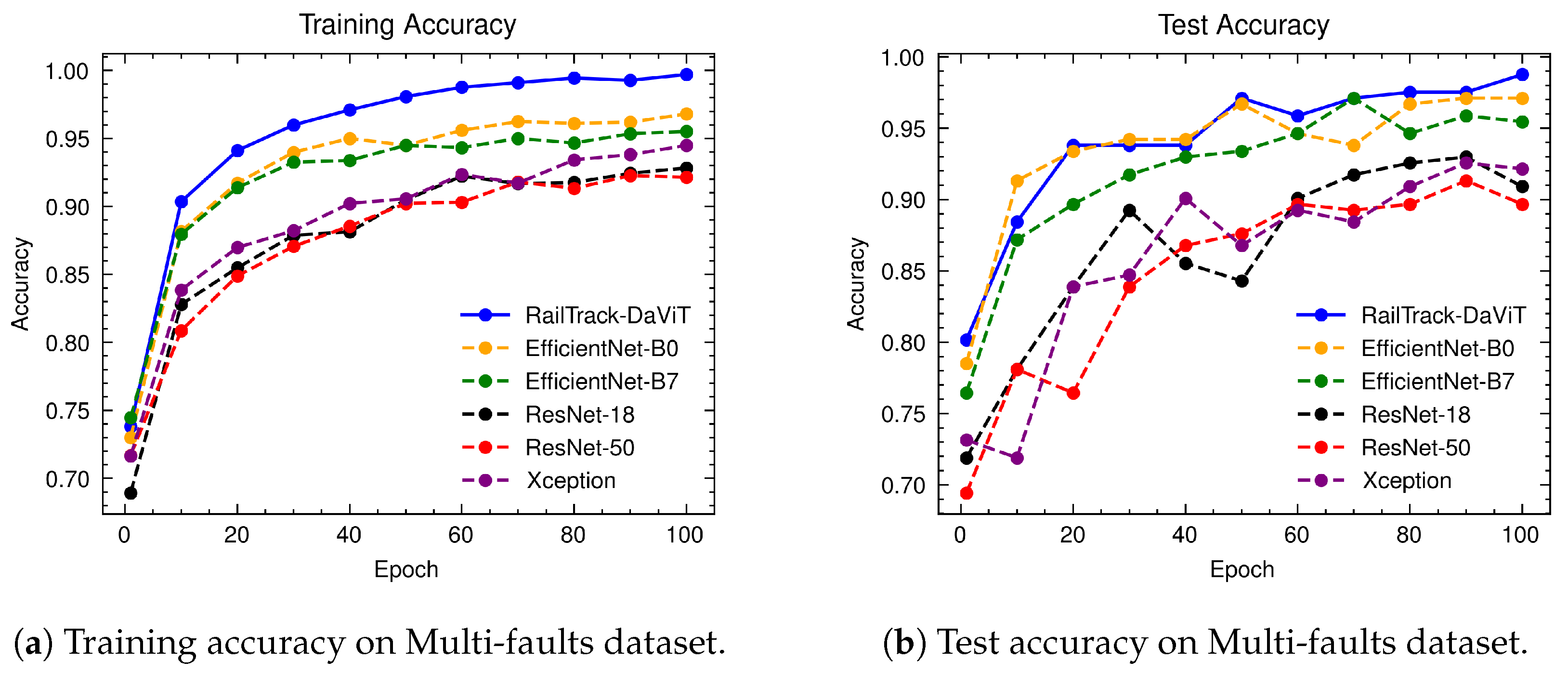
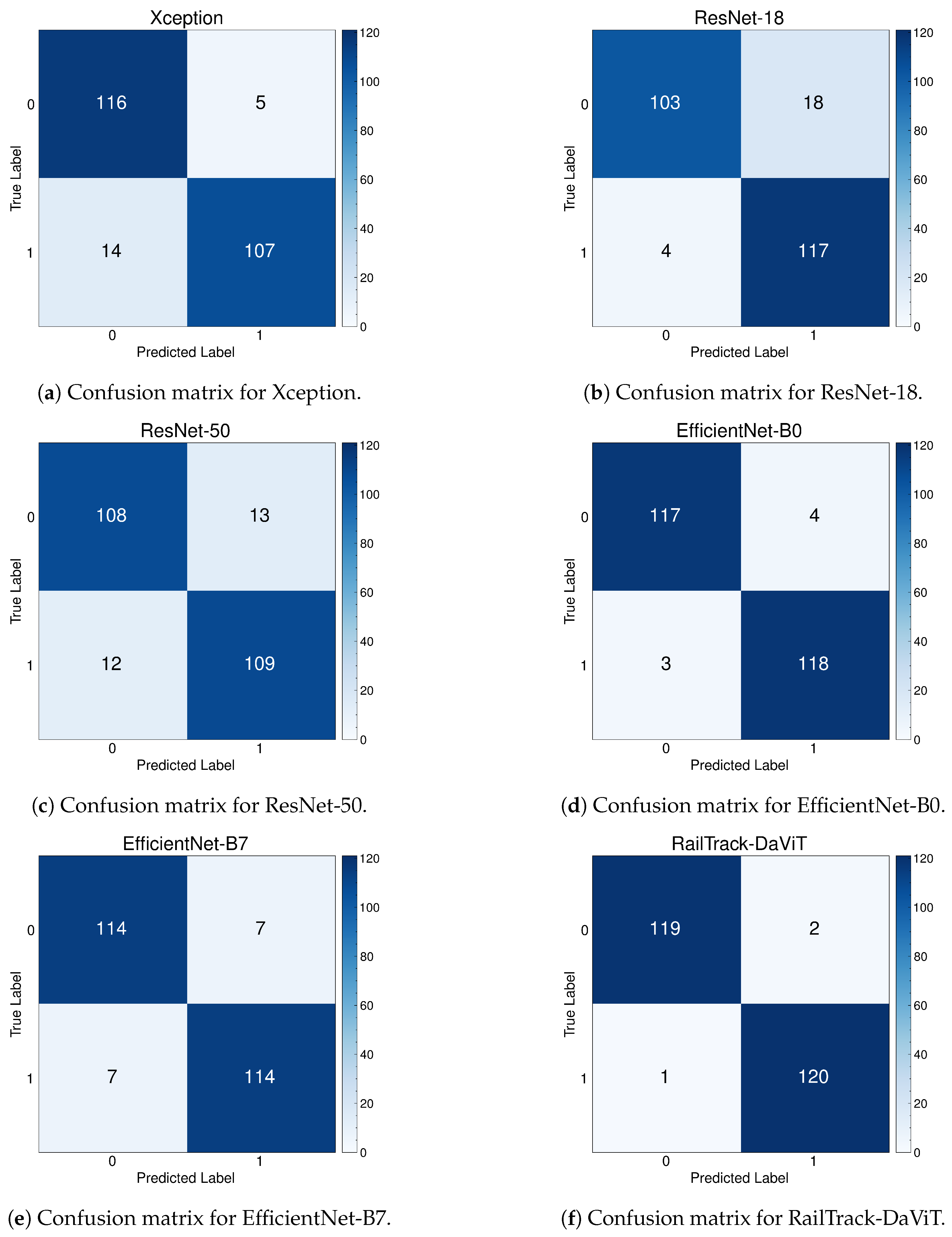
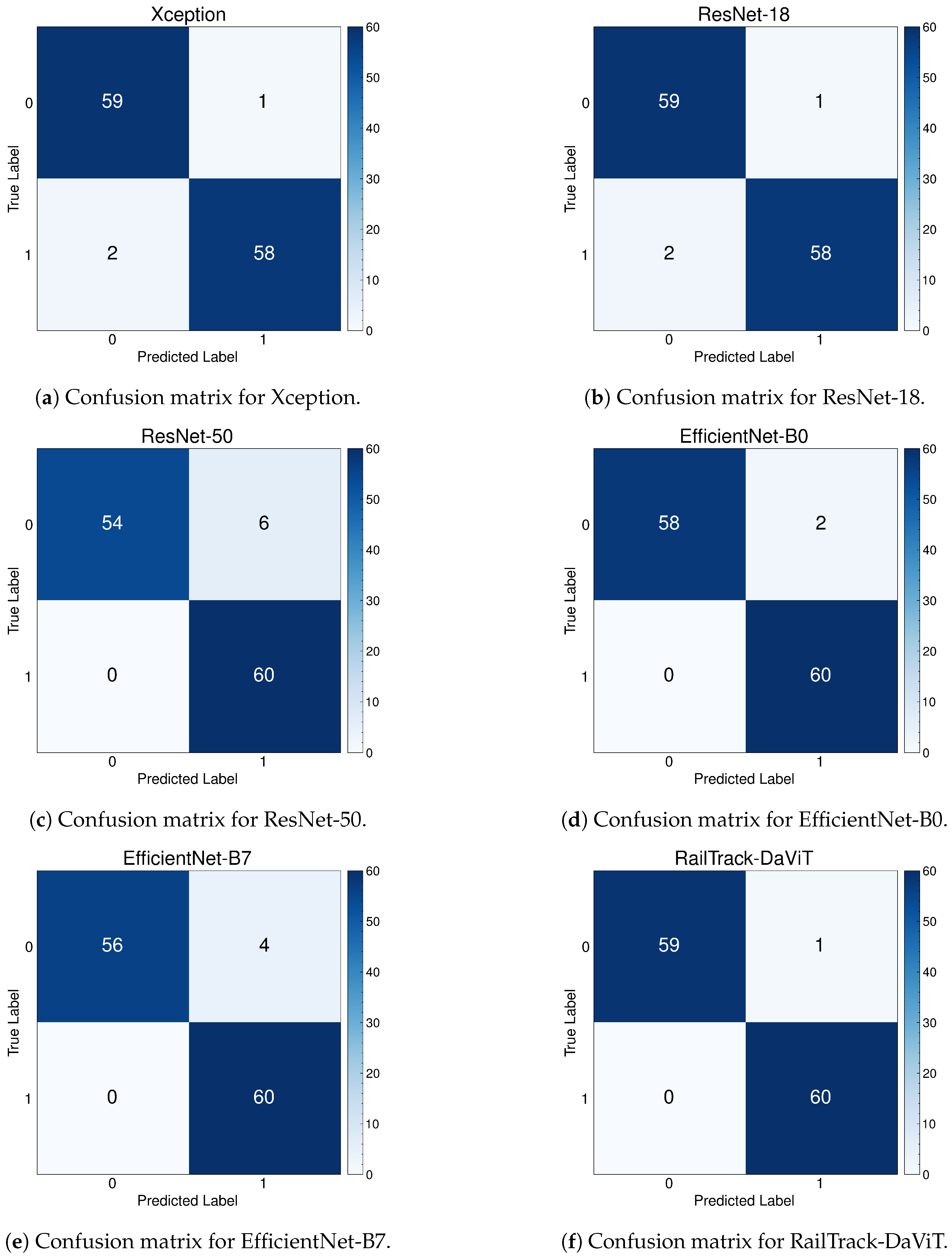
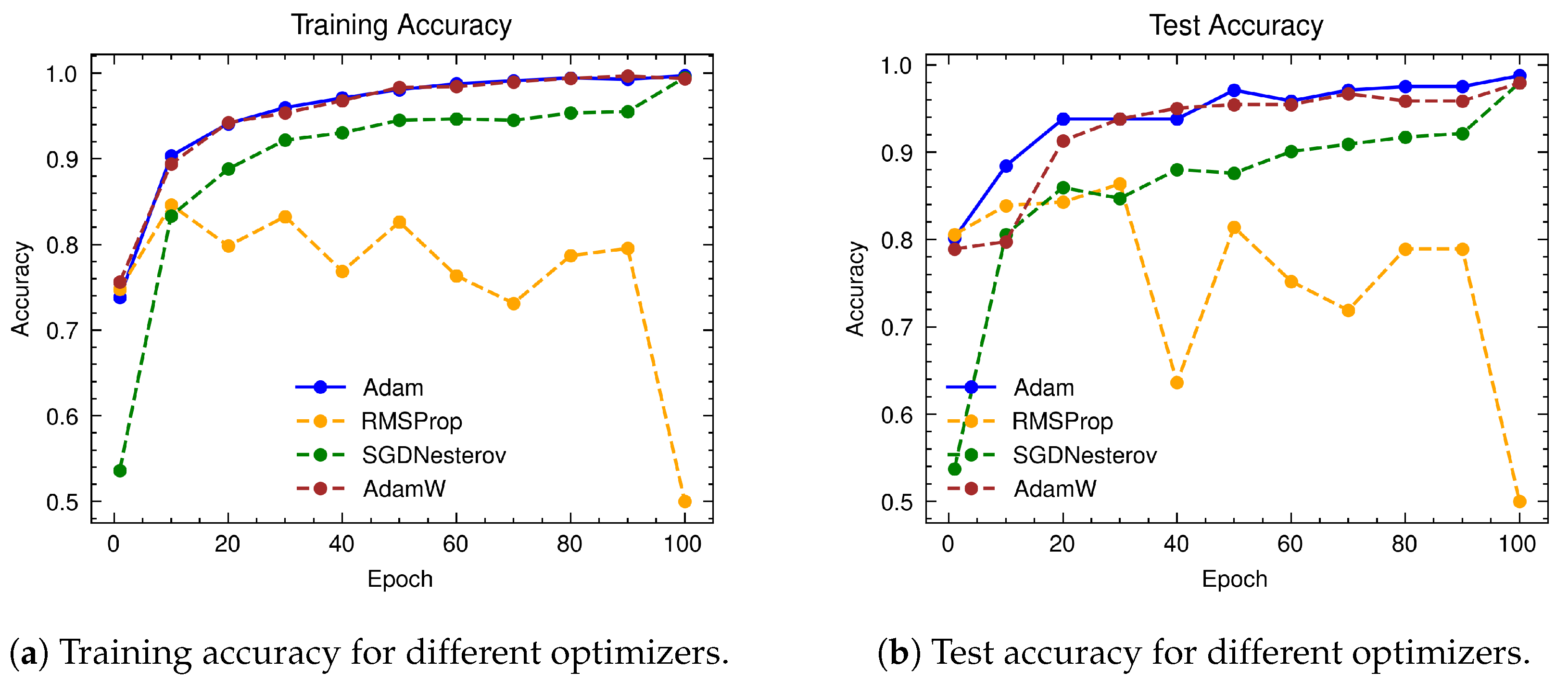
A comprehensive analysis of model performance is presented, including metrics such as a confusion matrix, training history visualization, and classification metrics. For extensive evaluation, the proposed model is evaluated on various datasets, including Rail, Fastener and fishplate, Multi-faults, and ThaiRailTrack datasets.
6. Discussion and Conclusions
In this paper, we proposed RailTrack-DaViT, a novel vision transformer-based deep learning approach for detecting defects from railway track images. By employing a Dual Attention Vision Transformer (DaViT) architecture, RailTrack-DaViT effectively captures both global and local information, addressing the limitations of traditional CNN-based models in capturing long-range dependencies on railway track datasets. The customized classification head and training pipeline enable the model to adapt pre-trained DaViT features for binary defect identification.
Extensive evaluations on various datasets, including Rail, Fastener and fishplate, Multi-faults, and ThaiRailTrack datasets, demonstrate the superior performance of RailTrack-DaViT compared to conventional CNN-based models used in this paper including Xception, ResNet-18, ResNet-50, EfficientNet-B0, and EfficientNet-B7. Overall, the proposed approach consistently achieves high precision, recall, specifically, F1 score, and accuracy across all datasets, highlighting its robustness and generalization capabilities. Moreover, when fine-tuning the model on the ThaiRailTrack dataset, RailTrack-DaViT demonstrates its capability for handing unseen data through its ability to quickly adapt to novel images. This rapid adaptation can significantly reduce time consumption in practical applications.
The ability of RailTrack-DaViT to capture long-range dependencies and effectively model both global and local information makes it a promising solution for automated railway track defect detection. By automating the inspection process, RailTrack-DaViT has the potential to significantly reduce the time and cost associated with manual inspections while improving the accuracy and reliability of defect detection.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}