
Deep Efficient Data Association for Multi-Object Tracking: Augmented with SSIM-Based Ambiguity Elimination


Abstract
1. Introduction
- The proposed data association framework employs the deep feature association network (deepFAN) along with the Structural Similarity Index Metric (SSIM) to estimate an efficient association matrix. This combination improves the robustness of object associations by leveraging deep learning for feature extraction and similarity evaluation.
- In the proposed data association framework, a neighborhood-detection-estimation (NDE) scheme is introduced to select a reliable subset of detection–target pairs. This neighborhood detection estimation, along with post-processing steps within the deep feature association network, contributes to enhancing the computational efficiency. Experimental evaluations highlight that the proposed approach minimizes incorrect associations, thereby improving overall tracking performance.
- A specialized training strategy is developed for the deep feature association network (deepFAN), allowing the network to utilize non-consecutive frame pairs for the effective learning of the data association function. This method improves the overall ability of the network to link objects across frames, thereby reducing identity switches and fragmented trajectories.
2. Related Works
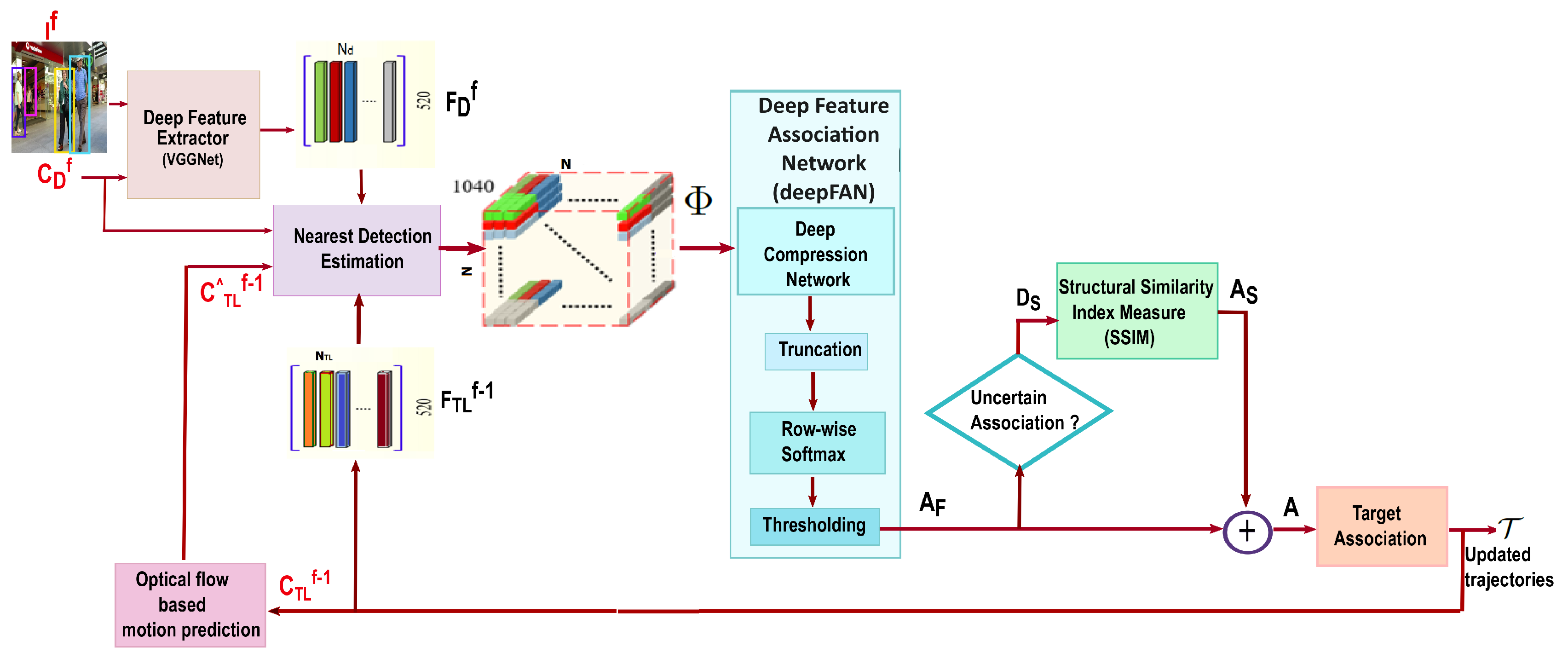
3. Methodology: Online Multiple Object Tracking Framework
3.1. Data Association Methodology
3.1.1. Neighborhood Detection Estimation
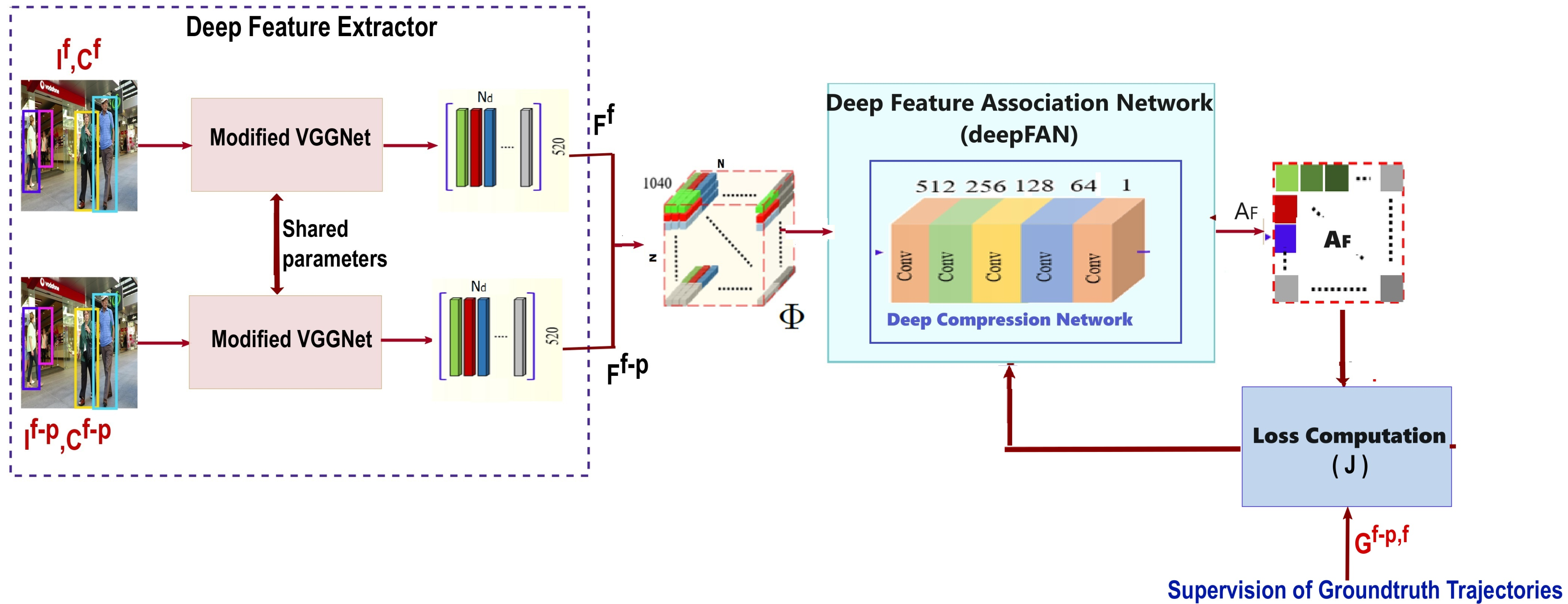
3.1.2. Deep Feature Association Network
- (i)
- Since we have only detections and active targets, the matrix is resized by truncating the matrix to .
- (ii)
- This operation normalizes the rows of the association matrix by fitting a separate probability distribution. The output row values are between the range [0, 1], and the total sums up to 1. Thus, each row of the resulting association matrix encodes the association probability between each active target in and all the detections in .
- (iii)
- The association matrix values indicate the similarity between the detection and target objects. For a reliable data association, the values above the threshold are retained, and all other values below the threshold are set to zero.
3.1.3. Structural Similarity Index Metric for Association Update
3.2. Track Association
| Algorithm 1: Online multiple object tracking. |
| Input: Video sequence, and object detections Output: Set of object trajectories, ,
|
4. Experiment Results and Discussion
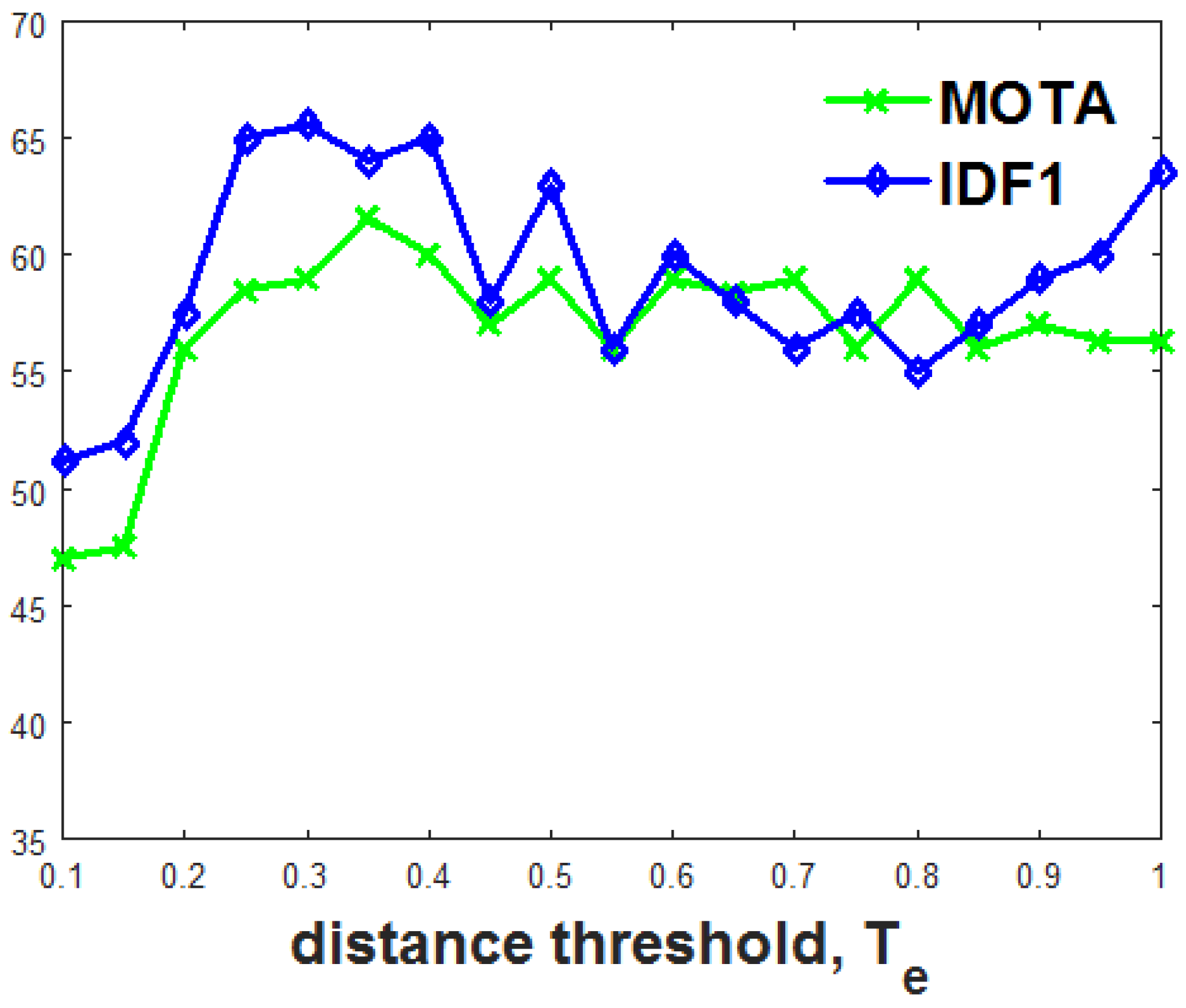
4.1. Implementation Details
4.2. Ablation Study
Significance of the Proposed Tracking Components
- (i)
- Neighborhood detection estimation:
- (ii)
- Deep feature association network:
- (iii)
- SSIM association update:
4.3. MOT Benchmark Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tian, Y.; Dehghan, A.; Shah, M. On detection, data association and segmentation for multi-target tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2146–2160. [Google Scholar] [CrossRef]
- Wen, L.; Du, D.; Li, S.; Bian, X.; Lyu, S. Learning nonuniform hypergraph for multi-object racking. arXiv 2018, arXiv:1812.03621. [Google Scholar]
- Sheng, H.; Zhang, Y.; Chen, J.; Xiong, Z.; Zhang, J. Heterogeneous association graph fusion for target association in multiple object tracking. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3269–3280. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Yang, F.; Choi, W.; Lin, Y. Exploit all the layers: Fast and accurate CNN object detector with scale dependent pooling and cascaded rejection classifiers. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2129–2137. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards realtime object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Kobayashi, T. Structured Feature Similarity with Explicit Feature Map; National Institute of Advanced Industrial Science and Technology Umezono: Tsukuba, Japan, 2016. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Premaratne, P.; Premaratne, M. New Structural Similarity Measure for Image Comparison. Commun. Comput. Inf. Sci. 2012, 304, 292–297. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Zhao, X.; Kim, T.K. Multiple Object Tracking: A Literature Review. arXiv 2017, arXiv:1409.7618v4. pp. 1–18. [Google Scholar] [CrossRef]
- Ciaparrone, G.; Sánchez, F.L.; Tabik, F.L.S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep learning in video multi-object tracking: A survey. Neurocomputing 2020, 381, 61–88. [Google Scholar] [CrossRef]
- Park, Y.; Dang, L.M.; Lee, S.; Han, D.; Moon, H. Multiple Object Tracking in Deep Learning Approaches: A Survey. Electronics 2021, 10, 2406. [Google Scholar] [CrossRef]
- Kim, C.; Li, F.; Ciptadi, A.; Rehg, J.M. Multiple hypothesis tracking revisited. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4696–4704. [Google Scholar]
- Zhang, S.; Lan, X.; Yao, H.; Zhou, H.; Tao, D.; Li, X. A Biologically Inspired Appearance Model for Robust Visual Tracking. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2357–2370. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4293–4302. [Google Scholar]
- Breitenstein, M.D.; Reichlin, F.; Leibe, B.; Koller-Meier, E.; VanGool, L. Robust tracking-by-detection using a detector confidence particle filter. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 27 September–4 October 2009; pp. 1515–1522. [Google Scholar]
- Kutschbach, T.; Bochinski, E.; Eiselein, V.; Sikora, T. Sequential sensor fusion combining probability hypothesis density and kernelized correlation filters for multi-object tracking in video data. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017. [Google Scholar]
- Fu, Z.; Feng, P.; Naqvi, S.M.; Chambers, J.A. Particle PHD filter based multi-target tracking using discriminative groupstructured dictionary learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4376–4380. [Google Scholar]
- Bae, S.H.; Yoon, K.J. Confidence-Based Data Association and Discriminative Deep Appearance Learning for Robust Online Multi-Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 595–610. [Google Scholar] [CrossRef] [PubMed]
- Wen, L.; Li, W.; Yan, J.; Lei, Z.; Yi, D.; Li, S.Z. Multiple target tracking based on undirected hierarchical relation hypergraph. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; Volume 1, pp. 1282–1289. [Google Scholar]
- Schulter, S.; Vernaza, P.; Choi, W.; Chandraker, M. Deep network flow for multi-object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6951–6960. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Detect to Track and Track to Detect. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 2017, pp. 3057–3065. [Google Scholar]
- Insafutdinov, E.; Andriluka, M.; Pishchulin, L.; Tang, S.; Levinkov, E.; Andres, B.; Schiele, B. rtTrack: Articulated Multi-person Tracking in the Wild. arXiv 2017, arXiv:1612.01465. [Google Scholar]
- Kim, C.; Li, F.; Rehg, J.M. Multi-object tracking with neural gating using bilinear lstm. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 200–215. [Google Scholar]
- Zhang, D.; Zheng, Z.; Wang, T.; He, Y. HROM: Learning High-Resolution Representation and Object-Aware Masks for Visual Object Tracking. Sensors 2020, 20, 4807. [Google Scholar] [CrossRef] [PubMed]
- Sun, S.; Akhtar, N.; Song, H.; Mian, A.; Shah, M. Deep affinity network for multiple object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 104–119. [Google Scholar] [CrossRef] [PubMed]
- Emami, P.; Pardalos, P.M.; Elefteriadou, L.; Ranka, S. Machine Learning Methods for Solving Assignment Problems in Multi Target Tracking. arXiv 2018, 1–35. [Google Scholar]
- Murphey, R.A.; Pardalos, P.M.; Pitsoulis, L.S. A greedy randomized adaptive search procedure for the multitarget multisensor tracking problem. Netw. Des. Connect. Facil. Locat. 1997, 40, 277–302. [Google Scholar]
- Berclaz, J.; Fleuret, F.; Turetken, E.; Fua, P. Multiple object tracking using k-shortest paths optimization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1806–1819. [Google Scholar] [CrossRef]
- Yang, M.; Wu, Y.; Jia, Y. A hybrid data association framework for robust online multi-object tracking. IEEE Trans. Image Process. 2017, 26, 5667–5679. [Google Scholar] [CrossRef]
- Choi, W. Near-online multi-target tracking with aggregated local flow descriptor. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’15), Boston, MA, USA, 7–12 June 2015; pp. 3029–3037. [Google Scholar]
- Milan, A.; Schindler, K.; Roth, S. Multi-target tracking by discrete-continuous energy minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2054–2068. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Huang, C.; Nevatia, R. Learning affinities and dependencies for multi-target tracking using a CRF model. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’11), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1233–1240. [Google Scholar]
- Meyer, F.; Braca, P.; Willett, P.; Hlawatsch, F. Tracking an unknown number of targets using multiple sensors: A belief propagation method. In Proceedings of the 19th International Conference on Information Fusion (FUSION’16), Heidelberg, Germany, 5–8 July 2016; pp. 719–726. [Google Scholar]
- Chen, L.; Wainwright, M.J.; Cetin, M.; Willsky, A.S. Data association based on optimization in graphical models with application to sensor networks. Math. Comput. Model. 2006, 43, 1114–1135. [Google Scholar] [CrossRef]
- Oh, S.; Russell, S.; Sastry, S. Markov chain Monte Carlo data association for general multiple-target tracking problems. In Proceedings of the 43rd IEEE Conference on Decision and Control (CDC’04), Bahamas, Nassau, 14–17 December 2004; Volume 1, pp. 735–742. [Google Scholar]
- Pasula, H.; Russell, S.; Ostland, M.; Ritov, Y. Tracking many objects with many sensors. In Proceedings of the 1999 International Joint Conference on Artificial Intelligence (IJCAI’99), Stockholm, Sweden, 31 July–6 August 1999; Volume 99, pp. 1160–1171. [Google Scholar]
- Chu, P.; Ling, H. FAMNet: Joint Learning of Feature, Affinity and Multi-Dimensional Assignment for Online Multiple Object Tracking. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV’19), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Xu, Y.; Ban, Y.; Alameda-Pineda, X.; Horaud, R. DeepMOT: A Differentiable Framework for Training Multiple Object Trackers. arXiv 2019, arXiv:1906.06618. [Google Scholar]
- Zhu, J.; Yang, H.; Liu, N.; Kim, M.; Zhang, W.; Yang, M.H. Online multi-object tracking with dual matching attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 366–382. [Google Scholar]
- Ondruska, P.; Posner, I. Deep Tracking: Seeing Beyond Seeing Using Recurrent Neural Networks. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16), Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Washington, DC, USA, 2016; pp. 3361–3367. [Google Scholar]
- Steenkiste, S.V.; Chang, M.; Greff, K.; Schmidhuber, J. Relational neural expectation maximization: Unsupervised discovery of objects and their interactions. arXiv 2018, arXiv:1802.10353. [Google Scholar]
- Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Tracking by prediction: A deep generative model for mutli-person localisation and tracking. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1122–1132. [Google Scholar]
- Leal-Taixe, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. MOTChallenge 2015: Towards a Benchmark for Multi-Target Tracking. arXiv 2015, arXiv:1504.01942. [Google Scholar]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.-C.; Qi, H.; Lim, J.; Yang, M.-H.; Lyu, S. UA-DETRAC: A New Benchmark and Protocol for Multi-Object Detection and Tracking. Comput. Vis. Image Underst. 2015, 193, 102907. [Google Scholar] [CrossRef]
- Lyu, S.; Chang, M.C.; Du, D.; Wen, L.; Qi, H.; Li, Y.; Wei, Y.; Ke, L.; Hu, T.; Del Coco, M.; et al. UA-DETRAC 2018: Report of AVSS2018 & IWT4S challenge on advanced traffic monitoring. In Proceedings of the 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018. [Google Scholar]
- Bouguet, J.Y. Pyramidal implementation of the affine Lucas Kanade feature tracker description of the algorithm. Intel Corp. 2001, 5, 1–10. [Google Scholar]
- Munkres, J. Algorithms for the Assignment and Transportation Problems. J. Soc. Ind. Appl. Math. 1957, 5, 32–38. [Google Scholar] [CrossRef]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Brasó, G.; Leal-Taixé, L. Learning a Neural Solver for Multiple Object Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6246–6256. [Google Scholar]
- Stadler, D.; Beyerer, J. Improving Multiple Pedestrian Tracking by Track Management and Occlusion Handling. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10953–10962. [Google Scholar] [CrossRef]
- Stadler, D.; Beyerer, J. Multi-Pedestrian Tracking with Clusters. In Proceedings of the 2021 17th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Virtual, 16–19 November 2021. [Google Scholar]
- Ren, W.; Wang, X.; Tian, J.; Tang, Y.; Chan, A.B. Tracking-by-Counting: Using Network Flows on Crowd Density Maps for Tracking Multiple Targets. IEEE Trans. Image Process. 2020, 30, 1439–1452. [Google Scholar] [CrossRef] [PubMed]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking without bells and whistles. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yoon, Y.C.; Kim, D.Y.; Song, Y.M.; Yoon, K.; Jeon, M. Online Multiple Pedestrian Tracking Using Deep Temporal Appearance Matching Association. Inf. Sci. 2021, 561, 326–351. [Google Scholar] [CrossRef]
- Zhang, Y.; Sheng, H.; Wu, Y.; Wang, S.; Lyu, W.; Ke, W.; Xiong, Z. Long-Term Tracking with Deep Tracklet Association. IEEE Trans. Image Process. 2020, 29, 6694–6706. [Google Scholar] [CrossRef]
- Papakis, I.; Sarkar, A.; Karpatne, A. GCNNMatch: Graph Convolutional Neural Networks for Multi-Object Tracking via Sinkhorn Normalization. arXiv 2020, arXiv:abs/2010.00067. [Google Scholar]
- Wang, L.; Lu, Y.; Wang, H.; Zheng, Y.; Ye, H.; Xue, X. Evolving boxes for fast vehicle detection. In Proceedings of the IEEE International Conference on Multimedia and Expo, Hong Kong, China, 10–14 July 2017; pp. 1135–1140. [Google Scholar]
- Cai, Z.; Saberian, M.; Vasconcelos, N. Learning complexity aware cascades for deep pedestrian detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3361–3369. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-Speed tracking-by-detection without using image information. In Proceedings of the IEEE 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017. [Google Scholar]
- Bae, S.H.; Yoon, K.J. Robust online multi-object tracking based on tracklet confidence and online discriminative appearance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2014 (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1218–1225. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Input Channels | Output Channels | BN |
|---|---|---|---|
| 0 | 1040 | 512 | Y |
| 3 | 512 | 256 | Y |
| 6 | 256 | 128 | Y |
| 9 | 128 | 64 | N |
| 11 | 64 | 1 | N |
| Training | Validation |
|---|---|
| MOT15 | |
| TUD-Stadtmitte | TUD-Campus |
| ETH-Bahnhof | ETH-Sunnyday, ETH-Pedcross2 |
| ADL-Rundle-6 | ADL-Rundle-8, Venice-2 |
| KITTI-13 | KITTI-17 |
| MOT 17 | |
| MOT17-02 | MOT17-04 |
| MOT17-05 | MOT17-09 |
| MOT17-10 | MOT17-11, MOT17-13 |
| MOT 20 | |
| MOT20-01 | MOT20-02 |
| MOT20-03 | MOT20-05 |
| Tracker | MOTA↑ | IDF1↑ | MT↑ | ML↓ | FP↓ | FN↓ | Recall↑ | Precision↑ | FAF↓ | IDSw↓ | Frag↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MOT20 | |||||||||||
| Proposed MOT | 53.6 | 51.0 | 31.6 | 28.1 | 12,094 | 135,548 | 55.4 | 85.5 | 1.2 | 1264 | 1853 |
| Proposed MOT without NDE | 51.2 | 49.3 | 29.6 | 30.7 | 14,296 | 154,780 | 52.0 | 79.3 | 1.2 | 1573 | 2098 |
| Proposed MOT trained with sequential frames | 52.6 | 50.9 | 30.9 | 29.4 | 12,944 | 139,547 | 55.3 | 95.6 | 1.5 | 1463 | 1921 |
| Proposed MOT without SSIM | 51.7 | 48.9 | 27.3 | 31.2 | 14,991 | 141,703 | 53.1 | 97.4 | 2.1 | 2234 | 3084 |
| MOT17 | |||||||||||
| Proposed MOT | 61.6 | 65.6 | 34.4 | 24.9 | 8361 | 76,123 | 62.1 | 88.8 | 1.1 | 695 | 969 |
| Proposed MOT without NDE | 56.3 | 63.6 | 33.2 | 25.6 | 9662 | 86,425 | 58.7 | 85.7 | 1.2 | 834 | 1167 |
| Proposed MOT trained with sequential frames | 59.2 | 64.2 | 33.4 | 25.2 | 8691 | 77,453 | 59.3 | 87.4 | 1.1 | 726 | 1098 |
| Proposed MOT without SSIM | 54.7 | 62.3 | 32.4 | 26.5 | 10,231 | 89,653 | 61.5 | 88.4 | 1.5 | 832 | 1217 |
| MOT15 | |||||||||||
| Proposed MOT | 46.2 | 62.3 | 22.2 | 15.4 | 2134 | 10,162 | 55.4 | 85.5 | 0.8 | 121 | 286 |
| Proposed MOT without NDE | 38.2 | 71.9 | 18.0 | 20.0 | 3094 | 10,943 | 52.0 | 79.3 | 1.0 | 236 | 341 |
| Proposed MOT trained with sequential frames | 43.2 | 74.2 | 21.1 | 16.4 | 2652 | 10,295 | 54.8 | 82.4 | 1.0 | 134 | 291 |
| Proposed MOT without SSIM | 38.1 | 73.1 | 19.2 | 21.8 | 2851 | 11,343 | 53.6 | 82.1 | 1.1 | 216 | 312 |
| Tracker | MOTA↑ | IDF1↑ | MT↑ | ML↓ | FP↓ | FN↓ | Recall↑ | Precision↑ | FAF↓ | IDSw↓ | Frag↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MOT20 | |||||||||||
| Proposed MOT | 58.9 | 59.7 | 30.7 | 19.2 | 31,063 | 158,876 | 61.7 | 89.2 | 4.5 | 1842 | 3126 |
| Proposed MOT without NDE | 55.4 | 57.9 | 29.2 | 20.7 | 33,473 | 161,875 | 60.5 | 88.1 | 5.6 | 2187 | 4125 |
| Proposed MOT trained with sequential frames | 57.5 | 58.6 | 30.9 | 19.8 | 31,974 | 159,174 | 58.6 | 88.5 | 4.9 | 1925 | 3215 |
| Proposed MOT without SSIM | 56.1 | 57.6 | 28.7 | 20.1 | 33,542 | 168,654 | 67.9 | 87.7 | 5.3 | 2213 | 3982 |
| MPN Track [55] | 57.6 | 59.1 | 38.2 | 22.5 | 16,953 | 201,384 | 61.1 | 94.9 | 3.8 | 1210 | 1420 |
| TMOH [56] | 60.1 | 61.2 | 46.7 | 17.8 | 38,043 | 165,899 | 67.8 | 90.2 | 8.5 | 2342 | 4326 |
| MPTC [57] | 60.6 | 59.7 | 51.1 | 16.7 | 45,318 | 153,978 | 70.2 | 88.9 | 10.1 | 4533 | 5163 |
| TBC [58] | 54.5 | 50.1 | 33.4 | 19.7 | 37,937 | 195,242 | 62.3 | 89.5 | 8.5 | 2449 | 2580 |
| MOT17 | |||||||||||
| Proposed MOT | 58.6 | 60.8 | 24.1 | 29.1 | 20,230 | 212,345 | 59.5 | 93.9 | 0.8 | 1122 | 1943 |
| Proposed MOT without NDE | 56.4 | 58.3 | 22.6 | 31.9 | 21,237 | 222,746 | 54.0 | 92.5 | 0.9 | 1782 | 2153 |
| Proposed MOT trained with sequential frames | 57.8 | 60.1 | 23.5 | 29.9 | 20,934 | 215,145 | 57.5 | 93.3 | 0.8 | 1352 | 1986 |
| Proposed MOT without SSIM | 54.9 | 52.8 | 20.9 | 31.1 | 22,237 | 229,447 | 55.9 | 92.9 | 1.1 | 2668 | 3469 |
| DAN [30] | 52.4 | 49.5 | 21.4 | 30.7 | 25,423 | 234,592 | 58.4 | 76.9 | NA | 8431 | 14,797 |
| Tractor++ [59] | 53.5 | 52.3 | 49.5 | 36.6 | 12,201 | 248,047 | 56.0 | 96.3 | 0.7 | 2072 | 4611 |
| DMAN [44] | 48.2 | 55.7 | 19.3 | 38.3 | 26,218 | 263,608 | 53.3 | 92.0 | 1.5 | 2194 | 5378 |
| DEEP TAMA [60] | 50.3 | 53.5 | 19.2 | 37.5 | 25,479 | 252,996 | 55.2 | 92.4 | 1.4 | 2192 | 3978 |
| FAMNet [42] | 52.0 | 48.7 | 18.1 | 33.4 | 14,138 | 253,616 | 55.1 | 95.6 | 0.8 | 3072 | 5318 |
| TT17 [61] | 54.9 | 63.1 | 24.4 | 38.1 | 20,236 | 233,295 | 58.7 | 94.2 | 1.1 | 1088 | 2392 |
| MOT15 | |||||||||||
| Proposed MOT | 52.5 | 60.0 | 33.8 | 25.8 | 6837 | 21,218 | 64.8 | 85.3 | 1.2 | 370 | 784 |
| Proposed MOT without NDE | 49.4 | 58.8 | 29.4 | 28.2 | 10,774 | 23,204 | 64.1 | 84.6 | 1.2 | 628 | 1090 |
| Proposed MOT trained with sequential frames | 51.1 | 59.0 | 31.1 | 27.6 | 8070 | 21,292 | 64.6 | 84.7 | 1.7 | 677 | 922 |
| Proposed MOT without SSIM | 47.5 | 47.8 | 23.4 | 26.4 | 9531 | 25,502 | 58.5 | 83.7 | 1.3 | 1040 | 1350 |
| MPN Track [55] | 51.5 | 58.6 | 31.2 | 25.9 | 7620 | 21,780 | 64.6 | 83.9 | 1.3 | 375 | 872 |
| Tracker++ [59] | 46.6 | 47.6 | 18.2 | 27.9 | 4624 | 26,896 | 56.2 | 88.2 | 0.8 | 1290 | 1702 |
| GNN Match [62] | 46.7 | 43.2 | 21.8 | 28.2 | 6643 | 25,311 | 58.8 | 84.5 | 1.1 | 820 | 1371 |
| UA-DETRAC | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Tracker | PR-MOTA↑ | PR-MOTP↑ | PR-MT↑ | B | PR-FP↓ | PR-FN↓ | PR-IDSw↓ | B↓ | Hz |
| EB [63] + Proposed MOT | 23.4 | 30.9 | 17.5 | 16.8 | 8253.6 | 17,532.6 | 462.2 | 721.1 | 12.7 |
| EB + Proposed MOT without NDE | 21.1 | 28.5 | 16.5 | 17.9 | 9757.5 | 19,572.9 | 537.9 | 794.5 | 10.9 |
| EB + Proposed MOT trained with sequential frames | 21.7 | 29.1 | 16.9 | 18.1 | 9034.2 | 18,854.5 | 489.1 | 774.1 | 12.1 |
| EB + Proposed MOT without SSIM | 20.8 | 28.1 | 16.0 | 18.7 | 10,054.3 | 20,834.6 | 549.7 | 875.4 | 14.5 |
| EB + DAN [30] | 20.2 | 26.3 | 14.5 | 18.1 | 9747.8 | 135,978.1 | 518.2 | NA | 6.3 |
| compACT [64] + FAMNet [42] | 19.8 | 36.7 | 17.1 | 18.2 | 14,988.6 | 164,432.6 | 617.4 | 970.2 | NA |
| EB + IOUT [65] | 19.4 | 28.9 | 17.7 | 18.4 | 14,796.5 | 171,806.8 | 2311.3 | 2445.9 | NA |
| R-CNN [7] + IOUT | 16.0 | 38.3 | 13.8 | 20.7 | 22,535.1 | 193,041.9 | 5029.4 | 5795.7 | NA |
| compACT + CMOT [66] | 12.6 | 36.1 | 16.1 | 18.6 | 57,885.9 | 167,110.8 | 285.3 | 1516.8 | 3.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prasannakumar, A.; Mishra, D. Deep Efficient Data Association for Multi-Object Tracking: Augmented with SSIM-Based Ambiguity Elimination. J. Imaging 2024, 10, 171. https://doi.org/10.3390/jimaging10070171
Prasannakumar A, Mishra D. Deep Efficient Data Association for Multi-Object Tracking: Augmented with SSIM-Based Ambiguity Elimination. Journal of Imaging. 2024; 10(7):171. https://doi.org/10.3390/jimaging10070171
Chicago/Turabian StylePrasannakumar, Aswathy, and Deepak Mishra. 2024. "Deep Efficient Data Association for Multi-Object Tracking: Augmented with SSIM-Based Ambiguity Elimination" Journal of Imaging 10, no. 7: 171. https://doi.org/10.3390/jimaging10070171
APA StylePrasannakumar, A., & Mishra, D. (2024). Deep Efficient Data Association for Multi-Object Tracking: Augmented with SSIM-Based Ambiguity Elimination. Journal of Imaging, 10(7), 171. https://doi.org/10.3390/jimaging10070171