We first examine the in-distribution detection performance for the synthetically generated images, followed by a comparison with the related work on various out-of-distribution cases. We then show how the uncertainty measure helps to provide reliable model predictions. Last, we explore a further possibility to recognize potential failure cases by cross-checking the results of the output nodes of the network.
5.1. In-Distribution Detection Performance
The in-distribution performance of the BNN is evaluated on a test dataset of additional images, namely 1600 real and 1600 synthetic images that were unseen during training but from the same data sources. These images are randomly JPEG-compressed analogously to the JPEG augmentation during training.
The evaluation results are shown in
Table 1. The BNN performs almost perfectly well on all three tasks, namely the detection of real, synthetic, and compressed images. Overall, the BNN achieves an average F1-score of
and an average AU-ROC score of
, which demonstrates that the BNN effectively learns the tasks at hand.
5.2. Out-of-Distribution Detection Performance and Comparison to Related Work
Our primary emphasis is on the generalization ability regarding data from generators that were unseen during training. Hence, this experiment shows the generalization performance of the BNN to various generative models on which it was not trained. Recall from
Section 4.3 that the BNN is trained on synthetic ProGAN images and real images from the LSUN dataset. The testing is performed on a separate test dataset that was not observed during training. It comprises synthetic images from StyleGAN2 [
45], StyleGAN3 [
46], BigGAN [
47], Dall-E mini [
48], Dall-E 2 [
2], stable diffusion [
43], latent diffusion [
3], and taming transformer [
49]. For text-to-image generator models, we utilized the image descriptions provided by the COCO-datset [
44]. The real data for testing are also from datasets that were unseen during training, namely COCO [
44], ImageNet [
50], and UCID [
51].
The performance is compared to four related works for synthetic image detection, which are briefly introduced in this paragraph. Spec is a traditional approach based on frequency analysis [
52]. PatchForensics analyzes the local image patches [
53]. Wang et al. propose a learning-based approach using a ResNet50 architecture alongside post-processing augmentation [
15]. Gragnaniello et al. refine the approach by Wang et al. by abstaining from downsampling within the first layer and introducing additional augmentation [
15,
19]. The results are reported using balanced accuracy and its associated area under the receiver-operating curve (AUC). For the comparative methods, we use the numbers as provided by Corvi et al. [
18]. To ensure a fair comparison, we carefully follow the same evaluation protocol as Corvi et al. The only notable difference is that our testing data are smaller by a factor of 2; hence, we use 500 synthetic images from each generative model and 2500 real images.
Table 2 shows the results for the uncompressed synthetic images. Here, the detection only has to cope with the fact that the images come from unseen sources and generators, but no further post-processing is applied. The first row shows the detection performance on the in-distribution test set for the ProGAN images, and the following rows depict the performance on the out-of-distribution data. The last row shows the average performance of each method. The three rightmost columns depict the results of the BNN. Out of those three columns, the leftmost shows the BNN’s performance by selecting the most likely class. The middle column reflects the performance with an activation-based abstain threshold, where no decision is made if all the class activations are below a threshold of
. The abstains opt out of the evaluation; i.e., the reported performance only includes the samples from which the BNN did not abstain. The rightmost column shows the performance with an uncertainty-based abstain threshold. Here, each sample with high uncertainty is flagged as unreliable and analogously abstains from prediction. The uncertainty threshold
is set based on the mean uncertainty regarding the in-distribution test set
. A prediction is considered unreliable if the uncertainty exceeds the average in-distribution uncertainty
by a factor of two.
The results show that the performance of the BNN is comparable to related works on in-distribution data. The performance of the BNN also decreases on out-of-distribution data (as expected), with particularly weak spots on the StyleGAN3 and Dall-E 2 images. However, the ability to abstain from the decision can increase the performance across all the architectures.
Table 3 shows an analysis of the resized and compressed synthetic images, which is a more realistic and challenging scenario. Again, for a fair comparison, we follow the same post-processing approach of image resizing and additional JPEG compression as described by Corvi et al. [
18]. The overall structure of the results is the same as in
Table 2. In this more challenging scenario, Spec, PatchForensics, and Wang et al. drop to random guessing for all the generators [
15,
52,
53]. Meanwhile, Gragnaniello et al. is able to retain decent performance for the other GAN-based generators, and it also drops to random guessing for the diffusion-based models [
19]. The BNN also takes a performance penalty. However, it is able to retain decent performance for most of the GAN-based generators and for most of the diffusion-based generators, which again is slightly improved by utilizing our abstain policies. While the BNN shows on average on-par but slightly inferior performance regarding uncompressed data compared to Gragnaniello et al., it demonstrates higher robustness and stability within the more challenging setting [
19].
5.3. Out-of-Distribution Detection via Uncertainty Estimates
This experiment analyzes the BNN-specific possibility to express uncertainty for the detection of out-of-distribution samples and for avoiding unreliable predictions.
The BNN’s uncertainty estimates are compared to the activation statistics as expressed by the traditional neural network models. Therefore, we additionally train a CNN model analogously to the BNN described in
Section 4. Both models are evaluated on an out-of-distribution test set from various generators. More specifically, we include unseen in-distribution images from stable diffusion and out-of-distribution images from StyleGAN2 [
45], Dall-E 2 [
2], GLIDE [
54], denoising diffusion probabilistic models (DDPM) [
55], and the noise conditional score network (NCSNPP) [
56]. Additionally, we include images from other real datasets unseen during training, namely the LSUN dataset [
41] and the unconstrained face detection dataset (UFDD) [
57].
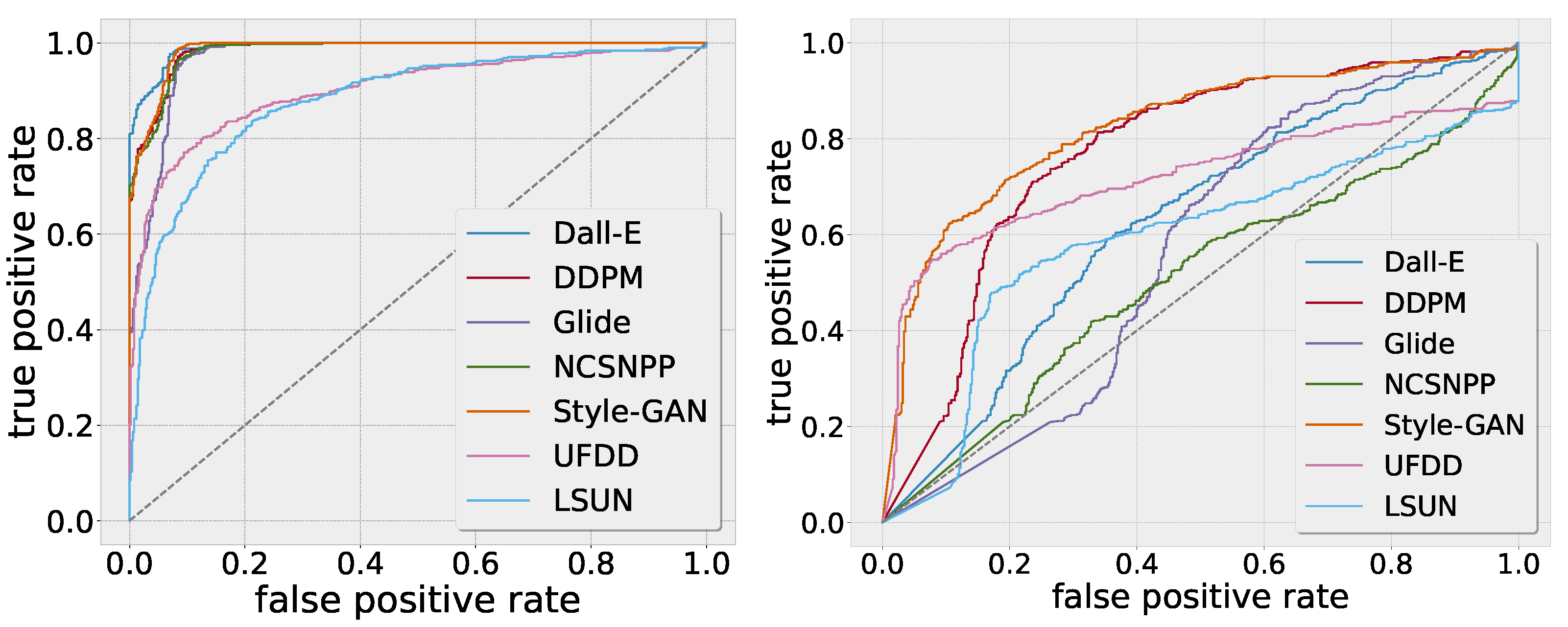
For the BNN, we use the uncertainty estimates based on Monte Carlo draws for discrimination between the in-distribution and out-of-distribution samples. For the CNN, we interpret —class activation as a means of uncertainty. The results are reported in terms of the area under the receiver-operating curve (AUC).
Figure 2 shows the results, with an ROC curve for the BNN uncertainties on the left and an ROC curve for the CNN class activation uncertainties on the right. The uncertainty-based thresholding achieves decent results for all the unseen generative models as well as for the unseen real images. In contrast, the CNN class activations are considerably weaker indicators as to whether a sample is from the out-of-distribution domain.
5.4. Reliability Evaluation via Compression Similarity
The three output nodes, real, synthetic, and compressed, provide another angle for assessing the reliability of the predictions.
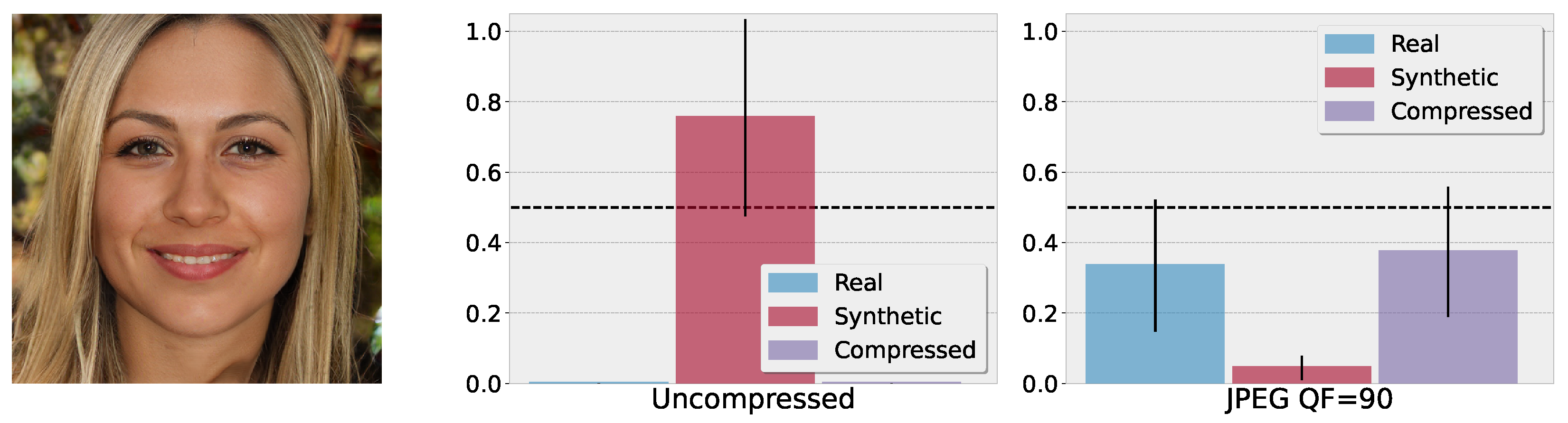
Figure 3 shows a qualitative example that is generated by the EG3D model. The data from this model are not used during training. The middle plot shows the BNN’s class activation for the uncompressed version of this image, averaged over
Monte Carlo draws. In this case, the BNN correctly shows a high activation for the synthetic class with
together with a high uncertainty of
. The right plot of
Figure 3 shows the BNN’s class activation after compressing the image with a JPEG quality factor of
. The prediction notably changes. The most likely predicted classes are now “real” alongside “compressed”, which would be a false decision. However, the BNN’s prediction is highly uncertain and the model abstains from a prediction as the mean activation for each class is below the threshold of
, as indicated by the dotted line. The inability to reliably operate on that input is therefore reflected by the abstain decision, i.e., to not decide on any class together with the high uncertainties regarding the classes.
Another telltale sign that the decision is unreliable can be found when examining the image regions that are relevant for the BNN decision as produced by Grad-CAM [
58] from the mean feature activation over
Monte Carlo draws.
Figure 4 shows the feature activations for each class that led to the respective decision from
Figure 3. The top row shows the feature activation for the uncompressed image per output class. For each class, there are different regions in the image that are relevant, with a slight overlap between the “real” and the “compressed” class. The bottom row shows the feature activation for the JPEG-compressed image. Here, the feature activation for the “synthetic” class is weaker. Additionally, the relevant regions for the “compressed” and “real” classes are very similar, which is a telltale sign in terms of the unreliable confusion induced by the post-processing.
To quantify this property, we evaluate the error rate of the BNN for various in-distribution and out-of-distribution generators and datasets. For each dataset, we analyze 500 images and use
Monte Carlo samples.
Table 4 shows a quantitative analysis regarding the effectivity of the previously introduced activation-based abstain, uncertainy-based abstain, and the now-presented SSIM-based abstain. The first two columns show the error rates when using the activation-based and the uncertainty-based abstain thresholds. The third column shows the error rates for the SSIM-based threshold. Here, we abstain from a prediction when the feature activation heatmaps achieve an SSIM score larger than or equal to
. The SSIM-based abstain is a helpful addition for several datasets, which particularly shows in the last column where all three abstain thresholds are combined, which considerably lowers the error rates for all the datasets.
5.5. Evaluation on Real-World Social Media Data
Resizing and compression operations are applied throughout the experiments to simulate real-world environments. To further increase the realism of the experiments, we additionally test our architecture on out-of-distribution data, which are composed of data from social media platforms. More specifically, we utilize the TrueFace dataset by Boato et al. [
59]. The dataset is composed of real and synthetic images, generated by the styleGAN1, styleGAN2, and styleGAN3 architectures before and after uploading to Facebook, Twitter, Telegram, and Whatsapp. The dataset is split into training and test data. For our evaluation, we use 100 images from the test dataset, where the synthetic images are generated by the styleGAN1 architecture. The images in these evaluations are severely out of distribution: neither the pre-social real images, nor the styleGAN1 generated images, nor the processing artifacts from real-world platforms like Facebook, Telegram, Twitter, or Whatsapp were observed during the training.
Figure 5 shows the mean predictions of our proposed architecture and the associated uncertainties as error bars. Our model shows high performance and confidence in its prediction on the real pre-social images. Synthetic pre-social images lead to higher uncertainty but can still be reasonably well detected. On the post-social images, our model shows, for the real and synthetic images, decreased class activation and highly increased uncertainty for almost every platform. One notable exception includes the synthetic images after uploading to Twitter. Here, our model wrongly classifies these as real with high confidence. However, at the same time, we can observe a high activation for the compressed class.
Table 5 shows the possibility to detect such unreliable false predictions. In fact, the false predictions on the out-of-distribution data can be reliably detected. The results in
Table 5 show our model’s error rate in dependence of the abstain threshold on the TrueFace data. By using the combined approach, we are able to significantly reduce the error rate on the out-of-distribution data. This is especially shown for the synthetic images uploaded to Twitter. An assessment of the compression similarity (cf.
Section 5.4) greatly reduces the initial error rate from
to
since the predictions for class “real” are rooted in confusion between the styleGAN and compression artifacts.
5.6. Ablation Study: Accuracy vs. Abstain Tradeoff by Uncertainty Thresholding
The uncertainty threshold has a major impact on reducing the error rate, as shown in the previous section. It also determines which predictions are deemed unreliable, which leads to abstaining from the predictions. In this section, we report the impact of the choice of on the error rate and abstain rate.
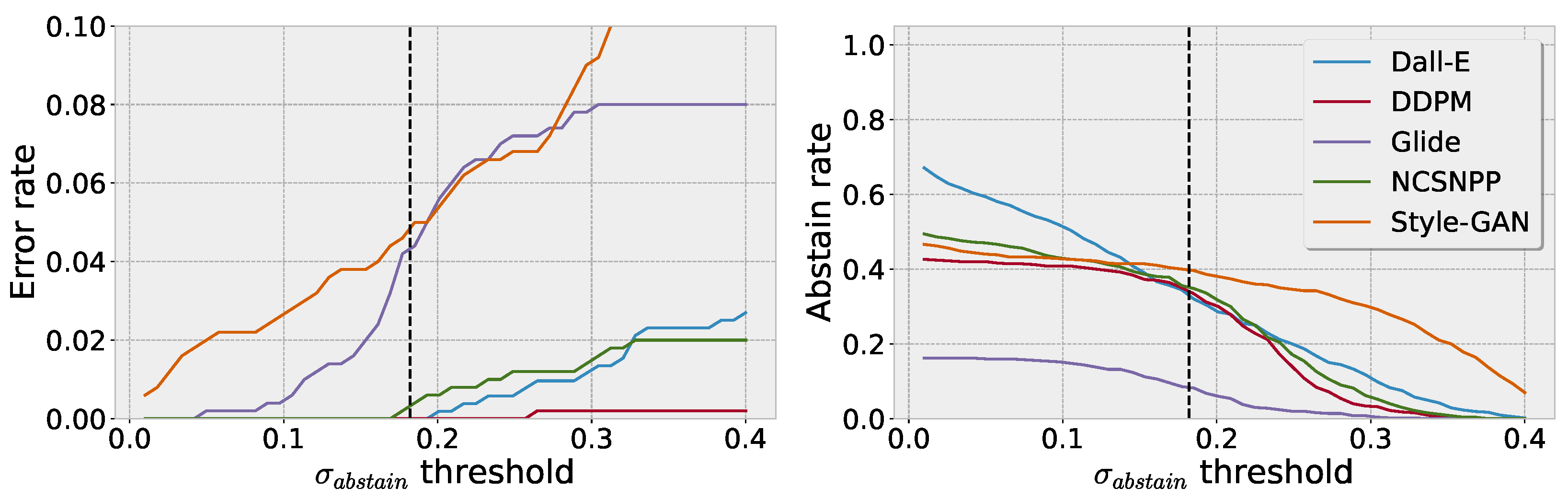
Figure 6 shows the tradeoff between the error rate and abstain rate of the BNN based on the chosen
. The left plot shows the error rate in dependency of the choice in threshold, where only predictions with an uncertainty smaller than
are considered reliable. Here, lower thresholds substantially decrease the error rate. On the other hand, lower thresholds simultaneously increase the abstain rate, as indicated in the right plot of
Figure 6.
The dotted black line shows the chosen uncertainty threshold we used throughout our previous experiments, which we specified as , twice the in-distribution uncertainty. In our experiments, this choice yields a good tradeoff between a reduction in the error rate and an increase in the abstain rate.
5.7. Ablation Study: Effectiveness of the Noise Contrastive Estimation
We show the effects of the noise contrastive prior on the uncertainty estimates of the BNN in an ablation study. The BNN is trained with and without the NCP. Both models are trained with the same protocol, as specified in
Section 4.
In
Figure 7, we compare the error rate of the BNN without the NCP (“BNN-noNCP”) with the proposed BNN. The BNN without the NCP shows a higher error rate on all four out-of-distribution datasets. The difference in error rates is particularly large for the Glide images.
Table 6 further underlines these results. It shows the abstain rate of the traditional CNN, the BNN without the NCP, and the full BNN. The CNN exhibits the lowest abstain rates since most of the decisions are based on very large activations and hence high confidence. BNN-noNCP shows higher uncertainty on the out-of-distribution datasets, which is reflected by the increasing abstain rates. This behavior is amplified by the proposed BNN with the NCP, which exhibits the highest abstain rates regarding the data it fails to generalize to, thereby avoiding confident false decisions.
Table 7 confirms this result by showing the proportion of confident false decisions. In this case, we classify a decision as confident if the class prediction is ≥0.9. While the traditional CNN approach shows a significant amount of confident false decisions on the out-of-distribution data, the BNN without the NCP halves the proportion of false decisions, and the BNN with the NCP again halves the proportion of false decisions.








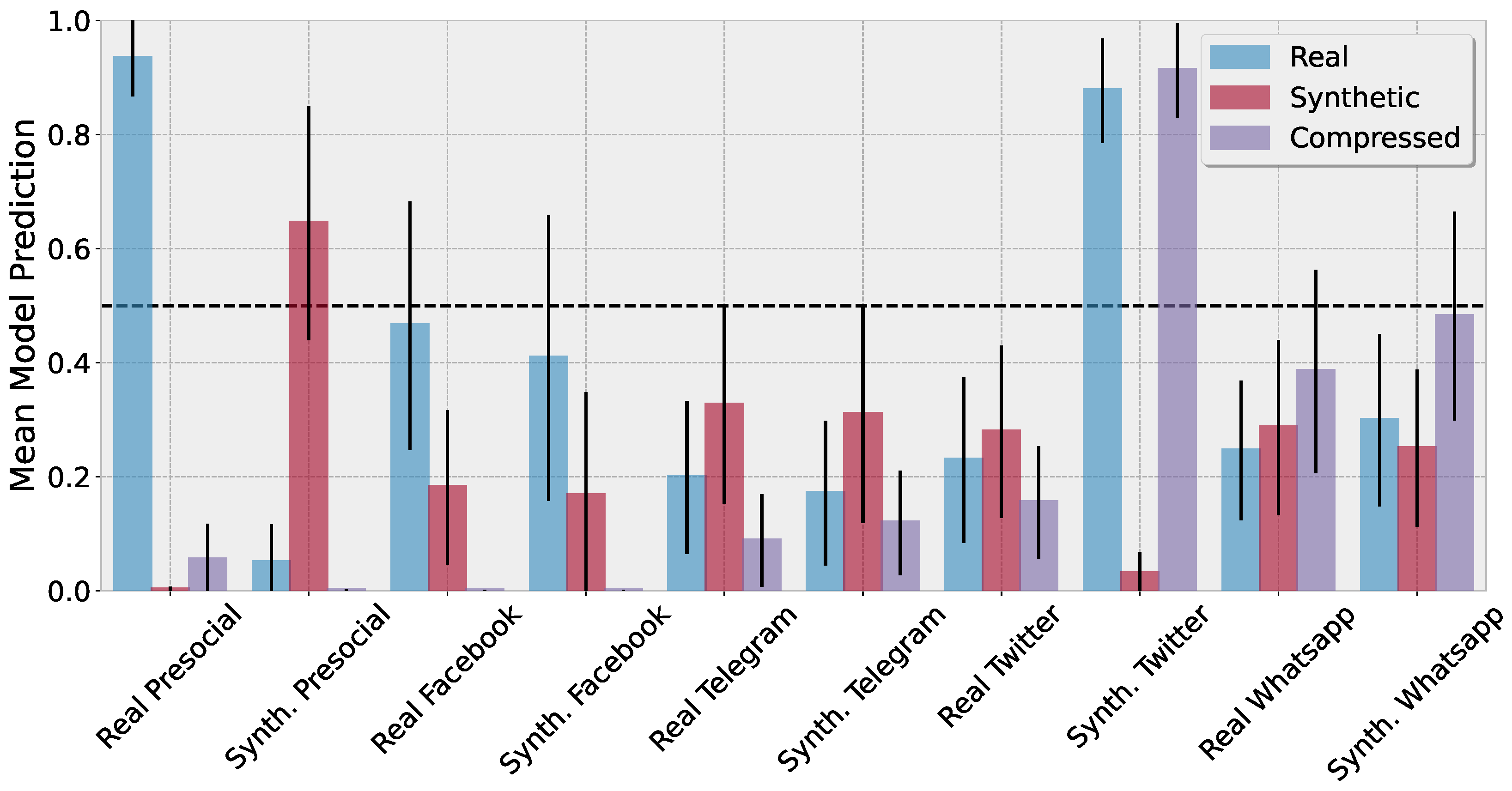


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}