




Optimizing Vision Transformers for Histopathology: Pretraining and Normalization in Breast Cancer Classification

 , , ,
, , , 
Abstract
1. Introduction
Background and Related Work
- RQ1:
- Is it possible to fine-tune a ViT model for breast cancer classification?
- RQ2:
- What are the effects of using pretraining strategies, such as data augmentation or normalization?
- RQ3:
- Is it possible to generalize our results to other datasets?
2. Materials and Methods
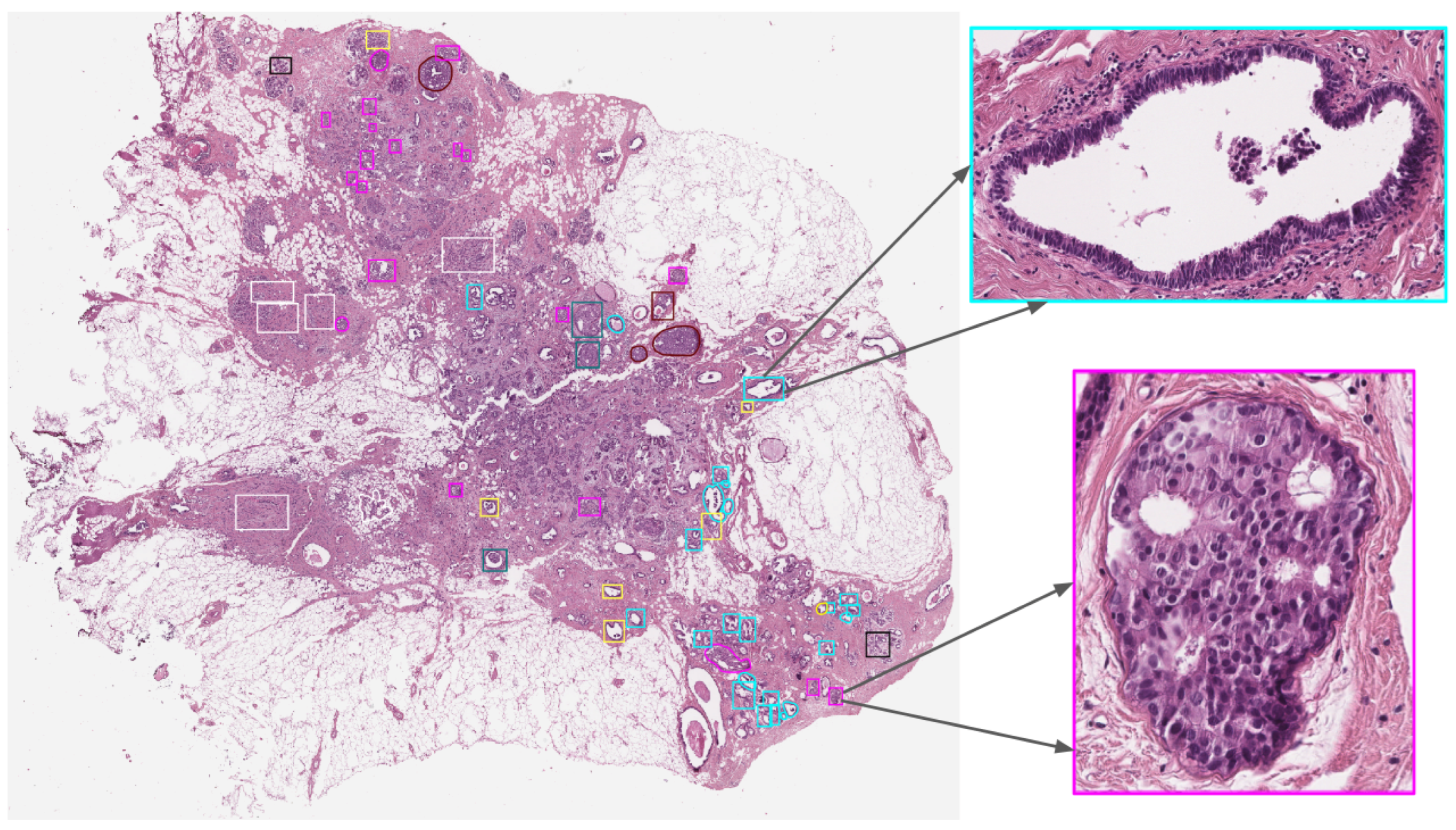
2.1. Datasets
2.1.1. BACH: Grand Challenge on BreAst Cancer Histology Images
2.1.2. BRACS: BReAst Carcinoma Subtyping Dataset
2.1.3. AIDPATH
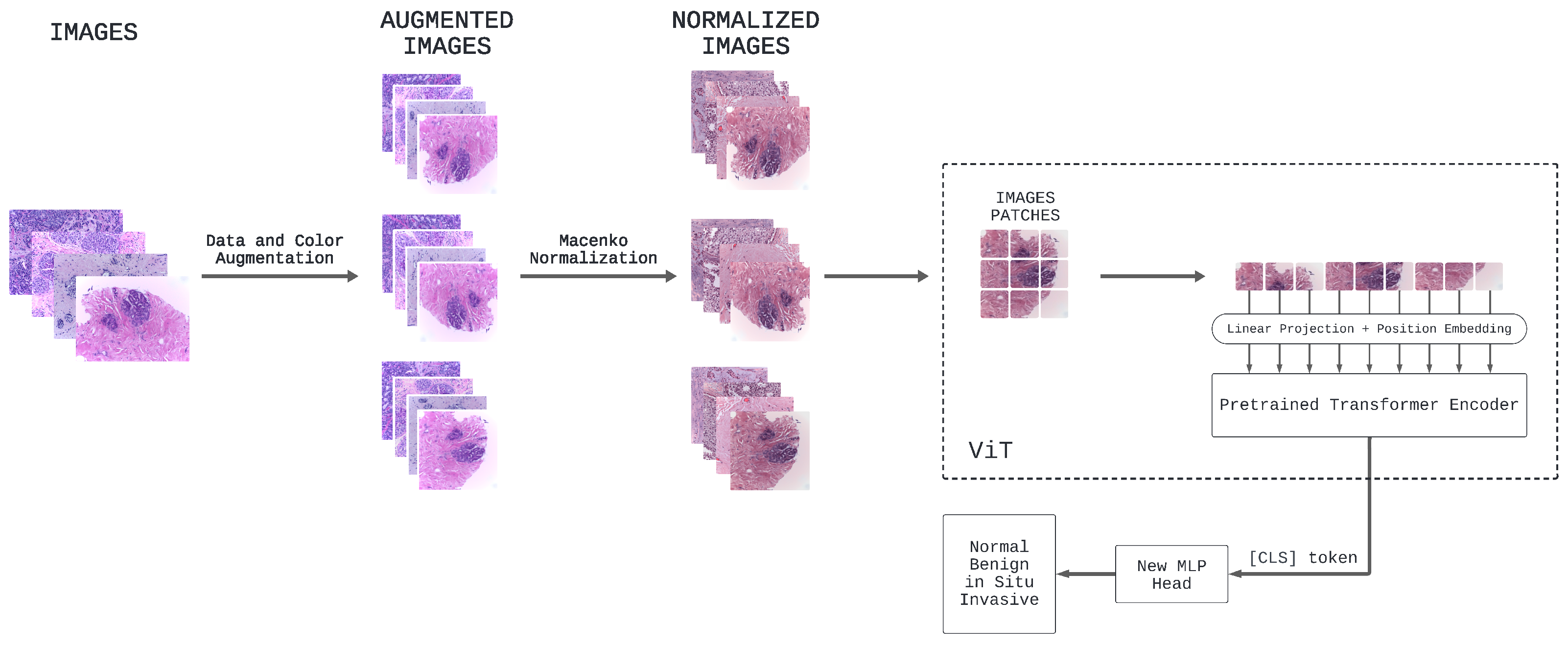
2.2. Overview of ViT Approach
2.3. Model Configurations
- Pretraining Strategy: Distinct strategies in our experimentation concerning the use of pretrained weights [47] are explored. The first strategy entails the utilization of a ViT model that has undergone prior training on a substantial dataset. Specifically, we make use of the google/vit-base-patch16-224-in21k model (https://huggingface.co/google/vit-base-patch16-224-in21k (accessed on 25 April 2024)) that underwent pretraining on ImageNet-21k, comprising 14 million images and approximately 22,000 classes, at a resolution of . This approach is motivated by the concept of transfer learning [48,49], which capitalizes on the knowledge acquired from the source domain to enhance performance in the target domain. On the other hand, the second strategy entails using the same ViT architecture but initializing the model’s weights randomly. This strategy, in essence, involves training the model from scratch.
- Resize Dimension: An examination is undertaken into the consequences of resizing the input images to a standardized dimension of pixels, a prevalent practice in image classification tasks. Additionally, we explore the implications of abstaining from resizing the input images, allowing the model to operate with their original dimensions.
- Data Augmentation: The application of geometric data augmentation techniques, including rotation, scaling, and flipping, to enhance the model’s generalization capabilities is investigated. Additionally, color data augmentation methods such as color jittering are explored. These modifications to our input images serve to artificially expand and diversify our dataset, thereby equipping the model with more robust and invariant features. We also consider an experimental scenario where no data augmentation is employed to assess the model’s performance in the absence of the additional diversity introduced by these augmentation processes. Furthermore, we shift our focus to the Part B dataset, incorporating tiles derived from WSIs. A single WSI can encompass multiple regions categorized as normal, benign, in situ carcinoma, and invasive carcinoma.
- Color Normalization: The importance of using Macenko’s color normalization [18,50] lies in its ability to standardize the appearance of digital histopathology images across different conditions. Images can vary significantly in color due to differences in staining processes, scanners, and lighting conditions. Macenko’s method addresses this issue by normalizing the colors in the images, ensuring that the tissue samples appear consistent across different images. This consistency is crucial for accurate diagnosis and research, as it allows for more reliable comparison and analysis of tissue samples. The method works by modeling the stain color and intensity distribution, then adjusting the images to fit a standard model. This not only aids pathologists in making more accurate diagnoses but also improves the efficacy of automated image analysis systems, which play an increasingly important role in histopathology.
- Tile Overlap: This refers to the number of pixels shared in common between two adjacent tiles. Increasing the overlap can potentially enhance the model’s performance by facilitating better integration of information across tiles. However, this improvement comes at the cost of increased computational demands. Therefore, our objective is to determine the optimal overlap that strikes a balance between model performance and computational efficiency.
- Tile Patch Size: The patch size plays a central role in defining the level of localized information the model can gather from each patch. Larger patches empower the model to capture intricate local nuances, while smaller patches facilitate a broader contextual perspective. However, opting for larger patches amplifies the computational workload due to the increased number of pixels within each patch. Hence, our aim is to identify the optimal patch size that effectively balances the trade-off between capturing local and global information while preserving computational efficiency.
3. Results
- Initially, the baseline ViT model employed 512 × 512 tiles with a 256 overlap and a 32 × 32 patch size, without any image resizing or pretraining, leading to an accuracy of 0.53. This suggests the chosen patch size may not adequately capture sufficient local detail for accurate predictions.
- Subsequently, the model was modified to use 512 × 512 tiles resized to 224 × 224, fine-tuned exclusively on the breast cancer dataset, with a 16 × 16 patch size and a 256 tile overlap, resulting in a similar accuracy score of 0.53.
- Enhancements were made in the next iteration where the base ViT model, pretrained on ImageNet and fine-tuned on the breast cancer dataset, used 512 × 512 tiles resized to 224 × 224 and a 256 tile overlap with an improved accuracy score of 0.84, emphasizing the significance of pretraining on extensive datasets.
- In the fourth variation, tile overlap was deleted. The images of 2048 × 1536 pixels were resized to 224 × 224, achieving an accuracy of 0.84. This indicates that increasing tile overlap does not necessarily improve performance, and may in fact introduce computational inefficiency and redundancy.
- Further improvements were observed in the fifth iteration, using the base ViT model pretrained on ImageNet and fine-tuned on the breast cancer dataset, with a 16 × 16 patch size and no tile overlap. The incorporation of geometric and color data augmentation techniques resulted in an enhanced accuracy of , demonstrating the effectiveness of these augmentations in model generalization.
- The final iteration involved pretraining the same ViT model on ImageNet, followed by fine-tuning on a comprehensive breast cancer dataset comprising both image-wise labeled histology images (Part A) and pixel-wise labeled cropped tiles from WSIs (Part B). The images in Part B were rescaled to match the pixel scale of Part A. Macenko color normalization was applied to all images to minimize stain variability, achieving the highest accuracy score of .
3.1. Pretraining Outcomes: A Detailed Assessment of HistoEncoder Strategies
3.2. The Robustness through the Use of K-Fold Cross-Validation
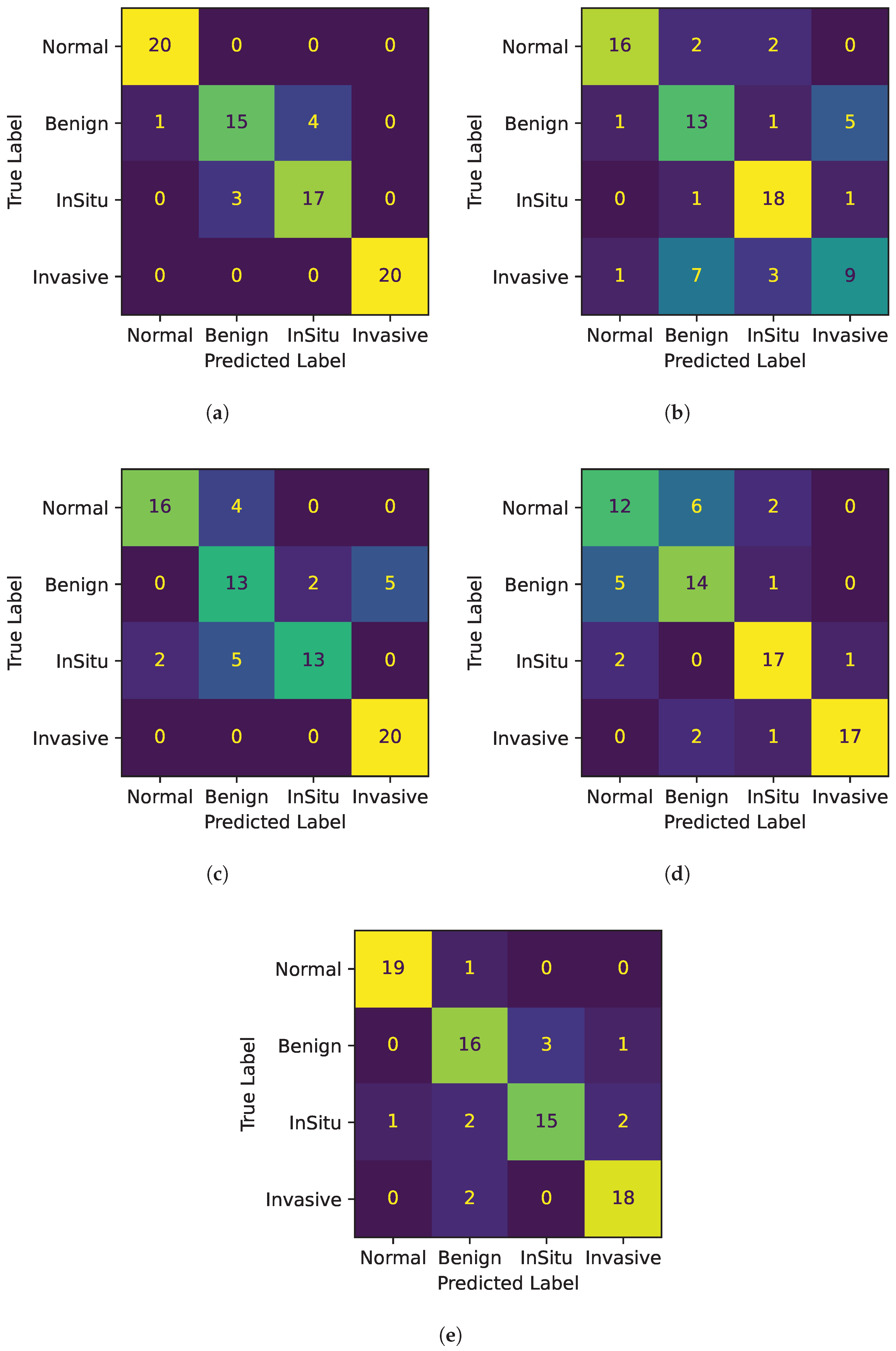
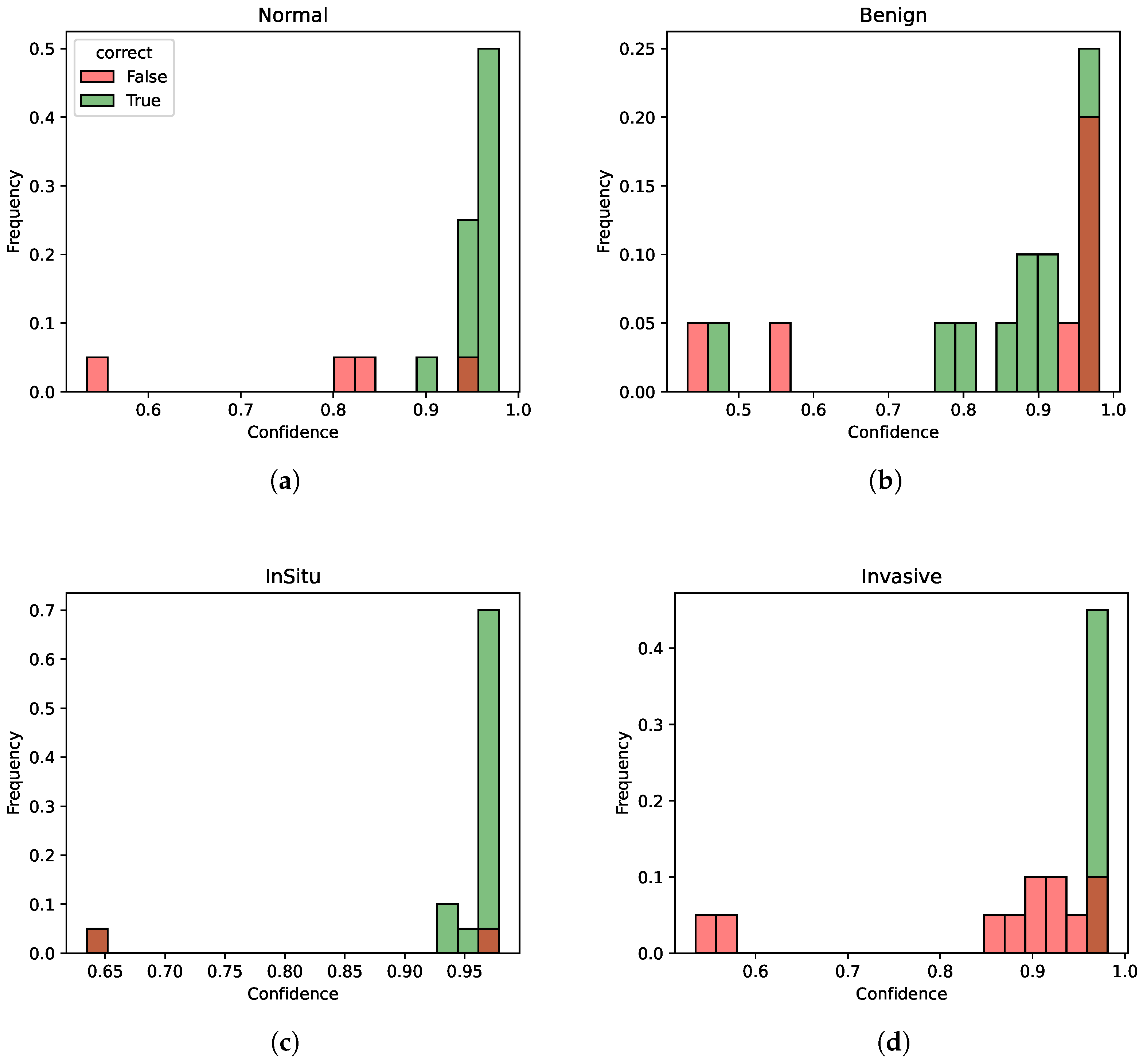
- Accuracy: Confusion matrices for all 5-fold cross-validations are depicted in Figure 4. Each figure shows a heatmap obtained from a fold. In the x-axis the predicted labels between normal, benign, in situ, and invasive are represented, while the y-axis presents the true labels. In other words, each row of the matrix illustrates the occurrences in the true class, while each column represents the occurrences in the predicted class. The elements on the main diagonal, from top left to bottom right, show the number of samples that are correctly classified. For instance, in the heatmap of Fold 1, the samples belonging to the normal and invasive classes, and in the heatmap of Fold 3, the samples belonging to the invasive class, are all correctly predicted. Instead, elements outside the main diagonal represent misclassifications. The final accuracy score for each fold is 0.90, 0.70, 0.78, 0.75, and 0.85 respectively. It is clear that the model’s accuracy varies significantly across folds, particularly for the invasive class, where the accuracy ranges from 0.45 (Fold 2) to 1.00 (Folds 1 and 3).
- Precision: The model’s precision is generally quite high, with the normal class showing the highest mean precision at 0.86. However, the invasive class again shows a high variation in precision across folds at 0.15.
- Recall: For the in situ class, the recall is quite stable, with a mean of 0.80 and a low standard deviation of 0.10, suggesting consistent performance in identifying this class across different subsets of data.
- F1-Score: The F1-Scores in the table generally follow the trends of precision and recall, with the normal class having the highest mean F1-Score of 0.85, while the benign class has the lowest at 0.69.
3.3. Model Generalization
4. Discussion
5. Conclusions
- RQ1:
- To answer RQ1, we can say that it is possible to fine-tune a Vision Transformer (ViT) model for breast cancer classification; in particular, adapting the chosen pretrained ViT model google/vit-base-patch16-224-in21k, which has learned general features from a large dataset, to the specific task of breast cancer classification using the histology images of the BACH dataset. Therefore, fine-tuning a ViT model for breast cancer classification is not only possible but also a practical and effective approach to leveraging the representation learning capabilities of pretrained models for specific medical imaging tasks.
- RQ2:
- To address RQ2, we can assert that our results indicate that pretraining ViT models on ImageNet, coupled with geometric and color data augmentation, significantly enhances performance in breast cancer histology image classification tasks. Optimal results are achieved with a 16 × 16 patch size and no tile overlap. These findings offer crucial insights for the development of future ViT-based models for similar image classification applications.
- RQ3:
- To answer RQ3, we can maintain that assessing the ViT model’s performance on the BRACS dataset provides a comprehensive examination of its ability to generalize across a spectrum of breast carcinoma sub-types. We obtain a valuable opportunity to rigorously validate the model’s diagnostic accuracy from the dataset’s wide-ranging diversity, including different lesions and tissue samples. This evaluation ensures an understanding of the model’s applicability beyond the specific dataset, enhancing confidence in its broader generalization capabilities.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
- Grand Challenge on BreAst Cancer Histology images (BACH) (https://iciar2018-challenge.grand-challenge.org)
- BReAst Carcinoma Subtyping (BRACS) dataset (https://www.bracs.icar.cnr.it)
- MSCA European Project AIDPATH (https://aidpath.eu)
Conflicts of Interest
References
- Rizzo, P.C.; Caputo, A.; Maddalena, E.; Caldonazzi, N.; Girolami, I.; Dei Tos, A.P.; Scarpa, A.; Sbaraglia, M.; Brunelli, M.; Gobbo, S.; et al. Digital pathology world tour. Digit Health 2023, 9, 20552076231194551. [Google Scholar] [CrossRef] [PubMed]
- Gardezi, S.J.S.; Elazab, A.; Lei, B.; Wang, T. Breast cancer detection and diagnosis using mammographic data: Systematic review. J. Med. Internet Res. 2019, 21, e14464. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Baroni, G.L.; Rasotto, L.; Roitero, K.; Siraj, A.H.; Della Mea, V. Vision Transformers for Breast Cancer Histology Image Classification. In Proceedings of the Image Analysis and Processing—ICIAP 2023 Workshops, Udine, Italy, 11–15 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 15–26. [Google Scholar]
- Aresta, G.; Araújo, T.; Kwok, S.; Chennamsetty, S.S.; Safwan, M.; Alex, V.; Marami, B.; Prastawa, M.; Chan, M.; Donovan, M.; et al. Bach: Grand challenge on breast cancer histology images. Med. Image Anal. 2019, 56, 122–139. [Google Scholar] [CrossRef] [PubMed]
- Srinidhi, C.L.; Ciga, O.; Martel, A.L. Deep neural network models for computational histopathology: A survey. Med. Image Anal. 2021, 67, 101813. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Van Esesn, B.C.; Awwal, A.A.S.; Asari, V.K. The history began from alexnet: A comprehensive survey on deep learning approaches. arXiv 2018, arXiv:1803.01164. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Chennamsetty, S.S.; Safwan, M.; Alex, V. Classification of breast cancer histology image using ensemble of pre-trained neural networks. In Proceedings of the Image Analysis and Recognition: 15th International Conference, ICIAR 2018, Póvoa de Varzim, Portugal, 27–29 June 2018; Proceedings 15. Springer: Berlin/Heidelberg, Germany, 2018; pp. 804–811. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Kwok, S. Multiclass classification of breast cancer in whole-slide images. In Proceedings of the Image Analysis and Recognition: 15th International Conference, ICIAR 2018, Póvoa de Varzim, Portugal, 27–29 June 2018; Proceedings 15. Springer: Berlin/Heidelberg, Germany, 2018; pp. 931–940. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- Dimitriou, N.; Arandjelović, O.; Caie, P.D. Deep learning for whole slide image analysis: An overview. Front. Med. 2019, 6, 264. [Google Scholar] [CrossRef]
- Hanna, M.G.; Parwani, A.; Sirintrapun, S.J. Whole slide imaging: Technology and applications. Adv. Anat. Pathol. 2020, 27, 251–259. [Google Scholar] [CrossRef]
- Brancati, N.; Frucci, M.; Riccio, D. Multi-classification of breast cancer histology images by using a fine-tuning strategy. In Proceedings of the Image Analysis and Recognition: 15th International Conference, ICIAR 2018, Póvoa de Varzim, Portugal, 27–29 June 2018; Proceedings 15. Springer: Berlin/Heidelberg, Germany, 2018; pp. 771–778. [Google Scholar]
- Roy, K.; Banik, D.; Bhattacharjee, D.; Nasipuri, M. Patch-based system for classification of breast histology images using deep learning. Comput. Med. Imaging Graph. 2019, 71, 90–103. [Google Scholar] [CrossRef]
- Macenko, M.; Niethammer, M.; Marron, J.S.; Borland, D.; Woosley, J.T.; Guan, X.; Schmitt, C.; Thomas, N.E. A method for normalizing histology slides for quantitative analysis. In Proceedings of the 2009 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Boston, MA, USA, 28 June–1 July 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1107–1110. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, J.; Hu, D.; Qu, H.; Tian, Y.; Cui, X. Application of Deep Learning in Histopathology Images of Breast Cancer: A Review. Micromachines 2022, 13, 2197. [Google Scholar] [CrossRef]
- Wang, W.; Jiang, R.; Cui, N.; Li, Q.; Yuan, F.; Xiao, Z. Semi-supervised vision transformer with adaptive token sampling for breast cancer classification. Front. Pharmacol. 2022, 13, 929755. [Google Scholar] [CrossRef]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A Dataset for Breast Cancer Histopathological Image Classification. IEEE Trans. Biomed. Eng. 2016, 63, 1455–1462. [Google Scholar] [CrossRef]
- Tummala, S.; Kim, J.; Kadry, S. BreaST-Net: Multi-class classification of breast cancer from histopathological images using ensemble of swin transformers. Mathematics 2022, 10, 4109. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Los Alamitos, CA, USA, 11–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Alotaibi, A.; Alafif, T.; Alkhilaiwi, F.; Alatawi, Y.; Althobaiti, H.; Alrefaei, A.; Hawsawi, Y.; Nguyen, T. ViT-DeiT: An Ensemble Model for Breast Cancer Histopathological Images Classification. In Proceedings of the 2023 1st International Conference on Advanced Innovations in Smart Cities (ICAISC), Jeddah, Saudi Arabia, 23–25 January 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Proceedings of Machine Learning Research. Meila, M., Zhang, T., Eds.; PMLR: Cambridge MA, USA, 2021; Volume 139, pp. 10347–10357. [Google Scholar]
- He, Z.; Lin, M.; Xu, Z.; Yao, Z.; Chen, H.; Alhudhaif, A.; Alenezi, F. Deconv-transformer (DecT): A histopathological image classification model for breast cancer based on color deconvolution and transformer architecture. Inf. Sci. 2022, 608, 1093–1112. [Google Scholar] [CrossRef]
- Sriwastawa, A.; Arul Jothi, J.A. Vision transformer and its variants for image classification in digital breast cancer histopathology: A comparative study. Multimed. Tools Appl. 2023, 83, 39731–39753. [Google Scholar] [CrossRef]
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking spatial dimensions of vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11936–11945. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Wang, W.; Yao, L.; Chen, L.; Lin, B.; Cai, D.; He, X.; Liu, W. CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Zhang, Z.; Zhang, H.; Zhao, L.; Chen, T.; Arik, S.Ö.; Pfister, T. Nested hierarchical transformer: Towards accurate, data-efficient and interpretable visual understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 3417–3425. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. Maxvit: Multi-axis vision transformer. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 459–479. [Google Scholar]
- Li, W.; Wang, X.; Xia, X.; Wu, J.; Xiao, X.; Zheng, M.; Wen, S. Sepvit: Separable vision transformer. arXiv 2022, arXiv:2203.15380. [Google Scholar]
- Cruz-Roa, A.; Basavanhally, A.; González, F.; Gilmore, H.; Feldman, M.; Ganesan, S.; Shih, N.; Tomaszewski, J.; Madabhushi, A. Automatic detection of invasive ductal carcinoma in whole slide images with convolutional neural networks. In Proceedings of the Medical Imaging 2014: Digital Pathology, San Diego, CA, USA, 15–20 February 2014; SPIE: Bellingham, WA, USA, 2014; Volume 9041, p. 904103. [Google Scholar]
- Janowczyk, A.; Madabhushi, A. Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases. J. Pathol. Inform. 2016, 7, 29. [Google Scholar] [CrossRef]
- Yao, H.; Zhang, X.; Zhou, X.; Liu, S. Parallel structure deep neural network using CNN and RNN with an attention mechanism for breast cancer histology image classification. Cancers 2019, 11, 1901. [Google Scholar] [CrossRef]
- Karuppasamy, A. Recent ViT based models for Breast Cancer Histopathology Image Classification. In Proceedings of the 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 6–8 July 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Pohjonen, J. HistoEncoder: Foundation Models for Digital Pathology. GitHub Repository. 2023. Available online: https://github.com/jopo666/HistoEncoder (accessed on 25 April 2024).
- Brancati, N.; Anniciello, A.M.; Pati, P.; Riccio, D.; Scognamiglio, G.; Jaume, G.; De Pietro, G.; Di Bonito, M.; Foncubierta, A.; Botti, G.; et al. BRACS: A Dataset for BReAst Carcinoma Subtyping in H&E Histology Images. Database J. Biol. Databases Curation 2022, 2022, baac093. [Google Scholar] [CrossRef]
- Ellis, I.O. Intraductal proliferative lesions of the breast: Morphology, associated risk and molecular biology. Mod. Pathol. 2010, 23, S1–S7. [Google Scholar] [CrossRef]
- Gobbi, H. Classification of Intraductal Precursor and Proliferative Lesions. In Breast Diseases: An Evidence-Based Pocket Guide; Springer Nature: Berlin, Germany, 2019; pp. 165–169. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Nassif, A.B.; Talib, M.A.; Nasir, Q.; Afadar, Y.; Elgendy, O. Breast cancer detection using artificial intelligence techniques: A systematic literature review. Artif. Intell. Med. 2022, 127, 102276. [Google Scholar] [CrossRef]
- Tay, Y.; Dehghani, M.; Rao, J.; Fedus, W.; Abnar, S.; Chung, H.W.; Narang, S.; Yogatama, D.; Vaswani, A.; Metzler, D. Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers. arXiv 2021, arXiv:2109.10686. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Reinhard, E.; Adhikhmin, M.; Gooch, B.; Shirley, P. Color transfer between images. IEEE Comput. Graph. Appl. 2001, 21, 34–41. [Google Scholar] [CrossRef]
- Medsker, L.R.; Jain, L. Recurrent neural networks. Des. Appl. 2001, 5, 64–67. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference Number | Dataset | Methods | Accuracy |
|---|---|---|---|
| Alotaibi et al. [26] | BreakHis | ViT + DeiT | 0.98 (8-class) |
| Baroni et al. [4] | BACH | ViT | 0.91 |
| Brancati et al. [16] | BACH | Resnet-34, 50, 101 | 0.86 |
| Chennamsetty et al. [9] | BACH | ResNet-101 + DenseNet-161 | 0.87 |
| He et al. [28] | BreakHis | DecT | 0.93 |
| BACH | DecT | 0.79 | |
| UC | DecT | 0.81 | |
| Kwok [12] | BACH | Inception-Resnet-v2 | 0.87 |
| Roy et al. [17] | BACH | PBC with CNN | 0.87 |
| Sriwastawa and Arul Jothi [29] | BreakHis | MaxViT | 0.916 |
| IDC | MaxViT | 0.92 | |
| BreakHis + IDC | MaxViT | 0.92 | |
| Tummala et al. [24] | BreakHis | Ensemble of SwinTs | 0.99 (2-class), 0.96 (8-class) |
| Wang et al. [22] | BUSI | CT + ViT + ATS | 0.95 |
| BreakHis | CT + ViT + ATS | 0.98 (2-class) | |
| Yao et al. [39] | BACH dataset | Ensemble of 5 models | 0.92 |
| Base Model | Pretrain Strategy | Resize Dimension | Data Augmentation | Tile Overlap | Patch Size | Accuracy Score |
|---|---|---|---|---|---|---|
| ViT | no | no | no | 256 | 32 | 0.53 |
| ViT | no | 224 × 224 | no | 256 | 16 | 0.53 |
| ViT | vit-base | 224 × 224 | no | 256 | 16 | 0.84 |
| ViT | vit-base | 224 × 224 | no | no | 16 | 0.84 |
| ViT | vit-base | 224 × 224 | Geometric, Color | no | 16 | 0.90 |
| ViT | vit-base | 224 × 224 | Geometric, Color, Set B | no | 16 | 0.91 |
| Base Model | Pretrain Strategy | Data Augmentation | Accuracy Score |
|---|---|---|---|
| ViT | vit-base | Geometric, Color, Set B | 0.91 |
| ViT | vit-base | Geometric, Color | 0.90 |
| ViT | HistoEncoder prostate_small | Geometric, Color, Set B | 0.89 |
| ViT | HistoEncoder prostate_medium | Geometric, Color, Set B | 0.86 |
| ViT | vit-base | no | 0.84 |
| ViT | vit-base | no | 0.84 |
| Class | Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | ||
|---|---|---|---|---|---|---|---|
| Accuracy | |||||||
| Normal | 1.00 | 0.80 | 0.80 | 0.60 | 0.95 | 0.83 | 0.16 |
| Benign | 0.75 | 0.65 | 0.65 | 0.70 | 0.80 | 0.71 | 0.07 |
| In situ | 0.85 | 0.90 | 0.65 | 0.85 | 0.75 | 0.80 | 0.10 |
| Invasive | 1.00 | 0.45 | 1.00 | 0.85 | 0.90 | 0.84 | 0.23 |
| Precision | |||||||
| Normal | 0.95 | 0.89 | 0.89 | 0.63 | 0.95 | 0.86 | 0.13 |
| Benign | 0.83 | 0.57 | 0.59 | 0.64 | 0.76 | 0.68 | 0.11 |
| In situ | 0.81 | 0.75 | 0.87 | 0.81 | 0.83 | 0.81 | 0.04 |
| Invasive | 1.00 | 0.60 | 0.80 | 0.94 | 0.86 | 0.84 | 0.15 |
| Recall | |||||||
| Normal | 1.00 | 0.80 | 0.80 | 0.60 | 0.95 | 0.83 | 0.16 |
| Benign | 0.75 | 0.65 | 0.65 | 0.70 | 0.80 | 0.71 | 0.07 |
| In situ | 0.85 | 0.90 | 0.65 | 0.85 | 0.75 | 0.80 | 0.10 |
| Invasive | 1.00 | 0.45 | 1.00 | 0.85 | 0.90 | 0.84 | 0.23 |
| F1-Score | |||||||
| Normal | 0.98 | 0.84 | 0.84 | 0.62 | 0.95 | 0.85 | 0.14 |
| Benign | 0.79 | 0.60 | 0.62 | 0.67 | 0.78 | 0.69 | 0.09 |
| In situ | 0.83 | 0.82 | 0.74 | 0.83 | 0.79 | 0.80 | 0.04 |
| Invasive | 1.00 | 0.51 | 0.89 | 0.89 | 0.88 | 0.83 | 0.19 |
| Normal | Benign | In situ | Invasive | Overall | |
|---|---|---|---|---|---|
| 0-N | 0.85 | 0.09 | 0.04 | 0.02 | |
| 1-PB | 0.37 | 0.36 | 0.14 | 0.13 | |
| 2-UDH | 0.23 | 0.20 | 0.50 | 0.07 | |
| 3-FEA | 0.12 | 0.35 | 0.41 | 0.12 | |
| 4-ADH | 0.10 | 0.12 | 0.71 | 0.06 | |
| 5-DCIS | 0.04 | 0.06 | 0.88 | 0.02 | |
| 6-IC | 0.06 | 0.03 | 0.03 | 0.88 | |
| Accuracy | 0.74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baroni, G.L.; Rasotto, L.; Roitero, K.; Tulisso, A.; Di Loreto, C.; Della Mea, V. Optimizing Vision Transformers for Histopathology: Pretraining and Normalization in Breast Cancer Classification. J. Imaging 2024, 10, 108. https://doi.org/10.3390/jimaging10050108
Baroni GL, Rasotto L, Roitero K, Tulisso A, Di Loreto C, Della Mea V. Optimizing Vision Transformers for Histopathology: Pretraining and Normalization in Breast Cancer Classification. Journal of Imaging. 2024; 10(5):108. https://doi.org/10.3390/jimaging10050108
Chicago/Turabian StyleBaroni, Giulia Lucrezia, Laura Rasotto, Kevin Roitero, Angelica Tulisso, Carla Di Loreto, and Vincenzo Della Mea. 2024. "Optimizing Vision Transformers for Histopathology: Pretraining and Normalization in Breast Cancer Classification" Journal of Imaging 10, no. 5: 108. https://doi.org/10.3390/jimaging10050108
APA StyleBaroni, G. L., Rasotto, L., Roitero, K., Tulisso, A., Di Loreto, C., & Della Mea, V. (2024). Optimizing Vision Transformers for Histopathology: Pretraining and Normalization in Breast Cancer Classification. Journal of Imaging, 10(5), 108. https://doi.org/10.3390/jimaging10050108