

Enhanced Self-Checkout System for Retail Based on Improved YOLOv10


Abstract
1. Introduction
1.1. Research Background
1.2. Challenges in Current Self-Checkout Systems
1.3. Overview of Advancements of Deep Learning and Computer Vision in Retail
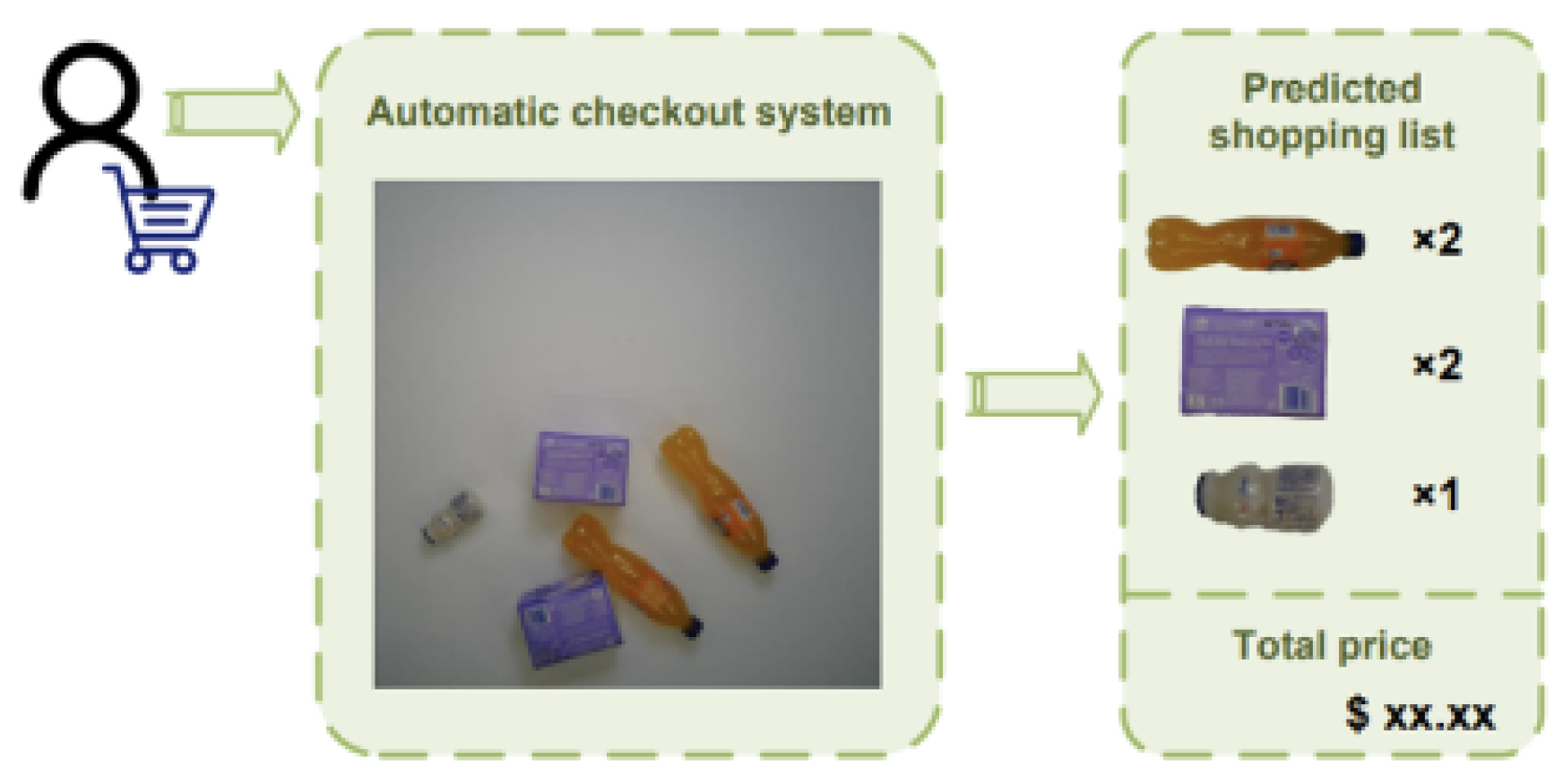
1.4. Purpose of the New System and Advantages
2. Related Work
2.1. Traditional Object Detection Algorithms
2.2. Development of the YOLO Series
2.3. Application of YOLO
3. The Improved MidState-YOLO-ED Network
3.1. Integration of YOLOv8n and YOLOv10
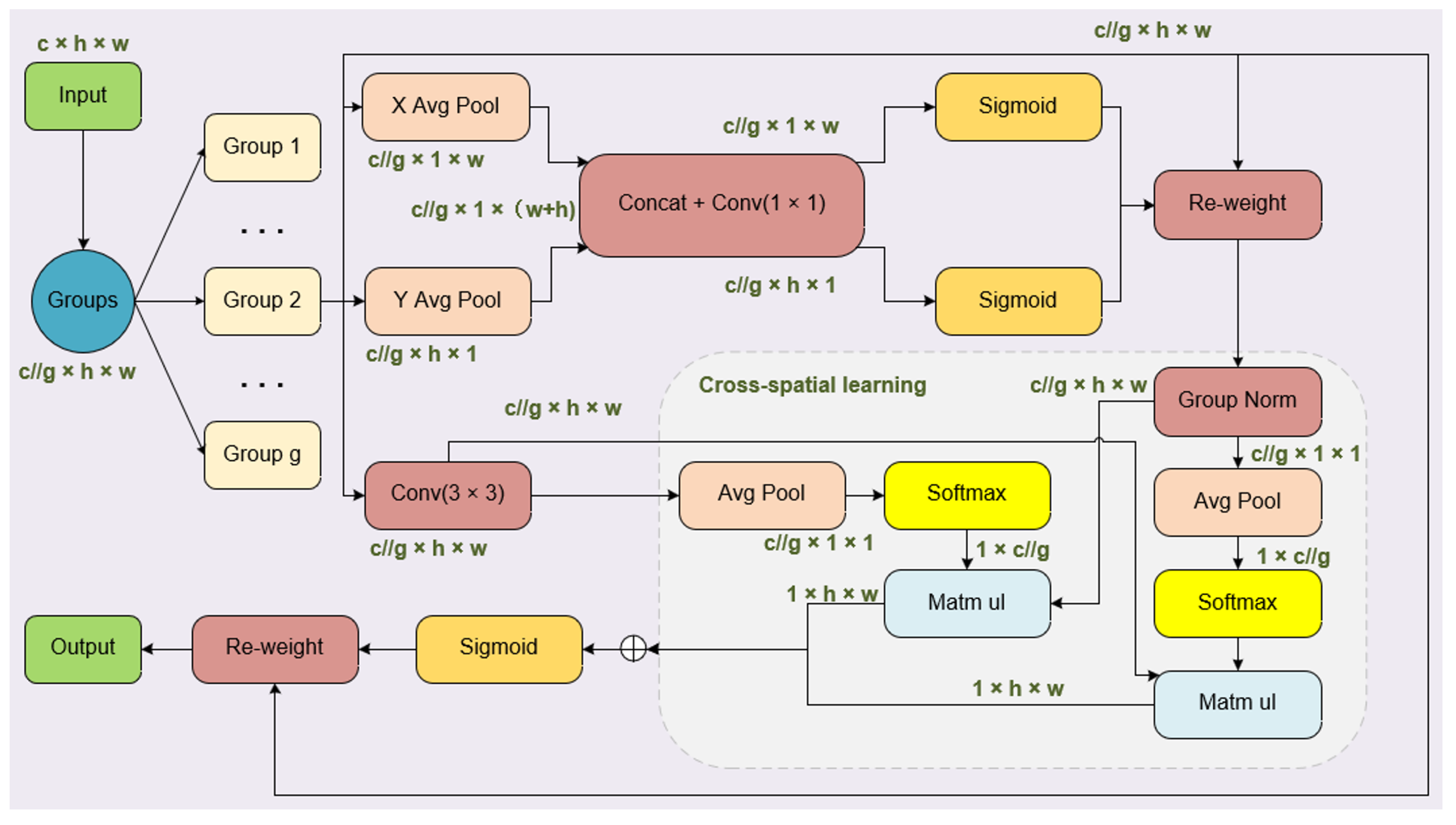
3.2. Integration of EMA Attention
3.3. Lightweight Dual Convolution C2f-Dual Design
4. Experimental Results and Analysis
4.1. Experimental Setup and Parameters
4.2. Dataset
4.3. Evaluation Metrics
4.4. Ablation Study
4.5. Experimental Results and Discussion
4.6. Comparative Visualization Analysis
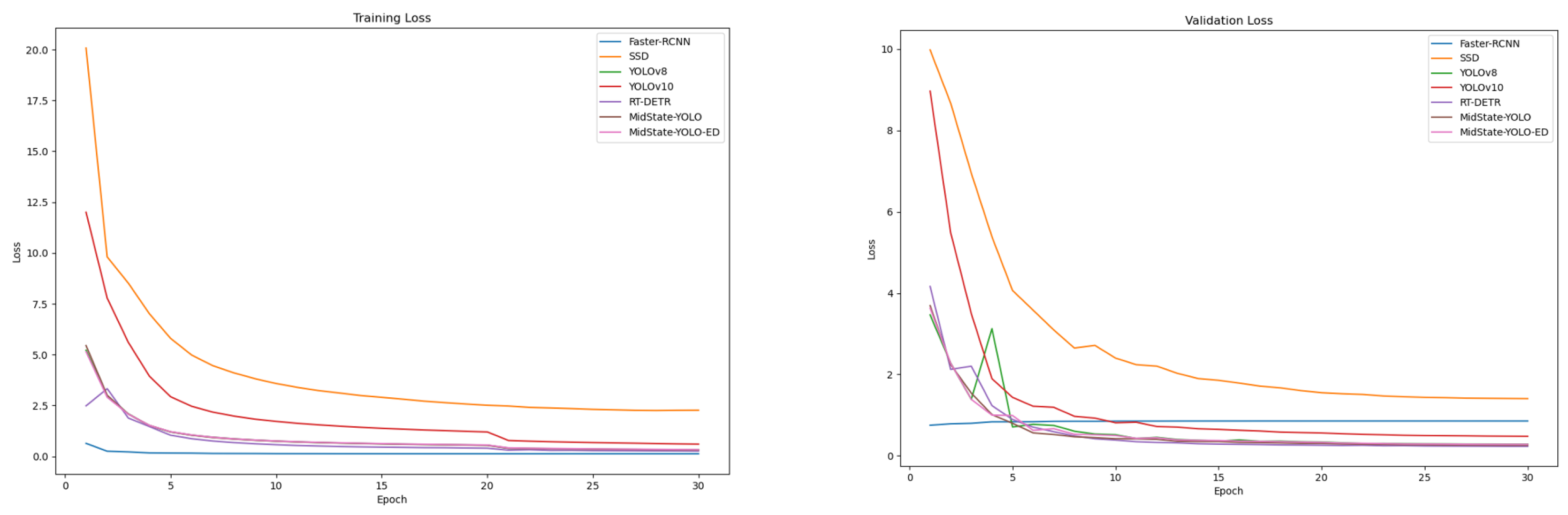
4.7. Loss Function Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Orel, F.D.; Kara, A. Supermarket self-checkout service quality, customer satisfaction, and loyalty: Empirical evidence from an emerging market. J. Retail. Consum. Serv. 2014, 21, 118–129. [Google Scholar]
- Vats, A.; Anastasiu, D.C. Enhancing retail checkout through video inpainting, yolov8 detection, and deepsort tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5530–5537. [Google Scholar]
- Shoman, M.; Aboah, A.; Morehead, A.; Duan, Y.; Daud, A.; Adu-Gyamfi, Y. A region-based deep learning approach to automated retail checkout. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3210–3215. [Google Scholar]
- Drid, K.; Allaoui, M.; Kherfi, M.L. Object detector combination for increasing accuracy and detecting more overlapping objects. In Proceedings of the International Conference on Image and Signal Processing, Marrakesh, Morocco, 4–6 June 2020; Springer: Cham, Switzerland, 2020; pp. 290–296. [Google Scholar]
- Oosthuizen, K.; Botha, E.; Robertson, J.; Montecchi, M. Artificial intelligence in retail: The AI-enabled value chain. Australas. Mark. J. 2021, 29, 264–273. [Google Scholar]
- Zheng, Q.; Yu, C.; Cao, J.; Xu, Y.; Xing, Q.; Jin, Y. Advanced Payment Security System: XGBoost, CatBoost and SMOTE Integrated. arXiv 2024, arXiv:2406.04658. [Google Scholar]
- Liu, J.; Huang, I.; Anand, A.; Chang, P.H.; Huang, Y. Digital Twin in Retail: An AI-Driven Multi-Modal Approach for Real-Time Product Recognition and 3D Store Reconstruction. In Proceedings of the 2024 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Orlando, FL, USA, 16–21 March 2024; pp. 368–373. [Google Scholar]
- Lin, Z.; Wang, C.; Li, Z.; Wang, Z.; Liu, X.; Zhu, Y. Neural radiance fields convert 2d to 3d texture. Appl. Sci. Biotechnol. J. Adv. Res. 2024, 3, 40–44. [Google Scholar]
- Liu, F.; Wang, X.; Chen, Q.; Liu, J.; Liu, C. SiamMAN: Siamese multi-phase aware network for real-time unmanned aerial vehicle tracking. Drones 2023, 7, 707. [Google Scholar] [CrossRef]
- Mokayed, H.; Quan, T.Z.; Alkhaled, L.; Sivakumar, V. Real-time human detection and counting system using deep learning computer vision techniques. In Proceedings of the Artificial Intelligence and Applications, Wuhan, China, 18–20 November 2023; Volume 1, pp. 221–229. [Google Scholar]
- He, C.; Li, K.; Zhang, Y.; Tang, L.; Zhang, Y.; Guo, Z.; Li, X. Camouflaged object detection with feature decomposition and edge reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22046–22055. [Google Scholar]
- Li, H.; Zhang, R.; Pan, Y.; Ren, J.; Shen, F. Lr-fpn: Enhancing remote sensing object detection with location refined feature pyramid network. arXiv 2024, arXiv:2404.01614. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Wei, Y.; Tran, S.; Xu, S.; Kang, B.; Springer, M. Deep learning for retail product recognition: Challenges and techniques. Comput. Intell. Neurosci. 2020, 2020, 8875910. [Google Scholar]
- Dang, B.; Zhao, W.; Li, Y.; Ma, D.; Yu, Q.; Zhu, E.Y. Real-Time pill identification for the visually impaired using deep learning. arXiv 2024, arXiv:2405.05983. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Duan, Y.; Zhao, Z.; Qi, L.; Wang, L.; Zhou, L.; Shi, Y.; Gao, Y. Mutexmatch: Semi-supervised learning with mutex-based consistency regularization. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 8441–8455. [Google Scholar] [CrossRef] [PubMed]
- Cruz-Mota, J.; Bogdanova, I.; Paquier, B.; Bierlaire, M.; Thiran, J.P. Scale invariant feature transform on the sphere: Theory and applications. Int. J. Comput. Vis. 2012, 98, 217–241. [Google Scholar] [CrossRef]
- Tokunaga, H.; Teramoto, Y.; Yoshizawa, A.; Bise, R. Adaptive weighting multi-field-of-view CNN for semantic segmentation in pathology. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12597–12606. [Google Scholar]
- Jin, Y. GraphCNNpred: A stock market indices prediction using a Graph based deep learning system. arXiv 2024, arXiv:2407.03760. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 14th European Conference of the Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Li, Z.; Yang, L.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An improved YOLOv2 for vehicle detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Sarda, A.; Dixit, S.; Bhan, A. Object detection for autonomous driving using yolo [you only look once] algorithm. In Proceedings of the IEEE 2021 3rd International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Online, 4–6 February 2021; pp. 1370–1374. [Google Scholar]
- Narejo, S.; Pandey, B.; Esenarro Vargas, D.; Rodriguez, C.; Anjum, M.R. Weapon detection using YOLO V3 for smart surveillance system. Math. Probl. Eng. 2021, 2021, 9975700. [Google Scholar] [CrossRef]
- Qureshi, R.; Ragab, M.G.; Abdulkader, S.J.; Alqushaib, A.; Sumiea, E.H.; Alhussian, H. A comprehensive systematic review of yolo for medical object detection (2018 to 2023). Authorea Prepr. 2023, 11, 2–31. [Google Scholar]
- Li, M.; Zhang, Z.; Lei, L.; Wang, X.; Guo, X. Agricultural greenhouses detection in high-resolution satellite images based on convolutional neural networks: Comparison of faster R-CNN, YOLO v3 and SSD. Sensors 2020, 20, 4938. [Google Scholar] [CrossRef] [PubMed]
- Dan, H.C.; Yan, P.; Tan, J.; Zhou, Y.; Lu, B. Multiple distresses detection for Asphalt Pavement using improved you Only Look Once Algorithm based on convolutional neural network. Int. J. Pavement Eng. 2024, 25, 2308169. [Google Scholar] [CrossRef]
- Zhong, X.; Liu, X.; Gong, T.; Sun, Y.; Hu, H.; Liu, Q. FAGD-Net: Feature-Augmented Grasp Detection Network Based on Efficient Multi-Scale Attention and Fusion Mechanisms. Appl. Sci. 2024, 14, 5097. [Google Scholar] [CrossRef]
- Wei, X.S.; Cui, Q.; Yang, L.; Wang, P.; Liu, L. RPC: A large-scale retail product checkout dataset. arXiv 2019, arXiv:1901.07249. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Parameter |
|---|---|
| GPU | RTX4080-16G |
| CPU | AMD Ryzen7 |
| Operating System | Windows11 |
| Deep Learning Frameworks | Pytorch2.1.1 |
| +cuda12.1 | |
| Build System | PyCharm |
| Model | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | Params | GFLOPs |
|---|---|---|---|---|---|---|
| YOLOv8-n | 0.824 | 0.809 | 0.877 | 0.691 | 3,371,024 | 9.8 |
| YOLO v10-n | 0.551 | 0.595 | 0.61 | 0.481 | 2,885,888 | 9.2 |
| MidState-YOLO | 0.794 | 0.775 | 0.842 | 0.654 | 3,405,456 | 9.8 |
| MidState-YOLO+DualConv | 0.84 | 0.816 | 0.883 | 0.686 | 3,251,856 | 9.4 |
| MidState-YOLO+EMA | 0.843 | 0.813 | 0.884 | 0.694 | 3,408,928 | 9.9 |
| MidState-YOLO-ED | 0.847 | 0.825 | 0.89 | 0.691 | 3,288,096 | 9.6 |
| Model | Recall | mAP@0.5 | mAP@0.5:0.95 | Params | GFLOPs | FPS |
|---|---|---|---|---|---|---|
| Faster R-CNN | 0.899 | 0.995 | 0.855 | 41,808,406 | 134.9 | 38.01 |
| SSD | 0.758 | 0.943 | 0.693 | 30,160,468 | 13.4 | 58.78 |
| YOLOv8-n | 0.981 | 0.992 | 0.869 | 3,371,024 | 9.8 | 106.38 |
| YOLO v10-n | 0.970 | 0.991 | 0.871 | 2,885,888 | 9.2 | 112.36 |
| RT-DETR-L | 0.991 | 0.994 | 0.879 | 32,394,740 | 104.3 | 89.29 |
| MidState-YOLO | 0.987 | 0.993 | 0.875 | 3,405,456 | 9.8 | 105.26 |
| MidState-YOLO-ED | 0.985 | 0.994 | 0.875 | 3,288,096 | 9.6 | 109.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, L.; Liu, S.; Gao, J.; Liu, X.; Chu, L.; Jiang, H. Enhanced Self-Checkout System for Retail Based on Improved YOLOv10. J. Imaging 2024, 10, 248. https://doi.org/10.3390/jimaging10100248
Tan L, Liu S, Gao J, Liu X, Chu L, Jiang H. Enhanced Self-Checkout System for Retail Based on Improved YOLOv10. Journal of Imaging. 2024; 10(10):248. https://doi.org/10.3390/jimaging10100248
Chicago/Turabian StyleTan, Lianghao, Shubing Liu, Jing Gao, Xiaoyi Liu, Linyue Chu, and Huangqi Jiang. 2024. "Enhanced Self-Checkout System for Retail Based on Improved YOLOv10" Journal of Imaging 10, no. 10: 248. https://doi.org/10.3390/jimaging10100248
APA StyleTan, L., Liu, S., Gao, J., Liu, X., Chu, L., & Jiang, H. (2024). Enhanced Self-Checkout System for Retail Based on Improved YOLOv10. Journal of Imaging, 10(10), 248. https://doi.org/10.3390/jimaging10100248