

Optimization of a Redox-Flow Battery Simulation Model Based on a Deep Reinforcement Learning Approach


Abstract
:1. Introduction
2. Modeling of the Vanadium Redox-Flow Battery
2.1. Determination of the State of Charge (SoC)
- ∘
- refers to the current used for charging or discharging the battery.
- ∘
- signifies the current losses resulting from internal processes within the VRFB, such as shunt currents or vanadium permeation.
- ∘
- denotes the practical storage capacity of the battery system, measured in ampere-hours (Ah), which typically differs from the theoretical storage capacity. The real storage capacity reflects the actual amount of charge the battery can hold, accounting for various factors that might affect its performance. These factors often make the real storage capacity deviate from the ideal or theoretical value .
- ∘
- R represents the gas constant with a numerical value of 8.314 J Mol K.
2.2. Determination of Cell Voltage (U)
- ∘
- is the formal cell potential, which applies when the concentrations of all vanadium oxidation states are identical.
- ∘
- F is a Faraday constant with a numerical value of 96,486 AsMol.
- ∘
- z refers to the transferred electrons during the reaction.
- ∘
- is the number of cells used to determine the battery voltage.
2.3. Calculation of Power (P)
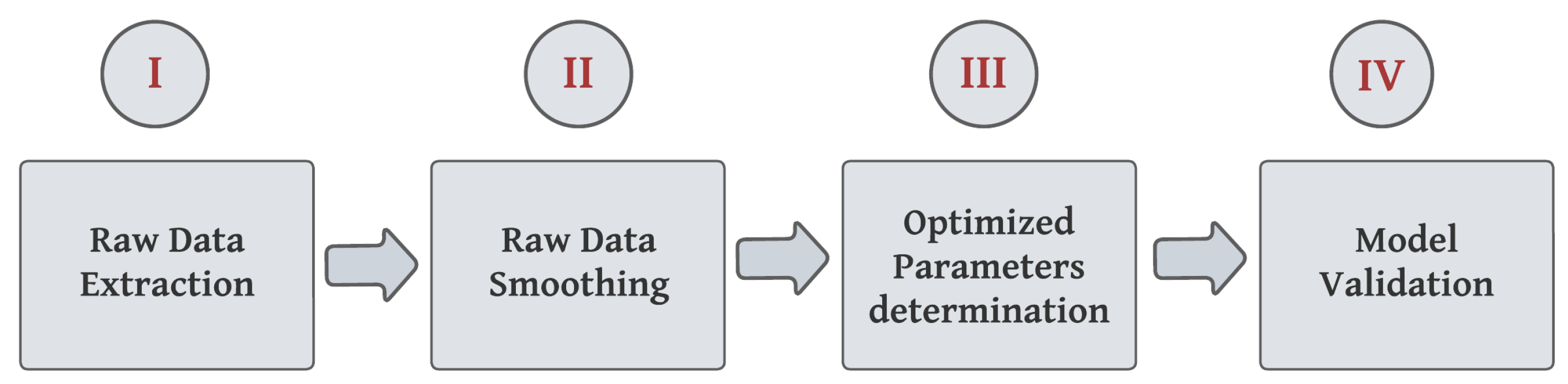
2.4. Dataset Overview
- ∘
- AC Power: This stands for “Alternating Current power”. It refers to the type of electrical power where the direction of the electric current reverses periodically. It is measured after the inverter and expressed in W.
- ∘
- DC Voltage: This is recorded by the battery management system (BMS) and reaches a maximum of 60 V when fully charged, decreasing to a minimum of 38 V during controlled discharge when in a discharged state.
- ∘
- DC: This stands for “Direct Current”, expressed in A.
- ∘
- State of charge (SoC): The SoC values were read out with the aid of the software and used to control the battery during charging or discharging. The validation of the open-circuit voltage used in the BMS is expressed as a %.
- ∘
- Temperature: This refers to the temperature of the container or the electrolytes, expressed in °C.
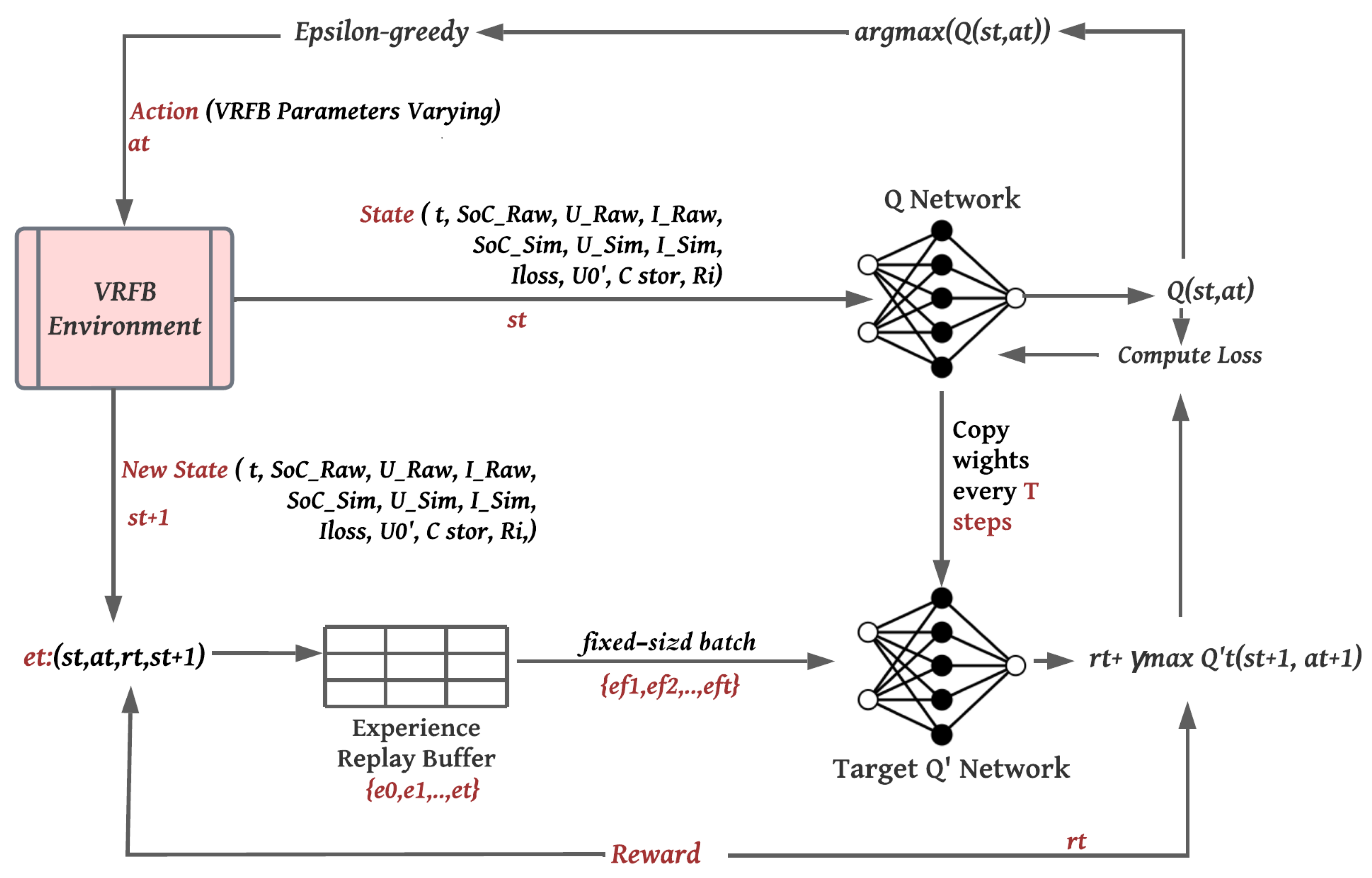
3. Learning VRFB Parameters Using Deep Reinforcement Learning
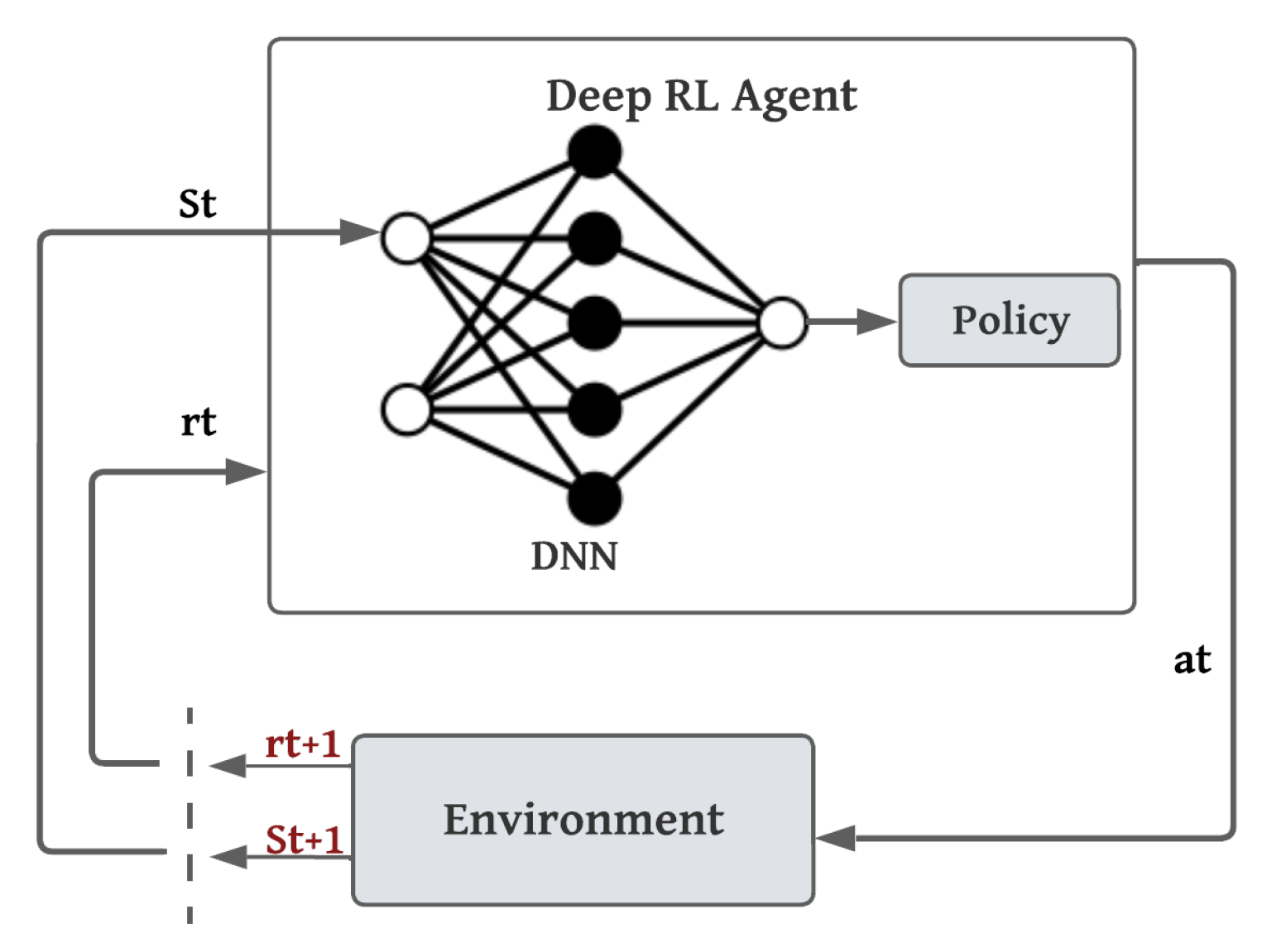
3.1. Advancing to Deep Reinforcement Learning (Deep RL)
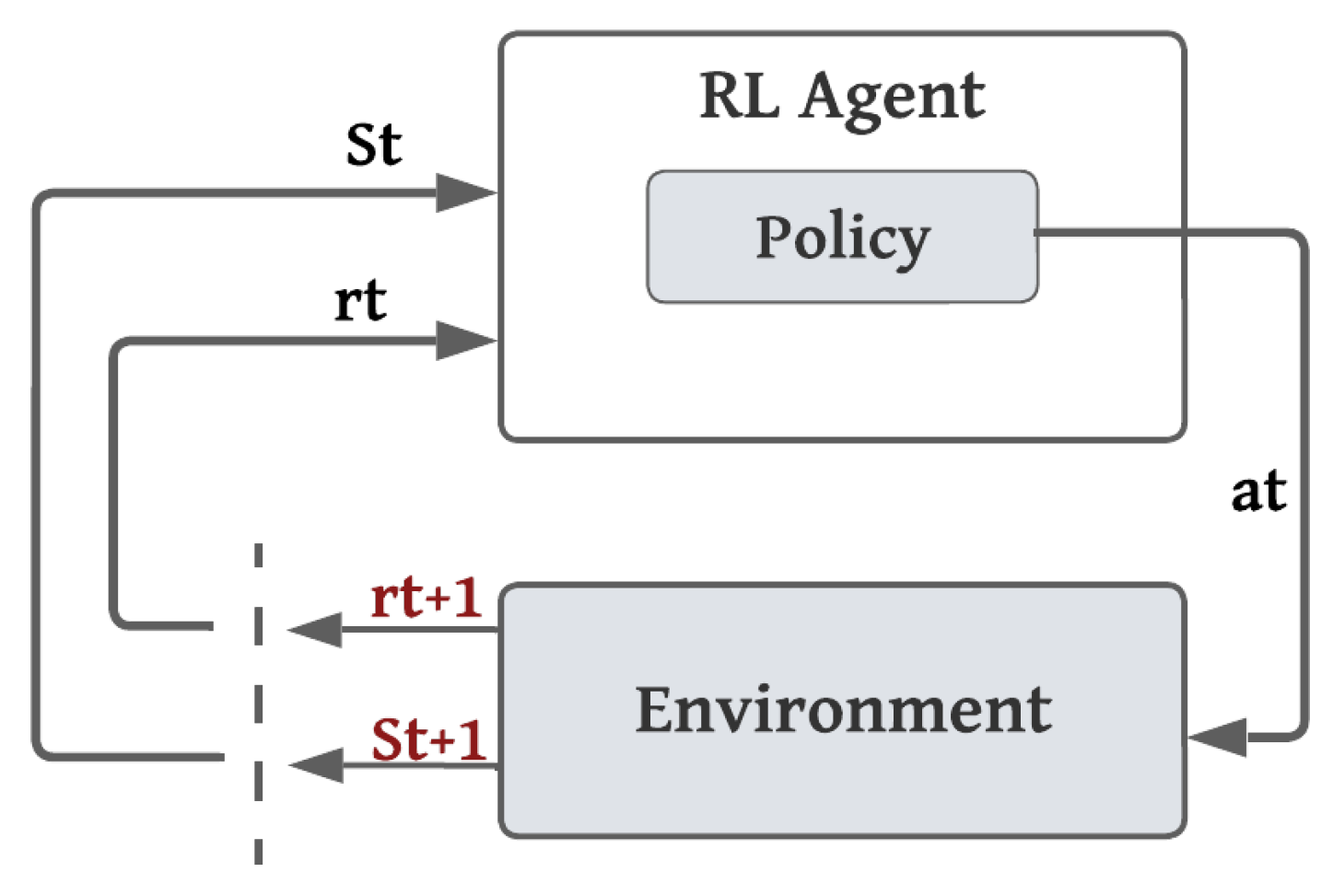
3.2. Markov Decision Process Formulation
- ∘
- Environment: As our focus is on the VRFB, we consider the VRFB as the environment for our RL system. It includes essential details about the battery, such as its internal parameters and the extracted and preprocessed raw dataset.
- ∘
- Agent: The agent uses the neural network to approximate the q-values through interactions with the VRFB environment.
- ∘
- State: The state s is a tensor that includes the raw data, the simulated data produced by resolving the mathematical system, and the battery-specific parameters.
- ∘
- Action Space: The action space reflects the adjustment and variation of the battery-specific parameters. Hence, our action space is a discrete space. In this context, we defined two different configurations of the action space. Initially, we outlined three possible actions, each involving adjusting the parameters: increasing , , , and ; decreasing them, or maintaining them. Subsequently, we expanded our action space to include nine distinct actions that refer to increasing, decreasing, or maintaining them separately. This method enabled us to determine which configuration produced better outcomes.
- ∘
- Reward function: The agent learns the optimal battery-specific parameters that can enhance the simulation model’s accuracy. Thus, we were inspired by and utilized the reward function in [36]. We defined the following straightforward reward function given by the equation to encourage faster convergence and facilitate the learning process for the DQN agent.
- ∘
- is a hyperparameter;
- ∘
- is the lowest error achieved so far during an episode;
- ∘
- includes the errors for the different battery state variables (, , and ) multiplied by the weights (, , and ) for each variable, as described in Equation (5).
3.3. Training Algorithm for Deep Q-Network
4. Results and Discussion
4.1. Training DQN Agent
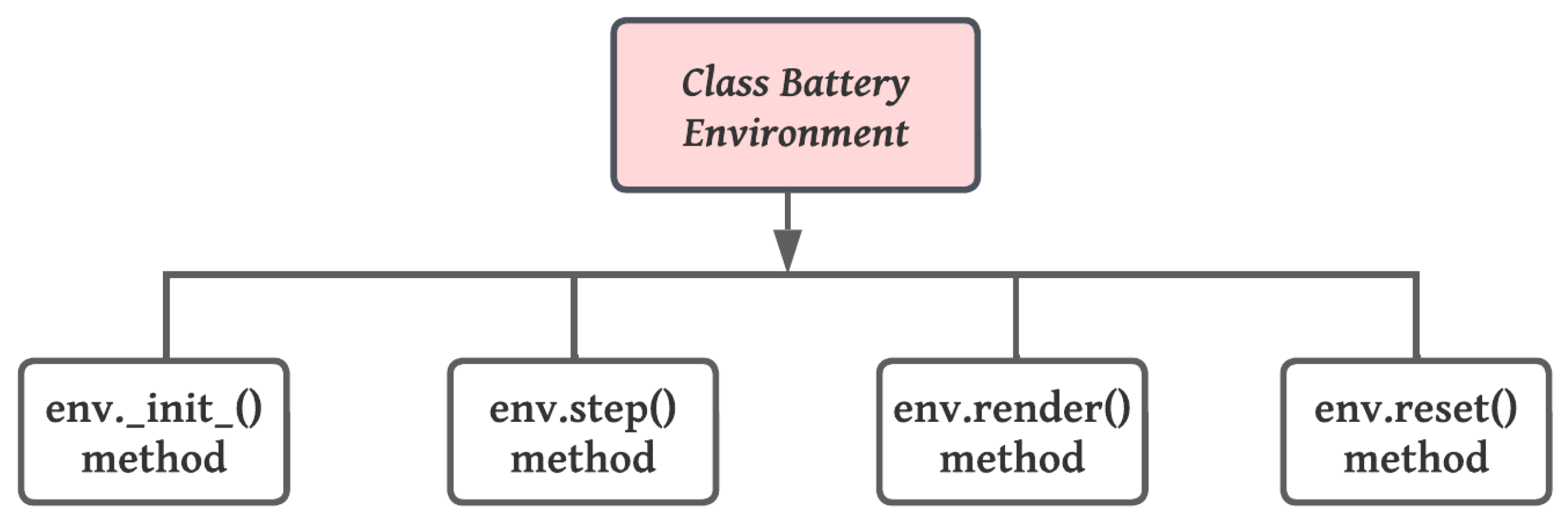
4.1.1. Definition of the Gym Environment
- ∘
- Initialization Method: The first method is the initialization method, where we create our environment class. We establish the action and state spaces and other initial battery parameter values within this function.
- ∘
- Step Method: This method is run every single time we take a step within our environment involving taking and applying an action to the environment. This method returns the next state/observation ; the actual determined reward ; a Boolean variable done, which refers to the end of the episode; and the set info, which contains some additional information. In our case, we used the variable info to store the battery-specific parameters , , , and .
- ∘
- Render method: This method is used to visualize the current state. We used this method to track and display the alignment between the simulated data and the raw data during the episode.
- ∘
- Reset method: Lastly, the reset method is where we reset the environment and obtain the initial observations.
4.1.2. DQN Parameters
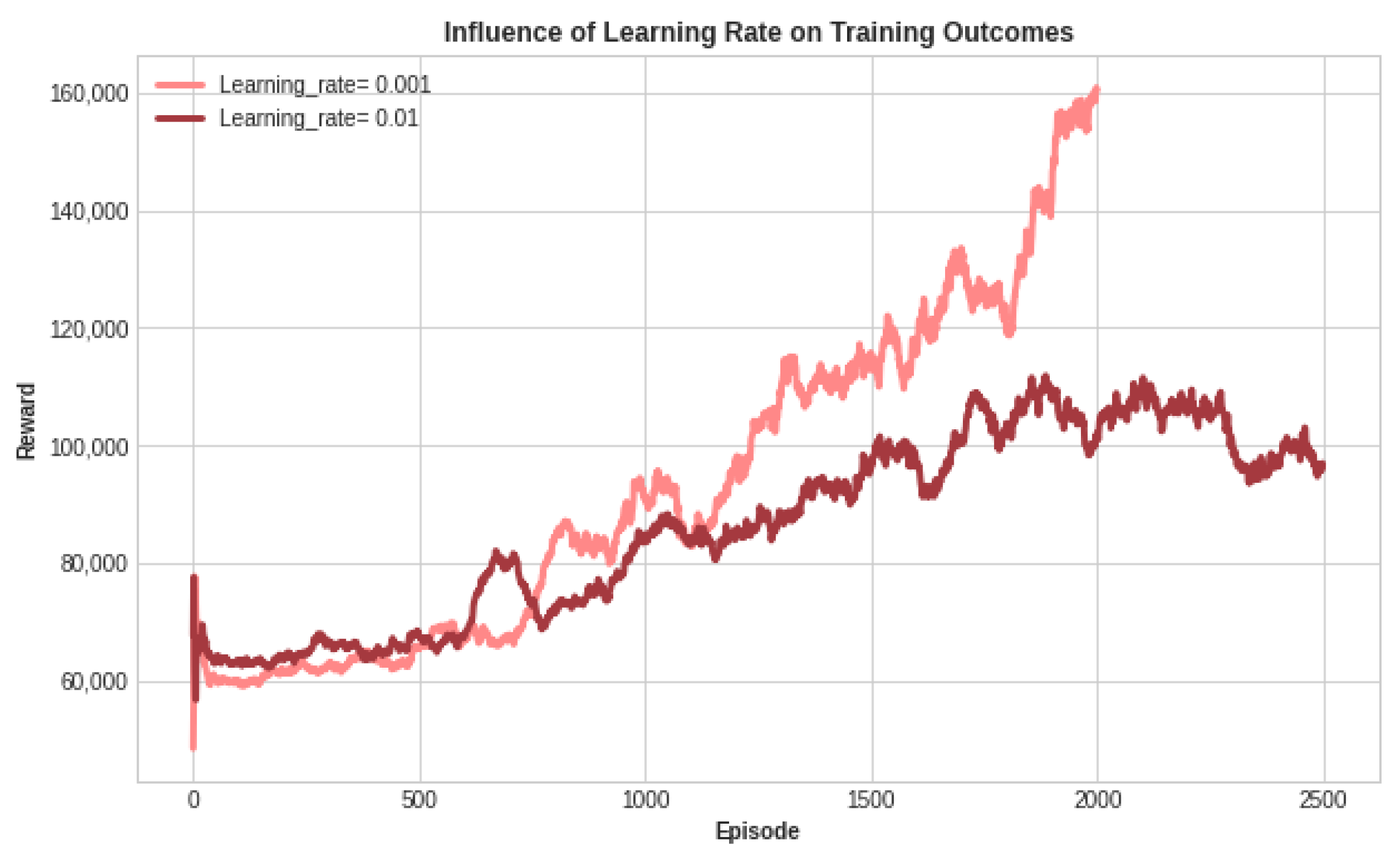
4.1.3. Training Results
- a.
- Optimizing the Learning Rate Selection for Training
- b.
- Choosing the Optimal Action Space
4.2. Evaluation of the DQN Agent
4.2.1. DQN Agent Testing Process
| Algorithm 1 General testing loop of our DQN agent |
| Reset the environment and get state for episode =1, M do do Reset the environment and get the initial state while True do Predict the action related to Execute a step s and get the next state , reward , done, and info Render the environment if done then Display optimal , , , and stored in the variable info end if end while end for |
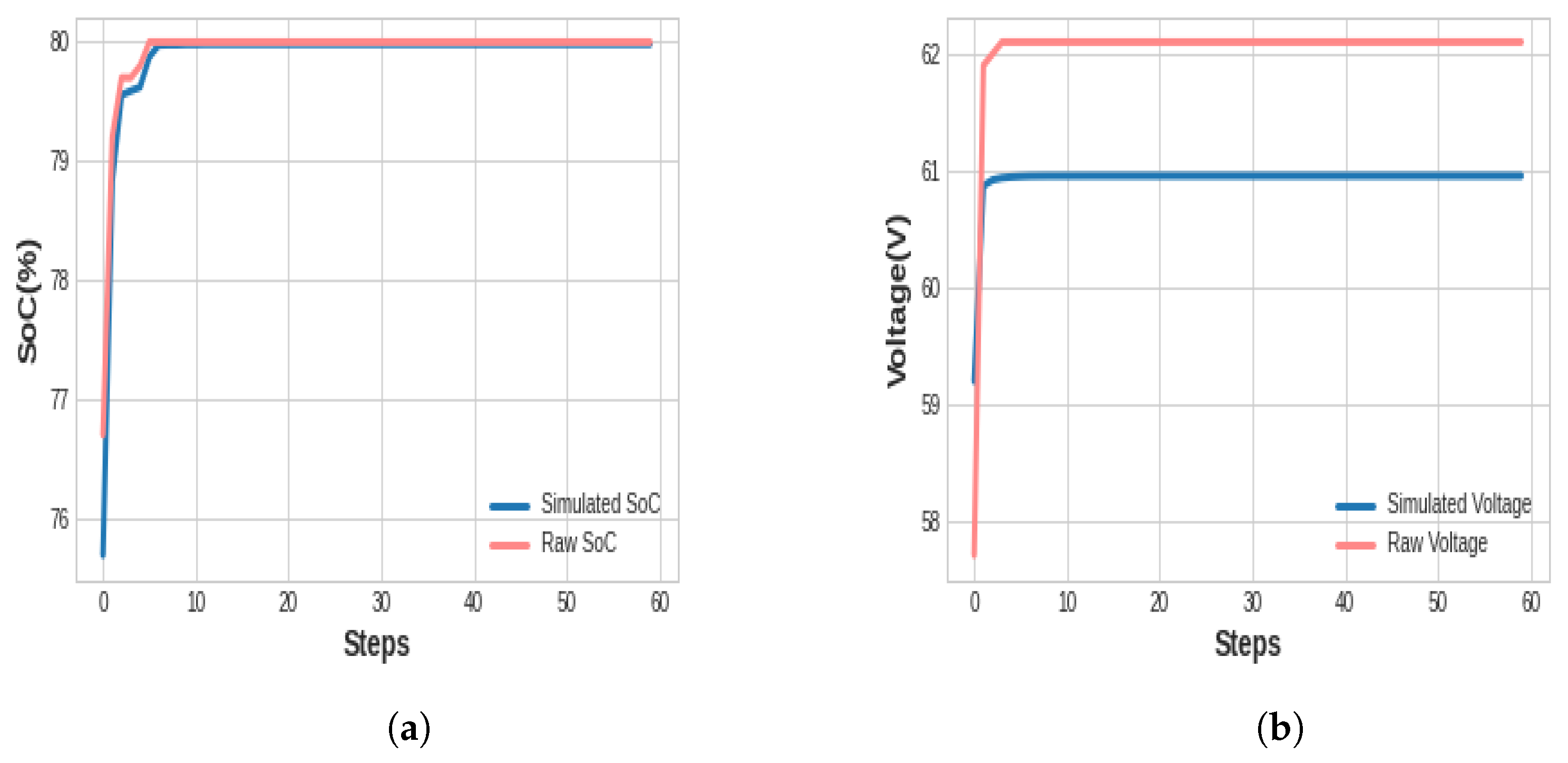
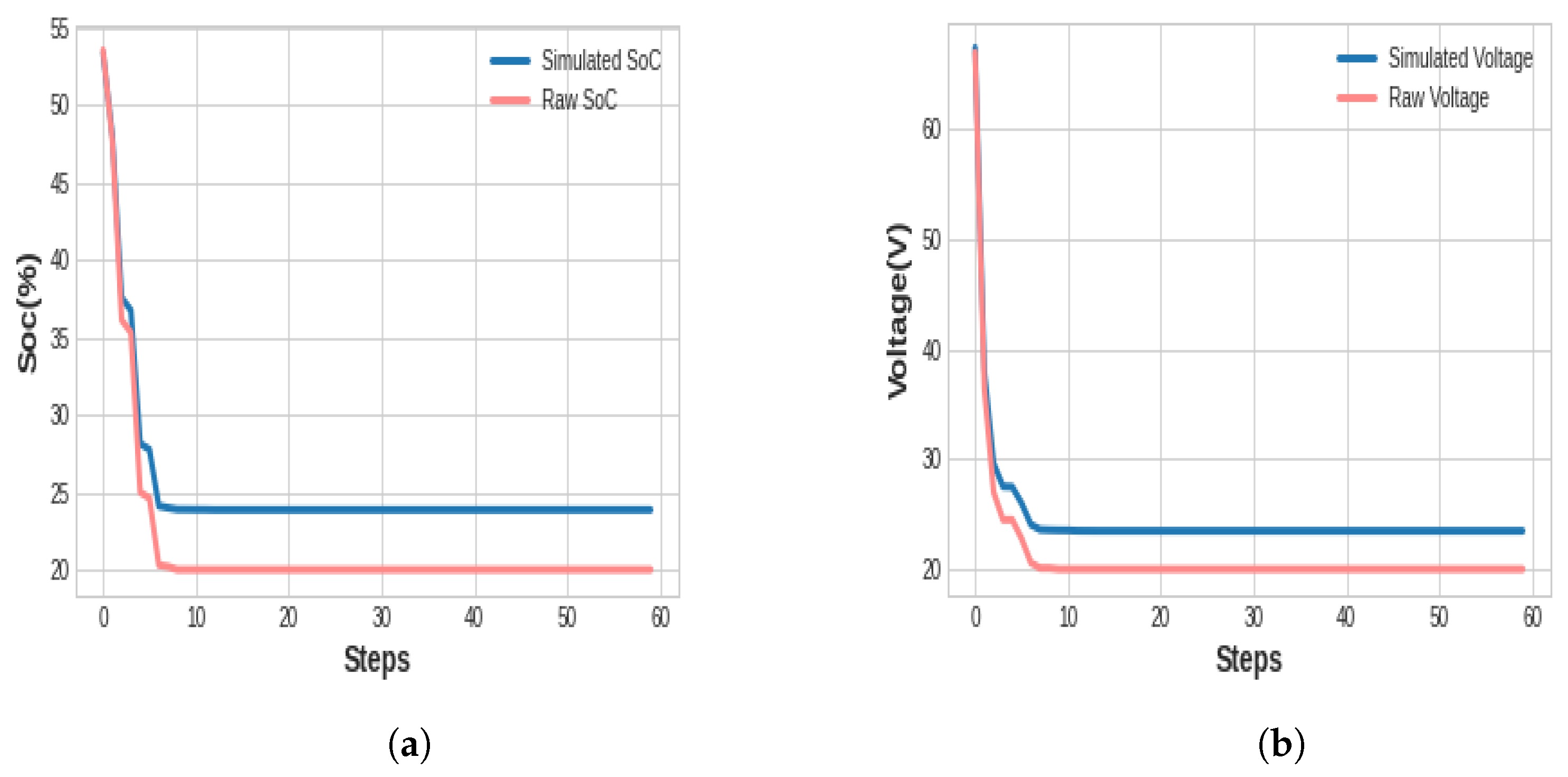
4.2.2. Testing Results and Evaluation
4.2.3. Discussion
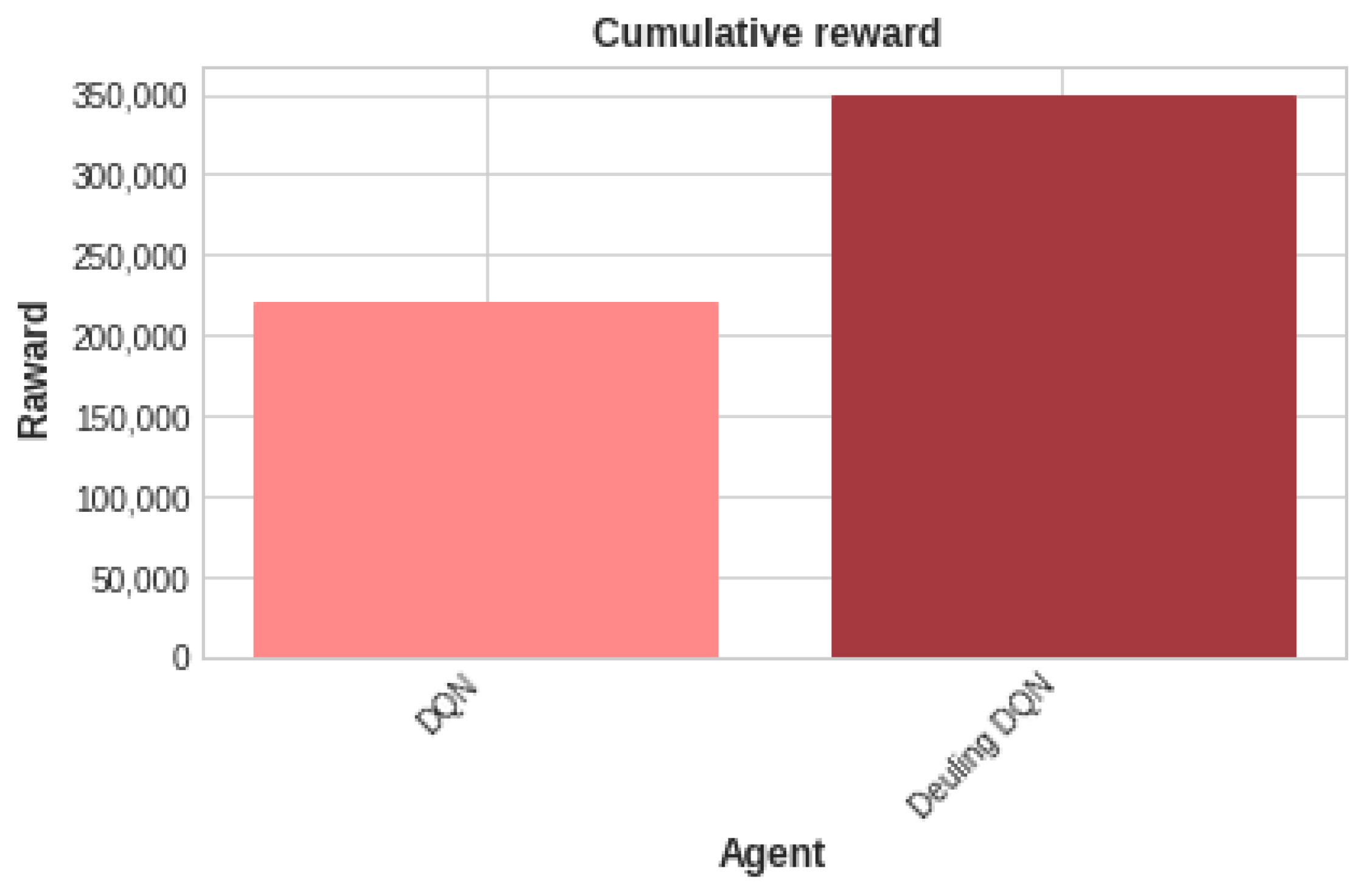
4.3. Enhancing the Performance of the DQN Agent
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Global Energy. Available online: https://www.iea.org/energy-system/transport/electric-vehicles (accessed on 15 July 2023).
- Sutikno, T.; Arsadiando, W.; Wangsupphaphol, A.; Yudhana, A.; Facta, M. A review of recent advances on hybrid energy storage system for solar photovoltaics power generation. IEEE Access 2022, 10, 42346–42364. [Google Scholar] [CrossRef]
- Ferret, R.; Sánchez-Díez, E.; Ventosa, E.; Guarnieri, M.; Trovò, A.; Flox, C.; Marcilla, R.; Soavi, F.; Mazur, P.; Aranzabe, E. Redox flow batteries: Status and perspective towards sustainable stationary energy storage. J. Power Sources 2021, 481, 228804. [Google Scholar]
- Skyllas-Kazacos, M. All-Vanadium Redox Battrey; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Rizzuti, A.; Carbone, A.; Dassisti, M.; Mastrorilli, P.; Cozzolino, G.; Chimienti, M.; Olabi, A.G.; Matera, F. Vanadium: A Transition Metal for Sustainable Energy Storing in Redox Flow Batteries; ELSEVIER: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Di Noto, V.; Sun, C.; Negro, E.; Vezzù, K.; Pagot, G.; Cavinato, G.; Nale, A.; Bang, Y.H. Hybrid Inorganic-Organic Proton-Conducting Membranes Based on SPEEK Doped with WO3 Nanoparticles for Application in Vanadium Redox Flow Batteries; Electrochimica Acta, ELSEVIER: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Neves, L.P.; Gonçalves, J.; Martins, A. Methodology for Real Impact Assessment of the Best Location of Distributed Electric Energy Storage; Sustainable Cities and Society; Elsevier: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Schubert, C.; Hassen, W.F.; Poisl, B.; Seitz, S.; Schubert, J.; Usabiaga, E.O.; Gaudo, P.M.; Pettinger, K.H. Hybrid Energy Storage Systems Based on Redox-Flow Batteries: Recent Developments, Challenges, and Future Perspectives. Batteries 2023, 9, 211. [Google Scholar] [CrossRef]
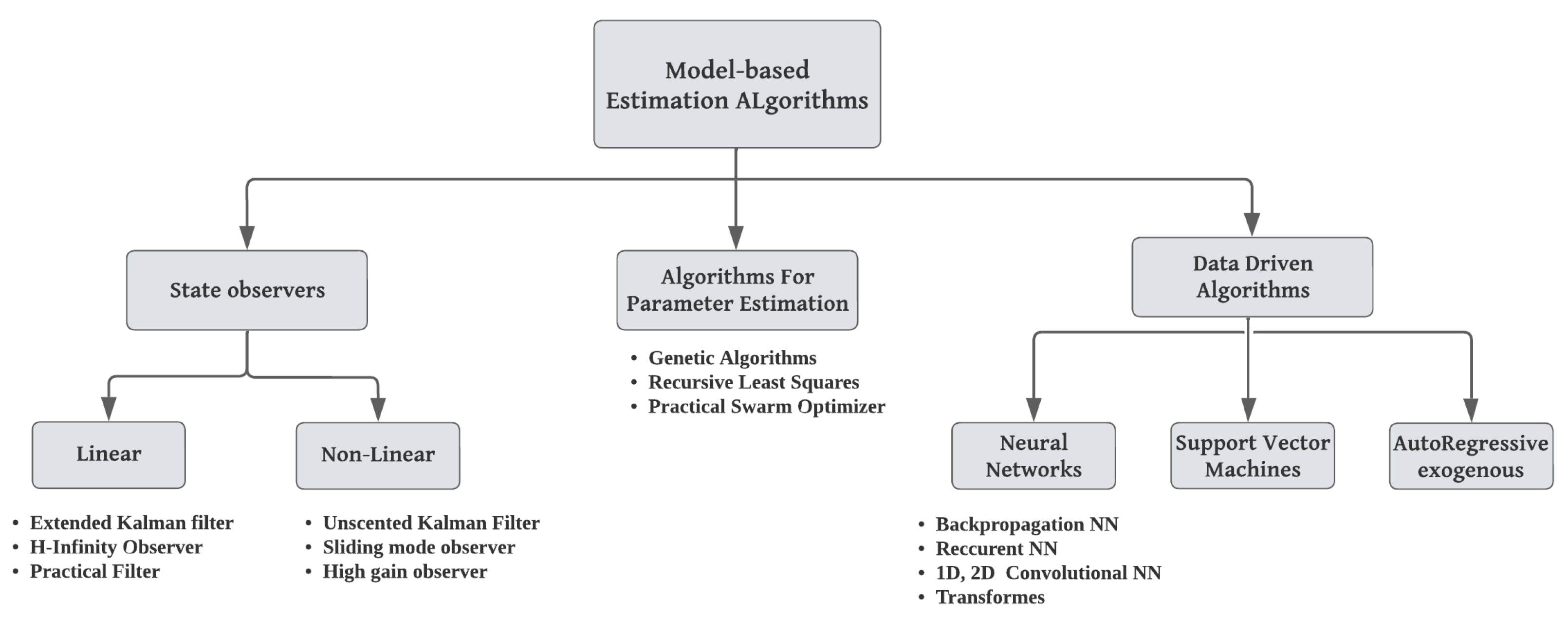
- Skyllas-Kazacos, M.; Xiong, B.; Zhao, J.; Wei, Z. Extended Kalman filter method for state of charge estimation of vanadium redox flow battery using thermal-dependent electrical model. J. Power Sources 2014, 262, 50–61. [Google Scholar]
- He, F.; Shen, W.X.; Kapoor, A.; Honnery, D.; Dayawansa, D. H infinity observer based state of charge estimation for battery packs in electric vehicles. In Proceedings of the 2016 IEEE 11th Conference on Industrial Electronics and Applications (ICIEA), Hefei, China, 5–7 June 2016. [Google Scholar]
- Hannan, M.A.; Lipu, M.H.; Hussain, A.; Mohamed, A. A review of lithium-ion battery state of charge estimation and management system in electric vehicle applications: Challenges and recommendations. Renew. Sustain. Energy Rev. 2017, 78, 834–854. [Google Scholar] [CrossRef]
- Costa-Castell’o, R.; Strahl, S.; Luna, J. Chattering free sliding mode observer estimation of liquid water fraction in proton exchange membrane fuel cells. J. Frankl. Inst. 2017, 357, 13816–13833. [Google Scholar]
- Clemente, A.; Cecilia, A.; Costa-Castelló, R. SOC and diffusion rate estimation in redox flow batteries: An I&I-based high-gain observer approach. In Proceedings of the 2021 European Control Conference (ECC), Rotterdam, The Netherlands, 29 June–2 July 2021. [Google Scholar]
- Battaiotto, P.; Fornaro, P.; Puleston, T.; Puleston, P.; Serra-Prat, M.; Costa-Castelló, R. Redox flow battery time-varying parameter estimation based on high-order sliding mode differentiators. Int. J. Energy Res. 2022, 46, 16576–16592. [Google Scholar]
- Clemente, A.; Montiel, M.; Barreras, F.; Lozano, A.; Costa-Castello, R. Vanadium redox flow battery state of charge estimation using a concentration model and a sliding mode observer. IEEE Access 2021, 9, 72368–72376. [Google Scholar] [CrossRef]
- Choi, Y.Y.; Kim, S.; Kim, S.; Choi, J.I. Multiple parameter identification using genetic algorithm in vanadium redox flow batteries. J. Power Sources 2020, 45, 227684. [Google Scholar] [CrossRef]
- Wan, S.; Liang, X.; Jiang, H.; Sun, J.; Djilali, N.; Zhao, T. A coupled machine learning and genetic algorithm approach to the design of porous electrodes for redox flow batteries. Appl. Energy 2021, 298, 117177. [Google Scholar] [CrossRef]
- Niu, H.; Huang, J.; Wang, C.; Zhao, X.; Zhang, Z.; Wang, W. State of charge prediction study of vanadium redox-flow battery with BP neural network. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 1289–1293. [Google Scholar]
- Cao, H.; Zhu, X.; Shen, H.; Shao, M. A neural network based method for real-time measurement of capacity and SOC of vanadium redox flow battery. In Proceedings of the International Conference on Fuel Cell Science, Engineering and Technology, American Society of Mechanical Engineers, San Diego, CA, USA, 28 June–2 July 2015; Volume 56611, p. V001T02A001. [Google Scholar]
- Heinrich, F.; Klapper, P.; Pruckner, M. A comprehensive study on battery electric modeling approaches based on machine learning. J. Power Sources 2021, 4, 17. [Google Scholar] [CrossRef]
- Iu, H.; Fernando, T.; Li, R.; Xiong, B.; Zhang, S.; Zhang, X.; Li, Y. A novel one dimensional convolutional neural network based data-driven vanadium redox flow battery modelling algorithm. J. Energy Storage 2023, 61, 106767. [Google Scholar]
- Iu, H.; Fernando, T.; Li, R.; Xiong, B.; Zhang, S.; Zhang, X.; Li, Y. A Novel U-Net based Data-driven Vanadium Redox Flow Battery Modelling Approach. Electrochim. Acta 2023, 444, 141998. [Google Scholar]
- Hannan, M.A.; How, D.N.; Lipu, M.H.; Mansor, M.; Ker, P.J.; Dong, Z.; Sahari, K.; Tiong, S.K.; Muttaqi, K.M.; Mahlia, T.I.; et al. Deep learning approach towards accurate state of charge estimation for lithium-ion batteries using self-supervised transformer model. Sci. Rep. 2021, 11, 19541. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Li, T.; Li, X. Machine learning for flow batteries: Opportunities and challenges. Chem. Sci. 2022, 17, 4740–4752. [Google Scholar]
- Wei, Z.; Xiong, R.; Lim, T.M.; Meng, S.; Skyllas-Kazacos, M. Online monitoring of state of charge and capacity loss for vanadium redox flow battery based on autoregressive exogenous modeling. J. Power Sources 2018, 402, 252–262. [Google Scholar] [CrossRef]
- Zugschwert, C.; Dundálek, J.; Leyer, S.; Hadji-Minaglou, J.R.; Kosek, J.; Pettinger, K.H. The Effect of input parameter variation on the accuracy of a Vanadium Redox Flow Battery Simulation Model. Batteries 2021, 7, 7. [Google Scholar] [CrossRef]
- Weber, R.; Schubert, C.; Poisl, B.; Pettinger, K.H. Analyzing Experimental Design and Input Data Variation of a Vanadium Redox Flow Battery Model. Batteries 2023, 9, 122. [Google Scholar] [CrossRef]
- He, Q.; Fu, Y.; Stinis, P.; Tartakovsky, A. Enhanced physics-constrained deep neural networks for modeling vanadium redox flow battery. J. Power Sources 2022, 542, 231807. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Plaat, A. Deep Reinforcement Learning; Springer Nature Singapore Pte Ltd.: Singapore, 2022. [Google Scholar]
- König, S. Model-Based Design and Optimization of Vanadium Redox Flow Batteries; Karlsruher Instituts für Technologie: Karlsruhe, Germany, 2017. [Google Scholar]
- Haisch, T.; Ji, H.; Weidlichm, C. Monitoring the state of charge of all-vanadium redox flow batteries to identify crossover of electrolyte. Electrochim. Acta 2020, 336, 135573. [Google Scholar] [CrossRef]
- Loktionov, P.; Konev, D.; Pichugov, R.; Petrov, M.; Antipov, A. Calibration-free coulometric sensors for operando electrolytes imbalance monitoring of vanadium redox flow battery. J. Power Sources 2023, 553, 232242. [Google Scholar] [CrossRef]
- Shin, K.H.; Jin, C.S.; So, J.Y.; Park, S.K.; Kim, D.H.; Yeon, S.H. Real-time monitoring of the state of charge (SOC) in vanadium redox-flow batteries using UV–Vis spectroscopy in operando mode. J. Energy Storage 2020, 27, 101066. [Google Scholar] [CrossRef]
- Cellstrom GmbH. Available online: https://unternehmen.fandom.com/de/wiki/Cellstrom_GmbH (accessed on 15 June 2023).
- Subramanian, S.; Ganapathiraman, V.; El Gamal, A. Learned Learning Rate Schedules for Deep Neural Network Training Using Reinforcement Learning; Amazon Science, ICLR: Los Angeles, CA, USA, 2023. [Google Scholar]
- Gym Library. Available online: https://www.gymlibrary.dev/content/basic_usage/ (accessed on 5 May 2023).
- DQN Improvement. Available online: https://dl.acm.org/doi/fullHtml/10.1145/3508546.3508598#:~:text=In%20a%20discrete%20or%20continuous,k%7D%2C%20k%20%E2%88%88%20R (accessed on 22 April 2023).
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1995–2003. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial Value | |
|---|---|
| SoC (%) | Charge: 20, Discharge: 80 |
| (As) | 870,000 |
| (A) | 10.0 |
| (V) | 1.375 |
| (m) | 0.75 |
| No. of stacks | 10 |
| Nominal Voltage (V) | 48 |
| Temperature (°C) | 21.85 |
| No. of Cells | 40 |
| Parameter | Definition | Value |
|---|---|---|
| num_layers | Number of hidden layers used | 2 |
| num_units | Number of units used to enhance the quality of training and prediction | 256.2 |
| Activation Function | The non-linear activation function used for the NN | ReLU |
| Replace | The frequency with which the target network is updated | 1000 |
| Epsilon | Level of probability randomness for each iteration | 1.0 |
| eps_min | The ending value of Epsilon | 0.1 |
| Decay_rate | Reducing the Epsilon at each iteration | 1 × |
| Gamma | Discount factor | 0.99 |
| Batch_size | Number of transitions sampled from the replay buffer | 64 |
| Learning_rate | The learning rate of the Adam optimizer | 0.001 |
| Evaluation Power | Ri (m) | U (V) | I (A) | C (Ah) |
|---|---|---|---|---|
| 2.5 kW | 0.29 | 1.075 | 9.7 | 2415.83 |
| 5 kW | 0.3 | 1.375 | 10.035 | 2416 |
| 7.5 kW | 0.305 | 1.675 | 10.3 | 2417.5 |
| 10 kW | 0.30 | 1.45 | 10.075 | 2416.88 |
| Evaluation Power | VRFB State Variables | RMSE | MAE |
|---|---|---|---|
| State of charge SoC (%) | 0.1114 | 0.029 | |
| 2.5 kW | Voltage U (V) | 1.923 | 1.8369 |
| Current I (A) | 0.312 | 0.1028 | |
| State of charge SoC (%) | 0.2407 | 0.0723 | |
| 5 kW | Voltage U (V) | 1.8311 | 1.7832 |
| Current I (A) | 0.2231 | 0.1031 | |
| State of charge SoC (%) | 0.8394 | 0.244 | |
| 7.5 kW | Voltage U (V) | 1.4741 | 1.468 |
| Current I (A) | 0.3741 | 0.068 | |
| State of charge SoC (%) | 0.5573 | 0.1498 | |
| 10 kW | Voltage U (V) | 1.114 | 1.1204 |
| Current I (A) | 0.113 | 0.0139 |
| Approach | Evaluation Power | WLSS (%) |
|---|---|---|
| Model [26] | 2.5 KW | 187.58 |
| 5 KW | 100.14 | |
| 7.5 KW | 7.9 | |
| 10 KW | 120.51 | |
| DQN Agent | 2.5 KW | 170.42 |
| 5 KW | 87.51 | |
| 7.5 KW | 6.07 | |
| 10 KW | 90.41 |
| Metric | DQN | Dueling DQN |
|---|---|---|
| RMSE [V] | 1.114 | 1.1081 |
| MAE [V] | 1.1204 | 1.0914 |
| Metric | DQN | Deuling DQN |
|---|---|---|
| RMSE [%] | 0.5573 | 0.456 |
| MAE [%] | 0.1498 | 0.0932 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ben Ahmed, M.; Fekih Hassen, W. Optimization of a Redox-Flow Battery Simulation Model Based on a Deep Reinforcement Learning Approach. Batteries 2024, 10, 8. https://doi.org/10.3390/batteries10010008
Ben Ahmed M, Fekih Hassen W. Optimization of a Redox-Flow Battery Simulation Model Based on a Deep Reinforcement Learning Approach. Batteries. 2024; 10(1):8. https://doi.org/10.3390/batteries10010008
Chicago/Turabian StyleBen Ahmed, Mariem, and Wiem Fekih Hassen. 2024. "Optimization of a Redox-Flow Battery Simulation Model Based on a Deep Reinforcement Learning Approach" Batteries 10, no. 1: 8. https://doi.org/10.3390/batteries10010008
APA StyleBen Ahmed, M., & Fekih Hassen, W. (2024). Optimization of a Redox-Flow Battery Simulation Model Based on a Deep Reinforcement Learning Approach. Batteries, 10(1), 8. https://doi.org/10.3390/batteries10010008