

IMVTS: A Detection Model for Multi-Varieties of Famous Tea Sprouts Based on Deep Learning

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Data Collection and Preparation
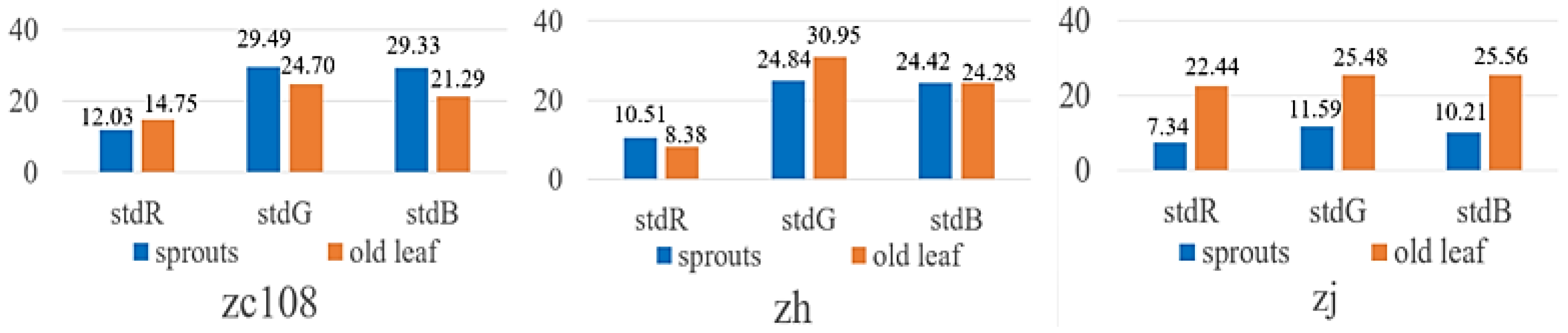
2.1.1. Fresh Tea Leaf Image Collection and MVT Dataset Production
2.1.2. MVT Dataset Division
2.2. Establishment and Training of the IMVTS Model
2.2.1. Experimental Platform and Environmental Configuration
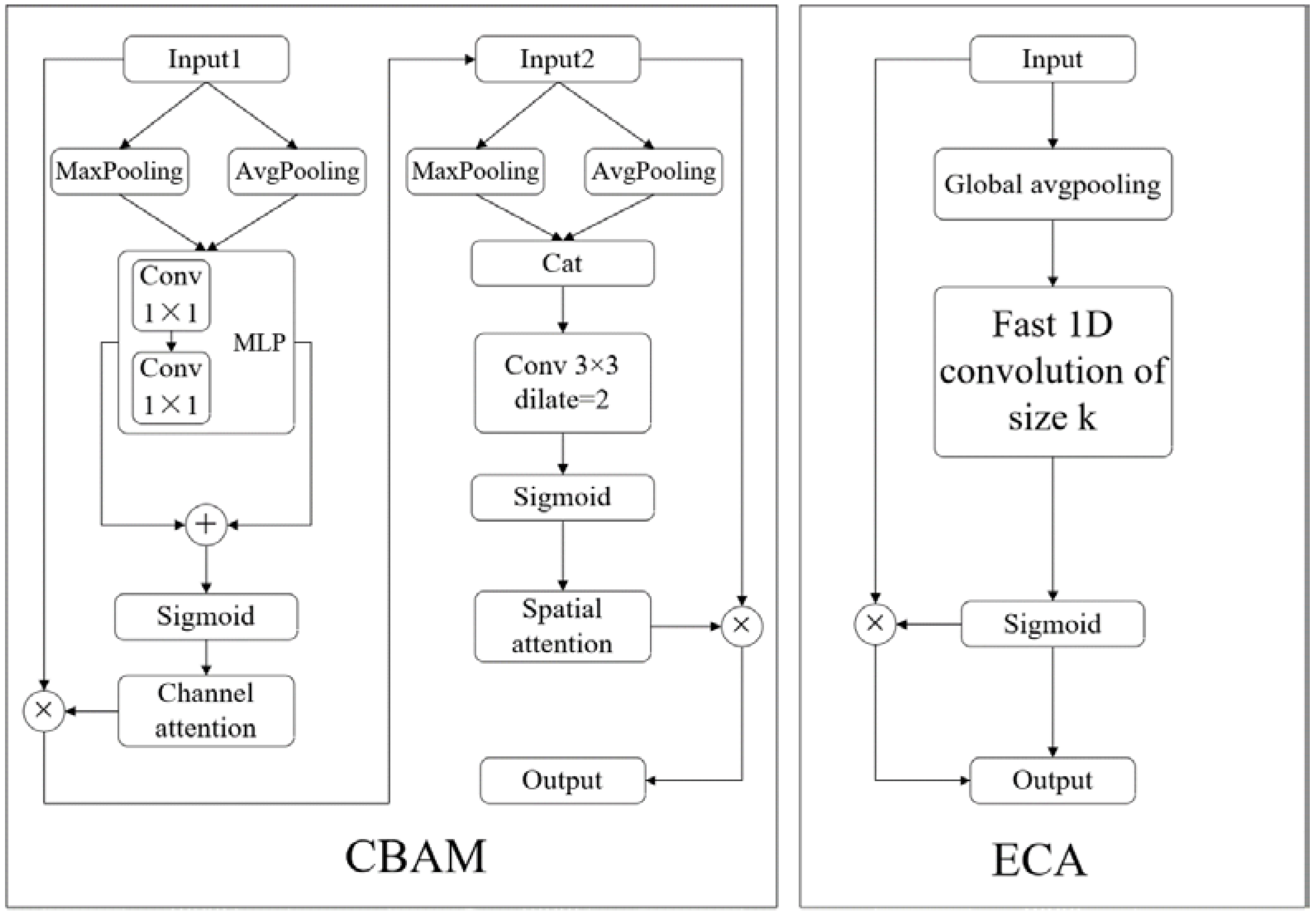
2.2.2. Establishment of the IMVTS Model
2.2.3. Training Parameter Settings
2.2.4. Model Evaluation Index
3. Results and Discussion
3.1. Model Identification Results and Comparative Analysis
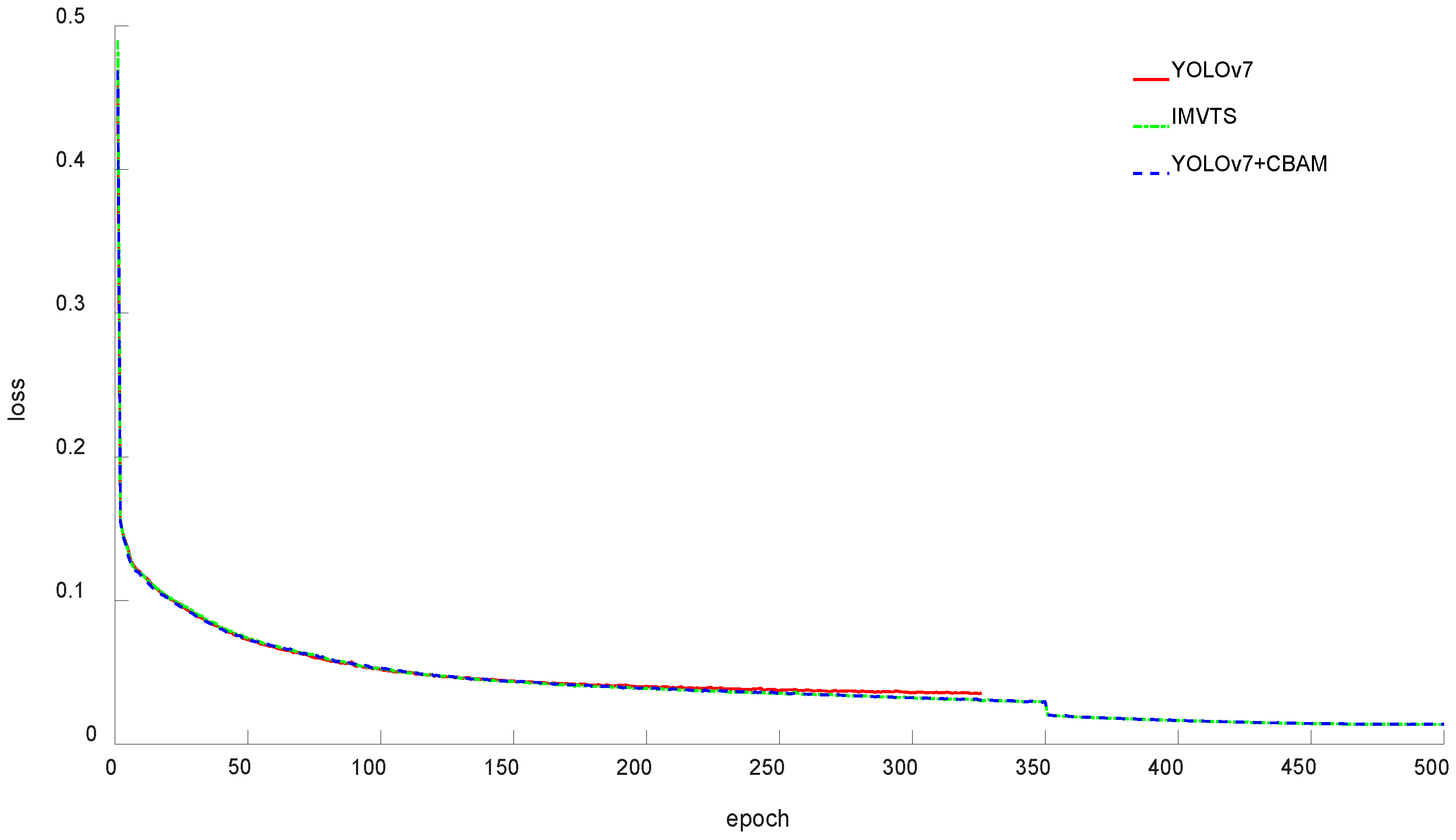
3.1.1. Comparison of YOLO v7 Model, YOLO v7+CBAM Model, and IMVTS Model Recognition Results
3.1.2. Comparison of IMVTS Model with Mainstream Target Detection Models
3.1.3. Results and Analysis of Ablation Test
3.1.4. IMVTS Model for VOC Dataset Detection Test
3.2. Comparison of Model Recognition Effects on the MVT Dataset
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Z. Design and Experiment of Intelligent Picking Robot for Famous Tea. Ph.D. Thesis, Shenyang University of Technology, Shenyang, China, 2020. [Google Scholar]
- Zhou, Y.; Wu, Q.; He, L.; Zhao, R.; Jia, J.; Chen, J.; Wu, C. Design and experiment of intelligent picking robot for famous tea. J. Mech. Eng. 2022, 58, 12–23. [Google Scholar]
- Zhang, L.; Zou, L.; Wu, C.; Jia, J.; Chen, J. Method of famous tea sprout identification and segmentation based on improved watershed algorithm. Comput. Electron. Agric. 2021, 184, 106108. [Google Scholar] [CrossRef]
- Zhang, L.; Zhan, H.; Chen, Y.; Dai, S.; Li, X.; Kenji, I.; Liu, Z.; Li, M. Real-time monitoring of optimum timing for harvesting fresh tea leaves based on machine vision. Int. J. Agric. Biol. Eng. 2019, 12, 6–9. [Google Scholar] [CrossRef]
- Yan, L.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Washington, DC, USA, 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 4 June 2015; IEEE: Washington, DC, USA, 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, CA, USA, 8 June 2015; IEEE: Washington, DC, USA, 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.-C. SSD: Single Shot Multibox Detector. European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Li, Y.; He, L.; Jia, J.; Lv, J.; Chen, J.; Qiao, X.; Wu, C. In-field tea shoot detection and 3D localization using an RGB-D camera. Comput. Electron. Agric. 2021, 185, 106149. [Google Scholar] [CrossRef]
- Xu, W.; Zhao, L.; Li, J.; Shang, S.; Ding, X.; Wang, T. Detection and classification of tea buds based on deep learning. Comput. Electron. Agric. 2022, 192, 106547. [Google Scholar] [CrossRef]
- Chen, Y.-T.; Chen, S.-F. Localizing plucking points of tea leaves using deep convolutional neural networks. Comput. Electron. Agric. 2020, 171, 105298. [Google Scholar] [CrossRef]
- Liu, Y.; Cao, X.; Guo, B.; Chen, H.J.; Dai, Z.; Gong, C. Research on detection algorithm about the posture of meat goose in complex scene based on improved YOLO v5. J. Nanjing Agric. Univ. 2022, 32, 1544–1548. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Vaswani, A.; Shazier, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhinl, I. Attention is all you need. In Proceedings of the NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Washington, DC, USA, 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2022; IEEE: Washington, DC, USA, 2022; pp. 11531–11539. [Google Scholar]
- Qi, L.; Gao, J. Small Object Detection Based on Improved YOLOv7. Comput. Eng. 2022, 1000–3428. [Google Scholar] [CrossRef]
- Yu, L.; Huang, C.; Tang, J.; Huang, H.; Zhou, Y.; Huang, Y.; Sun, J. Tea Bud Recognition Method Based on Improved YOLOX Model. Guangdong Agric. Sci. 2022, 49, 49–56. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P (%) | R (%) | F1-Score | mAP (%) |
|---|---|---|---|---|
| YOLO v7 | 99.52 | 94.57 | 0.97 | 97.46 |
| YOLO v7+CBAM | 99.66 | 96.93 | 0.98 | 98.80 |
| IMVTS | 99.76 | 97.03 | 0.98 | 98.82 |
| Model | P (%) | R (%) | F1-Score | mAP (%) |
|---|---|---|---|---|
| IMVTS | 99.76 | 97.03 | 0.98 | 98.82 |
| YOLO v3 | 97.38 | 90.01 | 0.92 | 93.94 |
| YOLO v5 | 97.97 | 90.72 | 0.94 | 94.45 |
| FASTER-RCNN | 96.84 | 70.19 | 0.89 | 89.28 |
| SSD | 99.32 | 58.22 | 0.72 | 85.92 |
| Model | Backbone | Model Size | Attention | mAP (%) |
|---|---|---|---|---|
| ECA | 98.82 | |||
| YOLO v7 | CBAM | 98.80 | ||
| NONE | 97.46 | |||
| YOLO v7 | ECA | 97.86 | ||
| YOLO v7_x | CBAM | 97.73 | ||
| NONE | 96.58 | |||
| ECA | 94.26 | |||
| YOLO v3 | CBAM | 94.20 | ||
| NONE | 93.94 | |||
| ECA | 96.03 | |||
| YOLO v5_l | CBAM | 95.66 | ||
| NONE | 94.45 | |||
| Cspdarknet | ECA | 95.83 | ||
| YOLO v5_x | CBAM | 95.72 | ||
| NONE | 94.51 | |||
| YOLO v5 | ECA | 94.28 | ||
| YOLO v5_l | CBAM | 94.23 | ||
| NONE | 94.05 | |||
| Convnext_tiny | ECA | 94.41 | ||
| YOLO v5_x | CBAM | 94.30 | ||
| NONE | 94.12 | |||
| ECA | 90.24 | |||
| Resnet50 | CBAM | 89.76 | ||
| NONE | 89.28 | |||
| FASTER-RCNN | ECA | 87.77 | ||
| Vgg | CBAM | 87.59 | ||
| NONE | 86.33 | |||
| ECA | 88.06 | |||
| Vgg | CBAM | 87.24 | ||
| NONE | 85.92 | |||
| SSD | ECA | 85.42 | ||
| Mobilenetv2 | CBAM | 84.11 | ||
| NONE | 83.31 |
| Model | P (%) | R (%) | F1-Score | mAP (%) |
|---|---|---|---|---|
| IMVTS | 87.79 | 72.20 | 0.79 | 83.85 |
| YOLO v7 | 87.60 | 62.08 | 0.72 | 77.90 |
| Model | ZC108 (AP%) | ZH (AP%) | ZJ (AP%) |
|---|---|---|---|
| YOLO v7 | 99.79 | 93.30 | 99.30 |
| YOLO v7+CBAM | 99.87 | 96.89 | 99.64 |
| IMVTS | 99.87 | 96.97 | 99.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, R.; Liao, C.; Yu, T.; Chen, J.; Li, Y.; Lin, G.; Huan, X.; Wang, Z. IMVTS: A Detection Model for Multi-Varieties of Famous Tea Sprouts Based on Deep Learning. Horticulturae 2023, 9, 819. https://doi.org/10.3390/horticulturae9070819
Zhao R, Liao C, Yu T, Chen J, Li Y, Lin G, Huan X, Wang Z. IMVTS: A Detection Model for Multi-Varieties of Famous Tea Sprouts Based on Deep Learning. Horticulturae. 2023; 9(7):819. https://doi.org/10.3390/horticulturae9070819
Chicago/Turabian StyleZhao, Runmao, Cong Liao, Taojie Yu, Jianneng Chen, Yatao Li, Guichao Lin, Xiaolong Huan, and Zhiming Wang. 2023. "IMVTS: A Detection Model for Multi-Varieties of Famous Tea Sprouts Based on Deep Learning" Horticulturae 9, no. 7: 819. https://doi.org/10.3390/horticulturae9070819
APA StyleZhao, R., Liao, C., Yu, T., Chen, J., Li, Y., Lin, G., Huan, X., & Wang, Z. (2023). IMVTS: A Detection Model for Multi-Varieties of Famous Tea Sprouts Based on Deep Learning. Horticulturae, 9(7), 819. https://doi.org/10.3390/horticulturae9070819