

Quality Grading Algorithm of Oudemansiella raphanipes Based on Transfer Learning and MobileNetV2

Abstract
1. Introduction
2. Materials and Methods
2.1. Datasets
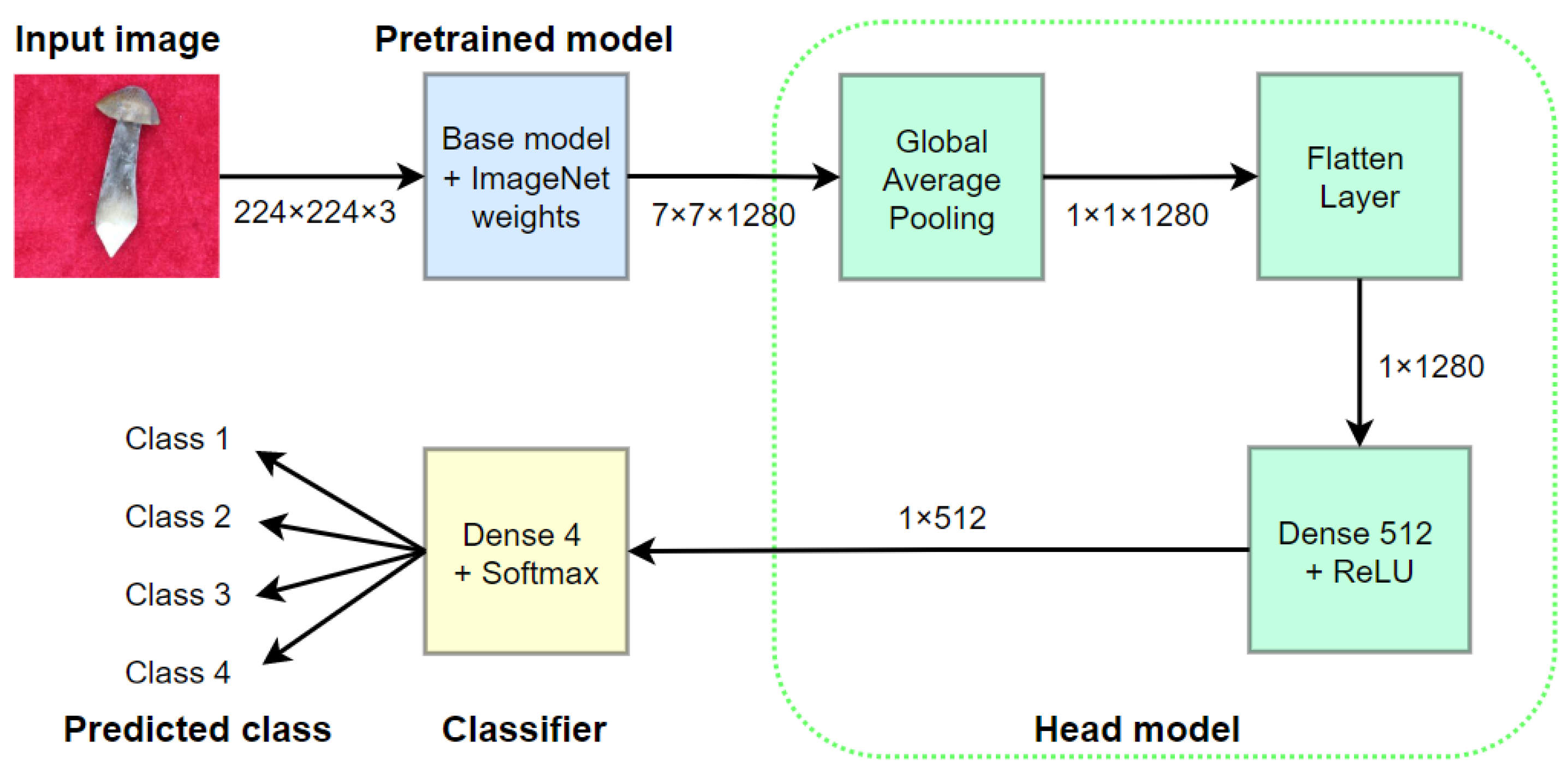
2.2. Transfer Leaning
2.3. Computing Resources
3. Results
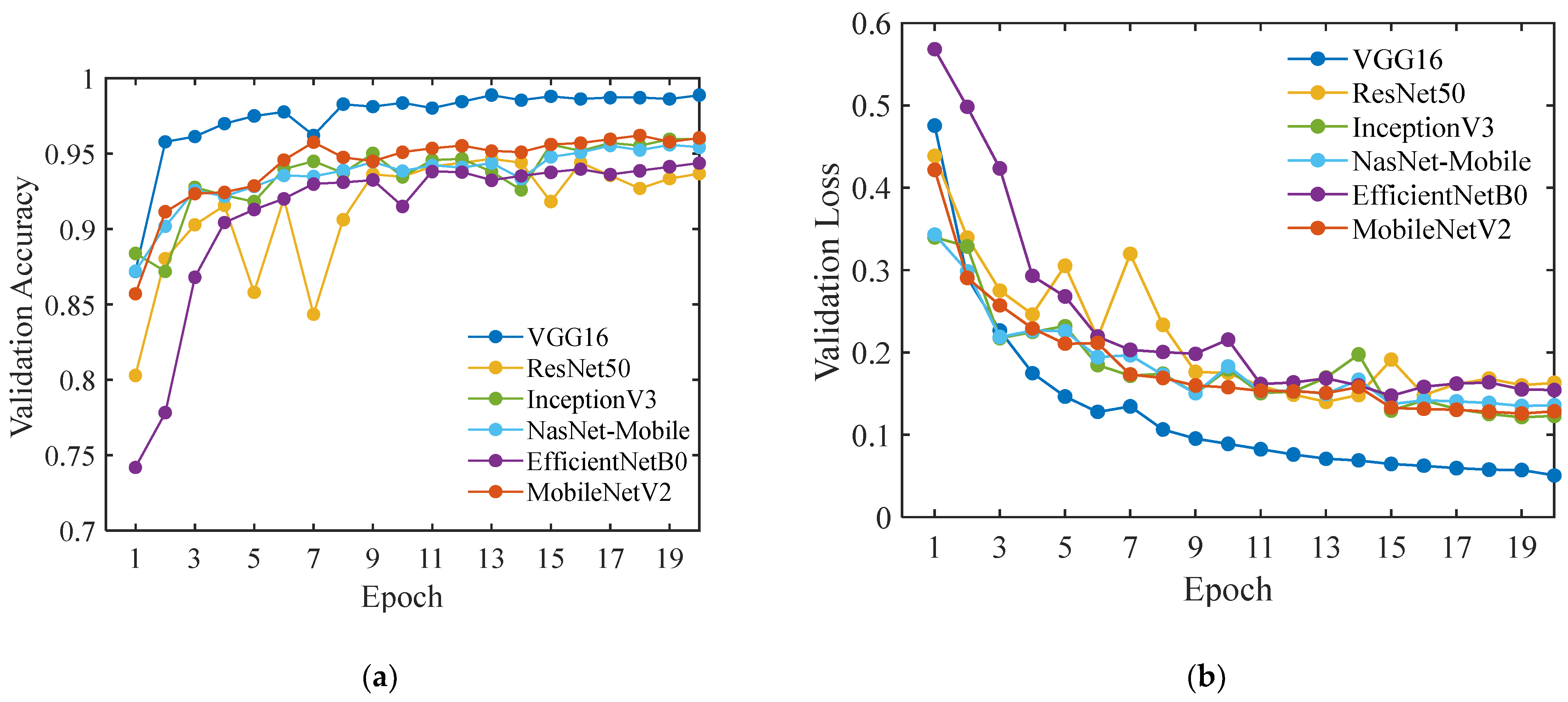
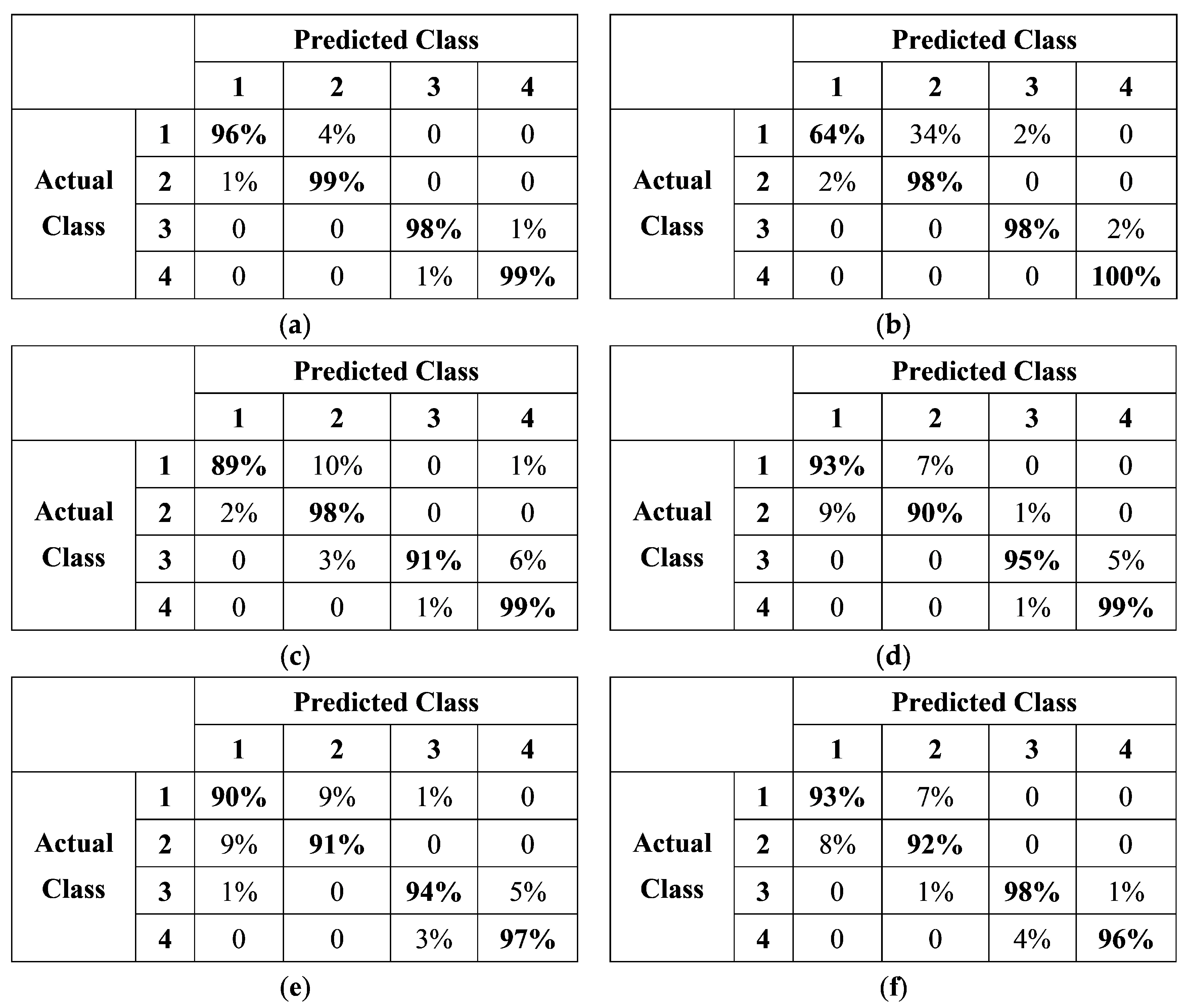
3.1. Comparison of MobileNetV2 with other Five Typical CNN Models
3.2. Optimizations of MobileNetV2
3.2.1. Optimization 1: Data Augmentation
3.2.2. Optimization 2: Hyperparameter Selecting
- Optimizer
- Learning Rate
- Batch Size
- Number of Epochs
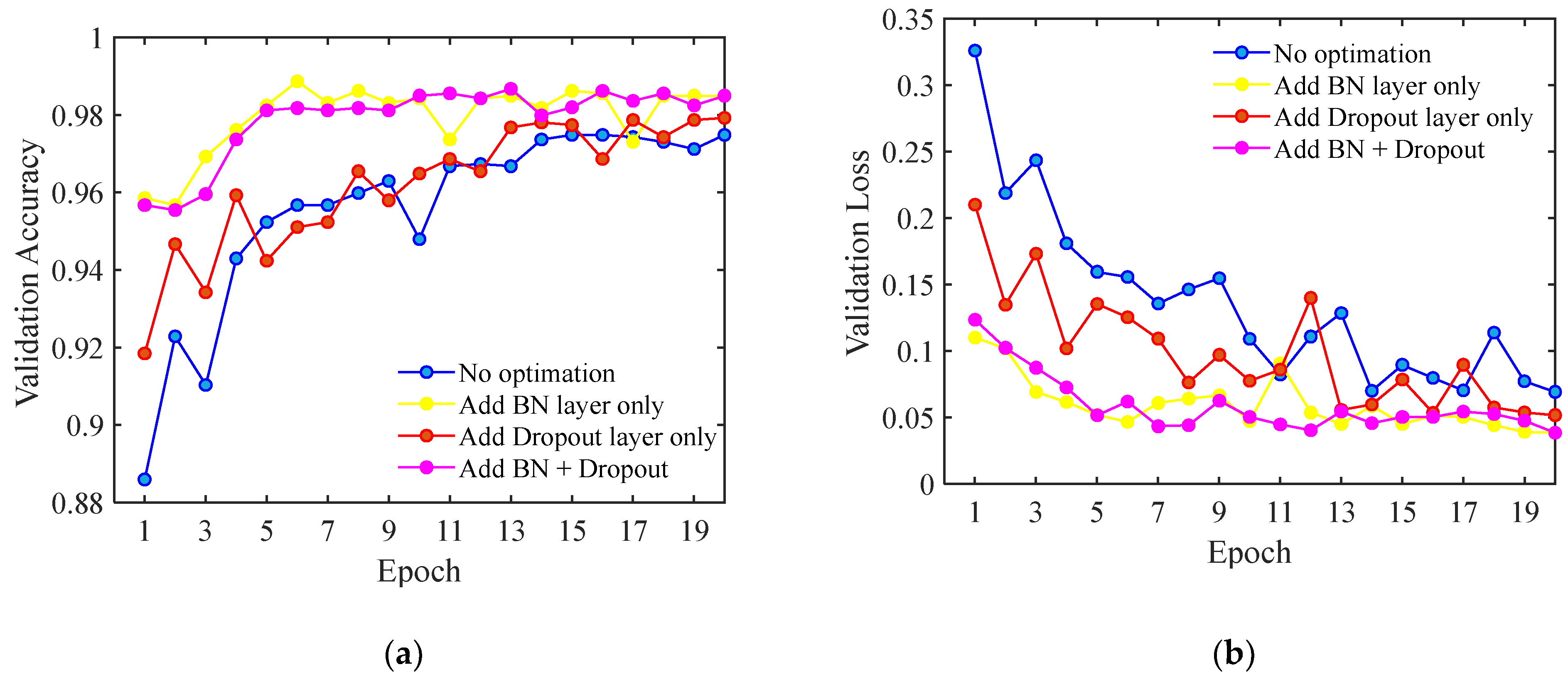
3.2.3. Optimization 3: Overfitting Control Strategy
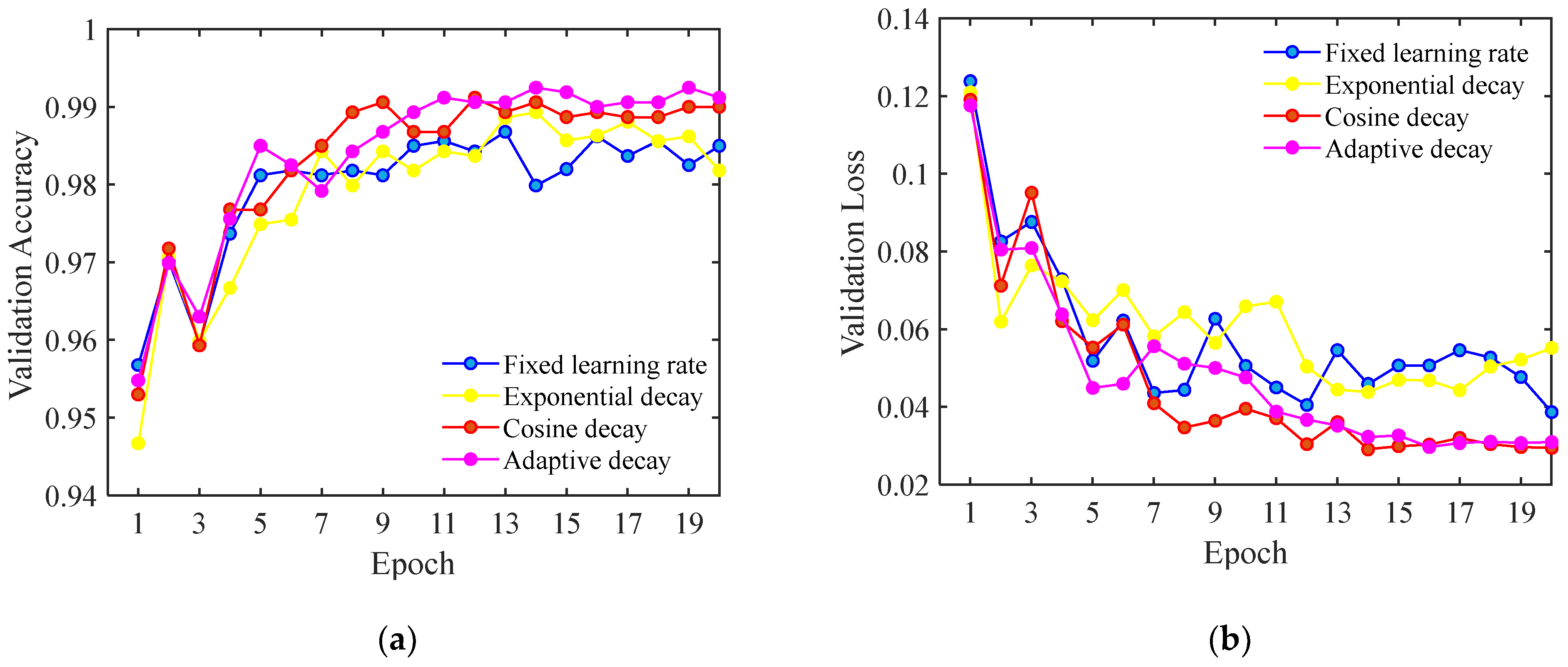
3.2.4. Optimization 4: Dynamic Learning Rate Strategy
- Exponential Decay
- Cosine Annealing Decay
- Adaptive Decay
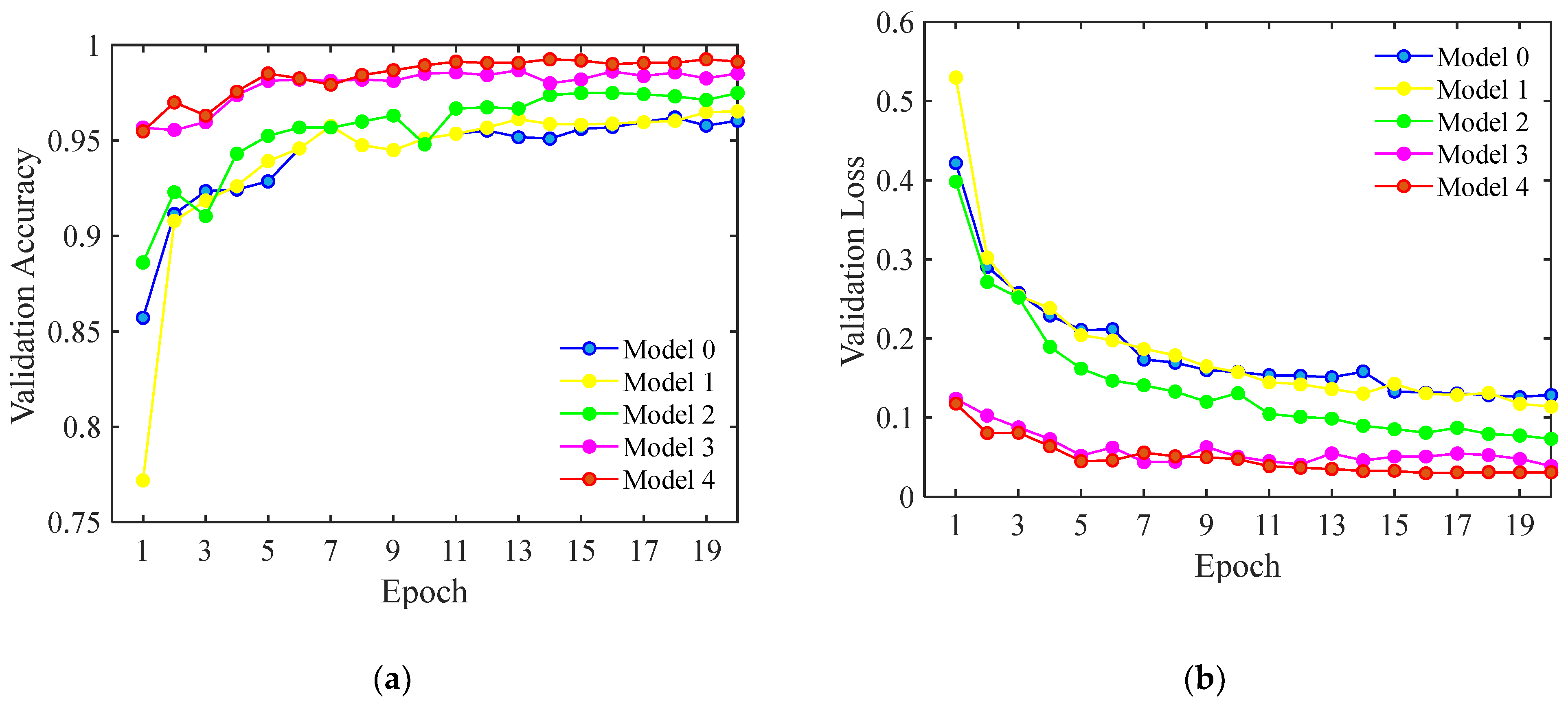
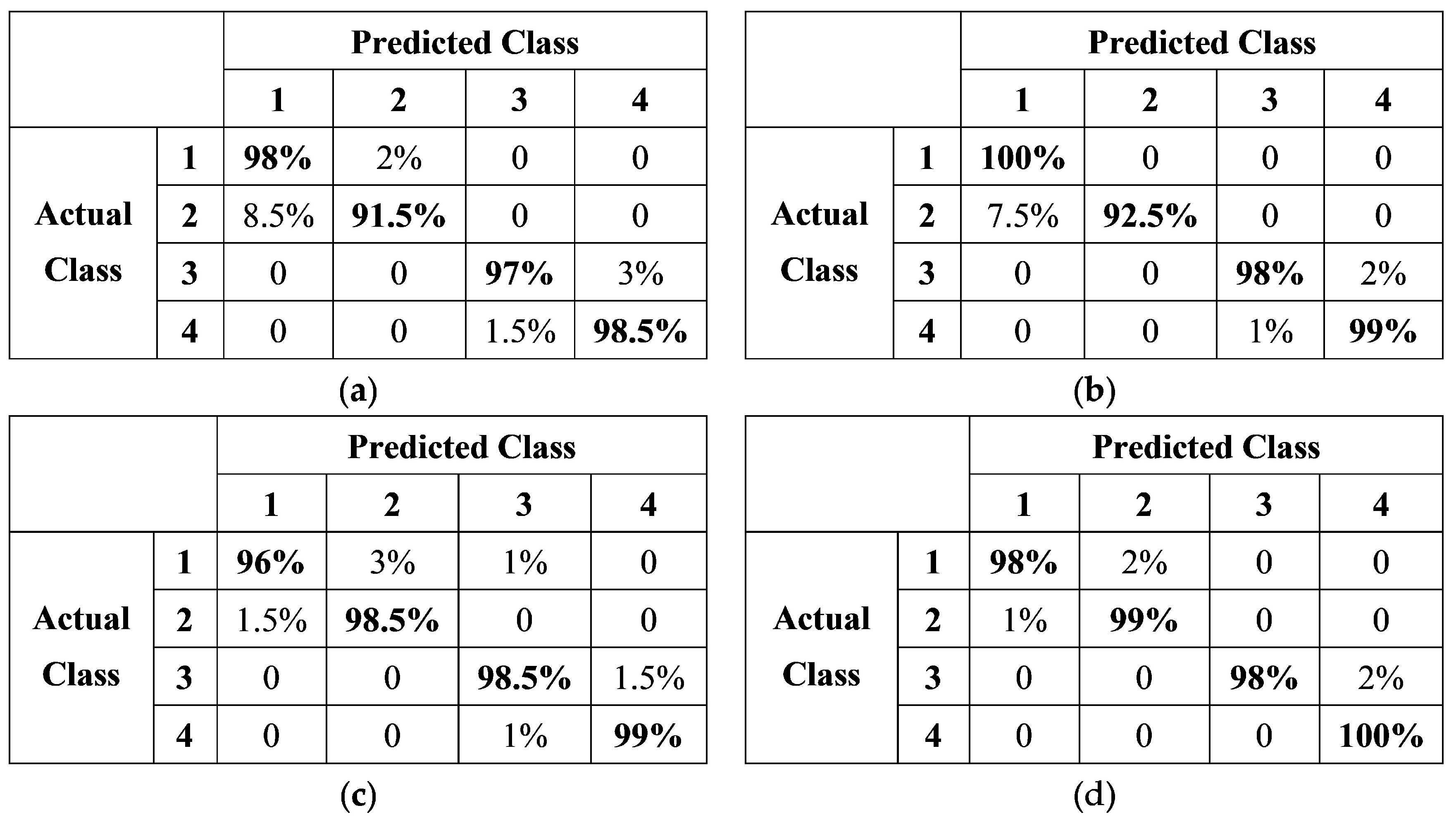
3.2.5. Performance Comparison after the Four Optimizations
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, Y.; Wang, Y.; Li, K.; Mazurenko, I. Effect of Oudemansiella Raphanipes Powder on Physicochemical and Textural Properties, Water Distribution and Protein Conformation of Lower-Fat Pork Meat Batter. Foods 2022, 11, 2623. [Google Scholar] [CrossRef] [PubMed]
- Azadnia, R.; Kheiralipour, K. Recognition of Leaves of Different Medicinal Plant Species Using a Robust Image Processing Algorithm and Artificial Neural Networks Classifier. J. Appl. Res. Med. Aromat. Plants 2021, 25, 100327. [Google Scholar] [CrossRef]
- Seydi, S.T.; Amani, M.; Ghorbanian, A. A Dual Attention Convolutional Neural Network for Crop Classification Using Time-series Sentinel-2 Imagery. Remote Sens. 2022, 14, 498. [Google Scholar] [CrossRef]
- Moreno-Revelo, M.Y.; Guachi-Guachi, L.; Gómez-Mendoza, J.B.; Revelo-Fuelagán, J.; Peluffo-Ordóñez, D.H. Enhanced Convolutional-Neural-Network Architecture for Crop Classification. Appl. Sci. 2021, 11, 4292. [Google Scholar] [CrossRef]
- Yu, Q.; Yang, H.; Gao, Y.; Ma, X.; Chen, G.; Wang, X. LFPNet: Lightweight Network on Real Point Sets for Fruit Classification and Segmentation. Comput. Electron. Agric. 2022, 194, 106691. [Google Scholar] [CrossRef]
- Ghazal, S.; Qureshi, W.S.; Khan, U.S.; Iqbal, J.; Rashid, N.; Tiwana, M.I. Analysis of Visual Features and Classifiers for Fruit Classification Problem. Comput. Electron. Agric. 2021, 187, 106267. [Google Scholar] [CrossRef]
- Hossain, M.S.; Al-Hammad, M.; Muhammad, G. Automatic Fruit Classification Using Deep Learning for Industrial Applications. IEEE Trans. Industr. Inform. 2018, 15, 1027–1034. [Google Scholar] [CrossRef]
- Altaheri, H.; Alsulaiman, M.; Muhammad, G. Date Fruit Classification for Robotic Harvesting in a Natural Environment Using Deep Learning. IEEE Access 2019, 7, 117115–117133. [Google Scholar] [CrossRef]
- Ahmed, M.I.; Mamun, S.M.; Asif, A.U.Z. DCNN-Based Vegetable Image Classification Using Transfer Learning: A Comparative Study. In Proceedings of the 5th International Conference on Computer, Communication and Signal Processing (ICCCSP), Chennai, India, 24–25 May 2021. [Google Scholar]
- Ulloa, C.C.; Krus, A.; Barrientos, A.; Del Cerro, J.; Valero, C. Robotic Fertilization in Strip Cropping Using a CNN Vegetables Detection-Characterization Method. Comput. Electron. Agric. 2022, 193, 106684. [Google Scholar] [CrossRef]
- Hameed, K.; Chai, D.; Rassau, A. A Comprehensive Review of Fruit and Vegetable Classification Techniques. Image Vis. Comput. 2018, 80, 24–44. [Google Scholar] [CrossRef]
- Sujatha, R.; Chatterjee, J.M.; Jhanjhi, N.Z.; Brohi, S.N. Performance of Deep Learning vs Machine Learning in Plant Leaf Disease Detection. Microprocess. Microsyst. 2021, 80, 103615. [Google Scholar] [CrossRef]
- Esgario, J.G.M.; Krohling, R.A.; Ventura, J.A. Deep Learning for Classification and Severity Estimation of Coffee Leaf Biotic Stress. Comput. Electron. Agric. 2020, 169, 105162. [Google Scholar] [CrossRef]
- Arwatchananukul, S.; Kirimasthong, K.; Aunsri, N. A New Paphiopedilum Orchid Database and Its Recognition Using Convolutional Neural Network. Wireless. Pers. Commun. 2020, 115, 3275–3289. [Google Scholar] [CrossRef]
- Ji, M.; Zhang, K.; Wu, Q.; Deng, Z. Multi-label Learning for Crop Leaf Diseases Recognition and Severity Estimation Based on Convolutional Neural Networks. Soft Comput. 2020, 24, 15327–15340. [Google Scholar] [CrossRef]
- Suharjito Elwirehardja, G.N.; Prayoga, J.S. Oil Palm Fresh Fruit Bunch Ripeness Classification on Mobile Devices Using Deep Learning Approaches. Comput. Electron. Agr. 2021, 188, 106359. [Google Scholar] [CrossRef]
- Preechasuk, J.; Chaowalit, O.; Pensiri, F.; Visutsak, P. Image Analysis of Mushroom Types Classification by Convolution Neural Networks. In Proceedings of the 2nd Artificial Intelligence and Cloud Computing Conference (AICCC), Kobe, Japan, 21–23 December 2019. [Google Scholar]
- Zahan, N.; Hasan, M.Z.; Malek, M.A.; Reya, S.S. A Deep Learning-Based Approach for Edible, Inedible and Poisonous Mushroom Classification. In Proceedings of the International Conference on Information and Communication Technology for Sustainable Development (ICICT4SD), Dhaka, Bangladesh, 27–28 February 2021. [Google Scholar]
- Zhao, M.; Li, Y.; Xu, P.; Song, T.; Li, H. Image Classification Method for Oudemansiella Raphanipes Using Compound Knowledge Distillation Algorithm. Trans. Chin. Soc. Agric. Eng. 2021, 37, 303–309. [Google Scholar]
- Ketwongsa, W.; Boonlue, S.; Kokaew, U. A New Deep Learning Model for the Classification of Poisonous and Edible Mushrooms Based on Improved AlexNet Convolutional Neural Network. Appl. Sci. 2022, 12, 3409. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Srinivasu, P.N.; SivaSai, J.G.; Ijaz, M.F.; Bhoi, A.K.; Kim, W.; Kang, J.J. Classification of Skin Disease Using Deep Learning Neural Networks with MobileNetV2 and LSTM. Sensors 2021, 21, 2852. [Google Scholar] [CrossRef]
- Lin, Z.; Guo, W. Cotton Stand Counting from Unmanned Aerial System Imagery Using MobileNet and CenterNet Deep Learning Models. Remote Sens. 2021, 13, 2822. [Google Scholar] [CrossRef]
- Kim, M.; Kwon, Y.; Kim, J.; Kim, Y. Image Classification of Parcel Boxes Under the Underground Logistics System Using CNN MobileNet. Appl. Sci. 2022, 12, 3337. [Google Scholar] [CrossRef]
- Sun, H.; Zhang, S.; Ren, R.; Su, L. Maturity Classification of “Hupingzao” Jujubes with an Imbalanced Dataset Based on Improved MobileNetV2. Agriculture 2022, 12, 1305. [Google Scholar] [CrossRef]
- Li, Y.; Xue, J.; Wang, K.; Zhang, M.; Li, Z. Surface Defect Detection of Fresh-Cut Cauliflowers Based on Convolutional Neural Network with Transfer Learning. Foods 2022, 11, 2915. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 2015 International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 2019 International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Kogilavani, S.V.; Prabhu, J.; Sandhiya, R.; Kumar, M.S.; Subramaniam, U.; Karthick, A.; Imam, S.B.S. COVID-19 Detection Based on Lung CT Scan Using Deep Learning Techniques. Comput. Math. Methods Med. 2022, 2022, 7672196. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Equipment | Environment |
|---|---|
| CPU | Intel(R) Core(TM) i5-8250U, 1.80 GHz |
| Memory | 8 GB |
| Operation system | Windows 10 (64bit) |
| Python | Version 3.7.0 |
| Tensorflow | Version 2.3.0 |
| Compiler environment | PyCharm 2020 |
| CNN Models | Test Accuracy (%) | Average Detection Time (ms) | Model Size (MB) |
|---|---|---|---|
| VGG16 | 97.75 | 185 | 56.20 |
| ResNet50 | 90.00 | 70 | 90.38 |
| InceptionV3 | 94.25 | 42.5 | 83.74 |
| NasNet-Mobile | 94.25 | 92.5 | 23.70 |
| EfficientNetB0 | 93.00 | 52.5 | 23.35 |
| MobileNetV2 | 94.75 | 37.5 | 16.44 |
| Model | Testing Accuracy (%) | Average Detection Time (ms) | Model Size (MB) | F1 Score (%) | Kappa Coefficient |
|---|---|---|---|---|---|
| Model 0 | 94.75 | 37.5 | 16.44 | 95.00 | 0.930 |
| Model 1 | 96.25 | 45 | 16.44 | 96.30 | 0.948 |
| Model 2 | 97.38 | 52.5 | 16.44 | 96.95 | 0.965 |
| Model 3 | 98.00 | 23.75 | 16.48 | 98.00 | 0.973 |
| Model 4 | 98.75 | 22.5 | 16.48 | 98.75 | 0.983 |
| Reference | Model | Testing Accuracy (%) | Detection Time (ms) | F1 Score (%) | Kappa Coefficient |
|---|---|---|---|---|---|
| [17] | 6-layer CNN | 74 | / | 74 | / |
| [18] | InceptionV3 | 88.40 | / | 88 | / |
| [19] | ResNet18 | 96.89 | 32 | / | 0.959 |
| [20] | Modified AlexNet | 98.5 | / | 99.09 | / |
| This paper | Improved MobileNetV2 | 98.75 | 22.5 | 98.75 | 0.983 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Huang, H.; Peng, Y.; Zhou, H.; Hu, H.; Liu, M. Quality Grading Algorithm of Oudemansiella raphanipes Based on Transfer Learning and MobileNetV2. Horticulturae 2022, 8, 1119. https://doi.org/10.3390/horticulturae8121119
Li T, Huang H, Peng Y, Zhou H, Hu H, Liu M. Quality Grading Algorithm of Oudemansiella raphanipes Based on Transfer Learning and MobileNetV2. Horticulturae. 2022; 8(12):1119. https://doi.org/10.3390/horticulturae8121119
Chicago/Turabian StyleLi, Tongkai, Huamao Huang, Yangyang Peng, Hui Zhou, Haiying Hu, and Ming Liu. 2022. "Quality Grading Algorithm of Oudemansiella raphanipes Based on Transfer Learning and MobileNetV2" Horticulturae 8, no. 12: 1119. https://doi.org/10.3390/horticulturae8121119
APA StyleLi, T., Huang, H., Peng, Y., Zhou, H., Hu, H., & Liu, M. (2022). Quality Grading Algorithm of Oudemansiella raphanipes Based on Transfer Learning and MobileNetV2. Horticulturae, 8(12), 1119. https://doi.org/10.3390/horticulturae8121119