

Segmentation-Based Classification of Plants Robust to Various Environmental Factors in South Korea with Self-Collected Database

Abstract
1. Introduction
- -
- When capturing close-up images of plant leaves, the camera’s shallow depth of field (DoF) often results in only a portion of the leaf being in focus, while the rest appears blurred. Typically, the focused area is considered the primary region of interest for recognition. However, most previous studies have not addressed this issue. This study explores plant recognition by focusing on clearly visible leaf regions and disregarding blurred areas. Furthermore, while previous studies did not consider input images containing moisture, water droplets, dust, or partially missing leaves, this study collects and investigates a dataset of plant images captured in real field environments with complex backgrounds in South Korea.
- -
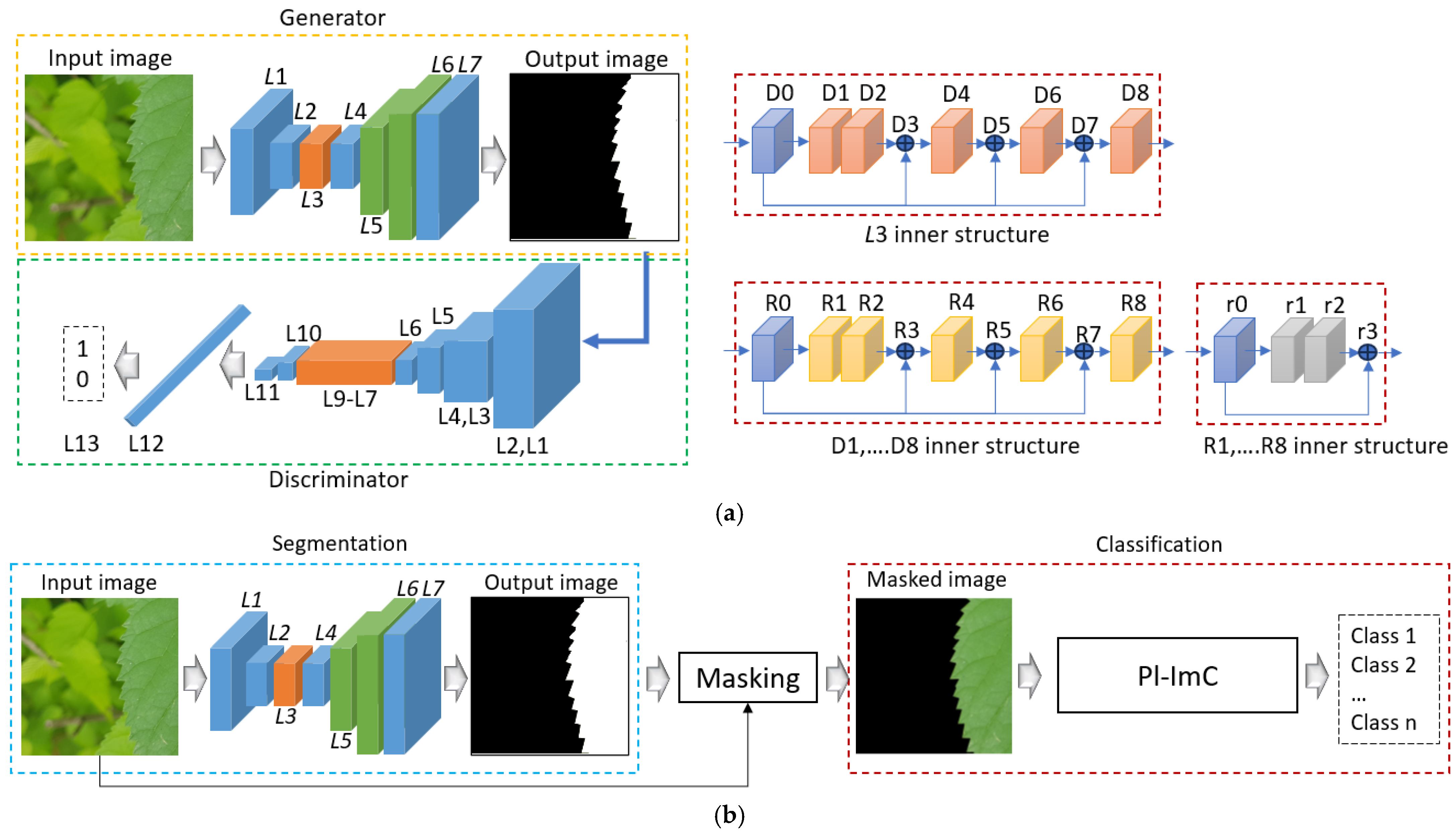
- To address these challenges, this study proposes the Pl-ImS network in plant image segmentation. The Pl-ImS network incorporates residual blocks and a densely connected architecture, optimized based on the self-collected dataset. Additionally, a new residual DenseNet (RDense) block is designed, integrating five densely connected blocks. The RDense block architecture enables skip-connection-based feature fusion at multiple steps, ensuring high segmentation performance. Moreover, the Pl-ImS network is trained using a GAN framework, incorporating a discriminator network to improve performance. During training, ground-truth images are prepared to facilitate segmentation, emphasizing only the high-quality plant regions in the input images.
- -
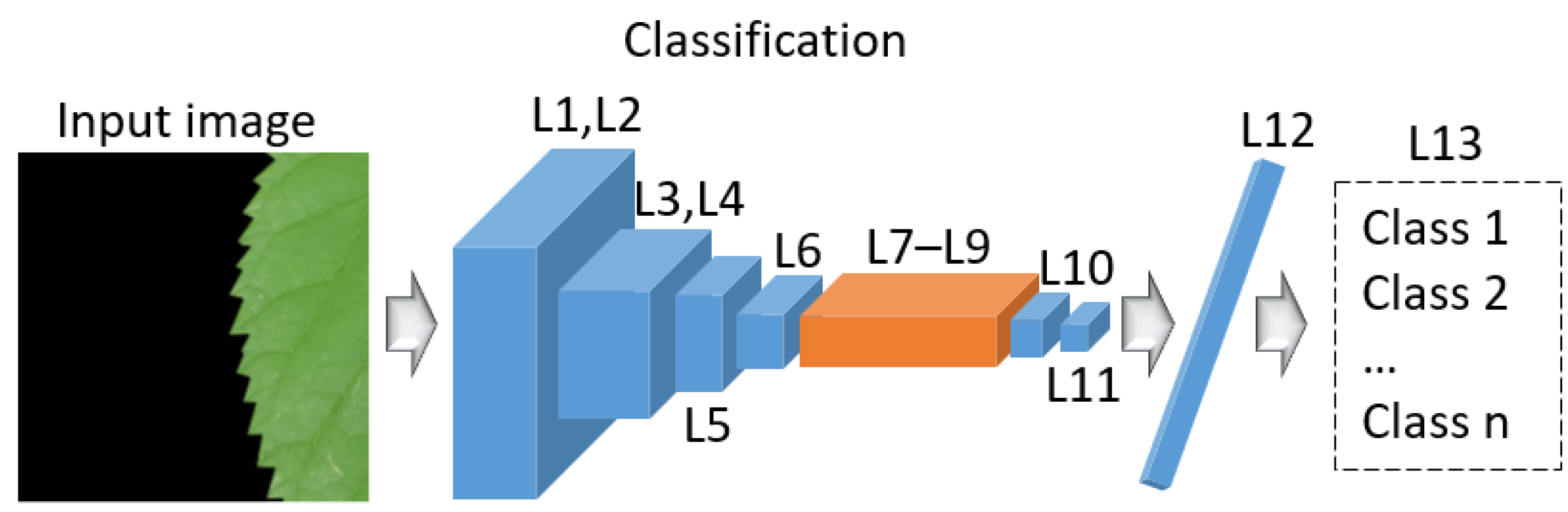
- To further improve classification performance, this study proposes the Pl-ImC network in plant image classification. In the Pl-ImC network, using only residual blocks yields better performance than incorporating a densely connected network. Therefore, the architecture is designed with three residual blocks and eight convolutional layers. Since the Pl-ImS network has a large number of parameters and a slow processing speed, a simplified architecture is implemented for the Pl-ImC network, reducing the number of parameters to 2.1 M to enhance processing efficiency. Additionally, overall model design time is minimized by utilizing only the simplified fully connected (FC) layer architecture from the Pl-ImC network as the discriminator network for the Pl-ImS network.
- -
- Fractal dimension estimation is applied to the Pl-ImS network to further refine segmentation performance. Moreover, the proposed models, source codes, and built databases are available on GitHub [19].
2. Related Work
2.1. Plant Image Segmentation Studies
2.1.1. Images with a Single Plant
2.1.2. Images with Multiple Plants
2.2. Plant Image Classification Studies
2.2.1. Images with a Single Plant
2.2.2. Images with Multiple Plants
2.2.3. Images with Single and Multiple Plants
3. Proposed Methodology
3.1. Overview of the Proposed Method
3.2. Overview of Proposed Segmentation Method
3.3. Overview of Proposed Classification Method
3.4. Description of the Dataset
4. Experimental Results
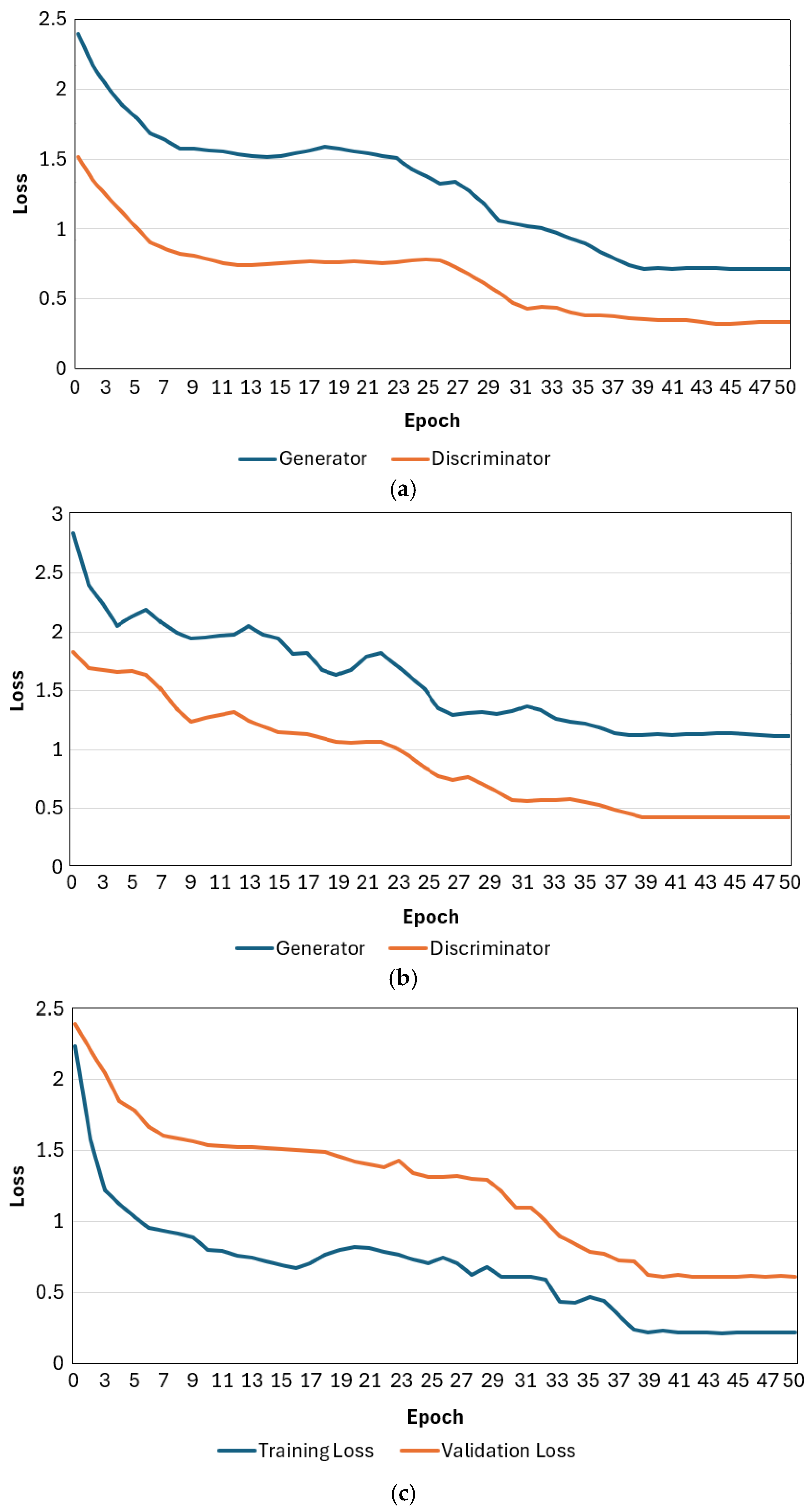
4.1. Training
4.2. Testing
4.2.1. Evaluation Metrics
4.2.2. Ablation Study
4.2.3. Comparisons with Plant Image-Based SOTA Segmentation Methods
4.2.4. Comparisons with Plant Image-Based SOTA Classification Methods
4.2.5. Comparisons of Algorithm Complexity
5. Discussion
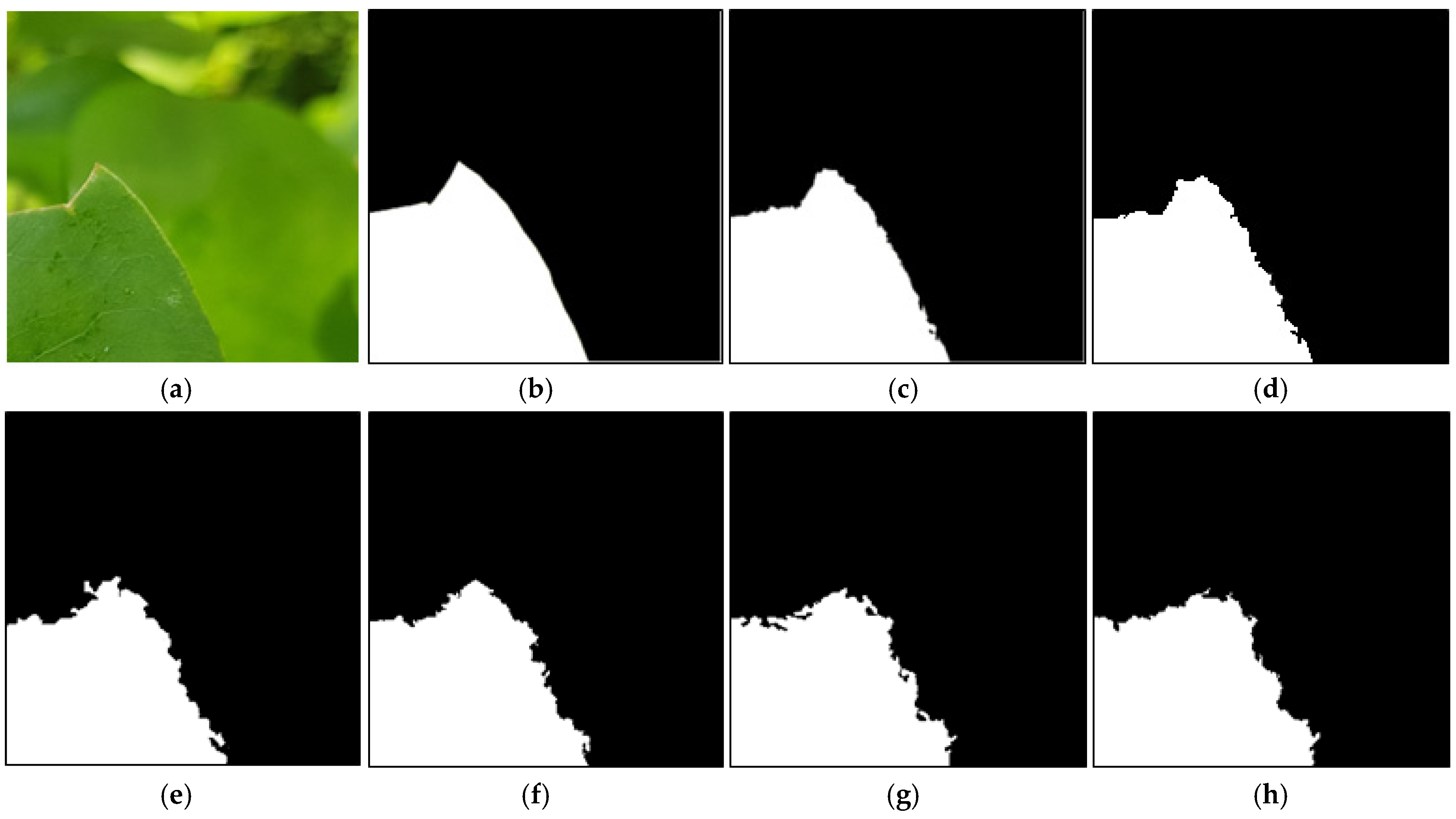
5.1. Error and Correct Segmentation Cases
5.2. Error and Correct Classification Cases
5.3. FD Estimation for Plant Image Segmentation
5.4. Statistical Analysis
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Batchuluun, G.; Nam, S.H.; Park, K.R. Deep learning-based plant classification and crop disease classification by thermal camera. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 1319–1578. [Google Scholar] [CrossRef]
- Anasta, N.; Setyawan, F.X.A.; Fitriawan, H. Disease detection in banana trees using an image processing-based thermal camera. IOP Conf. Ser. Earth Environ. Sci. 2021, 739, 012088. [Google Scholar] [CrossRef]
- Raza, S.E.; Prince, G.; Clarkson, J.P.; Rajpoot, N.M. Automatic detection of diseased tomato plants using thermal and stereo visible light images. PLoS ONE 2015, 10, e0123262. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Chen, H.; Ciechanowska, I.; Spaner, D. Application of infrared thermal imaging for the rapid diagnosis of crop disease. IFAC-Pap. 2018, 51, 424–430. [Google Scholar] [CrossRef]
- Shahi, T.B.; Sitaula, C.; Neupane, A.; Guo, W. Fruit classification using attention-based MobileNetV2 for industrial applications. PLoS ONE 2022, 17, e0264586. [Google Scholar] [CrossRef] [PubMed]
- Kader, A.; Sharif, S.; Bhowmick, P.; Mim, F.H.; Srizon, A.Y. Effective workflow for high-performance recognition of fruits using machine learning approaches. Int. Res. J. Eng. Technol. 2020, 7, 1516–1521. [Google Scholar]
- Biswas, B.; Ghosh, S.K.; Ghosh, A. A robust multi-label fruit classification based on deep convolution neural network. In Computational Intelligence in Pattern Recognition; Advances in Intelligent Systems and Computing; Das, A., Nayak, J., Naik, B., Pati, S., Pelusi, D., Eds.; Springer: Singapore, 2020; Volume 999. [Google Scholar] [CrossRef]
- Hossain, M.S.; Al-Hammadi, M.; Muhammad, G. Automatic fruit classification using deep learning for industrial applications. IEEE Trans. Ind. Inform. 2019, 15, 1027–1034. [Google Scholar] [CrossRef]
- Abawatew, G.Y.; Belay, S.; Gedamu, K.; Assefa, M.; Ayalew, M.; Oluwasanmi, A.; Qin, Z. Attention augmented residual network for tomato disease detection and classification. Turk. J. Electr. Eng. Comput. Sci. 2021, 29, 2869–2885. [Google Scholar] [CrossRef]
- Ashwinkumar, S.; Rajagopal, S.; Manimaran, V.; Jegajothi, B. Automated plant leaf disease detection and classification using optimal MobileNet based convolutional neural networks. Mater. Today 2022, 51, 480–487. [Google Scholar] [CrossRef]
- Chakraborty, A.; Kumer, D.; Deeba, K. Plant leaf disease recognition using Fastai image classification. In Proceedings of the 5th International Conference on Computing Methodologies and Communication, Erode, India, 8–10 April 2021; pp. 1624–1630. [Google Scholar] [CrossRef]
- Wang, D.; Wang, J.; Li, W.; Guan, P. T-CNN: Trilinear convolutional neural networks model for visual detection of plant diseases. Comput. Electron. Agric. 2021, 190, 106468. [Google Scholar] [CrossRef]
- Yun, C.; Kim, Y.W.; Lee, S.J.; Im, S.J.; Park, K.R. WRA-Net: Wide receptive field attention network for motion deblurring in crop and weed image. Plant Phenomics 2023, 5, 0031. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wu, B.; Kohnen, M.V.; Lin, D.; Yang, C.; Wang, X.; Qiang, A.; Liu, W.; Kang, J.; Li, H.; et al. Classification of rice yield using UAV-based hyperspectral imagery and lodging feature. Plant Phenomics 2021, 2021, 9765952. [Google Scholar] [CrossRef] [PubMed]
- PlantVillage Dataset. Available online: https://www.kaggle.com/datasets/emmarex/plantdisease (accessed on 8 January 2025).
- Horea, M.; Mihai, O. Fruit recognition from images using deep learning. Acta Univ. Sapientiae Inform. 2018, 10, 26–42. [Google Scholar]
- Wang, P.; Deng, H.; Guo, J.; Ji, S.; Meng, D.; Bao, J.; Zuo, P. Leaf segmentation using modified YOLOv8-seg models. Life 2024, 14, 780. [Google Scholar] [CrossRef] [PubMed]
- Singh, D.; Jain, N.; Jain, P.; Kayal, P.; Kumawat, S.; Batra, N. PlantDoc: A dataset for visual plant disease detection. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data (CoDS-COMAD), Hyderabad, India, 5–7 January 2020; pp. 249–253. [Google Scholar] [CrossRef]
- The Self-Collected Dataset and the Source Code. Available online: https://github.com/ganav/Pl-ImS-Pl-ImC (accessed on 18 March 2025).
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661v1. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA; 27–30 June 2016; pp. 770–778. [CrossRef]
- Yang, T.; Zhou, S.; Xu, A.; Ye, J.; Yin, J. An approach for plant leaf image segmentation based on YOLOV8 and the improved DEEPLABV3+. Plants 2023, 12, 3438. [Google Scholar] [CrossRef] [PubMed]
- Shoaib, M.; Hussain, T.; Shah, B.; Ullah, I.; Shah, S.M.; Ali, F.; Park, S.H. Deep learning-based segmentation and classification of leaf images for detection of tomato plant disease. Front. Plant Sci. 2022, 13, 1031748. [Google Scholar] [CrossRef] [PubMed]
- Ward, D.; Moghadam, P.; Hudson, N. Deep leaf segmentation using synthetic data. arXiv 2018, arXiv:1807.10931. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Milioto, A.; Lottes, P.; Stachniss, C. Real-time semantic segmentation of crop and weed for precision agriculture robots leveraging background knowledge in CNNs. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2229–2235. [Google Scholar]
- Hamid, N.N.A.A.; Razali, R.A.; Ibrahim, Z. Comparing bags of features, conventional convolutional neural network and AlexNet for fruit recognition. Indones. J. Elect. Eng. Comput. Sci. 2019, 14, 333–339. [Google Scholar] [CrossRef]
- Katarzyna, R.; Paweł, M.A. Vision-based method utilizing deep convolutional neural networks for fruit variety classification in uncertainty conditions of retail sales. Appl. Sci. 2019, 9, 3971. [Google Scholar] [CrossRef]
- Siddiqi, R. Comparative performance of various deep learning based models in fruit image classification. In Proceedings of the 11th International Conference on Advances in Information Technology, Bangkok, Thailand, 1–3 July 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Chompookham, T.; Surinta, O. Ensemble methods with deep convolutional neural networks for plant leaf recognition. ICIC Express Lett. 2021, 15, 553–565. [Google Scholar]
- Batchuluun, G.; Nam, S.H.; Park, K.R. Deep learning-based plant classification using nonaligned thermal and visible light images. Mathematics 2022, 10, 4053. [Google Scholar] [CrossRef]
- Analysis of Variance. Available online: https://en.wikipedia.org/wiki/Analysis_of_variance (accessed on 8 February 2024).
- Batchuluun, G.; Nam, S.H.; Park, C.; Park, K.R. Super-resolution reconstruction based plant image classification using thermal and visible-light images. Mathematics 2023, 11, 76. [Google Scholar] [CrossRef]
- Python. Available online: https://www.python.org/ (accessed on 8 January 2025).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 8 January 2025).
- OpenCV. Available online: http://opencv.org/ (accessed on 8 January 2025).
- Chollet, F. Keras, California, U.S. Available online: https://keras.io/ (accessed on 8 January 2025).
- Zhang, Z.; Sabuncu, M.R. Generalized cross entropy loss for training deep neural networks with noisy labels. arXiv 2018, arXiv:1805.07836. [Google Scholar]
- Wali, R. Xtreme Margin: A tunable loss function for binary classification problems. arXiv 2022, arXiv:2211.00176. [Google Scholar]
- Kingma, D.P.; Ba, J.B. ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Bertels, J.; Eelbode, T.; Berman, M.; Vandermeulen, D.; Maes, F.; Bisschops, R.; Blaschko, M.B. Optimizing the dice score and jaccard index for medical image segmentation: Theory & practice. In Proceedings of the 22nd International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; pp. 92–100. [Google Scholar]
- Terven, J.; Cordova-Esparza, D.M.; Romero-González, J.A.; Ramírez-Pedraza, A.; Chávez-Urbiola, E.A. A comprehensive survey of loss functions and metrics in deep learning. Artif. Intell. Rev. 2025, 58, 195. [Google Scholar] [CrossRef]
- Brouty, X.; Garcin, M. Fractal properties, information theory, and market efficiency. Chaos Solitons Fractals 2024, 180, 114543. [Google Scholar] [CrossRef]
- Huixian, J. The analysis of plants image recognition based on deep learning and artificial neural network. IEEE Access 2020, 8, 68828–68841. [Google Scholar] [CrossRef]
- Arun, Y.; Viknesh, G.S. Leaf classification for plant recognition using EfficientNet architecture. In Proceedings of the IEEE Fourth International Conference on Advances in Electronics, Computers and Communications, Bengaluru, India, 10–11 January 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Keerthika, P.; Devi, R.M.; Prasad, S.J.S.; Venkatesan, R.; Gunasekaran, H.; Sudha, K. Plant classification based on grey wolf optimizer based support vector machine (GOS) algorithm. In Proceedings of the 7th International Conference on Computing Methodologies and Communication, Erode, India, 23–25 February 2023; pp. 902–906. [Google Scholar] [CrossRef]
- Sun, Y.; Tian, B.; Ni, C.; Wang, X.; Fei, C.; Chen, Q. Image classification of small sample grape leaves based on deep learning. In Proceedings of the IEEE 7th Information Technology and Mechatronics Engineering Conference, Chongqing, China, 15–17 September 2023; pp. 1874–1878. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. arXiv 2016, arXiv:1610.02391. [Google Scholar]
- Curtis, D. Welch’s t test is more sensitive to real world violations of distributional assumptions than student’s t test but logistic regression is more robust than either. Stat. Pap. 2024, 65, 3981–3989. [Google Scholar] [CrossRef]
- Groß, J.; Möller, A. Some additional remarks on statistical properties of Cohen’s d in the presence of covariates. Stat. Pap. 2024, 65, 3971–3979. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Type | Dataset | Method | Advantage | Disadvantage | |
|---|---|---|---|---|---|---|
| Segmentation | Single plant | TDUS | DEEPLABV3+ [22] | - Considers images from real field conditions - Effective for segmenting a single plant in images | - Fails to account for various environmental factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) and cannot segment multiple plants at once | |
| PlantVillage | Modified U-Net [23] | - Can segment both plant parts and disease-affected areas - Effective for segmenting a single plant in images | - Does not consider images captured in real farmland environment - Fails to account for various environmental factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) and cannot segment multiple plants at once | |||
| Multiple plants | CVPPP | YOLOv8-seg [17] Mask-RCNN [24] | Able to segment multiple plant leaves simultaneously | - Simultaneously segmenting multiple plants is time-consuming and less accurate - Fails to consider various factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) | ||
| Bonn, Stuttgart, and Zurich | CNN-SS [26] | - Considers various illumination conditions and soil types - Considers images from real field conditions - Able to segment multiple plants simultaneously | - Images become blurred as robots move while capturing images in farms - Simultaneously segmenting multiple plants is time-consuming and less accurate - Fails to consider various factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) | |||
| Classification | Single plant | Fruits-360 | Alexnet [27]; YOLO-V3 [28]; FruitNet [29]; SVM [6] | It is effective to segment a single plant in images. | - Reduced performance when images contain multiple plants or a large background - Does not consider images captured in a real farmland environment - Fails to consider various factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) | |
| Single and multiple plants | FIDS30 and Fruits-360 | CNN-based [7] | - Consistent performance regardless of the number of plants - Considers various scenarios, including images with a single plant or a large background, filled with plant content, etc. | Fails to account for various environmental factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) | ||
| Supermarket produce, self-collected | VGG16-based [8] | - Segmenting various plant images acquired from supermarkets effectively - Consistent performance regardless of the number of plants | - Does not consider images captured in a real farmland environment - Fails to consider various factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) | |||
| Dataset collection | MobileNetV2 [5] | - Strong performance resulting from training the model on diverse fruit and vegetable datasets - Consistent performance regardless of the number of plants | - Does not consider the leaves of plants, fruits, and vegetables - Does not consider images captured in a real farmland environment - Fails to consider various factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) | |||
| PlantVillage, PlantDoc | T-CNN [12] | - Able to differentiate plants and plant diseases - Consistent performance regardless of the number of plants in the images | - Fails to consider various factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) - Does not consider images captured in a real farmland environment | |||
| Multiple plants | Normal plant images | Self-collected | If-then rule [2]; PlantCR [32]; SVM [3]; PlantMC [34] | - Can differentiate plants in visual and thermal images - Improves plant and plant disease classification by integrating thermal and visual images - Consistent performance regardless of the number of plants | - High processing speed achieved by utilizing multiple images simultaneously - Fails to account for various environmental factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) | |
| PlantDoc | AAR [9]; OMNCNN [10]; DenseNet-121 [11] | - Able to differentiate plants and plant diseases - Consistent performance regardless of the number of plants in the images | Fails to account for various environmental factors (missing parts of the plant’s leaves due to blurring, the presence of small or large water droplets, dust, or insects) | |||
| Plant images of blur, small or large water droplets, dust, and insects with parts of leaves | Self-collected | Pl-ImS + Pl-ImC (Proposed method) | - Accurately segments plant regions regardless of the number of plants in the images - Accounts for diverse environmental factors in images captured from real farmlands | - Extended processing time for plant image segmentation and classification - Large model size | ||
| Hardware | Software | ||
|---|---|---|---|
| Hardware | Specification | Library | Version |
| Memory | 32 GB RAM | Python [35] | 3.5.4 |
| GPU | Nvidia GeForce TITAN X (12 GB) | TensorFlow [36] | 1.9.0 |
| CPU | Intel(R) CoreTM i7-6700 CPU@3.40 GHz (8 CPUs) | OpenCV [37] | 4.3.0 |
| Keras API [38] | 2.1.6-tf | ||
| Parameter | Pl-ImC | Pl-ImS |
|---|---|---|
| Loss | Categorical cross-entropy (CCE) [39] | Binary cross entropy loss (BCE) [40] |
| Optimizer | Adaptive moment estimation (Adam) [41] | Adam |
| # Epochs | 100 | 100 |
| Learning rate | 0.001 | 0.001 |
| Batch size | 8 | 8 |
| Architectures | DS | IoU |
|---|---|---|
| Pl-ImS (with three dense blocks) | 88.74 | 80.18 |
| Pl-ImS (with four dense blocks) | 89.19 | 81.58 |
| Pl-ImS (with five dense blocks) | 89.90 | 81.82 |
| Pl-ImS (with six dense blocks) | 89.05 | 81.58 |
| Pl-ImS (with seven dense blocks) | 87.16 | 79.58 |
| Input Images | DS | IoU |
|---|---|---|
| Normal | 91.23 | 82.83 |
| Missing part | 89.52 | 81.46 |
| Little wet leaf with small water droplets | 90.06 | 82.01 |
| Drenched leaf with large water droplets | 89.74 | 81.48 |
| Dust | 88.95 | 81.36 |
| Average | 89.90 | 81.82 |
| Architectures | Pl-ImS + Pl-ImC | ||
|---|---|---|---|
| TPR | PPV | F1-Score | |
| With a residual block | 96.36 | 93.99 | 95.18 |
| With two residual blocks | 96.36 | 94.52 | 95.44 |
| With three residual blocks | 96.67 | 95.28 | 95.97 |
| With four residual blocks | 96.29 | 94.71 | 95.50 |
| With five residual blocks | 96.32 | 95.26 | 95.79 |
| Predicted | Aruncus dioicus | Callicarpa dichotoma | Euonymus fortunei | Lonicera ruprechtiana | Malus floribunda | Populus tremula L. | Vaccinium myrtillus L. | White paeonia | Total # of Data | TPR (%) | |
| Actual | |||||||||||
| Aruncus dioicus | 2289 | 0 | 19 | 14 | 15 | 17 | 1 | 5 | 2360 | 96.99 | |
| Callicarpa dichotoma | 3 | 3416 | 48 | 23 | 10 | 2 | 9 | 9 | 3520 | 97.05 | |
| Euonymus fortunei | 33 | 25 | 3403 | 54 | 16 | 3 | 31 | 35 | 3600 | 94.53 | |
| Lonicera ruprechtiana | 1 | 12 | 2 | 2030 | 5 | 20 | 5 | 5 | 2080 | 97.60 | |
| Malus floribunda | 11 | 17 | 6 | 12 | 2100 | 40 | 5 | 9 | 2200 | 95.45 | |
| Populus tremula L. | 1 | 14 | 0 | 5 | 10 | 2550 | 5 | 15 | 2600 | 98.08 | |
| Vaccinium myrtillus L. | 35 | 9 | 15 | 43 | 10 | 15 | 3100 | 53 | 3280 | 94.51 | |
| White paeonia | 22 | 4 | 12 | 3 | 5 | 16 | 18 | 2040 | 2120 | 96.23 | |
| Input Images | ResNet-50 | Pl-ImS + ResNet-50 | ||||
|---|---|---|---|---|---|---|
| TPR | PPV | F1-Score | TPR | PPV | F1-Score | |
| Normal | 91.51 | 95.14 | 93.32 | 97.74 | 94.49 | 96.11 |
| Missing part | 88.59 | 89.25 | 88.92 | 93.02 | 92.78 | 92.90 |
| Little wet leaf with small water drop | 86.59 | 86.36 | 86.47 | 95.16 | 92.14 | 93.65 |
| Drenched leaf with large water drop | 90.22 | 94.46 | 92.34 | 94.90 | 93.40 | 94.15 |
| Dust | 90.08 | 87.07 | 88.57 | 93.96 | 91.82 | 92.89 |
| Average | 89.39 | 90.45 | 89.92 | 94.95 | 92.92 | 93.94 |
| Input Images | Pl-ImC | Pl-ImS + Pl-ImC | ||||
|---|---|---|---|---|---|---|
| TPR | PPV | F1-Score | TPR | PPV | F1-Score | |
| Normal | 94.56 | 97.51 | 96.03 | 98.23 | 97.35 | 97.79 |
| Missing part | 90.14 | 90.90 | 90.52 | 95.44 | 94.82 | 95.13 |
| Little wet leaf with small water drop | 88.70 | 89.77 | 89.23 | 95.95 | 93.66 | 94.80 |
| Drenched leaf with large water drop | 92.37 | 96.17 | 94.27 | 97.18 | 96.15 | 96.66 |
| Dust | 93.76 | 88.27 | 91.01 | 96.57 | 94.42 | 95.49 |
| Average | 91.90 | 92.52 | 92.21 | 96.67 | 95.28 | 95.97 |
| Input Images | Model/Method | DS | IoU |
|---|---|---|---|
| Normal | DeepLabV3+ [22] | 84.93 | 81.35 |
| YOLOv8-Seg [17] | 83.74 | 79.41 | |
| Mask R-CNN [24] | 83.84 | 79.56 | |
| Modified U-Net [23] | 83.48 | 80.48 | |
| CNN-SS [26] | 84.52 | 81.65 | |
| Pl-ImS (proposed) | 91.23 | 82.83 | |
| Missing part | DeepLabV3+ [22] | 83.62 | 80.13 |
| YOLOv8-Seg [17] | 82.29 | 78.12 | |
| Mask R-CNN [24] | 82.34 | 78.37 | |
| Modified U-Net [23] | 82.52 | 79.78 | |
| CNN-SS [26] | 83.41 | 80.13 | |
| Pl-ImS (proposed) | 89.52 | 81.46 | |
| Little wet leaf with small water drop | DeepLabV3+ [22] | 84.43 | 80.91 |
| YOLOv8-Seg [17] | 82.89 | 79.14 | |
| Mask R-CNN [24] | 83.09 | 79.72 | |
| Modified U-Net [23] | 82.85 | 79.92 | |
| CNN-SS [26] | 83.88 | 81.08 | |
| Pl-ImS (proposed) | 90.06 | 82.01 | |
| Drenched leaf with large water drop | DeepLabV3+ [22] | 84.33 | 80.40 |
| YOLOv8-Seg [17] | 82.39 | 78.88 | |
| Mask R-CNN [24] | 82.93 | 78.86 | |
| Modified U-Net [23] | 82.69 | 79.79 | |
| CNN-SS [26] | 83.60 | 80.28 | |
| Pl- ImS (proposed) | 89.74 | 81.48 | |
| Dust | DeepLabV3+ [22] | 83.06 | 80.11 |
| YOLOv8-Seg [17] | 81.70 | 78.37 | |
| Mask R-CNN [24] | 82.17 | 78.18 | |
| Modified U-Net [23] | 81.60 | 79.49 | |
| CNN-SS [26] | 81.80 | 80.11 | |
| Pl-ImS (proposed) | 88.95 | 81.36 | |
| Average | DeepLabV3+ [22] | 84.07 | 80.58 |
| YOLOv8-Seg [17] | 82.60 | 78.78 | |
| Mask R-CNN [24] | 82.87 | 78.93 | |
| Modified U-Net [23] | 82.62 | 79.89 | |
| CNN-SS [26] | 83.44 | 80.65 | |
| Pl-ImS (proposed) | 89.90 | 81.82 |
| Input Images | Model/Method | TPR | PPV | F1-Score |
|---|---|---|---|---|
| Normal | DeepLabV3+ [22] + ResNet-50 | 87.45 | 90.64 | 89.04 |
| YOLOv8-Seg [17] + ResNet-50 | 88.34 | 88.41 | 88.37 | |
| Mask R-CNN [24] + ResNet-50 | 95.12 | 89.43 | 92.27 | |
| Modified U-Net [23] + ResNet-50 | 92.56 | 89.18 | 90.87 | |
| CNN-SS [26] + ResNet-50 | 89.78 | 94.71 | 92.24 | |
| Pl-ImS + ResNet-50 | 97.74 | 94.49 | 96.11 | |
| Missing part | DeepLabV3+ [22] + ResNet-50 | 86.18 | 93.05 | 89.61 |
| YOLOv8-Seg [17] + ResNet-50 | 89.37 | 89.60 | 89.48 | |
| Mask R-CNN [24] + ResNet-50 | 91.06 | 90.17 | 90.61 | |
| Modified U-Net [23] + ResNet-50 | 90.03 | 87.02 | 88.52 | |
| CNN-SS [26] + ResNet-50 | 91.87 | 87.23 | 89.55 | |
| Pl-ImS + ResNet-50 | 93.02 | 92.78 | 92.90 | |
| Little wet leaf with small water drop | DeepLabV3+ [22] + ResNet-50 | 85.57 | 88.01 | 86.79 |
| YOLOv8-Seg [17] + ResNet-50 | 86.80 | 86.98 | 86.89 | |
| Mask R-CNN [24] + ResNet-50 | 93.58 | 87.06 | 90.32 | |
| Modified U-Net [23] + ResNet-50 | 90.56 | 87.86 | 89.21 | |
| CNN-SS [26] + ResNet-50 | 87.74 | 92.08 | 89.91 | |
| Pl-ImS + ResNet-50 | 95.16 | 92.14 | 93.65 | |
| Drenched leaf with large water drop | DeepLabV3+ [22] + ResNet-50 | 91.62 | 88.40 | 90.01 |
| YOLOv8-Seg [17] + ResNet-50 | 90.96 | 94.86 | 92.91 | |
| Mask R-CNN [24] + ResNet-50 | 85.68 | 88.72 | 87.20 | |
| Modified U-Net [23] + ResNet-50 | 92.64 | 94.88 | 93.76 | |
| CNN-SS [26] + ResNet-50 | 88.20 | 89.55 | 88.87 | |
| Pl-ImS + ResNet-50 | 94.90 | 93.40 | 94.15 | |
| Dust | DeepLabV3+ [22] + ResNet-50 | 89.11 | 94.38 | 91.74 |
| YOLOv8-Seg [17] + ResNet-50 | 92.08 | 88.69 | 90.38 | |
| Mask R-CNN [24] + ResNet-50 | 91.26 | 93.01 | 92.13 | |
| Modified U-Net [23] + ResNet-50 | 88.29 | 88.40 | 88.34 | |
| CNN-SS [26] + ResNet-50 | 94.96 | 89.37 | 92.16 | |
| Pl-ImS + ResNet-50 | 93.96 | 91.82 | 92.89 | |
| Average | DeepLabV3+ [22] + ResNet-50 | 87.98 | 90.89 | 89.44 |
| YOLOv8-Seg [17] + ResNet-50 | 89.51 | 89.70 | 89.60 | |
| Mask R-CNN [24] + ResNet-50 | 91.34 | 89.67 | 90.50 | |
| Modified U-Net [23] + ResNet-50 | 90.81 | 89.46 | 90.14 | |
| CNN-SS [26] + ResNet-50 | 90.51 | 90.58 | 90.54 | |
| Pl-ImS + ResNet-50 | 94.95 | 92.92 | 93.94 |
| Input Images | Model/Method | TPR | PPV | F1-Score |
|---|---|---|---|---|
| Normal | ANN-based [45] | 93.01 | 93.84 | 93.43 |
| EfficientNet B5 [46] | 92.25 | 92.64 | 92.45 | |
| SVM-based [47] | 93.15 | 95.78 | 94.47 | |
| CNN-GLS [48] | 92.45 | 96.45 | 94.45 | |
| CNN-SS [26] | 93.49 | 95.04 | 94.27 | |
| Pl-ImC | 94.56 | 97.51 | 96.04 | |
| Pl-ImS + Pl-ImC (proposed) | 98.23 | 97.35 | 97.79 | |
| Missing part | ANN-based [45] | 89.57 | 90.20 | 89.88 |
| EfficientNet B5 [46] | 90.04 | 90.40 | 90.22 | |
| SVM-based [47] | 89.13 | 89.71 | 89.42 | |
| CNN-GLS [48] | 89.00 | 90.84 | 89.92 | |
| CNN-SS [26] | 89.90 | 90.32 | 90.11 | |
| Pl-ImC | 90.14 | 90.90 | 90.52 | |
| Pl-ImS + Pl-ImC (proposed) | 95.44 | 94.82 | 95.13 | |
| Little wet leaf with small water drop | ANN-based [45] | 87.31 | 87.97 | 87.64 |
| EfficientNet B5 [46] | 87.93 | 87.46 | 87.70 | |
| SVM-based [47] | 87.41 | 87.00 | 87.20 | |
| CNN-GLS [48] | 87.26 | 87.27 | 87.26 | |
| CNN-SS [26] | 87.16 | 87.35 | 87.25 | |
| Pl-ImC | 88.70 | 89.77 | 89.24 | |
| Pl-ImS + Pl-ImC (proposed) | 95.95 | 93.66 | 94.80 | |
| Drenched leaf with large water drop | ANN-based [45] | 90.56 | 95.20 | 92.88 |
| EfficientNet B5 [46] | 91.48 | 95.09 | 93.28 | |
| SVM-based [47] | 90.77 | 95.30 | 93.04 | |
| CNN-GLS [48] | 90.84 | 95.88 | 93.36 | |
| CNN-SS [26] | 91.33 | 96.08 | 93.71 | |
| Pl-ImC | 92.37 | 96.17 | 94.27 | |
| Pl-ImS + Pl-ImC (proposed) | 97.18 | 96.15 | 96.66 | |
| Dust | ANN-based [45] | 91.37 | 88.34 | 89.85 |
| EfficientNet B5 [46] | 91.07 | 88.54 | 89.81 | |
| SVM-based [47] | 91.09 | 87.34 | 89.21 | |
| CNN-GLS [48] | 91.46 | 88.30 | 89.88 | |
| CNN-SS [26] | 91.97 | 87.74 | 89.85 | |
| Pl-ImC | 93.76 | 88.27 | 91.02 | |
| Pl-ImS + Pl-ImC (proposed) | 96.57 | 94.42 | 95.49 | |
| Average | ANN-based [45] | 90.36 | 91.11 | 90.74 |
| EfficientNet B5 [46] | 90.55 | 90.83 | 90.69 | |
| SVM-based [47] | 90.31 | 91.03 | 90.67 | |
| CNN-GLS [48] | 90.20 | 91.75 | 90.97 | |
| CNN-SS [26] | 90.77 | 91.31 | 91.04 | |
| Pl-ImC | 91.91 | 92.52 | 92.22 | |
| Pl-ImS + Pl-ImC (proposed) | 96.67 | 95.28 | 95.97 |
| Model | Processing Time (Unit: ms) | GFLOPs | # Parameters (unit: Mega) | Model Size (Unit: MB) |
|---|---|---|---|---|
| ANN-based [45] | 122.7 | 108.4 | 5.4 | 24.7 |
| EfficientNet B5 [46] | 135.8 | 115 | 30 | 56.4 |
| CNN-GLS [48] | 118.2 | 92.9 | 3.1 | 30.4 |
| CNN-SS [26] | 110.4 | 91.2 | 2.5 | 23.2 |
| Pl-ImS + Pl-ImC (proposed) | 151.4 | 131.2 | 123.0 | 62.0 |
| # | Device/Chipset | Architecture | Year | Estimated Time (ms) |
|---|---|---|---|---|
| 1 | GTX Titan X (ours) | Maxwell | 2015 | 151.4 |
| 2 | GTX 1060 6GB | Pascal | 2016 | 204.8 |
| 3 | GTX 1070 | Pascal | 2016 | 156.2 |
| 4 | GTX 1080 | Pascal | 2016 | 113.9 |
| 5 | RTX 2080 Ti | Turing | 2018 | 38.1 |
| 6 | GTX 1650 | Turing | 2019 | 302.8 |
| 7 | RTX 2060 | Turing | 2019 | 78.5 |
| 8 | Snapdragon 865 (Galaxy S20) | Android (Adreno 650) | 2020 | 25,233.3 |
| 9 | RTX 3090 | Ampere | 2020 | 28.7 |
| 10 | Jetson Xavier NX (FP16) | Volta | 2020 | 3028.0 |
| 11 | Snapdragon 888 (Galaxy S21) | Android (Adreno 660) | 2021 | 18,925.0 |
| 12 | RTX 3060 | Ampere | 2021 | 79.7 |
| 13 | Apple A15 Bionic (iPhone 13) | iOS (Neural Engine) | 2021 | 9462.5 |
| 14 | RTX 4090 | Ada Lovelace | 2022 | 12.3 |
| 15 | Apple M2 (iPad Pro/MacBook) | macOS (Neural Eng.) | 2022 | 1009.3 |
| 16 | Snapdragon 8 Gen 2 (Galaxy S23) | Android (Adreno 740) | 2022 | 12,616.7 |
| 17 | Apple A16 Bionic (iPhone 14) | iOS (Neural Engine) | 2022 | 8411.1 |
| 18 | Jetson Orin Nano (INT8) | Ampere | 2023 | 1514.0 |
| 19 | RTX 4060 | Ada Lovelace | 2023 | 67.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Batchuluun, G.; Kim, S.G.; Kim, J.S.; Park, K.R. Segmentation-Based Classification of Plants Robust to Various Environmental Factors in South Korea with Self-Collected Database. Horticulturae 2025, 11, 843. https://doi.org/10.3390/horticulturae11070843
Batchuluun G, Kim SG, Kim JS, Park KR. Segmentation-Based Classification of Plants Robust to Various Environmental Factors in South Korea with Self-Collected Database. Horticulturae. 2025; 11(7):843. https://doi.org/10.3390/horticulturae11070843
Chicago/Turabian StyleBatchuluun, Ganbayar, Seung Gu Kim, Jung Soo Kim, and Kang Ryoung Park. 2025. "Segmentation-Based Classification of Plants Robust to Various Environmental Factors in South Korea with Self-Collected Database" Horticulturae 11, no. 7: 843. https://doi.org/10.3390/horticulturae11070843
APA StyleBatchuluun, G., Kim, S. G., Kim, J. S., & Park, K. R. (2025). Segmentation-Based Classification of Plants Robust to Various Environmental Factors in South Korea with Self-Collected Database. Horticulturae, 11(7), 843. https://doi.org/10.3390/horticulturae11070843