1. Introduction
According to the United Nations Food and Agriculture Organization (FAO), global apple production has continued to grow over the past decade, reaching 82.934 million tons in 2022 [
1]. However, apple harvesting faces significant challenges due to declining rural labor forces. In China, the production cost per hectare of apple orchards is approximately CNY 7672, with labor costs accounting for approximately CNY 4030, representing 52.5% of the total expenditure [
2]. Manual apple harvest remains a laborious and costly process, particularly when orchards contain large numbers of trees that require to be harvested. This problem is exacerbated by rising labor costs and a shrinking pool of skilled workers [
3]. Therefore, there is an urgent need to investigate apple-harvesting robots to achieve efficient and cost-effective fruit picking. A harvesting robot typically comprises two primary subsystems: a vision system and an end effector system [
4]. The vision system guides the end effector of the robot to detect and locate apples for precise picking from trees [
5].
In recent years, foundation models and generative AI have shown remarkable progress in robotic control, exemplified by approaches like Robotics Transformers (RT-X) that generate motor actions directly from visual inputs [
6] and Physical Intelligence’s pi-series for embodied agents [
7]. However, these data-intensive frameworks face significant deployment challenges in agricultural settings. Limited computational resources, sparse task-specific training data, and stringent real-time requirements in orchard environments necessitate more streamlined solutions. Recent studies [
8,
9] highlight this gap, indicating that lightweight, domain-optimized perception modules remain critical for agricultural robotics. Intelligent machine vision-based detection technologies have significantly improved the recognition accuracy and positioning efficiency of agricultural harvesting robots for apple targets. Regarding the optimization of visual positioning systems, Zhao et al. implemented fruit spatial positioning using a CCD-based monocular color vision system, with experiments demonstrating a picking success rate of 77% [
10]. Abeyrathna et al. developed a composite perception system integrating an RGB-D camera with a single-point laser sensor, achieving positioning accuracy within ±2 cm error margins (excluding occluded targets) [
11]. In the field of deep learning applications, the fruit detection system developed by Zhang’s team exhibited remarkable time-efficiency advantages, requiring only 0.3 s to complete the recognition and positioning of all fruits in a single image [
12]. Gené-Mola et al. innovatively employed mobile terrestrial laser scanning (MTLS) technology to acquire 3D point cloud data and constructed a detection algorithm combining apparent reflectance features, achieving an F1-score of 0.86 in complex scenarios [
13]. To address the challenge of occluded target recognition, Yuan et al. proposed an adaptive radius selection strategy integrated with the Random Sample Consensus (RANSAC) algorithm, which effectively improved the detection accuracy of overlapping fruits while maintaining an average processing time below 50 ms per frame [
14]. These research achievements provide reliable technical support for automated apple harvesting.
Binocular positioning has emerged as a widely adopted positioning method, offering biologically inspired principles, broader applicability, and lower hardware costs compared to other vision-based positioning approaches [
15]. While this method is inherently constrained by its heavy reliance on feature matching, which may be susceptible to challenges such as textureless surfaces [
16], such limitations rarely occur under typical agricultural harvesting robot operational conditions with natural illumination and can thus be considered negligible. Binocular vision demonstrates favorable performance in efficiency and accuracy while maintaining a simple system architecture, making it highly suitable for target recognition and positioning tasks [
17]. Consequently, integrating binocular positioning into agricultural robots’ perception systems represents a viable solution. Seminal work by Takahashi et al. pioneered the application of binocular stereo vision for apple harvesting in fruit recognition research, establishing a foundational framework for subsequent studies [
18]. Williams et al. designed a quadrupedal kiwifruit-harvesting robot employing binocular vision, achieving a visual recognition success rates of 76.3–89.6% [
19]. Furthermore, Lei et al., Luo et al., Yu et al., and Zhao et al. have successfully employed binocular positioning to obtain fruit 3D coordinates, collectively confirming the suitability of binocular vision for agricultural harvesting robots [
20,
21,
22,
23].
Prior to apple positioning, harvesting robots must first identify apples within binocular images. Common techniques for separating apples from backgrounds include object detection, semantic segmentation, and instance segmentation. However, conventional detection and segmentation methods often lack robustness in most orchard scenarios. Henila et al. proposed a Fuzzy Cluster-Based Thresholding (FCBT) method for apple fruit sorting [
24]. Ibarra et al. developed a Color Dominance-Based Polynomial Optimization Segmentation approach, primarily designed to identify leaves and fruits on tomato plants [
25]. Fu et al. created an image processing algorithm leveraging the color and shape features of kiwifruits and their calyxes to separate linearly clustered fruits [
26]. Mizushima and Lu introduced segmentation methods combining support vector machines with Otsu’s algorithm [
27,
28,
29]. While traditional image processing algorithms are computationally efficient to implement, their detection and segmentation accuracy becomes susceptible to variations in fruit/surface coloration, illumination conditions, camera perspectives, and camera-to-fruit distances [
30,
31]. The heterogeneous characteristics of orchard fruits and complex background variations impose heightened demands on image detection and segmentation technologies.
Compared to traditional image processing algorithms relying on manual feature design, target detection methods based on Convolutional Neural Networks (CNNs) have significantly enhanced object recognition performance in complex agricultural scenarios through autonomous learning mechanisms and multi-level feature fusion advantages [
32,
33]. With the advancement of deep learning technologies, researchers have developed various network models for crop target detection and semantic segmentation tasks [
33,
34,
35,
36,
37,
38,
39]. However, semantic segmentation techniques still suffer from inherent limitations in intra-class object differentiation capabilities [
40]. To address this, instance segmentation methods capable of distinguishing individual differences have emerged, providing refined solutions for overlapping target recognition through pixel-level positioning and instance boundary delineation. In apple-harvesting applications, Gené-Mola et al. developed a Fuji apple segmentation model based on the Mask R-CNN framework, achieving synchronized optimization with 0.86 accuracy and F1-score on 2D RGB images [
41]. The Wang team innovatively implemented a DeepSnake architecture for apple detection systems, elevating the comprehensive recognition accuracy to 95.66% [
42]. Kang et al. integrated a real-time instance segmentation model with a harvesting robot system, ultimately achieving an over 80% harvesting success rate [
43]. Notably, instance segmentation not only provides pixel-level descriptions of target contours but also effectively resolves positioning challenges for overlapping fruits through inter-instance differentiation mechanisms, demonstrating superior engineering applicability in automated orchard harvesting operations.
Regarding the harvesting system design for apple-picking robots, Huang et al. achieved 76.97% harvesting success at 7.29 s/fruit using dual-arm vision and genetic algorithms, improving efficiency by 150% over single-arm systems [
44]. Xie et al. reduced the operation time by 3.1% in 50-target scenarios via deep reinforcement learning with self-attention for spatial constraints [
45]. Chen et al. attained 91.2% grasp success (3 pp higher than PID) using FNN-SMC control to suppress joint vibration [
46]. Zhang et al. developed a nonlinear motion control robotic arm, integrated with an air-electric hybrid vacuum end-effector, to achieve the smart separation of apples [
12]. Zhang et al. proposed a novel perception algorithm tailored for apple picking, enabling rapid identification and precise localization of apples. He also developed a four-degree-of-freedom (4-DOF) robotic arm and a flexible vacuum end-effector [
47].
Although significant progress has been made in fruit-picking robots, current vision-based localization methods often face a trade-off between high accuracy and cost-effectiveness. To address these challenges, this study proposes a visual localization method for apple-picking robots that integrates an improved Mask R-CNN with binocular vision. The Intersection over Union (IoU) for apple detection and segmentation using the improved Mask R-CNN was calculated. Additionally, the Coefficient of Variation (CoV) and Positioning Accuracy (PA) were computed to evaluate the localization performance of the proposed method. Furthermore, 70 picking experiments designed for varying occlusion levels were conducted using a custom-developed apple-picking robot to validate the method’s effectiveness. This research not only provides a novel solution for intelligent fruit picking but also offers valuable insights for the development of low-cost, high-performance robotic vision systems in agricultural applications.
2. Materials and Methods
2.1. Image Acquisition
The experimental images were captured using a ZED2i stereo camera (Stereolabs, San Diego, CA, USA). The ZED2i has two sensors (
Figure 1). A total of 1000 apple images were acquired under varying conditions, including different time periods (morning, afternoon, and night), diverse illumination intensities (sunny and cloudy conditions), as well as varying degrees of overlap, occlusion, and oscillation interference. The images were stored in PNG format with a resolution of 1280 × 960.
To avoid singularity in the image samples and ensure the dataset encompasses apple images under diverse natural conditions (see
Figure 2), 900 images were randomly selected for training and parameter optimization of the Mask R-CNN model, with 90% allocated to the training set and 10% to the validation set. After training, the remaining 100 images were utilized for testing to evaluate the performance of the trained model.
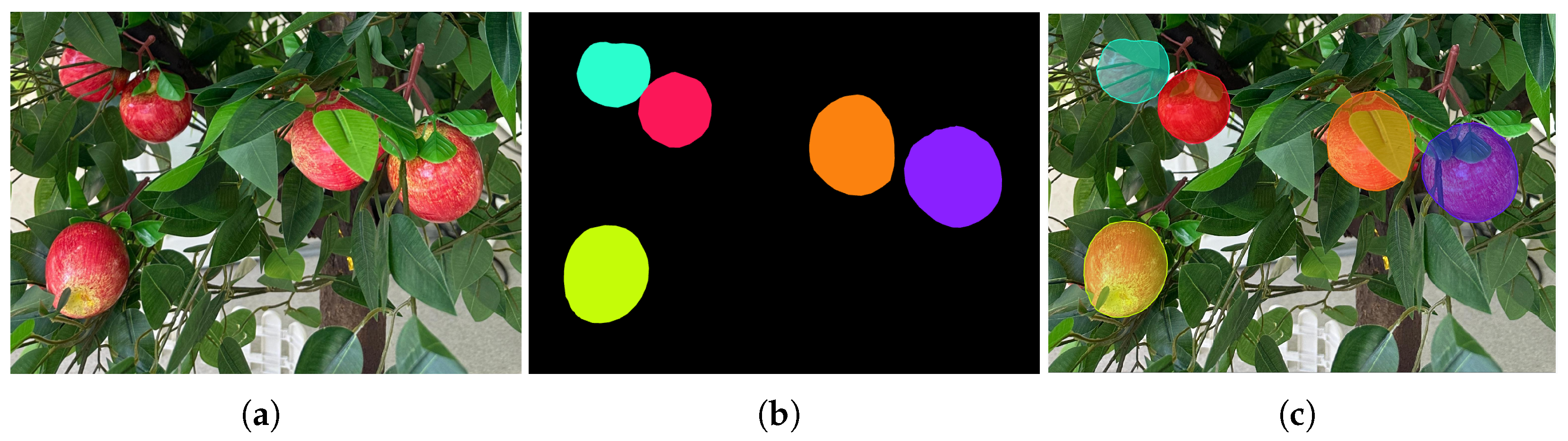
The experimental data were annotated using the image annotation tool Labelme to generate mask images of apples. These mask images were subsequently employed to compute backpropagation losses and optimize model parameters during training. Additionally, the performance of the trained model in instance segmentation tasks was assessed by comparing annotated mask images with predicted mask results. Fruit regions in the images were labeled, while the remaining areas were designated as background by default. The annotated apple images are shown in
Figure 3.
2.2. Training Platform
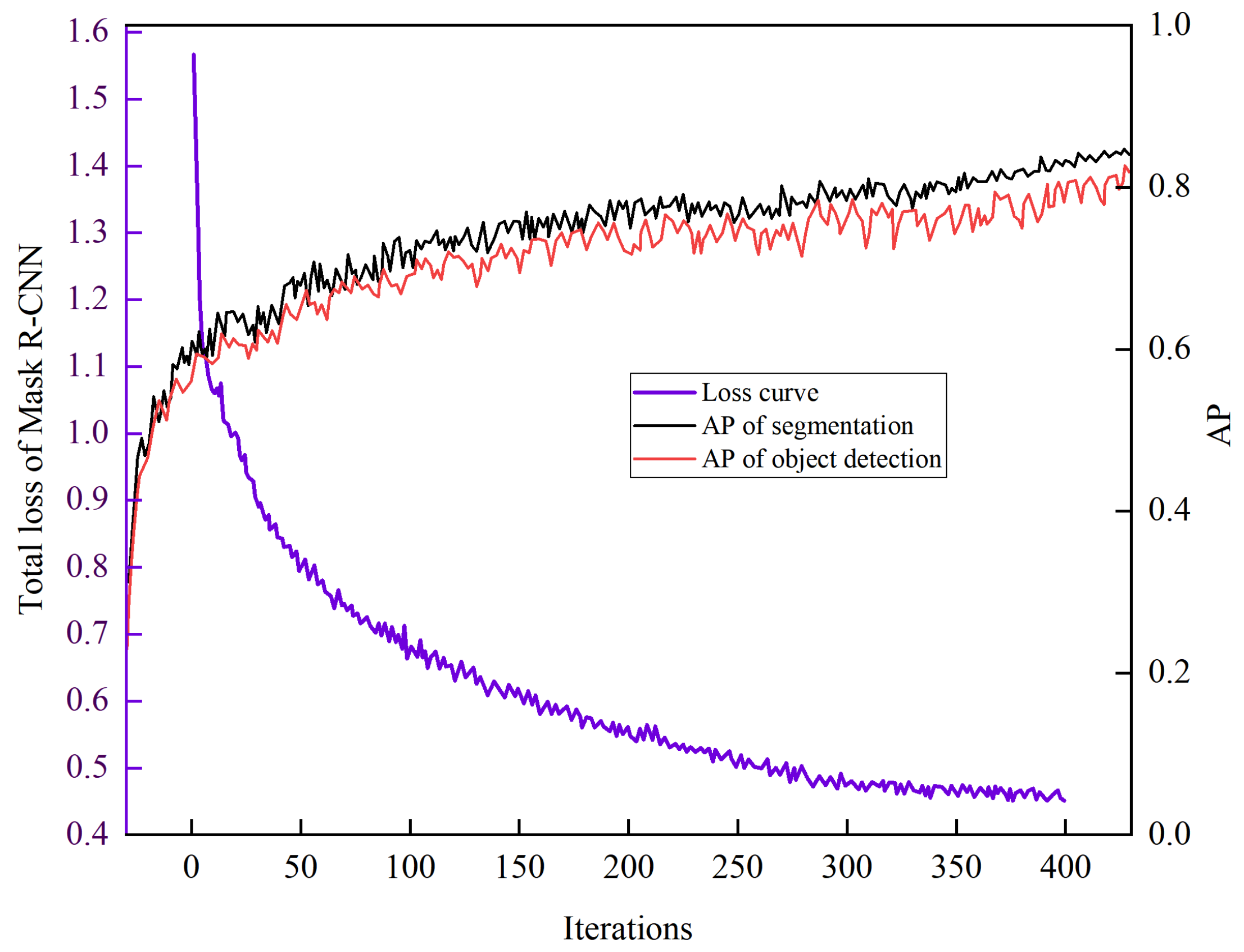
The training platform included a desktop computer with an Intel Core i7-14650HX (5.20 GHz) 16-core CPU, a GeForce GTX 4060 8 GB GPU, and 16 GB of memory, running on a Windows 10 64-bit system. Software tools used included CUDA 11.0.194, CUDNN 8.0.5, Python 3.9.1, and Numpy 1.20.0. The experiments were implemented in the TensorFlow framework. Detection speed was measured with the same computer hardware.
2.3. Deep Learning Model
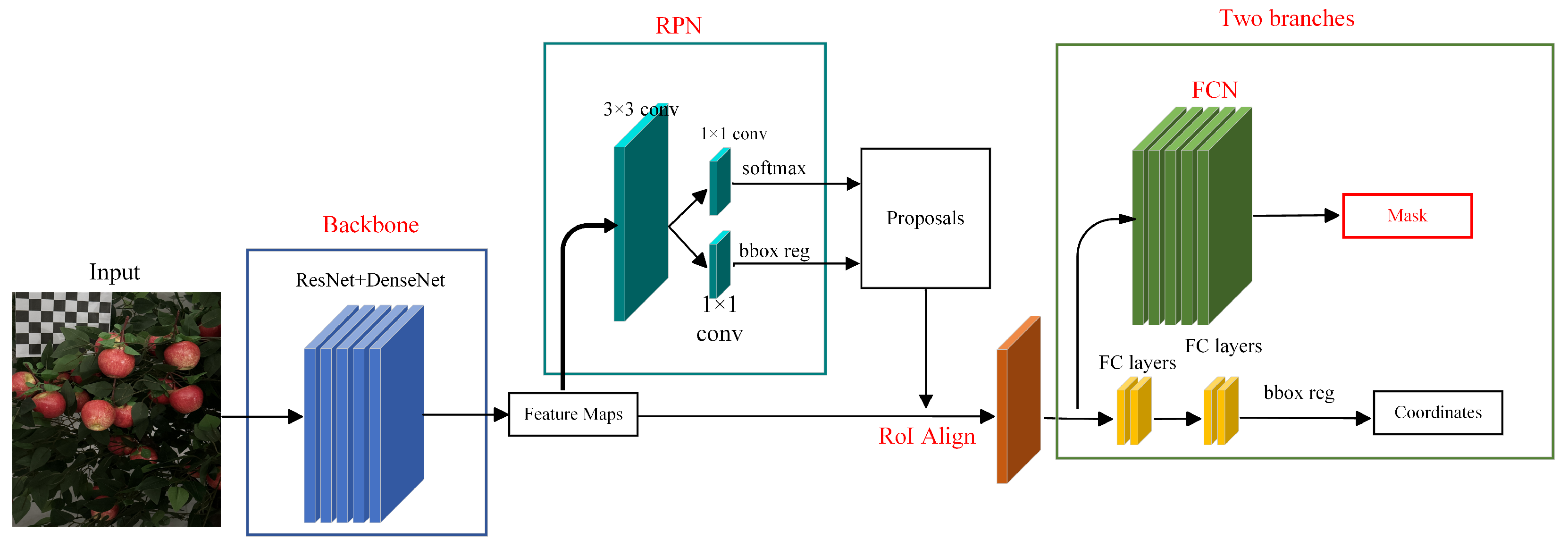
Mask R-CNN represents a state-of-the-art method in object detection, extending the Faster R-CNN framework by incorporating an additional branch at the model’s terminal to achieve instance segmentation for each output proposal through fully connected (FC) layers. To enhance its suitability for real-time apple fruit segmentation, several adjustments and improvements were implemented in this work. A ResNet-DenseNet hybrid architecture was proposed as a replacement for the original backbone network to improve feature extraction. This modification enhances feature transferability and reusability while achieving superior performance with fewer parameters. Furthermore, since our objective focuses on apple recognition and segmentation in complex backgrounds—where the final segmentation output involves only a single class and does not require distinguishing between object categories—the classification branch within the multi-task framework was eliminated. A dedicated “apple” class was defined to streamline computational efficiency and minimize losses. The overall model architecture is depicted in
Figure 4.
2.3.1. Feature Extraction (ResNet + DenseNet)
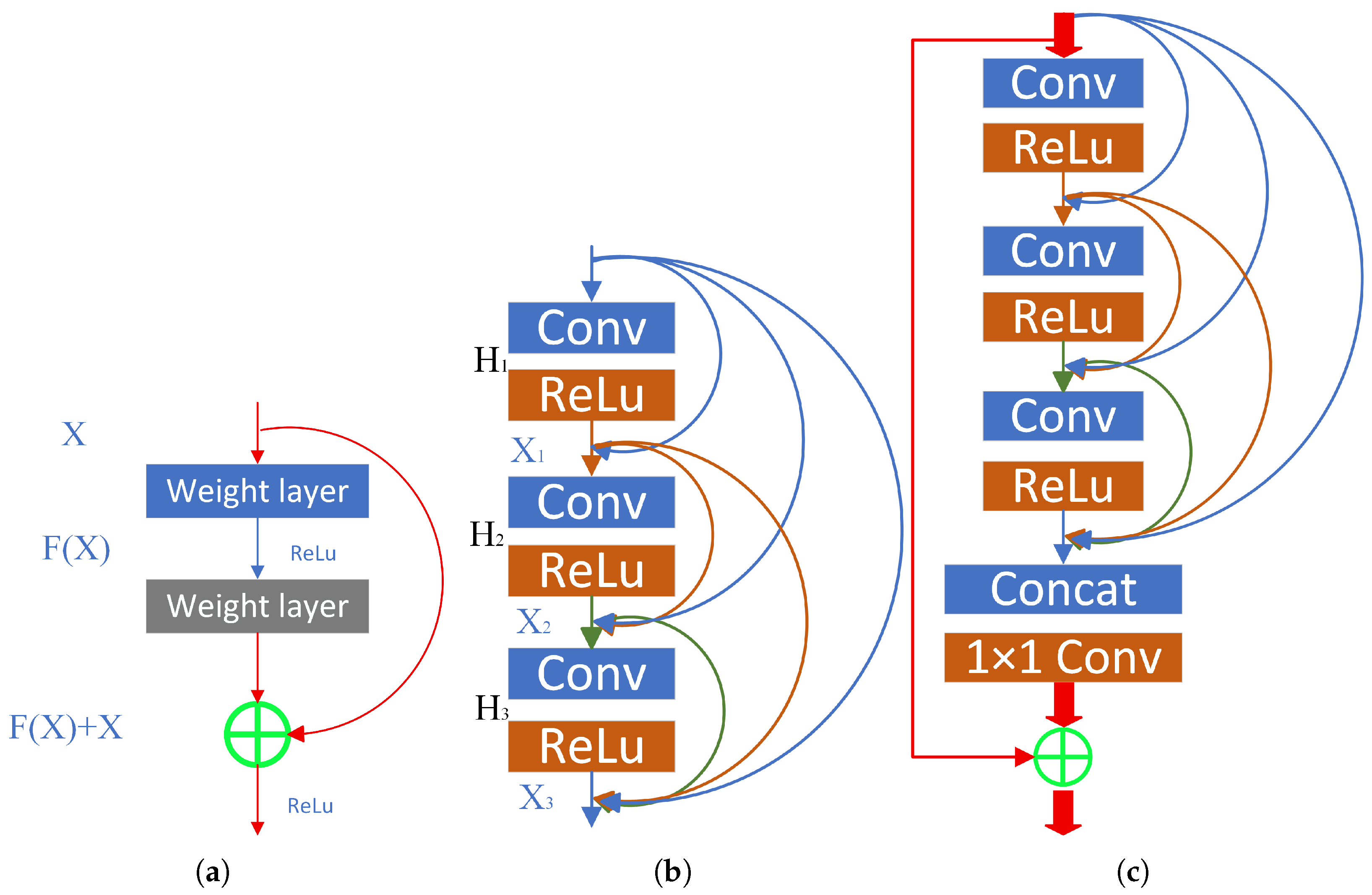
Convolutional networks of varying depths can be constructed by designing distinct weight layers for image feature extraction. However, when conventional CNN networks exceed a certain depth, training error increases with additional convolutional layers, leading to reduced classification accuracy on test datasets. ResNet addresses this challenge by learning residual representations between inputs and outputs through multi-layer parameters, significantly enhancing training speed and prediction accuracy in deep networks. Its core innovation lies in establishing “shortcut connections” (skip connections) between layers, facilitating gradient backpropagation during training to enable deeper architectures. Nevertheless, during practical training, features from excessively small regions may be neglected due to resolution reduction during convolution. To better preserve small-region features, DenseNet—inspired by ResNet—is designed such that each layer directly receives outputs from all preceding layers. By connecting all layers in a feed-forward manner, DenseNet enhances feature reuse at all levels compared to ResNet with Feature Pyramid Networks (FPNs). This strengthens feature propagation and reuse, particularly beneficial for detecting occluded or undersized targets. Consequently, this study employs a backbone network integrating ResNet (to deepen training capability) and DenseNet (to retain low-dimensional features) for feature extraction. Each Residual Dense Unit comprises multiple convolutional layers and ReLU activations. Its output establishes dense connections with every convolutional layer in subsequent units, enabling continuous information flow (as detailed in
Figure 5).
For a convolutional network, let
denote the input image. The network comprises L layers, with each layer implementing a nonlinear transformation
, where
i represents the
layer. The
i layer receives feature maps
from all preceding layers as input, as
where
represents the concatenation of these feature maps. Here,
is defined as a composite function of two sequential operations: a ReLU activation followed by a 3 × 3 convolution (Conv).
Let
and
denote the input and output of the
d-th dense unit, respectively, and
the number of initial feature maps. The output of the
c-th convolutional layer within the unit can be expressed as
Owing to the connectivity between the unit’s input and its convolutional layers, feature maps require compression at the unit’s terminus. Thus, the feature map count regulated by a 1 × 1 convolution is denoted as
where
represents 1 × 1 convolution. The final output of the unit can be expressed as
In this work, we employ a 3-layer dense block architecture, where each block consists of a sequence of BN + ReLU + Conv (3 × 3) operations. The input image resolution is set to 512 × 512 pixels. To maximize information flow between layers, all network layers are directly interconnected. Maintaining feed-forward characteristics, each layer receives the concatenated feature maps from all preceding layers as input, while its own output feature maps serve as inputs to all subsequent layers. Following the dense blocks, a transition layer is incorporated, comprising a 1 × 1 convolutional kernel with 4k channels, where k denotes the growth rate. Setting k = 4 results in each dense layer produces feature maps with a dimensionality of 4.
2.3.2. Generation of RoIs and RoIAlign
Feature extraction of apple images is performed using a hybrid ResNet-DenseNet backbone, generating corresponding feature maps. The output from this backbone network serves as input to the Region Proposal Network (RPN), which produces candidate object regions with associated probability scores. To address scale variation across images (caused by varying shooting distances) and occlusion challenges (including vertical/horizontal overlapping structures), we employ three anchor scales (16 × 16, 64 × 64, 128 × 128) and three aspect ratios (1:1, 1:2, 2:1). Within the RPN, classification (CLS) and bounding-box regression (BBR) branches are randomly initialized to generate nine anchors per sliding-window position. These anchors correspond to a 2 × 9 probability matrix (objectness scores) and a 4 × 9 coordinate matrix (bounding-box vertices). After processing through the RPN (adding minimal computational overhead equivalent to a two-layer network), preliminary proposals are generated. These proposals are mapped onto the feature maps from the preceding stage, forming Regions of Interest (RoIs). The RoIs and their corresponding feature maps are fed into RoIAlign—a technique proposed to enhance pixel-accurate mask prediction. RoIAlign eliminates the harsh quantization of RoIPooling by precisely aligning extracted features with input coordinates through bilinear interpolation.
2.3.3. Target Detection and Instance Segmentation (FCN)
Following RoIAlign processing, instance segmentation is performed using a Fully Convolutional Network (FCN). While traditional Mask R-CNN employs three parallel branches for classification, bounding-box regression, and instance segmentation, this work streamlines the architecture to achieve single-target apple recognition in complex backgrounds. Specifically, the classification branch is eliminated to enhance computational efficiency without compromising segmentation accuracy. The adopted FCN provides end-to-end segmentation through an encoder-decoder structure: convolutional layers progressively downsample feature maps, followed by transposed convolutions (deconvolution) that upsample resolution via interpolation. Pixel-wise classification is ultimately applied to generate precise segmentation masks.
Segmentation is performed concurrently with recognition tasks. The Mask R-CNN framework comprises three stages. First, the input image is processed through the backbone network to extract multi-scale feature maps. Subsequently, the Region Proposal Network (RPN) generates candidate object proposals based on these feature maps, which are precisely aligned via the RoI Align layer (employing bilinear interpolation to avoid quantization errors). The aligned features are then fed into two parallel branches: a bounding box regression branch (refining proposal coordinates) and a mask branch (generating pixel-level binary masks using a Fully Convolutional Network, FCN). The final outputs consist of the target’s localized bounding box coordinates and instance segmentation masks.
2.4. The Binocular Calibration and Binocular Positioning Principle
Binocular positioning first requires camera calibration to obtain rectified images, as stereoscopic images exhibit distortions (
Figure 6a). This study employs Zhang’s calibration method [
48]. By capturing multiple images of a planar calibration board (e.g., a checkerboard), the intrinsic parameters (focal length, principal point, distortion coefficients) and extrinsic parameters (pose relationships between the camera and calibration board) are efficiently computed through a combination of closed-form solutions and nonlinear optimization. Subsequently, image distortions from the stereo camera are algorithmically corrected. After rectification, the positions of apples in the left and right images become horizontally aligned (
Figure 6b).
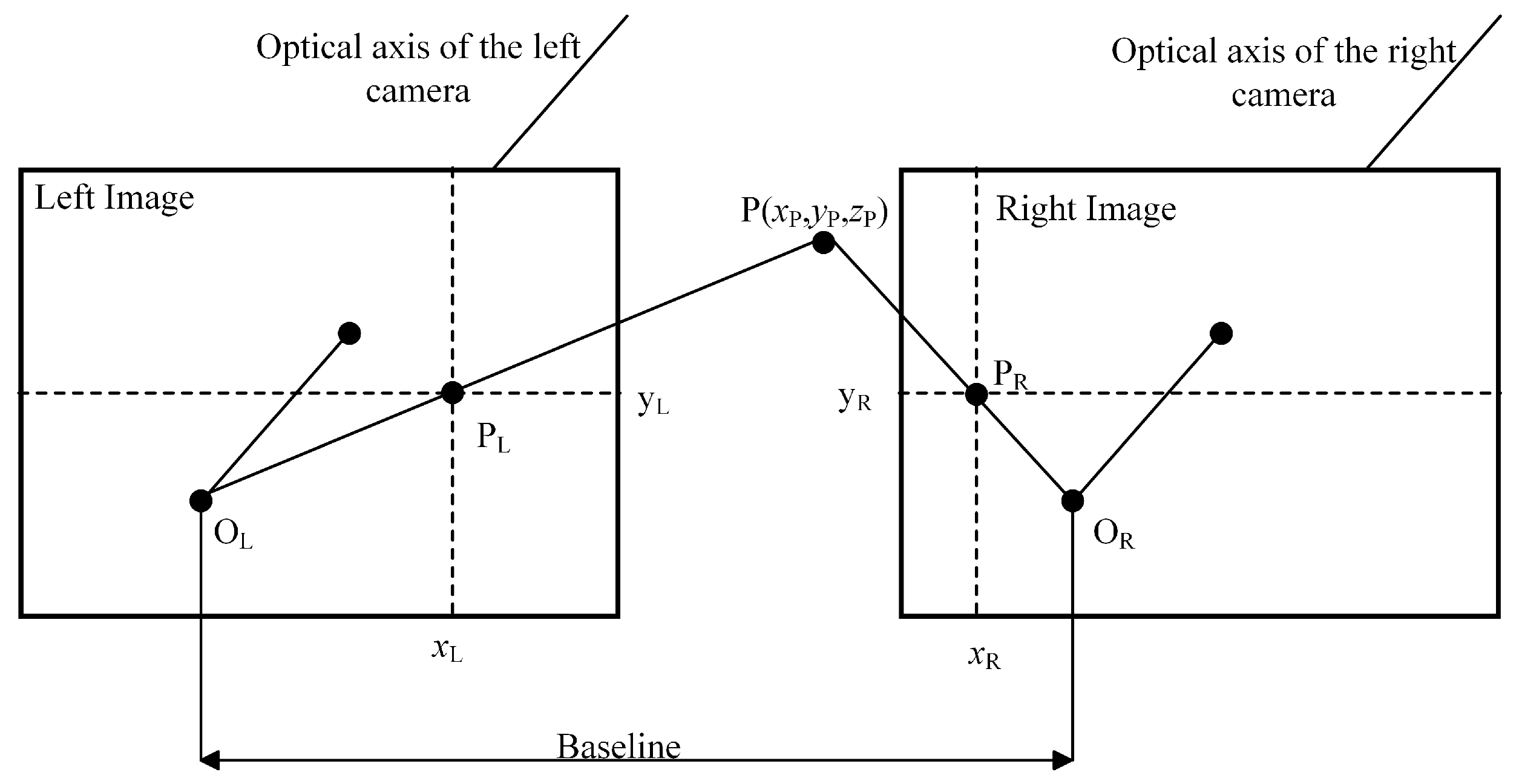
The critical requirement for binocular vision lies in maintaining parallel optical axes and coplanar imaging planes between the two cameras. As illustrated in
Figure 7, the binocular positioning principle employs left (
) and right (
) cameras arranged in a parallel configuration with identical orientation. The
distance between their optical centers and a shared focal length (
f) constitute key system parameters. A spatial feature point
P(
) projects onto the left and right imaging planes as pixel coordinates
(
) and
(
), respectively, with their horizontal coordinate difference defining the
(
). Following triangulation principles, the three-dimensional coordinates of the feature point can be analytically determined through Equations (1)–(3).
It is evident that determining variables such as the focal length f, , and is critically important for further computation of the 3D coordinates of P. Among these, the and f can be directly obtained from the camera specifications. However, must be derived from the pixel coordinates of feature points in the left and right images, which are acquired through stereo matching.
2.5. Apple Stereo Matching
Stereo matching constitutes a critical technology in binocular vision systems. Its fundamental task lies in establishing projective correspondence between corresponding pixels in left and right views to resolve scene depth information through disparity calculation. Current mainstream matching algorithms include region-based Semi-Global Block Matching (SGBM), local window block matching, and feature descriptor-based strategies such as SIFT and SURF [
49,
50]. Addressing the morphological characteristics of apple targets in orchard environments, this study employs a template-matching approach to achieve cross-view association of fruit targets.The core principle of template matching involves sliding a template image over a target image to calculate similarity metrics between the template and each potential region in the target, thereby identifying the optimal match. During the sliding process, the matching cost at each position is computed, forming a matching cost matrix. The extremum positions within this matrix correspond to the matched apple locations.
The template-matching algorithm in the OpenCV vision library, implemented via the cv2.matchTemplate() function, provides six similarity metric-based matching criteria as follows: squared difference (TM_SQDIFF), normalized squared difference (TM_SQDIFF_NORMED), cross-correlation (TM_CCORR) and its normalized form (TM_CCORR_NORMED), as well as the correlation coefficient (TM_CCOEFF) and normalized correlation coefficient (TM_CCOEFF_NORMED). Through quantitative comparative analysis of response characteristics across different matching criteria in fruit imagery, this study found that the normalized squared difference method (TM_SQDIFF_NORMED) demonstrates superior template similarity discrimination under illumination-invariant conditions. Specifically, it achieves 12.6–25.3% higher matching accuracy compared to alternative approaches, proving particularly effective for target association tasks in orchard environments with complex lighting conditions, which was defined in Equation (
4).
The similarity metric
for normalized squared difference matching is calculated as the normalized sum of squared differences between template pixels
and target region pixels
, with its value range constrained to
. Here, 0 indicates perfect matching, while 1 denotes complete dissimilarity. When
persistently resides in the high-value domain, the system automatically activates an invalid match filtering mechanism to address occlusion-induced or cross-view absence of corresponding apple targets. To enhance matching efficiency, this study innovatively introduces a parallel epipolar constraint mechanism. Leveraging the prior knowledge in binocular geometry that the horizontal coordinate of a left-view feature point consistently exceeds its right-view counterpart (
), the template-matching search domain is restricted to ([
],[
]) (illustrated in
Figure 8). This spatial constraint reduces computational complexity by approximately 62.3% compared to conventional full-image search strategies. By eliminating invalid search regions, the proposed method significantly improves algorithmic real-time performance while maintaining matching accuracy.
The instance segmentation results generated by the Mask R-CNN framework exhibit dual representations: geometric positioning information via bounding boxes (BBoxes) and pixel-level contour descriptions through masks. As visualized in
Figure 9, each apple instance’s BBox is defined by its top-left coordinate (
,
) and bottom-right coordinate (
,
), maintaining strict instance-level topological consistency with the corresponding mask matrix.
The template-matching process selects the bounding box (BBox) generated by Mask R-CNN in the left image as the template to search for similar regions in the right image, aiming to identify the most-matching region (i.e., the matching BBox) and thereby establish correspondence between apples in the left and right views. However, since the BBoxes and masks in the right image are independently generated by Mask R-CNN, discrepancies may exist between the matching BBox derived from template matching and the right-image BBox. Consequently, the left BBox and its corresponding mask can only align with the template-matching result (the matched BBox), necessitating a secondary matching operation between the matched BBox and the right-image BBox to achieve their association. Notably, during this secondary matching phase, three types of invalid apple data should be eliminated to ensure data validity:
Apples present only in the left image: Apples detected by Mask R-CNN in the left image (with generated BBoxes and masks) lack corresponding regions in the right image due to template-matching failures (excessive matching cost or absence of similar regions within the search range). This occurs when apples are occluded in the right image or lie outside its field of view. Such apples introduce depth calculation errors, resulting in invalid 3D coordinates.
Apples present only in the right image: Apples detected in the right image (with generated BBoxes and masks) lack corresponding templates in the left image (i.e., undetected by Mask R-CNN in the left image). This arises from occlusion in the left image or template-matching failures. Without template support from the left image, these apples cannot establish correspondence through template matching, thereby introducing spurious targets.
Matched apples undetected in the right image (Mask R-CNN false negatives): While template matching identifies regions in the right image resembling the left template (matching BBox), Mask R-CNN fails to generate corresponding BBoxes and masks. Causes include missed detections by Mask R-CNN in the right image or erroneous classification of background regions as apples by template matching. These apples yield entirely erroneous positioning coordinates.
The secondary matching method involves iterating through all BBoxes in the right image, calculating their Intersection over Union () with the matching BBox, and selecting the right BBox with the maximum as the final matching result. Upon completing secondary matching, the correspondence between BBoxes and masks in the left and right images is definitively established.
2.6. Apple Positioning
After completing stereo matching of apples, the depth information can be derived from the disparity data obtained through stereo matching using binocular positioning principles. The depth map visually represents the spatial distribution of apples and their surrounding environment, providing enhanced visual reference for subsequent apple positioning. The depth information is illustrated in
Figure 10b.
To improve positioning accuracy and reduce errors, four feature points of each apple are selected, and their 3D coordinates are calculated, with the final positioning result determined by averaging these coordinates. The methodology for feature point selection is demonstrated in
Figure 10a. Within the bounding box (BBox) of an apple, a vertical traversal is performed to identify the feature points with the minimum and maximum y-coordinates, while a horizontal traversal locates the points with the minimum and maximum x-coordinates. These four points represent the apple’s extreme positions (leftmost, rightmost, topmost, and bottommost), effectively encompassing its geometric profile and mitigating positioning deviations caused by partial occlusion or irregular shapes.
2.7. Evaluation Criteria of Detection Model
This study evaluates the detection and segmentation performance of improved Mask R-CNN using Intersection over Union (
) and Average Precision (
), as formalized in Equations (5) and (6), respectively.
Here,
refers to the masks or bounding boxes generated by improved Mask R-CNN, while
(ground truth) represents the manually annotated polygonal and rectangular labels for apples in the dataset.
(average precision) denotes the average precision for object detection or segmentation. Precision (
P) and recall (
R) are defined in Equations (7) and (8), respectively.
The terms true positives (), false positives (), and false negatives () are derived by comparing improved Mask R-CNN outputs with ground truth data, representing correctly detected, erroneously detected, and undetected objects, respectively. An threshold of 0.5 was applied for calculating , P, and R.
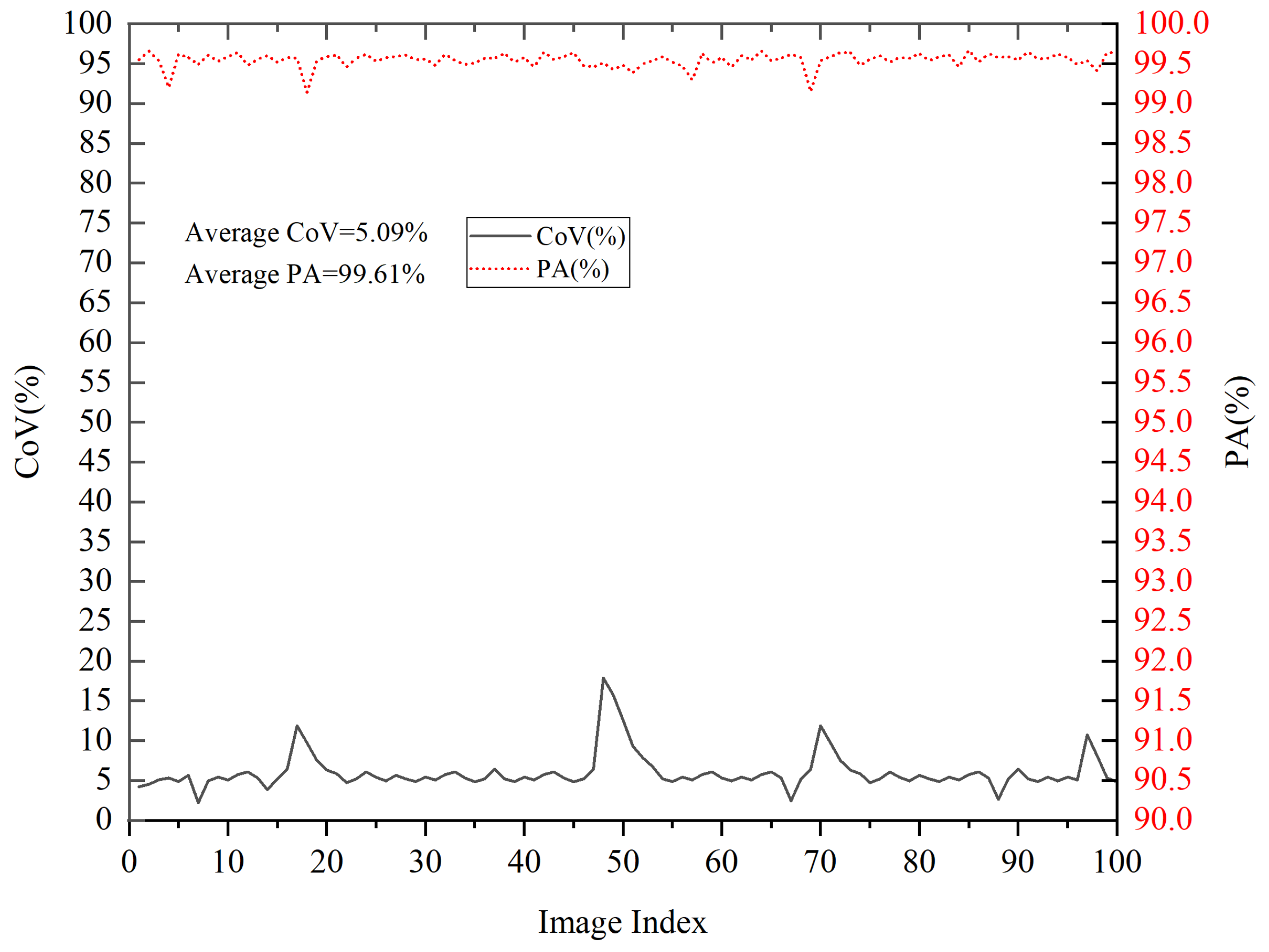
2.8. Evaluation Criteria of Apple Binocular Positioning
This study employs the coefficient of variation (
) and positioning accuracy (
) to evaluate positioning performance. As a dimensionless metric, the
normalizes the standard deviation to the mean, enabling equitable comparison of positioning precision across different apples or datasets. A smaller
indicates that the depth values of the four feature points are closely clustered, reflecting stable positioning results, while a larger
suggests significant discrepancies in depth values, which may lead to unreliable positioning. The mathematical definitions of
and
are provided in Equations (10) and (11), respectively.
Here, S represents the standard deviation of the four feature points for each apple, while denotes the average depth value of these four points. and correspond to the maximum and minimum depth values among the four feature points of each apple. The operator () returns the maximum value among the comma-separated entries within the parentheses.
2.9. Picking Experiment
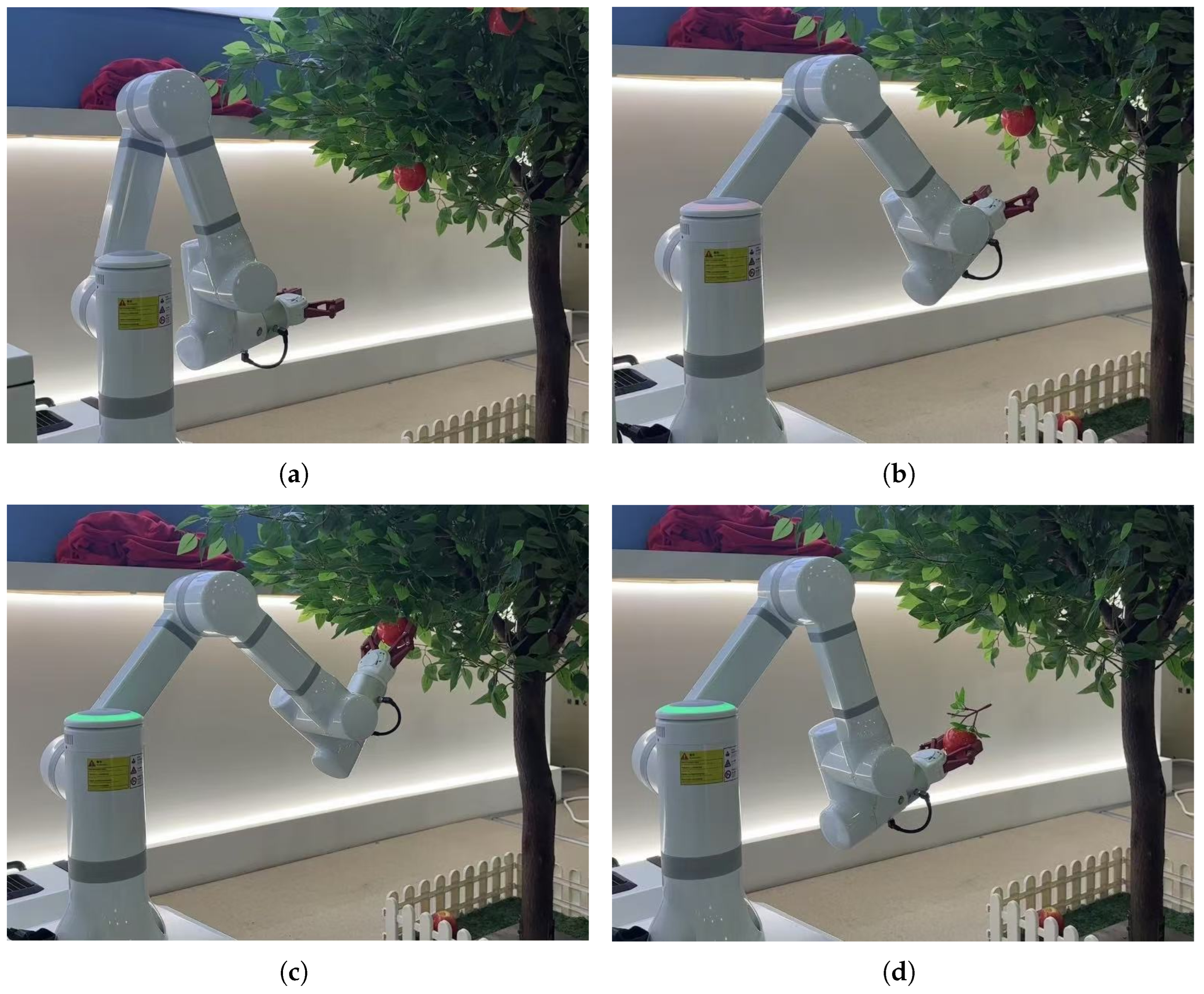
This study conducted apple positioning and picking experiments using a self-designed apple-picking robot, as illustrated in
Figure 11. The apple-picking robotic system developed in this study employs a modular architecture comprising three core functional modules: a mobile chassis, a 6-degree-of-freedom (6-DoF) manipulator, and an end-effector. The crawler-type mobile chassis integrates critical subsystems, including a power supply unit, manipulator control module, and central control system. A custom-designed 6-DoF manipulator is mounted on this chassis, with the end-effector attached to its terminal link to form an integrated picking unit.
The mobile base features a crawler-type chassis composed of a chassis compartment and a crawler locomotion mechanism. The chassis compartment houses environmental sensing systems and motion control units for the robot. The crawler locomotion mechanism integrates load-bearing wheels, drive wheels, tension auxiliary wheels, and belt support wheels. The manipulator incorporates six rotational joints, corresponding to 6 DoF, including the base (Joint 1), shoulder (Joint 2), elbow (Joint 3), wrist 1 (Joint 4), wrist 2 (Joint 5), and wrist 3 (Joint 6). The robotic arm control process first involves path planning within the joint space for the picking manipulator, achieved using the APF-A* algorithm. Subsequently, the required pose information for the robotic arm is transmitted via serial communication to the individual joint actuators. These actuators drive the corresponding joints through the calculated angles, thereby accomplishing the apple-picking task.
The end-effector incorporates a bionic flexible two-finger gripper. Mimicking the joint distribution of a human finger, the gripper base achieves 360° rotation via a brushless DC motor to attain suitable grasping postures. The symmetrical two-finger design adaptively envelops the fruit, increasing the contact area by 40%. The gripper’s opening/closing stroke ranges from 0 to 120 mm, enabling adaptation to apples of varying sizes. Furthermore, the full-stroke opening/closing response time is within 0.5 s, meeting the requirement for rapid apple grasping. Grip force control employs a fuzzy PID adjustment strategy. Real-time adjustments to the gripping force are made based on the magnitude of the pressure error. Concurrently, PID parameters are dynamically updated based on fruit firmness detected by the pressure sensor, effectively maintaining overshoot at a low level.
To validate the effectiveness of the proposed localization method, this approach was implemented on an apple-picking robot for picking experiments. The robot performed individual apple-target picking across 70 experimental trials. To evaluate the localization performance under diverse conditions, these 70 picking operations were further categorized according to varying occlusion scenarios. According to the proportion of fruit occlusion area, it is divided into slight occlusion (occlusion area < 30%), moderate occlusion (30–60%), severe occlusion (60–90%), and complete occlusion (above 90%). Across the 70 picking trials, the occlusion conditions were classified as follows: 10 trials under light occlusion, 20 trials under moderate occlusion, 35 trials under severe occlusion, 5 trials under full occlusion. During picking experiments, the robot’s host computer first processes images of apples captured by binocular cameras. An improved Mask R-CNN model detects the target apples within the images. Subsequently, the 3D coordinates of the apples are calculated based on binocular vision. The host computer then determines the deviation between the target fruit’s coordinates and the image center. This deviation is converted into corresponding joint motion angles for the robotic arm using a specified scaling factor. Path planning for the robotic arm within the joint space is achieved using the APF-A* algorithm. The required pose information for the robotic arm is transmitted via serial communication to the individual joint actuators. These actuators drive the corresponding joints to move by the calculated angles, enabling the robotic arm to approach the target along the planned trajectory. Finally, the claw-type end-effector completes damage-free grasping of the fruit, assisted by the pressure sensor.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}