
High-Precision Complex Orchard Passion Fruit Detection Using the PHD-YOLO Model Improved from YOLOv11n


Abstract
1. Introduction
- (1)
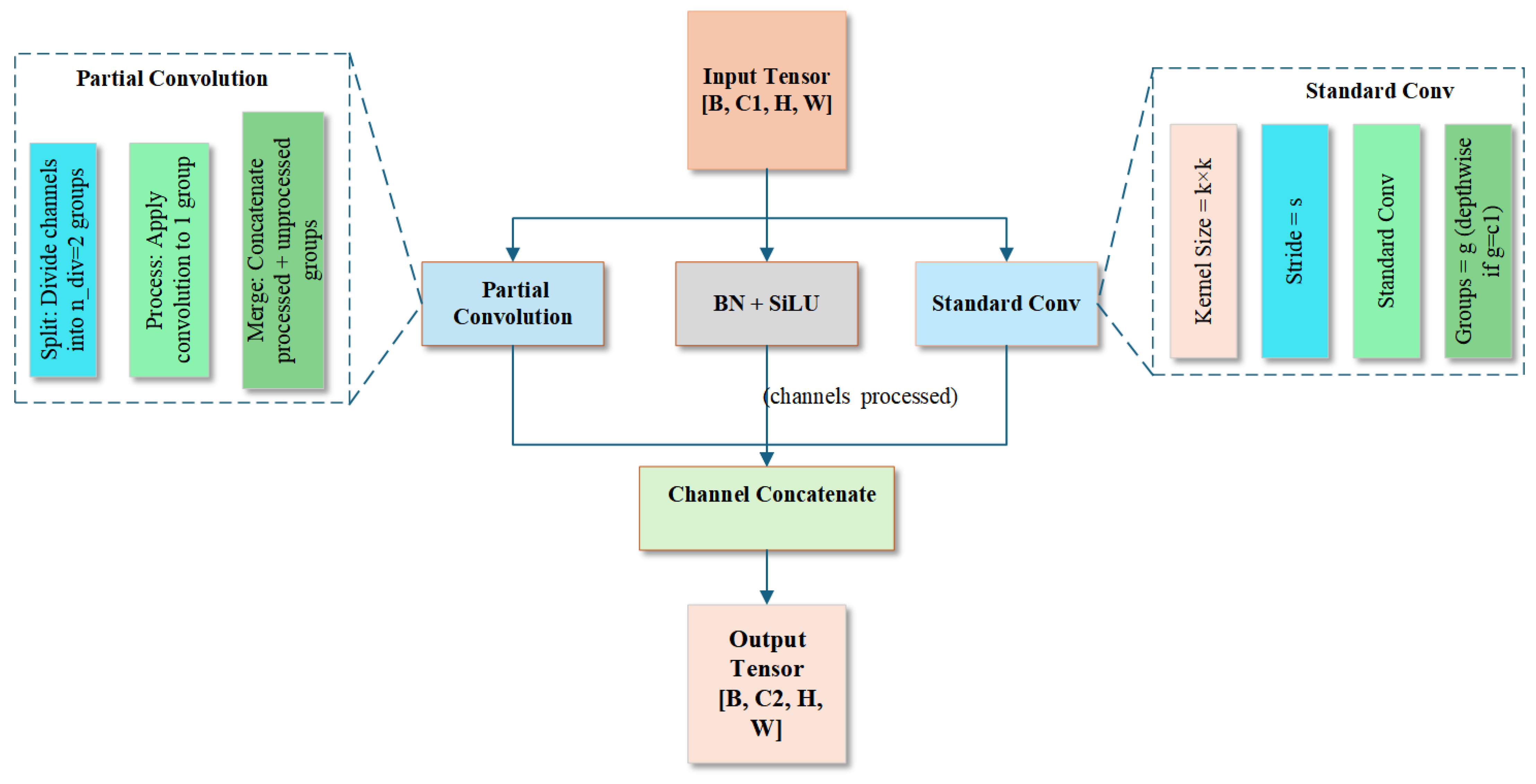
- Designing a novel partial convolution module (ParConv) that employs a channel grouping strategy for independent processing. By decoupling the feature learning process, this approach effectively reduces feature confusion in fruit-dense regions while preserving multi-scale semantic information.
- (2)
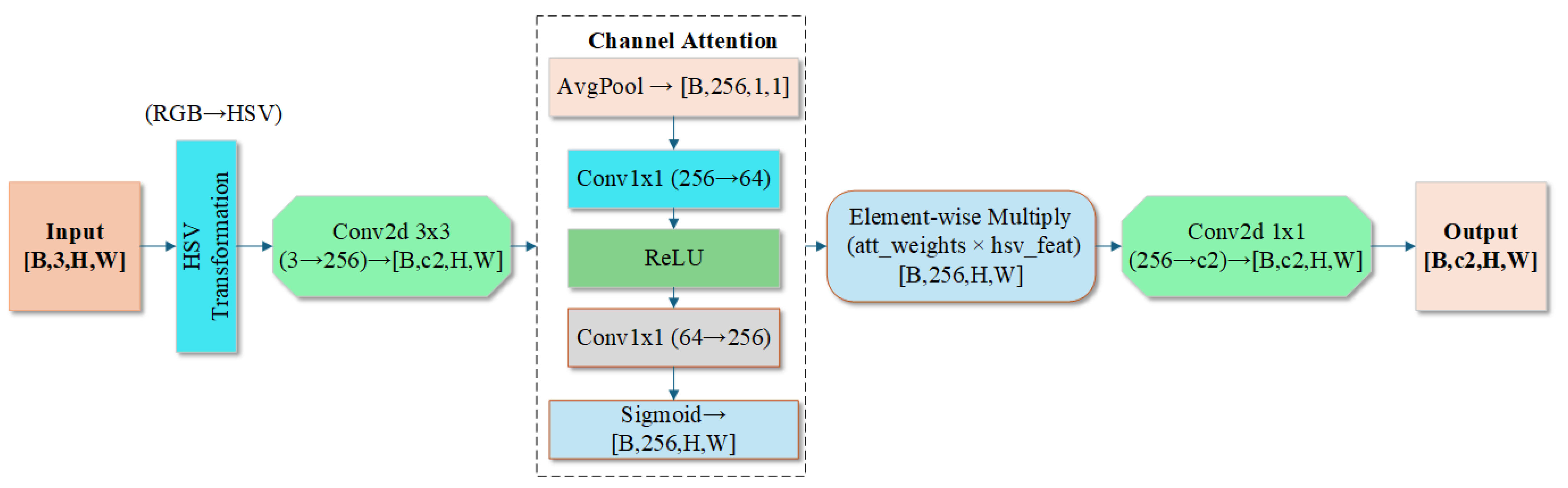
- Developing an HSV Attentional Fusion hybrid attention mechanism that integrates hue, saturation, and brightness features from the HSV color space. This is combined with Halo Attention’s extended receptive field, dynamic channel weighting reconstruction, and spatial pyramid multi-scale fusion to enhance feature discriminability under complex lighting conditions.
- (3)
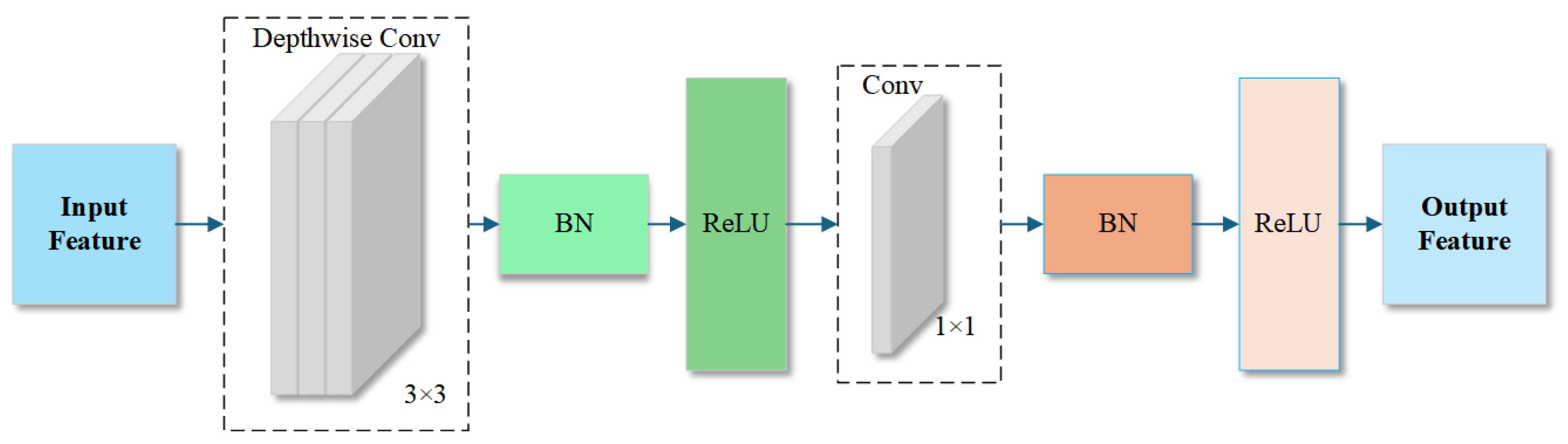
- Reconstructing the backbone network using deep separable convolutions to optimize computational efficiency while maintaining feature expression capabilities significantly, resolving the trade-off between real-time performance and accuracy in mobile device deployments.
2. Materials and Methods
2.1. Datasets
2.2. PHD-YOLO Framework
2.2.1. Network Architecture Design
2.2.2. Novel Partial Convolution
2.2.3. HSV Attentional Fusion
2.2.4. Depth Wise Separable Convolution
3. Results
3.1. Experimental Environment
3.2. Evaluation Indicators
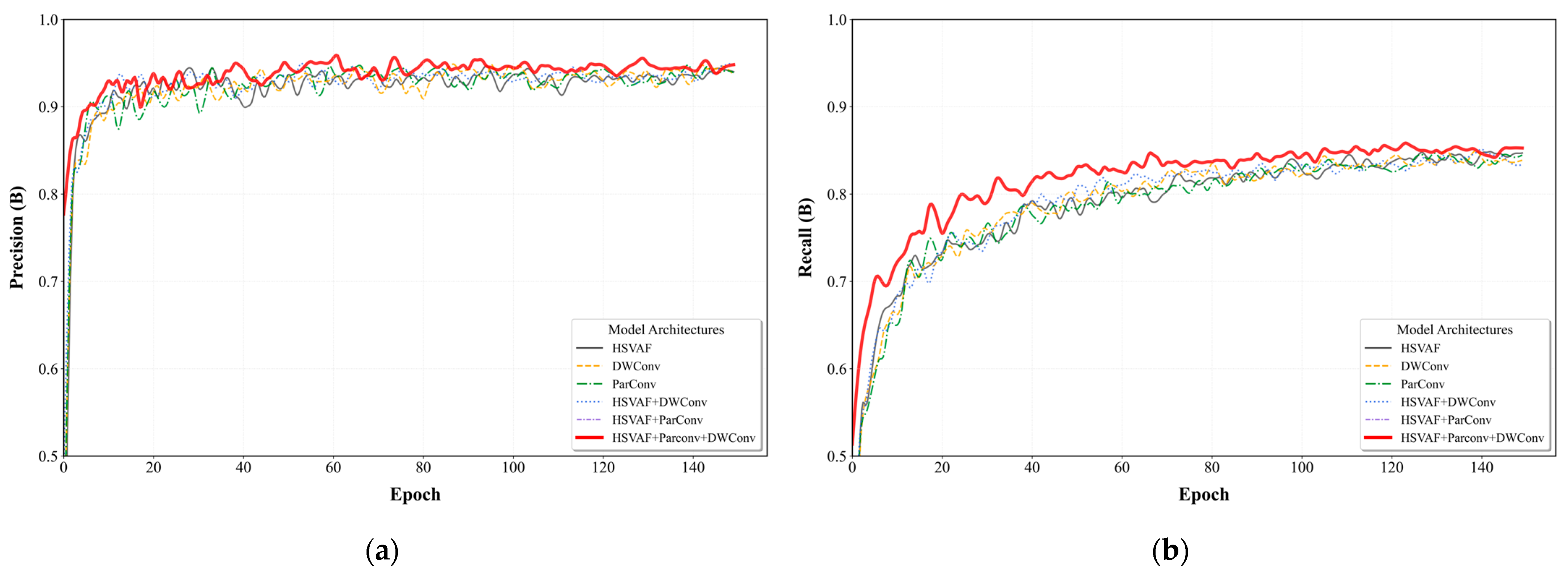
3.3. Ablation Experiment Results and Analysis
3.4. Comparison with State-of-the-Art Models
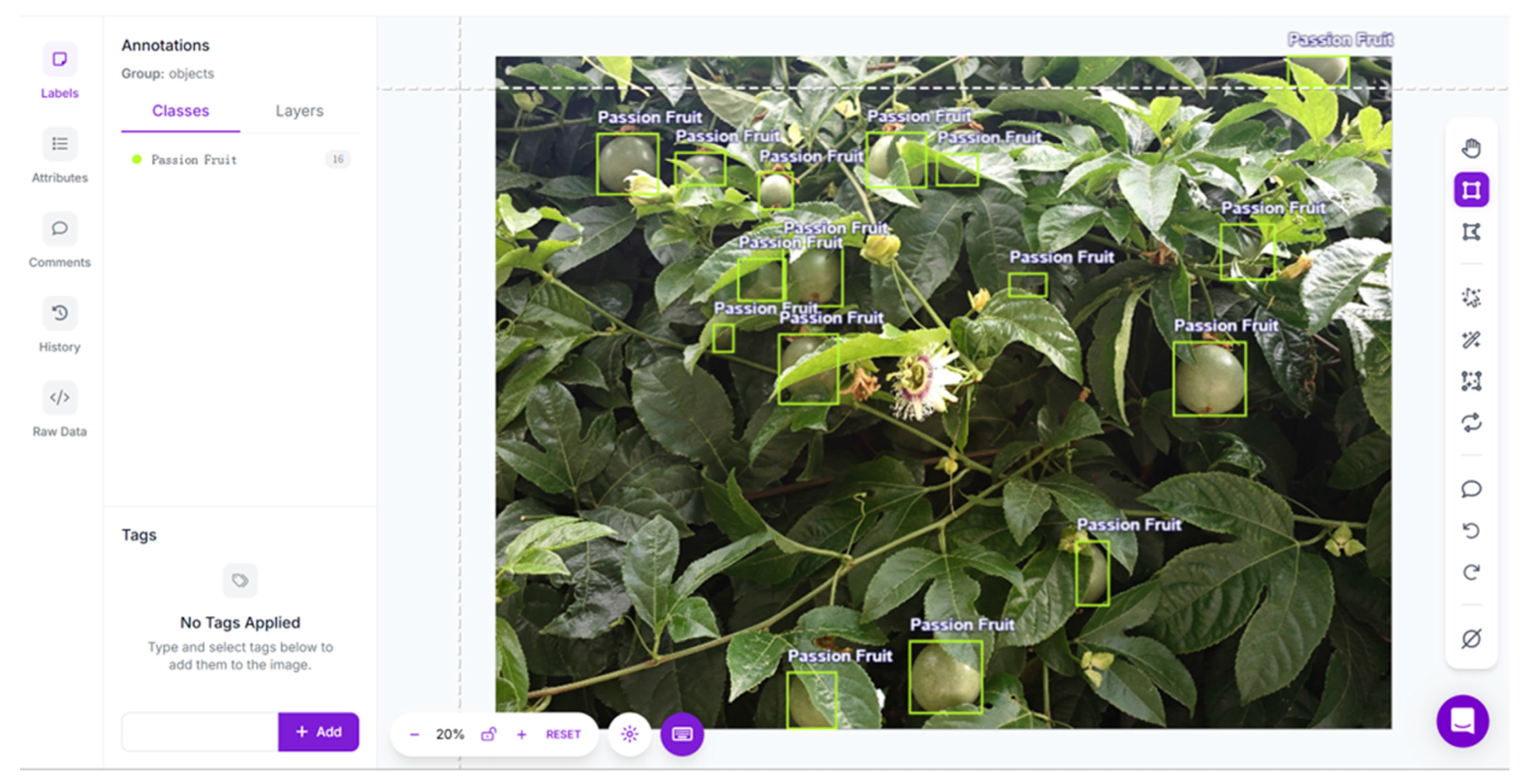
3.5. Comparison of Recognition Effect Before and After Improvement
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ni, X.; Li, C.; Jiang, H.; Takeda, F. Three-dimensional photogrammetry with deep learning instance segmentation to extract berry fruit harvestability traits. ISPRS J. Photogramm. Remote Sens. 2021, 171, 297–309. [Google Scholar] [CrossRef]
- Nan, Y.; Zhang, H.; Zeng, Y.; Zheng, J.; Ge, Y. Intelligent detection of Multi-Class pitaya fruits in target picking row based on WGB-YOLO network. Comput. Electron. Agric. 2023, 208, 107780. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 783–792. [Google Scholar]
- Zhang, X.; Li, J.; Hua, Z. MRSE-Net: Multiscale residuals and SE-attention network for water body segmentation from satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5049–5064. [Google Scholar] [CrossRef]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 6688–6697. [Google Scholar]
- Shen, Y.; Guo, J.; Liu, Y.; Xu, C.; Li, Q.; Qi, F. SMANet: Superpixel-guided multi-scale attention network for medical image segmentation. Biomed. Signal Process. Control 2025, 100, 107062. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhao, Y.; Ju, Z.; Sun, T.; Dong, F.; Li, J.; Yang, R.; Fu, Q.; Lian, C.; Shan, P. Tgc-yolov5: An enhanced yolov5 drone detection model based on transformer, gam & ca attention mechanism. Drones 2023, 7, 446. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Xu, J.; Yang, S.; Liang, Q.; Zheng, Z.; Ren, L.; Fu, H.; Yang, P.; Xie, W.; Yang, D. Transillumination imaging for detection of stress cracks in maize kernels using modified YOLOv8 after pruning and knowledge distillation. Comput. Electron. Agric. 2025, 231, 109959. [Google Scholar] [CrossRef]
- Ling, H.; Tu, Z.; Li, G.; Wang, J. ED-YOLOv8s: An enhanced approach for passion fruit maturity detection based on YOLOv8s. In Proceedings of the 2024 5th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT), Nanjing, China, 29–31 March 2024; pp. 2320–2324. [Google Scholar]
- Chen, Z.; Qian, M.; Zhang, X.; Zhu, J. Chinese Bayberry Detection in an Orchard Environment Based on an Improved YOLOv7-Tiny Model. Agriculture 2024, 14, 1725. [Google Scholar] [CrossRef]
- Liu, Z.; Xiong, J.; Cai, M.; Li, X.; Tan, X. V-YOLO: A Lightweight and Efficient Detection Model for Guava in Complex Orchard Environments. Agronomy 2024, 14, 1988. [Google Scholar] [CrossRef]
- Li, R.; Sun, X.; Yang, K.; He, Z.; Wang, X.; Wang, C.; Wang, B.; Wang, F.; Liu, H. A lightweight wheat ear counting model in UAV images based on improved YOLOv8. Front. Plant Sci. 2025, 16, 1536017. [Google Scholar] [CrossRef]
- Liang, Y.; Jiang, W.; Liu, Y.; Wu, Z.; Zheng, R. Picking-Point Localization Algorithm for Citrus Fruits Based on Improved YOLOv8 Model. Agriculture 2025, 15, 237. [Google Scholar] [CrossRef]
- Liu, Y.; Zheng, H.; Zhang, Y.; Zhang, Q.; Chen, H.; Xu, X.; Wang, G. “Is this blueberry ripe?”: A blueberry ripeness detection algorithm for use on picking robots. Front. Plant Sci. 2023, 14, 1198650. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Xu, S.; Ma, Z.; Fu, H.; Lin, B. Grape clusters detection based on multi-scale feature fusion and augmentation. Sci. Rep. 2024, 14, 22701. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Wang, J.; Jalil, H.; Wang, H. A fast and lightweight detection algorithm for passion fruit pests based on improved YOLOv5. Comput. Electron. Agric. 2023, 204, 107534. [Google Scholar] [CrossRef]
- Sun, Q.; Li, P.; He, C.; Song, Q.; Chen, J.; Kong, X.; Luo, Z. A lightweight and high-precision passion fruit YOLO detection model for deployment in embedded devices. Sensors 2024, 24, 4942. [Google Scholar] [CrossRef]
- Yang, X.; Zhao, W.; Wang, Y.; Yan, W.Q.; Li, Y. Lightweight and efficient deep learning models for fruit detection in orchards. Sci. Rep. 2024, 14, 26086. [Google Scholar] [CrossRef]
- Tu, S.; Huang, Y.; Liang, Y.; Liu, H.; Cai, Y.; Lei, H. A passion fruit counting method based on the lightweight YOLOv5s and improved DeepSORT. Precis. Agric. 2024, 25, 1731–1750. [Google Scholar] [CrossRef]
- Sasagawa, Y.; Nagahara, H. Yolo in the dark-domain adaptation method for merging multiple models. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. pp. 345–359. [Google Scholar]
- Sun, H.; Wang, B.; Xue, J. YOLO-P: An efficient method for pear fast detection in complex orchard picking environment. Front. Plant Sci. 2023, 13, 1089454. [Google Scholar] [CrossRef]
- Codes-Alcaraz, A.M.; Furnitto, N.; Sottosanti, G.; Failla, S.; Puerto, H.; Rocamora-Osorio, C.; Freire-García, P.; Ramírez-Cuesta, J.M. Automatic Grape Cluster Detection Combining YOLO Model and Remote Sensing Imagery. Remote Sens. 2025, 17, 243. [Google Scholar] [CrossRef]
- Li, H.; Chen, J.; Gu, Z.; Dong, T.; Chen, J.; Huang, J.; Gai, J.; Gong, H.; Lu, Z.; He, D. Optimizing edge-enabled system for detecting green passion fruits in complex natural orchards using lightweight deep learning model. Comput. Electron. Agric. 2025, 234, 110269. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Chollet, F. Xception: Deep learning with Depth Wise separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Wu, X.; Tang, R. Fast Detection of Passion Fruit with Multi-class Based on YOLOv3. In Proceedings of the Chinese Intelligent Systems Conference; Springer: Singapore, 2020; pp. 818–825. [Google Scholar]
- Tu, S.; Huang, J.; Lin, Y.; Li, J.; Liu, H.; Chen, Z. Automatic detection of passion fruit based on improved faster R-CNN. Res. Explor. Lab 2021, 40, 32–37. [Google Scholar]
- Ou, J.; Zhang, R.; Li, X.; Lin, G. Research and explainable analysis of a real-time passion fruit detection model based on FSOne-YOLOv7. Agronomy 2023, 13, 1993. [Google Scholar] [CrossRef]
- Tu, S.; Huang, Y.; Huang, Q.; Liu, H.; Cai, Y.; Lei, H. Estimation of passion fruit yield based on YOLOv8n+ OC-SORT+ CRCM algorithm. Comput. Electron. Agric. 2025, 229, 109727. [Google Scholar] [CrossRef]
- Chen, D.; Lin, F.; Lu, C.; Zhuang, J.; Su, H.; Zhang, D.; He, J. YOLOv8-MDN-Tiny: A lightweight model for multi-scale disease detection of postharvest golden passion fruit. Postharvest Biol. Technol. 2025, 219, 113281. [Google Scholar] [CrossRef]
- Muhammad, M.B.; Yeasin, M. Eigen-cam: Class activation map using principal components. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Total Number of Pictures | Training Set | Validation Set | Test Set |
|---|---|---|---|---|
| Original image | 1212 | 849 | 242 | 121 |
| Data enhancement | 2910 | 2037 | 582 | 291 |
| ParConv | HSVAF | DWConv | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5–0.95 (%) | F1-Score (%) |
|---|---|---|---|---|---|---|---|
| ✓ | ✕ | ✕ | 94.3 | 84.1 | 91.2 | 80.6 | 88.9 |
| ✕ | ✓ | ✕ | 94.0 | 85.1 | 90.8 | 80.5 | 89.3 |
| ✕ | ✕ | ✓ | 94.7 | 83.2 | 90.3 | 80.2 | 88.6 |
| ✓ | ✓ | ✕ | 93.2 | 84.8 | 91.0 | 80.7 | 88.8 |
| ✕ | ✓ | ✓ | 95.0 | 83.4 | 90.8 | 80.4 | 88.8 |
| ✓ | ✕ | ✓ | 94.3 | 84.2 | 91.0 | 81.1 | 89.0 |
| ✓ | ✓ | ✓ | 95.4 | 85.0 | 91.5 | 80.8 | 90.0 |
| Model | P (%) | R (%) | mAP@0.5 (%) | mAP@0.5–0.95 (%) | F1-Score (%) | Inference Time (ms) |
|---|---|---|---|---|---|---|
| YOLOv3-tiny | 95.9 | 83.5 | 89.9 | 79.9 | 89.3 | 0.7 |
| YOLOv5n | 94.1 | 84.1 | 90.2 | 80.5 | 88.8 | 0.7 |
| YOLOv6n | 94.3 | 84.3 | 90.3 | 80.3 | 89.0 | 0.6 |
| YOLOv8n | 94.6 | 84.3 | 91.1 | 81.5 | 89.1 | 0.7 |
| YOLOv10n | 92.0 | 81.6 | 88.8 | 79.3 | 86.5 | 0.7 |
| YOLOv11n | 94.7 | 81.5 | 90.2 | 80.3 | 87.6 | 0.7 |
| Our model | 95.4 | 85.0 | 91.5 | 80.8 | 90.0 | 0.6 |
| Model | Literature | P (%) | R (%) | mAP@0.5 (%) |
|---|---|---|---|---|
| YOLOv3 | Wu et al., 2020 [29] | \ | \ | 86.7 |
| Faster R-CNN | Tu et al., 2021 [30] | 90.79 | 90.47 | \ |
| YOLOv7 | Ou et al., 2023 [31] | 91.20 | \ | 90.45 |
| YOLOv5s | Sun et al., 2024 [20] | 93.00 | 92.10 | 96.40 |
| YOLOv8n | Tu et al., 2025 [32] | 80.40 | 80.40 | 86.30 |
| YOLOv8n | Li et al., 2025 [26] | 96.00 | 83.70 | 91.90 |
| YOLOv8-MDN-Tiny | Chen et al., 2025 [33] | 92.60 | 89.90 | 94.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, R.; Zhao, R.; Ding, X.; Peng, S.; Cai, F. High-Precision Complex Orchard Passion Fruit Detection Using the PHD-YOLO Model Improved from YOLOv11n. Horticulturae 2025, 11, 785. https://doi.org/10.3390/horticulturae11070785
Luo R, Zhao R, Ding X, Peng S, Cai F. High-Precision Complex Orchard Passion Fruit Detection Using the PHD-YOLO Model Improved from YOLOv11n. Horticulturae. 2025; 11(7):785. https://doi.org/10.3390/horticulturae11070785
Chicago/Turabian StyleLuo, Rongxiang, Rongrui Zhao, Xue Ding, Shuangyun Peng, and Fapeng Cai. 2025. "High-Precision Complex Orchard Passion Fruit Detection Using the PHD-YOLO Model Improved from YOLOv11n" Horticulturae 11, no. 7: 785. https://doi.org/10.3390/horticulturae11070785
APA StyleLuo, R., Zhao, R., Ding, X., Peng, S., & Cai, F. (2025). High-Precision Complex Orchard Passion Fruit Detection Using the PHD-YOLO Model Improved from YOLOv11n. Horticulturae, 11(7), 785. https://doi.org/10.3390/horticulturae11070785