1. Introduction
Tomato, as a vital global agricultural crop, requires early disease detection to ensure yield and quality. Traditional manual inspection methods are time-consuming and subjective, failing to meet modern agricultural efficiency demands. Recent advancements in deep learning, particularly convolutional neural networks (CNNs), offer new solutions for crop disease detection.
In plant disease detection, technical improvements based on R-CNN and YOLO (You Only Look Once) frameworks [
1] have shown notable progress. Wu et al. [
2] developed HM-R-CNN and TbHM-R-CNN models that automatically correct mislabeled data while efficiently identifying key pest features. Fang et al. [
3] created the Pest-ConFormer hybrid model, combining traditional image analysis with advanced global modeling to enhance detection accuracy. Sun et al. [
4] proposed the E-TomatoDet network, which improves tomato disease recognition under challenging conditions by combining global disease distribution patterns with local lesion textures. Pandiyaraju et al. [
5] achieved higher classification accuracy through adaptive learning rate optimization and model fusion strategies on classical networks like VGG-16. Saleem et al. [
6] introduced AgirLeafNet, a lightweight model capable of detecting diseases across multiple crops (tomato, potato, mango) using limited data, enhanced by the ExG vegetation feature algorithm for reliable disease–health differentiation in IoT agricultural systems.
Zhang et al. [
7] enhanced the YOLOv5 model by integrating deep feature extraction and key region focusing techniques, addressing detection errors for small targets like cotton bolls. Appe et al. [
8] proposed the CAM-YOLO algorithm with dynamic attention allocation and precise localization strategies, significantly improving recognition of overlapping small tomato targets. Umar [
9] upgraded YOLOv7 through optimized attention mechanisms and image segmentation, enabling better focus on disease areas (e.g., lesions) in tomato detection. Wu [
10] developed the MTS-YOLO model with multi-scale feature extraction and specialized attention for slender targets, providing lightweight solutions for agricultural sorting. Li et al. [
11] created the PDC-VLD multimodal model using self-learning and context guidance modules to automatically extract disease features while reducing background interference, even with limited data. Thanjaivadivel et al. [
12] achieved 99.87% accuracy across 39 crops (including tomato and corn) through lightweight convolutional techniques based on leaf color and texture analysis, demonstrating low computational costs for practical deployment.
While the aforementioned studies have continuously advanced detection accuracy and speed through algorithmic innovations, two core challenges persist in practical agricultural applications: On the one hand, although innovative methods represented by studies like [
2,
3,
4,
5,
6] significantly improve detection accuracy, their high training costs and large model volumes severely limit their practical deployment potential in resource-constrained environments. On the other hand, actual crop disease and pest features are characterized by their subtlety and dense distribution, making them difficult to capture effectively. Concurrently, background noise (e.g., similar color interference) significantly impacts plant feature recognition, leading to suboptimal performance of existing methods [
7,
8,
9,
10,
11,
12] in complex, variable environments. These limitations collectively hinder the large-scale deployment of deep learning models in precision agriculture.
To address these dual challenges of computational efficiency and robustness in complex environments, this study proposes a novel optimized network model named AHN-YOLO. Based on the YOLOv8-n framework, the model incorporates three core innovations: First, the ADown (Adaptive Downsampling) module [
13] with its dual-channel feature path structure is introduced as the downsampling component. This significantly reduces computational redundancy and model size in complex scenarios while maintaining accuracy, effectively cutting training and deployment costs to achieve a more lightweight model. Second, a light-ES (Lightweight Hybrid ECA-SimAM Attention Module) is designed. Through local–global feature coupling and a dynamic weight allocation mechanism, this module enhances the saliency of subtle disease regions under complex backgrounds and noise interference, improving target recognition accuracy. Finally, the Normalized Wasserstein Distance (NWD) loss function is innovatively combined with the CIoU (Complete Intersection over Union Loss) loss function and applied to the detection head. This fusion leverages feature distribution similarity metrics to effectively mitigate the sensitivity of traditional bounding box regression to small targets, significantly enhancing the model’s robustness in detecting tiny, dense, and low-overlap targets. The synergistic integration of these innovative modules endows the AHN-YOLO model with lightweight and high-efficiency characteristics, specifically optimizing its detection performance for dense small targets in complex field environments.
Experimental results demonstrate that through modular co-optimization and single-stage training, AHN-YOLO not only significantly reduces training costs but also achieves higher detection accuracy in complex dense scenarios. With its low deployment cost and improved precision, AHN-YOLO meets the requirements of high-accuracy real-time detection on agricultural edge devices while providing a robust and efficient solution for disease identification in field environments.
2. Related Works
Deep learning fundamentally differs from traditional machine learning methods. As an end-to-end model, it possesses the capability to automatically learn feature representations from data without requiring manually designed feature extractors [
14], making it particularly effective in processing large-scale, high-dimensional datasets. The rapid advancement of computer hardware technologies has enabled researchers to train deeper neural networks with increased hidden layers, thereby enhancing model learning capacities. For instance, Guan et al. [
15] proposed Dise-Efficient, a novel network architecture based on EfficientNetV2, which achieved exceptional recognition accuracy on the PlantVillage plant disease dataset. Yuan et al. [
16] introduced the ESA attention mechanism into the ResNet34 framework, developing the ESA-ResNet34 architecture that reduces model parameters and computational costs while improving detection precision. These examples demonstrate that the selection of network backbone architectures is critical for high-performance applications. The YOLO series framework has undergone continuous architectural optimization through iterative updates, achieving coordinated improvements in both detection accuracy and inference efficiency [
17]. The latest YOLOv12 iteration [
18] innovatively incorporates a regional attention mechanism that significantly reduces computational complexity through localized feature focusing strategies while preserving core detection capabilities, thereby maintaining real-time detection performance. However, specialized evaluations in plant disease detection scenarios reveal limitations in its feature generalization capabilities. Given these considerations, we adopt the more technically mature YOLOv11 framework as our foundation. Through customized adjustments to the network topology and feature extraction depth, our approach achieves targeted enhancement of plant disease visual characteristics while preserving detection robustness, ultimately realizing optimized detection performance. This methodology enables specialized reinforcement of typical phytopathological features without compromising the framework’s inherent reliability.
Among various network architectures, convolutional modules serve as fundamental units of CNNs, whose performance directly determines feature extraction efficiency and quality, thereby influencing detection accuracy and speed. We conducted a comparative analysis of downsampling convolutional modules commonly employed in plant disease detection models. Traditional downsampling approaches like 3 × 3 convolution with stride 2 (VGG16) [
19] effectively reduce feature map resolution but suffer from information loss and parameter redundancy [
20]. Recent lightweight designs based on Depthwise Separable Convolution (e.g., MobileNet series) significantly reduce computational costs through spatial–channel decoupling, though they exhibit limitations in feature retention capabilities [
21]. The ADown module proposed in YOLOv9 employs a dual-path structure combining parallel 3 × 3 convolution (stride 2) and 1 × 1 convolution (stride 1). This architecture ensures efficient spatial compression while enhancing feature representation through channel dimension reorganization [
20]. In the YOLO-ADual framework [
22], researchers deeply integrated the ADown module into both backbone and neck networks. Through synergistic optimization with C3Dual modules, they achieved significant model parameter reduction. Similarly, RT-DETR-SoilCuc [
23] innovatively incorporated ADown into the RT-DETR framework by replacing backbone convolutional blocks with generalized lightweight networks, maintaining model efficiency while substantially strengthening deep semantic feature interpretation. These cross-framework adaptations validate ADown’s exceptional balance between parameter efficiency and feature preservation. Following comprehensive evaluation of computational constraints and feature representation capabilities, we ultimately selected the ADown module as the core downsampling component to construct a detection system that optimizes both efficiency and precision.
In the field of deep learning, optimizing attention mechanisms for specific tasks has become a pivotal direction for model innovation. Shi et al. [
24] designed the MOC-YOLO model for oyster mushroom detection by integrating a Large Separable Kernel Attention (LSKA) mechanism, which enhances the model’s ability to analyze local regions of input feature maps. Wu et al. [
10] proposed the MTS-YOLO model with a Contextual Anchor Attention (CAA) module, significantly improving recognition accuracy for slender targets such as tomato clusters and stems. For fine-grained image detection of disease lesions, incorporating attention mechanisms not only mitigates background noise interference but also directs the model’s focus toward discriminative regions, substantially boosting recognition efficacy [
25]. Ji et al. [
26] developed a hybrid attention-based system for radish disease detection, combining spatial and channel attention mechanisms to markedly enhance real-time detection performance. Inspired by these advances, this study constructs a hybrid attention mechanism to strengthen the model’s global and local information processing capabilities. Specifically, we employ the SimAM (Similarity-Aware Activation Module) module [
27] for local feature extraction—its parameter-free design with 3D weights enables precise capture of fine-grained details. Concurrently, we integrate the ECA (Efficient Channel Attention) module [
28] from Zhao et al.’s IMVTS tea bud detection model [
29], which reinforces global features by avoiding dimensionality reduction and enabling local cross-channel interactions. This hybrid mechanism synergizes SimAM and ECA modules, not only improving feature extraction but also significantly enhancing accuracy and real-time performance in disease detection, offering an innovative solution for agricultural image analysis.
For small-target detection in complex environments, loss function design critically impacts the model’s sensitivity to tiny object localization and feature learning. Current research predominantly adopts Complete Intersection over Union (CIoU) as the bounding box regression loss, which improves localization accuracy through center-distance penalties and aspect-ratio constraints [
30]. However, CIoU’s limitations in complex scenarios—such as inadequate fine-grained constraints for small-target aspect ratios—have become apparent [
31]. Zhang et al. [
32] proposed Inner-IoU loss, which computes IoU using auxiliary bounding boxes to enable more precise overlap evaluation. This approach has been successfully adopted by multiple small-target detection models [
33,
34]. Building on CIoU’s strengths, this study incorporates the NWD-IoU algorithm proposed by Wang et al. [
35] to augment CIoU in box-loss computation, thereby stabilizing the model’s focus on small lesions and improving both training efficiency and precision.
3. Dataset and Methodology
3.1. Dataset
The PlantVillage dataset is currently the most widely used dataset for plant disease detection, containing 54,306 plant leaf images annotated with 38 class labels formatted as “crop–disease” pairs. While it has significantly contributed to plant disease research, its limitations are evident: the majority of images were captured in laboratory or controlled environments, resulting in trained models that underperform in real-world natural settings. To address this, Gehlot et al. [
36] curated the Tomato-Village dataset, comprising 14,358 images (640 × 640 × 3 resolution) of tomato plants photographed in natural field environments across Jodhpur and Jaipur, Rajasthan, India. As illustrated in
Figure 1, the dataset categorizes six tomato disease states and includes 161,223 labels annotated in YOLO format using LabelImg.
The data augmentation method is shown in
Figure 2. Systematic analysis of the Tomato-Village dataset revealed significant data redundancy, where direct utilization of the raw dataset for model training could induce overfitting risks and reduce computational resource efficiency. To mitigate these issues, we implemented a data cleaning strategy by curating 9000 representative images to form the core dataset. Following machine learning best practices, these samples were partitioned into training, validation, and test sets through stratified random sampling at a 7:2:1 ratio to ensure balanced class distributions. Detailed label statistics across subsets are presented in
Table 1.
3.2. AHN-YOLO
To facilitate comparison of model detection performance in complex environments, we selected the YOLOv series models, trained them under consistent training parameters, and evaluated their performance on the test set. As shown in
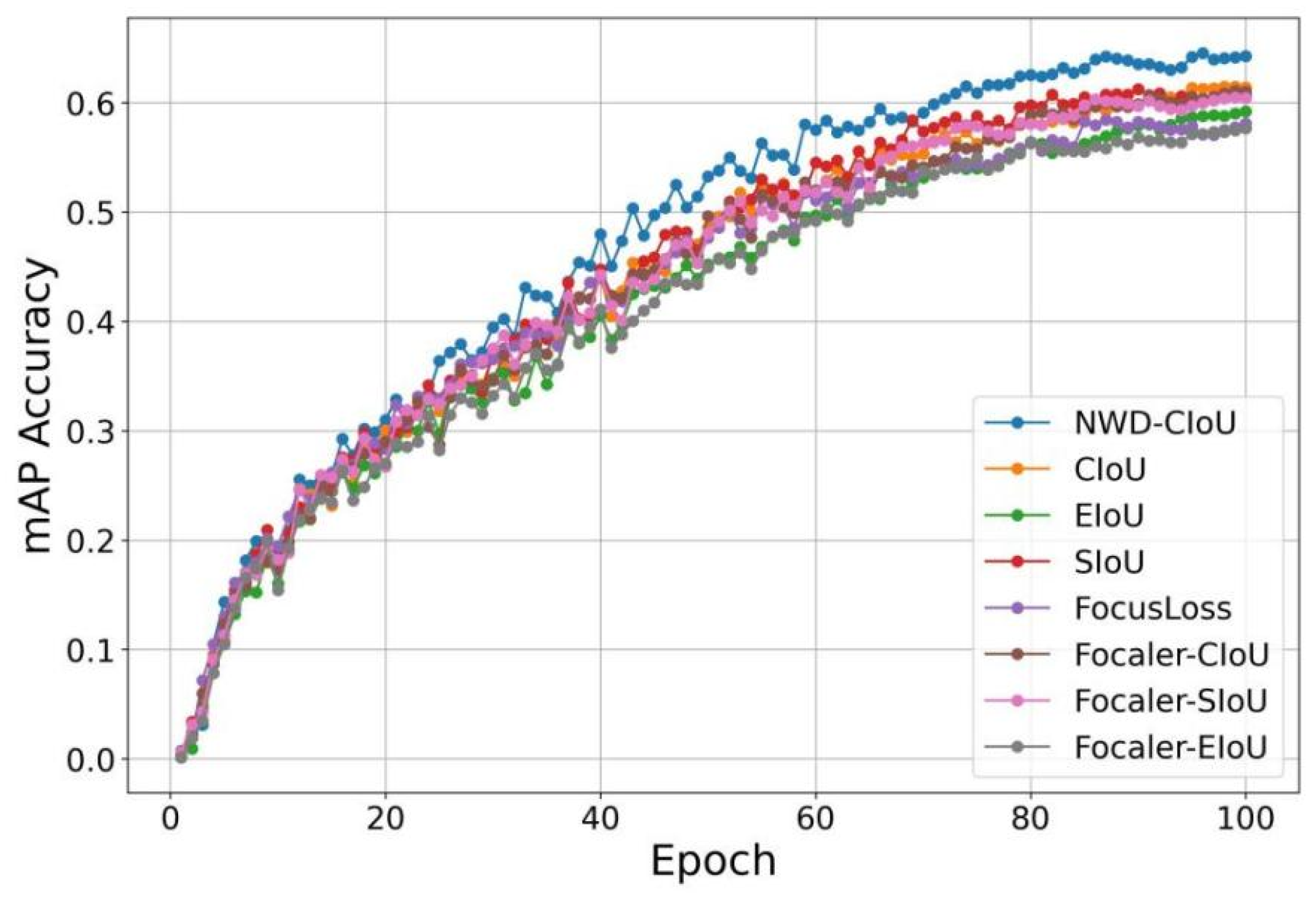
Table 2, YOLOv8 and YOLOv9 demonstrated superior performance in terms of accuracy, but their parameter counts were significantly higher than other models, increasing actual deployment costs. In contrast, YOLOv6 and YOLOv5 achieved the highest FPS and smallest model size, respectively, but their average precision was relatively poor, showing obvious disadvantages in practical applications. Comparatively, YOLOv10, YOLOv11 and YOLOv12 exhibited more balanced performance, among which YOLOv11 performed better—while maintaining higher FPS and fewer parameters, its average precision was approximately 3% higher than other models. Therefore, this paper selected YOLOv11 as the network framework.
As evidenced in
Table 2, YOLOv11 demonstrates significant advantages in both real-time detection efficiency and accuracy, which can be attributed to its redesigned backbone network architecture, neck network structure, and the incorporation of the novel C3k2 component. We selected it as our baseline network and further optimized it to enable faster and more accurate detection of diseased plant targets in complex environments.
The current YOLOv11 object detection series comprises five models of varying sizes: YOLOv11n, YOLOv11s, YOLOv11m, YOLOv11l, and YOLOv11x. As the model size increases, the network depth progressively expands to handle more complex environmental detection tasks. To better evaluate the performance improvements of our modified model, we adopted the YOLOv11n framework as our baseline.
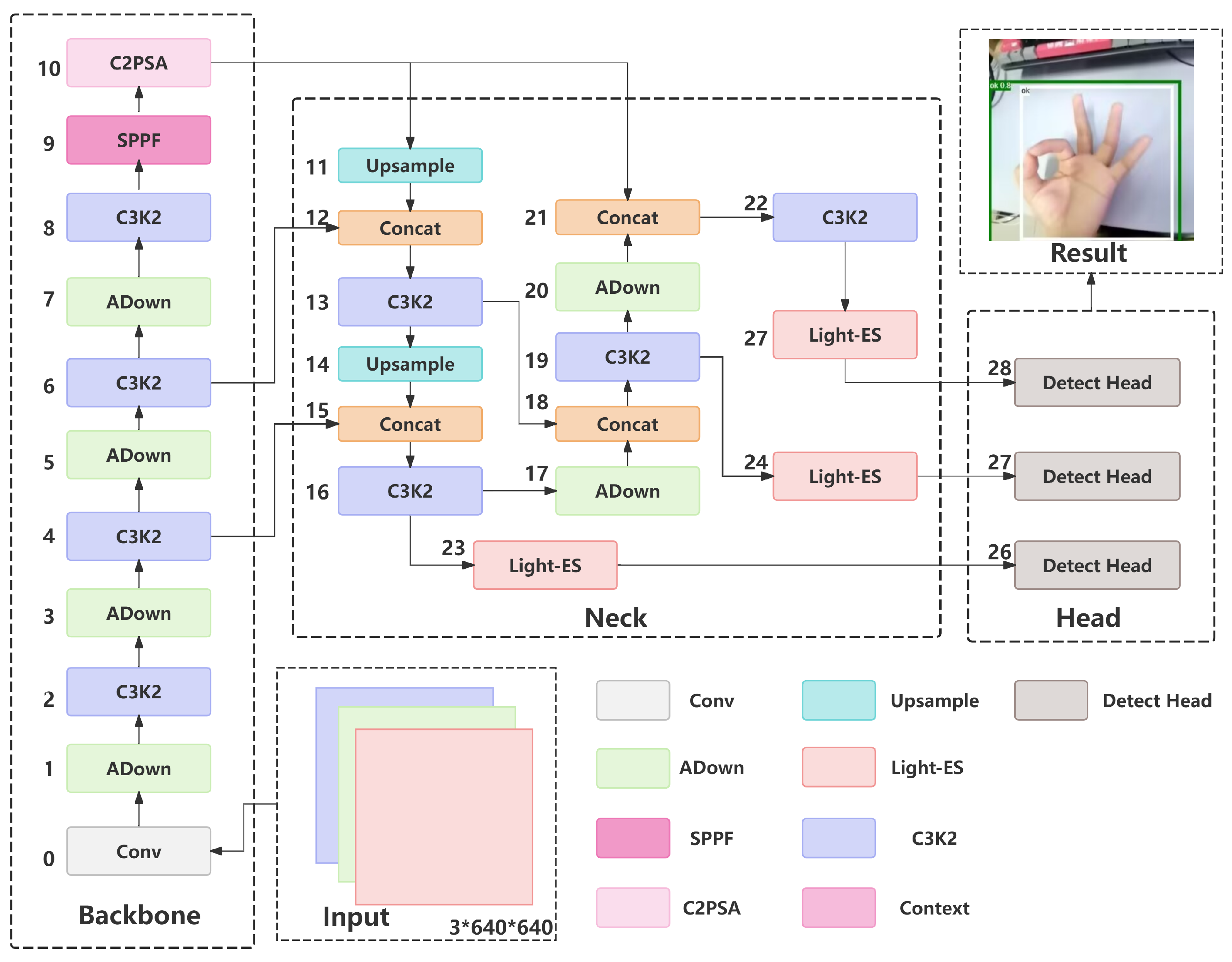
The framework consists of three primary components: the backbone network, neck network, and head network, which respectively perform three core functions: feature extraction, feature fusion, and prediction/classification. Our optimization approach correspondingly focuses on these three components. The overall architecture diagram of our optimized model, AHN-YOLO, is presented in
Figure 3.
3.3. Construction of AD-Backbone
The backbone network typically extracts useful features from input images. To extract more subtle features in plant diseases efficiently, we replaced the original Conv layers with ADown modules to optimize the downsampling convolutional components, creating the AD-Backbone. The network processes input images initially sized [640, 640, 3]. It starts with a standard convolutional layer followed by an ADown convolutional layer for downsampling. Both layers use 3 × 3 kernels with a stride of 2 and multiple convolutional kernels to increase the feature map channel depth. A C3K2 convolutional layer then enhances feature extraction. This downsampling pattern of one ADown layer followed by one C3K2 layer repeats three times, generating four feature maps with dimensions [160, 160, 128], [80, 80, 256], [40, 40, 512], and [20, 20, 1024]. We retain the last three feature maps. The final feature map undergoes refinement through SPPF and C2PSA modules sequentially, then concatenates with the preceding two feature maps for input to the neck network.
ADown Module
The recognition of complex images often relies on deep and large-scale convolutional neural networks, which may contain hundreds or even thousands of layers. Their massive parameter counts and computational demands pose significant challenges to computing resources and may cause delays in real-time detection. To address this issue, two primary strategies exist: first, reducing parameters through model compression, and second, optimizing and improving the original network architecture. In the paper “Enhanced YOLOv8 algorithm for leaf disease detection with lightweight GOCR-ELAN module and loss function: WSIoU” [
37], Wen et al. replaced the traditional CBS module with the ADown module in the network framework, effectively compressing data volume and parameters while mitigating model overfitting. In the original network architecture, the Conv module aims to reduce feature map resolution to facilitate multi-scale fusion in the neck network. However, this process introduces a substantial number of parameters, increasing the model’s computational burden. To address this, we employ the ADown module to replace the Conv module, maintaining the downsampling functionality while reducing model parameters and computational complexity, further suppressing noise interference in complex environments.
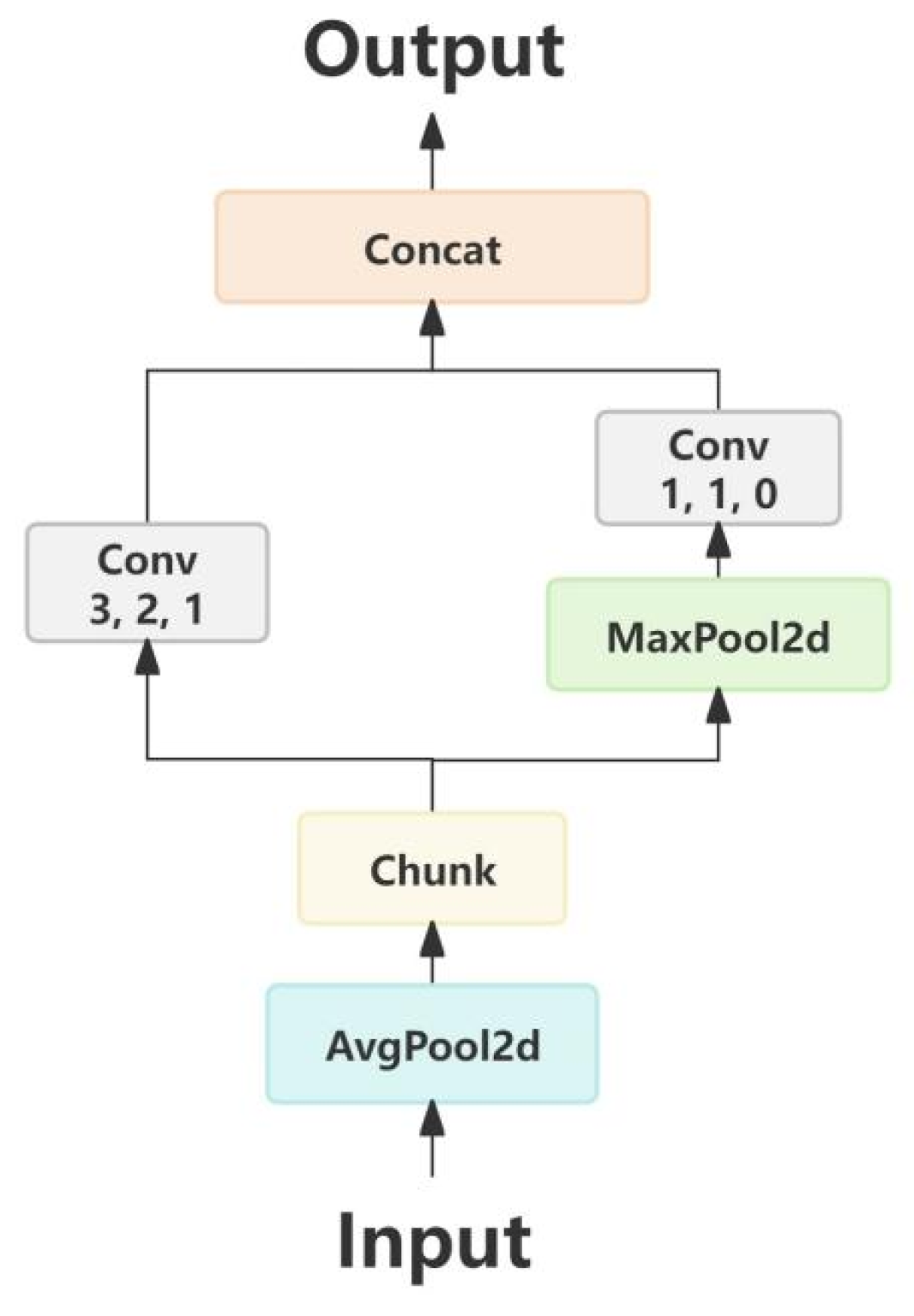
The input feature map first undergoes feature extraction via the C3K2 module, where the feature map has a large width and contains numerous weight parameters. It is then fed into the ADown module, whose implementation steps are illustrated in
Figure 4. First, an average pooling layer captures global information from features of different scales, reducing background noise interference. Next, channel splitting halves the input channels, directing them into left and right branches. The left branch combines a 3 × 3 convolutional kernel with average pooling to capture local texture features while reducing resolution. The right branch employs a 1 × 1 convolutional kernel paired with max pooling, focusing on extracting globally salient features.
Assuming the input tensor is
, the mathematical formulation of the module’s output is defined in Equations (1) and (2).
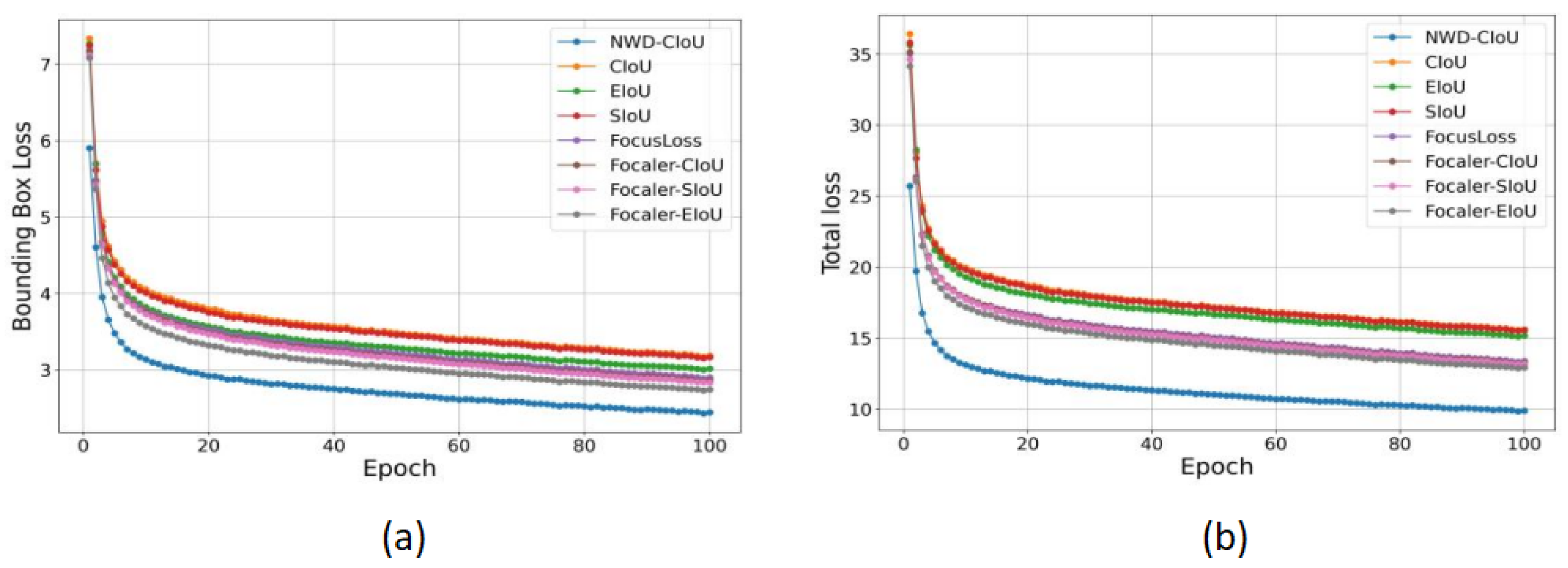
The ADown module algorithm reduces the parameter count. For a convolutional kernel size of 3 × 3, the parameter count of traditional downsampling convolution is , while that of the ADown module is . Under identical input and output channel configurations, the ADown module exhibits a significantly lower parameter count and computational load compared to traditional convolution. This indicates that the module enhances training efficiency under constrained training conditions, making it highly suitable for deployment in lightweight models addressing general complex problems.
To elucidate the implementation workflow of the ADown module, we provide its pseudocode below (Algorithm 1), which visually demonstrates the branch processing and feature fusion procedures of input feature maps.
3.4. Design of Light-ES Attention Module
The neck network of the YOLO series employs BiFPN (Bidirectional Feature Pyramid Network), which processes three feature maps of varying dimensions and channel depths for multi-scale feature aggregation to enhance detection accuracy. However, this network relies on fixed-weight cross-scale feature fusion, making it difficult to dynamically adjust the relative importance of features at different levels. This limitation may excessively dilute subtle target details contained in shallow features [
38]. To mitigate this drawback, we developed a lightweight hybrid attention mechanism named Light-ES, which is inserted at the terminal output of the neck network as a post-fusion optimization module.
| Algorithm 1 ADown Module |
| Input: Feature map |
| Output: Enhanced feature map |
- 1:
Initial Downsampling: - 2:
Apply average pooling with kernel size 2 and stride 1: - 3:
- 4:
Channel Split: - 5:
Split X into two equal parts along the channel dimension: - 6:
- 7:
Left Branch (Local Feature Extraction): - 8:
Apply convolution with stride 2 to : - 9:
- 10:
Right Branch (Global Feature Extraction): - 11:
Apply max pooling with kernel size 3 and stride 2 to : - 12:
- 13:
Apply convolution to : - 14:
- 15:
Feature Fusion: - 16:
Concatenate outputs from both branches: - 17:
- 18:
Return
|
The Light-ES module consists of parallel SimAM and ECA components that perform weighted refinement on multi-scale input feature maps. This design strengthens the model’s localization and classification capabilities while serving as a preprocessing step for subsequent detection heads, ultimately improving detection performance in complex scenarios. By adaptively enhancing feature representation, Light-ES effectively compensates for BiFPN’s static fusion mechanism while maintaining computational efficiency.
3.4.1. SimAM Model
The SimAM (Similarity-Aware Activation Module) [
29] represents an innovative attention mechanism grounded in the local self-similarity of feature maps and characterized by its parameter-free design. Specifically, it dynamically adjusts pixel weights based on the similarity between pixels within the feature map, thereby amplifying task-critical features while suppressing irrelevant ones. This property enables SimAM to efficiently capture key information when processing small-scale features, avoiding overfitting or information loss caused by excessive parameters and significantly enhancing model performance in fine-grained feature extraction tasks.
The implementation steps of SimAM are as follows: Assume an input tensor with batch size B, C channels, and spatial dimensions H × W. SimAM first computes the mean and variance across the spatial dimensions (H × W) for each sample and channel within the input tensor. These statistical measures reflect the distribution of activation values at different spatial positions within the same channel. For the c-th channel of the b-th sample, the formulas for mean and variance are provided in Equations (3) and (4).
To effectively implement attention mechanisms, it is essential to evaluate the importance of each neuron. In neuroscience, neurons exhibiting spatial inhibition effects should be assigned higher importance, and the simplest method to identify such neurons is to measure the linear separability between a target neuron and others. Consequently, the previously mentioned variance and mean can be utilized to formulate an energy computation equation (Equation (
5)) that quantifies the relative saliency of a pixel within its corresponding sample and channel positions.
The operations of multiplying by 1/4 and adding 1/2 are designed to normalize the energy values into the effective working range of the Sigmoid function, thereby mitigating issues such as gradient vanishing or exploding gradients. Subsequently, the energy values are mapped to the [0, 1] interval via the Sigmoid activation function (Equation (
6)), generating attention weights. These weights are then element-wise multiplied with the original input tensor (Equation (
7)) to produce a weighted feature map.
Through this process, the SimAM module assigns a unique weight to each neuron, significantly enhancing the model’s ability to focus on complex, densely distributed features.
3.4.2. ECA Model
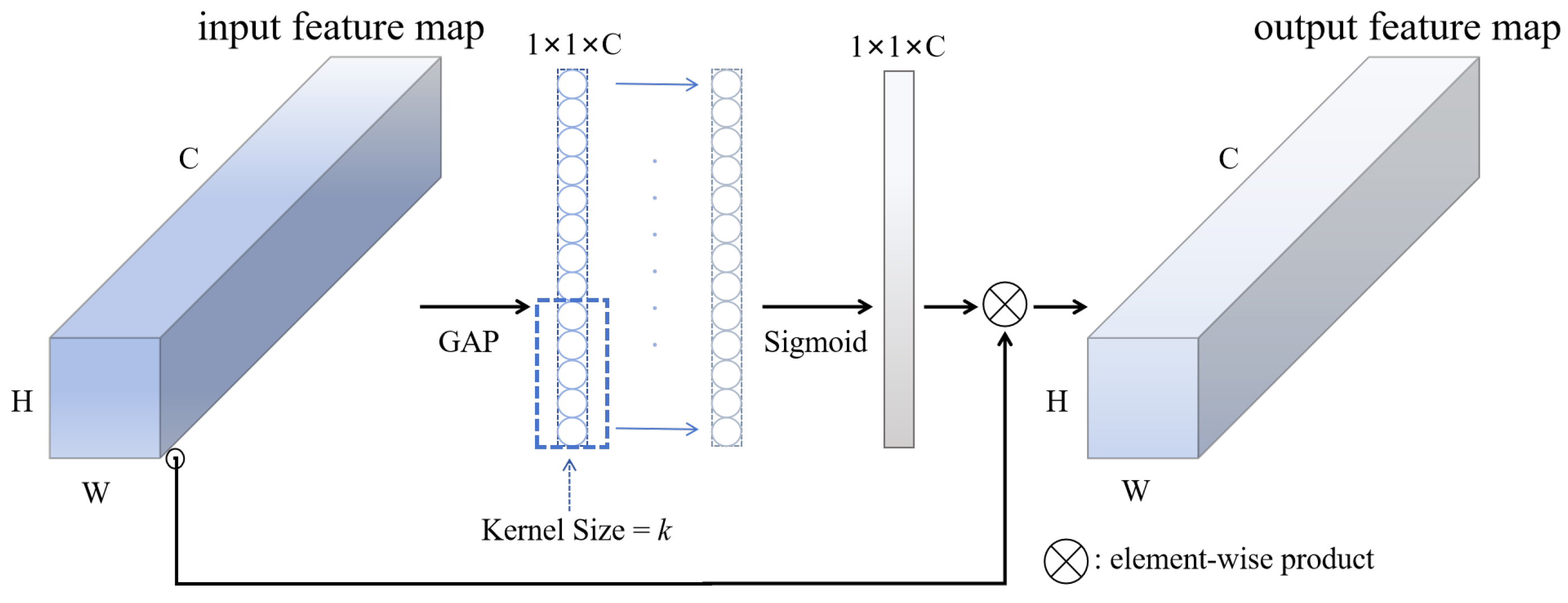
ECA (Efficient Channel Attention) [
30] is a channel attention mechanism designed to enhance the ability of convolutional neural networks (CNNs) to assess the importance of individual channels. This mechanism extends the SE (Squeeze-and-Excitation) attention framework. While the SE module computes channel attention via fully connected (FC) layers—a method prone to computational redundancy—the ECA module employs a simplified one-dimensional convolution operation, significantly improving computational efficiency.
The implementation steps of ECA are shown in
Figure 5: The ECA module first applies Global Average Pooling (GAP) to the input feature map
, aggregating global spatial information into a one-dimensional vector
. Next, the optimal receptive field length k for the one-dimensional convolutional kernel is determined using a theoretically derived formula (Equation (
8)).
where
denotes the number of input channels, and
,
are hyper-parameters set to 2 and 1 by default. This formula ensures effective capture of inter-channel dependencies. The output is then normalized to the [0, 1] interval via a Sigmoid activation function, generating channel-wise attention weights. Finally, these weights are multiplied channel-wise with the original feature map to accomplish feature recalibration.
3.4.3. Light-ES Model
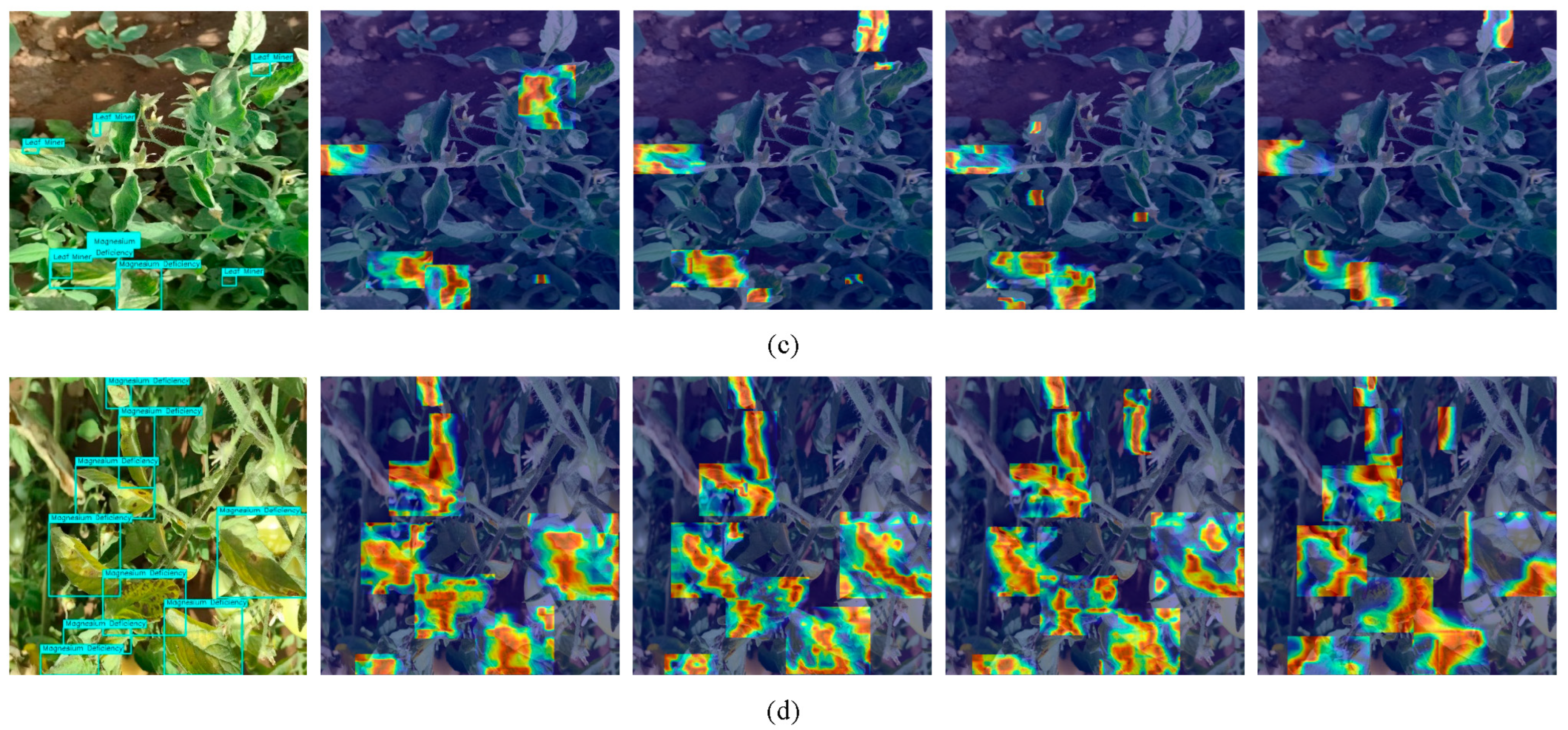
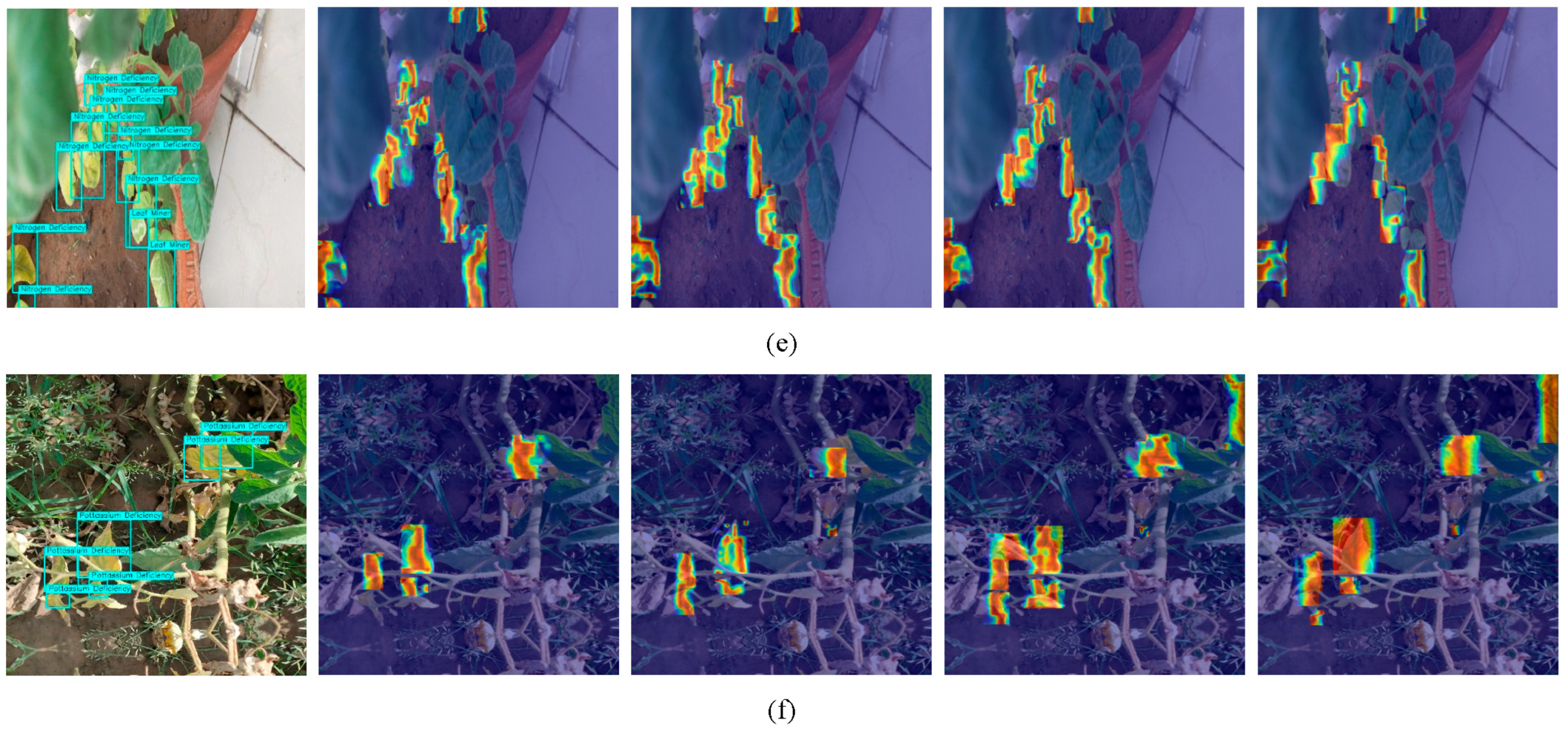
To enable the model to effectively detect dense, small-sized pathological features in complex environments, capturing global information helps the model better recognize target characteristics amidst various interfering factors and complex backgrounds, thereby reducing false positives and missed detections. Meanwhile, in datasets with dense feature distributions, subtle differences in local features may be critical for target identification, making detailed local feature extraction equally essential.
To address these requirements, we designed a hybrid attention mechanism for global–local information processing, incorporating both ECA (Efficient Channel Attention) and SimAM (Similarity-based Attention Module) modules. The ECA module employs 1D convolution to capture inter-channel dependencies, enhancing the model’s perception of global information. The SimAM module dynamically adjusts pixel-wise weights by calculating similarity between each pixel and its neighbors, thereby improving the model’s focus on local details. By processing these two modules in parallel and fusing their outputs through weighted integration, the model simultaneously attends to both global and local features, enabling more effective handling of dense small targets. For the tomato dataset containing dense small features, the ECA module improves the model’s sensitivity to subtle features by modeling channel-wise relationships, while the SimAM module enhances localized attention through adaptive pixel weighting. This dual focus on global and local information significantly boosts the model’s capability to extract small features. Both ECA and SimAM are lightweight attention mechanisms with relatively low algorithmic complexity, avoiding substantial computational overhead while maintaining performance—theoretically improving computational efficiency and real-time capability.
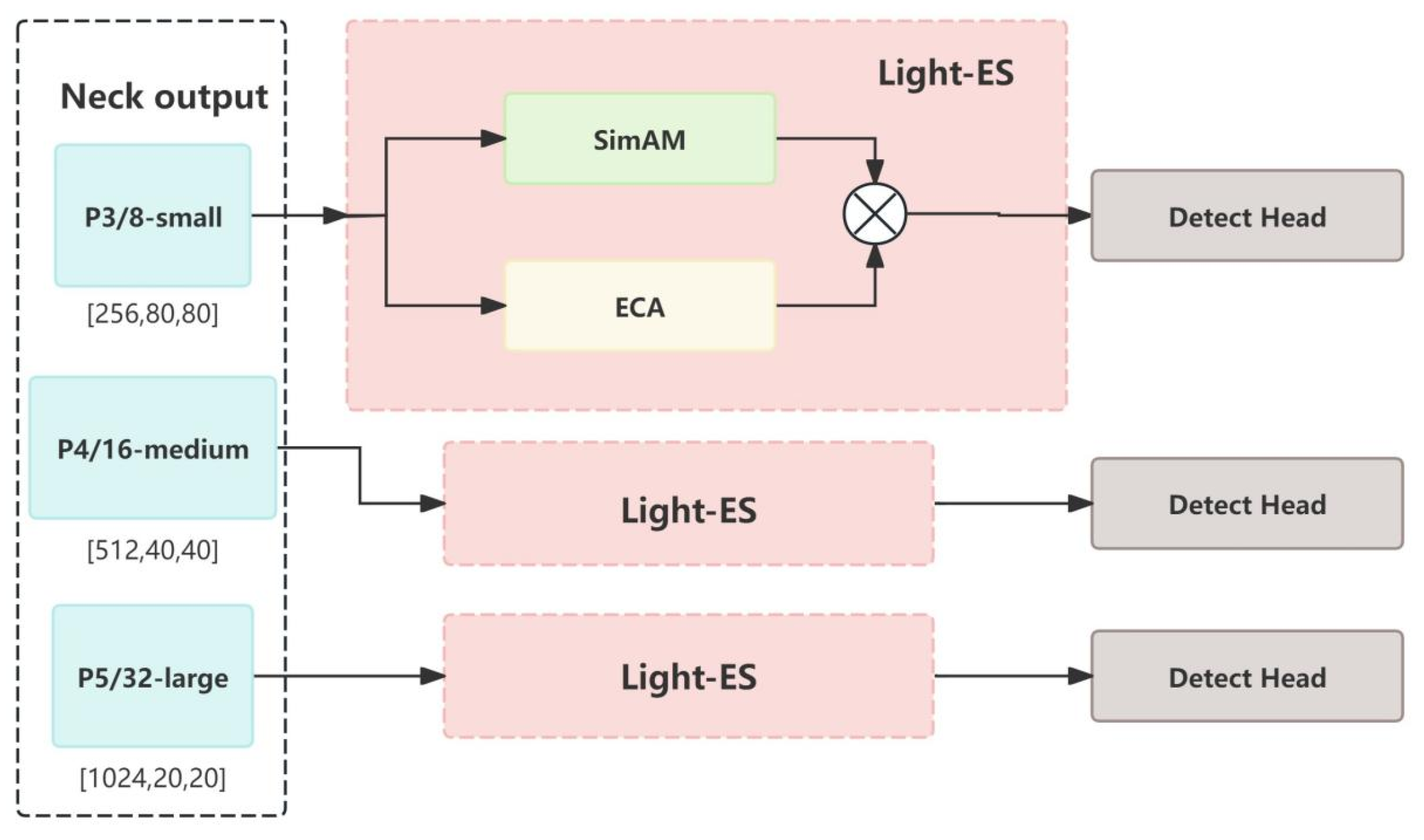
As illustrated in
Figure 6, we positioned this mechanism ahead of the three detection heads. The input consists of three feature maps with varying dimensions and channel depths, allowing the module to maximally extract discriminative features across all scales and thereby elevate overall detection performance.
The implementation steps of this hybrid attention mechanism are as follows: Input feature maps are fed in parallel into the ECA and SimAM modules. After computation by these modules, the resulting parameters are fused through weighted summation, as shown in Equation (9).
The weights and are dynamically adjusted during model training via forward propagation algorithms, completing the construction of the hybrid attention mechanism.
To elucidate the implementation workflow of the light-ES module, we provide its pseudocode below (Algorithm 2), which visually demonstrates the branch processing and feature fusion procedures of input feature maps.
| Algorithm 2 Light-ES Hybrid Attention Module |
| Input: Feature map |
| Output: Enhanced feature map |
- 1:
Local Attention (SimAM): - 2:
Compute mean of X over spatial dimensions: - 3:
- 4:
Compute variance-like energy E: - 5:
- 6:
Apply Sigmoid to energy E: - 7:
- 8:
Generate local-attention enhanced feature: - 9:
- 10:
Global Attention (ECA): - 11:
Compute global average pooling: - 12:
- 13:
Apply 1D convolution to G (kernel size k): - 14:
- 15:
Apply Sigmoid to generate channel weights: - 16:
- 17:
Generate global-attention enhanced feature: - 18:
- 19:
Hybrid Fusion: - 20:
Assign learnable weights , to local and global features: - 21:
- 22:
Return
|
3.5. Head Network Optimization
Compared to previous YOLO versions, YOLOv11 introduces two additional DWConv (Depthwise Separable Convolution) layers in its classification detection head to reduce computational overhead. Furthermore, it incorporates the EIoU (Extended IoU) loss function, which considers the overlap area, aspect ratio, and center offset between predicted and ground-truth bounding boxes, thereby improving localization accuracy. Given its superior performance, we retained YOLOv11’s detection head structure for final image processing. In this architecture, the bounding box regression loss combines CIoU and DFL (Distribution Focal Loss), which quantifies the discrepancy between predicted and ground truth boxes, playing a critical role in model parameter optimization. While CIoU demonstrates excellent performance for medium- and large-sized targets, it shows limitations in small object detection [
39]. To address this, we integrated NWD (Normalized Wasserstein Distance) with CIoU to create the NWD-CIoU loss function, enabling more robust handling of targets across varying scales.
NWD-CIoU Loss Function
In complex natural scenarios, dense small-target detection faces dual challenges of geometric feature ambiguity and environmental noise interference. Small targets typically occupy only a few to dozens of pixels in an image, and their bounding box regression is susceptible to positional sensitivity, gradient imbalance, and shape constraint limitations, resulting in poor localization accuracy. To enhance the model’s precision and efficiency for small-target detection, we introduce the Normalized Wasserstein Distance (NWD) algorithm—a novel approach leveraging Wasserstein distance for small-target detection—and integrate it with CIoU to optimize the existing loss function. First, the NWD-CIoU loss function retains CIoU’s geometric alignment terms, enforcing spatial consistency between predicted and ground truth bounding boxes through Equation (
10).
Here, represents the Euclidean distance between centers, c denotes the diagonal length of the minimum enclosing rectangle, v signifies the aspect ratio of the anchor box, corresponds to the aspect ratio penalty term, and w and h are the width and height of the anchor box, respectively. This module ensures that the model’s localization accuracy for medium and large targets remains uncompromised.
For small-target detection, most bounding boxes are not strictly rectangular. A bounding box
inevitably contains background pixels. To better prioritize and enhance pixel-level relevance for small objects, a 2D Gaussian distribution is introduced to model the bounding box, where the central pixels exhibit the highest weights, decaying gradually toward the periphery. The formula for this 2D Gaussian distribution is defined in Equation (
11).
where
denotes the computed pixel weight,
X represents the coordinates of a pixel
,
is the mean vector, and
is the covariance matrix.
Subsequently, the Wasserstein distance from optimal transport theory is employed to measure the distance between the predicted bounding box
and the ground-truth bounding box
, which are modeled as Gaussian distributions
and
, respectively; the Wasserstein distance between these two bounding boxes can be further simplified to Equation (
12).
Here,
denotes the Frobenius norm. At this stage,
remains a distance metric and cannot directly serve as a similarity measure bounded within [0, 1]. To address this, we normalize
via an exponential transformation to derive the Normalized Wasserstein Distance (NWD), as defined in Equations (13) and (14).
where
C is the normalization coefficient used to scale the Wasserstein distance, ensuring that the NWD value is bounded within a reasonable range. The resulting NWD-IoU loss increases as the distance
between predicted and ground-truth bounding boxes grows, and vice versa. This loss function exhibits scale invariance to minor positional deviations in small targets, preventing pixel-level errors from being overshadowed.
Finally, a tunable ratio
is introduced to balance the contributions of CIoU and NWD-IoU, optimizing the module’s performance for both small and medium to large targets in the dataset. The formulation is given in Equation (
15).
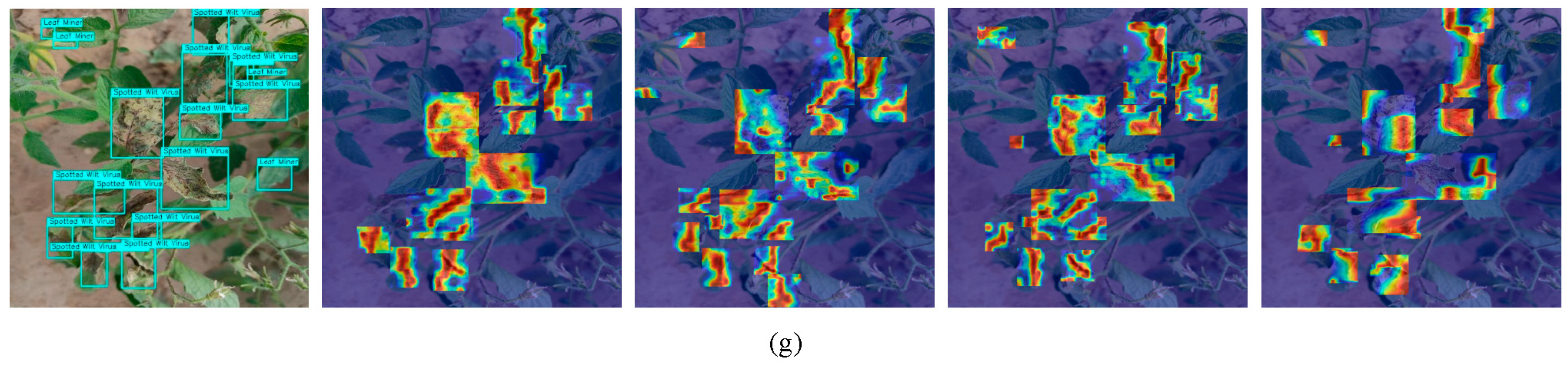
5. Conclusions
Our research focuses on enhancing crop disease recognition models’ robustness and detection accuracy while reducing training and deployment costs, particularly when addressing challenges like diverse disease morphologies, complex backgrounds, and subtle features in real-world environments. Building upon the YOLOv11-n framework, we implemented three key improvements: (1) the ADown module for parameter reduction, (2) the Normalized Wasserstein Distance (NWD) loss function for small-feature detection stability, and (3) the light-ES hybrid attention mechanism for better disease region focus. These innovations collectively achieve model compression alongside significant accuracy gains, with experimental results thoroughly validating AHN-YOLO’s superiority in crop disease recognition tasks and demonstrating its practical application potential.
However, AHN-YOLO still faces several challenges. First, real-world disease features exhibit greater complexity and variability, demanding stronger model generalization. During validation, we observed AHN-YOLO’s insensitivity to features under varying exposure conditions, where lighting intensity sometimes impaired disease judgment accuracy. To address this, we plan to develop networks better adapted to fluctuating lighting environments, strengthening AHN-YOLO’s performance in challenging conditions.
Second, while AHN-YOLO shows remarkable performance on tomato disease detection, its generalization capability requires further verification. Our current training and testing relied solely on tomato-specific disease datasets, leaving cross-crop (e.g., cucumber, pepper) and cross-environment (e.g., different lighting, cameras) adaptability unassessed. This limitation stems from the dataset’s domain specificity—relatively uniform disease morphologies, background complexities, and imaging conditions may constrain the model’s generalization potential for unknown distributions. Our future work will incorporate public agricultural disease datasets to evaluate cross-species feature transfer capabilities, facilitating the transition from lab prototypes to practical field deployment.
Finally, we acknowledge that our current research concentrates on algorithmic-level lightweight optimization and performance validation, without testing hardware deployment in real agricultural scenarios. This leaves engineering challenges like edge device compatibility and multi-sensor synchronization unexplored. Our goal is to investigate embedded integration solutions with drones or inspection robots, employing model quantization and distillation techniques to further reduce inference latency. Concurrently, we will construct multimodal field datasets incorporating real-world noise (e.g., lighting fluctuations, device vibrations) to evaluate model degradation in non-steady scenarios. Through these efforts, we aim to deliver more efficient and accurate solutions for crop disease recognition, ultimately contributing to agricultural production.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}