
Comprehensive Evaluation of Paprika Instance Segmentation Models Based on Segmentation Quality and Confidence Score Reliability

 , , , and
, , , and 
Abstract
1. Introduction
- We proposed metrics for evaluating various aspects of paprika fruit instance segmentation models. This will enable us to develop flexible and high-performance methods for yield prediction and automated harvesting.
- We trained and evaluated various instance segmentation models using data obtained from large-scale commercial greenhouses. Previous studies have often used images captured in laboratory environments or manually collected data from greenhouses. These approaches often introduce risks, such as inconsistent camera-to-fruit distances, arbitrary imaging target selection, and unstable lighting. The cultivation rows were captured at night with LED lighting using our monitoring device in a commercial greenhouse. This enabled model evaluation using stable and comprehensive data.
2. Related Works
3. Materials and Methods
3.1. Image Collection and Dataset Construction
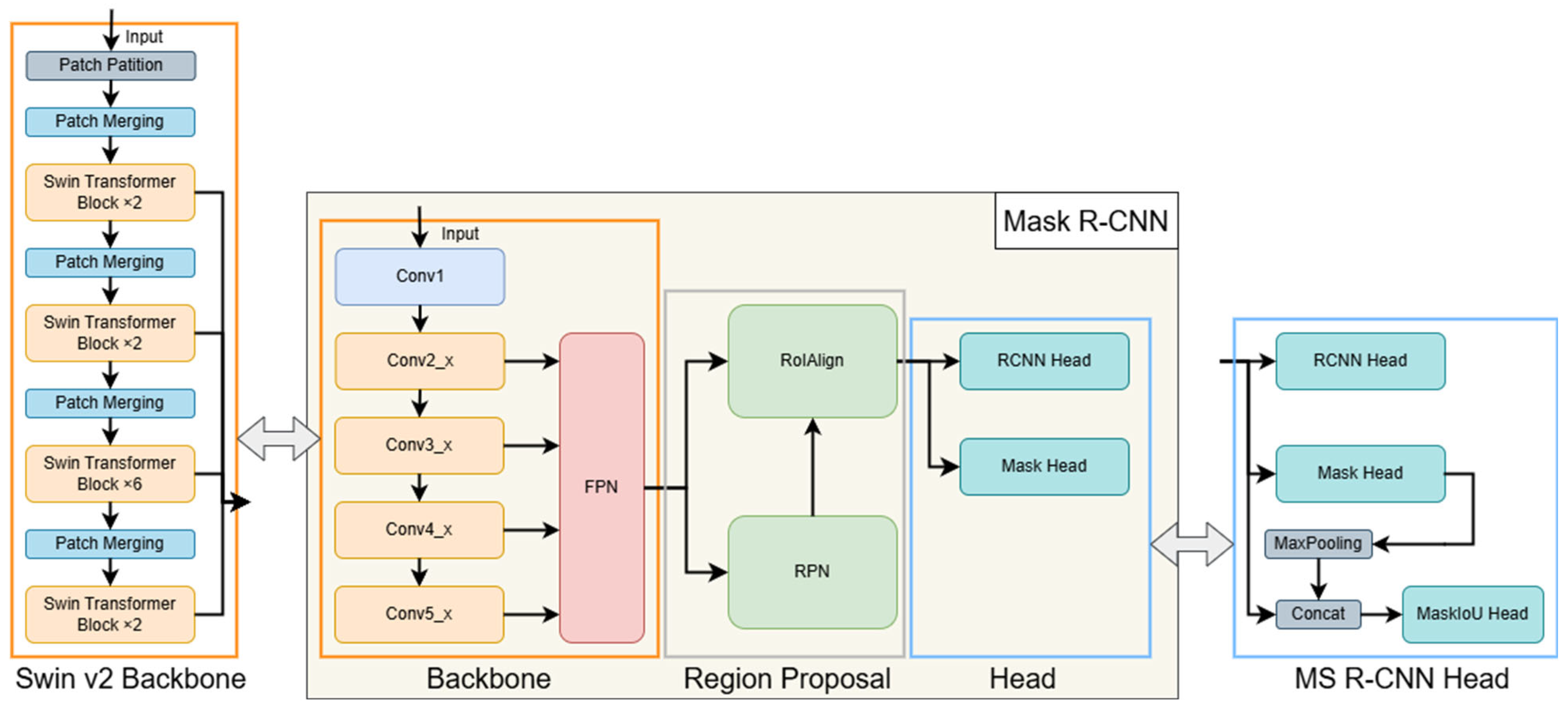
3.2. Instance Segmentation Models
3.2.1. Mask R-CNN
3.2.2. Mask Scoring R-CNN
3.2.3. Mask R-CNN with Swin Transformer v2
3.2.4. YOLO11
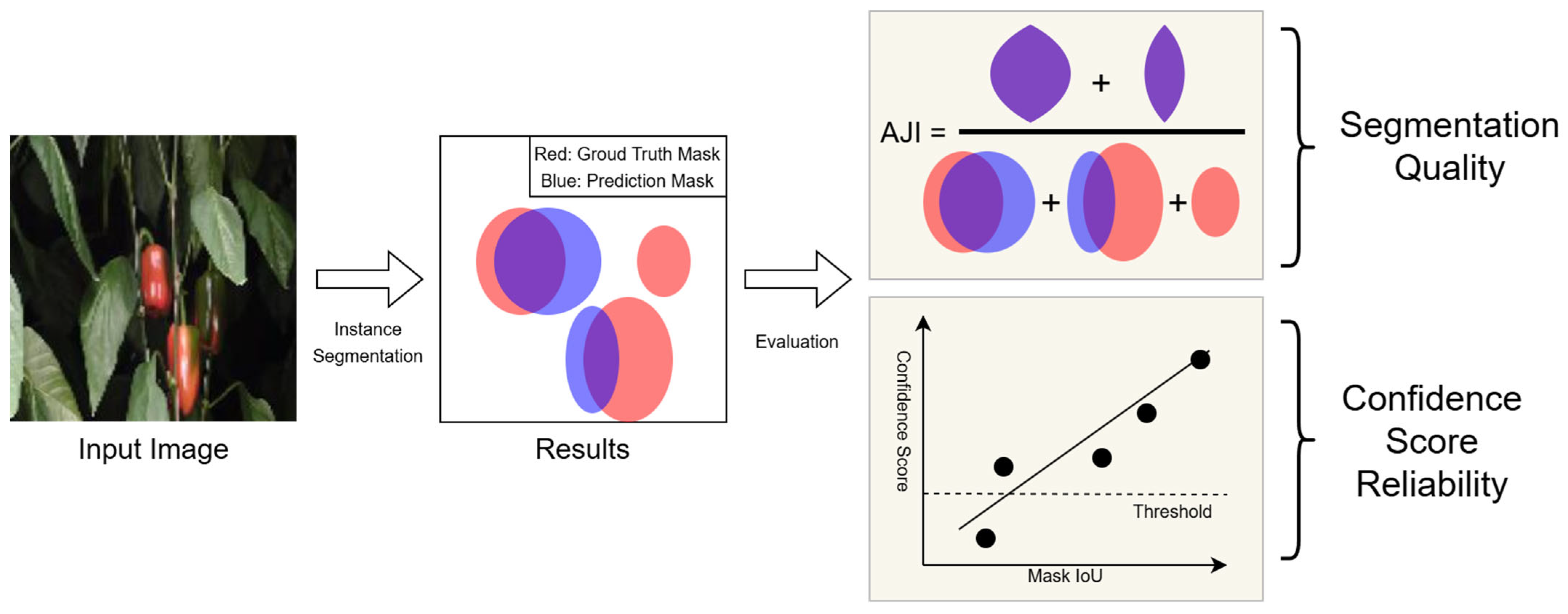
3.3. Evaluation Metrics
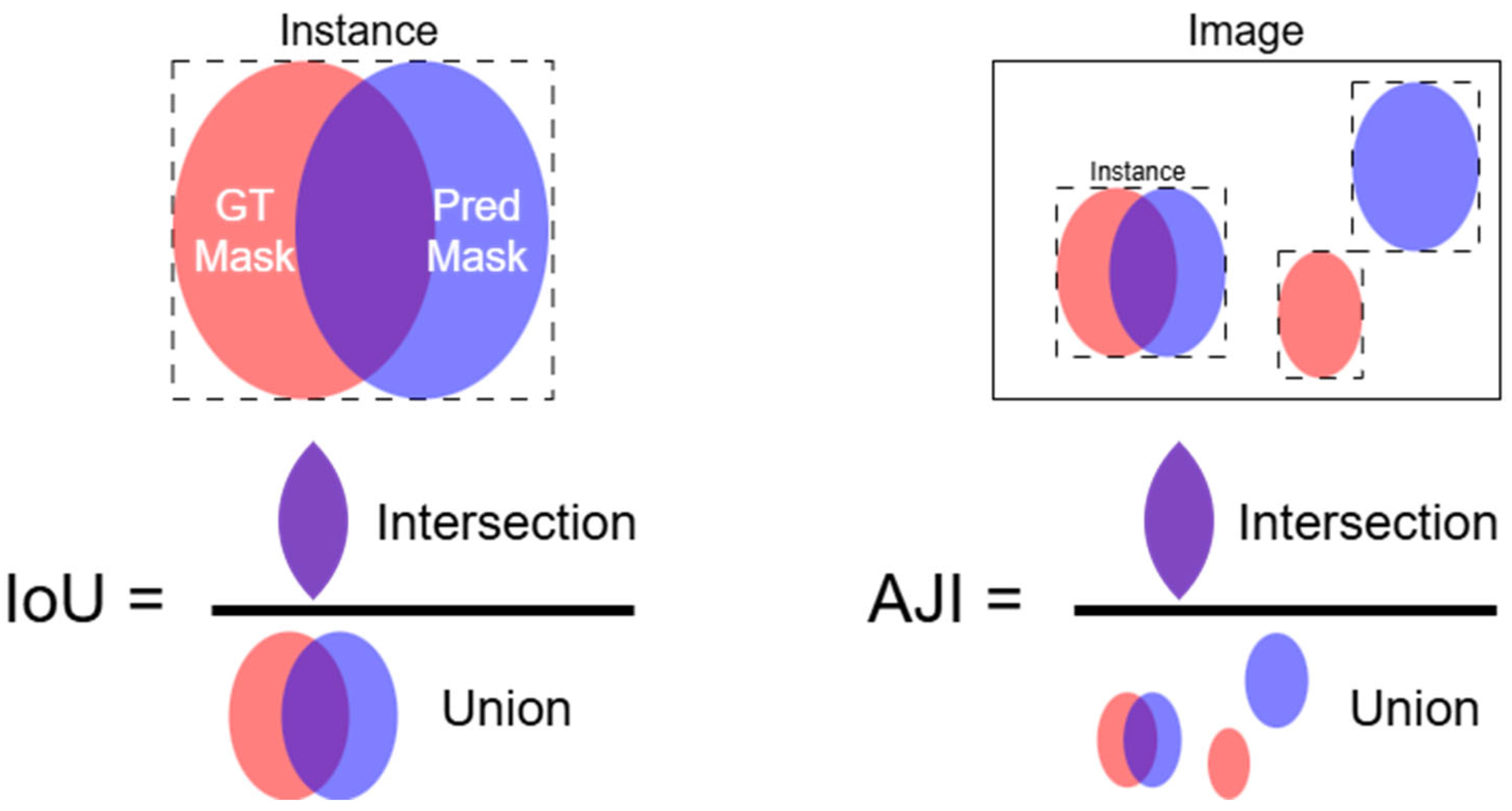
3.3.1. Intersection over Union
3.3.2. Aggregated Jaccard Index
3.3.3. Average Precision
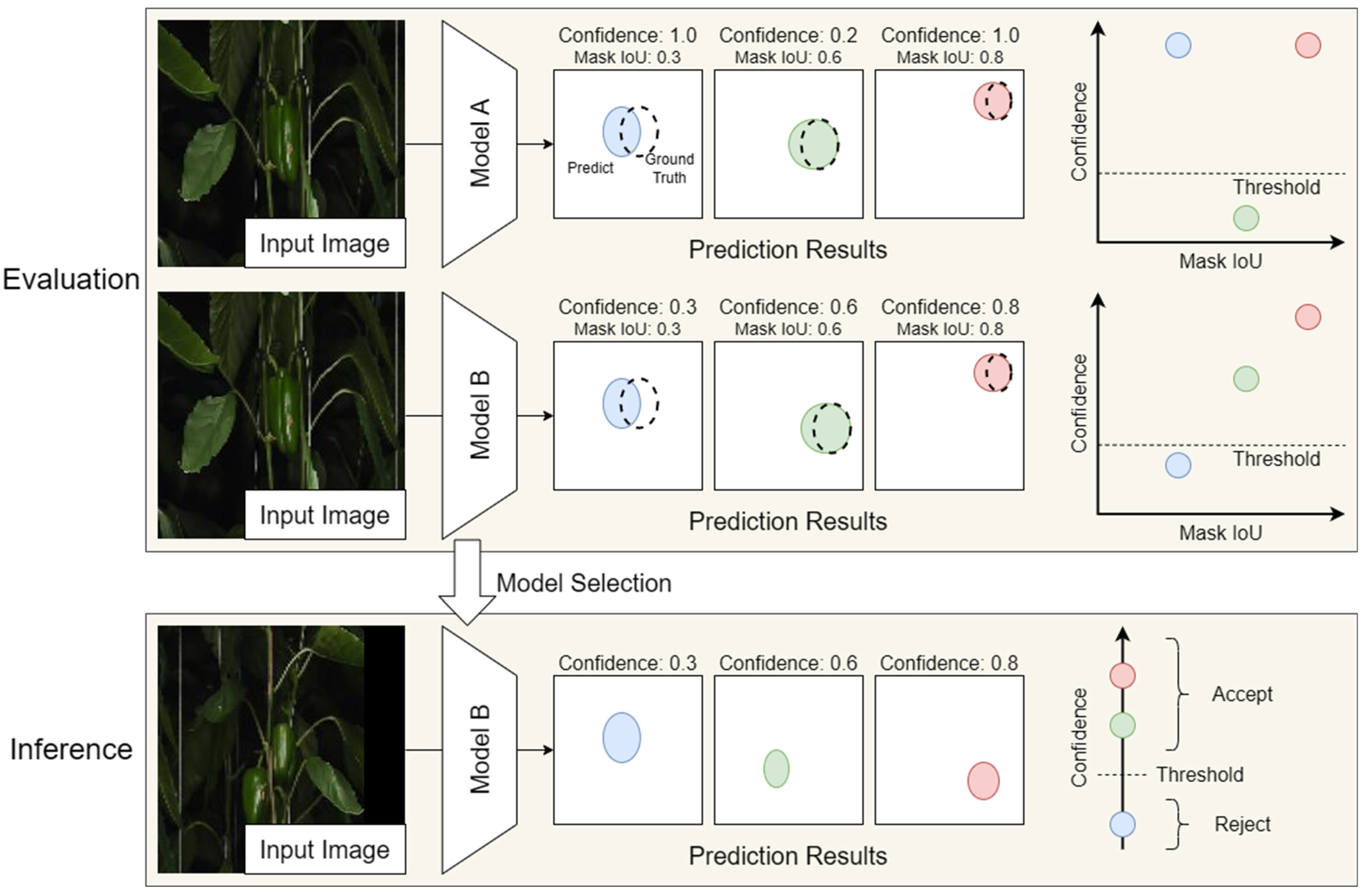
3.3.4. Segmentation Reliability Diagram and Its Coefficient of Determination
3.4. Experimental Design
4. Results
4.1. Comparison of AP, F1-Score and AJI for Models
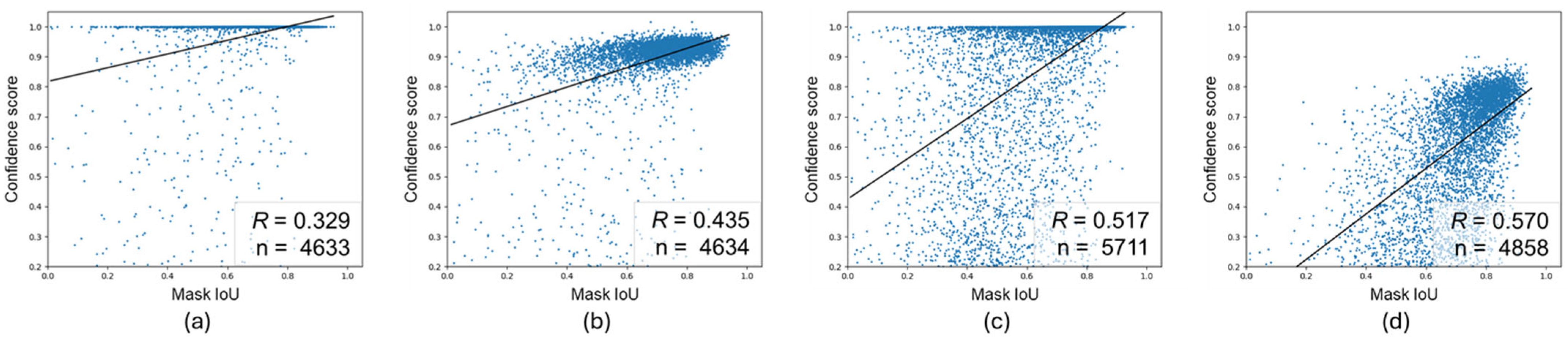
4.2. Correlation Between Confidence Scores and Mask IoU
4.3. Comparison of Computational Resources Among Models
5. Discussion
5.1. Analysis of Each Metric
5.2. Interpretation of Results for Each Model
5.3. Selection of Metrics Based on Application Context
5.4. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Afonso, M.; Fonteijn, H.; Fiorentin, F.; Lensink, D.; Mooij, M.; Faber, N.; Polder, G.; Wehrens, R. Tomato Fruit Detection and Counting in Greenhouses Using Deep Learning. Front. Plant Sci. 2020, 11, 571299. [Google Scholar] [CrossRef] [PubMed]
- Naito, H.; Shimomoto, K.; Fukatsu, T.; Hosoi, F.; Ota, T. Interoperability Analysis of Tomato Fruit Detection Models for Images Taken at Different Facilities, Cultivation Methods, and Times of the Day. AgriEngineering 2024, 6, 1827–1846. [Google Scholar] [CrossRef]
- Shimomoto, K.; Shimazu, M.; Matsuo, T.; Kato, S.; Naito, H.; Fukatsu, T. Development of Double-Camera AI System for Efficient Monitoring of Paprika Fruits; International Society for Horticultural Science (ISHS): Leuven, Belgium, 2025; pp. 355–360. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Chen, L.; Wu, Y.; Stegmaier, J.; Merhof, D.; Sorted, A.P. Rethinking evaluation metrics for instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 3923–3929. [Google Scholar] [CrossRef]
- Gauvain, J.; Lamel, L. Large-vocabulary continuous speech recognition: Advances and applications. Proc. IEEE 2000, 88, 1181–1200. [Google Scholar] [CrossRef]
- Padilla, R.; Passos, W.; Dias, T.; Netto, S.; da Silva, E. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Kang, H.; Zhou, H.; Wang, X.; Chen, C. Real-Time Fruit Recognition and Grasping Estimation for Robotic Apple Harvesting. Sensors 2020, 20, 5670. [Google Scholar] [CrossRef] [PubMed]
- Hemming, J.; Ruizendaal, J.; Hofstee, J.; van Henten, E. Fruit Detectability Analysis for Different Camera Positions in Sweet-Pepper. Sensors 2014, 14, 6032–6044. [Google Scholar] [CrossRef]
- McCool, C.; Sa, I.; Dayoub, F.; Lehnert, C.; Perez, T.; Upcroft, B. Visual detection of occluded crop: For automated harvesting. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2506–2512. [Google Scholar] [CrossRef]
- Ji, W.; Gao, X.; Xu, B.; Chen, G.; Zhao, D. Target recognition method of green pepper harvesting robot based on manifold ranking. Comput. Electron. Agric. 2020, 177, 105663. [Google Scholar] [CrossRef]
- Ning, Z.; Luo, L.; Ding, X.; Dong, Z.; Yang, B.; Cai, J.; Chen, W.; Lu, Q. Recognition of sweet peppers and planning the robotic picking sequence in high-density orchards. Comput. Electron. Agric. 2022, 196, 106878. [Google Scholar] [CrossRef]
- Escamilla, L.; Gómez-Espinosa, A.; Cabello, J.; Cantoral-Ceballos, J. Maturity Recognition and Fruit Counting for Sweet Peppers in Greenhouses Using Deep Learning Neural Networks. Agriculture 2024, 14, 331. [Google Scholar] [CrossRef]
- López-Barrios, J.; Cabello, J.; Gómez-Espinosa, A.; Montoya-Cavero, L. Green Sweet Pepper Fruit and Peduncle Detection Using Mask R-CNN in Greenhouses. Appl. Sci. 2023, 13, 6296. [Google Scholar] [CrossRef]
- Cong, P.; Li, S.; Zhou, J.; Lv, K.; Feng, H. Research on Instance Segmentation Algorithm of Greenhouse Sweet Pepper Detection Based on Improved Mask RCNN. Agronomy 2023, 13, 196. [Google Scholar] [CrossRef]
- Xiao, F.; Wang, H.; Xu, Y.; Zhang, R. Fruit Detection and Recognition Based on Deep Learning for Automatic Harvesting: An Overview and Review. Agronomy 2023, 13, 1625. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6409–6418. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11999–12009. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 13 March 2025).
- Ali, M.; Zhang, Z. The YOLO Framework: A Comprehensive Review of Evolution, Applications, and Benchmarks in Object Detection. Computers 2024, 13, 336. [Google Scholar] [CrossRef]
- Kumar, N.; Verma, R.; Sharma, S.; Bhargava, S.; Vahadane, A.; Sethi, A. A Dataset and a Technique for Generalized Nuclear Segmentation for Computational Pathology. IEEE Trans. Med. Imaging 2017, 36, 1550–1560. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Borrero, I.; Marín-Santos, D.; Gegúndez-Arias, M.; Cortés-Ancos, E. A fast and accurate deep learning method for strawberry instance segmentation. Comput. Electron. Agric. 2020, 178, 105736. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Degroot, M.H.; Fienberg, S.E. The Comparison and Evaluation of Forecasters. J. R. Stat. Soc. Ser. D Stat. 2018, 32, 12–22. [Google Scholar] [CrossRef]
- Wahyono; Wibowo, M.E.; Ashari, A.; Putra, M.P.K. Improvement of Deep Learning-based Human Detection using Dynamic Thresholding for Intelligent Surveillance System. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 1053. [Google Scholar] [CrossRef]
- Thatikonda, M.; PK, M.K.; Amsaad, F. A Novel Dynamic Confidence Threshold Estimation AI Algorithm for Enhanced Object Detection. In Proceedings of the NAECON 2024—IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 15–18 July 2024; pp. 359–363. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Box AP@50 | Box AP@50-95 | Mask AP@50 | Mask AP@50-95 | F1-Score | AJI |
|---|---|---|---|---|---|---|
| Mask R-CNN | 76.23 | 38.41 | 73.90 | 34.36 | 81.17 | 63.33 |
| MS R-CNN | 76.00 | 36.77 | 74.00 | 32.57 | 80.76 | 63.57 |
| Mask R-CNN-SW | 77.18 | 37.86 | 76.31 | 36.21 | 77.40 | 59.60 |
| YOLO11 | 87.16 | 48.26 | 85.83 | 42.90 | 82.28 | 63.05 |
| Model | MACs | Params |
|---|---|---|
| Mask R-CNN | 191.8 G | 62.6 M |
| MS R-CNN | 182.8 G | 78.9 M |
| Mask R-CNN-SW | 127.5 G | 45.9 M |
| YOLO11 | 10.4 G | 2.8 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ohta, N.; Shimomoto, K.; Naito, H.; Kashino, M.; Yoshida, S.; Fukatsu, T. Comprehensive Evaluation of Paprika Instance Segmentation Models Based on Segmentation Quality and Confidence Score Reliability. Horticulturae 2025, 11, 525. https://doi.org/10.3390/horticulturae11050525
Ohta N, Shimomoto K, Naito H, Kashino M, Yoshida S, Fukatsu T. Comprehensive Evaluation of Paprika Instance Segmentation Models Based on Segmentation Quality and Confidence Score Reliability. Horticulturae. 2025; 11(5):525. https://doi.org/10.3390/horticulturae11050525
Chicago/Turabian StyleOhta, Nozomu, Kota Shimomoto, Hiroki Naito, Masakazu Kashino, Sota Yoshida, and Tokihiro Fukatsu. 2025. "Comprehensive Evaluation of Paprika Instance Segmentation Models Based on Segmentation Quality and Confidence Score Reliability" Horticulturae 11, no. 5: 525. https://doi.org/10.3390/horticulturae11050525
APA StyleOhta, N., Shimomoto, K., Naito, H., Kashino, M., Yoshida, S., & Fukatsu, T. (2025). Comprehensive Evaluation of Paprika Instance Segmentation Models Based on Segmentation Quality and Confidence Score Reliability. Horticulturae, 11(5), 525. https://doi.org/10.3390/horticulturae11050525