1. Introduction
The tomato (Solanum lycopersicum) is one of the most widely cultivated and highest-yielding vegetables in the world [
1]. As a major producer, China still heavily relies on manual labor for most tomato picking, leading to relatively low picking efficiency. With labor resources becoming increasingly scarce and the agricultural industry undergoing transformation and upgrading, the demand for automated and mechanized picking has grown more urgent [
2]. The inconsistency in tomato maturity necessitates careful identification of maturity for each bunch to prevent economic losses caused by improper picking times. Distinguishing between different maturity levels of tomato fruit bunches and accurately locating the fruit stems are critical technical challenges [
3]. Consequently, many researchers are focused on developing precise, efficient, and lightweight target-detection algorithms that are easy to deploy, significantly enhancing the recognition capabilities of picking robots [
4].
Traditional image processing methods typically analyzed the color, texture, and shape of tomatoes, using algorithms such as support vector machines (SVM) and geometric techniques for classification and detection. Kumar et al. [
5] proposed a non-destructive tomato sorting and grading system that utilized a three-stage classification process with SVM classifiers to effectively sort and grade tomatoes. However, solving the non-linear problem required cascading multiple SVM classifiers, which introduced significant computational complexity. Bai et al. [
6] proposed a vision algorithm that combined shape, texture, and color features for tomato recognition, employing geometric processing methods like Hough circle detection and spline interpolation for precise picking point localization in fruit bunches. However, their experiments focused entirely on single fruit bunches, overlooking the complex background information typically found in tomato greenhouses.
With advancements in deep-learning technology and the accelerated transformation of smart agriculture, convolutional neural network-based target-detection algorithms have been widely applied in tomato fruit detection due to their strong feature learning capabilities. Early target-detection algorithms adopted two-stage detection methods, with Faster R-CNN [
7] being a representative model. Sun et al. [
8] proposed a method based on an improved feature pyramid network (FPN) to enhance the recognition of tomato organs, achieving significant performance improvements over Faster R-CNN models, with mean average precision reaching 99.5%. Mu et al. [
9] used a tomato detection model combining Faster R-CNN and ResNet 101, achieving an average accuracy of 87.83% with intersection over union (IoU) ≥ 0.5. Seo et al. [
10] reported an 88.6% detection accuracy for tomatoes grown in hydroponic greenhouses using Faster R-CNN.
In recent years, the emergence of single-stage detection algorithms, which do not generate candidate regions like two-stage detection algorithms, significantly improves detection speed while maintaining high accuracy. These algorithms gradually become the preferred solution for fruit detection, with the single shot multibox detector (SSD) [
11] and the you only look once (YOLO) series [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21] being representative models. Yuan et al. [
22] replaced SSD’s backbone network with Inception V2, achieving an average precision (AP) of 98.85% for small tomato recognition in greenhouse environments. Vasconez et al. [
23] proposed an SSD integrated with MobileNet for accurate fruit counting in orchards, reaching a 90.0% success rate, thus facilitating improved decision making in agricultural practices. Zheng et al. [
24] introduced RC-YOLOv4, which integrated R-CSPDarknet53 and depthwise separable convolutions to improve the detection accuracy of small, distant, and partially occluded objects in complex environments. Ge et al. [
25] developed YOLO-deepSort, a target tracking network for recognizing and counting tomatoes at different growth stages, achieving average detection accuracies of 93.1%, 96.4%, and 97.9% for flowers, green tomatoes, and red tomatoes, respectively. Zeng et al. [
26] achieved a lightweight implementation with an mAP@0.5 of 96.9% while deploying an Android mobile application based on an improved YOLOv5. Phan et al. [
27] proposed four deep-learning frameworks (Yolov5m and Yolov5 based on ResNet-50, ResNet-101, and EfficientNet-B0, respectively) for classifying ripe, unripe, and damaged tomatoes, all of which achieved strong results. Li et al. [
28] introduced the MHSA-YOLOv8 model for tomato maturity grading and fruit counting, which was suitable for practical production scenarios. Chen et al. [
29] developed a cherry tomato multi-task detection network based on YOLOv7, which successfully handled cherry tomato detection, fruit, and fruit cluster maturity grading, with an average inference time of 4.9 ms (RTX3080). Yue et al. [
30] proposed an improved YOLOv8 network, RSR-YOLO, for long-distance recognition of tomato fruits, achieving accuracy, recall, F1-score, and mAP@0.5 of 91.6%, 85.9%, 88.7%, and 90.7%, respectively, while also designing a dedicated graphical user interface (GUI) for real-time tomato detection tasks.
In the study of tomato maturity recognition and classification, computational cost and model weight are key factors that directly impact the feasibility of the model in real-world deployment. As summarized in
Table 1, a comparative analysis of key metrics related to tomato maturity recognition and classification research is conducted based on the cited references. Zheng et al. [
24] improved YOLOv4 by incorporating depthwise separable convolutions to enhance the ability to capture small objects, achieving high-precision tomato maturity classification. However, they did not consider the model size and inference time needed for actual deployment. Zeng et al. [
26] focused on deploying lightweight models on mobile devices with limited performance, significantly reducing model parameters by using the MobileNetV3 lightweight backbone and a pruned neck network, although there was still room for optimization in inference time. Li et al. [
28] introduced the multi-head self-attention (MHSA) mechanism to enhance YOLOv8’s diverse feature extraction capabilities, enabling tomato maturity classification in complex scenarios with occlusion and overlap. However, to ensure accuracy improvement, the study did not reduce model parameters and computational costs, nor did it fully account for practical deployment needs. Chen et al. [
29] added two additional decoders on the basis of YOLOv7 to detect tomato fruit bunches, fruit maturity, and bunch maturity, and they utilized scale-sensitive intersection over union (SIoU) to improve the model’s recognition accuracy. These improvements did not significantly increase inference time, but the high computational cost (103.3 G) limited the model’s further deployment. Yue et al. [
30] enhanced feature fusion and used repulsion loss to improve YOLOv8 for tomato maturity classification and detection in large-area environments. However, its inference time (13.2 ms) and FLOPs (16.9 G) were higher than YOLOv8n’s 7.9 ms and 8.1 G. Overall, these advancements indicate progress in addressing the challenges of tomato maturity recognition and classification. However, there remains considerable opportunity for further research to reduce computational costs and model weight, which are crucial for practical deployment and scalability.
In prolonged robotic picking operations, models capable of performing multiple tasks simultaneously are essential for reducing computational costs [
31,
32,
33]. Achieving accurate simultaneous recognition of tomato maturity and stem position is crucial for enhancing the performance and operational efficiency of tomato-picking robots, with further improvements needed in detection precision. Additionally, even on picking robots with limited computing power, lightweight designs can optimize operations and reduce energy consumption [
34,
35,
36]. Current studies often overlook the necessity of distinguishing between foreground and background targets in picking scenarios [
37,
38]. In real tomato-picking environments, attention should be focused on the nearest row of targets while ignoring background elements.
To address these challenges, this study proposes an innovative lightweight model, MTS-YOLO, trained using a dataset annotated to include both the maturity of tomato fruit bunches and their stems. Compared to existing advanced detection methods, MTS-YOLO features fewer parameters, efficient feature fusion capabilities, and higher multi-task detection accuracy. Additionally, it tackles the challenge of distinguishing foreground picking targets from the background in practical picking scenarios. The specific contributions are as follows:
- (1)
We propose the top-down select feature fusion module (TSFF), which enhances the MFDS-DETR [
39] SFF module by replacing bilinear interpolation with DySample [
40] upsampling, using point sampling to eliminate convolution operations, resulting in a lighter model with faster inference.
- (2)
We propose HLIS-PAN, featuring the newly designed down-top select feature fusion module (DSFF), which fuses low-level features into high-level features, compensating for positional information loss and improving semantic understanding. Compared to the YOLOv8 neck network, HLIS-PAN is lighter and more efficient.
- (3)
We integrate CAA [
41] to sharpen the focus on central features, enhance elongated target recognition, and boost foreground detection precision, which contributes to optimizing the picking robot’s performance.
The remainder of this paper is organized as follows:
Section 2 introduces the dataset utilized and provides a detailed description of the enhancements made to the model;
Section 3 presents the experimental results, followed by validation and analysis;
Section 4 discusses the current state of research on maturity and picking object-detection algorithms, the limitations of this study, and offers perspectives on future research directions;
Section 5 concludes this study.
5. Conclusions
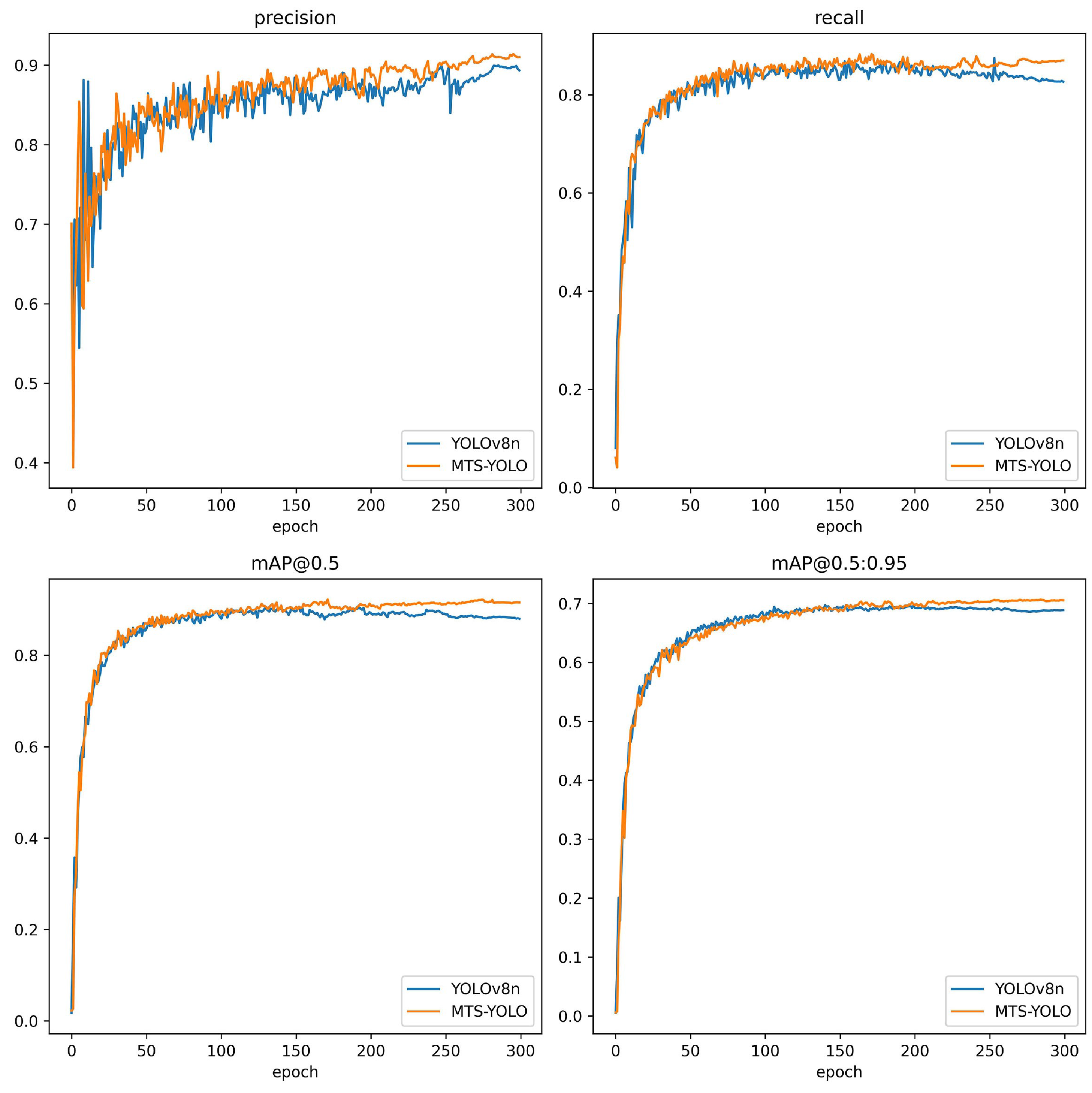
This study proposes MTS-YOLO, a lightweight model designed for detecting tomato fruit bunch maturity and stem positions. Its lightweight design makes it ideal for deployment on resource-constrained picking robots, offering lower inference times and high accuracy, which enhance picking performance. MTS-YOLO’s outstanding ability to recognize foreground targets effectively prevents the robot from straying from the intended picking area, thereby improving the overall efficiency of the picking process. The core of MTS-YOLO is the HLIS-PAN neck network, which excels in feature fusion while minimizing parameter redundancy. DySample is used for efficient upsampling, resulting in a lower computational load and reduced inference time. Additionally, the integration of CAA enhances the model’s focus on foreground targets, ensuring precise detection and improved recognition of elongated targets, even in complex picking scenarios. Experimental results demonstrate that MTS-YOLO achieves an F1-score of 88.7% and mAP@0.5 of 92.0%, outperforming several state-of-the-art models by notable margins, all while maintaining a significantly smaller number of parameters (2.05 M) and FLOPs (6.8 G). Compared with YOLOv5n, YOLOv6n, YOLOv7-tiny, YOLOv8n, YOLOv9t, and YOLOv10n, MTS-YOLO shows F1-score improvements of 2.2%, 2.4%, 2.9%, 2.4%, 2.4%, and 4.4%, respectively, and mAP@0.5 improvements of 2.0%, 2.7%, 2.1%, 1.4%, 0.9%, and 4.6%, respectively. Visualization and heatmap results validate the model’s precision in identifying mature fruit bunches and stems. The ablation studies further confirm the effectiveness of HLIS-PAN in enhancing the model’s recognition capabilities. In summary, MTS-YOLO excels in the multi-task detection of tomato fruit bunches and stems, offering a highly efficient technical solution for intelligent fruit picking in agriculture.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}