Abstract
In this paper, a lightweight model—OMC-YOLO, improved based on YOLOv8n—is proposed for the automated detection and grading of oyster mushrooms. Aiming at the problems of low efficiency, high costs, and the difficult quality assurance of manual operations in traditional oyster mushroom cultivation, OMC-YOLO was improved based on the YOLOv8n model. Specifically, the model introduces deeply separable convolution (DWConv) into the backbone network, integrates the large separated convolution kernel attention mechanism (LSKA) and Slim-Neck structure into the Neck part, and adopts the DIoU loss function for optimization. The experimental results show that on the oyster mushroom dataset, the OMC-YOLO model had a higher detection effect compared to mainstream target detection models such as Faster R-CNN, SSD, YOLOv3-tiny, YOLOv5n, YOLOv6, YOLOv7-tiny, YOLOv8n, YOLOv9-gelan, YOLOv10n, etc., and that the mAP50 value reached 94.95%, which is an improvement of 2.62%. The number of parameters and the computational amount were also reduced by 26%. The model provides technical support for the automatic detection of oyster mushroom grades, which helps in realizing quality control and reducing labor costs and has positive significance for the construction of smart agriculture.
1. Introduction
Mushrooms are fungi with important nutritional value, and there are about 2000 edible species worldwide [1]. The most cultivated species include Agaricus bisporus, Lentinula edodes, and Pleurotus ostreatus. The current global fresh mushroom market was valued at USD 38 billion in 2018 [2]. China is one of the world’s largest producers and exporters of wild edible mushrooms; the value of edible mushroom cultivation ranks in the top five after grain, vegetable, fruit, and edible oil cultivation and is larger than sugar, cotton, and tobacco. Mushroom cultivation has had a significant impact on China’s poverty alleviation program, with incomes at least ten times higher than those from rice and maize, and the rapid development of the market and increased demand for edible mushrooms have generally strengthened the domestic edible mushroom economy [3].
However, oyster mushroom cultivation is still mainly performed manually, which is inefficient and costly, and it is also difficult to ensure the quality of the mushrooms. The future trend of edible mushroom production will be from automation to intelligence and informationization [4]. Bria et al. [5] used a fuzzy logic system to predict the size and quality of oyster mushrooms by utilizing the temperature, light intensity, and humidity. Cikarge and Arifin also used fuzzy logic to maintain an optimum humidity and thus promote the growth of oyster mushrooms [6]. Meanwhile, Rawidean et al. [7] implemented a smart mushroom farm using IoT technology to provide optimal conditions for mushroom growth. At the other end of the production spectrum, harvesting and grading are equally important. In many rural mushroom farms, growing conditions and economic factors often prevent growers from utilizing industrial automation to harvest mushrooms. Due to the short shelf life of fresh mushrooms, untimely harvesting can lead to a decline in mushroom quality, resulting in significant economic losses [8]. Not only are labor costs very high, but the accuracy of human judgment may decrease with increases in working hours, so intelligent picking and grading are of great significance for the development of smart mushroom factories.
Algorithms for deep learning and target detection have been developing rapidly in recent years, and machine vision will be applied in large quantities to automated, intelligent agricultural growing bases in the future [9,10,11,12]. There are many related research works on applying deep learning to mushroom smart factories: Alok Mukherjee [13] from IIT Malda, India, used two supervised learning models combining Support Vector Machines (SVMs) and Artificial Neural Networks (ANNs) to carry out classification of the freshness and deterioration of oyster mushrooms. Qian et al. [14] improved SSD Convolutional Neural Networks combined with a binocular depth camera to realize the recognition and localization of flat oyster mushrooms in three-dimensional space to accomplish the task of oyster mushroom picking. Chuan-Pin Lu et al. [15], from Meiwa University, utilized a YOLOv3 algorithm combined with a self-designed Score-Punishment algorithm for mushroom cap measurements. BOHAN Wei [16] et al., from Zhejiang College of Tongji University, utilized an improved YOLOv5 algorithm for detecting edible mushrooms. Wang Leilei et al. [17], from Hebei University of Engineering, used the improved YOLOv5 algorithm to detect the maturity of oyster mushrooms. The YOLO algorithm has become the mainstream model for target detection due to its advantages of being fast, lightweight, and much better than traditional models in the design of its single-stage model. Current research mainly focuses on the mature picking of oyster mushrooms, and there is no research on the use of the mainstream YOLO algorithm for detecting the grading of oyster mushrooms. This paper synthesizes the above research and adopts YOLOv8 for the grading detection of oyster mushrooms.
Furthermore, by applying YOLOv8 to the grading detection of oyster mushrooms, this paper proposes an OMC-YOLO model and optimizes and improves the network model according to the characteristics of oyster mushrooms, which improves its detection accuracy while making the model more lightweight. The model shows good results in solving the problems of omission, wrong detection, and low accuracy when detecting oyster mushrooms.
The main contributions of this paper are as follows: firstly, images of oyster mushrooms were collected through self-growing and internet resources, and they were organized and labeled to extend the oyster mushroom dataset. Secondly, depth-wise separable convolution (DWConv) [18] was used to replace the regular convolution of part of the backbone network so that the number of model parameters decreased and was more lightweight. Then, large separable kernel attention (LSKA) [19] was incorporated into the C2F module in the Neck part, which focuses on localized regions of the input feature maps through advanced spatial attention convolution processing to enhance the model’s ability to understand and capture spatial details. Then, Slim-Neck was used in the Neck part, including GSConv instead of the regular convolution and incorporating the use of VoVGSCSP to replace the C2F part of the Neck in order to alleviate the resistance of the deep layer to the data flow and to reduce the inference time. Finally, the Distance-IoU (DIoU) loss function [20] was selected by comparing experiments with different loss functions.
2. Materials and Methods
2.1. Material
The dataset was collected through both self-photography and online channels. A Redmi k50 cell phone(Xiaomi Corporation, Bejing, China) was used to take photos of the oyster mushrooms grown by our team in the experimental field ( Jilin Agricultural University, Changchun, China), resulting in 825 images of oyster mushrooms. Additionally, 1414 images of oyster mushrooms were obtained from the internet. By enhancing some of the self-acquired oyster mushroom images with techniques such as flipping, shearing, rotating, adjusting brightness, and adding noise, as well as modifying saturation and hue data and adjusting their labels with flipping, shearing, and rotating, 1504 enhanced images were obtained (Figure 1 is a schematic diagram of the data-enhancement effect). In total, the oyster mushroom dataset comprised 3502 images.

Figure 1.
Data enhancement effect diagram.
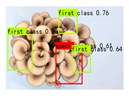
In this study, the images were manually labeled according to the 2015 edition of the Chinese classification standard for oyster mushrooms, NY/T2715-2015, and were classified into Special Class, First Class, Second Class, and Unripe categories. The Unripe category is included because of the fact that the growth time of oyster mushrooms in the same packet is not uniform, and the collection of images may contain immature oyster mushrooms, making it impossible to grade them at that time. Figure 2 shows example images of Special Class, First Class, and Second Class oyster mushrooms from the dataset, and Table 1 identifies the criteria for grading.

Figure 2.
Schematic diagram of different grades of oyster mushrooms.

Table 1.
Chinese National Standard Table for Grading Oyster Mushrooms, 2015 Edition.
Finally, all the images were randomly divided into a training set, validation set, and test set at a ratio of 6:2:2, with 2334 images in the training set and 584 images in the validation set and test set, respectively. Table 2 shows the label distribution in the oyster mushroom dataset.
Table 2.
Table of label distribution of dataset.
2.2. The Improved YOLOv8
The YOLO algorithm [21,22], known as YOU ONLY LOOK ONCE, is a fast and accurate single-stage target detection algorithm; it divides the whole image into grids and predicts the confidence of the presence of objects in each grid as well as gives the prediction frame, and then gives the final prediction result through non-maximal suppression. YOLOv8 [23] is a relatively lightweight network, and its detection effect and speed are very good among the mainstream target detection models. Compared with YOLOv5 [24], YOLOv8 omits the convolutional structure in the up-sampling stage of Feature Pyramid Networks (FPN) [25] and Path Aggregation Network (PANet) [26] and replaces the C3 module with the C2F module in the whole model and replaces the head portion with a decoupled head design. The loss function of YOLOv8 consists of a classification loss function and a regression loss function. The classification loss function employs the Varifocal Loss (VFL) [23], the regression loss function adopts Complete-IoU (CIoU) loss combined with Distribution Focal Loss (DFL) [23], and YOLOv8 also adopts the idea of an anchor-free prediction frame.
In practice, a more lightweight model will reduce costs and improve certain efficiency; therefore, OMC-YOLO adopts the YOLOv8n model as the basis for improvement to detect the quality of oyster mushrooms.
OMC-YOLO replaces the backbone network with DWConv, adds LSKA to the C2F module in the Neck section, replaces the conventional convolution with GSConv, replaces the C2F module with VoVGSCSP, and replaces the more effective DIoU loss function for the oyster mushroom dataset. These modules improved the network structure of the YOLOv8 model and enhanced the detection ability of the model while making it more lightweight. Figure 3 shows the original YOLOv8 model, and the network structure of OMC-YOLO is shown in Figure 4, with the improvements circled in red.
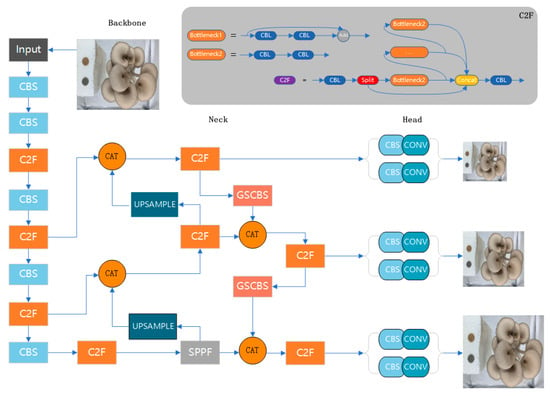
Figure 3.
YOLOv8’s original model structure.
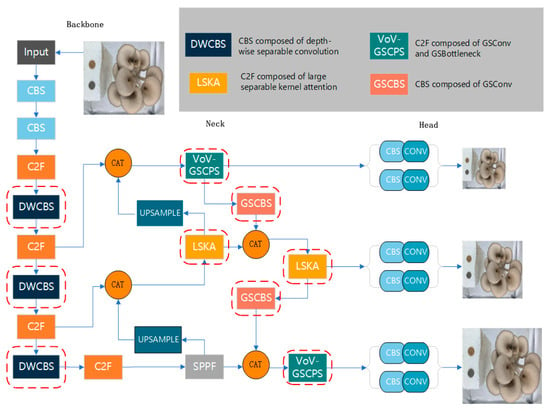
Figure 4.
OMC-YOLO network architecture diagram.
2.2.1. Depth-Wish Separable Convolution
In order to reduce the computational cost and make the oyster mushrooms quality recognition model more lightweight, a lightweight convolution module is needed to replace the traditional convolution. DWConv, as a lightweight alternative, has been widely used in embedded devices and mobile applications since its introduction in 2017, and especially performs well in the YOLO target detection framework, which is particularly suitable for oyster mushrooms classification. Compared to traditional convolutional layers, DWConv decomposes the standard convolution into deep convolution and pointwise convolution, thereby reducing the number of total parameters and computational complexity. This decomposition allows DWConv to focus on a single channel during deep convolution, thus improving the efficiency of the model. Figure 5 illustrates the network structure for depth-wise separable convolutions.
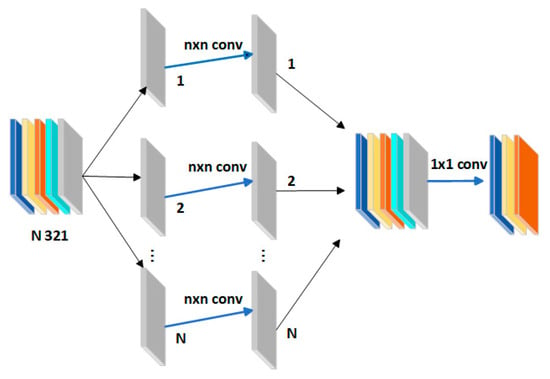
Figure 5.
Depth-separable convolution module structure.
Standard Convolution:
Deep Convolution:
Pointwise Convolution:
is the output feature map at . is the input feature map. is the convolution kernel. is the output feature map of the channel in the deep convolution. is the m channel of the deep convolution kernel. is the m element of the point-by-point convolution kernel. is the final output after point-by-point convolution.
Real-time processing and resource constraints are critical when performing oyster mushrooms grading in YOLO. DWConv provides a lightweight solution, and by employing DWConv, OMC-YOLO can simplify the computation while maintaining or improving the accuracy. DWConv enables a more efficient feature extraction process by using specialized convolutional kernels that efficiently process each channel separately. Compared to traditional convolution, the computational complexity of DWConv (denoted as ) is significantly lower than standard convolution (denoted as ). This reduction in complexity means faster inference times and smaller memory footprints, making DWConv particularly suitable for resource-constrained applications.
2.2.2. Large Separable Kernel Attention
Increasing the receptive field helps to enhance the feature extraction capability of the CNN model and improve the recognition performance for objects of different sizes, especially in oyster mushrooms hierarchical recognition tasks. CNNs can use the attention mechanism to simulate long-distance dependencies or extend the receptive field by stacking convolutional layers or increasing the convolutional kernel. However, stacking convolutional layers increases the model’s parameter size, while increasing the convolutional kernel creates higher memory and computational costs.
The Visual Attention Network (VAN) proposed by Guo et al. [27] employs an approach known as Large Kernel Attention (LKA). LKA combines standard deep convolution with a small receptive field kernel to capture local dependencies and expansive deep convolution with a large receptive field kernel to model long-range dependencies. However, as the size of the convolutional kernel increases, the deep convolutional layers in the LKA module lead to a quadratic increase in computation and memory. To address this problem, Lau et al. [19] proposed the LSKA module, which consists of a residual structure comprising four depth-separable convolutional blocks and a point-by-point convolutional block. Figure 6 shows a comparison of the network structure of LKA and LSKA.
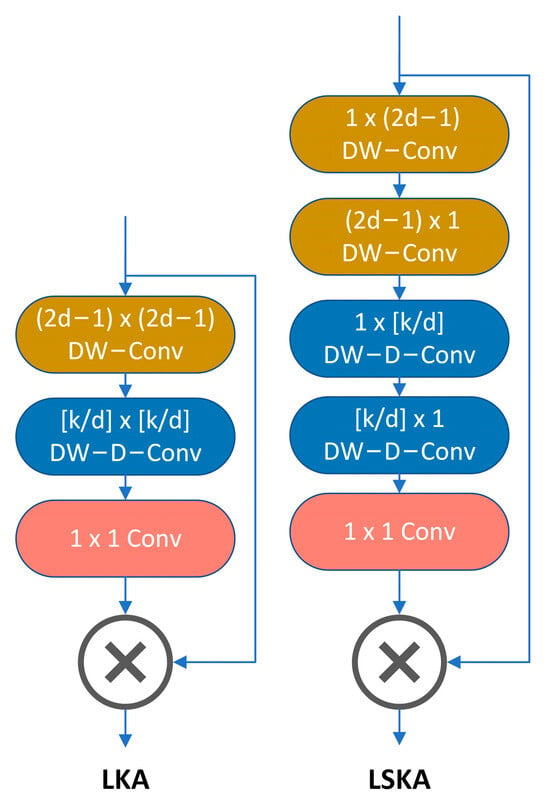
Figure 6.
The structure of LKA and LSKA.
In the point-by-point convolution stage, the output channels of the depth convolution are linearly combined using a 1 × 1 convolution kernel. It is demonstrated that the LSKA module employed in the VAN is able to achieve comparable performance to the standard LKA module while reducing computational complexity and memory footprint. The LSKA output is shown in Equations (7)–(10), and all the parameters in Equations (7)–(10) will be explained in detail in this paper, as well as the computational symbols. and stand for convolution and the Hadamard product, respectively.
where is the output of the deep convolution obtained by convolving a kernel W of size k × k with the input feature map of F. The output of LSKA is the Hadamard product of the attention map and the input feature map [28].
The C2F module of YOLOv8 introduces LSKA, which replaces the bottleneck section. The module works as follows: the input passes through the Conv module and is divided into two parts. one part is processed through multiple layers of bottleneck, and the other part remains unchanged. Finally, the two parts concatenate together and output through the Conv module. In this module, Bottleneck1 is used for the backbone’s C2F, and Bottleneck2 is used for the neck’s C2F. Figure 7 shows the original C2F module of YOLOv8.
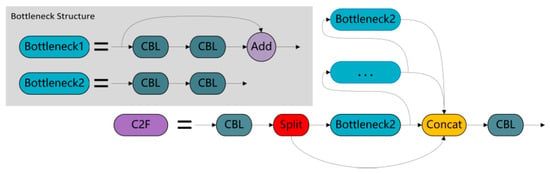
Figure 7.
YOLOv8’s original C2F module.
Figure 8 illustrates the C2F module of OMC-YOLO with LSK Attention, replacing bottleneck. LSK Attention introduces the mechanism of attention to local regions, which is realized by a series of grouped convolutions with different expansion rates and kernel sizes. These convolutions focus on different local regions and set different attentional focuses according to the kernel size, enhancing the network’s ability to capture spatial information. In contrast, the bottleneck architecture improves the computational efficiency of the network mainly by changing the dimensionality of the feature maps, while LSK Attention enhances the model’s ability to understand and capture spatial details through advanced spatial attention convolution processing.
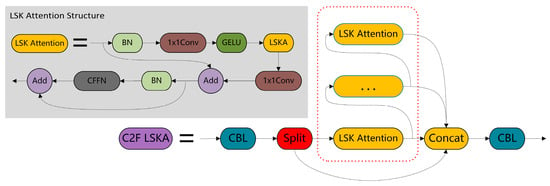
Figure 8.
C2F module after adding LSKA.
2.2.3. Slim-Neck
OMC-YOLO uses the Slim-Neck module [29], which consists of two parts, GSConv and VoV-GSCSP. GSConv is added to the Neck part, and part of the C2F module is replaced with the VoV-GSCSP module. GSConv is used to accelerate the prediction computation because, in CNNs, the feed image usually needs to undergo a gradual transfer of spatial information to the channel-transfer conversion process. Dense convolution preserves the hidden connections as much as possible, while sparse convolution cuts off these connections. GSConv reduces the resistance due to the depth of the model while preserving the connections and no longer needs to perform transformations when dealing with slender feature maps in the Neck stage. Therefore, it is more appropriate to use GSConv in the Neck phase when the feature maps do not require further compression, and GSConv maintains the connections while reducing redundant information. In real-time monitoring applications, in order to make the oyster mushroom hierarchical model more lightweight, a lightweight convolution should be used in both the backbone and Neck parts, and GSConv is the best choice. Figure 9 shows the network structure of GSConv.
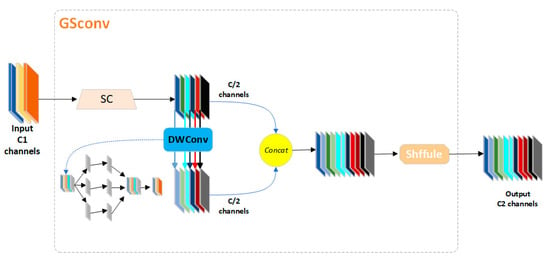
Figure 9.
GSConv module structure.
GSConv provides an efficient method to reduce model complexity while maintaining accuracy, achieving a better balance between model accuracy and speed. In addition, it introduces the Slim-Neck design paradigm, which helps to improve the computational cost-effectiveness of the detector [27]. In previous work, LSKA has successfully replaced the first and third C2F modules in the Neck part. Here, we utilize the VoVGSCSP module to replace the C2F module of the Neck section, and this design provides higher efficiency and performance. Figure 10 shows the network structure of VoV-GSCSP:
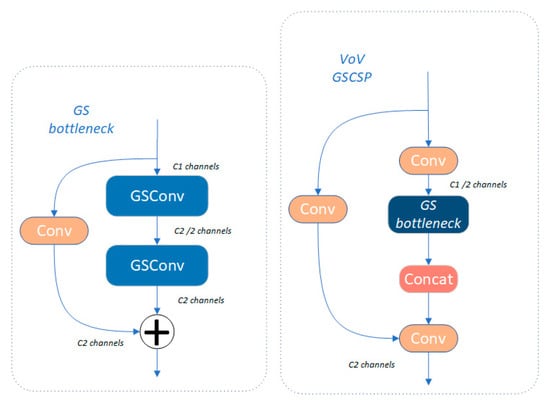
Figure 10.
VoVGSCSP and GSbottleneck module architecture.
In GSbottleneck, two GSConv and one standard convolution operation are defined and applied to the inputs, respectively. The standard convolution operation helps promote gradient flow and avoids gradient vanishing. This structure is similar to residual connectivity and encourages the network to learn the residuals between the inputs and outputs, improving training efficiency and performance. The final outputs form a bottleneck structure for residual learning by summing rather than simply splicing.
2.2.4. DIoU Loss Function
OMC-YOLO uses the DIoU loss function [20] (14) for the bounding box regression task of grading oyster mushrooms. This loss function combines the normalized distance between centroids and IoU [30] (13) to promote accurate localization. The DIoU loss is particularly effective for grading flat oyster mushrooms that are relatively regular in shape, and centroid alignment directly affects accuracy. The DIoU loss provides an effective gradient signal under non-overlapping frames, accelerating model convergence. Its computational simplicity without complex aspect ratio adjustment improves the training efficiency. Experiments show that DIoU loss outperforms traditional IoU loss and other variants, proving its superiority in specific application scenarios. YOLOv8 uses VFL Loss for classification loss and CIoU Loss combined with DFL for regression loss. The orginal loss function in YOLOv8 consists of a classification loss function and a regression loss function, with the classification loss function employing the VFL Loss (11) and the regression loss function employing the CIoU Loss (15) combined with DFL (12).
DIoU loss for bounding box regression, where the normalized distance between centroids can be directly minimized. is the diagonal length of the smallest closed box covering both boxes, and is the distance between the centroids of the two boxes.
This study aims to achieve automatic grading of oyster mushrooms through deep learning models. In the process of model training, various mainstream bounding box regression loss functions are considered, such as SIoU [31], EIoU, GIoU [32], WIoU [33], CIoU [20], among which DIoU has the best results. After a series of experiments, the results are shown in Table 3. It is found that OMC-YOLO using the DIoU loss function outperforms the models using the other loss functions on the oyster mushroom graded dataset.
Table 3.
Experimental table comparing different loss functions.
The DIoU loss function performs more efficiently in the oyster mushroom grading task, as it directly optimizes centroid alignment, improving the speed of exact matching of the bounding box and positioning accuracy. In contrast, although CIoU loss considers aspect ratio consistency, in the case of oyster mushrooms, the small difference in aspect ratios is not enough to significantly improve the performance, but rather increases the model complexity. Therefore, DIoU loss is more suitable for this task.
2.3. Training Equipment and Parameter Setting
2.3.1. Experimental Environment and Parameter Adjustment
The hardware environment of the experimental platform for the training and testing of the oyster mushroom dataset in this paper is as follows: the CPU is 12th Gen Intel Core i5-12400F@4.00 GHz, the GPU is NVIDIA GeForce RTX 3060 (12 Gigabytes of video memory), the RAM is 32 Gigabytes (32 MHz), the operating system is 64-bit Windows 10, CUDA version 12.0, Pycharm 2023 2.1, Pytorch 2.0.2, Python 3.8. All the comparative experiments in this paper were conducted in the same environment. The training configurations are learning rate of 0.01, momentum of 0.937, weight decay of 0.0005, batch size of 16, a total of 100 iteration rounds, and image size of 640 × 640 pixels. Table 4 shows the configuration information of the experimental environment.
Table 4.
Experimental environment configuration table.
2.3.2. Model Evaluation Indicators
The evaluation metrics adopted in this paper are mean average precision (mAP), precision(P), recall(R), Params, Giga Floating-point Operations Per Second (GFLOPS), etc. Among them, TP denotes correct prediction, and FP denotes wrong prediction. At the same time, P represents the proportion of real frames among the target frames detected by the algorithm, which is calculated by matching the predicted frames with the real labeled frames. When the IoU is larger than a certain threshold (e.g., 0.5 or 0.7), it is considered to be a correctly detected target. Then, the ratio of the number of correctly detected target frames to the total number of predicted frames is calculated. The ratio of the number of correctly detected target frames to the total number of predicted frames is then calculated. R, calculated by TPand precision, is the ratio of correctly recognized positive instances to all real positive instances. Recall is calculated by matching the predicted frames with the real labeled frames, and when the overlap is greater than a certain threshold, it is considered to be a correctly detected target and then calculates the ratio of the number of correctly detected target frames to the number of real labeled frames. mAP is used to sort predicted frames according to the confidence and calculates the precision according to different thresholds. mAP is used to sort the predicted frames according to the confidence level, calculate the precision and recall according to different thresholds, and finally calculate the average precision of different categories. The higher the mAP value, the higher the prediction precision. GFLOPS is a unit used to measure the performance of a computer, which refers to the number of floating point operations per second. Reducing GFLOPS can make the inference of the model faster, which reduces the cost of hardware as well as saves energy for embedded devices, makes it easier to train and optimize the model, and enhances the model’s generalization ability. These metrics adopted in this paper are commonly used in the field of deep learning, and the following formula is applied to the calculation of the above metrics:
3. Results
3.1. Comparison of Ablation Experiments
First, OMC-YOLO reduces the number of parameters by 27% by replacing three convolutional layers with deeply separable ones in the backbone network part of YOLOv8, making the model more lightweight. Secondly, the first and third C2F modules in the Neck section add C2Fs with large separable convolutional attention modules, which reduces the number of parameters by 13% and enhances the model’s ability to understand and capture spatial details by focusing on localized regions of the input feature maps through advanced spatial attention convolutional processing. Then, the second and fourth C2F modules are replaced with VoVGSCSP modules, and the two convolutions connected upwards in the Neck part are replaced with GSConv, resulting in a 10% reduction in the number of parameters of the model. The use of GSConv and VoVGSCSP preserves as much as possible the hidden connectivity of these channels, and for going to the Neck part of the already slimmed-down feature maps, the use of GSConv can alleviate the resistance of the deeper layers to the data flow and significantly reduce the inference time. Finally, the original CIoU loss function of YOLOv8 is replaced by the DIoU loss function, with the best tested effect by comparing the six loss functions in the experiments. After these improvements, the parameter count was reduced by 26%, the model size by 1.26 MB, and the GFLOPS computation by 26%, while the mAP effect improved by 2.62%, all while maintaining the same FPS detection speed. This achieves a significant improvement in detection performance while making the model more lightweight (see Table 5 for a comparison of the effect of the ablation experiments) and makes the YOLOv8 network more suitable for the hierarchical level of oyster mushroom dataset target detection.
Table 5.
Table of ablation experiment results.
Figure 11a illustrates the increase in values of mAP50, mAP95, and precision for each module one by one, and Figure 11b illustrates the number of parametric quantities replacing each module. In Figure 11a, L represents the replacement of BottleNeck with the LSKA in the C2F in the Neck part; DW represents the replacement of part of the regular convolution in the Backbone part using DWConv; G represents the replacement of the regular convolution in the Neck part using GSConv, as well as the replacement of part of the regular C2F modules in the Neck part using the VoVGSCSP modules; and D stands for the use of the DIoU loss function.
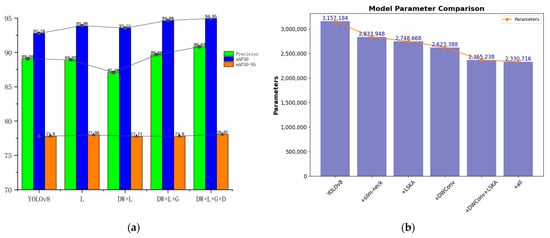
Figure 11.
(a) Plot of mAP and precision results of ablation experiments; (b) Plot of parametric quantities for ablation experiments.
Figure 12 shows the comparison of the precision–recall (PR) curves before and after improvement. The PR curve of OMC-YOLO is convex toward the upper right corner compared to the original model as a whole, which represents the improved combined value of precision and recall of the improved model. The mAP50 values derived from the PR values are improved in all four categories: the special class from 0.928 to 0.969, the first class from 0.945 to 0.958, the second class from 0.977 to 0.982, and the Unripe category from 0.861 to 0.888.
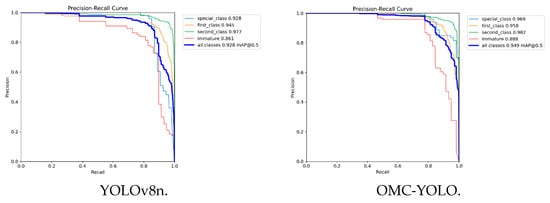
Figure 12.
The comparison of PR curve of YOLOv8n and OMC-YOLO.
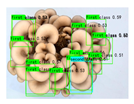
The comparison chart in Table 6 shows the ability of OMC-YOLO to solve the problems on the oyster mushrooms grading dataset compared to YOLOv8 through examples. The comparison shows that OMC-YOLO is able to solve the problems of missed detection, false alarms, and low accuracy to a certain extent, and the confidence level of prediction is significantly improved, while the error rate of detection and grading is also significantly reduced. For example, some oyster mushrooms in the table are incorrectly recognized by YOLOv8, while OMC-YOLO can correctly recognize them, and OMC-YOLO can also better solve the omission problem of smaller unripe oyster mushrooms. As shown in the following table, there are two unripe oyster mushrooms in total, and the original YOLOv8 model can only detect one of them, which is an omission problem. The original YOLOv8 model can only detect one unripe oyster mushroom, which has the problem of missed detection, while OMC-YOLO can accurately detect two unripe oyster mushrooms.
Table 6.
OMC-YOLO detection effect table.
3.2. Comparison of Detection Performance between Different Models
In this paper, by comparing YOLOv3-tiny [34] (Darknet-19), YOLOv5 (CSPDarknet53), YOLOv6 [35] (EfficentRep), YOLOv7-tiny [36] (E-ELAN), YOLOv8n (Darknet53), YOLOv9-gelan [37] (Combining CSPNet and ELAN), and YOLOv10n [38] (Generalized ELAN with CSPNet, RepConv) models of the YOLO family and other mainstream models such as the Faster R-CNN [39] (Resnet 50) and SSD [40] (Resnet 50) model, we verified that the detection effect of OMC-YOLO is higher than that of the other models. Additionally, the sizes, number of parameters, and GFLOPS computation are smaller than other models. The reason for selecting YOLOv3-tiny, YOLOv7-tiny, and YOLOv9-gelan (currently the most lightweight version in the official Github open source code) is that since YOLOv8n itself is a lightweight model and the original models of YOLOv3, YOLOv7, and YOLOv9 have larger sizes, their lightweight versions are selected for comparison with the lightweight YOLOv8n model for comparison. Figure 13 shows a comparison of the number of parameters and the mAP50 effect for each model.
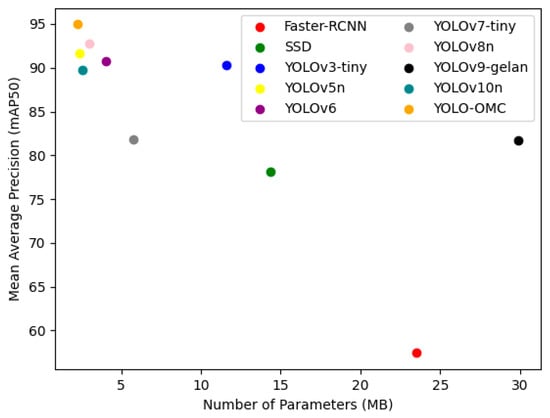
Figure 13.
Comparison of number of parameters and mAP50 in different models.
For Faster R-CNN, SSD models, whose backbone networks are selected asResnet50 [38], the mAP50 values of OMC-YOLO are 37.52% and 16.78% higher than Faster R-CNN and SSD models, the precision is 36.7% and 4.63% higher, the recall is 28.34% and 17.65%, while the model size is lower by 103.31 MB and 42.01 MB, respectively. The mAP50 value of the OMC-YOLO model is the highest among the YOLO series of models, reaching 94.95%, which is 2.17% higher compared to YOLOv8n, with a precision increase of 1.75%, a recall increase of 0.2%, and a reduction of 1.26 MB in the model size. The number of parameters of OMC-YOLO is only 7.83% of the number of parameters of the Faster R-CNN model, which is 15.55% of the SSD, and the amount of computation is only 0.07% of the Faster R-CNN, which is 43.70% of the SSD. The comparison in the YOLO series is not only ahead of the latest YOLOv10n in terms of the number of parameters and mAP values as well as the amount of computation but also reduces the number of parameters and the amount of computation by about 26% when compared with the YOLOv8n model. The effect of each model is shown in Table 7.
Table 7.
Table of results of comparative experiments.
Figure 14 shows a comparison of the mAP50 values of the training process of the YOLO series of models, which shows that OMC-YOLO is significantly more effective than the other models.
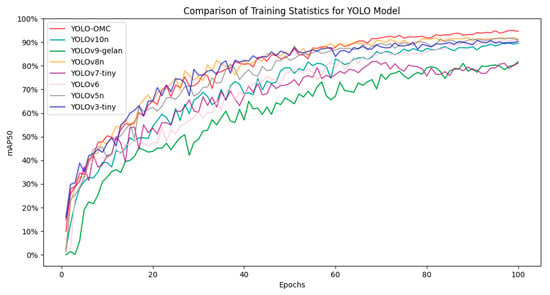
Figure 14.
Comparison of mAP50 for the training process.
Figure 15 shows the normalized confusion matrices of the three models, OMC-YOLO, YOLOv8n, and YOLOv10n, through which the detection effectiveness of each model on the test set (see Table 2 for the number of sample distributions) can be compared. It is obvious from the figure that OMC-YOLO has a significant improvement in the detection effect compared to YOLOv8n and YOLOv10n. Especially for Special-class, the classification accuracy of OMC-YOLO reaches 85.19%, compared with 79.63% and 77.78% for YOLOv8n and YOLOv10n, respectively. In First Class categorization, the accuracy of OMC-YOLO is 89.52%, which is also higher than 84.84% for YOLOv8n and 85.02% for YOLOv10n. In addition, OMC-YOLO also shows higher accuracy in two categories, Second Class and Unripe.
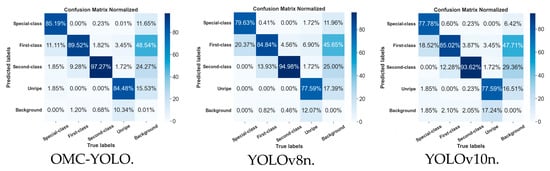
Figure 15.
Comparison of confusion matrices.
For the Background category, the Unripe category was most easily recognized as background, which was explained by the fact that the samples in this category were usually smaller and closer to the surface of the sticks. For this category, the OMC-YOLO model had the lowest probability of misidentifying it as background at 10.34%, compared to 12.07% and 17.24% for YOLOv8n and YOLOv10n, respectively. However, OMC-YOLO has slightly higher misidentification rates in the First Class and Second Class categories, 0.38% and 0.22%, respectively.
These analyses show that OMC-YOLO performs well in all categorization tasks, especially in Special Class, First Class, and Background categorization, demonstrating significant improvement in effectiveness.
4. Discussion
The performance of OMC-YOLO was compared via ablation and comparison experiments, and the performance results were significantly better than YOLOv8 and its mainstream models. To ensure that the model does not overfit the data, we used separate training, validation, and test sets. The dataset was divided into 60% for training, 20% for validation, and 20% for testing. Table 8 shows the detection performance of OMC-YOLO compared to YOLOv8 and other models on several test sets, demonstrating that the model generalizes well to new data.
Table 8.
Effectiveness of different models in detection of selected test sets table.
We employed techniques such as early stopping and regularization to prevent overfitting. Training was halted when the validation loss stopped improving, thereby avoiding an overly complex model that might fit the noise in the training data. Additionally, we used Dropout and weight decay to penalize overly complex models, promoting simplicity and generalization. To evaluate bias and variance, we compared the training loss and validation loss. The small gap between these losses indicated low variance, while the lower validation loss suggested low bias. Figure 16 shows the prediction frame loss, classification loss, and DFL for the OMC-YOLO training and validation sets. The loss values leveled off at 100 epoch iterations, indicating that the training had converged without overfitting. The step-down in the training set loss values in the last ten rounds was due to the image mosaic being turned off during the last ten rounds of training, which improved the model’s stability and reduced unnecessary noise in the later stages of training.
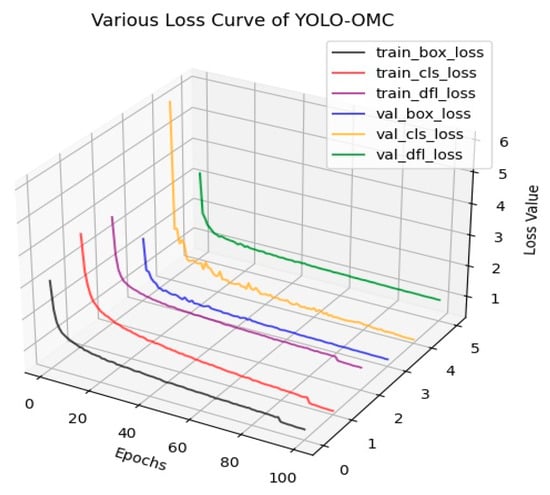
Figure 16.
Training and validation set loss values for OMC-YOLO.
The excellent performance of OMC-YOLO stems from the various modules added in this paper for the features of the oyster mushroom dataset. The main role of the Neck part of the model is to integrate and extract the features from the previous convolutional layers and scale fusion for objects of different sizes, playing a decisive role in the final detection results. The main improvement of OMC-YOLO focuses on the Neck part, firstly by integrating the LSKA attention mechanism and secondly by adopting the Slim-Neck network structure.
Figure 17 shows the performance of the heat map after adding the large separable convolutional kernel attention mechanism. The darker color of the heat map and the denser heat performance on the detected objects after the addition prove that LSKA pays more attention to the local region of the input feature map, which enhances the model’s ability to understand and capture spatial details.
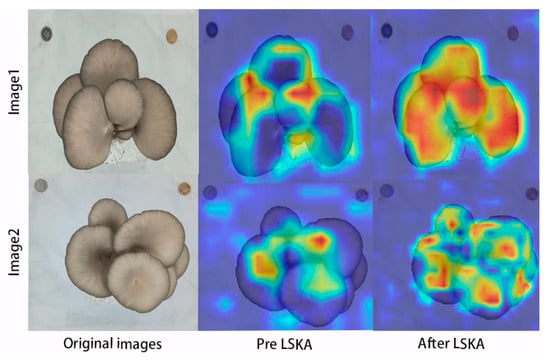
Figure 17.
Comparison of the heat map visualization before and after adding the LSKA module.
The Slim-Neck module, on the other hand, is a module specifically designed to improve on the Neck section. Its usefulness for the Neck section has been extensively described. The use of GSConv and VoVGSCSP preserves as many of the hidden connections of these channels as possible. For feature maps that have become slender by the time they reach the Neck section, the use of GSConv alleviates the deeper resistance to the data flow, significantly reducing inference time. Table 9 shows a comparison of the performance of the Slim-Neck module on the Neck section alone, both overall and by category, and it is clear that the module has a significant impact on the final performance of OMC-YOLO.
Table 9.
Comparison of the performance of OMC-YOLO before and after adding Slim-Neck in each category and overall.
5. Conclusions
Currently, the process of mushroom cultivation has been partially applied with intelligence, but it still mainly relies on manual labor in picking and sorting, which is not only time-consuming but also labor-intensive. OMC-YOLO effectively improves the accuracy and efficiency of grading detection of oyster mushrooms by adopting the latest YOLOv8 model and optimizing it for the characteristics of oyster mushrooms. The experimental results show that the improved model outperforms the current mainstream target detection models, including Faster R-CNN, SSD, and various versions of the YOLO series, and that OMC-YOLO is suitable for sorting oyster mushrooms in automated mycological factories.
OMC-YOLO carries out in-depth network model optimization and improvement for its characteristics, which effectively improves the accuracy and efficiency of oyster mushroom sorting detection. By introducing DWConv, LSKA, and Slim-Neck modules and adopting the DIoU loss function, OMC-YOLO not only significantly reduces the number of parameters and computation volume of the model and realizes model lightweighting but also enhances the model’s ability to extract oyster mushroom features, which in turn improves the accuracy of detection. The experimental results show that OMC-YOLO outperforms the current mainstream target-detection models in the oyster mushrooms classification detection task, especially in the mAP50 value of 94.95%, with improvements in the Special Class, First Class, and Second Class of 4.16%, 1.33%, and 0.48%, which are higher than that of the YOLOv8 model, and the number of parameters and computation as well as the size of the model have also been reduced, verifying the effectiveness of the optimization improvement.
Despite the results achieved in this study, the challenges of the diversity of appearance characteristics of oyster mushrooms, the complexity of cultivation environments, and the stability of the model under different light conditions still exist. Future work will focus on improving the performance and reliability of the model in more complex and variable real-world application scenarios by further expanding the training dataset, optimizing the model structure and tuning parameters. In addition, exploring more efficient algorithms and techniques to cope with the accuracy problem of Unripe mushroom detection is also an important direction for subsequent research. Through continuous technological innovation and optimization, it is expected that fully automated and intelligent cultivation and management of oyster mushrooms will be realized in the near future, contributing more scientific and technological power to the development of the edible mushroom industry.
Author Contributions
Conceptualization, L.S. and Z.W.; Data curation, L.S.; Formal analysis, L.S., Z.W. and H.Y. (Haohai You); Funding acquisition, H.Y. (Helong Yu) and C.B.; Investigation, L.S., Z.W., H.Y. (Haohai You), J.W. and Z.B.; Methodology, L.S. and Z.W.; Project administration, H.Y. (Helong Yu); Resources, L.S., J.W., H.Y. (Helong Yu) and C.B.; Software, Z.W.; Supervision, H.Y. (Helong Yu) and R.J.; Validation, Z.W. and H.Y. (Haohai You); Visualization, C.B. and R.J.; Writing—original draft, Z.W.; Writing—review and editing, H.Y. (Helong Yu) and R.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Agriculture and Rural Affairs project, grant number NK202302020205.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to the privacy policy of the organization.
Acknowledgments
The main author expresses sincere gratitude to the School of Information Technology, Jilin Agriculture University, for supplying the essential equipment. The unavailability of these tools would have hindered the completion of this study. We also extend our appreciation to the anonymous reviewers for their invaluable input.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rathore, H.; Prasad, S.; Kapri, M.; Tiwari, A.; Sharma, S. Medicinal Importance of Mushroom Mycelium: Mechanisms and Applications. J. Funct. Foods 2019, 56, 182–193. [Google Scholar] [CrossRef]
- Wan Mahari, W.A.; Peng, W.; Nam, W.L.; Yang, H.; Lee, X.Y.; Lee, Y.K.; Liew, R.K.; Ma, N.L.; Mohammad, A.; Sonne, C.; et al. A Review on Valorization of Oyster Mushroom and Waste Generated in the Mushroom Cultivation Industry. J. Hazard. Mater. 2020, 400, 123156. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Xu, S. Edible Mushroom Industry in China: Current State and Perspectives. Appl. Microbiol. Biotechnol. 2022, 106, 3949–3955. [Google Scholar] [CrossRef]
- Marinoudi, V.; Sørensen, C.G.; Pearson, S.; Bochtis, D. Robotics and Labour in Agriculture. A Context Consideration. Biosyst. Eng. 2019, 184, 111–121. [Google Scholar] [CrossRef]
- Bria, Y.; Ngaga, E.; Olviana, P. Fuzzy Logic Application to Predict The Size Quality of White Oyster Mushroom with Temperature, Light Intensity and Humidity Inputs. Int. J. Adv. Res. Comput. Sci. 2016, 7, 1–6. [Google Scholar]
- Cikarge, G.P.; Arifin, F. Oyster Mushrooms Humidity Control Based On Fuzzy Logic By Using Arduino ATMega238 Microcontroller. J. Phys. Conf. Ser. 2018, 1140, 012002. [Google Scholar] [CrossRef]
- Kassim, M.R.M.; Mat, I.; Yusoff, I.M. Applications of Internet of Things in Mushroom Farm Management. In Proceedings of the 2019 13th International Conference on Sensing Technology (ICST), Sydney, Australia, 2–4 December 2019; pp. 1–6. [Google Scholar]
- Thuc, L.V.; Corales, R.G.; Sajor, J.T.; Truc, N.T.T.; Hien, P.H.; Ramos, R.E.; Bautista, E.; Tado, C.J.M.; Ompad, V.; Son, D.T.; et al. Rice-Straw Mushroom Production. In Sustainable Rice Straw Management; Springer: Cham, Switzerland, 2020; pp. 93–109. [Google Scholar]
- Yang, S.; Zhang, H.; Xing, L.; Du, Y. Improved MobileViT Network for Lightweight Field Weed Recognition. Trans. Chin. Soc. Agric. Eng. 2023, 39, 152–160. [Google Scholar]
- Zhou, G.; Ma, S.; Liang, F. Apple Recognition in Panoramic Images Based on Improved YOLOv4 Model. Trans. Chin. Soc. Agric. Eng. 2022, 38, 159–168. [Google Scholar]
- Li, T.; Sun, M.; Ding, X.; Li, Y.; Zhang, G.; Shi, G.; Li, W. Tomato Ripeness Recognition Method Based on YOLO v4+HSV. Trans. Chin. Soc. Agric. Eng. 2021, 37, 183–190. [Google Scholar]
- An, Z.; Li, Z.; Liu, S.; Zhao, Y.; Chen, Q.; Zuo, R.; Lin, Y. Multi-Class Seafood Counting Method Integrating YOLOv7 and BYTE Multi-Object Tracking. Trans. Chin. Soc. Agric. Eng. 2023, 39, 183–189. [Google Scholar]
- Mukherjee, A.; Sarkar, T.; Chatterjee, K.; Lahiri, D.; Nag, M.; Rebezov, M.; Shariati, M.A.; Miftakhutdinov, A.; Lorenzo, J.M. Development of Artificial Vision System for Quality Assessment of Oyster Mushrooms. Food Anal. Methods 2022, 15, 1663–1676. [Google Scholar] [CrossRef]
- Yang, Q.; Rong, J.; Wang, P.; Yang, Z.; Geng, C. Real-Time Detection and Localization Using SSD Method for Oyster Mushroom Picking Robot. In Proceedings of the IEEE International Conference on Real-time Computing and Robotics (RCAR), Irkutsk, Russia, 18–22 August 2020; pp. 158–163. [Google Scholar]
- Lu, C.-P.; Liaw, J.-J. A Novel Image Measurement Algorithm for Common Mushroom Caps Based on Convolutional Neural Network. Comput. Electron. Agric. 2020, 171, 105336. [Google Scholar] [CrossRef]
- Wei, B.; Zhang, Y.; Pu, Y.; Sun, Y.; Zhang, S.; Lin, H.; Zeng, C.; Zhao, Y.; Wang, K.; Chen, Z. Recursive-YOLOv5 Network for Edible Mushroom Detection in Scenes with Vertical Stick Placement. IEEE Access 2022, 10, 40093–40108. [Google Scholar] [CrossRef]
- Wang, L.; Wang, B.; Li, D.; Zhao, Y.; Wang, C.; Zhang, D. Oyster Mushroom Detection and Classification in Mushroom Rooms Based on Improved YOLOv5. Trans. Chin. Soc. Agric. Eng. 2023, 39, 163–171. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Lau, K.W.; Po, L.-M.; Rehman, Y.A.U. Large Separable Kernel Attention: Rethinking the Large Kernel Attention Design in CNN. Expert Syst. Appl. 2024, 236, 121352. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27 June–1 July 2016; pp. 779–788. [Google Scholar]
- Jocher, G. YOLOv8 by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 15 February 2023).
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Guo, M.-H.; Lu, C.-Z.; Liu, Z.-N.; Cheng, M.-M.; Hu, S.-M. Visual Attention Network. Comp. Visual Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Lu, Y.; Sun, M. SSE-YOLO: Efficient UAV Target Detection With Less Parameters and High Accuracy. Preprints 2024, 2024011108. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-Neck by GSConv: A Better Design Paradigm of Detector Architectures for Autonomous Vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Cho, Y.-J. Weighted Intersection over Union (wIoU): A New Evaluation Metric for Image Segmentation. arXiv 2023, arXiv:2107.09858. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1–6. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]




























Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).