
Wineinformatics: Can Wine Reviews in Bordeaux Reveal Wine Aging Capability?


Abstract
:1. Introduction
2. Methods and Materials
2.1. Wine Reviews
- 50–74 Not recommended
- 75–79 Mediocre: A drinkable wine that may have minor flaws
- 80–84 Good: A solid, well-made wine
- 85–89 Very good: A wine with special qualities
- 90–94 Outstanding: A wine of superior character and style
- 95–100 Classic: A great wine
2.2. Bordeaux Dataset
2.3. Extract Consumption Data
2.4. Methods
- Define the problem
- Employ algorithms (KNN, naïve Bayes, SVM)
- Dimension reduction
- Compute results
2.4.1. Algorithms
The KNN Algorithm
Support Vector Machines (SVM)
2.4.2. Evaluation
2.4.3. Dimension Reduction
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Muhammad, I.; Yan, Z. Supervised machine learning approaches: A survey. ICTACT J. Soft Comput. 2015, 5, 946–952. [Google Scholar] [CrossRef]
- Khanum, M.; Mahboob, T.; Imtiaz, W.; Ghafoor, H.A.; Sehar, R. A Survey on Unsupervised Machine Learning Algorithms for Automation, Classification and Maintenance. Int. J. Comput. Appl. 2015, 119, 34–39. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Padakandla, S. A survey of reinforcement learning algorithms for dynamically varying environments. ACM Comput. Surv. 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Chen, B.; Velchev, V.; Palmer, J.; Atkison, T. Wine Informatics: A Quantitative Analysis of Wine Reviewers. Fermentation 2018, 4, 82. [Google Scholar] [CrossRef] [Green Version]
- Schuring, R. RoboSomm Chapter 3: Wine Embeddings and a Wine Recommender. Available online: https://towardsdatascience.com/robosomm-chapter-3-wine-embeddings-and-a-wine-recommender-9fc678f1041e (accessed on 12 November 2020).
- Chen, B. Wineinformatics: 21st Century Bordeaux Wines Dataset. IEEE Dataport. 2020. Available online: https://ieee-dataport.org/open-access/wineinformatics-21st-century-bordeaux-wines-dataset (accessed on 18 October 2021).
- Ugliano, M. Oxygen contribution to wine aroma evolution during bottle aging. J. Agric. Food Chem. 2013, 61, 6125–6136. [Google Scholar] [CrossRef] [PubMed]
- Tao, Y.; García, J.F.; Sun, D. Advances in wine aging technologies for enhancing wine quality and accelerating wine aging process. Crit. Rev. Food Sci. Nutr. 2014, 54, 817–835. [Google Scholar] [CrossRef] [PubMed]
- Dong, Z.; Guo, X.; Rajana, S.; Chen, B. Understanding 21st Century Bordeaux Wines from Wine Reviews Using Naïve Bayes Classifier. Beverages 2020, 6, 5. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Rhodes, C.; Crawford, A.; Hambuchen, L. Wineinformatics: Applying data mining on wine sensory reviews processed by the computational wine wheel. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 142–149. [Google Scholar]
- Chen, B.; Le, H.; Rhodes, C.; Che, D. Understanding the wine judges and evaluating the consistency through white-box classification algorithms. In Proceedings of the Industrial Conference on Data Mining, New York, NY, USA, 13–17 July 2016; Springer: Cham, Switzerland, 2016; pp. 239–252. [Google Scholar]
- Palmer, J.; Chen, B. Wineinformatics: Regression on the Grade and Price of Wines through Their Sensory Attributes. Fermentation 2018, 4, 84. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Chawla, V.N.; Japkowicz, N.; Kotcz, A. Special issue on learning from imbalanced data sets. ACM SIGKDD Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Kuang, Q.; Zhao, L. A practical GPU based kNN algorithm. In Proceedings of the 2009 International Symposium on Computer Science and Computational Technology (ISCSCI 2009), New Orleans, LA, USA, 31 August–4 September 2009; Academy Publisher: Oulu, FL, USA, 2009; p. 151. [Google Scholar]
- Metsis, V.; Androutsopoulos, I.; Paliouras, G. Spam Filtering with Naive Bayes—Which Naive Bayes? CEAS 2018, 17, 28–69. [Google Scholar]
- Suykens, K.J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Ray, I.S. SVM: Support Vector Machine Algorithm in Machine Learning. 2020. Available online: https://www.analyticsvidhya.com/blog/2017/09/understaing-support-vector-machine-example-code/ (accessed on 28 November 2020).
- Fan, L.; Poh, K.L. A comparative study of PCA, ICA and class-conditional ICA for naïve bayes classifier. In Proceedings of the International Work-Conference on Artificial Neural Networks, San Sebastián, Spain, 20–22 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 16–22. [Google Scholar]
- Zhang, M.L.; Peña, J.M.; Robles, V. Feature selection for multi-label naive Bayes classification. Inf. Sci. 2009, 179, 3218–3229. [Google Scholar] [CrossRef]

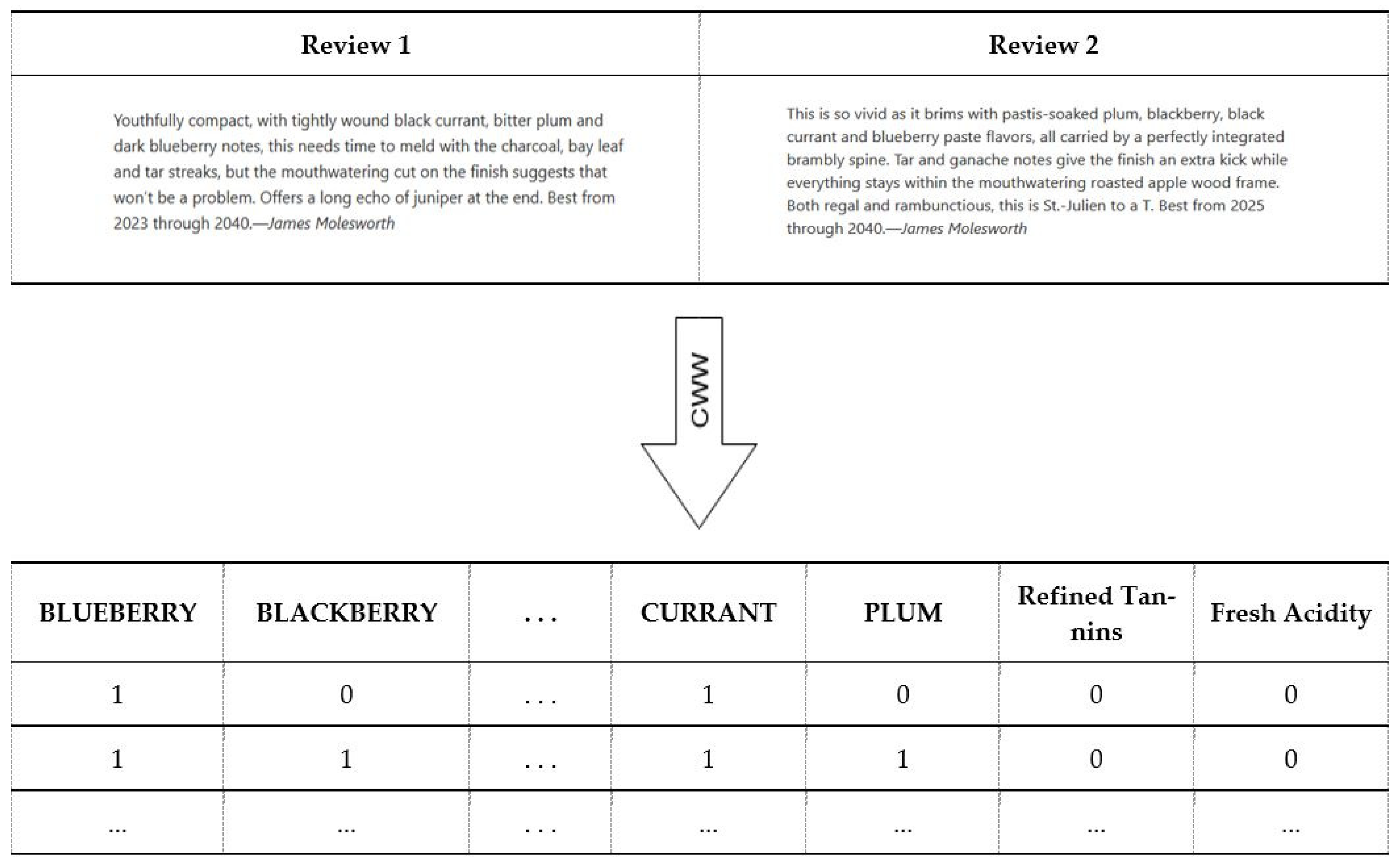


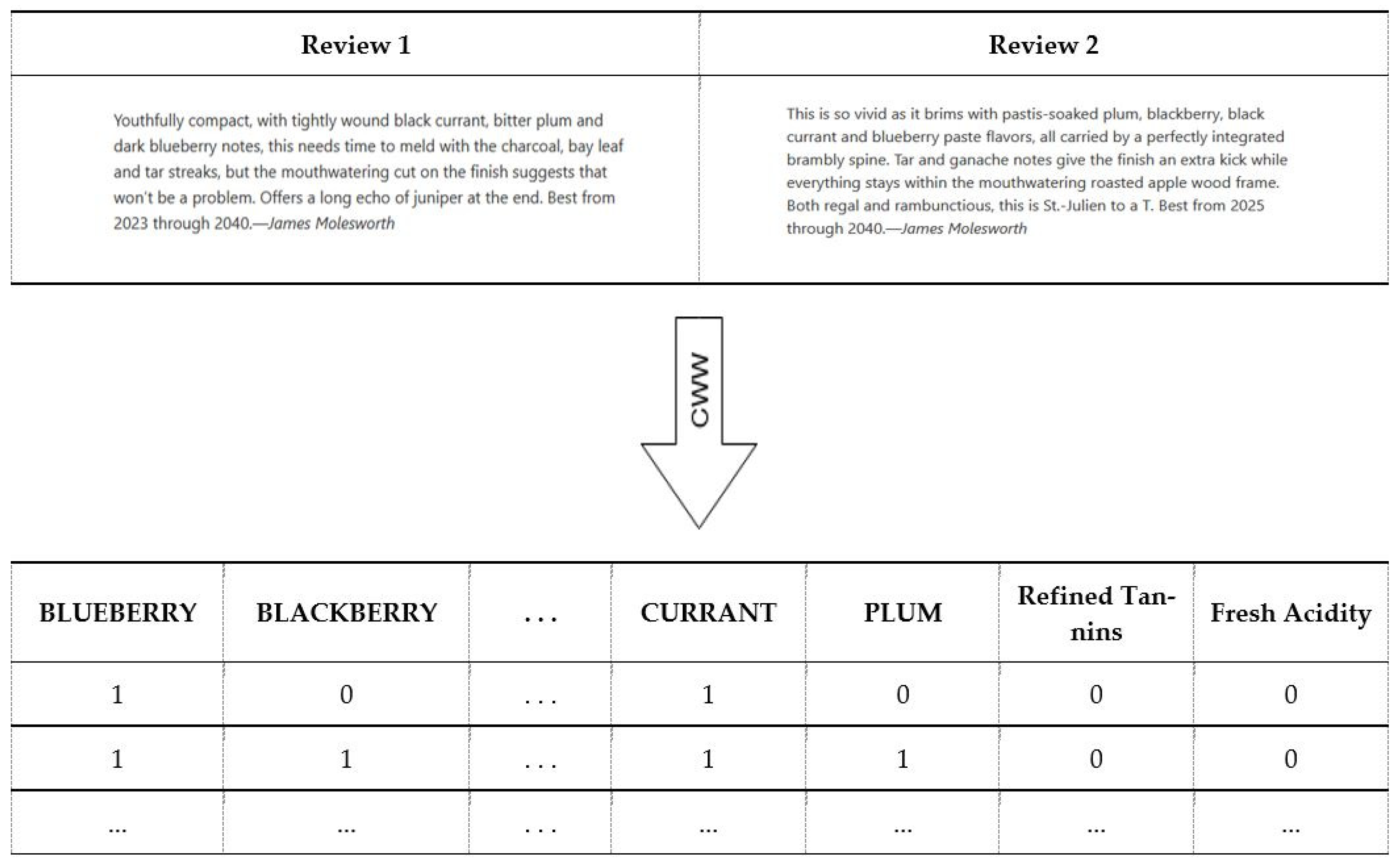
{kind=link}
{kind=link}
{kind=link}
| Threshold for Drink-or-Hold Aging Capability | Drink (<than Aging Capability) | Hold (≥than Aging Capability) |
|---|---|---|
| 5 years | 185 | 720 |
| 6 years | 401 | 504 |
| 7 years | 572 | 333 |
| Boysenberry | … | Current | Plum | Refined Tannings | Fresh Acidity | Class Label (Drink as 0 Hold as 1) | |
|---|---|---|---|---|---|---|---|
| Wine A | 0 | … | 1 | 0 | 0 | 0 | 0 |
| Wine B | 1 | … | 1 | 1 | 0 | 0 | 1 |
| Confusion Matrix | Predicted: YES | Predicted: NO |
|---|---|---|
| Actual: YES | TP | FN |
| Actual: NO | FP | TN |
| Accuracy | Recall | Precision | F-Score | |
|---|---|---|---|---|
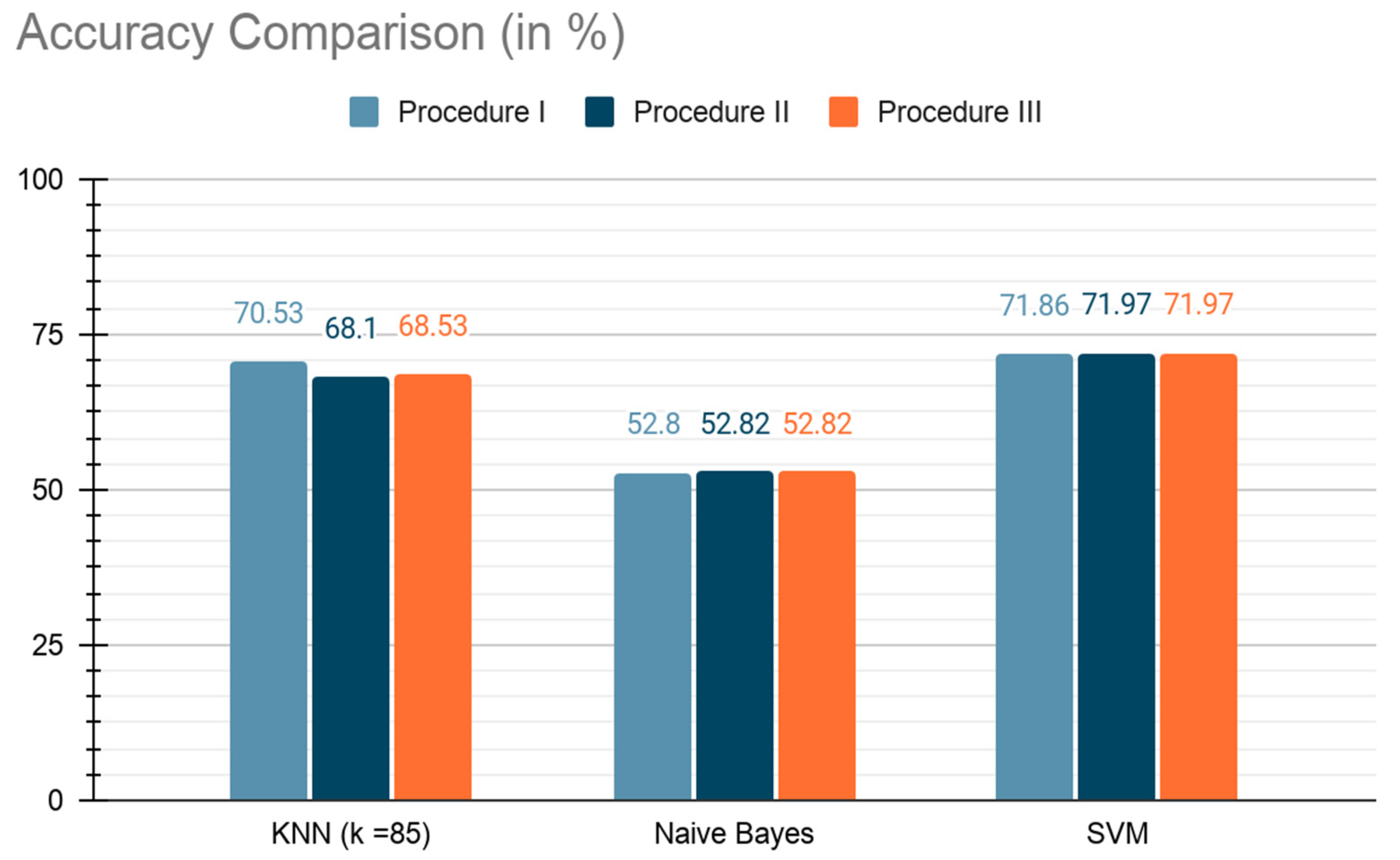
| Procedure I (all wine attributes) | 70.53% | 72.56% | 74.04% | 73.29% |
| Procedure II (FINISH attribute removed) | 68.10% | 75.55% | 70.37% | 72.86% |
| Procedure III (FRUIT, PLUM, GREAT, and FINISH attributes removed) | 68.53% | 84.10% | 67.46% | 74.86% |
| Accuracy | Recall | Precision | F-Score | |
|---|---|---|---|---|
| Procedure I (All wine attributes) | 52.92% | 22.35% | 80.13% | 34.33% |
| Procedure II (FINISH attribute removed) | 52.92% | 22.35% | 80.13% | 34.33% |
| Procedure III (FRUIT, PLUM, GREAT, and FINISH attributes removed) | 52.92% | 22.35% | 80.13% | 34.33% |
| Accuracy | Recall | Precision | F-Score | |
|---|---|---|---|---|
| Procedure I (All wine attributes) | 71.86% | 74.44% | 73.69% | 74.12% |
| Procedure II (FINISH attribute removed) | 71.97% | 74.55% | 74.26% | 74.40% |
| Procedure III (FRUIT, PLUM, GREAT, and FINISH attributes removed) | 71.97% | 74.95% | 74.51% | 78.75% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwabla, W.; Coulibaly, F.; Zhenis, Y.; Chen, B. Wineinformatics: Can Wine Reviews in Bordeaux Reveal Wine Aging Capability? Fermentation 2021, 7, 236. https://doi.org/10.3390/fermentation7040236
Kwabla W, Coulibaly F, Zhenis Y, Chen B. Wineinformatics: Can Wine Reviews in Bordeaux Reveal Wine Aging Capability? Fermentation. 2021; 7(4):236. https://doi.org/10.3390/fermentation7040236
Chicago/Turabian StyleKwabla, William, Falla Coulibaly, Yerkebulan Zhenis, and Bernard Chen. 2021. "Wineinformatics: Can Wine Reviews in Bordeaux Reveal Wine Aging Capability?" Fermentation 7, no. 4: 236. https://doi.org/10.3390/fermentation7040236
APA StyleKwabla, W., Coulibaly, F., Zhenis, Y., & Chen, B. (2021). Wineinformatics: Can Wine Reviews in Bordeaux Reveal Wine Aging Capability? Fermentation, 7(4), 236. https://doi.org/10.3390/fermentation7040236