The lncRNA Toolkit: Databases and In Silico Tools for lncRNA Analysis




Abstract
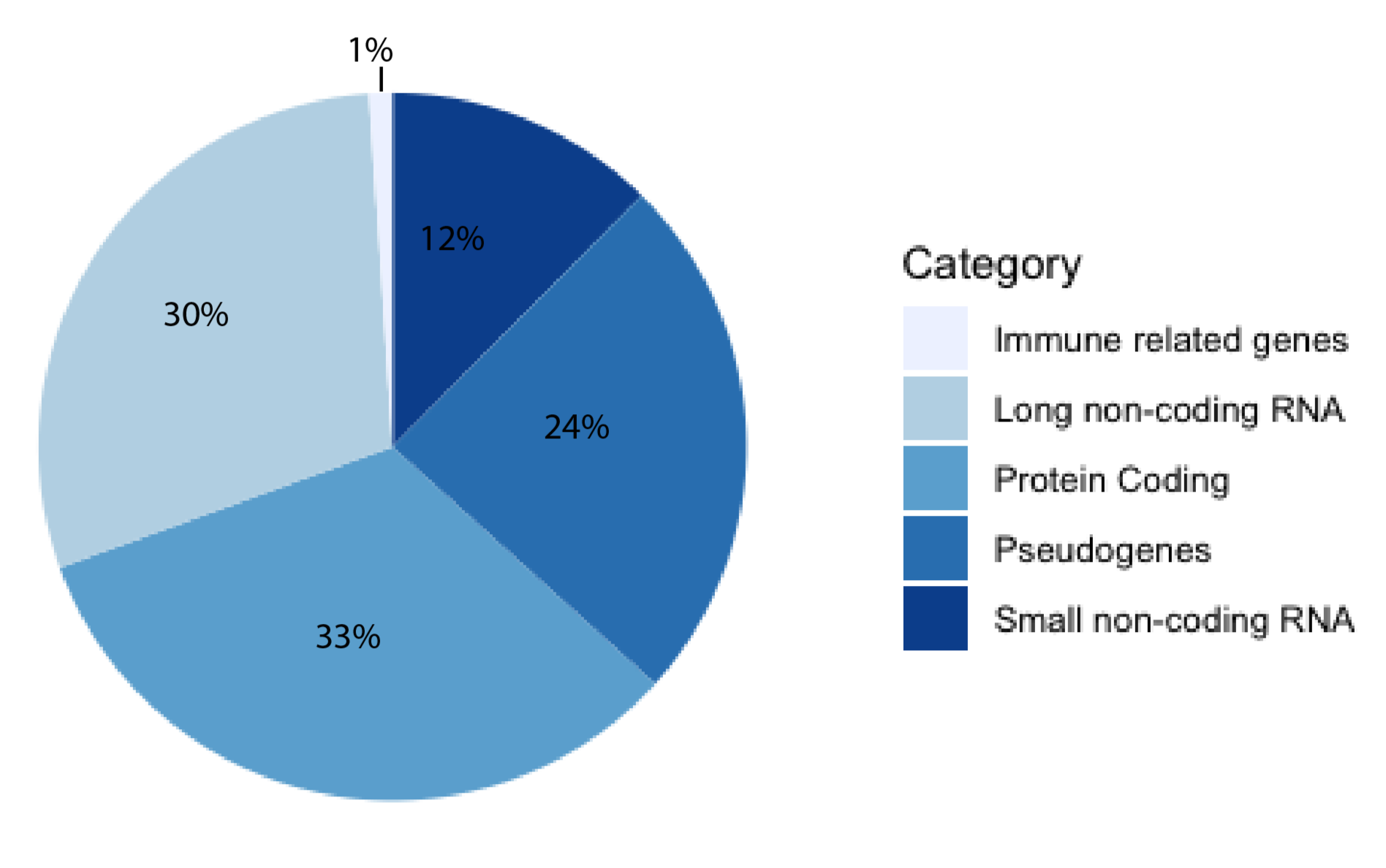
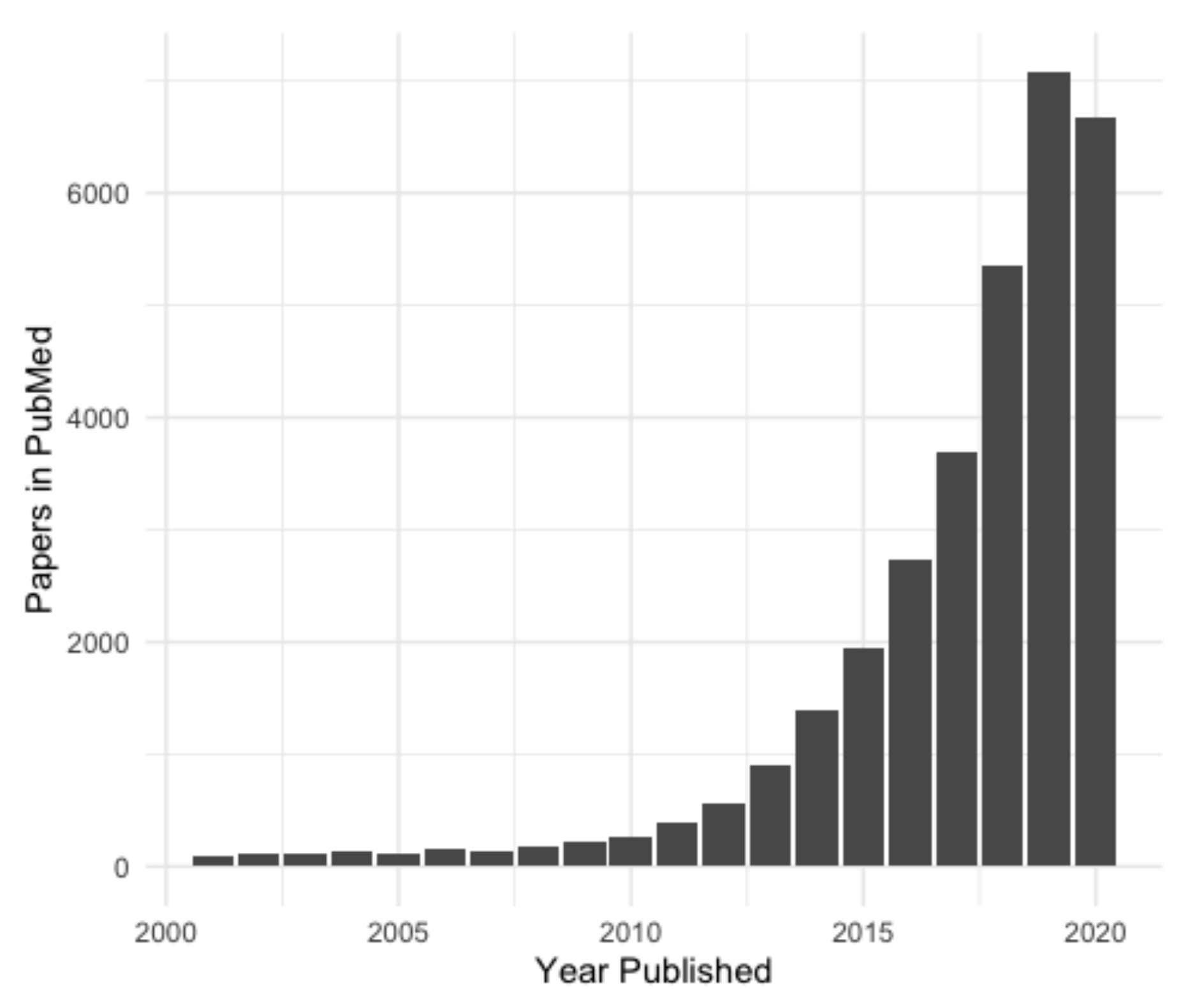
1. Introduction
2. General lncRNA Databases
2.1. LNCipedia
2.2. LNCBook
3. LncRNA Expression Databases
3.1. GTEx
3.2. TANRIC
3.3. CANTATAdb
4. Protein Coding Potential
4.1. CPPred
4.2. CNIT
5. Subcellular Localization
5.1. LncSLdb
5.2. LncATLAS
5.3. LncLocator
6. Structural Conformation
6.1. RMDB
6.2. RNAfold
6.3. DMfold
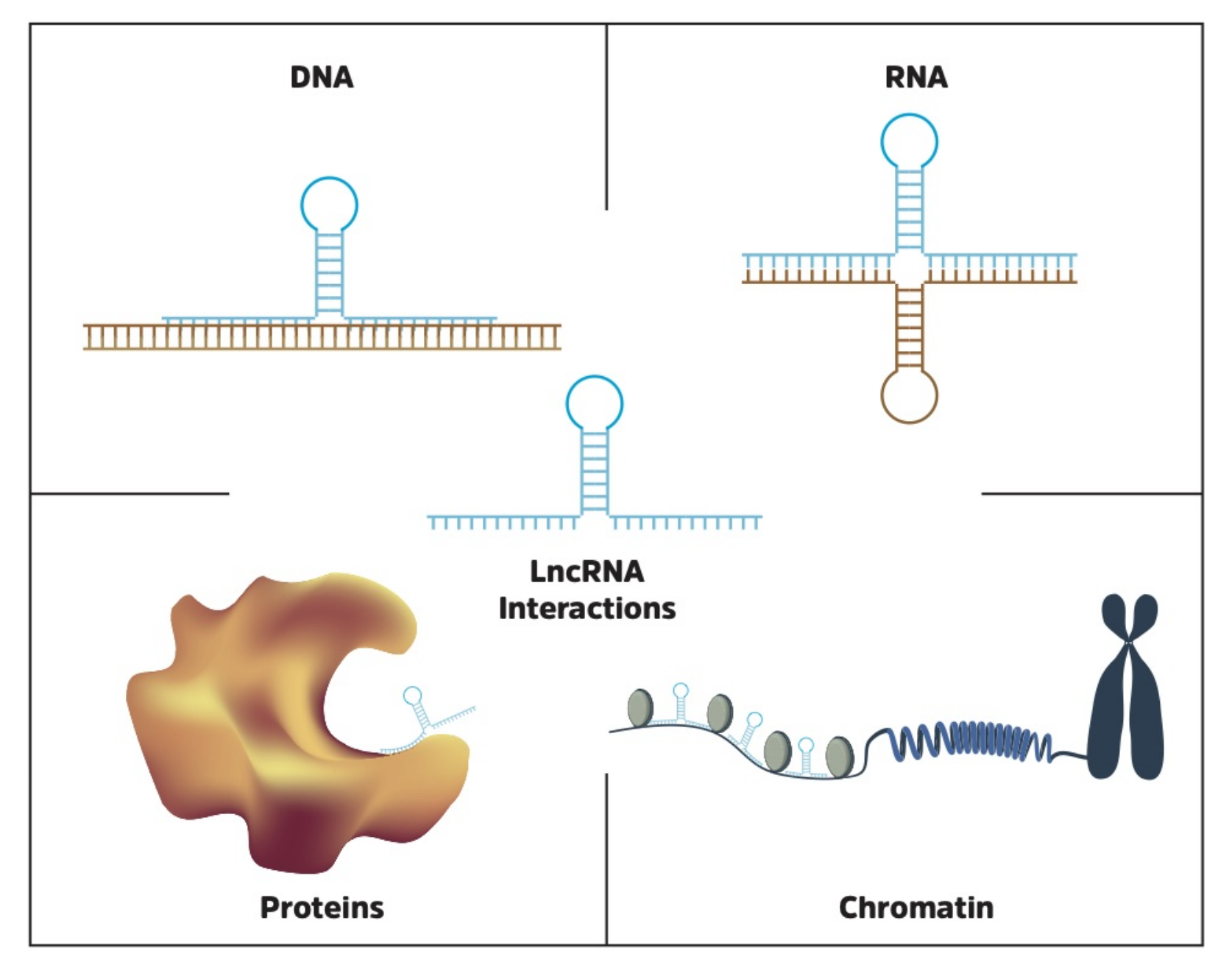
7. LncRNA Interactions
7.1. RNA Interactome Databases
7.1.1. RNAInter
7.1.2. RISE
7.2. LncRNA-RNA Interaction Prediction
7.2.1. IntaRNA
7.2.2. LncRRIsearch
7.3. LncRNA-DNA Interaction
7.3.1. LnChrom
7.3.2. Triplexator
7.4. LncRNA-Protein Interaction Prediction
SFPEL-LPI
8. Function Prediction
SEEKR
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Tool/Database Name | Description | Link | Citation |
|---|---|---|---|
| General lncRNA Databases | |||
| LNCipedia | General lncRNA database, expertly curated | https://lncipedia.org/ | [18,19] |
| LNCBook | General lncRNA database, some community curation | http://bigd.big.ac.cn/lncbook/index | [29] |
| Expression Databases | |||
| GTEx | Comprehensive public resource to study tissue-specific gene expression and regulation. | https://gtexportal.org/home/ | [39,40] |
| TANRIC | Database of non-coding RNAs in cancer | www.tanric.org | [42] |
| CANTATAdb | Database of plant lncRNAs | http://cantata.amu.edu.pl/ | [48,49] |
| Protein Coding Potential | |||
| CPC | Protein coding potential prediction | http://cpc.gao-lab.org/ | [55] |
| CPPred | Protein coding potential prediction | http://www.rnabinding.com/CPPred/ | [60] |
| CNIT | Protein coding potential prediction | http://cnit.noncode.org/CNIT/ | [62] |
| Subcellular Localization | |||
| LncSLdb | Database of lncRNA subcellular localization | http://bioinformatics.xidian.edu.cn/lncSLdb/ | [72] |
| LncATLAS | Database of lncRNA subcellular localization | https://lncatlas.crg.eu/ | [76] |
| LncLocator | LncRNA subcellular localization prediction | http://www.csbio.sjtu.edu.cn/bioinf/lncLocator/ | [77] |
| Structural Conformation | |||
| RMDB | Database of RNA structures | https://rmdb.stanford.edu | [94] |
| RNAfold | RNA structure prediction | http://rna.tbi.univie.ac.at/, http://rna.tbi.univie.ac.at/cgi-bin/RNAWebSuite/RNAfold.cgi | [95] |
| DMfold | RNA structure prediction with pseudoknots | https://github.com/linyuwangPHD/RNA-Secondary-Structure-Database | [96] |
| Interactions | |||
| RNAInter | Database of RNA interactions | http://www.rna-society.org/rnainter/ | [130] |
| RISE | Database of RNA interactions | http://rise.life.tsinghua.edu.cn | [123] |
| IntaRNA 2.0 | RNA-RNA interaction prediction | http://rna.informatik.uni-freiburg.de/IntaRNA/Input.jsp | [135] |
| LncRRISearch | LncRNA-RNA interaction prediction | http://rtools.cbrc.jp/LncRRIsearch/ | [137] |
| LnChrom | Database of lncRNA-Chromatin interactions | http://biocc.hrbmu.edu.cn/LnChrom/ | [149] |
| Triplexator | RNA-DNA interaction prediction | http://bioinformatics.org.au/tools/triplexator/ | [157] |
| SFPEL-LPI | LncRNA-protein interaction prediction | http://bioinfotech.cn/SFPEL-LPI/ | [166] |
| Function Prediction | |||
| SEEKR | K-mer similarity predictor | http://seekr.org/home | [168] |
References
- Hangauer, M.J.; Vaughn, I.W.; McManus, M.T. Pervasive transcription of the human genome produces thousands of previously unidentified long intergenic noncoding RNAs. PLoS Genet. 2013, 9, e1003569. [Google Scholar] [CrossRef]
- Djebali, S.; Davis, C.A.; Merkel, A.; Dobin, A.; Lassmann, T.; Mortazavi, A.; Tanzer, A.; Lagarde, J.; Lin, W.; Schlesinger, F.; et al. Landscape of transcription in human cells. Nature 2012, 489, 101–108. [Google Scholar] [CrossRef]
- ENCODE Project Consortium. An integrated encyclopedia of DNA elements in the human genome. Nature 2012, 489, 57–74. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Li, H.; Fang, S.; Kang, Y.; Wu, W.; Hao, Y.; Li, Z.; Bu, D.; Sun, N.; Zhang, M.Q.; et al. NONCODE 2016: An informative and valuable data source of long non-coding RNAs. Nucleic Acids Res. 2016, 44, D203–D208. [Google Scholar] [CrossRef]
- Kung, J.T.Y.; Colognori, D.; Lee, J.T. Long noncoding RNAs: Past, present, and future. Genetics 2013, 193, 651–669. [Google Scholar] [CrossRef] [PubMed]
- Wutz, A. Gene silencing in X-chromosome inactivation: Advances in understanding facultative heterochromatin formation. Nat. Rev. Genet. 2011, 12, 542–553. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Egranov, S.D.; Yang, L.; Lin, C. Molecular mechanisms of long noncoding RNAs-mediated cancer metastasis. Genes Chromosomes Cancer 2019. [Google Scholar] [CrossRef] [PubMed]
- He, R.Z.; Luo, D.X.; Mo, Y.Y. Emerging roles of lncRNAs in the post-transcriptional regulation in cancer. Genes Dis. 2019, 6, 6–15. [Google Scholar] [CrossRef]
- Diermeier, S.D.; Chang, K.C.; Freier, S.M.; Song, J.; El Demerdash, O.; Krasnitz, A.; Rigo, F.; Bennett, C.F.; Spector, D.L. Mammary Tumor-Associated RNAs Impact Tumor Cell Proliferation, Invasion, and Migration. Cell Rep. 2016, 17, 261–274. [Google Scholar] [CrossRef]
- Wei, M.M.; Zhou, G.B. Long Non-coding RNAs and Their Roles in Non-small-cell Lung Cancer. Genom. Proteom. Bioinform. 2016, 14, 280–288. [Google Scholar] [CrossRef]
- Kino, T.; Hurt, D.E.; Ichijo, T.; Nader, N.; Chrousos, G.P. Noncoding RNA gas5 is a growth arrest- and starvation-associated repressor of the glucocorticoid receptor. Sci. Signal. 2010, 3, ra8. [Google Scholar] [CrossRef] [PubMed]
- Luo, Q.; Chen, Y. Long noncoding RNAs and Alzheimer’s disease. Clin. Interv. Aging 2016, 11, 867–872. [Google Scholar] [CrossRef] [PubMed]
- Yarani, R.; Mirza, A.H.; Kaur, S.; Pociot, F. The emerging role of lncRNAs in inflammatory bowel disease. Exp. Mol. Med. 2018, 50, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wei, F.; Zhou, H. Advances of lncRNA in autoimmune diseases. Front. Lab. Med. 2018, 2, 79–82. [Google Scholar] [CrossRef]
- Sathishkumar, C.; Prabu, P.; Mohan, V.; Balasubramanyam, M. Linking a role of lncRNAs (long non-coding RNAs) with insulin resistance, accelerated senescence, and inflammation in patients with type 2 diabetes. Hum. Genom. 2018, 12, 41. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, P.; Wang, Y.; Ma, X.; Zhi, H.; Zhou, D.; Li, X.; Fang, Y.; Shen, W.; Xu, Y.; et al. Lnc2Cancer v2.0: Updated database of experimentally supported long non-coding RNAs in human cancers. Nucleic Acids Res. 2019, 47, D1028–D1033. [Google Scholar] [CrossRef]
- Paytuvi-Gallart, A.; Sanseverino, W.; Aiese Cigliano, R. A Walkthrough to the Use of GreeNC: The Plant lncRNA Database; Humana Press: New York, NY, USA, 2019; pp. 397–414. [Google Scholar]
- Volders, P.J.; Helsens, K.; Wang, X.; Menten, B.; Martens, L.; Gevaert, K.; Vandesompele, J.; Mestdagh, P. LNCipedia: A database for annotated human lncRNA transcript sequences and structures. Nucleic Acids Res. 2013, 41, D246–D251. [Google Scholar] [CrossRef]
- Volders, P.J.; Anckaert, J.; Verheggen, K.; Nuytens, J.; Martens, L.; Mestdagh, P.; Vandesompele, J. LNCipedia 5: Towards a reference set of human long non-coding RNAs. Nucleic Acids Res. 2019, 47, D135–D139. [Google Scholar] [CrossRef]
- Amaral, P.P.; Clark, M.B.; Gascoigne, D.K.; Dinger, M.E.; Mattick, J.S. lncRNAdb: A reference database for long noncoding RNAs. Nucleic Acids Res. 2011, 39, D146–D151. [Google Scholar] [CrossRef]
- Cabili, M.N.; Trapnell, C.; Goff, L.; Koziol, M.; Tazon-Vega, B.; Regev, A.; Rinn, J.L. Integrative annotation of human large intergenic noncoding RNAs reveals global properties and specific subclasses. Genes Dev. 2011, 25, 1915–1927. [Google Scholar] [CrossRef]
- Yates, A.D.; Achuthan, P.; Akanni, W.; Allen, J.; Allen, J.; Alvarez-Jarreta, J.; Amode, M.R.; Armean, I.M.; Azov, A.G.; Bennett, R.; et al. Ensembl 2020. Nucleic Acids Res. 2020, 48, D682–D688. [Google Scholar] [CrossRef] [PubMed]
- O’Leary, N.A.; Wright, M.W.; Brister, J.R.; Ciufo, S.; Haddad, D.; McVeigh, R.; Rajput, B.; Robbertse, B.; Smith-White, B.; Ako-Adjei, D.; et al. Reference sequence (RefSeq) database at NCBI: Current status, taxonomic expansion, and functional annotation. Nucleic Acids Res. 2016, 44, D733–D745. [Google Scholar] [CrossRef]
- Hon, C.C.; Ramilowski, J.A.; Harshbarger, J.; Bertin, N.; Rackham, O.J.L.; Gough, J.; Denisenko, E.; Schmeier, S.; Poulsen, T.M.; Severin, J.; et al. An atlas of human long non-coding RNAs with accurate 5’ ends. Nature 2017, 543, 199–204. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, M.M.; Tehler, D.; Vang, S.; Sudzina, F.; Hedegaard, J.; Nordentoft, I.; Orntoft, T.F.; Lund, A.H.; Pedersen, J.S. Identification of expressed and conserved human noncoding RNAs. RNA 2014, 20, 236–251. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Gadad, S.S.; Kim, D.S.; Kraus, W.L. Discovery, Annotation, and Functional Analysis of Long Noncoding RNAs Controlling Cell-Cycle Gene Expression and Proliferation in Breast Cancer Cells. Mol. Cell 2015, 59, 698–711. [Google Scholar] [CrossRef] [PubMed]
- Villegas, V.E.; Zaphiropoulos, P.G. Neighboring gene regulation by antisense long non-coding RNAs. Int. J. Mol. Sci. 2015, 16, 3251–3266. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Cao, J.; Liu, L.; Du, Q.; Li, Z.; Zou, D.; Bajic, V.B.; Zhang, Z. LncBook: A curated knowledgebase of human long non-coding RNAs. Nucleic Acids Res. 2019, 47, D128–D134. [Google Scholar] [CrossRef]
- Derrien, T.; Johnson, R.; Bussotti, G.; Tanzer, A.; Djebali, S.; Tilgner, H.; Guernec, G.; Martin, D.; Merkel, A.; Knowles, D.G.; et al. The GENCODE v7 catalog of human long noncoding RNAs: Analysis of their gene structure, evolution, and expression. Genome Res. 2012, 22, 1775–1789. [Google Scholar] [CrossRef]
- Ma, L.; Li, A.; Zou, D.; Xu, X.; Xia, L.; Yu, J.; Bajic, V.B.; Zhang, Z. LncRNAWiki: Harnessing community knowledge in collaborative curation of human long non-coding RNAs. Nucleic Acids Res. 2015, 43, D187–D192. [Google Scholar] [CrossRef]
- Lewis, B.P.; Burge, C.B.; Bartel, D.P. Conserved seed pairing, often flanked by adenosines, indicates that thousands of human genes are microRNA targets. Cell 2005, 120, 15–20. [Google Scholar] [CrossRef]
- John, B.; Enright, A.J.; Aravin, A.; Tuschl, T.; Sander, C.; Marks, D.S. Human MicroRNA targets. PLoS Biol. 2004, 2, e363. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Park, H.J.; Dasari, S.; Wang, S.; Kocher, J.P.; Li, W. CPAT: Coding-Potential Assessment Tool using an alignment-free logistic regression model. Nucleic Acids Res. 2013, 41, e74. [Google Scholar] [CrossRef] [PubMed]
- Li, A.; Zhang, J.; Zhou, Z. PLEK: A tool for predicting long non-coding RNAs and messenger RNAs based on an improved k-mer scheme. BMC Bioinform. 2014, 15, 311. [Google Scholar] [CrossRef] [PubMed]
- Josset, L.; Tchitchek, N.; Gralinski, L.E.; Ferris, M.T.; Eisfeld, A.J.; Green, R.R.; Thomas, M.J.; Tisoncik-Go, J.; Schroth, G.P.; Kawaoka, Y.; et al. Annotation of long non-coding RNAs expressed in collaborative cross founder mice in response to respiratory virus infection reveals a new class of interferon-stimulated transcripts. RNA Biol. 2014, 11, 875–890. [Google Scholar] [CrossRef] [PubMed]
- Carlevaro-Fita, J.; Lanzós, A.; Feuerbach, L.; Hong, C.; Mas-Ponte, D.; Pedersen, J.S.; PCAWG Drivers and Functional Interpretation Group; Johnson, R.; PCAWG Consortium. Cancer LncRNA Census reveals evidence for deep functional conservation of long noncoding RNAs in tumorigenesis. Commun. Biol. 2020, 3, 56. [Google Scholar] [CrossRef] [PubMed]
- Fatica, A.; Bozzoni, I. Long non-coding RNAs: New players in cell differentiation and development. Nat. Rev. Genet. 2014, 15, 7–21. [Google Scholar] [CrossRef]
- Delás, M.J.; Hannon, G.J. lncRNAs in development and disease: From functions to mechanisms. Open Biol. 2017, 7, 170121. [Google Scholar] [CrossRef]
- Lonsdale, J.; Thomas, J.; Salvatore, M.; Phillips, R.; Lo, E.; Shad, S.; Hasz, R.; Walters, G.; Garcia, F.; Young, N.; et al. The Genotype-Tissue Expression (GTEx) project. Nat. Genet. 2013, 45, 580–585. [Google Scholar] [CrossRef]
- GTEx Consortium. The GTEx Consortium atlas of genetic regulatory effects across human tissues. Science 2020, 369, 1318–1330. [Google Scholar] [CrossRef]
- Schroeder, A.; Mueller, O.; Stocker, S.; Salowsky, R.; Leiber, M.; Gassmann, M.; Lightfoot, S.; Menzel, W.; Granzow, M.; Ragg, T. The RIN: An RNA integrity number for assigning integrity values to RNA measurements. BMC Mol. Biol. 2006, 7, 3. [Google Scholar] [CrossRef]
- Li, J.; Han, L.; Roebuck, P.; Diao, L.; Liu, L.; Yuan, Y.; Weinstein, J.N.; Liang, H. TANRIC: An Interactive Open Platform to Explore the Function of lncRNAs in Cancer. Cancer Res. 2015, 75, 3728–3737. [Google Scholar] [CrossRef] [PubMed]
- Weinstein, J.N.; Collisson, E.A.; Mills, G.B.; Shaw, K.R.M.; Ozenberger, B.A.; Ellrott, K.; Shmulevich, I.; Sander, C.; Stuart, J.M.; Network, C.G.A.R.; et al. The cancer genome atlas pan-cancer analysis project. Nat. Genet. 2013, 45, 1113. [Google Scholar] [CrossRef] [PubMed]
- Barretina, J.; Caponigro, G.; Stransky, N.; Venkatesan, K.; Margolin, A.A.; Kim, S.; Wilson, C.J.; Lehár, J.; Kryukov, G.V.; Sonkin, D.; et al. The Cancer Cell Line Encyclopedia enables predictive modelling of anticancer drug sensitivity. Nature 2012, 483, 603–607. [Google Scholar] [CrossRef] [PubMed]
- Seo, J.S.; Ju, Y.S.; Lee, W.C.; Shin, J.Y.; Lee, J.K.; Bleazard, T.; Lee, J.; Jung, Y.J.; Kim, J.O.; Shin, J.Y.; et al. The transcriptional landscape and mutational profile of lung adenocarcinoma. Genome Res. 2012, 22, 2109–2119. [Google Scholar] [CrossRef]
- Sato, Y.; Yoshizato, T.; Shiraishi, Y.; Maekawa, S.; Okuno, Y.; Kamura, T.; Shimamura, T.; Sato-Otsubo, A.; Nagae, G.; Suzuki, H.; et al. Integrated molecular analysis of clear-cell renal cell carcinoma. Nat. Genet. 2013, 45, 860–867. [Google Scholar] [CrossRef]
- Bao, Z.S.; Chen, H.M.; Yang, M.Y.; Zhang, C.B.; Yu, K.; Ye, W.L.; Hu, B.Q.; Yan, W.; Zhang, W.; Akers, J.; et al. RNA-seq of 272 gliomas revealed a novel, recurrent PTPRZ1-MET fusion transcript in secondary glioblastomas. Genome Res. 2014, 24, 1765–1773. [Google Scholar] [CrossRef]
- Szcześniak, M.W.; Bryzghalov, O.; Ciomborowska-Basheer, J.; Makałowska, I. CANTATAdb 2.0: Expanding the Collection of Plant Long Noncoding RNAs. Methods Mol. Biol. 2019, 1933, 415–429. [Google Scholar]
- Kodama, Y.; Shumway, M.; Leinonen, R.; International Nucleotide Sequence Database Collaboration. The Sequence Read Archive: Explosive growth of sequencing data. Nucleic Acids Res. 2012, 40, D54–D56. [Google Scholar] [CrossRef]
- Altschul, S.F.; Gish, W.; Miller, W.; Myers, E.W.; Lipman, D.J. Basic local alignment search tool. J. Mol. Biol. 1990, 215, 403–410. [Google Scholar] [CrossRef]
- Aldridge, S.; Teichmann, S.A. Single cell transcriptomics comes of age. Nat. Commun. 2020, 11, 4307. [Google Scholar] [CrossRef]
- Cao, J.; Zhou, W.; Steemers, F.; Trapnell, C.; Shendure, J. Sci-fate characterizes the dynamics of gene expression in single cells. Nat. Biotechnol. 2020, 38, 980–988. [Google Scholar] [CrossRef] [PubMed]
- Litviňuková, M.; Talavera-López, C.; Maatz, H.; Reichart, D.; Worth, C.L.; Lindberg, E.L.; Kanda, M.; Polanski, K.; Heinig, M.; Lee, M.; et al. Cells of the adult human heart. Nature 2020. [Google Scholar] [CrossRef]
- Kong, L.; Zhang, Y.; Ye, Z.Q.; Liu, X.Q.; Zhao, S.Q.; Wei, L.; Gao, G. CPC: Assess the protein-coding potential of transcripts using sequence features and support vector machine. Nucleic Acids Res. 2007, 35, W345–W349. [Google Scholar] [CrossRef] [PubMed]
- Anderson, D.M.; Anderson, K.M.; Chang, C.L.; Makarewich, C.A.; Nelson, B.R.; McAnally, J.R.; Kasaragod, P.; Shelton, J.M.; Liou, J.; Bassel-Duby, R.; et al. A Micropeptide Encoded by a Putative Long Noncoding RNA Regulates Muscle Performance. Cell 2015, 160, 595–606. [Google Scholar] [CrossRef] [PubMed]
- Cai, B.; Li, Z.; Ma, M.; Wang, Z.; Han, P.; Abdalla, B.A.; Nie, Q.; Zhang, X. LncRNA-Six1 Encodes a Micropeptide to Activate Six1 in Cis and Is Involved in Cell Proliferation and Muscle Growth. Front. Physiol. 2017, 8, 230. [Google Scholar] [CrossRef] [PubMed]
- Guo, B.; Wu, S.; Zhu, X.; Zhang, L.; Deng, J.; Li, F.; Wang, Y.; Zhang, S.; Wu, R.; Lu, J.; et al. Micropeptide CIP2A-BP encoded by LINC00665 inhibits triple-negative breast cancer progression. EMBO J. 2020, 39, e102190. [Google Scholar] [CrossRef] [PubMed]
- Yeasmin, F.; Yada, T.; Akimitsu, N. Micropeptides Encoded in Transcripts Previously Identified as Long Noncoding RNAs: A New Chapter in Transcriptomics and Proteomics. Front. Genet. 2018, 9, 144. [Google Scholar] [CrossRef]
- Tong, X.; Liu, S. CPPred: Coding potential prediction based on the global description of RNA sequence. Nucleic Acids Res. 2019, 47, e43. [Google Scholar] [CrossRef]
- Kang, Y.J.; Yang, D.C.; Kong, L.; Hou, M.; Meng, Y.Q.; Wei, L.; Gao, G. CPC2: A fast and accurate coding potential calculator based on sequence intrinsic features. Nucleic Acids Res. 2017, 45, W12–W16. [Google Scholar] [CrossRef]
- Guo, J.C.; Fang, S.S.; Wu, Y.; Zhang, J.H.; Chen, Y.; Liu, J.; Wu, B.; Wu, J.R.; Li, E.M.; Xu, L.Y.; et al. CNIT: A fast and accurate web tool for identifying protein-coding and long non-coding transcripts based on intrinsic sequence composition. Nucleic Acids Res. 2019, 47, W516–W522. [Google Scholar] [CrossRef]
- Sun, L.; Luo, H.; Bu, D.; Zhao, G.; Yu, K.; Zhang, C.; Liu, Y.; Chen, R.; Zhao, Y. Utilizing sequence intrinsic composition to classify protein-coding and long non-coding transcripts. Nucleic Acids Res. 2013, 41, e166. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Gunawardane, L.; Niazi, F.; Jahanbani, F.; Chen, X.; Valadkhan, S. A novel RNA motif mediates the strict nuclear localization of a long noncoding RNA. Mol. Cell. Biol. 2014, 34, 2318–2329. [Google Scholar] [CrossRef] [PubMed]
- Lin, M.F.; Jungreis, I.; Kellis, M. PhyloCSF: A comparative genomics method to distinguish protein coding and non-coding regions. Bioinformatics 2011, 27, i275–i282. [Google Scholar] [CrossRef] [PubMed]
- Hu, L.; Xu, Z.; Hu, B.; Lu, Z.J. COME: A robust coding potential calculation tool for lncRNA identification and characterization based on multiple features. Nucleic Acids Res. 2017, 45, e2. [Google Scholar] [CrossRef] [PubMed]
- Stueber, D.; Ibrahimi, I.; Cutler, D.; Dobberstein, B.; Bujard, H. A novel in vitro transcription-translation system: Accurate and efficient synthesis of single proteins from cloned DNA sequences. EMBO J. 1984, 3, 3143–3148. [Google Scholar] [CrossRef]
- Engreitz, J.M.; Haines, J.E.; Perez, E.M.; Munson, G.; Chen, J.; Kane, M.; McDonel, P.E.; Guttman, M.; Lander, E.S. Local regulation of gene expression by lncRNA promoters, transcription and splicing. Nature 2016, 539, 452–455. [Google Scholar] [CrossRef]
- Braidotti, G.; Baubec, T.; Pauler, F.; Seidl, C.; Smrzka, O.; Stricker, S.; Yotova, I.; Barlow, D.P. The Air noncoding RNA: An imprinted cis-silencing transcript. Cold Spring Harb. Symp. Quant. Biol. 2004, 69, 55–66. [Google Scholar] [CrossRef]
- Kim, Y.K.; Furic, L.; Parisien, M.; Major, F.; DesGroseillers, L.; Maquat, L.E. Staufen1 regulates diverse classes of mammalian transcripts. EMBO J. 2007, 26, 2670–2681. [Google Scholar] [CrossRef]
- Huarte, M.; Guttman, M.; Feldser, D.; Garber, M.; Koziol, M.J.; Kenzelmann-Broz, D.; Khalil, A.M.; Zuk, O.; Amit, I.; Rabani, M.; et al. A large intergenic noncoding RNA induced by p53 mediates global gene repression in the p53 response. Cell 2010, 142, 409–419. [Google Scholar] [CrossRef]
- Liu, B.; Sun, L.; Liu, Q.; Gong, C.; Yao, Y.; Lv, X.; Lin, L.; Yao, H.; Su, F.; Li, D.; et al. A cytoplasmic NF-κB interacting long noncoding RNA blocks IκB phosphorylation and suppresses breast cancer metastasis. Cancer Cell 2015, 27, 370–381. [Google Scholar] [CrossRef]
- Cesana, M.; Cacchiarelli, D.; Legnini, I.; Santini, T.; Sthandier, O.; Chinappi, M.; Tramontano, A.; Bozzoni, I. A long noncoding RNA controls muscle differentiation by functioning as a competing endogenous RNA. Cell 2011, 147, 358–369. [Google Scholar] [CrossRef] [PubMed]
- Wen, X.; Gao, L.; Guo, X.; Li, X.; Huang, X.; Wang, Y.; Xu, H.; He, R.; Jia, C.; Liang, F. lncSLdb: A resource for long non-coding RNA subcellular localization. Database 2018, 2018, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Kent, W.J.; Sugnet, C.W.; Furey, T.S.; Roskin, K.M.; Pringle, T.H.; Zahler, A.M.; Haussler, D. The human genome browser at UCSC. Genome Res. 2002, 12, 996–1006. [Google Scholar] [CrossRef] [PubMed]
- Thurmond, J.; Goodman, J.L.; Strelets, V.B.; Attrill, H.; Gramates, L.S.; Marygold, S.J.; Matthews, B.B.; Millburn, G.; Antonazzo, G.; Trovisco, V.; et al. FlyBase 2.0: The next generation. Nucleic Acids Res. 2019, 47, D759–D765. [Google Scholar] [CrossRef]
- Mas-Ponte, D.; Carlevaro-Fita, J.; Palumbo, E.; Hermoso Pulido, T.; Guigo, R.; Johnson, R. LncATLAS database for subcellular localization of long noncoding RNAs. RNA 2017, 23, 1080–1087. [Google Scholar] [CrossRef]
- Cao, Z.; Pan, X.; Yang, Y.; Huang, Y.; Shen, H.B. The lncLocator: A subcellular localization predictor for long non-coding RNAs based on a stacked ensemble classifier. Bioinformatics 2018, 34, 2185–2194. [Google Scholar] [CrossRef]
- Su, Z.D.; Huang, Y.; Zhang, Z.Y.; Zhao, Y.W.; Wang, D.; Chen, W.; Chou, K.C.; Lin, H. iLoc-lncRNA: Predict the subcellular location of lncRNAs by incorporating octamer composition into general PseKNC. Bioinformatics 2018, 34, 4196–4204. [Google Scholar] [CrossRef]
- Gudenas, B.L.; Wang, L. Prediction of LncRNA Subcellular Localization with Deep Learning from Sequence Features. Sci. Rep. 2018, 8, 16385. [Google Scholar] [CrossRef]
- Pierleoni, A.; Indio, V.; Savojardo, C.; Fariselli, P.; Martelli, P.L.; Casadio, R. MemPype: A pipeline for the annotation of eukaryotic membrane proteins. Nucleic Acids Res. 2011, 39, W375–W380. [Google Scholar] [CrossRef]
- Wen, J.; Liu, Y.; Shi, Y.; Huang, H.; Deng, B.; Xiao, X. A classification model for lncRNA and mRNA based on k-mers and a convolutional neural network. BMC Bioinform. 2019, 20, 469. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, G.; Zhou, S.; Niu, Y. LncRNA-miRNA interaction prediction through sequence-derived linear neighborhood propagation method with information combination. BMC Genom. 2019, 20, 946. [Google Scholar] [CrossRef] [PubMed]
- Baldi, P. Autoencoders, unsupervised learning and deep architectures. In Proceedings of the 2011 International Conference on Unsupervised and Transfer Learning workshop, Bellevue, WA, USA, 2 July 2011; Volume 27, pp. 37–50. [Google Scholar]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Wang, Y.; Zhu, W.; Levy, D.E. Nuclear and cytoplasmic mRNA quantification by SYBR green based real-time RT-PCR. Methods 2006, 39, 356–362. [Google Scholar] [CrossRef] [PubMed]
- Raj, A.; van den Bogaard, P.; Rifkin, S.A.; van Oudenaarden, A.; Tyagi, S. Imaging individual mRNA molecules using multiple singly labeled probes. Nat. Methods 2008, 5, 877–879. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Rice, K.; Wang, Y.; Chen, W.; Zhong, Y.; Nakayama, Y.; Zhou, Y.; Klibanski, A. Maternally expressed gene 3 (MEG3) noncoding ribonucleic acid: Isoform structure, expression, and functions. Endocrinology 2010, 151, 939–947. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.N.; Thiel, B.C.; Mrozowich, T.; Hennelly, S.P.; Hofacker, I.L.; Patel, T.R.; Sanbonmatsu, K.Y. Zinc-finger protein CNBP alters the 3-D structure of lncRNA Braveheart in solution. Nat. Commun. 2020, 11, 148. [Google Scholar] [CrossRef] [PubMed]
- Spokoini-Stern, R.; Stamov, D.; Jessel, H.; Aharoni, L.; Haschke, H.; Giron, J.; Unger, R.; Segal, E.; Abu-Horowitz, A.; Bachelet, I. Visualizing the structure and motion of the long noncoding RNA HOTAIR. RNA 2020, 26, 629–636. [Google Scholar] [CrossRef]
- Obayashi, E.; Oubridge, C.; Krummel, D.P.; Nagai, K. Crystallization of RNA-Protein Complexes. In Macromolecular Crystallography Protocols: Volume 1, Preparation and Crystallization of Macromolecules; Walker, J.M., Doublié, S., Eds.; Humana Press: Totowa, NJ, USA, 2007; pp. 259–276. [Google Scholar]
- Novikova, I.V.; Hennelly, S.P.; Sanbonmatsu, K.Y. Structural architecture of the human long non-coding RNA, steroid receptor RNA activator. Nucleic Acids Res. 2012, 40, 5034–5051. [Google Scholar] [CrossRef]
- Chillón, I.; Marcia, M. The molecular structure of long non-coding RNAs: Emerging patterns and functional implications. Crit. Rev. Biochem. Mol. Biol. 2020, 55, 662–690. [Google Scholar] [CrossRef]
- Zampetaki, A.; Albrecht, A.; Steinhofel, K. Long Non-coding RNA Structure and Function: Is There a Link? Front. Physiol. 2018, 9. [Google Scholar] [CrossRef]
- Yesselman, J.D.; Tian, S.; Liu, X.; Shi, L.; Li, J.B.; Das, R. Updates to the RNA mapping database (RMDB), version 2. Nucleic Acids Res. 2018, 46, D375–D379. [Google Scholar] [CrossRef]
- Gruber, A.R.; Lorenz, R.; Bernhart, S.H.; Neuböck, R.; Hofacker, I.L. The Vienna RNA websuite. Nucleic Acids Res. 2008, 36, W70–W74. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Liu, Y.; Zhong, X.; Liu, H.; Lu, C.; Li, C.; Zhang, H. DMfold: A Novel Method to Predict RNA Secondary Structure With Pseudoknots Based on Deep Learning and Improved Base Pair Maximization Principle. Front. Genet. 2019, 10, 143. [Google Scholar] [CrossRef] [PubMed]
- Merino, E.J.; Wilkinson, K.A.; Coughlan, J.L.; Weeks, K.M. RNA Structure Analysis at Single Nucleotide Resolution by Selective 2`-Hydroxyl Acylation and Primer Extension (SHAPE). J. Am. Chem. Soc. 2005, 127, 4223–4231. [Google Scholar] [CrossRef]
- Siegfried, N.A.; Busan, S.; Rice, G.M.; Nelson, J.A.E.; Weeks, K.M. RNA motif discovery by SHAPE and mutational profiling (SHAPE-MaP). Nat. Methods 2014, 11, 959–965. [Google Scholar] [CrossRef] [PubMed]
- Lucks, J.B.; Mortimer, S.A.; Trapnell, C.; Luo, S.; Aviran, S.; Schroth, G.P.; Pachter, L.; Doudna, J.A.; Arkin, A.P. Multiplexed RNA structure characterization with selective 2’-hydroxyl acylation analyzed by primer extension sequencing (SHAPE-Seq). Proc. Natl. Acad. Sci. USA 2011, 108, 11063–11068. [Google Scholar] [CrossRef]
- Lu, Z.; Zhang, Q.C.; Lee, B.; Flynn, R.A.; Smith, M.A.; Robinson, J.T.; Davidovich, C.; Gooding, A.R.; Goodrich, K.J.; Mattick, J.S.; et al. RNA Duplex Map in Living Cells Reveals Higher-Order Transcriptome Structure. Cell 2016, 165, 1267–1279. [Google Scholar] [CrossRef]
- Aw, J.G.A.; Shen, Y.; Wilm, A.; Sun, M.; Lim, X.N.; Boon, K.L.; Tapsin, S.; Chan, Y.S.; Tan, C.P.; Sim, A.Y.L.; et al. In Vivo Mapping of Eukaryotic RNA Interactomes Reveals Principles of Higher-Order Organization and Regulation. Mol. Cell 2016, 62, 603–617. [Google Scholar] [CrossRef]
- Sharma, E.; Sterne-Weiler, T.; O’Hanlon, D.; Blencowe, B.J. Global Mapping of Human RNA-RNA Interactions. Mol. Cell 2016, 62, 618–626. [Google Scholar] [CrossRef]
- Berman, H.M.; Battistuz, T.; Bhat, T.N.; Bluhm, W.F.; Bourne, P.E.; Burkhardt, K.; Feng, Z.; Gilliland, G.L.; Iype, L.; Jain, S.; et al. The Protein Data Bank. Acta Crystallogr. Sect. D Biol. Crystallogr. 2002, 58, 899–907. [Google Scholar] [CrossRef]
- Cordero, P.; Lucks, J.B.; Das, R. An RNA Mapping DataBase for curating RNA structure mapping experiments. Bioinformatics 2012, 28, 3006–3008. [Google Scholar] [CrossRef]
- Ingle, S.; Azad, R.N.; Jain, S.S.; Tullius, T.D. Chemical probing of RNA with the hydroxyl radical at single-atom resolution. Nucleic Acids Res. 2014, 42, 12758–12767. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Wells, S.E.; Hughes, J.M.X.; Haller Igel, A.; Ares, M. Use of dimethylsulfate to probe RNA structure in vivo. Methods Enzymol. 2000, 318, 479–493. [Google Scholar]
- Lai, D.; Meyer, I.M. A comprehensive comparison of general RNA–RNA interaction prediction methods. Nucleic Acids Res. 2016. [Google Scholar] [CrossRef] [PubMed]
- Umu, S.U.; Gardner, P.P. A comprehensive benchmark of RNA-RNA interaction prediction tools for all domains of life. Bioinformatics 2017, 33, 988–996. [Google Scholar] [CrossRef] [PubMed]
- Zuker, M.; Stiegler, P. Optimal computer folding of large RNA sequences using thermodynamics and auxiliary information. Nucleic Acids Res. 1981, 9, 133–148. [Google Scholar] [CrossRef] [PubMed]
- McCaskill, J.S. The equilibrium partition function and base pair binding probabilities for RNA secondary structure. Biopolymers 1990, 29, 1105–1119. [Google Scholar] [CrossRef] [PubMed]
- Qin, T.; Li, J.; Zhang, K.Q. Structure, Regulation, and Function of Linear and Circular Long Non-Coding RNAs. Front. Genet. 2020, 11, 150. [Google Scholar] [CrossRef]
- Kerpedjiev, P.; Hammer, S.; Hofacker, I.L. Forna (force-directed RNA): Simple and effective online RNA secondary structure diagrams. Bioinformatics 2015, 31, 3377–3379. [Google Scholar] [CrossRef]
- Staple, D.W.; Butcher, S.E. Pseudoknots: RNA structures with diverse functions. PLoS Biol. 2005, 3, e213. [Google Scholar] [CrossRef]
- Condon, A.; Jabbari, H. Computational prediction of nucleic acid secondary structure: Methods, applications, and challenges. Theor. Comput. Sci. 2009, 410, 294–301. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27, pp. 3104–3112. [Google Scholar]
- Ward, M.; Datta, A.; Wise, M.; Mathews, D.H. Advanced multi-loop algorithms for RNA secondary structure prediction reveal that the simplest model is best. Nucleic Acids Res. 2017, 45, 8541–8550. [Google Scholar] [CrossRef] [PubMed]
- Uroda, T.; Anastasakou, E.; Rossi, A.; Teulon, J.M.; Pellequer, J.L.; Annibale, P.; Pessey, O.; Inga, A.; Chillón, I.; Marcia, M. Conserved Pseudoknots in lncRNA MEG3 Are Essential for Stimulation of the p53 Pathway. Mol. Cell 2019, 75, 982–995.e9. [Google Scholar] [CrossRef] [PubMed]
- Kretz, M.; Siprashvili, Z.; Chu, C.; Webster, D.E.; Zehnder, A.; Qu, K.; Lee, C.S.; Flockhart, R.J.; Groff, A.F.; Chow, J.; et al. Control of somatic tissue differentiation by the long non-coding RNA TINCR. Nature 2013, 493, 231–235. [Google Scholar] [CrossRef] [PubMed]
- Grote, P.; Herrmann, B.G. The long non-coding RNA Fendrr links epigenetic control mechanisms to gene regulatory networks in mammalian embryogenesis. RNA Biol. 2013, 10, 1579–1585. [Google Scholar] [CrossRef] [PubMed]
- Marchese, F.P.; Raimondi, I.; Huarte, M. The multidimensional mechanisms of long noncoding RNA function. Genome Biol. 2017, 18, 206. [Google Scholar] [CrossRef] [PubMed]
- Cech, T.R.; Steitz, J.A. The Noncoding RNA Revolution—Trashing Old Rules to Forge New Ones. Cell 2014, 157, 77–94. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Liu, T.; Cui, T.; Wang, Z.; Zhang, Y.; Tan, P.; Huang, Y.; Yu, J.; Wang, D. RNAInter in 2020: RNA interactome repository with increased coverage and annotation. Nucleic Acids Res. 2020, 48, D189–D197. [Google Scholar] [CrossRef]
- Gong, J.; Shao, D.; Xu, K.; Lu, Z.; Lu, Z.J.; Yang, Y.T.; Zhang, Q.C. RISE: A database of RNA interactome from sequencing experiments. Nucleic Acids Res. 2018, 46, D194–D201. [Google Scholar] [CrossRef]
- Li, J.H.; Liu, S.; Zhou, H.; Qu, L.H.; Yang, J.H. starBase v2.0: Decoding miRNA-ceRNA, miRNA-ncRNA and protein-RNA interaction networks from large-scale CLIP-Seq data. Nucleic Acids Res. 2014, 42, D92–D97. [Google Scholar] [CrossRef]
- Nguyen, T.C.; Cao, X.; Yu, P.; Xiao, S.; Lu, J.; Biase, F.H.; Sridhar, B.; Huang, N.; Zhang, K.; Zhong, S. Mapping RNA–RNA interactome and RNA structure in vivo by MARIO. Nat. Commun. 2016, 7, 12023. [Google Scholar] [CrossRef]
- Helwak, A.; Kudla, G.; Dudnakova, T.; Tollervey, D. Mapping the human miRNA interactome by CLASH reveals frequent noncanonical binding. Cell 2013, 153, 654–665. [Google Scholar] [CrossRef] [PubMed]
- Kudla, G.; Granneman, S.; Hahn, D.; Beggs, J.D.; Tollervey, D. Cross-linking, ligation, and sequencing of hybrids reveals RNA-RNA interactions in yeast. Proc. Natl. Acad. Sci. USA 2011, 108, 10010–10015. [Google Scholar] [CrossRef] [PubMed]
- Engreitz, J.M.; Sirokman, K.; McDonel, P.; Shishkin, A.A.; Surka, C.; Russell, P.; Grossman, S.R.; Chow, A.Y.; Guttman, M.; Lander, E.S. RNA-RNA interactions enable specific targeting of noncoding RNAs to nascent Pre-mRNAs and chromatin sites. Cell 2014, 159, 188–199. [Google Scholar] [CrossRef] [PubMed]
- Junge, A.; Refsgaard, J.C.; Garde, C.; Pan, X.; Santos, A.; Alkan, F.; Anthon, C.; von Mering, C.; Workman, C.T.; Jensen, L.J.; et al. RAIN: RNA–protein association and interaction networks. Database 2017. [Google Scholar] [CrossRef] [PubMed]
- Yi, Y.; Zhao, Y.; Li, C.; Zhang, L.; Huang, H.; Li, Y.; Liu, L.; Hou, P.; Cui, T.; Tan, P.; et al. RAID v2.0: An updated resource of RNA-associated interactions across organisms. Nucleic Acids Res. 2017, 45, D115–D118. [Google Scholar] [CrossRef] [PubMed]
- Teng, X.; Chen, X.; Xue, H.; Tang, Y.; Zhang, P.; Kang, Q.; Hao, Y.; Chen, R.; Zhao, Y.; He, S. NPInter v4.0: An integrated database of ncRNA interactions. Nucleic Acids Res. 2020, 48, D160–D165. [Google Scholar] [CrossRef]
- Wenzel, A.; Akbaşli, E.; Gorodkin, J. RIsearch: Fast RNA–RNA interaction search using a simplified nearest-neighbor energy model. Bioinformatics 2012. [Google Scholar] [CrossRef] [PubMed]
- Seemann, S.E.; Richter, A.S.; Gesell, T.; Backofen, R.; Gorodkin, J. PETcofold: Predicting conserved interactions and structures of two multiple alignments of RNA sequences. Bioinformatics 2011, 27, 211–219. [Google Scholar] [CrossRef]
- Wekesa, J.S.; Meng, J.; Luan, Y. A deep learning model for plant lncRNA-protein interaction prediction with graph attention. Mol. Genet. Genom. 2020, 295, 1091–1102. [Google Scholar] [CrossRef]
- Mann, M.; Wright, P.R.; Backofen, R. IntaRNA 2.0: Enhanced and customizable prediction of RNA–RNA interactions. Nucleic Acids Res. 2017, 45, W435–W439. [Google Scholar] [CrossRef]
- Fukunaga, T.; Iwakiri, J.; Ono, Y.; Hamada, M. LncRRIsearch: A Web Server for lncRNA-RNA Interaction Prediction Integrated With Tissue-Specific Expression and Subcellular Localization Data. Front. Genet. 2019, 10, 462. [Google Scholar] [CrossRef] [PubMed]
- Fukunaga, T.; Hamada, M. RIblast: An ultrafast RNA–RNA interaction prediction system based on a seed-and-extension approach. Bioinformatics 2017, 33, 2666–2674. [Google Scholar] [CrossRef] [PubMed]
- Iwakiri, J.; Terai, G.; Hamada, M. Computational prediction of lncRNA-mRNA interactions by integrating tissue specificity in human transcriptome. Biol. Direct 2017, 12, 15. [Google Scholar] [CrossRef] [PubMed]
- Raden, M.; Ali, S.M.; Alkhnbashi, O.S.; Busch, A.; Costa, F.; Davis, J.A.; Eggenhofer, F.; Gelhausen, R.; Georg, J.; Heyne, S.; et al. Freiburg RNA tools: A central online resource for RNA-focused research and teaching. Nucleic Acids Res. 2018, 46, W25–W29. [Google Scholar] [CrossRef]
- Busch, A.; Richter, A.S.; Backofen, R. IntaRNA: Efficient prediction of bacterial sRNA targets incorporating target site accessibility and seed regions. Bioinformatics 2008, 24, 2849–2856. [Google Scholar] [CrossRef]
- Uhlen, M.; Berling, H.; von Feilitzen, K.; Nielsen, J.; Szigyarto, C.A.K.; Edlund, K. Tissue-based map of the human proteome. Science 2015, 347, 1260419. [Google Scholar] [CrossRef]
- The GTEx Consortium. The Genotype-Tissue Expression (GTEx) pilot analysis: Multitissue gene regulation in humans. Science 2015, 348, 648–660. [Google Scholar] [CrossRef]
- Roadmap Epigenomics Consortium; Kundaje, A.; Meuleman, W.; Ernst,, J.; Bilenky, M.; Yen, A.; Heravi-Moussavi, A.; Kheradpour, P.; Zhang, Z.; Wang, J.; et al. Integrative analysis of 111 reference human epigenomes. Nature 2015, 518, 317–330. [Google Scholar]
- FANTOM Consortium and the RIKEN PMI and CLST (DGT); Forrest, A.R.R.; Kawaji, H.; Rehli, M.; Baillie, J.K.; de Hoon, M.J.L.; Haberle, V.; Lassmann, T.; Kulakovskiy, I.V.; Lizio, M.; et al. A promoter-level mammalian expression atlas. Nature 2014, 507, 462–470. [Google Scholar]
- Huntley, M.A.; Lou, M.; Goldstein, L.D.; Lawrence, M.; Dijkgraaf, G.J.P.; Kaminker, J.S.; Gentleman, R. Complex regulation of ADAR-mediated RNA-editing across tissues. BMC Genom. 2016, 17, 61. [Google Scholar] [CrossRef]
- Merkin, J.; Russell, C.; Chen, P.; Burge, C.B. Evolutionary dynamics of gene and isoform regulation in Mammalian tissues. Science 2012, 338, 1593–1599. [Google Scholar] [CrossRef] [PubMed]
- Tsai, M.C.; Manor, O.; Wan, Y.; Mosammaparast, N.; Wang, J.K.; Lan, F.; Shi, Y.; Segal, E.; Chang, H.Y. Long noncoding RNA as modular scaffold of histone modification complexes. Science 2010, 329, 689–693. [Google Scholar] [CrossRef] [PubMed]
- Rinn, J.L.; Chang, H.Y. Genome regulation by long noncoding RNAs. Annu. Rev. Biochem. 2012, 81, 145–166. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Zhang, G.; Shi, A.; Hu, J.; Li, F.; Zhang, X.; Zhang, Y.; Huang, J.; Xiao, Y.; Li, X.; et al. LnChrom: A resource of experimentally validated lncRNA–chromatin interactions in human and mouse. Database 2018. [Google Scholar] [CrossRef]
- Buske, F.A.; Bauer, D.C.; Mattick, J.S.; Bailey, T.L. Triplexator: Detecting nucleic acid triple helices in genomic and transcriptomic data. Genome Res. 2012, 22, 1372–1381. [Google Scholar] [CrossRef]
- Chu, C.; Qu, K.; Zhong, F.L.; Artandi, S.E.; Chang, H.Y. Genomic maps of long noncoding RNA occupancy reveal principles of RNA-chromatin interactions. Mol. Cell 2011, 44, 667–678. [Google Scholar] [CrossRef]
- Akhade, V.S.; Arun, G.; Donakonda, S.; Rao, M.R.S. Genome wide chromatin occupancy of mrhl RNA and its role in gene regulation in mouse spermatogonial cells. RNA Biol. 2014, 11, 1262–1279. [Google Scholar] [CrossRef]
- Sridhar, B.; Rivas-Astroza, M.; Nguyen, T.C.; Chen, W.; Yan, Z.; Cao, X.; Hebert, L.; Zhong, S. Systematic Mapping of RNA-Chromatin Interactions In Vivo. Curr. Biol. 2017, 27, 602–609. [Google Scholar] [CrossRef]
- Yang, L.; Lin, C.; Jin, C.; Yang, J.C.; Tanasa, B.; Li, W.; Merkurjev, D.; Ohgi, K.A.; Meng, D.; Zhang, J.; et al. lncRNA-dependent mechanisms of androgen-receptor-regulated gene activation programs. Nature 2013, 500, 598–602. [Google Scholar] [CrossRef]
- Simon, M.D.; Pinter, S.F.; Fang, R.; Sarma, K.; Rutenberg-Schoenberg, M.; Bowman, S.K.; Kesner, B.A.; Maier, V.K.; Kingston, R.E.; Lee, J.T. High-resolution Xist binding maps reveal two-step spreading during X-chromosome inactivation. Nature 2013, 504, 465–469. [Google Scholar] [CrossRef]
- Barrett, T.; Wilhite, S.E.; Ledoux, P.; Evangelista, C.; Kim, I.F.; Tomashevsky, M.; Marshall, K.A.; Phillippy, K.H.; Sherman, P.M.; Holko, M.; et al. NCBI GEO: Archive for functional genomics data sets–update. Nucleic Acids Res. 2013, 41, D991–D995. [Google Scholar] [CrossRef] [PubMed]
- Papatheodorou, I.; Moreno, P.; Manning, J.; Fuentes, A.M.P.; George, N.; Fexova, S.; Fonseca, N.A.; Füllgrabe, A.; Green, M.; Huang, N.; et al. Expression Atlas update: From tissues to single cells. Nucleic Acids Res. 2020, 48, D77–D83. [Google Scholar] [CrossRef] [PubMed]
- Euskirchen, G.M.; Rozowsky, J.S.; Wei, C.L.; Lee, W.H.; Zhang, Z.D.; Hartman, S.; Emanuelsson, O.; Stolc, V.; Weissman, S.; Gerstein, M.B.; et al. Mapping of transcription factor binding regions in mammalian cells by ChIP: Comparison of array- and sequencing-based technologies. Genome Res. 2007, 17, 898–909. [Google Scholar] [CrossRef] [PubMed]
- Felsenfeld, G.; Davies, D.R.; Rich, A. Formation of a Three-Stranded Polynucleotide Molecule. J. Am. Chem. Soc. 1957, 79, 2023–2024. [Google Scholar] [CrossRef]
- Sentürk Cetin, N.; Kuo, C.C.; Ribarska, T.; Li, R.; Costa, I.G.; Grummt, I. Isolation and genome-wide characterization of cellular DNA:RNA triplex structures. Nucleic Acids Res. 2019, 47, 2306–2321. [Google Scholar] [CrossRef] [PubMed]
- Antonov, I.V.; Mazurov, E.; Borodovsky, M.; Medvedeva, Y.A. Prediction of lncRNAs and their interactions with nucleic acids: Benchmarking bioinformatics tools. Brief. Bioinform. 2019, 20, 551–564. [Google Scholar] [CrossRef]
- Mohammad, A.; Saleh, O.; Abdeen, R.A. Occurrences algorithm for string searching based on brute-force algorithm. J. Comput. Sci. 2006, 2, 82–85. [Google Scholar] [CrossRef]
- Munschauer, M.; Nguyen, C.T.; Sirokman, K.; Hartigan, C.R.; Hogstrom, L.; Engreitz, J.M.; Ulirsch, J.C.; Fulco, C.P.; Subramanian, V.; Chen, J.; et al. The NORAD lncRNA assembles a topoisomerase complex critical for genome stability. Nature 2018, 561, 132–136. [Google Scholar] [CrossRef]
- Nozawa, R.S.; Gilbert, N. RNA: Nuclear Glue for Folding the Genome. Trends Cell Biol. 2019, 29, 201–211. [Google Scholar] [CrossRef]
- Peng, L.; Liu, F.; Yang, J.; Liu, X.; Meng, Y.; Deng, X.; Peng, C.; Tian, G.; Zhou, L. Probing lncRNA-Protein Interactions: Data Repositories, Models, and Algorithms. Front. Genet. 2020, 10, 1346. [Google Scholar] [CrossRef]
- Zhang, W.; Yue, X.; Tang, G.; Wu, W.; Huang, F.; Zhang, X. SFPEL-LPI: Sequence-based feature projection ensemble learning for predicting LncRNA-protein interactions. PLoS Comput. Biol. 2018, 14, e1006616. [Google Scholar] [CrossRef] [PubMed]
- Pandurangan, A.P.; Stahlhacke, J.; Oates, M.E.; Smithers, B.; Gough, J. The SUPERFAMILY 2.0 database: A significant proteome update and a new webserver. Nucleic Acids Res. 2019, 47, D490–D494. [Google Scholar] [CrossRef] [PubMed]
- Kirk, J.M.; Kim, S.O.; Inoue, K.; Smola, M.J.; Lee, D.M.; Schertzer, M.D.; Wooten, J.S.; Baker, A.R.; Sprague, D.; Collins, D.W.; et al. Functional classification of long non-coding RNAs by k-mer content. Nat. Genet. 2018, 50, 1474–1482. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.; Redfern, O.; Orengo, C. Predicting protein function from sequence and structure. Nat. Rev. Mol. Cell Biol. 2007, 8, 995–1005. [Google Scholar] [CrossRef]
- Bassett, A.R.; Akhtar, A.; Barlow, D.P.; Bird, A.P.; Brockdorff, N.; Duboule, D.; Ephrussi, A.; Ferguson-Smith, A.C.; Gingeras, T.R.; Haerty, W.; et al. Considerations when investigating lncRNA function in vivo. Elife 2014, 3, e03058. [Google Scholar] [CrossRef]
- Charles Richard, J.L.; Eichhorn, P.J.A. Platforms for Investigating LncRNA Functions. SLAS Technol. 2018, 23, 493–506. [Google Scholar] [CrossRef]
- Jabbari, H.; Wark, I.; Montemagno, C.; Will, S. Knotty: Efficient and accurate prediction of complex RNA pseudoknot structures. Bioinformatics 2018, 34, 3849–3856. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pinkney, H.R.; Wright, B.M.; Diermeier, S.D. The lncRNA Toolkit: Databases and In Silico Tools for lncRNA Analysis. Non-Coding RNA 2020, 6, 49. https://doi.org/10.3390/ncrna6040049
Pinkney HR, Wright BM, Diermeier SD. The lncRNA Toolkit: Databases and In Silico Tools for lncRNA Analysis. Non-Coding RNA. 2020; 6(4):49. https://doi.org/10.3390/ncrna6040049
Chicago/Turabian StylePinkney, Holly R., Brandon M. Wright, and Sarah D. Diermeier. 2020. "The lncRNA Toolkit: Databases and In Silico Tools for lncRNA Analysis" Non-Coding RNA 6, no. 4: 49. https://doi.org/10.3390/ncrna6040049
APA StylePinkney, H. R., Wright, B. M., & Diermeier, S. D. (2020). The lncRNA Toolkit: Databases and In Silico Tools for lncRNA Analysis. Non-Coding RNA, 6(4), 49. https://doi.org/10.3390/ncrna6040049