1. Introduction
Shipping and other marine-related operations are highly dependent on weather conditions. A range of technologies, methodologies, and historical data are used to forecast future weather conditions [
1]. The height of the sea waves is a critical meteorological condition. The length of a wave height forecast is often determined by the significance of the activity [
2]. High sea waves might endanger a ship by overturning it, resulting in significant losses. This can be prevented by optimizing the shipping route. Consequently, forecasting wave height might help to avoid dangerous conditions while simultaneously enhancing productivity and preserving fuel [
3]. Moreover, as carbon dioxide levels increase, one of the mitigation strategies is to use renewable energy resources efficiently [
4]. Waves at sea can be considered one renewable energy source, since they continuously propagate as the wind blows. Therefore, it is critical to estimate wave heights accurately to provide an overview of current ocean wave conditions [
5].
Predicting the height of a sea wave is challenging due to their stochastic nature and nonlinear characteristics [
6]. Consequently, research on wave height prediction is continuously being updated to keep increasing the accuracy of predictions and the computational speed of wave forecasting systems [
7]. In classic numerical approaches, wave height prediction is accomplished by three factors: the physical formulation, numerical discretization, and simulation [
8], all of which are dependent on the input data provided. The three most preferred phase-averaged wave models simulate wave generation and propagation, and they are usually called the so-called third-generation wave models: WAM [
9], SWAN [
10], and WAVEWATCH III [
11]. All are examples of numerical simulations in the spatial domain. The WAM and WAVEWATCH III models are intended for simulating large-domain or ocean-scale waves, since their direct temporal integration is incompatible with complicated shoreline scales [
12]. In comparison, the SWAN model is often used to forecast ocean waves at a local scale using regional forecasts [
13]. Indeed, since they are based on numerical simulations, they also come with some consequences: to calculate wave propagation in environments with complex geometries, high-resolution grids are needed, and they require powerful computational resources and a long period of time [
14].
An alternative approach to numerical simulations is the soft computing approach, which can calculate faster predictions than the numerical approaches while maintaining lower computational costs. The soft computing approach is not new in wave prediction, particularly with respect to neural networks. Several studies have used different approaches to forecast wave height. Alexandre et al. established forecasts with a Root Mean Square Error (RMSE) of 0.75 and an RMSE of 0.5 in two scenarios in the Western Atlantic and the Caribbean Sea, respectively [
15]. In 2017, Nikoo et al. demonstrated that fuzzy KNN and regression tree induction models outperform other soft computing models [
16]. Zubier used an artificial neural network (ANN), specifically NARX, to forecast waves on the Red Sea in 2018, with excellent results for 3–24 h forecasts [
17]. The MSE was only 0.07. Wang et al. discovered that using residual learning to adjust a numerical model was more accurate and efficient than using a numerical technique [
18] for predictions within 3–72 h. In 2019, Elbisy employed the group method of a data-handling-type neural network (GMDH-NN) and the multilayer perceptron neural network (MLPNN) to estimate wave heights [
19]. They concluded that the GMDH-NN produces better predictions than the MLPNN. Tong Liu et al. used a deep learning algorithm called WaveNet that can produce wave patterns more similar to buoy measurements than numerical simulations [
20]. In 2020, Callens et al. employed a random forest and gradient boosting to enhance the prediction accuracy at particular sites [
21]. Chen et al. used the wavelet graph neural network to predict wave height and compared it to other ANN models, finding that it outperformed other models by 16.4% [
3]. Ting Yu used the convolutional gated recurrent unit network to provide one-hour predictions with a correlation coefficient of 0.996 and an RMSE of 0.136 [
22]. The above-mentioned wave forecasting methods are generally used to forecast waves 3–72 h ahead. For coastal and offshore operational activities, especially for the scheduling of ship transportation, a longer forecasting time interval is needed, i.e., 7–14 days ahead. The wave height mentioned here is the significant wave height.
The forecasting method affects the accuracy of the wave prediction, but the geometry of the study area may also significantly affect the accuracy of the prediction. For a numerical approach, forecasting waves in a geometrically complex area, such as a coastal area, requires wave simulation with a high-resolution grid, which will lead to time-consuming computation. For a machine-learning-based wave forecasting model, the accuracy of the data for the machine learning training process significantly affects the forecasting system’s accuracy. Herein, we walk through the design of an efficient wave forecasting system built for rapid wave height predictions with acceptable accuracy. We propose a novel approach to designing a complex coastal area wave forecasting system. We combine high-resolution wave simulations using the SWAN wave model [
10] with a deep learning method called bidirectional long short-term memory (BiLSTM) to process wind information to predict significant wave height. We used the SWAN model to generate high-resolution training data in a coastal area with a complex geometry. For validation, we compared the numerical simulation results generated with the SWAN model, with available observation wave data from the Java Sea, Indonesia. The deep learning BiLSTM method was trained using wave data obtained from a continuous numerical wave simulation using the SWAN model over a 20 year-period with ECMWF ERA-5 wind data [
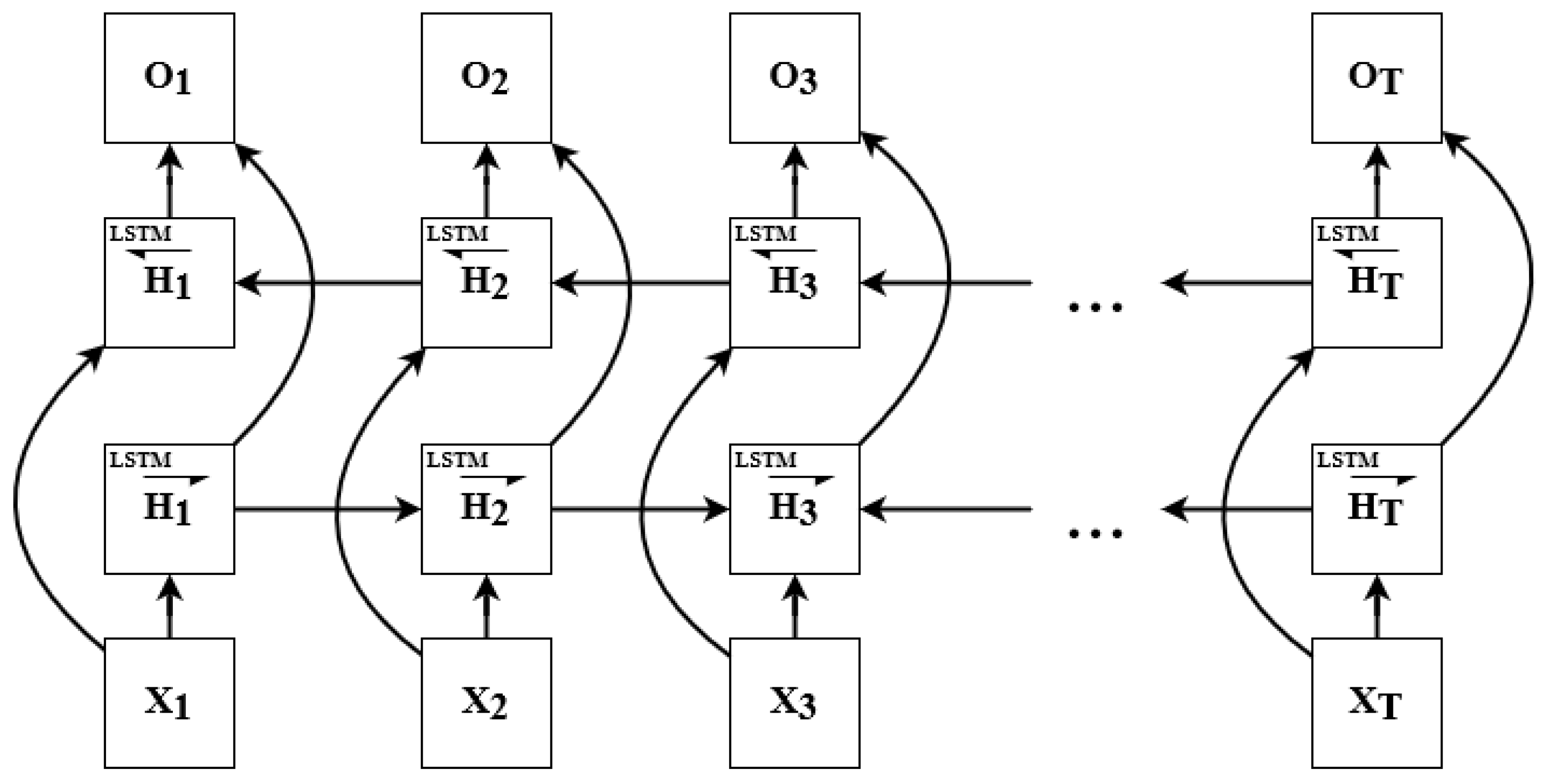
23]. We used highly spatially correlated wind as input for the deep learning method to select the best feature for significant wave forecasting. We chose an area with a complex geometry as the study case, an area in Indonesia’s Java Sea. Moreover, we also compared the results of wave prediction using BiLSTM with the results of other methods, i.e., LSTM, support vector regression (SVR), and a generalized regression neural network (GRNN).
The study area in the Java Sea was chosen since it is considered to have a complex geometry, in a relatively shallow coastal area. There have been several studies conducted in this study area. For example, in 2015, Rizkina et al. predicted the height of sea waves in the Java Sea using a simple ANN, which produced reasonably accurate prediction results with an RMSE of 0.06 m. In predicting it themselves, they used three inputs in the model, namely wave height, wind speed, and wind direction, to obtain the next wave height [
15]. In 2017, Dhanista et al. employed a neural network to forecast significant wave height in the Java Sea, especially in Northern Surabaya, and obtained favorable results for predicting 1 h and 6 h, with RMSE values of 0.03 and 0.09, respectively [
24]. In 2020, Vita Juliani et al. employed a GRNN to forecast the Jakarta Bay region, achieving a correlation coefficient of 0.92 and an RMSE of 0.13 [
25]. This paper aims to provide a better deep-learning-based significant wave forecasting method with the wind as the main feature of the deep learning input.
This paper is organized as follows:
Section 2 describes a brief description of the wave model and deep learning methods used in this study.
Section 3 describes the methodology to design the wave forecasting system, including data generation, exploratory data, and machine learning optimization. Results and discussions are presented in
Section 5. We conclude the paper in the last section.
3. Methodology
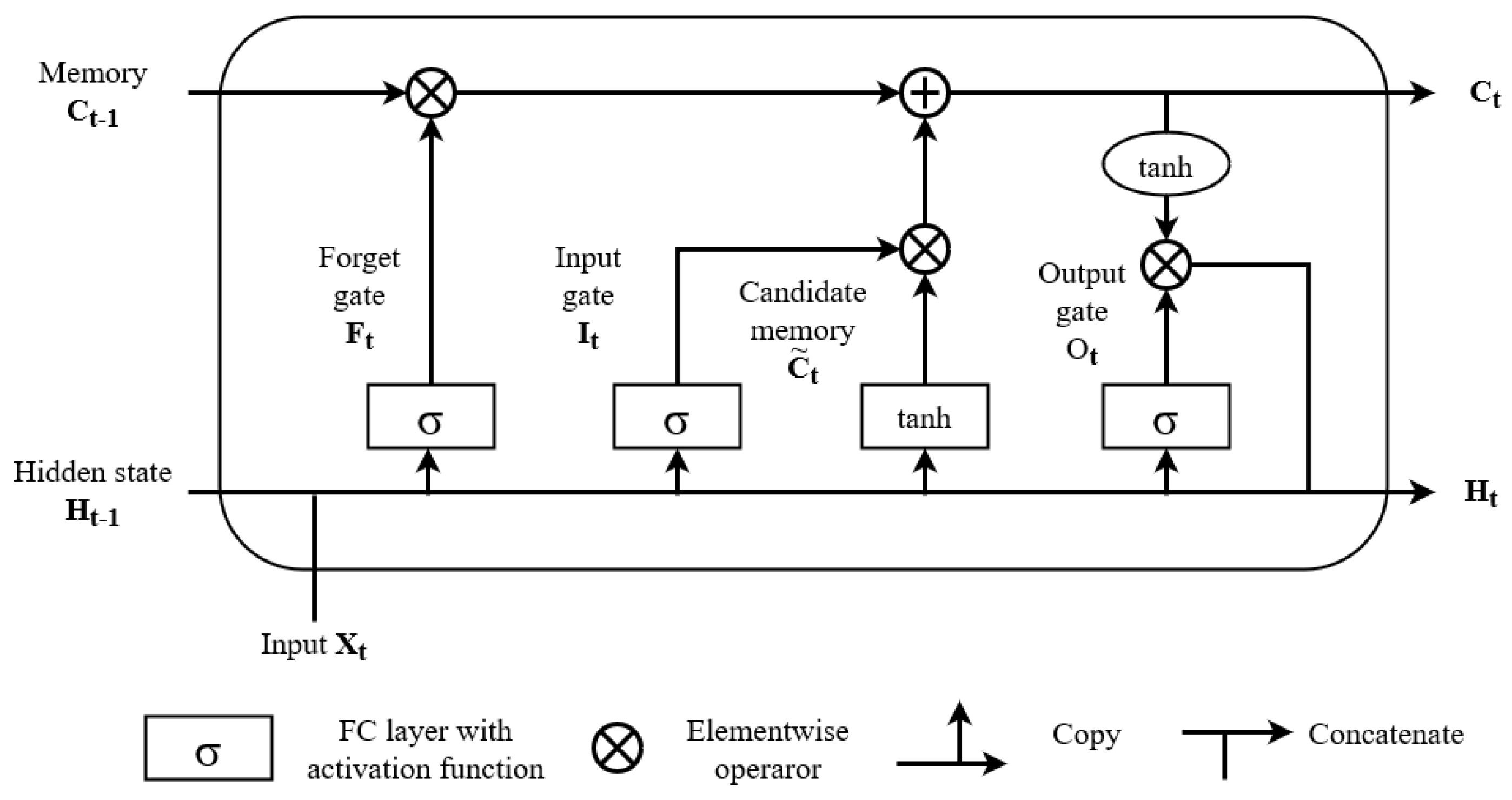
We designed a wave forecasting system based on a combined high-resolution numerical simulation with a deep learning model; there were three main steps in designing the system. The initial step was to build a wave dataset from wind field data by performing continuous-wave simulation using the SWAN model. In the second step, the obtained wave dataset and wind field data from the previous step were used for exploratory data to investigate the best feature to be used as input for the deep learning BiLSTM method. Here, we calculated the spatial correlation between wind field data and wave height at the study area, i.e., in Jakarta Bay, Java Sea, Indonesia. The last step was to optimize the deep learning algorithm to obtain the best forecasting accuracy. Moreover, we also compared the results of wave forecasting using BiLSTM with other machine learning models, such as LSTM, Support Vector Regression (SVR), and the Generalized Regression Neural Network (GRNN).
3.1. Wave Data Generation
For predicting waves in environments with a complex geometry, such as in a coastal area with many small islands, high-resolution wave simulation is needed, especially to better represent the simulation domain’s geometry. We used the SWAN model to generate high-resolution training data by performing continuous-wave simulation with the ECMWF ERA-5 wind data. The simulation procedure for obtaining significant wave height data is depicted in
Figure 3. The initial step was to prepare wind and bathymetry data for the wave simulation. As mentioned previously, we used hourly ECMWF ERA-5 wind data [
23] for the last 20 years (2000–2020). We used the bathymetry provided by GEBCO (General Bathymetric Chart of the Oceans) for simulation in the global domain, whereas we used Indonesia’s BATNAS (National Bathymetry) for the location domain.
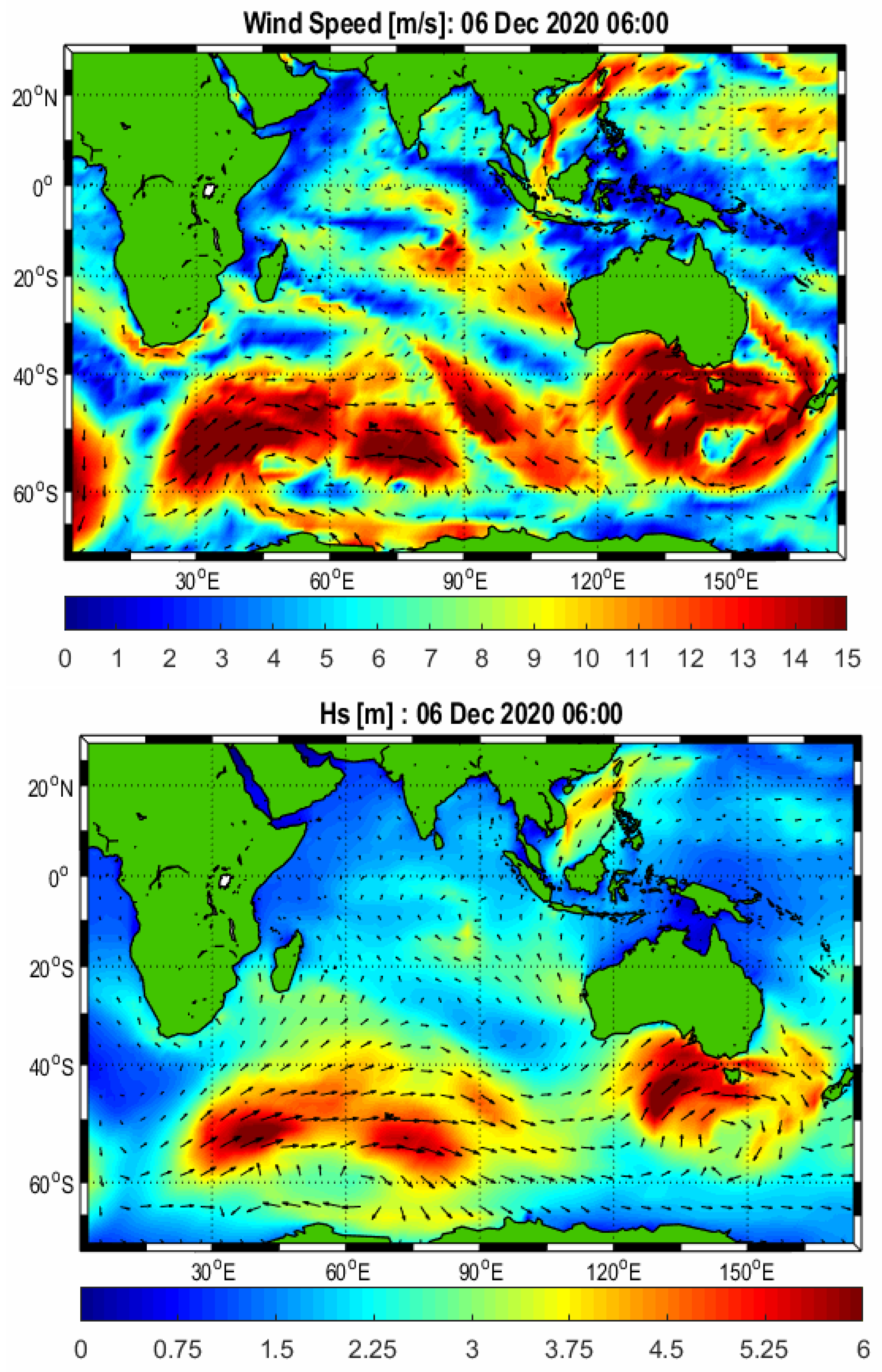
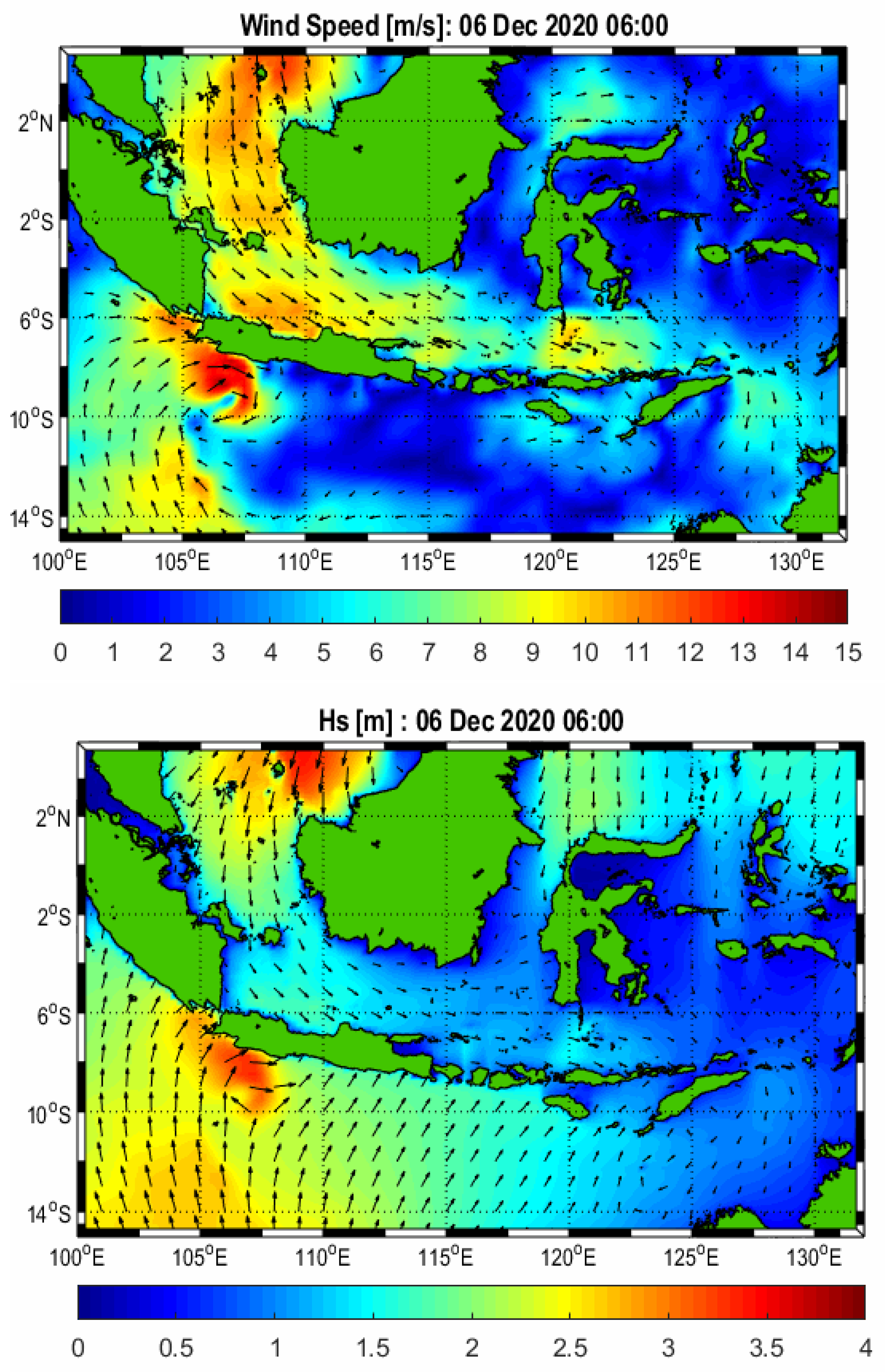
The wave data here consists of the significant wave height (Hs), peak wave period (Tp), and mean wave direction. To obtain accurate wave data for an environment with a complex geometry and a rather shallow bathymetry, such as in the Java Sea, we performed nested simulations consisting of 2 nested domains. These nested simulations were aimed to obtain a high-resolution simulation in our study area, in Jakarta Bay, Java Sea, Indonesia. Firstly, we simulated wave conditions in a global domain as shown in
Figure 4. Secondly, we simulated wave conditions and, in addition, obtained boundary conditions from the global simulation to simulate wave propagation in an intermediate domain, as shown in
Figure 5. Lastly, we simulated the wave propagation in a local domain in Jakarta Bay, Java Sea, by using boundary conditions obtained from the intermediate domain, as shown in
Figure 6.
Figure 4,
Figure 5 and
Figure 6 show snapshots of the wind field (left part) and the resulting significant wave height (right part) on 6 December 2020 at 06:00 UTC.
The numerical setting for these three domains is shown in
Table 1. Here,
and
denote the spatial grid size in longitude and latitude.
and
represent the number of discretization points in longitude and latitude. For the global and intermediate domains, we used spatial grid sizes of
and
, respectively, whereas to accurately represent the geometry of the local domain in Jakarta Bay, we used a spatial resolution of 0.00267
.
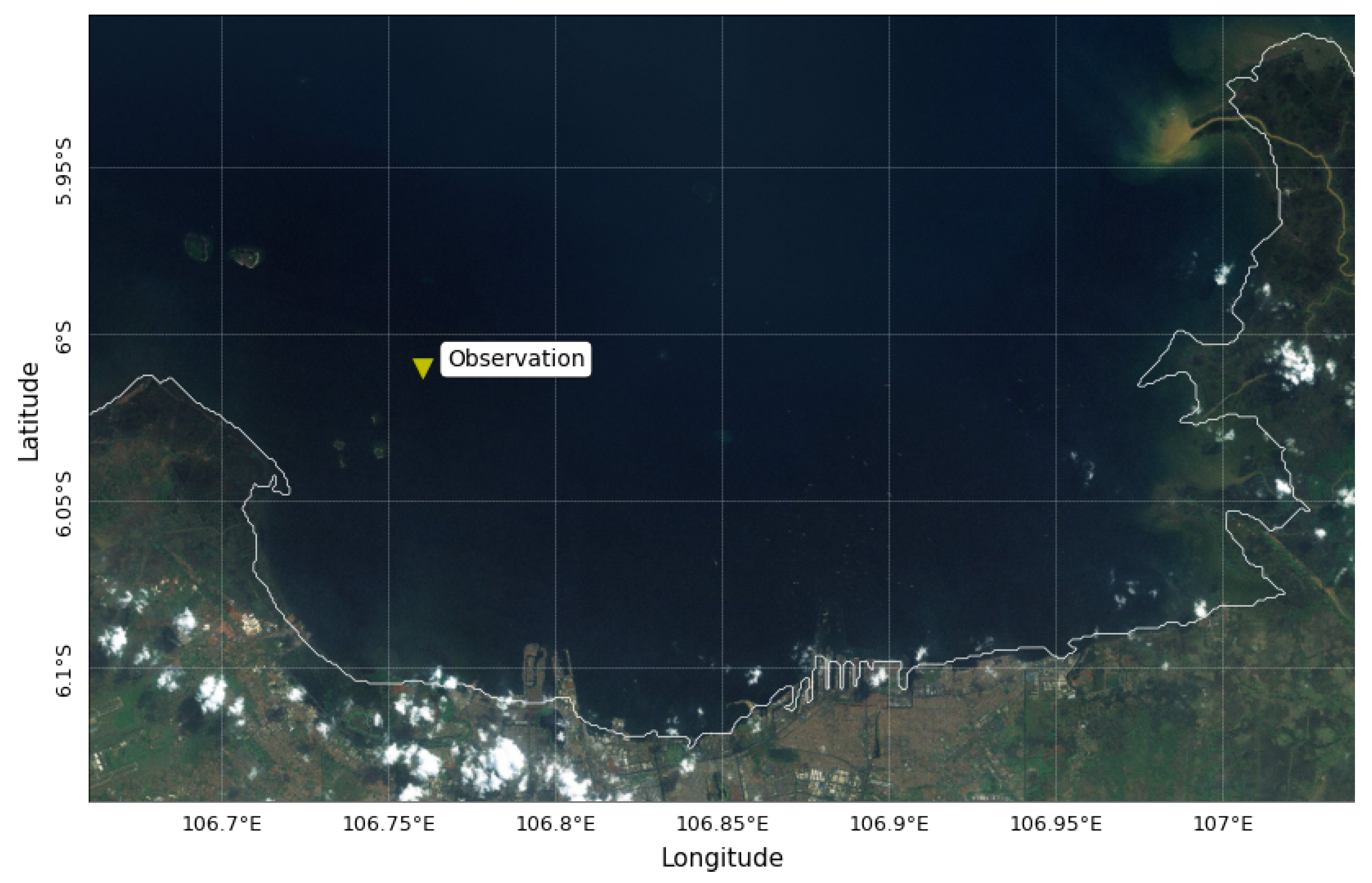
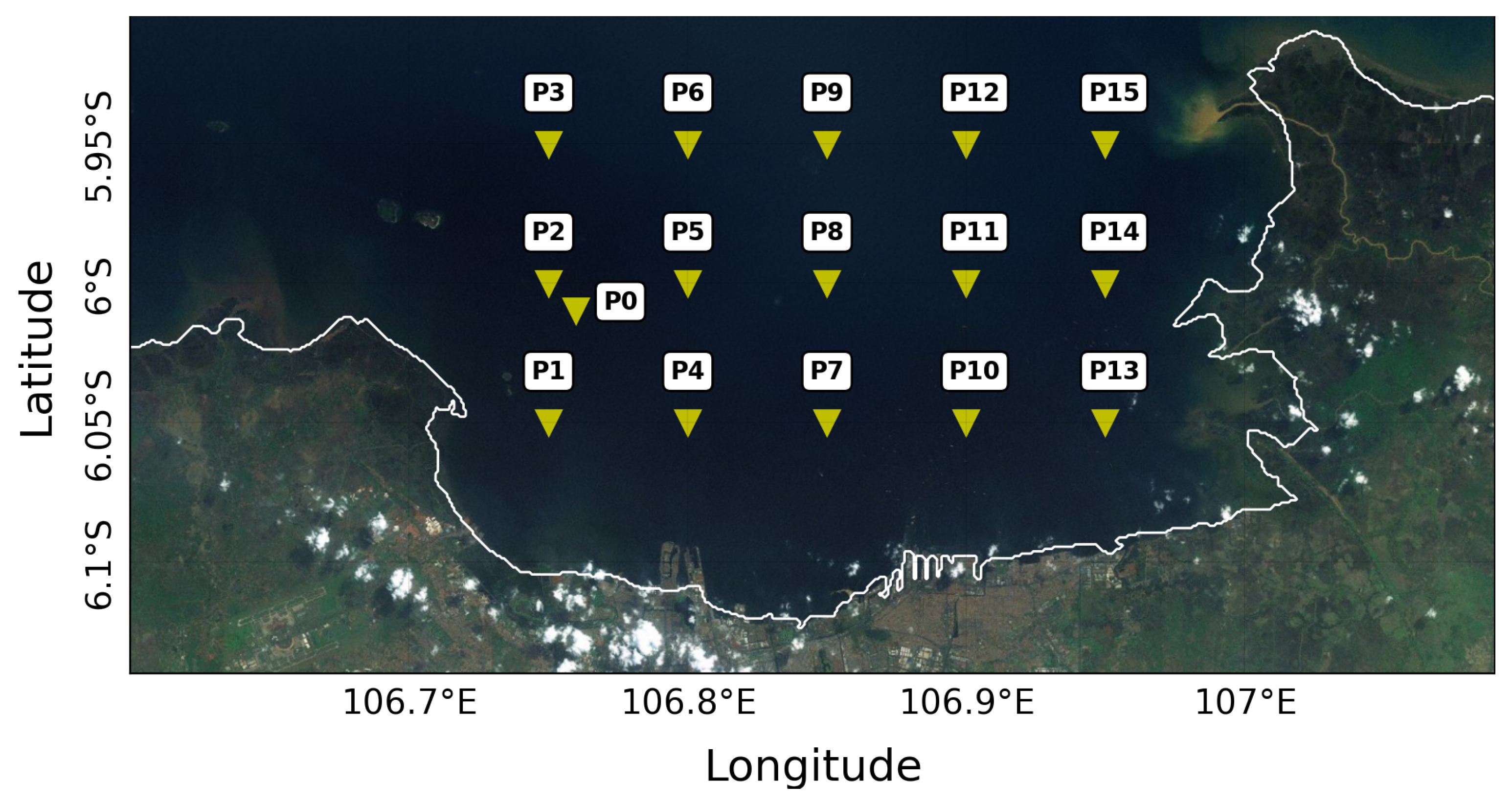
To test the accuracy of the resulting wave simulation, we compared the results of SWAN simulation with available wave observations in Jakarta Bay, Java Sea, Indonesia. The data on wave observations of the location 106.7654
E and 6.0108
S in Jakarta Bay, Java Sea, from 21 January–2 February 2017 are shown in
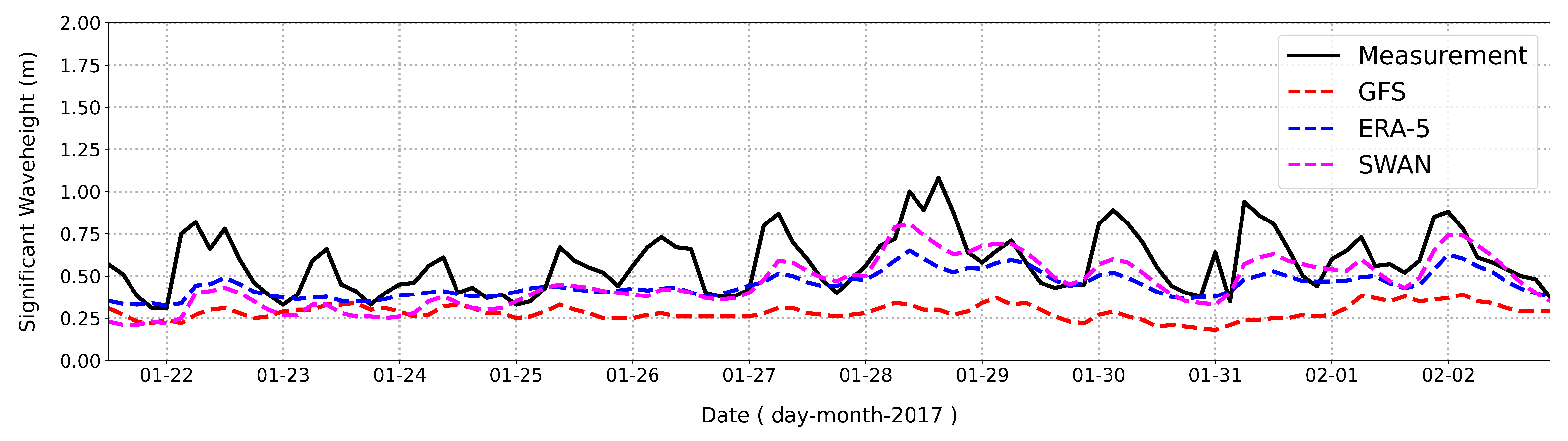
Figure 7. Results of the SWAN simulation, compared with observation data, waves from ERA-5, and waves from The Global Forecast System (GFS) from the National Oceanic and Atmospheric Administration (NOAA), are shown in
Figure 8. As shown in
Figure 8, the significant wave height results from the SWAN simulation show the best performance compared to the other wave simulations, i.e., from the waves from ERA-5 and GFS-NOAA.
In the following subsection, we investigate the spatial correlation between the wind data and the significant wave data from the SWAN simulation. We calculated the correlation coefficient from the wind data at all available wind locations with respect to the significant wave height data at the observation point in Jakarta Bay, i.e., at 106.7654 E and 6.0108 S.
3.2. Exploratory Data
As mentioned previously, the wave height and direction are significantly affected by wind magnitude and direction. Nevertheless, it is not clear at which locations the wind most affects the wave height in the study area. This subsection investigates the relation between wind field and significant wave height spatially. After generating a wave dataset from continuous-wave simulation using the SWAN model, we describe a method to find the best wind locations that significantly affect the significant wave height in our study area in Jakarta Bay, Teluk Jakarta. To that end, we define here the so-called Spatial Correlation (SC). We calculated the Correlation Coefficient (CC) between wind data at all available locations with significant wave data at one point in Jakarta Bay. The following formula defines the correlation coefficient that we used.
where
n denotes the number of data to be compared,
represents the values of the first variable, and
is the average of the first variable values, while
represents the values of the second variable, and
is the average of the second variable values.
In general, the method in this subsection is depicted in
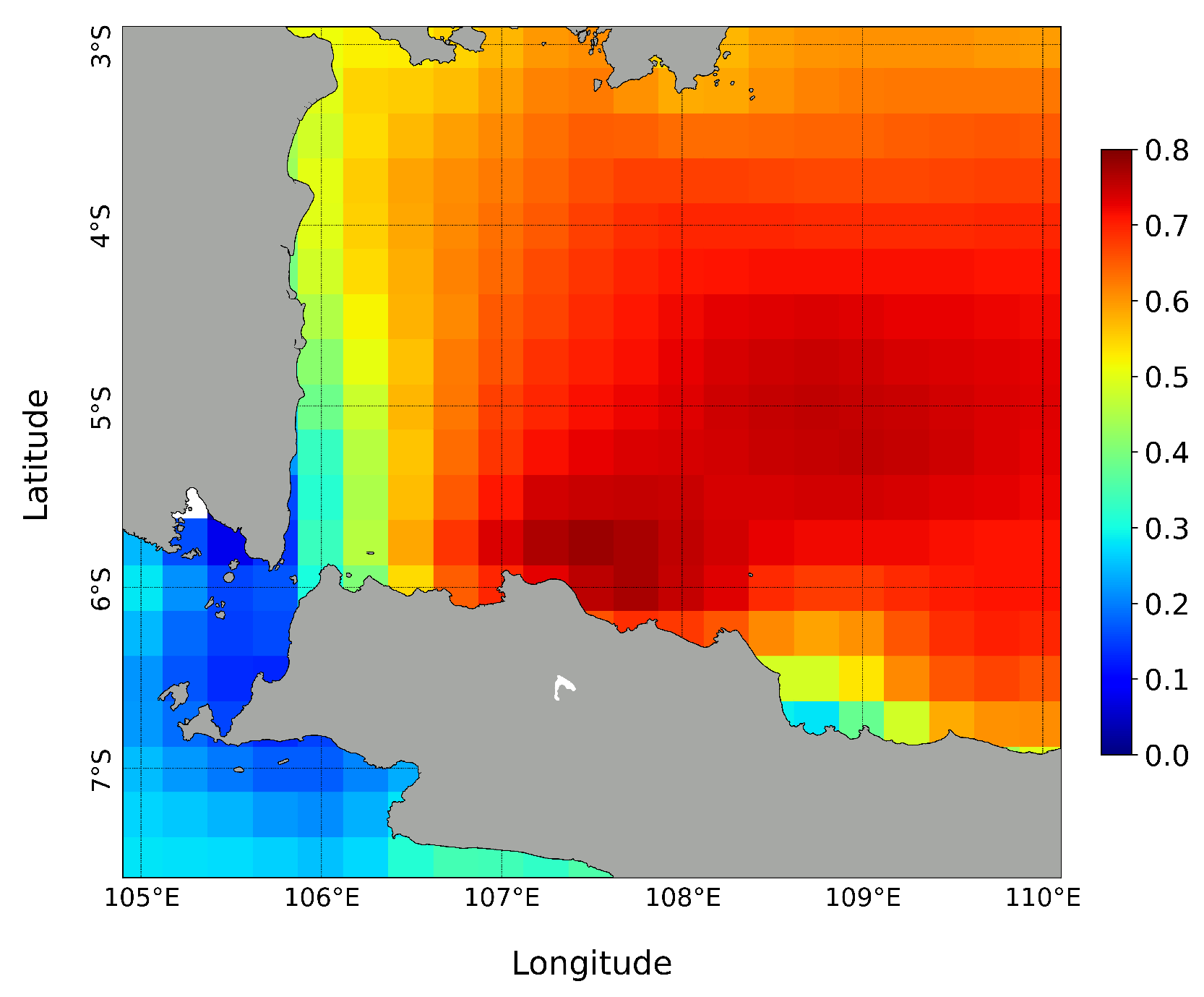
Figure 9. To obtain a Spatial Correlation (SC) map between wind fields with significant wave data, we calculated the correlation coefficient values between the wind data at the South East Asia region with wave data at the observation point in Jakarta Bay as shown in
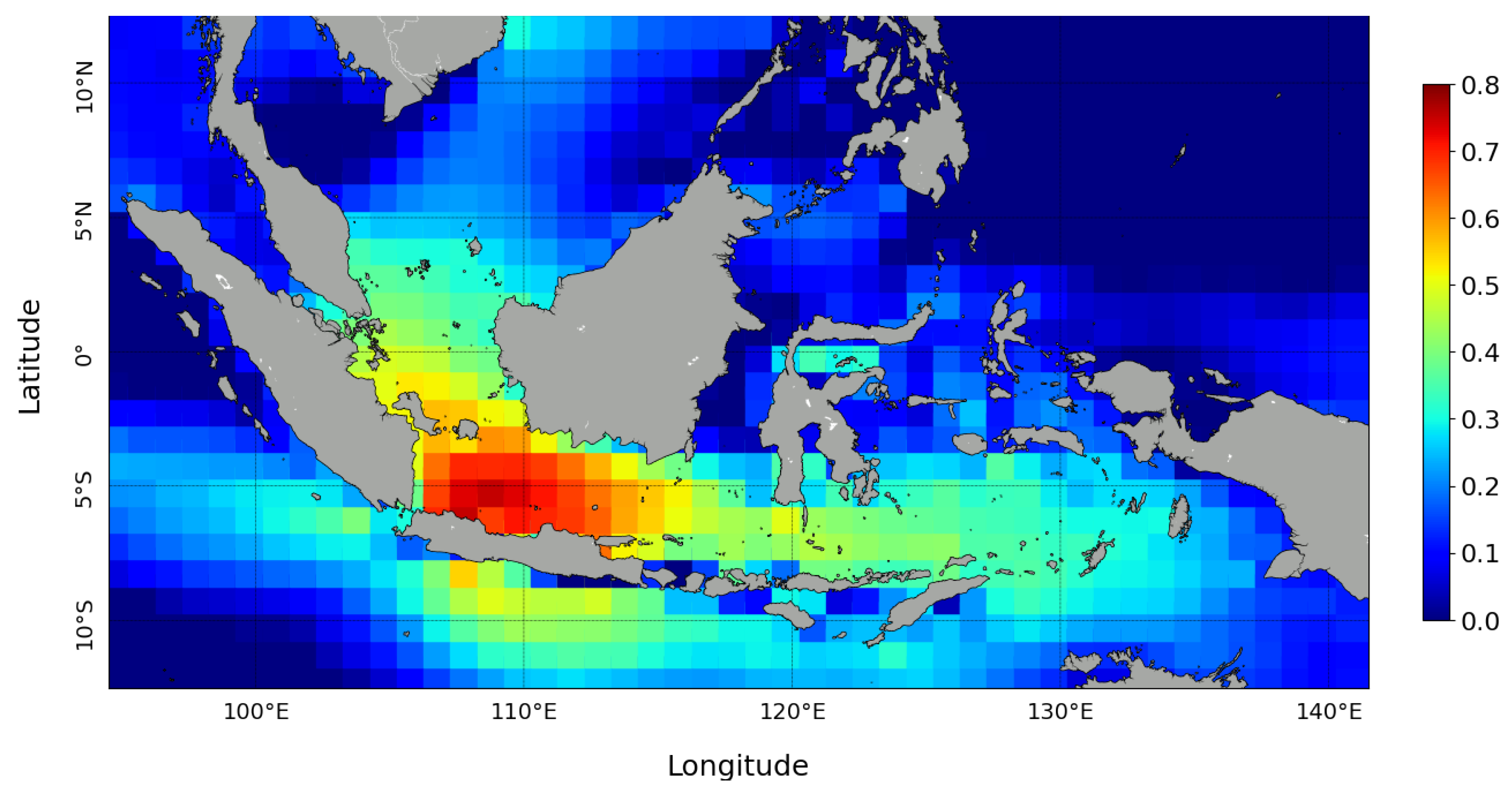
Figure 7. The resulting SC map in the South East Asia region is shown in
Figure 10. The figure shows that the correlation coefficient values are between 0 and 0.8. A higher CC value indicates that these wind locations are highly correlated with significant wave height at the wave observation point in Jakarta Bay.
Figure 10 shows that the wind closest to Jakarta Bay has a significant influence, with a correlation value nearing 0.8, indicating that the wind and the significant wave height are highly correlated.
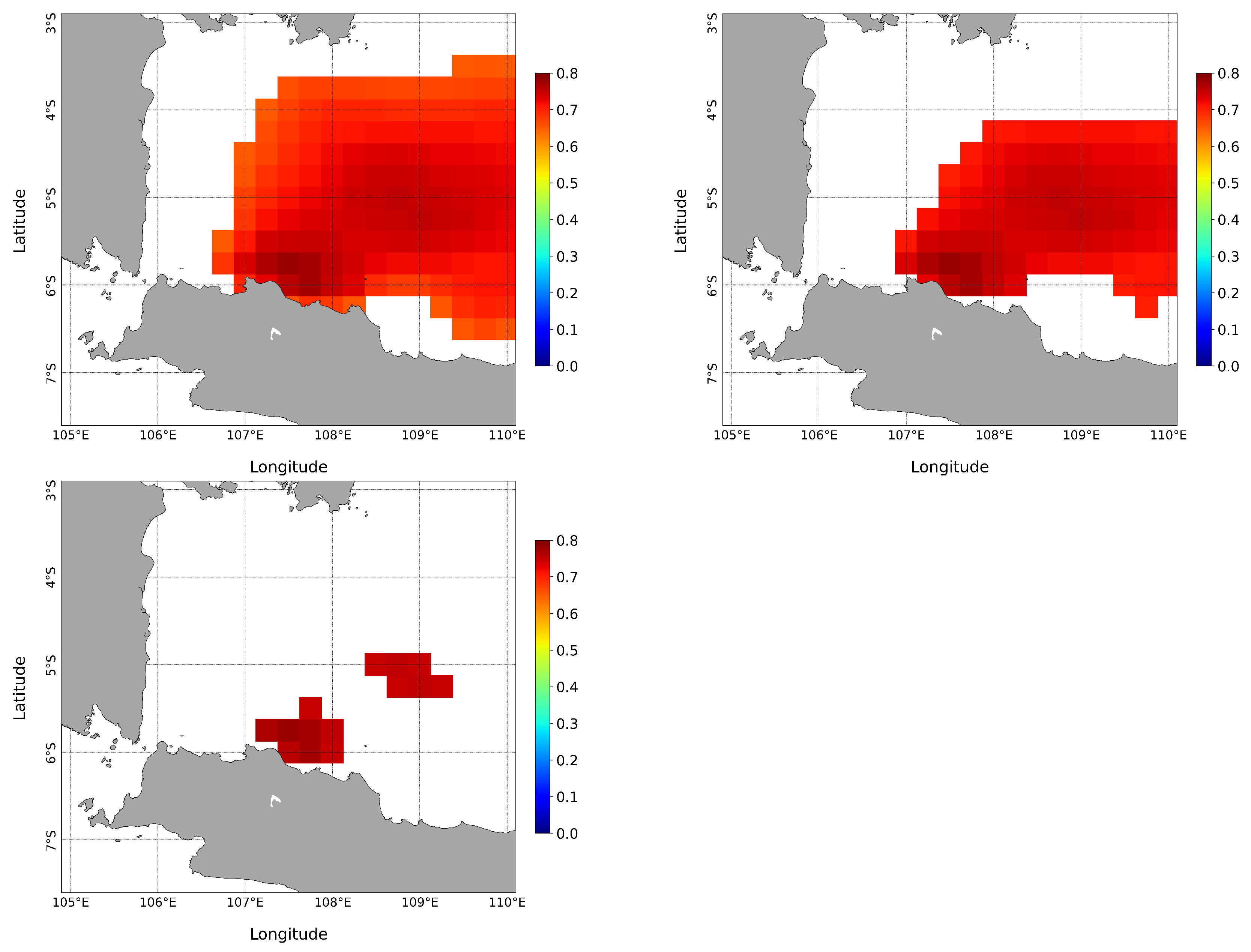
Higher correlation coefficient values are seen on the northwestern side of Java Island, as shown in
Figure 11. To investigate the effects of these correlation coefficient values, we categorized wind locations with high spatial correlation values on the western side of the Java Sea into three categories: i.e., wind locations where
,
, and
, shown in
Figure 12. Intuitively, wind locations with high correlation coefficient values will significantly affect wave height at the observation point in Jakarta Bay.
The obtained SC maps were then used to select which wind locations to be included as a feature in the machine learning models. In order to include the effects of wind direction, we used wind vector components and as features for the input for the machine learning models. Here, and are wind vector components at a 10 m height in the longitude and latitude direction, respectively.
After investigating the SC map between the wind data and the wave data at the observation point in Jakarta Bay, we conducted tests using machine learning models such as SVR, GRNN, LSTM, and BiLSTM, which are explained in the following subsection.
3.3. Machine Learning Optimization
This subsection aims to determine which machine learning model is best by assessing their accuracy using the Correlation Coefficient (CC) and Root Mean Square Error (RMSE) values. The CC value is as defined in Equation (
8), whereas the RMSE value is defined as follows:
where
n denotes the number of data observations,
represents the observed value, and
represents the predicted value.
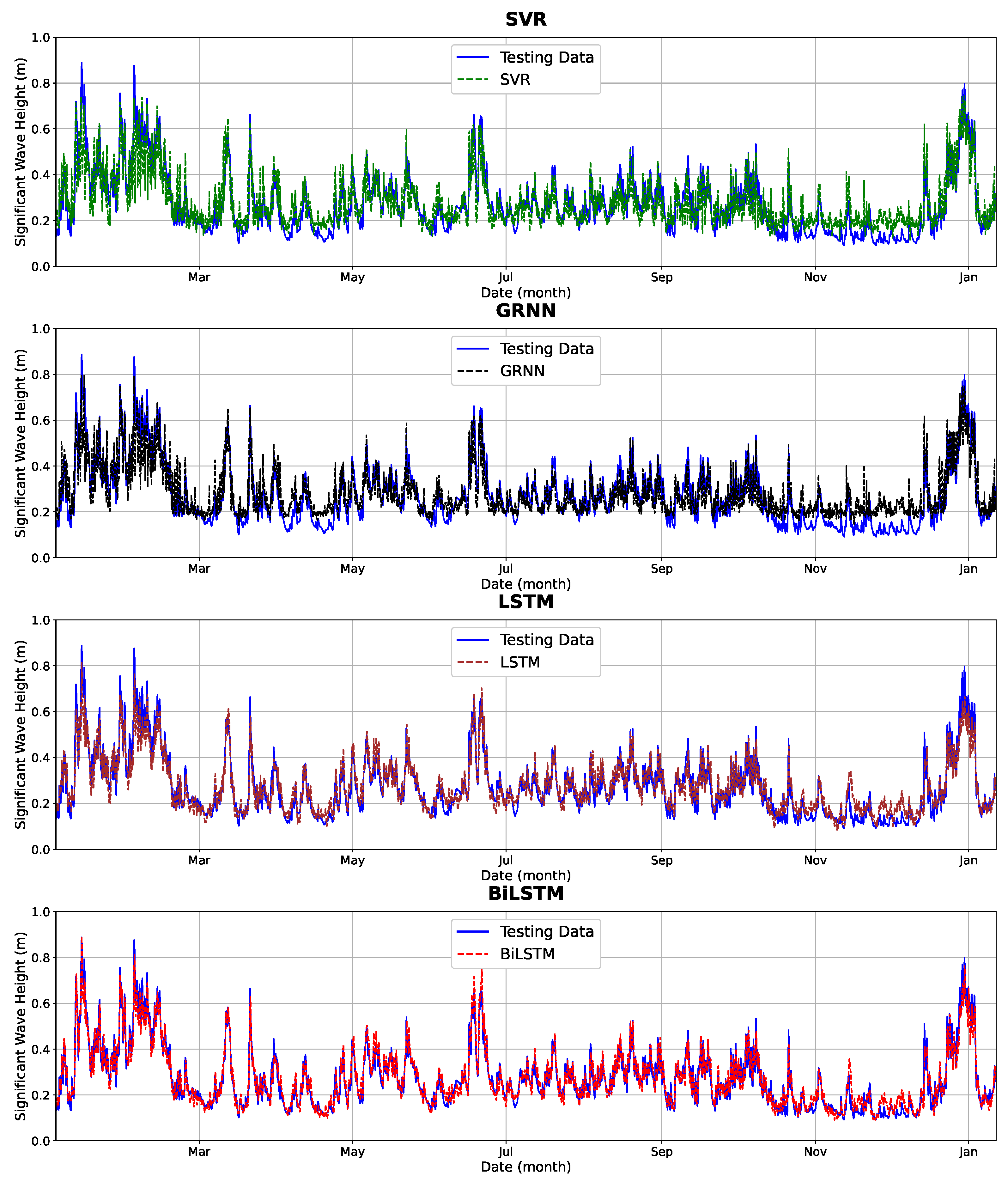
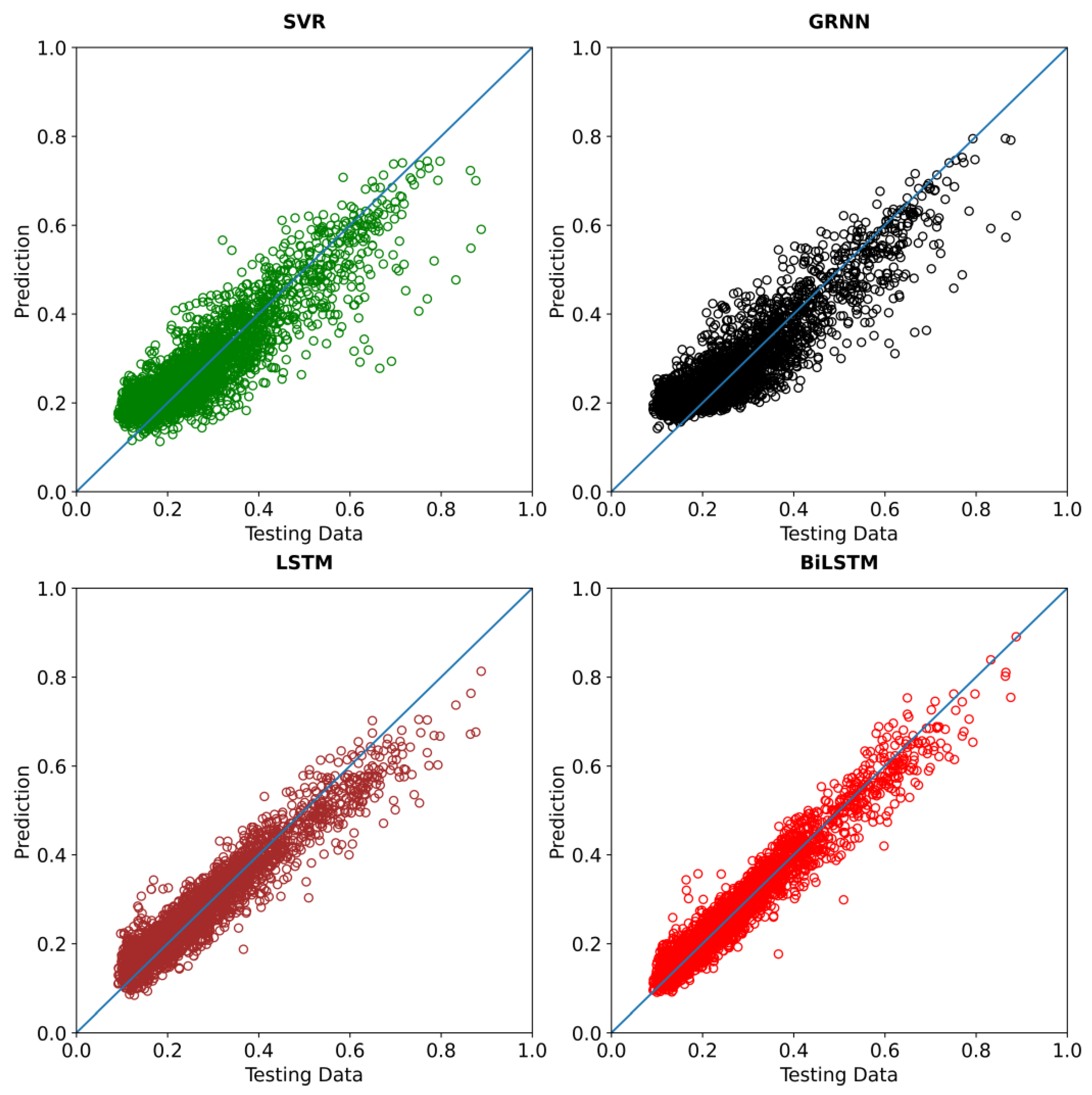
As mentioned previously, we compared the performance of four machine learning models, i.e., the SVR, GRNN, LSTM, and the BiLSTM. Whenever the accuracy of each model was insufficient, we performed hyperparameter tuning for each machine learning model. The procedure of the machine learning optimization can be seen in
Figure 13.
After performing hyperparameter tuning for each machine learning model, we obtained the following settings. For the Support Vector Regression (SVR) model, we found that the best parameter settings are with a RBF (radial basis function) kernel, with the parameter set as “scaled”, an of , and a relative error tolerance of . For the Generalized Regression Neural Network (GRNN), we found that a spreading parameter of yielded the best performance. For the LSTM model, we used three hidden layers, with the number of nodes at each layer being 512, 16, and 1. The activation function used was sigmoid, and was combined with the tanh function for its recurrent network. In the BiLSTM model, we also had the same configuration as the LSTM model for the number of hidden layers and its corresponding number of nodes, but with a Relu activation function combined with a sigmoid activation function for its recurrent network. For both LSTM and BiLSTM, Adam’s optimizer was used.
Not only did we perform hyperparameter tuning for each machine learning model, but we also investigated the effects of wind features on the resulting wave forecasting accuracy. In the following section, we calculate the machine learning prediction with wind input location based on a spatial correlation with
,
, and
, as shown in
Figure 12.
5. Conclusions
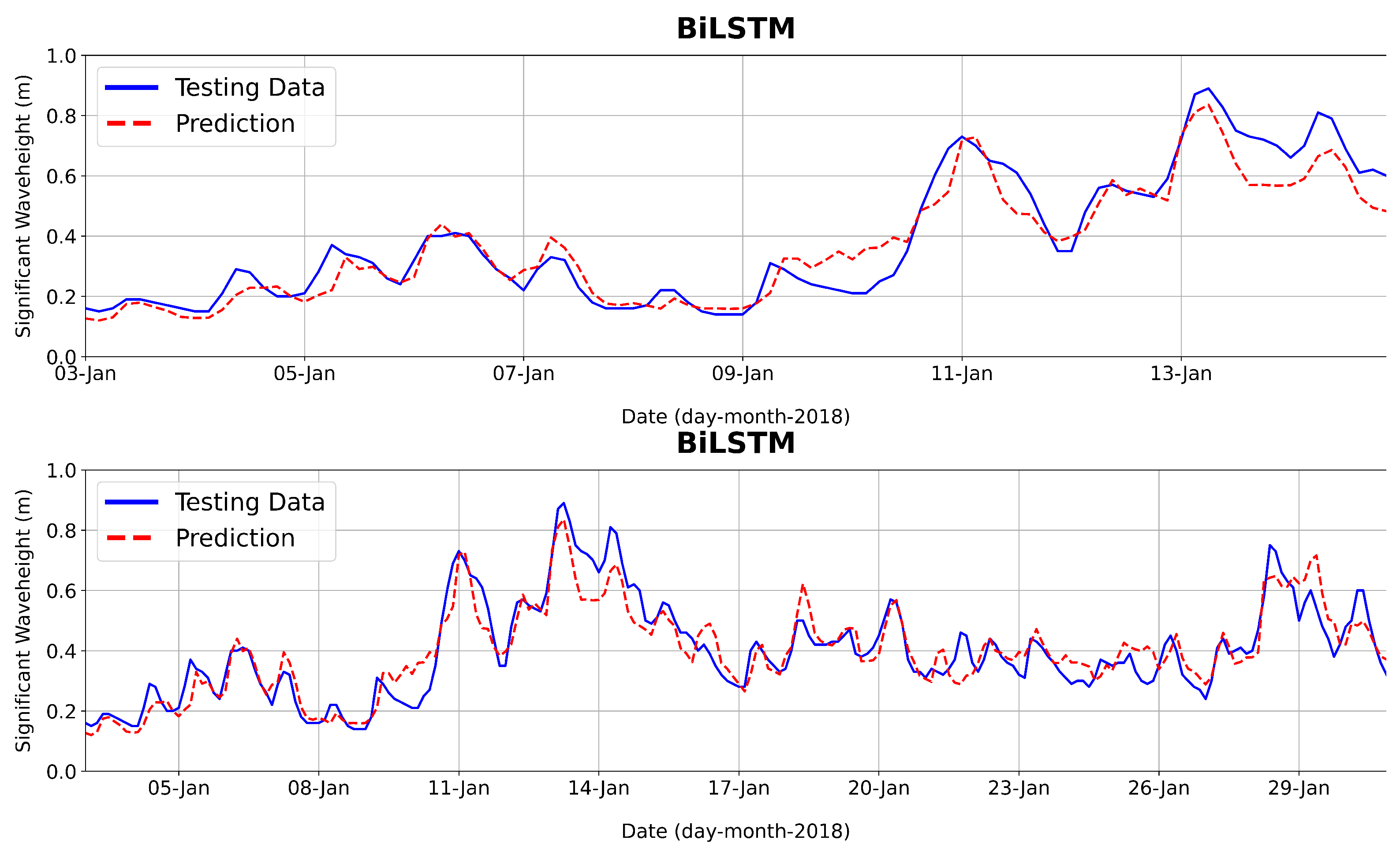
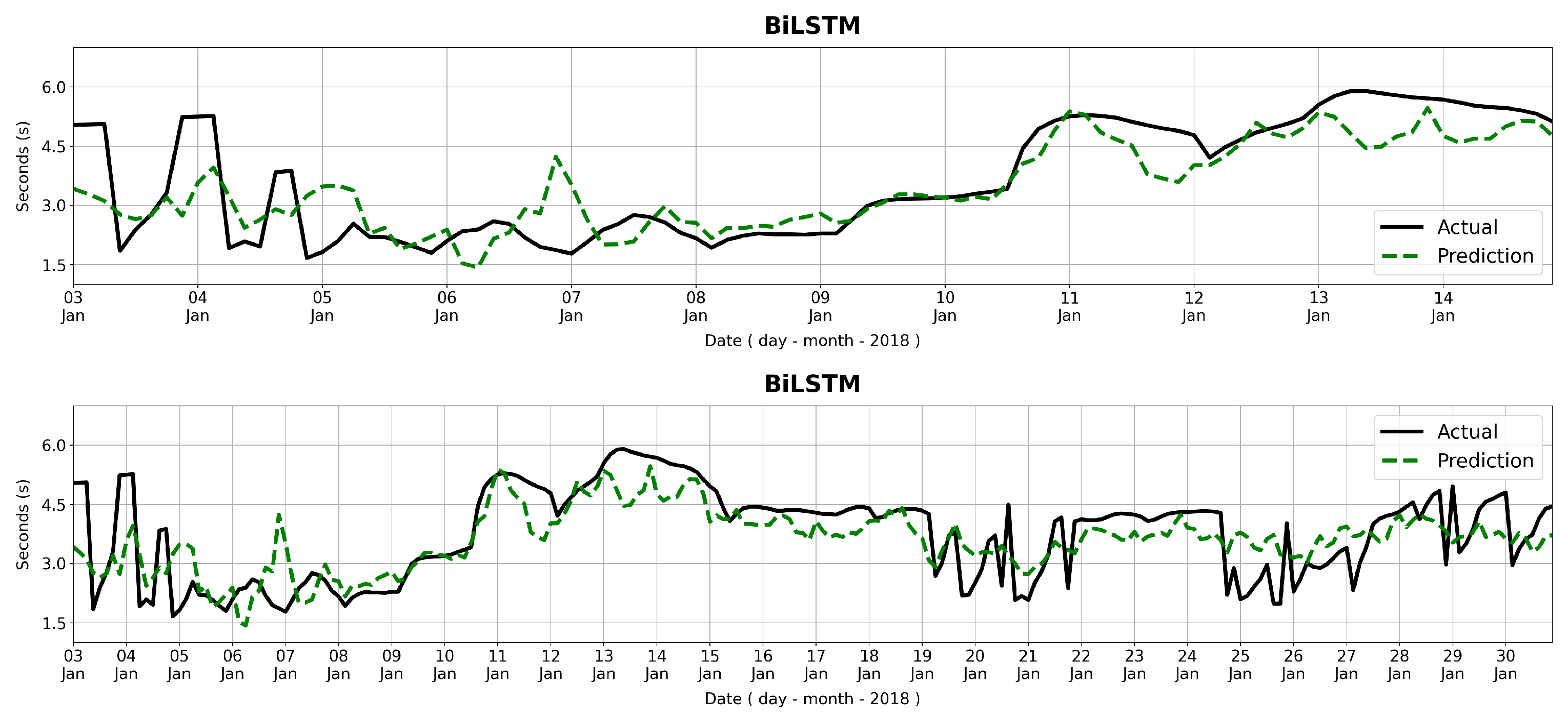
In this paper, we introduced a novel approach to designing a wave forecasting system based on combined high-resolution numerical wave simulation with a deep learning model, i.e., BiLSTM, to forecast significant wave height in an environment with a complex geometry, such as a coastal area with many islands. To that aim, we generated training data for the deep learning model using continuous numerical simulation using the SWAN model with two nested domains. We compared the SWAN simulation results with available wave observation data at Jakarta Bay, Java Sea, Indonesia, to validate the SWAN simulation results. The obtained training data were then used as training data for the deep learning method. To obtain the best possible wind feature as input for the deep learning model, we calculated spatial correlation values between the wind data at all locations in the Southeast Asia region and the significant wave height at the observation location in Jakarta Bay. Our investigation concludes that using wind input locations with a high spatial correlation improves forecast performance. In our case, wind locations with spatial correlation values with significant wave height data in Jakarta Bay of yielded the best forecast performance, with a correlation coefficient value of 0.96 and an RMSE value of 0.06. We also investigated the effect of the length of the training data in forecast performance. From a numerical experiment, we concluded that training data of 15 years yields the best performance compared with training data of a shorter period of time, even though results with 10 years of training data also yielded very similar results. In addition to significant wave height Hs, we also performed predictions of the peak wave period Tp and the mean wave direction. Since the characteristics of Tp are quite different from Hs, we obtained a CC value of 0.83 for predicting 14 days, whereas the mean wave direction results in a better performance with a CC value of 0.92. To predict Tp, more appropriate machine learning models can be investigated, since Tp characteristics are very different from Hs and mean wave direction.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}