

Automated Cattle Head and Ear Pose Estimation Using Deep Learning for Animal Welfare Research

Simple Summary
Abstract
1. Introduction
2. Materials and Methods
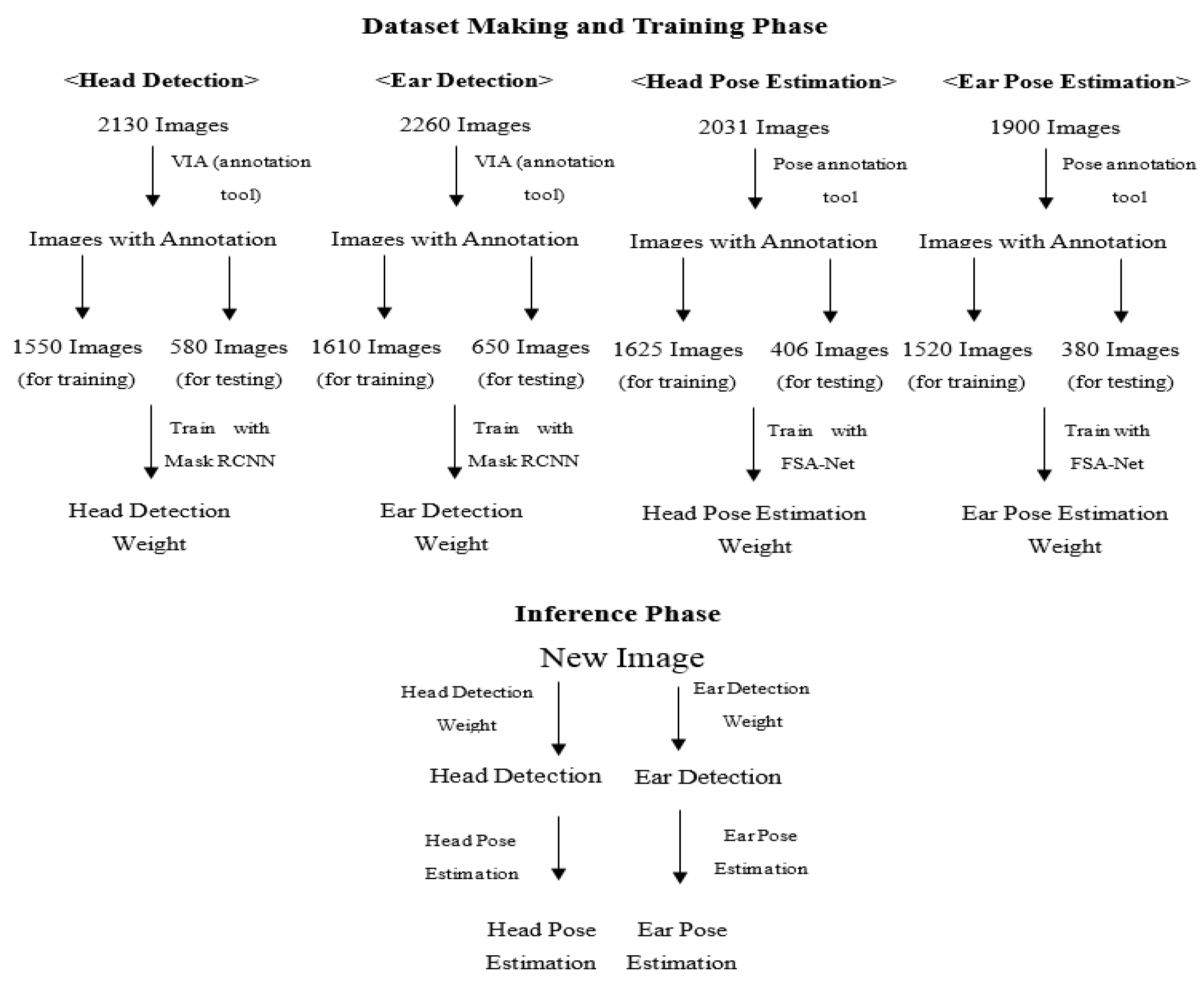
2.1. Overview of Our Framework
2.2. Image Acquisition and Dataset Composition
2.3. Object Detection: Annotation and Dataset Construction
2.4. Object Detection: Model Training
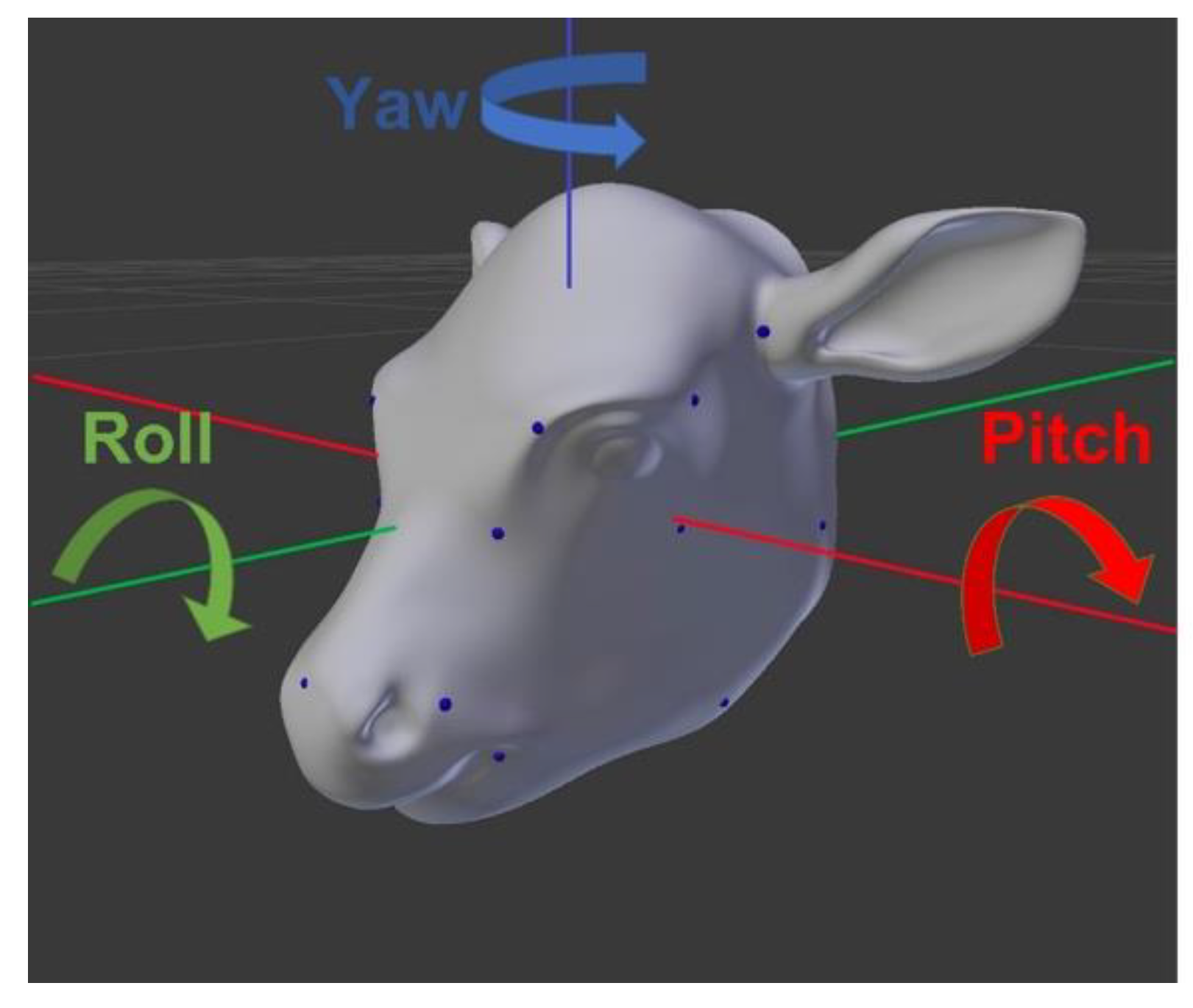
2.5. Pose Estimation: 3D Pose Annotation and Dataset Construction
2.6. Pose Estimation: Model Training
2.7. Performance Evaluation
3. Results
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cavallini, D.; Giammarco, M.; Buonaiuto, G.; Vignola, G.; Vettori, J.D.M.; Lamanna, M.; Prasinou, P.; Colleluori, R.; Formigoni, A.; Fusaro, I. Two years of precision livestock management: Harnessing ear tag device behavioral data for pregnancy detection in free-range dairy cattle on silage/hay-mix ration. Front. Anim. Sci. 2025, 6, 1547395. [Google Scholar] [CrossRef]
- Auer, U.; Kelemen, Z.; Vogl, C.; von Ritgen, S.; Haddad, R.; Borda, L.T.; Gabmaier, C.; Breteler, J.; Jenner, F. Development, refinement, and validation of an equine musculoskeletal pain scale. Front. Pain Res. 2024, 4, 1292299. [Google Scholar] [CrossRef] [PubMed]
- Evangelista, M.C.; Watanabe, R.; Leung, V.S.Y.; Monteiro, B.P.; O’tOole, E.; Pang, D.S.J.; Steagall, P.V. Facial expressions of pain in cats: The development and validation of a Feline Grimace Scale. Sci. Rep. 2019, 9, 1–11. [Google Scholar] [CrossRef]
- Gleerup, K.B.; Andersen, P.H.; Munksgaard, L.; Forkman, B. Pain evaluation in dairy cattle. Appl. Anim. Behav. Sci. 2015, 171, 25–32. [Google Scholar] [CrossRef]
- Rogers, L.J. Relevance of brain and behavioural lateralization to animal welfare. Appl. Anim. Behav. Sci. 2010, 127, 1–11. [Google Scholar] [CrossRef]
- Phillips, C.; Oevermans, H.; Syrett, K.; Jespersen, A.; Pearce, G. Lateralization of behavior in dairy cows in response to conspecifics and novel persons. J. Dairy Sci. 2015, 98, 2389–2400. [Google Scholar] [CrossRef]
- Amira, A.G.; Gareth, P.P.; Jashim, U.; Eloise, R.; Harriet, D.; Clive, J.P. A forced lateralisation test for dairy cows and its relation to their behaviour. Appl. Anim. Behav. Sci. 2018, 207, 8–19. [Google Scholar] [CrossRef]
- Ask, K.; Rhodin, M.; Rashid-Engström, M.; Hernlund, E.; Andersen, P.H. Changes in the equine facial repertoire during different orthopedic pain intensities. Sci. Rep. 2024, 14, 129. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Kim, S.; Hidaka, Y. Breathing Pattern Analysis in Cattle Using Infrared Thermography and Computer Vision. Animals 2021, 11, 207. [Google Scholar] [CrossRef]
- Kim, S.; Yamagishi, N.; Ishikawa, S.; Tsuchiaka, S. Unique temperature change patterns in calves eyes and muzzles: A non-invasive approach using infrared thermography and object detection. Front. Veter. Sci. 2025, 12, 1548906. [Google Scholar] [CrossRef] [PubMed]
- Nath, T.; Mathis, A.; Chen, A.C.; Patel, A.; Bethge, M.; Mathis, M.W. Using DeepLabCut for 3D markerless pose estimation across species and behaviors. Nat. Neurosci. 2019, 21, 1281–1289. [Google Scholar] [CrossRef] [PubMed]
- Pereira, T.D.; Tabris, N.; Matsliah, A.; Turner, D.M.; Li, J.; Ravindranath, S.; Papadoyannis, E.S.; Normand, E.; Deutsch, D.S.; Wang, Z.Y.; et al. SLEAP: A deep learning system for multi-animal pose tracking. Nat. Methods 2022, 19, 486–495. [Google Scholar] [CrossRef] [PubMed]
- Ye, S.; Filippova, A.; Lauer, J.; Schneider, S.; Vidal, M.; Qiu, T.; Mathis, A.; Mathis, M.W. SuperAnimal pretrained pose estimation models for behavioral analysis. Nat. Commun. 2024, 15, 5165. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Ferrario, C.R.; Maitland, A.D.; Ionides, R.B.; Ghimire, A.; Watson, B.; Iwasaki, K.; White, H.; Xi, Y.; Zhou, J.; et al. LabGym: Quantification of user-defined animal behaviors using learning-based holistic assessment. Cell Rep. Methods 2023, 3, 100415. [Google Scholar] [CrossRef]
- Mathis, A.; Mamidanna, P.; Cury, K.M.; Abe, T.; Murthy, V.N.; Mathis, M.W.; Bethge, M. DeepLabCut: Markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 2018, 21, 1281–1289. [Google Scholar] [CrossRef]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Baltrusaitis, T.; Robinson, P.; Morency, L.P. Constrained local neural fields for robust facial landmark detection in the wild. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops (ICCVW), Sydney, Australia, 1–8 December 2013; pp. 354–361. [Google Scholar]
- Yang, T.-Y.; Chen, Y.-T.; Lin, Y.-Y.; Chuang, Y.-Y. FSA-Net: Learning Fine-Grained Structure Aggregation for Head Pose Estimation From a Single Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1087–1096. [Google Scholar] [CrossRef]
- Ruiz, N.; Chong, E.; Rehg, J.M. Fine-grained head pose estimation without keypoints. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2074–2083. [Google Scholar]
- Dutta, A.; Zisserman, A. The VIA Annotation Software for Images, Audio and Video. In Proceedings of the 27th ACM International Conference on Multimedia (MM 2019), Nice, France, 21–25 October 2019; pp. 2276–2279. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V. Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Koestinger, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Annotated Facial Landmarks in the Wild: A Large-Scale, Real-World Database for Facial Landmark Localization. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2144–2151. [Google Scholar]
- Dementhon, D.F.; Davis, L.S. Model-based object pose in 25 lines of code. Int. J. Comput. Vis. 1995, 15, 123–141. [Google Scholar] [CrossRef]
- Robertson, I.; Kent, J.; Molony, V. Effect of different methods of castration on behaviour and plasma cortisol in calves of three ages. Res. Veter. Sci. 1994, 56, 8–17. [Google Scholar] [CrossRef]
- McMorris, T.; Swain, J.; Smith, M.; Corbett, J.; Delves, S.; Sale, C.; Potter, J. Heat stress, plasma concentrations of adrenaline, noradrenaline, 5-hydroxytryptamine and cortisol, mood state and cognitive performance. Int. J. Psychophysiol. 2006, 61, 204–215. [Google Scholar] [CrossRef]
- Hickey, M.C.; Drennan, M.; Earley, B. The effect of abrupt weaning of suckler calves on the plasma concentrations of cortisol, catecholamines, leukocytes, acute-phase proteins and in vitro interferon-gamma production. J. Anim. Sci. 2003, 81, 2847–2855. [Google Scholar] [CrossRef]
- Dzviti, M.; Mapfumo, L.; Muchenje, V. Relationship between saliva and blood cortisol in handled cows. Asian-Australas. J. Anim. Sci. 2019, 32, 734–741. [Google Scholar] [CrossRef]
- Rees, A.; Fischer-Tenhagen, C.; Heuwieser, W. Effect of Heat Stress on Concentrations of Faecal Cortisol Metabolites in Dairy Cows. Reprod. Domest. Anim. 2016, 51, 392–399. [Google Scholar] [CrossRef] [PubMed]
- Nejad, J.G.; Kim, B.; Lee, B.; Sung, K. Coat and hair color: Hair cortisol and serotonin levels in lactating Holstein cows under heat stress conditions. Anim. Sci. J. 2016, 88, 190–194. [Google Scholar] [CrossRef] [PubMed]
- Valle, R.; Buenaposada, J.M.; Baumela, L. Multi-task head pose estimation in-the-wild. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2874–2881. [Google Scholar] [CrossRef]
- Cho, Y.; Bianchi-Berthouze, N.; Oliveira, M.; Holloway, C.; Julier, S. NNose Heat: Exploring Stress-Induced Nasal Thermal Variability through Mobile Thermal Imaging. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; pp. 566–572. [Google Scholar]
- Ding, L.; Lv, Y.; Jiang, R.; Zhao, W.; Li, Q.; Yang, B.; Yu, L.; Ma, W.; Gao, R.; Yu, Q. Predicting the Feed Intake of Cattle Based on Jaw Movement Using a Triaxial Accelerometer. Agriculture 2022, 12, 899. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jiang, Z.; Zhao, L.; Li, S.; Jia, Y. Real-Time Object Detection Method Based on Improved YOLOv4-Tiny. arXiv 2020, arXiv:2011.04244. [Google Scholar]
- Guarnido-Lopez, P.; Ramirez-Agudelo, J.-F.; Denimal, E.; Benaouda, M. Programming and Setting Up the Object Detection Algorithm YOLO to Determine Feeding Activities of Beef Cattle: A Comparison between YOLOv8m and YOLOv10m. Animals 2024, 14, 2821. [Google Scholar] [CrossRef]
- Wang, J.; Zhai, Y.; Zhu, L.; Xu, L.; Yuan, H.; Maqbool, A. PD-YOLO: A study of daily behavioural detection in housed sheep. PLoS ONE 2024, 19, e0313412. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | #Training Images | #Validation Images | Annotation Type | Model (Backbone) | Batch Size | Learning Rate (Epochs) | Data Augmentation | Inference Speed |
|---|---|---|---|---|---|---|---|---|
| Head Detection | 1170 | 380 | Bounding Box | Mask R-CNN (ResNet-101) | 1 | 0.001 (100) | Rotation, Flipping | 5 FPS (640 × 480 pixel) |
| Left Ear Detection | 1210 | 400 |
| AFLW Landmarks (Human) | Cattle Head Landmarks | Mapping Type/Notes | |
|---|---|---|---|
| 1 | Left Brow Left Corner | Left Upper Mandible | Closest anatomical region |
| 2 | Left Brow Center | Left Eye Left Corner | Upper left eye region |
| 3 | Left Brow Right Corner | Left Eye Right Corner | Upper right eye region |
| 4 | Right Brow Left Corner | Right Eye Left Corner | Upper left of right eye |
| 5 | Right Brow Center | Right Eye Right Corner | Upper right of right eye |
| 6 | Right Brow Right Corner | Right Upper Mandible | Closest anatomical region |
| 7 | Left Eye Left Corner | Left Lower Mandible | Lower left eye region |
| 8 | Left Eye Center | Left Eye Right Lower Corner | Lower left of left eye |
| 9 | Left Eye Right Corner | Left Eye Right Lower Corner | Lower right of left eye |
| 10 | Right Eye Left Corner | Right Eye Left Lower Corner | Lower left of right eye |
| 11 | Right Eye Center | Right Eye Right Lower Corner | Lower right of right eye |
| 12 | Right Eye Right Corner | Right Lower Mandible | Lower right face region |
| 13 | Nose Left | Nose Left | 1:1 mapping |
| 14 | Nose Center | Nose Center | 1:1 mapping |
| 15 | Nose Right | Nose Right | 1:1 mapping |
| 16 | Mouth Left Corner | Mouth Left Corner | 1:1 mapping |
| 17 | Mouth Center | Mouth Center | 1:1 mapping |
| 18 | Mouth Right Corner | Mouth Right Corner | 1:1 mapping |
| 19 | Left Ear Lobe | Left Ear Root | Closest to ear base |
| 20 | Right Ear Lobe | Right Ear Root | Closest to ear base |
| 21 | Chin Center | Jaw | 1:1 mapping |
| Task | #Training Images | #Validation Images | Annotation Type | Model | Backbone | Batch Size | Learning Rate | Epochs | Inference Speed |
|---|---|---|---|---|---|---|---|---|---|
| Head Detection | 1225 | 400 | 3D Pose | FSA-Net | Capsule | 16 | 0.001 | 90 | 17.32 ms/image (64 × 64 pixel) |
| Left Ear Detection | 1140 | 380 |
| Testing Set | AFLW | Cow Head Pose Dataset | Cow Ear Pose Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | FSA-Net | ||||||||
| Aggregation | Capsule | ||||||||
| Pixelwise Scoring | w/o | 1 × 1 | var | w/o | 1 × 1 | var | w/o | 1 × 1 | var |
| MAE | 5.75 | 5.25 | 5.36 | 7.95 | 8.09 | 7.63 | 9.78 | 9.60 | 8.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S. Automated Cattle Head and Ear Pose Estimation Using Deep Learning for Animal Welfare Research. Vet. Sci. 2025, 12, 664. https://doi.org/10.3390/vetsci12070664
Kim S. Automated Cattle Head and Ear Pose Estimation Using Deep Learning for Animal Welfare Research. Veterinary Sciences. 2025; 12(7):664. https://doi.org/10.3390/vetsci12070664
Chicago/Turabian StyleKim, Sueun. 2025. "Automated Cattle Head and Ear Pose Estimation Using Deep Learning for Animal Welfare Research" Veterinary Sciences 12, no. 7: 664. https://doi.org/10.3390/vetsci12070664
APA StyleKim, S. (2025). Automated Cattle Head and Ear Pose Estimation Using Deep Learning for Animal Welfare Research. Veterinary Sciences, 12(7), 664. https://doi.org/10.3390/vetsci12070664