
Improving an Acoustic Vehicle Detector Using an Iterative Self-Supervision Procedure


Abstract
1. Introduction
1.1. Context
1.2. Problem Statement, Challenges, and Solution Overview
1.3. Related Work
1.4. Outline
2. Materials and Methods
2.1. Measurements and Signature Identification
2.2. Reference Classifier and Canonical Supervised Learning
2.3. Semi-/Self-Supervised Learning
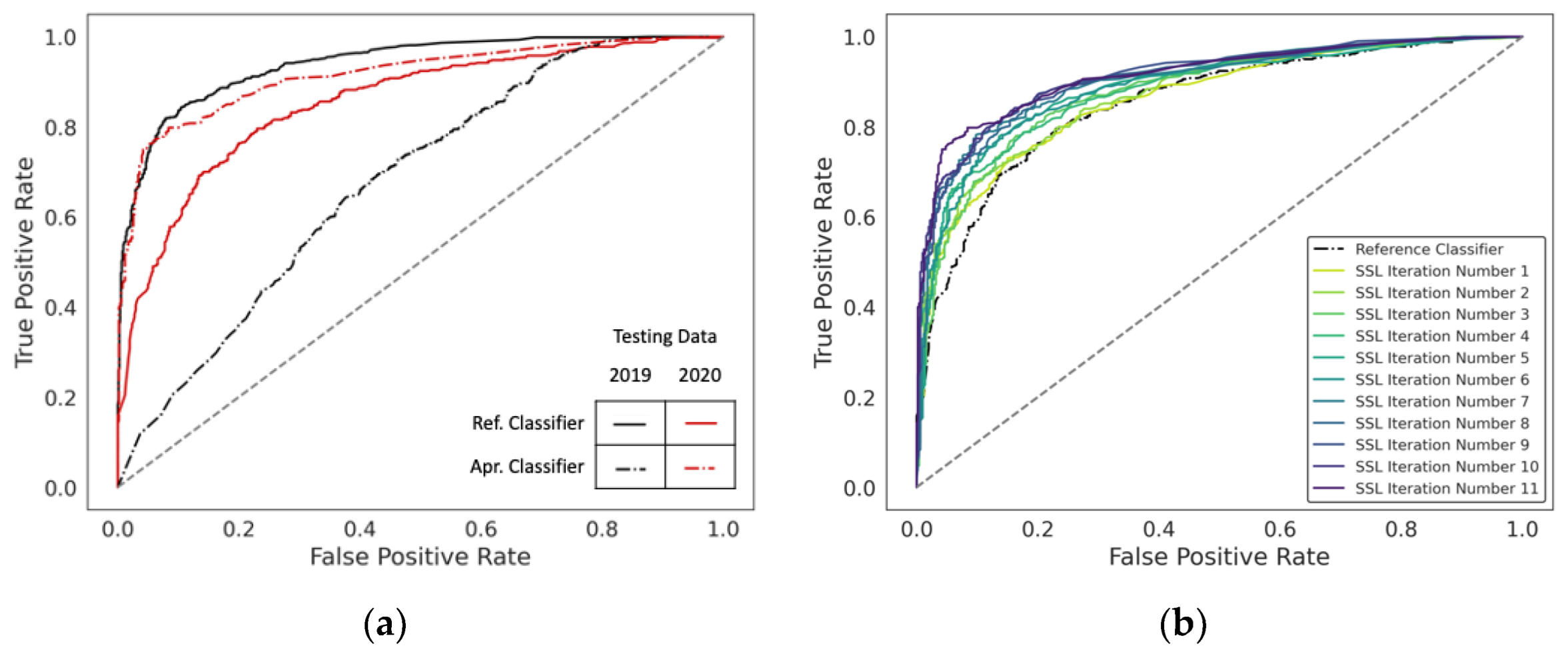
3. Results and Discussion
3.1. Self-Learning Validation
3.1.1. Recycle Method
3.1.2. Relabel Method
3.2. Extension to Unseen Data
3.2.1. Reference Classifier Training Dataset Retention
3.2.2. Pseudo-Labeled Background
3.2.3. Sensor Recalibration
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hite, J.; Dayman, K.; Rao, N.; Greulich, C.; Sen, S.; Chichester, D.; Nicholson, A.; Archer, D.; Willis, M.; Garishvili, I.; et al. Automated Vehicle Detection in a Nuclear Facility Using Low-Frequency Acoustic Sensors. In Proceedings of the 23rd International Conference on Information Fusion, Rustenburg, South Africa, 6–9 July 2020; pp. 1–6. [Google Scholar]
- Zou, T.; Sun, H.; Tian, X.; Zhang, E. Modeling A self-Learning detection engine automatically for IDS. In Proceedings of the IEEE International Conference on Robotics, Intelligent Systems and Signal Processing, Changsha, China, 8–13 October 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 1. [Google Scholar]
- Mao, J.; Yin, X.; Zhang, G.; Chen, B.; Chang, Y.; Chen, W.; Yu, J.; Wang, Y. Pseudo-Labeling Generative Adversarial Networks for Medical Image Classification. Comput. Biol. Med. 2022, 147, 105729. [Google Scholar] [CrossRef]
- Shi, X.; Jin, Y.; Dou, Q.; Heng, P.-A. Semi-supervised learning with progressive unlabeled data excavation for label-efficient surgical workflow recognition. Med. Image Anal. 2021, 73, 102158. [Google Scholar] [CrossRef]
- Alsafari, S.; Sadaoui, S. Semi-Supervised Self-Training of Hate and Offensive Speech from Social Media. Appl. Artif. Intell. 2021, 35, 1621–1645. [Google Scholar] [CrossRef]
- van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Cozman, F.G.; Cohen, I.; Cirelo, M. Unlabeled Data Can Degrade Classification Performance of Generative Classifiers. In Proceedings of the Fifteenth International Florida Artificial Intelligence Research Society Conference, Pensacola Beach, FL, USA, 14–16 May 2002; pp. 327–331. [Google Scholar]
- Han, L.; Ye, H.J.; Zhan, D.C. On Pseudo-Labeling for Class-Mismatch Semi-Supervised Learning. arXiv 2023, arXiv:2301.06010. [Google Scholar]
- Portnoff, M.R. Time-Frequency Representation of Digital Signals. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 55–69. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Galstyan, A.; Cohen, P.R. Empirical comparison of ‘hard’ and ‘soft’ label propagation for relational classification. In Inductive Logic Programming: 17th International Conference, ILP 2007, Corvallis, OR, USA, 19–21 June 2007, Revised Selected Papers 17; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4894, pp. 98–111. [Google Scholar]
- Cohen, I.; Goldszmidt, M. Properties and benefits of calibrated classifiers. In Knowledge Discovery in Databases: PKDD 2004, 8th European Conference on Principles and Practice of Knowledge Discovery in Databases, Pisa, Italy, 20–24 September 2004; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3202, pp. 125–136. [Google Scholar]
- De Vito, S.; Fattoruso, G.; Pardo, M.; Tortorella, F.; Di Francia, G. Semi-Supervised Learning Techniques in Artificial Olfaction: A Novel Approach to Classification Problems and Drift Counteraction. IEEE Sens. J. 2012, 12, 3215–3224. [Google Scholar] [CrossRef]
- Liu, Q.; Li, X.; Ye, M.; Ge, S.S.; Du, X. Drift Compensation for Electronic Nose by Semi-Supervised Domain Adaption. IEEE Sens. J. 2013, 14, 657–665. [Google Scholar] [CrossRef]
- Liu, T.; Li, D.; Chen, J.; Chen, Y.; Yang, T.; Cao, J. Gas-Sensor Drift Counteraction with Adaptive Active Learning for an Electronic Nose. Sensors 2018, 18, 4028. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Subakan, C.; Ravanelli, M.; Cornell, S.; Bronzi, M.; Zhong, J. Attention is all you need in speech separation. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 21–25. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Sensor | ||
|---|---|---|---|
| Training Data | Friday | 15 November 2019 | A |
| Friday | 20 December 2019 | B | |
| Thursday | 14 November 2019 | A | |
| Friday | 3 January 2020 | B | |
| Testing Data | Tuesday | 17 December 2019 | B |
| Audio File | Pseudo-Label Source | ||
|---|---|---|---|
| Date (Sensor) | Recycle | Relabel | |
| Dataset 1 | 15 November 2019 (A) | Reference Classifier | Reference Classifier |
| Dataset 2 | 15 November 2019 (A) | Reference Classifier | Classifier 1 |
| 20 December 2019 (B) | Classifier 1 | ||
| Dataset 3 | 15 November 2019 (A) | Reference Classifier | Classifier 2 |
| 20 December 2019 (B) | Classifier 1 | ||
| 14 November 2019 (A) | Classifier 2 | ||
| Dataset 4 | 15 November 2019 (A) | Reference Classifier | Classifier 3 |
| 20 December 2019 (B) | Classifier 1 | ||
| 14 November 2019 (A) | Classifier 2 | ||
| 3 January 2020 (B) | Classifier 3 | ||
| Probability of Overriding Trained Classifier Output | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0.00 | 0.05 | 0.10 | 0.15 | 0.20 | 0.25 | 0.50 | ||
| AUROC | Dataset 1 | 0.6676 | 0.6422 | 0.6308 | 0.6002 | 0.5891 | 0.5559 | 0.4912 |
| Dataset 2 | 0.7430 | 0.6602 | 0.5940 | 0.5574 | 0.4788 | 0.4844 | 0.3660 | |
| Dataset 3 | 0.8447 | 0.8005 | 0.7120 | 0.7420 | 0.5961 | 0.6178 | 0.4843 | |
| Dataset 4 | 0.8983 | 0.8789 | 0.8023 | 0.8185 | 0.7007 | 0.7304 | 0.5579 | |
| Total Samples | Dataset 1 | 152 | 456 | 458 | 434 | 450 | 440 | 460 |
| Dataset 2 | 590 | 672 | 816 | 880 | 824 | 822 | 898 | |
| Dataset 3 | 906 | 1018 | 1.174 | 1218 | 1200 | 1194 | 1222 | |
| Dataset 4 | 1160 | 1368 | 1508 | 1500 | 1472 | 1544 | 1500 | |
| Probability of Overriding Trained Classifier Output | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0.00 | 0.05 | 0.10 | 0.15 | 0.20 | 0.25 | 0.50 | ||
| AUROC | Dataset 1 | 0.6676 | 0.6422 | 0.6308 | 0.6002 | 0.5891 | 0.5559 | 0.4912 |
| Dataset 2 | 0.5893 | 0.7412 | 0.5489 | 0.7285 | 0.5163 | 0.5533 | 0.3581 | |
| Dataset 3 | 0.7877 | 0.8267 | 0.8060 | 0.8611 | 0.8096 | 0.7848 | 0.4151 | |
| Dataset 4 | 0.8815 | 0.8856 | 0.9165 | 0.9038 | 0.8669 | 0.8781 | 0.4257 | |
| Total Samples | Dataset 1 | 152 | 456 | 458 | 434 | 450 | 440 | 460 |
| Dataset 2 | 544 | 546 | 776 | 892 | 758 | 738 | 812 | |
| Dataset 3 | 742 | 558 | 620 | 798 | 730 | 700 | 798 | |
| Dataset 4 | 988 | 858 | 856 | 946 | 962 | 996 | 984 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Phathanapirom, B.; Hite, J.; Dayman, K.; Chichester, D.; Johnson, J. Improving an Acoustic Vehicle Detector Using an Iterative Self-Supervision Procedure. Data 2023, 8, 64. https://doi.org/10.3390/data8040064
Phathanapirom B, Hite J, Dayman K, Chichester D, Johnson J. Improving an Acoustic Vehicle Detector Using an Iterative Self-Supervision Procedure. Data. 2023; 8(4):64. https://doi.org/10.3390/data8040064
Chicago/Turabian StylePhathanapirom, Birdy, Jason Hite, Kenneth Dayman, David Chichester, and Jared Johnson. 2023. "Improving an Acoustic Vehicle Detector Using an Iterative Self-Supervision Procedure" Data 8, no. 4: 64. https://doi.org/10.3390/data8040064
APA StylePhathanapirom, B., Hite, J., Dayman, K., Chichester, D., & Johnson, J. (2023). Improving an Acoustic Vehicle Detector Using an Iterative Self-Supervision Procedure. Data, 8(4), 64. https://doi.org/10.3390/data8040064