
Digital Twins: A Systematic Literature Review Based on Data Analysis and Topic Modeling


Abstract
1. Introduction
- Is the digital twin a mature topic with established ‘schools of thought’ and approaches, or is it still a new topic and a kind of marketing label with a vague background?
- The analysis has revealed some ambiguity in the co-occurrence of keywords, i.e., this co-occurrence seems random in some cases. Are there any clear mainstream themes on this topic?
- Some researchers think machine learning is the future trend for digital-twin studies. What are the future trends in the development of the topic?
2. Related Literature
2.1. Digital Twin Literature Reviews
- Health Analysis and maintenance activities (deformation, anomalies, fatigue, etc.).
- Digital mirrors of the life of the physical entity.
- Decision support through engineering and statistical analysis [4].
2.2. Digital Twin Literature Meta-Reviews
- Physical entities, physical twin.
- Data generation.
- Network, connectivity.
- Data storage and integration.
- Data preparation and representation.
- Data model, algorithms, a virtual entity, virtual twin.
- Micro-services, deployment.
- System security, data privacy.
- Business model, processes [5].
- Data infrastructure.
- Modeling and simulation.
- Implementation.
- Privacy, security, and legal issues.
- Concept standardization.
- Clarification of benefits.
- Digital twin and human interaction [6].
2.3. Bibliometric Tools in Digital Twin Literature Research
- Industry 4.0, smart factory, big data, industrial internet of things, artificial intelligence.
- Cyber-physical systems, machine learning, simulation, virtual factory.
- Digital thread, virtualization, Product Lifecycle Management, modeling.
- Internet of things, AR/VR, digital shadow [8].
- Information monitoring model (1985–2002).
- Digital simulation (2003–2014).
- Implementation of IoT devices (2014–2016).
- Use of decision-making tools (2017–present).
- Existing literature discusses using digital twins for the entire process or plant.
- There is no literature on multi-domain models describing numerical and mathematical modeling for system monitoring and optimization.
- While some studies apply machine-learning algorithms, they are often not validated by simulations and mathematical models [9].
3. Materials and Methods
3.1. Materials
3.2. Methods
3.2.1. Text Mining
- Information is collected from unstructured data.
- Information is transformed into structured data (text is cleaned, words are tokenized, and stop words are filtered out).
- Patterns/themes are identified in the structured text.
- The pattern/topic is analyzed.
- Valuable information is extracted (e.g., visualized or stored in the database) [11].
3.2.2. Topic Analysis: Machine Learning
3.2.3. Stages of the Study
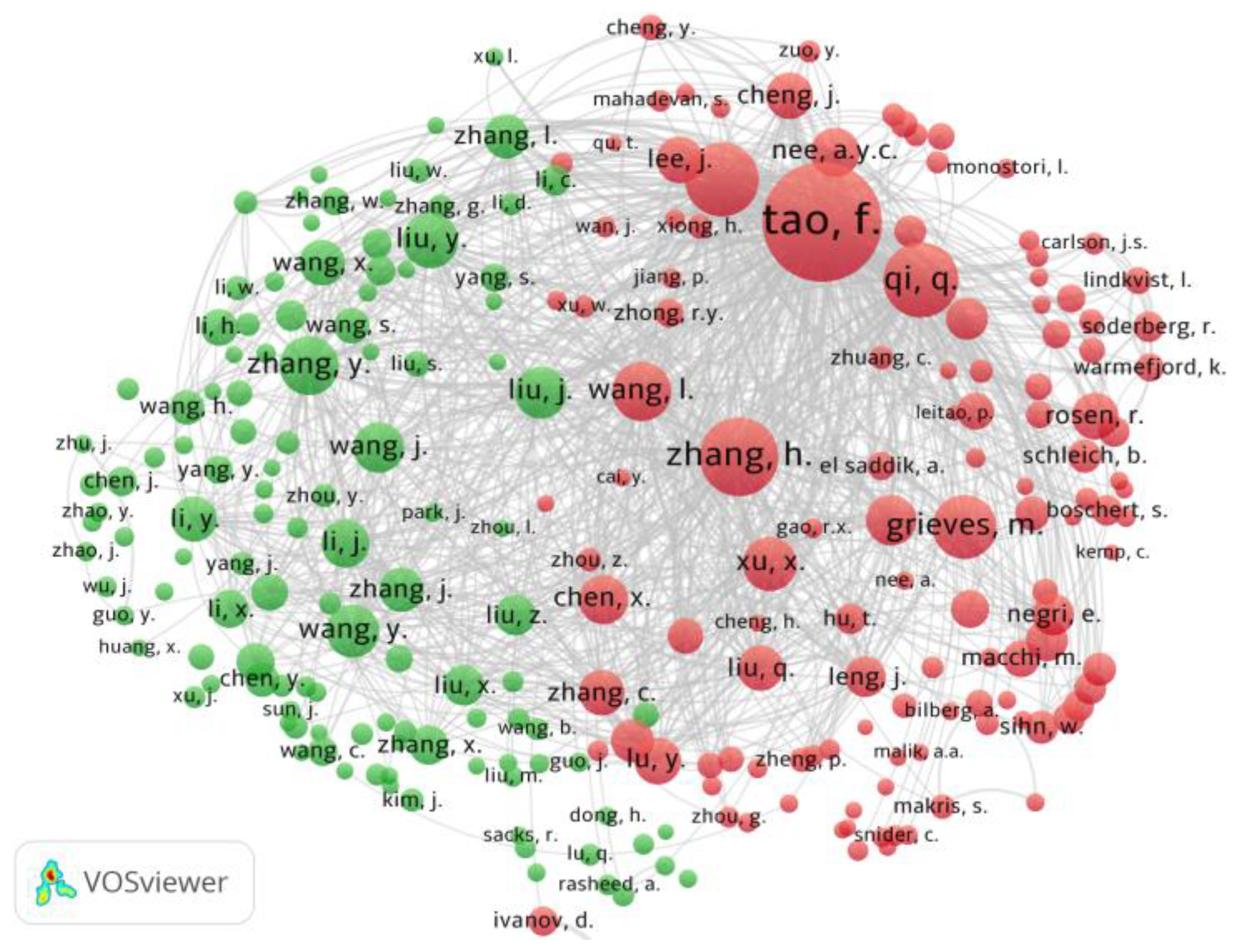
- Dataset was uploaded to the Jupyter Notebook; the number of publications per year was calculated, the co-authors were analyzed, and the most-cited authors and the most-cited publications were identified.
- Analysis of the keywords of the publications:
- The author’s keywords were normalized. This step helps avoid double counting of a keyword in different spellings. For example, ‘digital twin’ can be referred to as ‘dt’, ‘digital twins’, ‘digital-twin’, etc. Normalization means that all spellings of a keyword are renamed to the spelling that will be used for the analysis.
- The occurrences of the author’s keywords were counted.
- The co-occurrences of the author’s keywords were counted.
- A graph of the co-occurrence of keywords was constructed.
- Analysis of abstracts of publications:
- Stop words and punctuation marks were removed from the text.
- The abstract text was tokenized/decomposed into bigrams.
- The occurrences of individual words in the abstracts were counted.
- The most frequently occurring bigrams were identified.
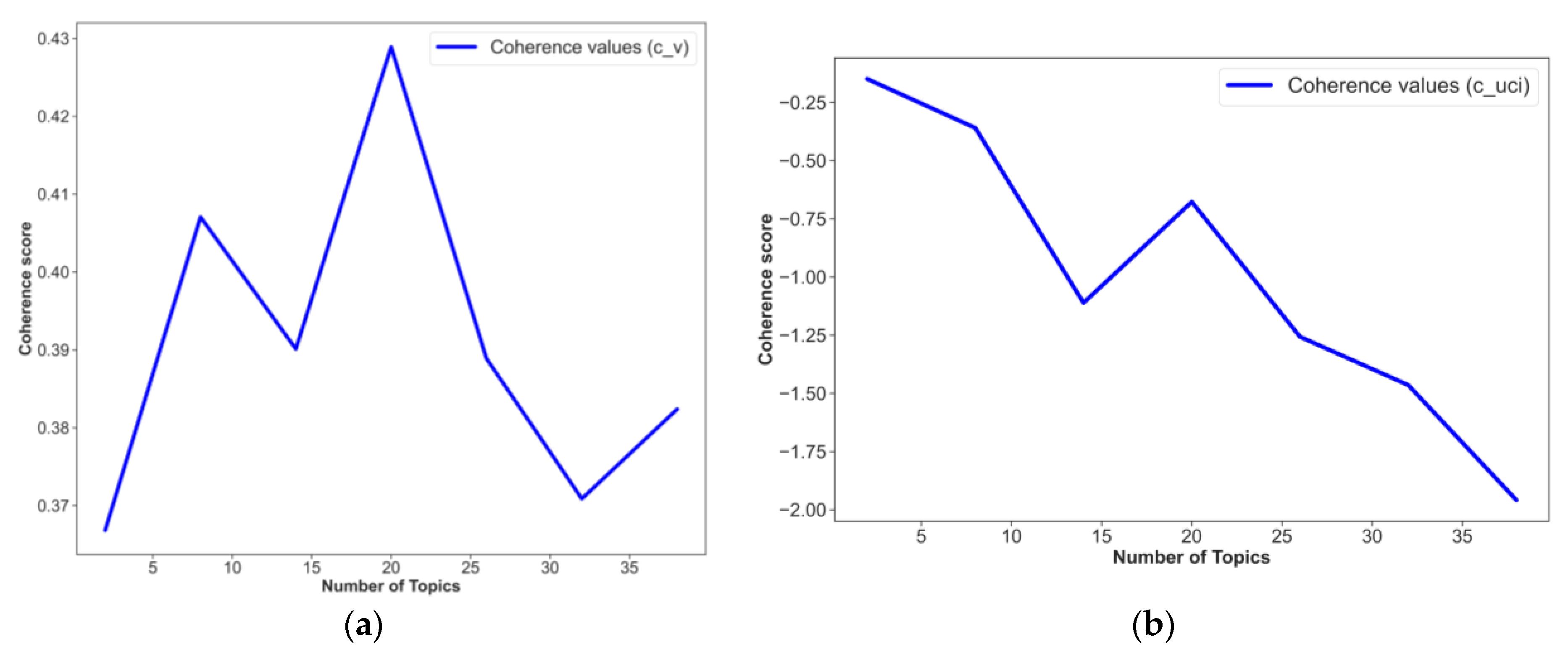
- The GenSim model was trained for LDA analysis, and the key topics were identified in the abstracts.
- The BERTopic model was trained, and the obtained results were visualized.
4. Stage I
5. Stage II
6. Stage III
6.1. Comparison of LDA and BERTopic Models
6.2. The LDA Model
- Topic 10. Business digital transformation (1354 articles).
- Topic 15. Physical processes (689 articles).
- Topic 6. Tests and software testing (531 articles).
- Topic 14. Internet of things and cloud services (488 articles).
- Topic 9. New materials and modeling (468 articles).
- Topic 17. Manufacturing processes (463 articles).
- Topic 13. Networks, communication and computing (368 articles).
- Topic 11. Structural-damage analysis and monitoring (324 articles).
- Topic 5. Engine- and machining-failure prediction (308 articles).
- Topic 1. Cities and infrastructure (304 articles).
- Topic 7. Robots (300 articles).
- Topic 12. Logistics and service (231 articles).
- Topic 3. Metaverse and virtual reality (198 articles).
6.3. The BERTopic Model
- Robots and virtual reality (keywords: robot, robots, robotic, human, assembly). 283 articles. Many publications deal with digital twins of assembly lines or factory floors in the virtual- and augmented-reality format. Examples of publications on this topic include: using digital-twin technologies to improve the quality and efficiency of robotic assemblies [35], training the digital twin of a robot in a virtual environment to reduce the training time of the real robot [36], and using the digital twin of an agricultural robot that receives information from the physical twin [37].
- Digital twin (keywords: digit3al, twins, digital twins, twin, digital twin). 257 articles. This topic is devoted to the conceptual study of digital twins. In particular, this category includes reviews that deal with the analysis of existing concepts and definitions of digital twins, the applications of digital twins in the context of the sustainable-production paradigm [38], and the framework and analysis of successful practices to implement digital twins [33].
- Construction and BIM technologies (keywords: construction, BIM, building, information, management). 239 articles. Creating digital twins of construction objects in the design phase and digital shadows of existing buildings makes it possible to optimize financial costs and shorten the construction cycle. Publications on this topic address possible approaches to integrating physical and digital twins throughout the construction process by including the third component, i.e., the social network, in these models [34]; an analysis is presented for the cases where a digital twin is used to automate construction processes [39].
- Energy and power (keywords: power, grid, energy, power grid, distribution). 175 articles. Digital twins can be used to model their processes and objects and digital shadows. Articles on digital twins in power grids and energy distribution are devoted to the digital twins of energy facilities, e.g., the digital twin of a transformer [40] and the digital twin of electric grids [41].
- Machining (keywords: machining, cutting, tool, process, grinding). 161 articles. Publications on digital twins of manufacturing equipment used for machining parts. Publications on this topic deal with digital twins of CNC cutting technologies [42], digital twins for grinding with abrasive belts [43], and digital twins for CNC plunge-cut grinding [44].
- Ships and shipbuilding (keywords: ship, vessels, machine, vessels). 139 articles. Key topics in this cluster include marine engines (development of “the generic procedure for the creation and usage of a complete system simulation for propulsion systems of ships with a focus on complex hybrid systems” [48]), the role of digital twins in shipbuilding and the benefits of this technology [49], the use of sensors in a research vessel to obtain data on its operation (“ship as an ideal platform from which to explore a definitive trend in the future marine industry: digital twin technology. This is a digital real-time in-context operational mime of an asset, which connects the digital and real word representations towards actionable insights” [50]).
- Structural damage and fatigue testing (keywords: fatigue, crack, damage, structural, crack growth). 133 articles. Key topics in this cluster include structural-health-monitoring systems using digital-twin technologies [51], damage prediction and modeling under creep conditions [52], development of a crack-growth algorithm using an airframe digital twin [53].
6.4. Comparison of LDA and BERTopic Analysis Results
6.4.1. Comparison of Model Performance Based on Unsupervised Clustering
- Uniform manifold approximation and projection, or UMAP, which creates a high-dimensional graph and then converts it to a low-dimensional one that should be structurally similar to the first one [56].
- Principal component analysis, or PCA, which reduces a large set of variables to a smaller set.
- The t-distributed stochastic neighbor embedding, or the t-SNE technique, transforms high-dimensional vectors into lower dimensional vectors, and preserves the relative similarity to the original [55].
6.4.2. Comparison of the Models Based on Topics Interpretation
- Robotics and robots (1_Robot_robots_robotic_human (BERTopic)/Topic 7. Robot, reality, robots, robotic, space (LDA).
- Cities and infrastructure (13_City_urban_cities_smart (BERTopic)/Topic 1. Energy, city, urban, scheduling, battery (LDA)).
- Machining and engines (5_Machining_cutting_tool_process (BERTopic)/Topic 5. Machining, engine, prediction, tool, crack (LDA)).
- Bridges and structural damage (17_Bridge_structural_bridges_monitoring (BERTopic)/Topic 11. Structural, damage, health, sensor, bridge (LDA)).
7. Conclusions
8. Future Research
- Do the results of topic modeling performed on a dataset of publication abstracts on the topic of digital twins match those of a dataset of full-text publications? Clearly, the larger the dataset used to train the machine model, the more accurate the analysis results, including predictions for the topics of new publications.
- To what extent does the automation of topic analysis in publications enable the preservation of the nuances of the text, i.e., the detection of all possible topics mentioned? As for the LDA model, in general, it is impossible to clearly separate the topics of the texts (one text can be assigned to several topics); moreover, it is difficult to interpret the results. The advantage of the BERTopic model is that the text can be assigned to only one topic; other topics of the source text are lost in this case, but the results are easier to interpret.
- Are there better topic-modeling techniques that can produce more accurate results? For example, several authors use a combination of the LDA model and BERTopic embeddings. According to their analysis, this mixed method is better than the LDA or BERTopic used individually [55,57,58]. Although finding the best method for topic modeling was not one of the goals of this paper, finding the best method for topic modeling can be a goal for future research.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Grieves, M.; Vickers, J. Digital Twin: Mitigating Unpredictable, Undesirable Emergent Behavior in Complex Systems. In Transdisciplinary Perspectives on Complex Systems; Kahlen, F.-J., Flumerfelt, S., Alves, A., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 85–113. ISBN 978-3-319-38754-3. [Google Scholar]
- Google Books Ngram Viewer. Available online: https://books.google.com/ngrams/graph?content=digital+twin&year_start=2010&year_end=2019&corpus=26&smoothing=3&direct_url=t1%3B%2Cdigital%20twin%3B%2Cc0 (accessed on 27 July 2022).
- Kritzinger, W.; Karner, M.; Traar, G.; Henjes, J.; Sihn, W. Digital Twin in Manufacturing: A Categorical Literature Review and Classification. IFAC-Pap. 2018, 51, 1016–1022. [Google Scholar] [CrossRef]
- Negri, E.; Fumagalli, L.; Macchi, M. A Review of the Roles of Digital Twin in CPS-Based Production Systems. Procedia Manuf. 2017, 11, 939–948. [Google Scholar] [CrossRef]
- Rossmann, A.; Hertweck, D. Digital Twins: A Meta-Review on Their Conceptualization, Application, and Reference Architecture. In Proceedings of the 55th Hawaii International Conference on System Sciences, Maui, HI, USA, 4 January 2022. [Google Scholar]
- Kuehner, K.; Scheer, R.; Straßburger, S. Digital Twin: Finding Common Ground—A Meta-Review. Procedia CIRP 2021, 104, 1227–1232. [Google Scholar] [CrossRef]
- Mejia, C.; Wu, M.; Zhang, Y.; Kajikawa, Y. Exploring Topics in Bibliometric Research Through Citation Networks and Semantic Analysis. Front. Res. Metr. Anal. 2021, 6, 742311. [Google Scholar] [CrossRef] [PubMed]
- Borovkov, A.I.; Gamzikova, A.A.; Kukushkin, K.V.; Ryabov, Y.A. Digital Twins in the High-Technology Manufacturing Industry. A Preliminary Research Report (September 2019); POLYTECH-PRESS: St. Petersburg, Russia, 2019; ISBN 978-5-7422-6922-9. (In Russian) [Google Scholar]
- Warke, V.; Kumar, S.; Bongale, A.; Kotecha, K. Sustainable Development of Smart Manufacturing Driven by the Digital Twin Framework: A Statistical Analysis. Sustainability 2021, 13, 10139. [Google Scholar] [CrossRef]
- Scopus—Document Search|Signed in. Available online: https://www.scopus.com/search/form.uri?display=basic#basic (accessed on 6 July 2022).
- Dang, S. Text Mining: Techniques and Its Application. Int. J. Eng. Technol. Innnovation 2014, 1, 22–25. [Google Scholar]
- Talib, R.; Kashif, M.; Ayesha, S.; Fatima, F. Text Mining: Techniques, Applications and Issues. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 20–25. [Google Scholar] [CrossRef]
- Zdonek, I. The Role of Word and N-Gram Frequency Analysis 2 in Inference of the Content of Scientific Publication. Sci. Pap. Silesian Univ. Technol. Organ. Manag. Ser. 2020, 2020, 21–31. [Google Scholar] [CrossRef]
- Gensim. Topic Modelling for Humans. Available online: https://radimrehurek.com/gensim/ (accessed on 28 July 2022).
- Campbell, J.C.; Hindle, A.; Stroulia, E. Latent Dirichlet Allocation. In The Art and Science of Analyzing Software Data; Elsevier: Amsterdam, The Netherlands, 2015; pp. 139–159. ISBN 978-0-12-411519-4. [Google Scholar]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet Allocation (LDA) and Topic Modeling: Models, Applications, a Survey. Multimed. Tools Appl. 2017, 78, 15169–15211. [Google Scholar] [CrossRef]
- Using BERT embeddings for Text Modeling (in Russian). Available online: https://habr.com/ru/post/653443/ (accessed on 6 July 2022).
- Grootendorst, M. BERTopic. Available online: https://github.com/MaartenGr/BERTopic (accessed on 6 July 2022).
- Grootendorst, M. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar] [CrossRef]
- Egger, R.; Yu, J. A Topic Modeling Comparison Between LDA, NMF, Top2Vec, and BERTopic to Demystify Twitter Posts. Front. Sociol. 2022, 7, 886498. [Google Scholar] [CrossRef] [PubMed]
- Tao, F.; Cheng, J.; Qi, Q.; Zhang, M.; Zhang, H.; Sui, F. Digital Twin-Driven Product Design, Manufacturing and Service with Big Data. Int. J. Adv. Manuf. Technol. 2018, 94, 3563–3576. [Google Scholar] [CrossRef]
- Ivanov, D. Predicting the Impacts of Epidemic Outbreaks on Global Supply Chains: A Simulation-Based Analysis on the Coronavirus Outbreak (COVID-19/SARS-CoV-2) Case. Transp. Res. Part E Logist. Transp. Rev. 2020, 136, 101922. [Google Scholar] [CrossRef] [PubMed]
- Tao, F.; Zhang, H.; Liu, A.; Nee, A.Y.C. Digital Twin in Industry: State-of-the-Art. IEEE Trans. Ind. Inform. 2019, 15, 2405–2415. [Google Scholar] [CrossRef]
- Perianes-Rodriguez, A.; Waltman, L.; van Eck, N.J. Constructing Bibliometric Networks: A Comparison between Full and Fractional Counting. J. Informetr. 2016, 10, 1178–1195. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, M.; Nee, A.Y.C. Digital Twin Driven Smart Manufacturing; Academic Press: Cambridge, MA, USA, 2019; ISBN 978-0-12-817631-3. [Google Scholar]
- Lu, Y.; Min, Q.; Liu, Z.; Wang, Y. An IoT-Enabled Simulation Approach for Process Planning and Analysis: A Case from Engine Re-Manufacturing Industry. Int. J. Comput. Integr. Manuf. 2019, 32, 413–429. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, H.; Liu, X.; Tian, G.; Wu, M.; Cao, L.; Wang, W. Dynamic Evaluation Method of Machining Process Planning Based on Digital Twin. IEEE Access 2019, 7, 19312–19323. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, X.; Liu, A. Digital Twin-Driven Analysis of Design Constraints. Procedia CIRP 2020, 91, 716–721. [Google Scholar] [CrossRef]
- Rosen, R.; von Wichert, G.; Lo, G.; Bettenhausen, K.D. About The Importance of Autonomy and Digital Twins for the Future of Manufacturing. IFAC-Pap. 2015, 48, 567–572. [Google Scholar] [CrossRef]
- Söderberg, R.; Wärmefjord, K.; Carlson, J.S.; Lindkvist, L. Toward a Digital Twin for Real-Time Geometry Assurance in Individualized Production. CIRP Ann. 2017, 66, 137–140. [Google Scholar] [CrossRef]
- Schleich, B.; Anwer, N.; Mathieu, L.; Wartzack, S. Shaping the Digital Twin for Design and Production Engineering. CIRP Ann. 2017, 66, 141–144. [Google Scholar] [CrossRef]
- Tuegel, E.J.; Ingraffea, A.R.; Eason, T.G.; Spottswood, S.M. Reengineering Aircraft Structural Life Prediction Using a Digital Twin. Int. J. Aerosp. Eng. 2011, 2011, 154798. [Google Scholar] [CrossRef]
- Sivarethinamohan, R.; Sujatha, S. Reimagining the Digital Twin: Powerful Use Cases for Industry 4.0. In Advances in Mechanical Engineering; Manik, G., Kalia, S., Sahoo, S.K., Sharma, T.K., Verma, O.P., Eds.; Lecture Notes in Mechanical Engineering; Springer: Singapore, 2021; pp. 175–182. ISBN 9789811609411. [Google Scholar]
- Turk, Ž.; Klinc, R. A Social–Product–Process Framework for Construction. Build. Res. Inf. 2020, 48, 747–762. [Google Scholar] [CrossRef]
- Li, X.; He, B.; Zhou, Y.; Li, G. Multisource Model-Driven Digital Twin System of Robotic Assembly. IEEE Syst. J. 2021, 15, 114–123. [Google Scholar] [CrossRef]
- Hassel, T.; Hofmann, O. Reinforcement Learning of Robot Behavior Based on a Digital Twin. In Proceedings of the 9th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2020), Valletta, Malta, 4 July 2022; pp. 381–386. [Google Scholar]
- Lumer-Klabbers, G.; Hausted, J.O.; Kvistgaard, J.L.; Macedo, H.D.; Frasheri, M.; Larsen, P.G. Towards a Digital Twin Framework for Autonomous Robots. In Proceedings of the 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 12–16 July 2021; pp. 1254–1259. [Google Scholar]
- Ball, P.; Badakhshan, E. Sustainable Manufacturing Digital Twins: A Review of Development and Application. In Sustainable Design and Manufacturing; Scholz, S.G., Howlett, R.J., Setchi, R., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 262, pp. 159–168. ISBN 9789811661273. [Google Scholar]
- Al-Saeed, Y.; Edwards, D.J.; Scaysbrook, S. Automating Construction Manufacturing Procedures Using BIM Digital Objects (BDOs): Case Study of Knowledge Transfer Partnership Project in UK. Constr. Innov. 2020, 20, 345–377. [Google Scholar] [CrossRef]
- Delong, Z.; Zhijun, Y.; Huipeng, C.; Peng, Z.; Jiliang, L. Research on Digital Twin Model and Visualization of Power Transformer. In Proceedings of the 2021 IEEE International Conference on Networking, Sensing and Control (ICNSC), Xiamen, China, 3–5 December 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2021. [Google Scholar]
- Zolin, D.S.; Ryzhkova, E.N. Digital Twins for Electric Grids. In Proceedings of the 2020 International Russian Automation Conference (RusAutoCon), Sochi, Russia, 6–12 September 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 175–180. [Google Scholar]
- Ward, R.; Sun, C.; Dominguez-Caballero, J.; Ojo, S.; Ayvar-Soberanis, S.; Curtis, D.; Ozturk, E. Machining Digital Twin Using Real-Time Model-Based Simulations and Lookahead Function for Closed Loop Machining Control. Int. J. Adv. Manuf. Technol. 2021, 117, 3615–3629. [Google Scholar] [CrossRef]
- Wang, Y.-H.; Lo, Y.-C.; Lin, P.-C. A Normal Force Estimation Model for a Robotic Belt-Grinding System. In Proceedings of the 2020 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Boston, MA, USA, 6–9 July 2020; IEEE: Boston, MA, USA, 2020; pp. 1922–1928. [Google Scholar]
- Akintseva, A.V.; Pereverzev, P.P.; Omel’chenko, S.V.; Kopyrkin, A.A. Digital Twins and Multifactorial Visualization of Shaping in CNC Plunge-Cut Grinding. Russ. Eng. Res. 2021, 41, 671–675. [Google Scholar] [CrossRef]
- Gaebel, J.; Keller, J.; Schneider, D.; Lindenmeyer, A.; Neumuth, T.; Franke, S. The Digital Twin: Modular Model-Based Approach to Personalized Medicine. Curr. Dir. Biomed. Eng. 2021, 7, 223–226. [Google Scholar] [CrossRef]
- Boulos, M.K.; Zhang, P. Digital Twins: From Personalised Medicine to Precision Public Health. J. Pers. Med. 2021, 11, 745. [Google Scholar] [CrossRef]
- De Maeyer, C.; Markopoulos, P. Future Outlook on the Materialisation, Expectations and Implementation of Digital Twins in Healthcare. In Proceedings of the 34th British HCI Conference, London, UK, 20–21 July 2021; BCS Learning and Development Ltd.: Swindon, UK, 2021; pp. 180–191. [Google Scholar]
- Jannsen, L.-E. Development of a Simulation Environment for Hybrid Propulsion Drive Trains: Utilization of a Holistic Approach to Predict the Dynamic Behavior in the Early Design Stage. In Proceedings of the Volume 1: Offshore Technology, Online, 3–7 August 2020; American Society of Mechanical Engineers: New York, NY, USA, 2020; p. V001T01A027. [Google Scholar]
- Morais, D.; Goulanian, G.; Danese, N. The Future Reality of the Digital Twin as a Cross-Enterprise Marine Asset. In Proceedings of the 19th International Conference on Computer Applications in Shipbuilding 2019, Rotterdam, The Netherlands, 24–26 September 2019; The Royal Institution of Naval Architects: London, UK, 2019; Volume 2. [Google Scholar]
- Bekker, A. Exploring the Blue Skies Potential of Digital Twin Technology for a Polar Supply and Research Vessel. In Proceedings of the 13th International Marine Design Conference Marine Design XIII (IMDC 2018), Helsinki, Finland, 10–14 June 2018; CRC Press: Boca Raton, FL, USA, 2018; Volume 1, pp. 135–146. [Google Scholar]
- Loghin, A.; Ismonov, S. Assessment of Crack Path Uncertainly Using 3d Fea and Response Surface Modeling. In Proceedings of the AIAA Scitech Forum, Orlando, FL, USA, 6–10 January 2020; American Institute of Aeronautics and Astronautics Inc.: Reston, VA, USA, 2020; Volume 1. Part F. [Google Scholar]
- Wang, K.; Wang, X.; Wen, J.; Zhang, X.; Gong, J.; Tu, S. Creep Rupture: From Physical Failure Mechanisms to Lifetime Prediction of Structures. Jixie Gongcheng Xuebao J. Mech. Eng. 2021, 57, 132–152. [Google Scholar] [CrossRef]
- Ocampo, J.; Millwater, H.; Crosby, N.; Gamble, B.; Hurst, C.; Reyer, M.; Mottaghi, S.; Nuss, M. An Ultrafast Crack Growth Lifing Model to Support Digital Twin, Virtual Testing, and Probabilistic Damage Tolerance Applications. In ICAF 2019—Structural Integrity in the Age of Additive Manufacturing; Niepokolczycki, A., Komorowski, J., Eds.; Lecture Notes in Mechanical Engineering; Springer International Publishing: Cham, Switzerland, 2020; pp. 145–158. ISBN 978-3-030-21502-6. [Google Scholar]
- Robinson, D. Is LDA Topic Modeling Dead? Available online: https://towardsdatascience.com/is-lda-topic-modeling-dead-9543c18488fa (accessed on 20 November 2022).
- George, L.; Sumathy, P. An Integrated Clustering and BERT Framework for Improved Topic Modeling. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Understanding UMAP. Available online: https://pair-code.github.io/understanding-umap/ (accessed on 20 November 2022).
- Atagun, E.; Hartoka, B.; Albayrak, A. Topic Modeling Using LDA and BERT Techniques: Teknofest Example. In Proceedings of the 2021 6th International Conference on Computer Science and Engineering (UBMK), Ankara, Turkey, 15–17 September 2021; IEEE: Ankara, Turkey, 2021; pp. 660–664. [Google Scholar]
- Shao, S. Contextual Topic Identification. Available online: https://blog.insightdatascience.com/contextual-topic-identification-4291d256a032 (accessed on 20 November 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| № of Column | Column | Content |
|---|---|---|
| 0 | Authors | Names of the authors |
| 2 | Title | Title of the publication |
| 3 | Year | Year of publication |
| 12 | Cited by | Number of citations |
| 17 | Abstract | Abstract of the article |
| 18 | Author Keywords | Keywords used by authors of an article |
| № | Article Name | Number of Citations |
|---|---|---|
| 1 | Fei Tao, Jiangfeng Cheng, Qinglin Qi, Meng Zhang, He Zhang, Fangyuan Sui ‘Digital twin-driven product design, manufacturing and service with big data’ [21] | 1147 |
| 2 | Dmitry Ivanov ‘Predicting the impacts of epidemic outbreaks on global supply chains: A simulation-based analysis on the coronavirus outbreak (COVID-19/SARS-CoV-2) case’ [22] | 772 |
| 3 | Werner Kritzinger, Matthias Karner, Georg Traar, Jan Henjes, Wilfried Sihn ‘Digital twin in manufacturing: a categorical literature review and classification’ [3] | 736 |
| 4 | Fei Tao, He Zhang, Ang Liu, Andrew Yeh-Ching Nee ‘Digital Twin in Industry: State-of-the-Art’ [23] | 728 |
| 5 | Michael Grieves, John Vickers ‘Digital Twin: Mitigating Unpredictable, Undesirable Emergent Behavior in Complex Systems’ [1] | 708 |
| Topic Name and Number | Number of Articles by Dominant Topic |
|---|---|
| Topic 10. Transformation, intelligence, companies, solutions, technological | 1354 |
| Topic 2. Human, construction, BIM, safety, robot | 690 |
| Topic 15. Thermal, temperature, power, flow, experimental | 689 |
| Topic 6. Test, planning, methodology, solution, flexible | 531 |
| Topic 14. IoT, cloud, CPS, knowledge, services | 488 |
| Topic 9. Material, properties, measurements, materials, element | 468 |
| Topic 17. Equipment, assembly, fault, line, workshop | 463 |
| Topic 8. Power, construction, vehicle, safety, traffic | 368 |
| Topic 13. Networks, edge, communication, computing, security | 368 |
| Topic 20. Mining, heritage, infrastructure, railway, equipment | 363 |
| Topic 18. Security, business, drilling, literature, DTs | 343 |
| Topic 11. Structural, damage, health, sensor, bridge | 324 |
| Topic 5. Machining, engine, prediction, tool, crack | 308 |
| Topic 1. Energy, city, urban, scheduling, battery | 304 |
| Topic 7. Robot, reality, robots, robotic, space | 300 |
| Topic 4. Construction, students, education, modeling, knowledge | 252 |
| Topic 16. Supply, chain, patient, health, medical | 246 |
| Topic 12. Value, service, logistics, lifecycle, context | 231 |
| Topic 3. Reality, metaverse, VR, augmented, commissioning | 198 |
| Topic 19. Structure, structural, point, construction, wind | 198 |
| Topic Name and Number | Number of Articles on Topic |
|---|---|
| 1_Robot_robots_robotic_human | 283 |
| 2_Digital_twins_digital twins_twin | 257 |
| 3_Construction_BIM_building_information | 239 |
| 4_Power_grid_energy_power grid | 175 |
| 5_Machining_cutting_tool_process | 161 |
| 6_Patients_healthcare_health_medicine | 149 |
| 7_Ship_vessel_ships_marine | 139 |
| 8_Fatigue_crack_damage_structural | 133 |
| 9_Teaching_students_education_learning | 120 |
| 10_Ontology_knowledge_semantic_ontologies | 107 |
| 11_Logistics_supply_supply chain_chain | 106 |
| 12_Maintenance_predictive maintenance_prediction | 90 |
| 13_City_urban_cities_smart | 87 |
| 14_Systems_MBSE_engineering_systems engineering | 87 |
| 15_Blockchain_sharing_data_decentralized | 84 |
| 16_Security_attack_cyber_attacks | 80 |
| 17_Bridge_structural_bridges_monitoring | 79 |
| 18_Fault_diagnosis_fault diagnosis_faults | 78 |
| 19_Battery_batteries_lithium-ion_charging | 70 |
| 20_Driving_vehicle_vehicles_traffic | 61 |
| Clustering Type | LDA | BERTopic |
|---|---|---|
| PCA | −0.00777 | 0.33081 |
| UMAP | 0.06249 | 0.34919 |
| t-SNE | 0.09098 | 0.36905 |
| No | Topics (BERTopic) | Topics (LDA) |
|---|---|---|
| 1. | 1_Robot_robots_robotic_human | Topic 10. Transformation, intelligence, companies, solutions, technological |
| 2. | 2_Digital_twins_digital twins_twin | Topic 2. Human, construction, bim, safety, robot |
| 3. | 3_Construction_bim_building_information | Topic 15. Thermal, temperature, power, flow, experimental |
| 4. | 4_Power_grid_energy_power grid | Topic 6. Test, planning, methodology, solution, flexible |
| 5. | 5_Machining_cutting_tool_process | Topic 14. IoT, cloud, CPS, knowledge, services |
| 6. | 6_Patients_healthcare_health_medicine | Topic 9. Material, properties, measurements, materials, element |
| 7. | 7_Ship_vessel_ships_marine | Topic 17. Equipment, assembly, fault, line, workshop |
| 8. | 8_Fatigue_crack_damage_structural | Topic 8. Power, construction, vehicle, safety, traffic |
| 9. | 9_Teaching_students_education_learning | Topic 13. Networks, edge, communication, computing, security |
| 10. | 10_Ontology_knowledge_semantic_ontologies | Topic 20. Mining, heritage, infrastructure, railway, equipment |
| 11. | 11_Logistics_supply_supply chain_chain | Topic 18. Security, business, drilling, literature, DTs |
| 12. | 12_Maintenance_predictive maintenance_prediction | Topic 11. Structural, damage, health, sensor, bridge |
| 13. | 13_City_urban_cities_smart | Topic 5. Machining, engine, prediction, tool, crack |
| 14. | 14_Systems_mbse_engineering_systems engineering | Topic 1. Energy, city, urban, scheduling, battery |
| 15. | 15_Blockchain_sharing_data_decentralized | Topic 7. Robot, reality, robots, robotic, space |
| 16. | 16_Security_attack_cyber_attacks | Topic 4. Construction, students, education, modeling, knowledge |
| 17. | 17_Bridge_structural_bridges_monitoring | Topic 16. Supply, chain, patient, health, medical |
| 18. | 18_Fault_diagnosis_fault diagnosis_faults | Topic 12. Value, service, logistics, lifecycle, context |
| 19. | 19_Battery_batteries_lithiumion_charging | Topic 3. Reality, metaverse, VR, augmented, commissioning |
| 20. | 20_Driving_vehicle_vehicles_traffic | Topic 19. Structure, structural, point, construction, wind |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kukushkin, K.; Ryabov, Y.; Borovkov, A. Digital Twins: A Systematic Literature Review Based on Data Analysis and Topic Modeling. Data 2022, 7, 173. https://doi.org/10.3390/data7120173
Kukushkin K, Ryabov Y, Borovkov A. Digital Twins: A Systematic Literature Review Based on Data Analysis and Topic Modeling. Data. 2022; 7(12):173. https://doi.org/10.3390/data7120173
Chicago/Turabian StyleKukushkin, Kuzma, Yury Ryabov, and Alexey Borovkov. 2022. "Digital Twins: A Systematic Literature Review Based on Data Analysis and Topic Modeling" Data 7, no. 12: 173. https://doi.org/10.3390/data7120173
APA StyleKukushkin, K., Ryabov, Y., & Borovkov, A. (2022). Digital Twins: A Systematic Literature Review Based on Data Analysis and Topic Modeling. Data, 7(12), 173. https://doi.org/10.3390/data7120173