Dataset of Search Results Organized as Learning Paths Recommended by Experts to Support Search as Learning



Abstract
1. Summary
2. Background and Rationale
3. Data Description
3.1. Files
- A comma-separated value (CSV) file with all the data in Spanish. The file name was LP_dataset_spanish_version.csv.
- A copy of the previous CSV file (LP_dataset_english_version.csv) with categorical data and variable names translated into English in order to facilitate analyses for English-speaking researchers.
3.2. Features
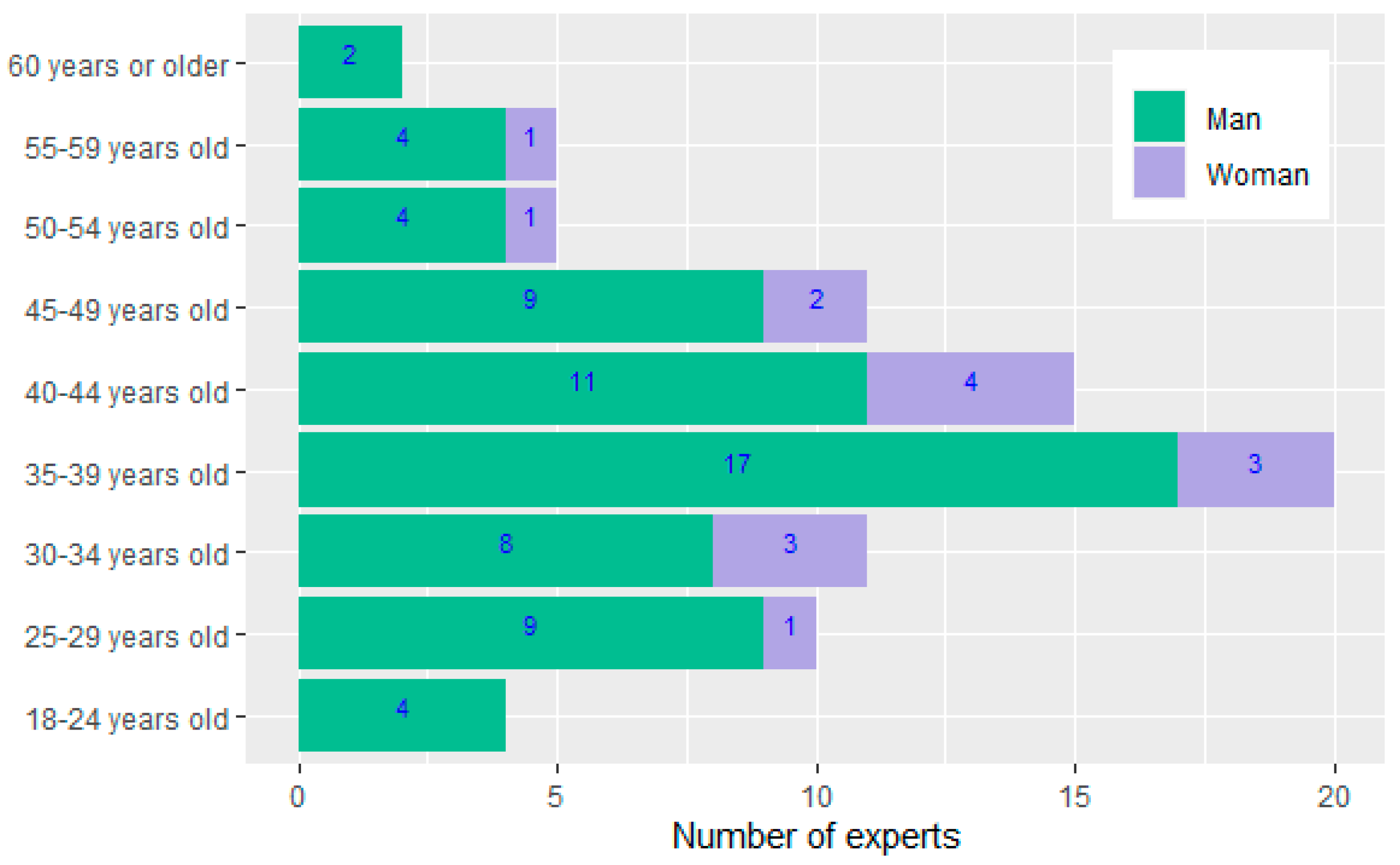
- The first fourteen features corresponded to demographic information provided by survey respondents.
- The following twelve variables described the LP, considering three sorted LOs and the description of the selection criteria provided by the experts.
- The last three characteristics were general features that we extracted from the recommended LPs—to facilitate the classification process—which are described in the following section.
3.3. Data Distribution
4. Methods
- In the first stage, prestigious universities, research centers, and industries of Spanish-speaking countries in each of the six domains of interest were identified.
- In the second stage, we created a list including faculty members, researchers, and professionals whose institutional email was available.
- In the third stage, invitations were sent out to the experts via an email to participate in the online survey. In addition, the experts were asked to share the survey with senior students (with at least a bachelor’s degree) who are proficient in the subject.
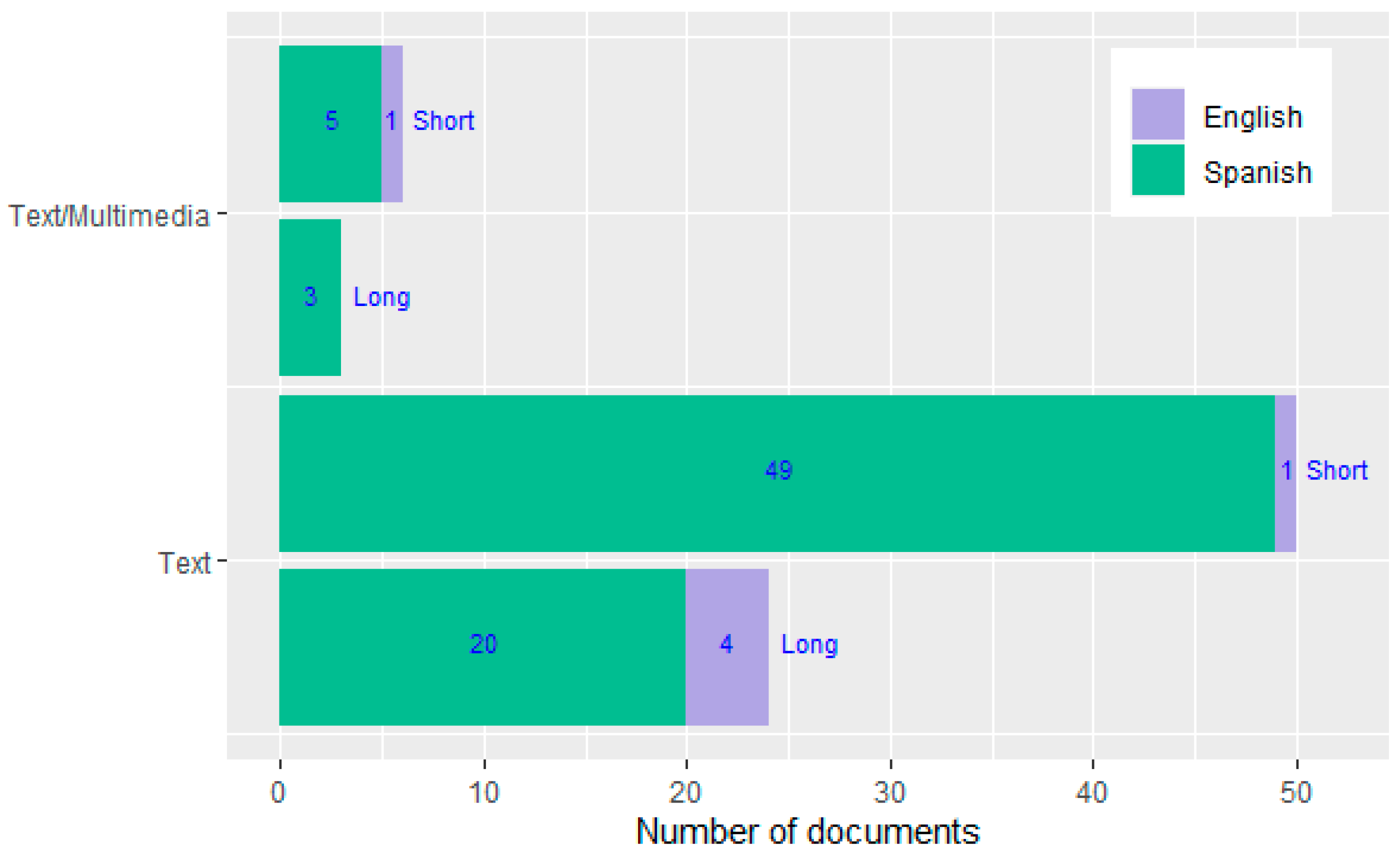
- LP document’s extension: This allows to identify if a LP document is short or long. For this purpose, we counted the number of words in each document of the LP. If the overall number of words was 4000 or less, the LP was classified as short. Otherwise, it was considered to be long. This decision was supported by the fact that the average reading rate is 200 words per minute for comprehensive reading tasks in the reader’s native language [32].
- Document language: This allows to identify if the LP documents are in Spanish or English.
- Document type: This allows to identify if the content of documents is mostly based on text or multimedia (i.e., audio and/or video).
- D: The first digit indicates the domain: (1) computer science, (2) finances, (3) industry, (4) physics, (5) laws, and (6) biology.
- NN: The two digits in the middle correspond to a sequential number for each domain. Note that this number does not indicate ranking or any other ordering criteria.
- O: The last digit indicates whether the LO is at (1) the beginning, (2) the middle, or (3) the end of the LP.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

References
- Bush, V. As we may think. Atl. Mon. 1945, 176, 101–108. [Google Scholar]
- Acampora, G.; Gaeta, M.; Loia, V. Hierarchical optimization of personalized experiences for e-Learning systems through evolutionary models. Neural Comput. Applic. 2011, 20, 641–657. [Google Scholar] [CrossRef]
- Al-Muhaideb, S.; Menai, M.E.B. Evolutionary computation approaches to the Curriculum Sequencing problem. Nat. Comput. 2011, 10, 891–920. [Google Scholar] [CrossRef]
- Caputi, V.; Garrido, A. Student-oriented planning of e-learning contents for Moodle. J. Netw. Comput. Appl. 2015, 53, 115–127. [Google Scholar] [CrossRef]
- Dwivedi, P.; Kant, V.; Bharadwaj, K.K. Learning path recommendation based on modified variable length genetic algorithm. Educ. Inf. Technol. 2018, 23, 819–836. [Google Scholar] [CrossRef]
- Byrne, J.; Kardefelt-Winther, D.; Livingstone, S.; Stoilova, M. Global Kids Online Research Synthesis, 2015–2016; UNICEF Office of Research—Innocenti and London School of Economics and Political Science: London, UK, 2016; pp. 1–75. [Google Scholar]
- Livingstone, S.; Kardefelt-Winther, D.; Saeed, M. Global Kids Online Comparative Report 2019; UNICEF Office of Research—Innocenti and London School of Economics and Political Science: London, UK, 2019; pp. 1–135. [Google Scholar]
- Rieh, S.Y.; Collins-Thompson, K.; Hansen, P.; Lee, H.-J. Towards searching as a learning process: A review of current perspectives and future directions. J. Inf. Sci. 2016, 42, 19–34. [Google Scholar] [CrossRef]
- Saracevic, T. Relevance reconsidered. In Proceedings of the Second Conference on Conceptions of Library and Information Science (CoLIS 2), Copenhagen, Denmark, 13–16 October 1996; ACM: New York, NY, USA, 1996; pp. 201–218. [Google Scholar]
- Saracevic, T. Why is relevance still the basic notion in information science. In Proceedings of the Re: Inventing Information Science in the Networked Society and Proceedings of the 14th International Symposium on Information Science (ISI 2015), Zadar, Croatia, 19–21 May 2015; pp. 26–35. [Google Scholar]
- Nahl, D.; Tenopir, C. Affective and cognitive searching behavior of novice end-users of a full-text database. J. Am. Soc. Inf. Sci. 1996, 47, 276–286. [Google Scholar] [CrossRef]
- Nahl, D.; Bilal, D. Information and Emotion: The Emergent Affective Paradigm in Information Behavior Research and Theory; American Society for Information Science and Technology: Silver Spring, MD, USA; Information Today, Inc.: Medford, NJ, USA, 2007; ISBN 978-1-57387-310-9. [Google Scholar]
- Farrell, R.G.; Liburd, S.D.; Thomas, J.C. Dynamic assembly of learning objects. In Proceedings of the WWW—ACM, New York, NY, USA, 17–22 May 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 162–169. [Google Scholar]
- Syed, R.; Collins-Thompson, K. Optimizing Search Results for Educational Goals: Incorporating Keyword Density as a Retrieval Objective. In Proceedings of the SAL@SIGIR, Pisa, Italy, 17–21 July 2016. [Google Scholar]
- Hearst, M. Search User Interfaces; Cambridge University Press: New York, NY, USA, 2009; ISBN 978-0-521-11379-3. [Google Scholar]
- Marchionini, G. Exploratory search: From finding to understanding. ACM 2006, 49, 41–46. [Google Scholar] [CrossRef]
- Large, A.; Nesset, V.; Beheshti, J. Children as information seekers: What researchers tell us. New Rev. Child. Lit. Librariansh. 2008, 14, 121–140. [Google Scholar] [CrossRef]
- Rieh, S.Y.; Kim, Y.-M.; Markey, K. Amount of invested mental effort (AIME) in online searching. Inf. Process. Manag. 2012, 48, 1136–1150. [Google Scholar] [CrossRef][Green Version]
- Graham, L.; Metaxas, P.T. “Of course it’s true; I saw it on the Internet!”: Critical thinking in the Internet era. Commun. ACM 2003, 46, 70–75. [Google Scholar] [CrossRef]
- Johnston, B.; Webber, S. Information Literacy in Higher Education: A review and case study. Stud. High. Educ. 2003, 28, 335–352. [Google Scholar] [CrossRef]
- Fernández Vítores, D. El Español: Una Lengua Viva—Informe 2019; Instituto Cervantes: Madrid, Spain, 2019; pp. 1–96. [Google Scholar]
- Escobar-Pérez, J.; Martínez, A. Validez de contenido y juicio de expertos: Una aproximación a su utilización. Av. En Med. 2008, 6, 27–36. [Google Scholar]
- Fotheringham, D. The role of expert judgement and feedback in sustainable assessment: A discussion paper. Nurse Educ. Today 2011, 31, e47–e50. [Google Scholar] [CrossRef] [PubMed]
- Hyrkäs, K.; Appelqvist-Schmidlechner, K.; Oksa, L. Validating an instrument for clinical supervision using an expert panel. Int. J. Nurs. Stud. 2003, 40, 619–625. [Google Scholar] [CrossRef]
- Drew, A.; Perera, A. Expert Knowledge as a Basis for Landscape Ecological Predictive Models. In Predictive Species and Habitat Modeling in Landscape Ecology: Concepts and Applications; Springer: New York, NY, USA, 2011; pp. 229–248. [Google Scholar]
- Tsyganok, V.V.; Kadenko, S.V.; Andriichuk, O.V. Significance of expert competence consideration in group decision making using AHP. Int. J. Prod. Res. 2012, 50, 4785–4792. [Google Scholar] [CrossRef]
- Hughes, R.T. Expert judgement as an estimating method. Inf. Softw. Technol. 1996, 38, 67–75. [Google Scholar] [CrossRef]
- Jørgensen, M. Forecasting of software development work effort: Evidence on expert judgement and formal models. Int. J. Forecast. 2007, 23, 449–462. [Google Scholar] [CrossRef]
- Burgman, M.; Fidler, F.; Mcbride, M.; Walshe, T.; Wintle, B. Eliciting Expert Judgments: Literature Review; Australian Centre for Excellence in Risk Analysis (ACERA): Melbourne, VIC, Australia, 2006. [Google Scholar]
- Ritter, F.E.; Nerb, J.; Lehtinen, E.; O’Shea, T.M. In Order to Learn: How the Sequence of Topics Influences Learning; Oxford University Press: Oxford, UK, 2007; Volume 2, ISBN 978-0-19-803977-8. [Google Scholar]
- White, R.W.; Dumais, S.T.; Teevan, J. Characterizing the influence of domain expertise on web search behavior. In Proceedings of the Second ACM International Conference on Web Search and Data Mining, Barcelona, Spain, 9–12 February 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 132–141. [Google Scholar]
- Grabe, W.; Stoller, F.L. Teaching and Researching Reading, 3rd ed.; Routledge: Abingdon, UK, 2019; ISBN 978-1-317-53642-0. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Column Name | Type | Description | * |
|---|---|---|---|
| ID_LP | Identifier | Row unique identifier (ID) or key | C |
| Age | Categorical | Expert’s age range | S |
| Sex | Categorical | Woman or Man | S |
| Nationality | Categorical | Expert’s nationality | S |
| Native_language | Categorical | Native language | S |
| Education | Categorical | Highest degree obtained or in course: bachelor’s, master’s, or doctorate | S |
| Professional_degree | Categorical | Expert’s career or profession | S |
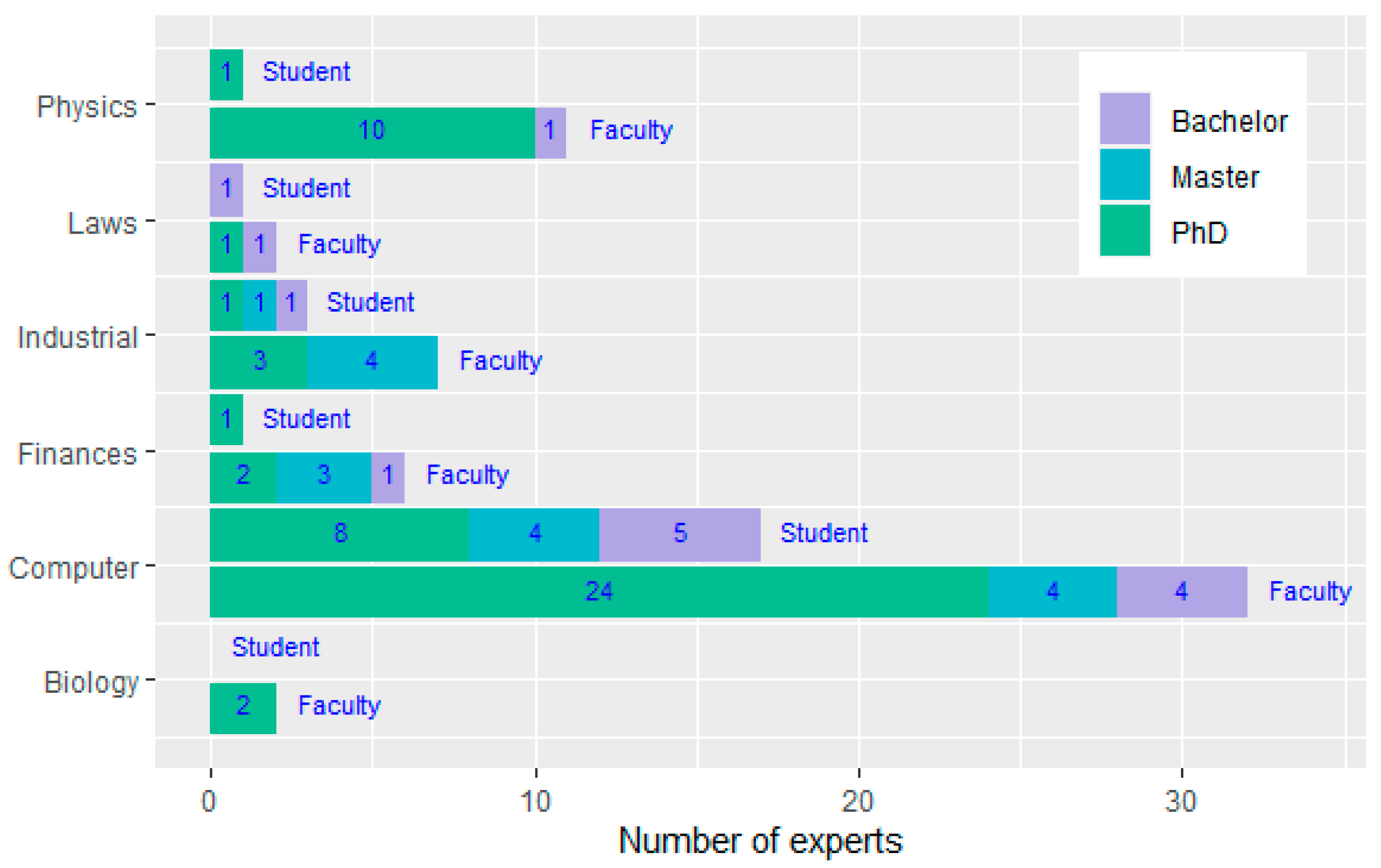
| Main_activity | Categorical | Main activity: student, lecturer (those that deal only with teaching duties), and faculty member (or researcher alone) | S |
| Current_year_study | Ordinal | If the expert is a student (e.g., doctoral program), current progress in terms of years within the program | S |
| Institution_type | Categorical | Higher level institution or research group | S |
| Time_spent | Categorical | Time spent on the Web according to the following scale: 0. Never 1. Once a week 2. Two or three days a week 3. At least five days a week, less than an hour a day 4. At least five days a week, between one hour and three hours a day 5. At least five days a week, more than three hours a day | S |
| Domain | Categorical | Expertise area: biology, computer science, finances, laws, physics, industrial engineering | S |
| Topic | Categorical | It can be one of the following six topics: - Bioethics of animal tissue cloning for human intake - Artificial neural networks - Investment projects - Inheritance laws in Chile - Quantum computing - Industrial revolutions | S |
| Experience_time | Categorical | Years of experience in the selected topic according to the following ranges: <1 year 2–3 years 4–5 years 6–9 years >10 years | S |
| Id_ LO_1 | Ordinal | Id of the first LO in the LP | C |
| URL_1 | Qualitative | URL of the first LO in the LP | S |
| Query_1 | Qualitative | Query used by the expert to obtain LO_1 | S |
| Reason_1 | Qualitative | Reasons for recommending reading LO_ 1 in first place | S |
| Id_ LO_2 | Ordinal | Id of the second LO in the LP | C |
| URL_2 | Qualitative | URL of the second LO in the LP | S |
| Query_2 | Qualitative | Query used by the expert to obtain LO_2 | S |
| Reason_2 | Qualitative | Reasons for recommending reading LO_2 in second place | S |
| Id_ LO_3 | Ordinal | Id of the third LO in the LP | C |
| URL_3 | Qualitative | URL of the third LO recommended in the LP | S |
| Query_3 | Qualitative | Query used by the expert to obtain LO_3 | S |
| Reason_3 | Qualitative | Reasons for recommending reading LO_3 last | S |
| Comments | Qualitative | Comments and observations made by each expert | S |
| LP_docs_extension | Categorical | LP documents’ extension: short or long | C |
| Document_language | Categorical | Documents’ language: Spanish or English | C |
| Document_type | Categorical | Documents’ content: text or multimedia | C |
| Domain | Student n = 23 | Lecturer n = 51 | Faculty n = 9 | TOTAL n = 83 | |||
|---|---|---|---|---|---|---|---|
| Women n = 4 | Men n = 19 | Women n = 9 | Men n = 42 | Women n = 2 | Men n = 7 | ||
| Biology | 0.00% | 0.00% | 0.00% | 1.20% | 1.20% | 0.00% | 2.40% |
| Computer | 3.61% | 16.88% | 4.82% | 30.14% | 1.20% | 2.41% | 50.06% |
| Finances | 0.00% | 1.20% | 2.41% | 4.82% | 0.00% | 0.00% | 8.43% |
| Industrial | 1.20% | 2.41% | 2.41% | 4.82% | 0.00% | 1.20% | 12.04% |
| Laws | 0.00% | 1.20% | 0.00% | 2.41% | 0.00% | 0.00% | 3.61% |
| Physics | 0.00% | 1.20% | 1.20% | 7.24% | 0.00% | 4.82% | 14.46% |
| TOTAL | 4.81% | 22.89% | 10.84% | 50.63% | 2.40% | 8.43% | 100.00% |
| Current Scenario | Criteria |
|---|---|
| Lack of validation for search results. | Consider experts’ knowledge and criteria to select and organize web documents as LOs. |
| Endless search results and random reading order. | Organize search results as LPs—defined as a finite and organized sequence of documents (LOs)—considering that the order in which study material is presented can lead to different learning outcomes [30]. |
| Observed common attitudes and behaviors among students toward web search contexts as little time and effort were invested in finding information [18]. | Short LPs intended to satisfy an immediate learning need, since students spend 14:21 min on average in a search session to read text documents [18]. |
| Most web content is in text format. | LPs mostly based on text. |
| Most IR (Information Retrieval) research is based on information presented in English language. | Spanish is the third most used language on the Internet [21], so it is necessary to pay attention to these users. |
| Domain | Topic | Subject |
|---|---|---|
| Biology | Bioethics of animal tissue cloning for human intake | What are the basic ethical principles to consider when cloning animal tissues for human intake? |
| Computer science | Artificial neural networks | What are the main differences between a simple artificial neural network and a deep artificial neural network? |
| Finances | Investment projects | What are the factors that must/should be considered when deciding whether to undertake a new business or to invest in properties? |
| Industry | Industrial revolutions | What are the main milestones for each industrial revolution? |
| Laws | Inheritance laws in Chile | Is it legal to disinherit a daughter or son? If so, in which cases? |
| Physics | Quantum computing | What are the main differences between quantum computers and classic computers? |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Proaño-Ríos, V.; González-Ibáñez, R. Dataset of Search Results Organized as Learning Paths Recommended by Experts to Support Search as Learning. Data 2020, 5, 92. https://doi.org/10.3390/data5040092
Proaño-Ríos V, González-Ibáñez R. Dataset of Search Results Organized as Learning Paths Recommended by Experts to Support Search as Learning. Data. 2020; 5(4):92. https://doi.org/10.3390/data5040092
Chicago/Turabian StyleProaño-Ríos, Verónica, and Roberto González-Ibáñez. 2020. "Dataset of Search Results Organized as Learning Paths Recommended by Experts to Support Search as Learning" Data 5, no. 4: 92. https://doi.org/10.3390/data5040092
APA StyleProaño-Ríos, V., & González-Ibáñez, R. (2020). Dataset of Search Results Organized as Learning Paths Recommended by Experts to Support Search as Learning. Data, 5(4), 92. https://doi.org/10.3390/data5040092