Distinct Two-Stream Convolutional Networks for Human Action Recognition in Videos Using Segment-Based Temporal Modeling



Abstract
1. Introduction
2. Related Works
2.1. Space-Time Networks
2.2. Hybrid Networks
2.3. Two-Stream Networks
3. Technical Approach
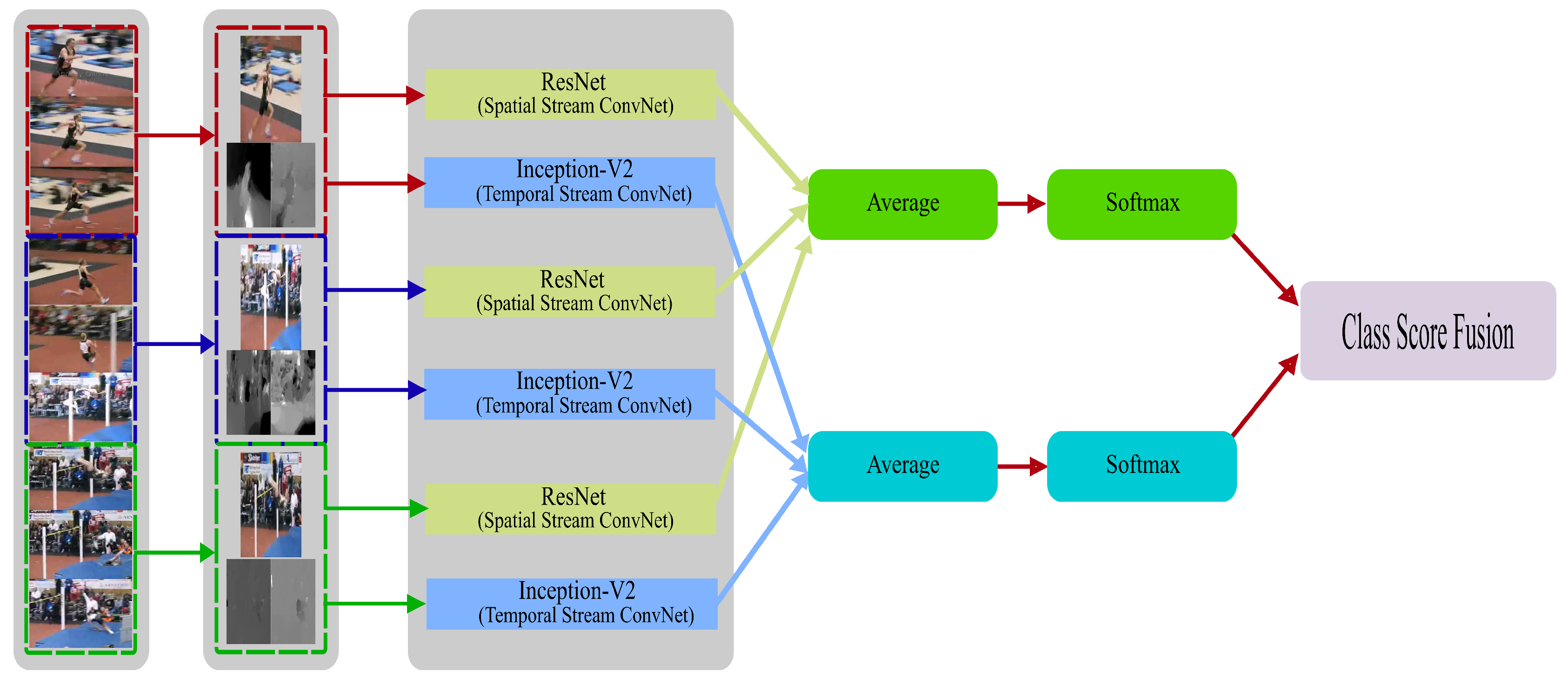
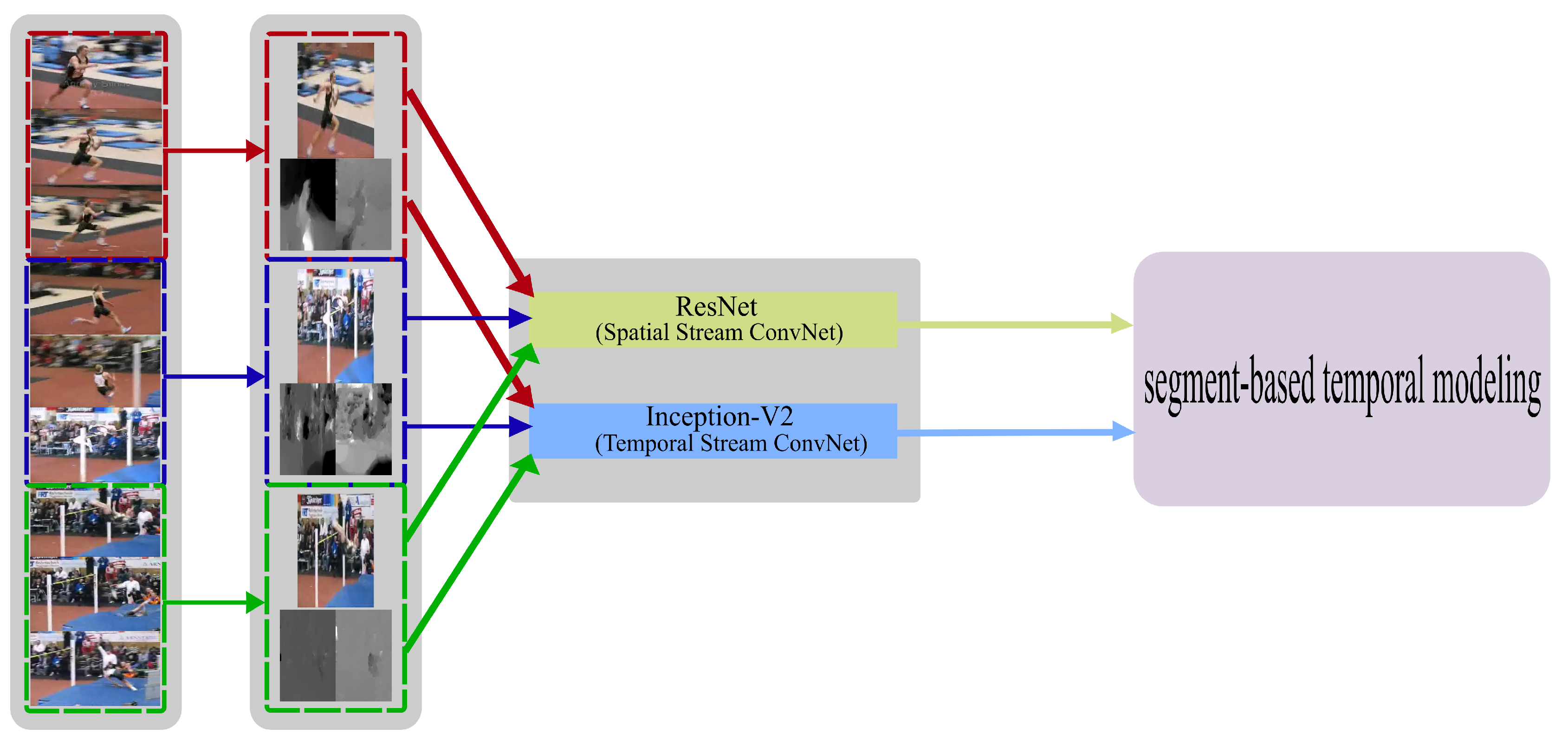
3.1. Distinct Two-Stream Convolution Networks
3.2. Base Networks
3.2.1. Residual Network
3.2.2. Inception-V2
3.3. Segment-Based Temporal Modeling
4. Network Training Strategies
4.1. Data Augmentation
4.2. Advanced Cross-Modal Pre-Training
5. Experiments
5.1. Datasets and Implementation Detials
5.2. Testing
5.3. Exploration Study
5.4. Comparison with State-of-the-Art
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nanda, A.; Sa, P.K.; Choudhury, S.K.; Bakshi, S.; Majhi, B. A neuromorphic person re-identification framework for video surveillance. IEEE Access 2017, 5, 6471–6482. [Google Scholar] [CrossRef]
- Nanda, A.; Chauhan, D.S.; Sa, P.K.; Bakshi, S. Illumination and scale invariant relevant visual features with hypergraph-based learning for multi-shot person re-identification. Multimed. Tools Appl. 2019, 78, 3885–3910. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal segment networks: Towards good practices for deep action recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 20–36. [Google Scholar]
- Christoph, R.P.W.; Pinz, F.A. Spatiotemporal residual networks for video action recognition. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3468–3476. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action recognition with trajectory-pooled deep-convolutional descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4305–4314. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Ji, J.; Buch, S.; Soto, A.; Niebles, J.C. End-to-end joint semantic segmentation of actors and actions in video. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 702–717. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Yu, P.S. Spatiotemporal pyramid network for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1529–1538. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Shahroudy, A.; Wang, G.; Duan, L.Y.; Kot, A.C. Skeleton-based online action prediction using scale selection network. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1453–1467. [Google Scholar] [CrossRef] [PubMed]
- Diba, A.; Fayyaz, M.; Sharma, V.; Karami, A.H.; Arzani, M.M.; Yousefzadeh, R.; Gool, L.V. Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv 2017, arXiv:1711.08200. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Wang, K.; Wang, X.; Lin, L.; Wang, M.; Zuo, W. 3d human activity recognition with reconfigurable convolutional neural networks. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3 November 2014; pp. 97–106. [Google Scholar]
- Ng, J.Y.H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Vonference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Kar, A.; Rai, N.; Sikka, K.; Sharma, G. Adascan: Adaptive scan pooling in deep convolutional neural networks for human action recognition in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 3376–3385. [Google Scholar]
- Diba, A.; Sharma, V.; Gool, L.V. Deep temporal linear encoding networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2329–2338. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.L.; Wang, G.; Duan, L.Y.; Chichung, A.K. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed]
- Veeriah, V.; Zhuang, N.; Qi, G.J. Differential recurrent neural networks for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4041–4049. [Google Scholar]
- Wu, Z.; Wang, X.; Jiang, Y.G.; Ye, H.; Xue, X. Modeling spatial-temporal clues in a hybrid deep learning framework for video classification. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 13 October 2015; pp. 461–470. [Google Scholar]
- Goodale, M.A.; Milner, A.D. Separate Visual Pathways for Perception and Action; Psychology Press: London, UK, 1992. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, W.; Yang, K.; Bai, Y.; Xiao, T.; Yao, H.; Rui, Y. Visualizing and comparing AlexNet and VGG using deconvolutional layers. In Proceedings of the 33 rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014, arXiv:1405.3531. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Latent hierarchical model of temporal structure for complex activity classification. IEEE Trans. Image Process 2013, 23, 810–822. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Zach, C.; Pock, T.; Bischof, H. A duality based approach for realtime tv-l 1 optical flow. In Joint Pattern Recognition Symposium; Springer: Berlin/Heidelberg, Germany, 2007; pp. 214–223. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3 November 2014; pp. 675–678. [Google Scholar]



{kind=link}
{kind=link}
| Network Architectures for Two-Streams | Spatial | Temporal | Two-Stream |
|---|---|---|---|
| Spatial_ResNet-101 + Temporal_ResNet-50 | 84.1% | 85.3% | 94.3% |
| Spatial_ResNet-152 + Temporal_ResNet-50 | 86.2% | 85.3% | 94.3% |
| Spatial_ResNet-101 + Temporal_Inception-V2 | 84.1% | 88.8% | 95.0% |
| Training Strategy | ResNet-50 | Inception-V2 |
|---|---|---|
| From scratch | 78.5% | 82.4% |
| Pre-Training [6] | 84.1% | 87.3% |
| Proposed - Advanced cross-modal pre-training | 85.3% | 88.8% |
| Methodology | UCF-101 | HMDB-51 |
|---|---|---|
| Two-stream network [5] | 88.0% | 59.4% |
| Two-stream network fusion [9] | 92.5% | 65.4% |
| Spatio-Temporal 3D CNNs [4] | 85.2% | – |
| Factorized Spatio-Temporal CNNs [36] | 88.1% | 59.1% |
| Pseudo-3D residual networks [14] | 93.7% | – |
| Temporal Segment Networks [6] | 94.0% | 68.5% |
| Temporal 3D CNNs [13] | 93.2% | 63.5% |
| SpatioTemporal residual networks [7] | 93.4% | 66.4% |
| (Proposed) Distinct two-stream CNN | 95.0% | 67.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarabu, A.; Santra, A.K. Distinct Two-Stream Convolutional Networks for Human Action Recognition in Videos Using Segment-Based Temporal Modeling. Data 2020, 5, 104. https://doi.org/10.3390/data5040104
Sarabu A, Santra AK. Distinct Two-Stream Convolutional Networks for Human Action Recognition in Videos Using Segment-Based Temporal Modeling. Data. 2020; 5(4):104. https://doi.org/10.3390/data5040104
Chicago/Turabian StyleSarabu, Ashok, and Ajit Kumar Santra. 2020. "Distinct Two-Stream Convolutional Networks for Human Action Recognition in Videos Using Segment-Based Temporal Modeling" Data 5, no. 4: 104. https://doi.org/10.3390/data5040104
APA StyleSarabu, A., & Santra, A. K. (2020). Distinct Two-Stream Convolutional Networks for Human Action Recognition in Videos Using Segment-Based Temporal Modeling. Data, 5(4), 104. https://doi.org/10.3390/data5040104