Linking Synthetic Populations to Household Geolocations: A Demonstration in Namibia


Abstract

1. Introduction
2. Methods
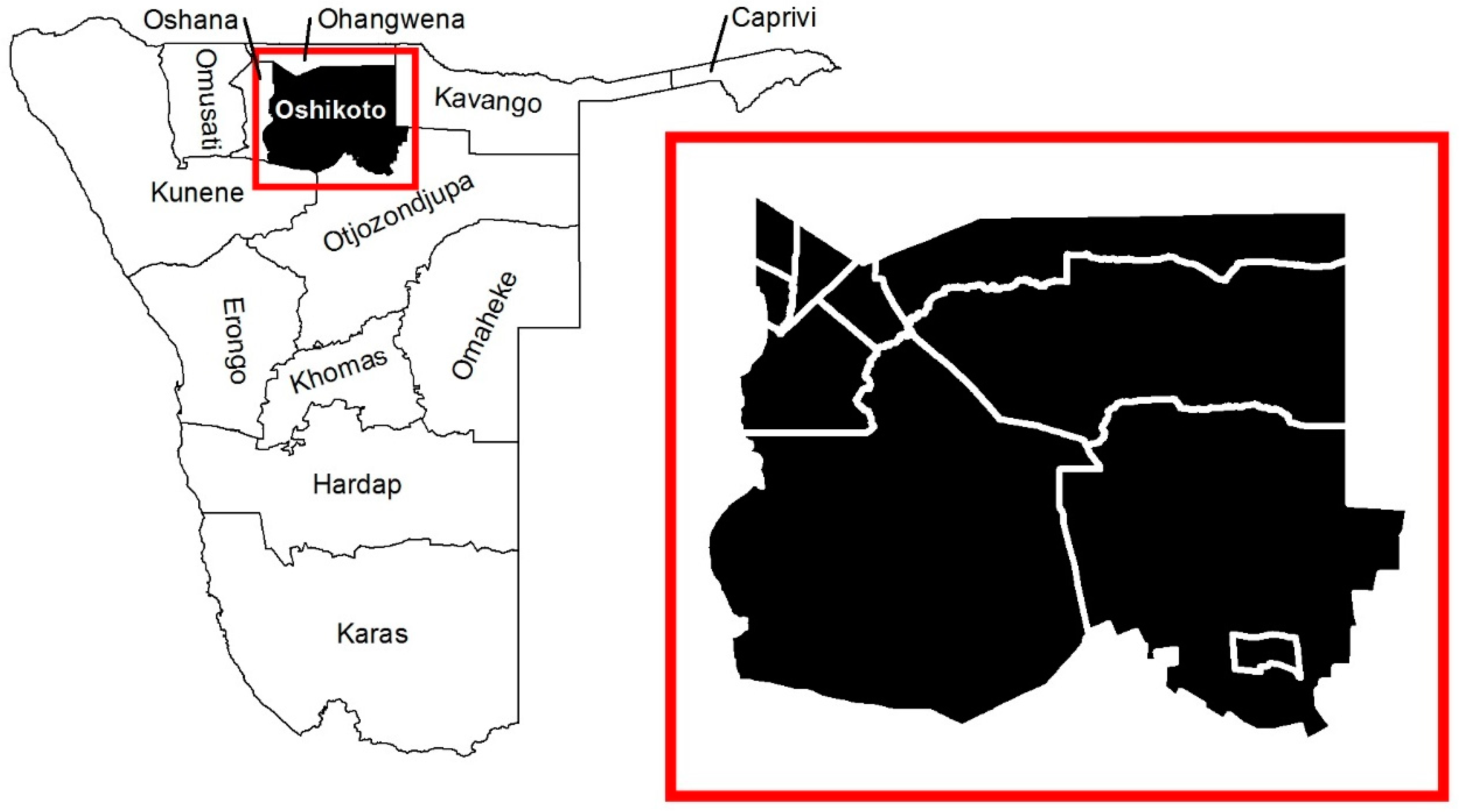
2.1. Setting
2.2. Data
2.3. Simulation
2.3.1. Phase A: Predict Spatial Distribution of Household Types
2.3.2. Phase B: Generate Synthetic Population and Assign Household Locations
2.3.3. Phase C. Predict Additional Population Characteristics, Generalize Locations
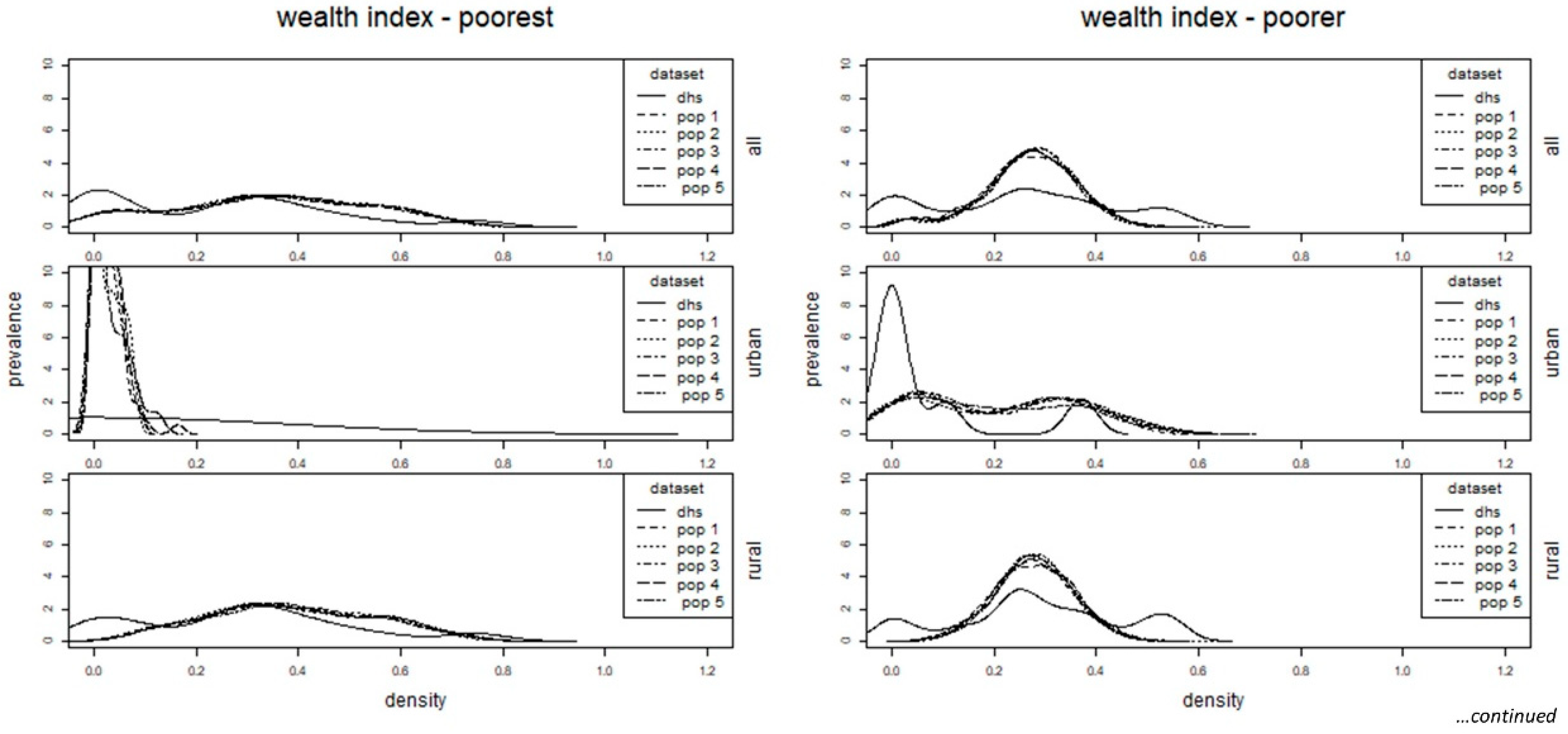
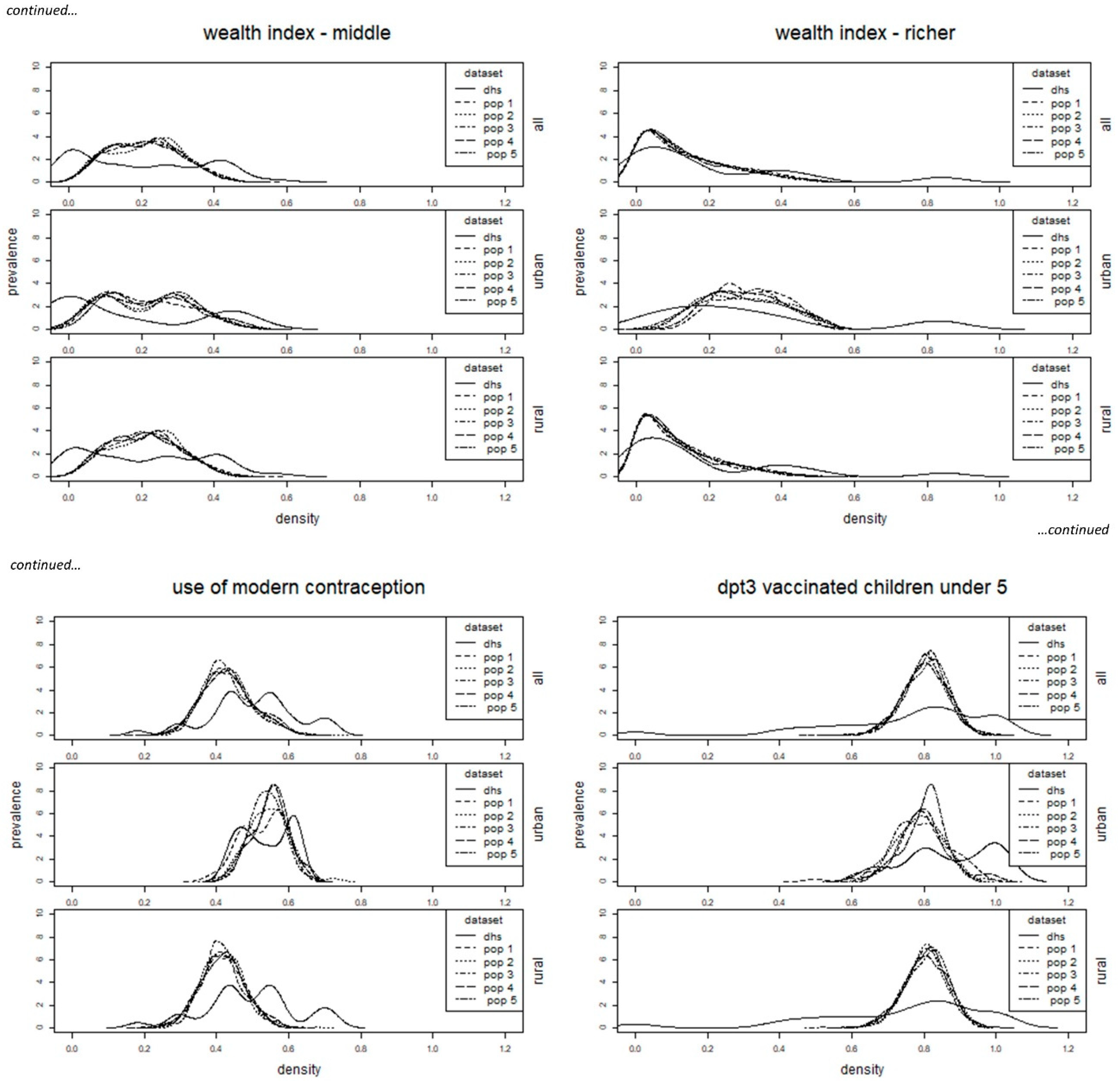
2.4. Assessment
2.5. Ethics
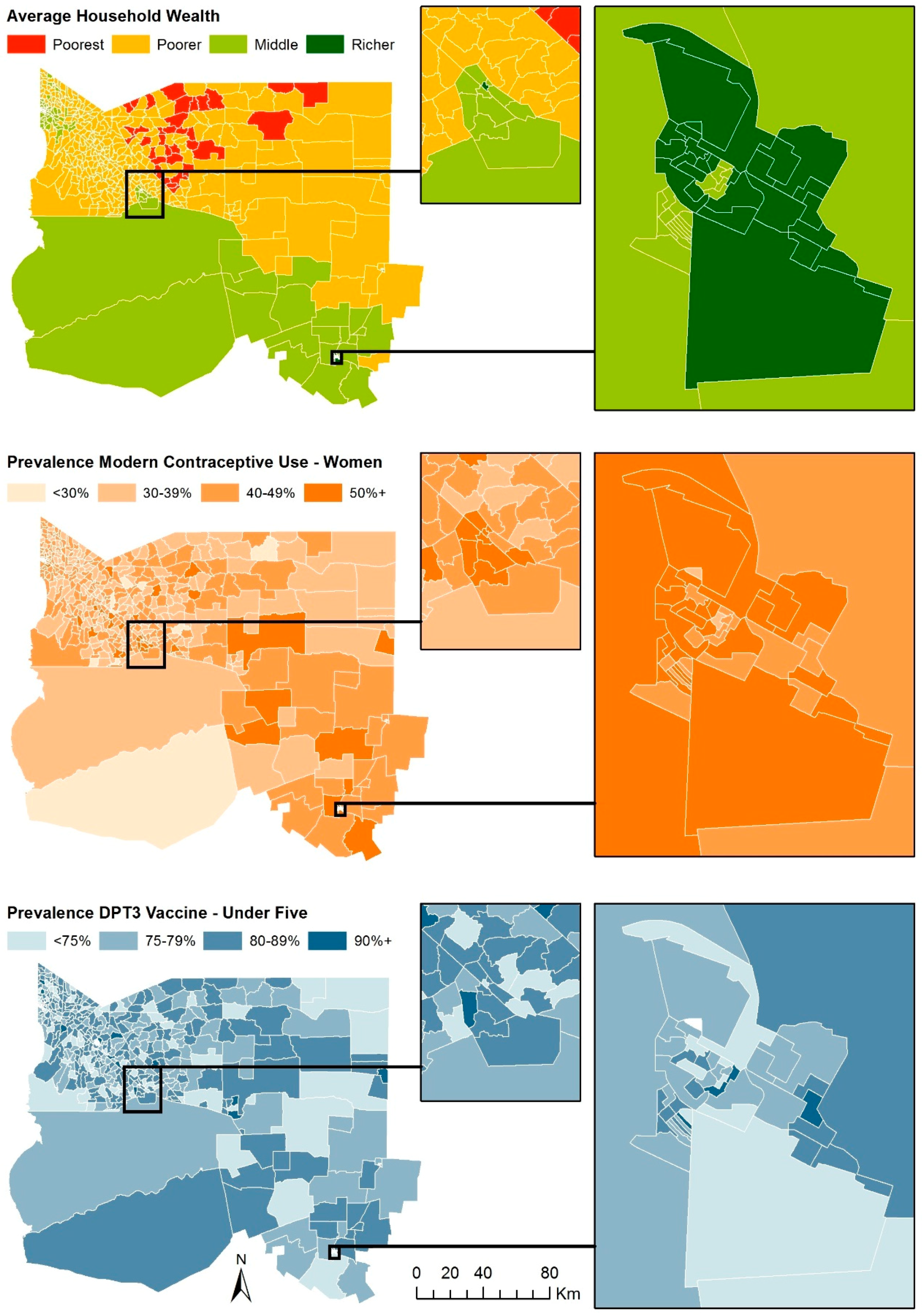
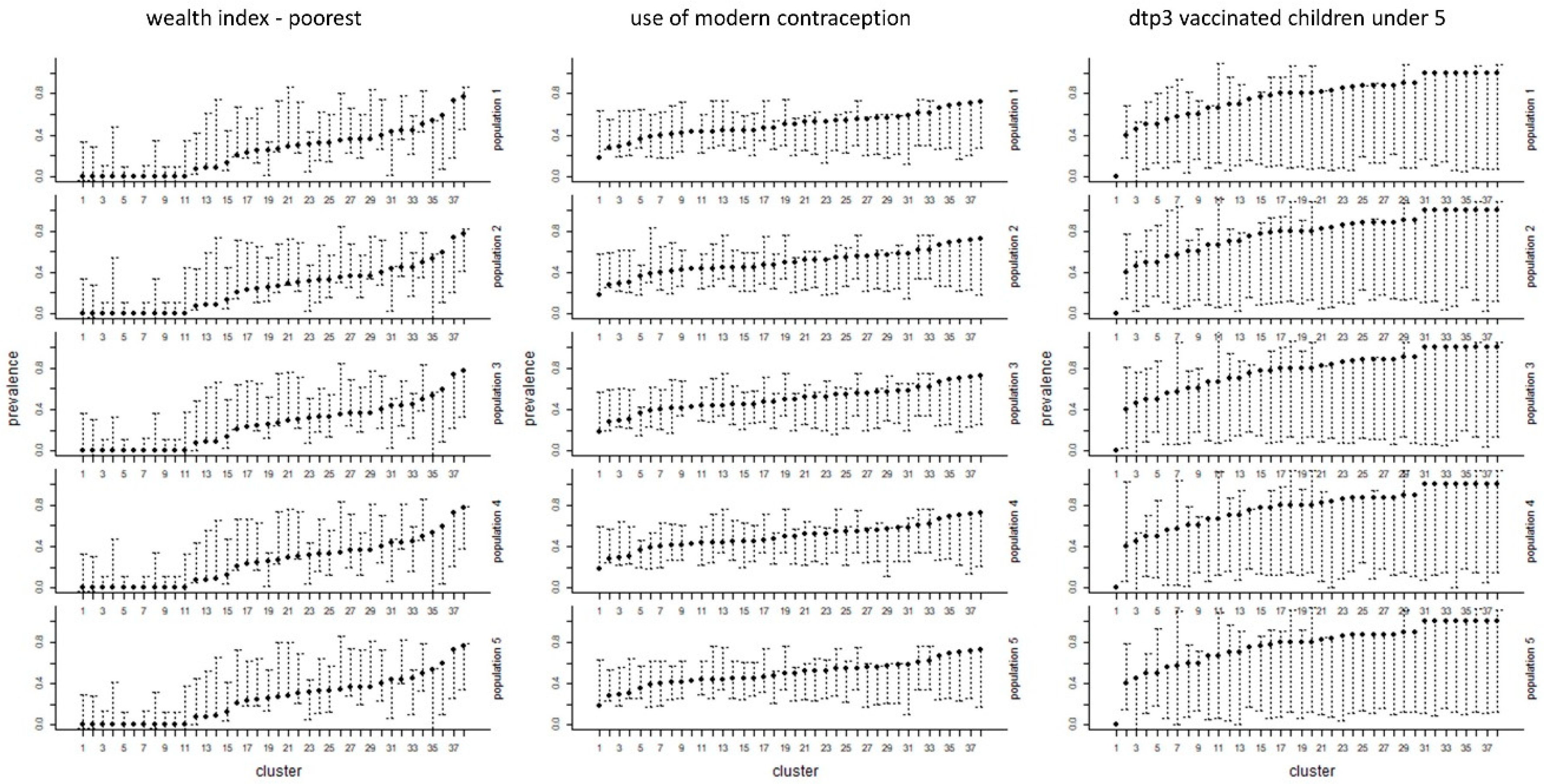
3. Results
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Doxsey-Whitfield, E.; MacManus, K.; Adamo, S.B.; Pistolesi, L.; Squires, J.; Borkovska, O.; Baptista, S.R. Taking advantage of the improved availability of census data: A first look at the gridded population of the world, version 4. Pap. Appl. Geogr. 2015, 1, 226–234. [Google Scholar] [CrossRef]
- Oak Ridge National Laboratories. LandScan Documentation. Available online: http://web.ornl.gov/sci/landscan/landscan_documentation.shtml (accessed on 6 February 2017).
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef] [PubMed]
- Azar, D.; Graesser, J.; Engstrom, R.; Comenetz, J.; Leddy, R.M.; Schechtman, N.G.; Andrews, T. Spatial refinement of census population distribution using remotely sensed estimates of impervious surfaces in haiti. Int. J. Remote Sens. 2010, 31, 5635–5655. [Google Scholar] [CrossRef]
- Hay, S.I.; Noor, A.M.; Nelson, A.; Tatem, A.J. The accuracy of human population maps for public health application. Trop. Med. Int. Health 2005, 10, 1073–1086. [Google Scholar] [CrossRef] [PubMed]
- Tatem, A.J.; Noor, A.M.; Hay, S.I. Assessing the accuracy of satellite derived global and national urban maps in Kenya. Remote Sens. Environ. 2005, 96, 87–97. [Google Scholar] [CrossRef] [PubMed]
- Alfons, A.; Kraft, S.; Templ, M.; Filzmoser, P. Simulation of close-to-reality population data for household surveys with application to EU-SILC. Stat. Methods Appl. 2011, 20, 383–407. [Google Scholar] [CrossRef]
- Minnesota Population Center. Integrated Public Use Microdata Series, International: Version 7.0 [Dataset]; University of Minnesota: Minneapolis, MN, USA, 2018. [Google Scholar]
- Global Health Data Exchange (GHDx). Available online: http://ghdx.healthdata.org/ (accessed on 2 February 2017).
- Tanton, R. A review of spatial microsimulation methods. Int. J. Microsimul. 2014, 7, 4–25. [Google Scholar] [CrossRef]
- Birkin, M.; Clarke, M. The generation of individual and household incomes at the small area level using synthesis. Reg. Stud. 1989, 23, 535–548. [Google Scholar] [CrossRef]
- Birkin, M.; Clarke, M. SYNTHESIS: A synthetic spatial information system for urban and regional analysis: Methods and examples. Environ. Plan. A 1988, 20, 1645–1671. [Google Scholar] [CrossRef]
- Ballas, D.; Kingston, R.; Stillwell, J.; Jin, J. Building a spatial microsimulation-based planning support system for local policy making. Environ. Plan. A 2007, 39, 2482–2499. [Google Scholar] [CrossRef]
- Farrell, N.; Morrissey, K.; O’Donoghue, C. Creating a spatial microsimulation model of the Irish local economy. In Spatial Microsimulation: A Reference Guide for Users; Tanton, R., Edwards, K., Eds.; Understanding Population Trends and Processes, volume 6; Springer: Dordrecht, The Netherlands, 2012; pp. 105–125. [Google Scholar]
- Templ, M.; Meindl, B.; Kowarik, A.; Dupriez, O. Simulation of synthetic complex data: The R package simPop. J. Stat. Softw. 2017, 79, 1–38. [Google Scholar] [CrossRef]
- Macal, C.M. Everything you need to know about agent-based modelling and simulation. J. Simul. 2016, 10, 144–156. [Google Scholar] [CrossRef]
- Chapuis, K.; Taillandier, P.; Renaud, M.; Drogoul, A. Gen*: A generic toolkit to generate spatially explicit synthetic populations. Int. J. Geogr. Inf. Sci. 2018, 32, 1–17. [Google Scholar] [CrossRef]
- Heppenstall, A.; Malleson, N.; Crooks, A. Space, the final frontier: How good are agent-based models at simulating individuals and space in cities? Systems 2016, 4, 9. [Google Scholar] [CrossRef]
- Synthetic Populations and Ecosystems of the World (SPEW). Available online: http://www.stat.cmu.edu/~spew/about/ (accessed on 15 May 2018).
- Synthetic Household PopulationTM. Available online: https://www.rti.org/impact/synthpop (accessed on 15 May 2018).
- SDG Indicators: Revised List of Global Sustainable Development Goal Indicators. Available online: https://unstats.un.org/sdgs/indicators/indicators-list/ (accessed on 3 September 2017).
- Tatem, A.J. WorldPop, open data for spatial demography. Sci. Data 2017, 4, 170004. [Google Scholar] [CrossRef] [PubMed]
- Bosco, C.; Alegana, V.; Bird, T.; Pezzulo, C.; Bengtsson, L.; Sorichetta, A.; Steele, J.; Hornby, G.; Ruktanonchai, C.; Ruktanonchai, N.; et al. Exploring the high-resolution mapping of gender-disaggregated development indicators. J. R. Soc. Interface 2017, 14, 20160825. [Google Scholar] [CrossRef] [PubMed]
- Alegana, V.A.; Atkinson, P.M.; Pezzulo, C.; Sorichetta, A.; Weiss, D.; Bird, T.; Erbach-Schoenberg, E.; Tatem, A.J. Fine resolution mapping of population age-structures for health and development applications. J. R. Soc. Interface 2015, 12, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Utazi, C.E.; Thorley, J.; Alegana, V.A.; Ferrari, M.J.; Takahashi, S.; Metcalf, C.J.E.; Lessler, J.; Tatem, A.J. High resolution age-structured mapping of childhood vaccination coverage in low and middle income countries. Vaccine 2018, 36, 1583–1591. [Google Scholar] [CrossRef] [PubMed]
- Thomson, D.R.; Stevens, F.R.; Ruktanonchai, N.W.; Tatem, A.J.; Castro, M.C. GridSample: An R package to generate household survey primary sampling units (PSUs) from gridded population data. Int. J. Health Geogr. 2017, 16, 25. [Google Scholar] [CrossRef] [PubMed]
- 2020 World Population and Household Census Programme Census Dates for All Countries. Available online: https://unstats.un.org/unsd/demographic/sources/census/censusdates.htm (accessed on 3 March 2017).
- [Namibia] National Statistics Agency. Namibia Population and Housing Census 2011: Main Report; Government of Namibia: Windhoek, Namibia, 2011.
- [Namibia] National Statistics Agency. Namibia 2011 Population and Housing Census [PUMS Dataset]; Version 1.0.; Government of Namibia: Windhoek, Namibia, 2013.
- [Namibia] National Statistics Agency 2011 Census EA Boundaries. Available online: https://digitalnamibia.nsa.org.na/ (accessed on 19 February 2018).
- ICF International Available Datasets. Available online: https://dhsprogram.com/data/available-datasets.cfm (accessed on 15 November 2017).
- Digital Globe Quickbird 50 cm Imagery. Available online: http://www.arcgis.com/home/item.html?id=10df2279f9684e4a9f6a7f08febac2a9 (accessed on 1 February 2018).
- Lloyd, C.T.; Sorichetta, A.; Tatem, A.J. High resolution global gridded data for use in population studies. Sci. Data 2017, 4, 1–17. [Google Scholar] [CrossRef] [PubMed]
- European Space Agency (ESA). Climate Change Initiative (CCI) Products. Available online: http://maps.elie.ucl.ac.be/CCI/viewer/download.php (accessed on 19 February 2017).
- Zhang, Q.; Pandey, B.; Seto, K.C. A robust method to generate a consistent time series from DMSP/OLS nighttime light data. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5821–5831. [Google Scholar] [CrossRef]
- CIESIN Gridded Population of the World, Version 4 (GPWv4). Country-Level Information and Sources Revision 10. Available online: http://sedac.ciesin.columbia.edu/downloads/docs/gpw-v4/gpw-v4-country-level-summary-rev10.xlsx (accessed on 19 February 2017).
- Open Street Map Base Data. Available online: www.openstreetmap.org (accessed on 19 February 2017).
- de Ferranti, J. Digital Elevation Data: SRTM Void Fill. Available online: http://www.viewfinderPanoramas.org/voidfill.html (accessed on 19 February 2017).
- Nelson, A. Estimated Travel Time to the Nearest City of 50,000 or More People in Year 2000; Global Environment Monitoring Unit—Joint Research Centre of the European Commission: Ispra, Italy, 2008; Available online: http://forobs.jrc.ec.europa.eu/products/gam/ (accessed on 8 August 2018).
- Esch, T.; Marconcini, M.; Felbeir, A.; Roth, A.; Heldens, W.; Huber, M.; Schwinger, M.; Taubenböck, H.; Müller, A.; Dech, S. Urban footprint processor—Fully automated processing chain generating settlement masks from global data of the TanDEM-X mission. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1617–1621. [Google Scholar] [CrossRef]
- European Commission. Global Human Settlement Layer. Available online: http://ghsl.jrc.ec.europa.eu/faq.php (accessed on 6 February 2017).
- UN-OCHA-ROSA Namibia—Health Facilities. Available online: https://data.humdata.org/dataset/namibia-health (accessed on 19 February 2017).
- UN-OCHA-ROSA Namibia—Education Facilities. Available online: https://data.humdata.org/dataset/namibia-education-0 (accessed on 19 February 2017).
- Steven, W.R.; Ramakrishna, R.N.; Faith Ann, H.; Maosheng, Z.; Matt, R.; Hirofumi, H. A continuous satellite-derived measure of global terrestrial primary production. Bioscience 2004, 54, 547–560. [Google Scholar]
- Fink, G.; Günther, I.; Hill, K. Slum residence and child health in developing countries. Demography 2014, 51, 1175–1197. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: Algorithm and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2013. [Google Scholar]
- ESRI. ArcGIS Release 10; Environmental Systems Research Institute: Redlands CA, USA, 2018. [Google Scholar]
- Nieves, J.J.; Stevens, F.R.; Gaughan, A.E.; Linard, C.; Sorichetta, A.; Hornby, G.; Patel, N.N.; Tatem, A.J. Examining the correlates and drivers of human population distributions across low- and middle-income countries. J. R. Soc. Interface 2017, 14, 20170401. [Google Scholar] [CrossRef] [PubMed]
- Burgert, C.R.; Zachary, B.; Colston, J. Incorporating Geographic Information into Demographic and Health Surveys: A Field Guide to GPS Data Collection; ICF International: Calverton, MD, USA, 2013. [Google Scholar]
- Perez-Heydrich, C.; Warren, J.L.; Burgert, C.R.; Emch, M.E. Influence of demographic and health survey point displacements on raster-based analyses. Spat. Demogr. 2016, 4, 135–153. [Google Scholar] [CrossRef] [PubMed]
- UN Habitat. Urbanization and development: Emerging futures. In World Cities Report 2016; United Nations Human Settlements Programme (UN-Habitat): Nairobi, Kenya, 2016. [Google Scholar]
- [Namibia] Ministry of Health and Social Services (MoHSS); ICF International. Namibia Demographic and Health Survey 2013; ICF International: Windhoek, Namibia; Rockville, MD, USA, 2014.
- Alfons, A.; Templ, M. Disclosure risk of synthetic population data with application in the case of EU-SILC. In Privacy in Statistical Databases; Domingo-Ferrer, J., Magkos, E., Eds.; Lecture Notes in Computer Science, volume 6344; Springer: Heidelberg, Germany, 2010; pp. 174–186. [Google Scholar]
- The Demographic and Health Surveys Program Modeled Surfaces. Available online: https://spatialdata.dhsprogram.com/modeled-surfaces/ (accessed on 16 April 2018).
- United Nations Children’s Fund (UNICEF). Multiple indicator cluster surveys round 4 (MICS4). In Designing and Selecting the Sample; UNICEF: New York, NY, USA, 2012. [Google Scholar]
- United Nations (UN). Designing Household Survey Samples: Practical Guidelines; Studies in Methods Series F No. 98; UN: New York, NY, USA, 2005. [Google Scholar]
- ICF International. Demographic and Health Survey Sampling and Household Listing Manual; ICF International: Calverton, MD, USA, 2012. [Google Scholar]
- Elsey, H.; Thomson, D.R.; Lin, R.Y.; Maharjan, U.; Agarwal, S.; Newell, J. Addressing inequities in urban health: Do decision-makers have the data they need? Report from the urban health data special session at international conference on urban health Dhaka 2015. J. Urban Health 2016, 93, 526–537. [Google Scholar] [CrossRef] [PubMed]
- A Breakthrough in Building Footprint Extraction. Available online: http://explore.digitalglobe.com/GBDX-Building-Footprints.html (accessed on 15 May 2018).
- Graesser, J.; Cheriyadat, A.; Vatsavai, R.R.; Chandola, V.; Long, J.; Bright, E. Image based characterization of formal and informal neighborhoods in an urban landscape. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1164–1176. [Google Scholar] [CrossRef]
- Jochem, W.C.; Bird, T.J.; Tatem, A.J. Identifying residential neighbourhood types from settlement points in a machine learning approach. Comput. Environ. Urban Syst. 2018, 69, 104–113. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Source; Original Unit | Output Unit |
|---|---|---|---|
| Population | |||
| dhs_hh | Individual recode file summarized by household | 2013 Demographic and Health Survey [31] | region |
| dhs_geo | Geo-displaced cluster coordinates | 2013 Demographic and Health Survey [31] | coordinate (cluster) |
| census_housing, census_person | 20% census microdata sample | 2011 National Statistics Agency [29] | constituency |
| census_report | Final census report | 2011 National Statistics Agency [28] | constituency |
| Used to generate new spatial data | |||
| imagery | High resolution satellite imagery | 2014–2016 DigitalGlobe Quickbird imagery [32]; 50 cm | Coordinate (household) |
| census_ea | 2011 Census EA boundaries | 2011 Namibia Statistics Agency [30] | EA |
| Spatial covariates | |||
| ccilc_dst011_2012 | Distance to land-cover: Cultivated terrestrial lands | 2012 ESA CCI annual LC maps v2.0.7 [34]; 10 arc seconds (≈300 m) * | 3 arc seconds (≈100 m) |
| ccilc_dst040_2012 | Distance to land-cover: Woody/Trees | 2012 ESA CCI annual LC maps v2.0.7 [34]; 10 arc seconds (≈300 m) * | 3 arc seconds (≈100 m) |
| ccilc_dst130_2012 | Distance to land-cover: Shrubs | 2012 ESA CCI annual LC maps v2.0.7 [34]; 10 arc seconds (≈300 m) * | 3 arc seconds (≈100 m) |
| ccilc_dst140_2012 | Distance to land-cover: Herbaceous | 2012 ESA CCI annual LC maps v2.0.7 [34]; 10 arc seconds (≈300 m) * | 3 arc seconds (≈100 m) |
| ccilc_dst150_2012 | Distance to land-cover: Other terrestrial vegetation | 2012 ESA CCI annual LC maps v2.0.7 [34]; 10 arc seconds (≈300 m) * | 3 arc seconds (≈100 m) |
| ccilc_dst190_2012 | Distance to land-cover: Urban | 2012 ESA CCI annual LC maps v2.0.7 [34]; 10 arc seconds (≈300 m) * | 3 arc seconds (≈100 m) |
| ccilc_dst200_2012 | Distance to land-cover: Bare | 2012 ESA CCI annual LC maps v2.0.7 [34]; 10 arc seconds (≈300 m) * | 3 arc seconds (≈100 m) |
| cciwat_dst | Distance to water bodies | ESA CCI, Water bodies v4.0 [34]; 5 arc seconds (≈150 m) * | 3 arc seconds (≈100 m) |
| dmsp_2011 | Nighttime lights intensity | 2011 inter-calibrated version of the v4 DMSP-OLS Nighttime Lights Time Series [35]; 30 arc seconds (≈1 km) * | 3 arc seconds (≈100 m) |
| gpw4coast_dst | Distance to coastline | GPWv4 input administrative units [36]; 3 arc seconds (≈100 m) * | 3 arc seconds (≈100 m) |
| osmint_dst | Distance to road intersections | 2016 OSM highways [37] * | 3 arc seconds (≈100 m) |
| osmriv_dst | Distance to major water ways | 2016 OSM waterways [37] * | 3 arc seconds (≈100 m) |
| slope | Slope | 2000 Viewfinder Panoramas [38]; (≈100 m) * | 3 arc seconds (≈100 m) |
| topo | Elevation | 2000 Viewfinder Panoramas [38]; (≈100 m) * | 3 arc seconds (≈100 m) |
| tt50k_2000 | Travel time to populated places of 50,000 or more people | 2000 EC-JRC Travel time to major cities [39]; 30 arc seconds (≈1 km) * | 3 arc seconds (≈100 m) |
| urbpx_prp_1_2012 | Proportion of settlement pixels with a one cell radius | 2012 DLR Global Urban Footprint [40]; 0.4 arc seconds (≈12.5 m) & 2000 EC-JRC Global Human Settlement Layer [41]; 38 m * | 3 arc seconds (≈100 m) |
| hfacilities_dst | Distance to health center or hospital | 2001 UN-OCHA [42] | 3 arc seconds (≈100 m) |
| schools_dst | Distance to primary or secondary school | 2001 UN-OCHA [43] | 3 arc seconds (≈100 m) |
| npp_2012 | Annual net primary productivity | 2010 MODIS [44]; 30 arc seconds (≈1 km) | 3 arc seconds (≈100 m) |
| Variable Name | Category | 20% Census Unweighted n (%) | DHS Unweighted n (%) | DHS Weighted n (%) |
|---|---|---|---|---|
| Households | Oshikoto (N) | 7475 | 705 | 817 |
| urban_rural | Urban | 1167 (15.6) | 113 (16.0) | 139 (17.1) |
| Rural | 6308 (84.4) | 592 (84.0) | 678 (82.9) | |
| structure | Durable floor | 2910 (38.9) | 281 (39.8) | 340 (41.6) |
| Non-durable floor | 4551 (60.9) | 422 (59.9) | 475 (58.1) | |
| Missing/unknown | 14 (0.2) | 2 (0.3) | 2 (0.3) | |
| fuel | Non-solid fuel | 1217 (16.3) | 141 (20.0) | 182 (22.3) |
| Solid fuel | 6253 (83.6) | 562 (79.7) | 633 (77.4) | |
| Missing/unknown | 5 (0.1) | 2 (0.3) | 2 (0.3) | |
| water | Improved water | 5388 (72.1) | 589 (83.6) | 688 (84.2) |
| Unimproved water | 2045 (27.3) | 72 (10.2) | 80 (9.8) | |
| Missing/unknown | 42 (0.6) | 44 (6.2) | 49 (7.0) | |
| toilet | Improved toilet | 1955 (26.1) | 207 (29.4) | 258 (31.6) |
| Unimproved toilet | 5491 (73.5) | 492 (69.8) | 553 (67.6) | |
| Missing/unknown | 29 (0.4) | 6 (1.0) | 6 (0.8) | |
| space | Adequate space | 6529 (87.3) | 619 (87.8) | 717 (87.7) |
| Inadequate space | 946 (12.7) | 82 (11.6) | 95 (11.6) | |
| Missing/unknown | 0 (0.0) | 4 (0.6) | 6 (0.7) | |
| noedu | Head household—any education | 5797 (77.6) | 581 (82.4) | 677 (82.8) |
| Head household—no education | 1528 (20.4) | 111 (15.7) | 125 (15.3) | |
| Missing/unknown | 150 (2.0) | 13 (1.9) | 15 (1.9) | |
| any_u5 | No child under age 5 | 4267 (57.1) | 405 (57.5) | 478 (58.5) |
| Any child under age 5 | 3208 (42.9) | 300 (42.5) | 340 (41.5) | |
| Individuals | Oshikoto (N) | 36,137 | 3316 | 3576 |
| relationship | Head | 7475 (20.7) | 705 (22.5) | 817 (22.9) |
| Spouse | 2391 (6.6) | 218 (7.0) | 250 (7.0) | |
| Child | 10,394 (28.8) | 785 (25.0) | 888 (24.8) | |
| Grandchild | 8635 (23.9) | 591 (18.9) | 660 (18.5) | |
| Extended | 5519 (15.3) | 622 (19.8) | 713 (19.9) | |
| Other | 1723 (4.8) | 215 (6.9) | 247 (6.9) | |
| sex | Female | 18,814 (52.1) | 1669 (53.2) | 1899 (53.1) |
| Male | 17,323 (47.9) | 1467 (46.8) | 1677 (46.9) | |
| age | 0 | 1136 (3.1) | 87 (2.8) | 99 (2.8) |
| 1–4 | 3968 (11.0) | 364 (11.6) | 414 (11.6) | |
| 5–9 | 4514 (12.5) | 404 (12.9) | 461 (12.9) | |
| 10–14 | 4895 (13.6) | 389 (12.4) | 435 (12.2) | |
| 15–19 | 4643 (12.9) | 385 (12.3) | 433 (12.1) | |
| 20–24 | 3284 (9.1) | 280 (8.9) | 323 (9.0) | |
| 25–29 | 2391 (6.6) | 213 (6.8) | 245 (6.9) | |
| 30–34 | 1912 (5.3) | 195 (6.2) | 230 (6.4) | |
| 35–39 | 1756 (4.9) | 161 (5.1) | 193 (5.4) | |
| 40–44 | 1371 (3.8) | 106 (3.4) | 120 (3.4) | |
| 45–49 | 1341 (3.7) | 118 (3.8) | 139 (3.9) | |
| 50–54 | 968 (2.7) | 102 (3.3) | 118 (3.3) | |
| 55–59 | 872 (2.4) | 68 (2.2) | 76 (2.1) | |
| 60–64 | 802 (2.2) | 71 (2.3) | 79 (2.2) | |
| 65–74 | 1105 (3.1) | 98 (3.1) | 107 (3.0) | |
| 75+ | 1177 (3.3) | 95 (3.0) | 104 (2.9) |
| Cluster | Urban_Rural | Noedu | any_u5 | Toilet | Water | Structure | Space | Fuel | Household Type Label |
|---|---|---|---|---|---|---|---|---|---|
| Type 1 | 0.00 | 0.00 | 0.04 | 0.06 | 0.00 | 0.00 | 0.00 | 0.00 | Urban rich |
| Type 2 | 0.00 | 0.19 | 0.07 | 0.85 | 0.06 | 0.47 | 0.32 | 0.80 | Urban poor |
| Type 3 | 1.00 | 0.05 | 0.12 | 0.55 | 0.00 | 0.00 | 0.04 | 0.10 | Rural rich |
| Type 4 | 1.00 | 0.12 | 0.06 | 0.46 | 0.07 | 0.39 | 0.09 | 0.79 | Rural middle |
| Type 5 | 1.00 | 0.012 | 0.11 | 0.81 | 0.04 | 0.45 | 0.01 | 0.97 | Rural middle (lack fuel) |
| Type 6 | 1.00 | 0.012 | 0.16 | 0.92 | 0.49 | 0.83 | 0.06 | 0.96 | Rural poor (lack water) |
| Type 7 | 1.00 | 0.22 | 0.13 | 0.91 | 0.09 | 0.83 | 0.04 | 0.98 | Rural poor (lack education) |
| Oshikoto | 0.84 | 0.016 | 0.12 | 0.77 | 0.11 | 0.60 | 0.07 | 0.79 |
| Variable | Category | pop_1 (%) | pop_2 (%) | pop_3 (%) | pop_4 (%) | pop_5 (%) |
|---|---|---|---|---|---|---|
| Households | Oshikoto (N) | 37,298 | 37,298 | 37,298 | 37,298 | 37,298 |
| urban_rural | Urban | 84.3 | 84.3 | 84.3 | 84.3 | 84.3 |
| Rural | 15.7 | 15.7 | 15.7 | 15.7 | 15.7 | |
| structure | Durable floor | 38.6 | 38.7 | 38.6 | 38.5 | 37.9 |
| Non-durable floor | 61.4 | 61.3 | 61.4 | 61.5 | 62.1 | |
| fuel | Non-solid fuel | 16.2 | 16.4 | 16.0 | 16.0 | 15.9 |
| Solid fuel | 83.8 | 83.6 | 84.0 | 84.0 | 84.1 | |
| water | Improved water | 73.2 | 73.2 | 72.9 | 73.1 | 72.7 |
| Unimproved water | 26.8 | 26.8 | 27.1 | 26.9 | 27.3 | |
| toilet | Improved toilet | 20.1 | 20.1 | 19.9 | 19.7 | 19.5 |
| Unimproved toilet | 79.9 | 79.9 | 80.1 | 80.3 | 80.5 | |
| space | Adequate space | 92.5 | 92.2 | 92.3 | 92.5 | 92.3 |
| Inadequate space | 7.5 | 7.8 | 8.7 | 7.5 | 7.7 | |
| noedu | Head household—any education | 70.8 | 70.5 | 70.5 | 70.8 | 70.9 |
| Head household—no education | 29.2 | 29.5 | 29.5 | 29.2 | 29.1 | |
| any_u5 | No child under age 5 | 57.4 | 57.0 | 56.8 | 57.1 | 57.0 |
| Any child under age 5 | 42.6 | 43.0 | 43.2 | 42.9 | 43.0 | |
| Individuals | Oshikoto (N) | 179,931 | 179,854 | 180,233 | 180,164 | 180,111 |
| relationship | Head | 20.7 | 20.7 | 20.7 | 20.7 | 20.7 |
| Spouse | 6.6 | 6.6 | 6.5 | 6.6 | 6.6 | |
| Child | 28.8 | 28.8 | 28.7 | 28.9 | 28.8 | |
| Grandchild | 23.8 | 24.0 | 23.9 | 23.8 | 23.8 | |
| Extended | 15.1 | 15.1 | 15.2 | 15.0 | 15.3 | |
| Other | 4.9 | 4.8 | 5.0 | 4.9 | 4.8 | |
| sex | Female | 52.2 | 52.0 | 51.9 | 51.8 | 52.0 |
| Male | 47.8 | 48.0 | 48.1 | 48.2 | 48.0 | |
| age | 0 | 3.1 | 3.1 | 3.2 | 3.1 | 3.2 |
| 1–4 | 10.9 | 11.1 | 11.1 | 10.9 | 10.9 | |
| 5–9 | 12.7 | 12.6 | 12.5 | 12.4 | 12.7 | |
| 10–14 | 13.6 | 13.6 | 13.6 | 13.7 | 13.6 | |
| 15–19 | 12.9 | 12.9 | 12.7 | 13.0 | 12.9 | |
| 20–24 | 9.0 | 9.0 | 9.1 | 9.1 | 9.0 | |
| 25–29 | 6.7 | 6.6 | 6.6 | 6.6 | 6.6 | |
| 30–34 | 5.2 | 5.3 | 5.3 | 5.2 | 5.3 | |
| 35–39 | 4.9 | 4.9 | 5.0 | 4.9 | 4.9 | |
| 40–44 | 3.8 | 3.8 | 3.7 | 3.9 | 3.8 | |
| 45–49 | 3.7 | 3.8 | 3.8 | 3.8 | 3.7 | |
| 50–54 | 2.7 | 2.7 | 2.7 | 2.7 | 2.7 | |
| 55–59 | 2.4 | 2.4 | 2.4 | 2.4 | 2.4 | |
| 60–64 | 2.2 | 2.2 | 2.2 | 2.2 | 2.2 | |
| 65–74 | 3.1 | 3.1 | 3.1 | 3.0 | 3.0 | |
| 75+ | 3.2 | 3.1 | 3.2 | 3.2 | 3.2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thomson, D.R.; Kools, L.; Jochem, W.C. Linking Synthetic Populations to Household Geolocations: A Demonstration in Namibia. Data 2018, 3, 30. https://doi.org/10.3390/data3030030
Thomson DR, Kools L, Jochem WC. Linking Synthetic Populations to Household Geolocations: A Demonstration in Namibia. Data. 2018; 3(3):30. https://doi.org/10.3390/data3030030
Chicago/Turabian StyleThomson, Dana R., Lieke Kools, and Warren C. Jochem. 2018. "Linking Synthetic Populations to Household Geolocations: A Demonstration in Namibia" Data 3, no. 3: 30. https://doi.org/10.3390/data3030030
APA StyleThomson, D. R., Kools, L., & Jochem, W. C. (2018). Linking Synthetic Populations to Household Geolocations: A Demonstration in Namibia. Data, 3(3), 30. https://doi.org/10.3390/data3030030