The #BTW17 Twitter Dataset–Recorded Tweets of the Federal Election Campaigns of 2017 for the 19th German Bundestag


Abstract
:1. Introduction
- What are the main influencers and multipliers in this political network?
- Are these influencers and multipliers aware or unaware in established political communication research?
- Are the influencers and multipliers influenceable?
- How robust are influencer and multiplier networks against disturbance of trolls and demobilizing effects?
- Is it possible to identify groups of multipliers that can be influenced more easily than other groups?
- Is it possible to identify relevant societal trends from social media streams that might be not covered by the political communication sufficiently?
- Is it possible to make use of social media as an early-warning system for rising societal trends that political actors are currently unaware of?
- Is it possible to identify commonalities of groups that feel politically penalized and misunderstood?
- Is it possible to measure this feeling of being politically penalized and misunderstood?
- And so on.
- Analysis of the political representativeness of Twitter users (Spanish election campaign of 2011 and U.S. presidential election campaign of 2012) [3]
- Twitter status updates in the context of Live-TV events [6]
- Tweets and Votes, a Special Relationship: The 2009 Federal Election in Germany [7]
- Real-time Twitter sentiment analysis of 2012 U.S. Presidential election cycle [8]
- Limits of Electoral Predictions using Twitter [9]
- Social media adaption in the U.S. congress [10]
- Twitter adoption and activity in U.S. legislatures [11]
- The uses of Twitter by populist presidents in contemporary Latin America [12]
- The design of future political campaigns using social media more systematically.
- Mechanisms of hate-speech, populism and their correlated network structures.
- Classification of Twitter accounts regarding political party proximity.
- Identification of influencing and multiplying Twitter accounts.
- Identification of strength and weaknesses in network structures that shall be considered for effective political communication through social media channels.
- Understanding motivations to distribute political content (more than 50% of all Twitter interactions are re-tweets).
- The effectiveness to identify swing-voters (which are only 3% according to this dataset).
- The limitations to target specific citizens (most observed Twitter users are too inactive to do this).
- And so on.
2. Data Acquisition and Processing Including Quality Control Measures
- In a first step, the official websites of the 18th German Bundestag factions have been crawled for Twitter screen names, because these websites contain lists of politicians with links to their official social media accounts.
- In a second step, these resulting screen names were checked for plausibility to exclude wrong screen names. Some pages contain Twitter live tweets of politicians containing screen names out of the political context like @Sportschau (famous German TV show for sport). This step has been done manually. In rare cases, some Twitter accounts were added like @MartinSchulz (one of the chancellor candidates for the 19th German Bundestag). Due to his former membership of the European Parliament1, he was not a member of the 18th German Bundestag, but was obviously a relevant actor in the political discussion.
3. Dataset Description
- screen names of observed politicians and their party membership,
- texts of recorded Tweets,
- user information of observed users provided by the Twitter Streaming API at the time of recording,
- user mentions,
- hashtags,
- media and further references,
- identifiers of users and tweets to query additional information per Tweet or Twitter user,
- interactions between users (reply to tweet, quote of tweet, re-tweet of tweet),
- and timestamps for all status posts and Twitter interactions (replies, re-tweets, quotes).
- volume of tweets during the political campaigns for the 19th German Bundestag,
- percentages of tweet subtypes (status messages, re-tweets, replies, quotes),
- amount of engaged Twitter users per party,
- and party-specific observations of account ages and “loudness” of re-tweeting Twitter accounts.
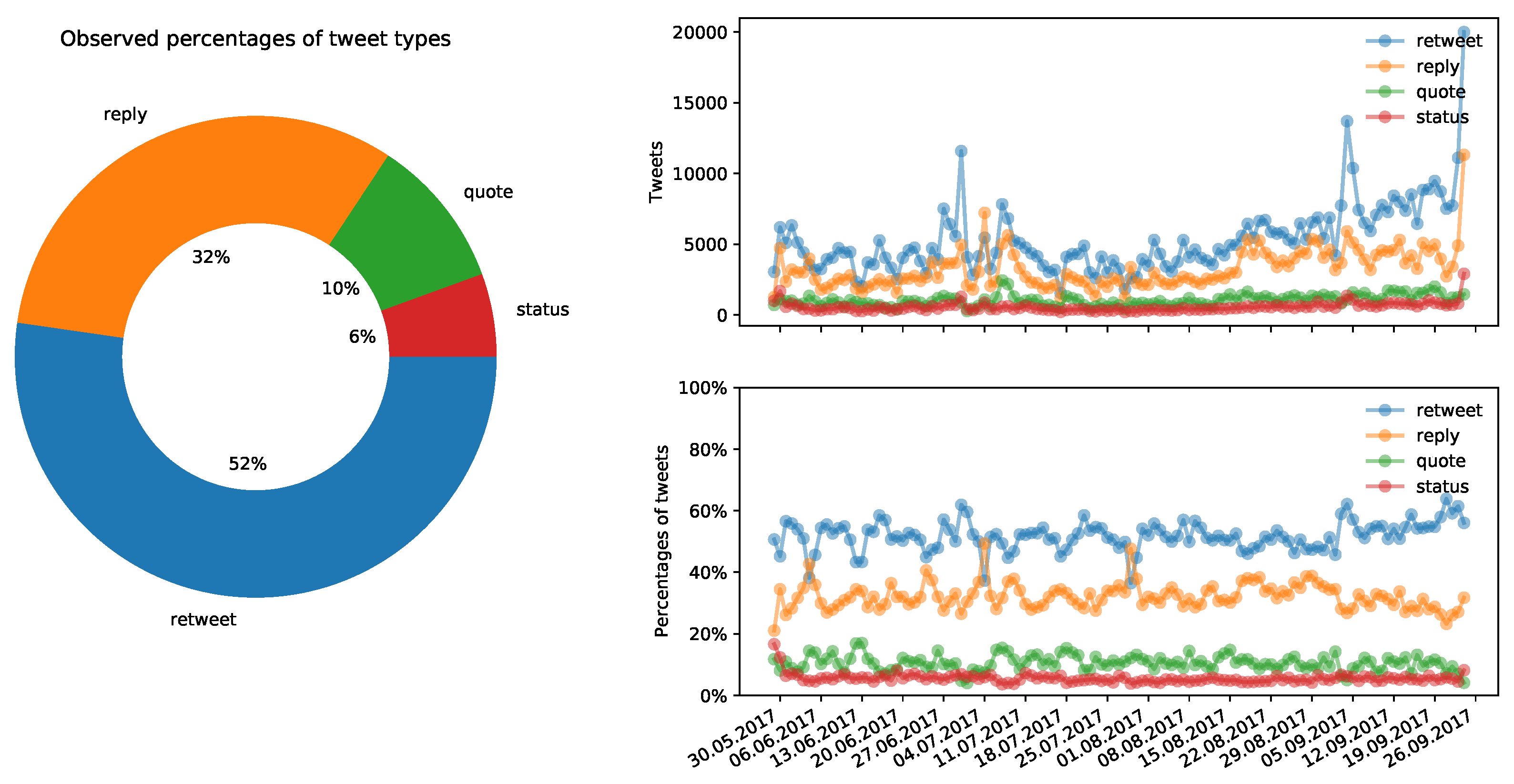
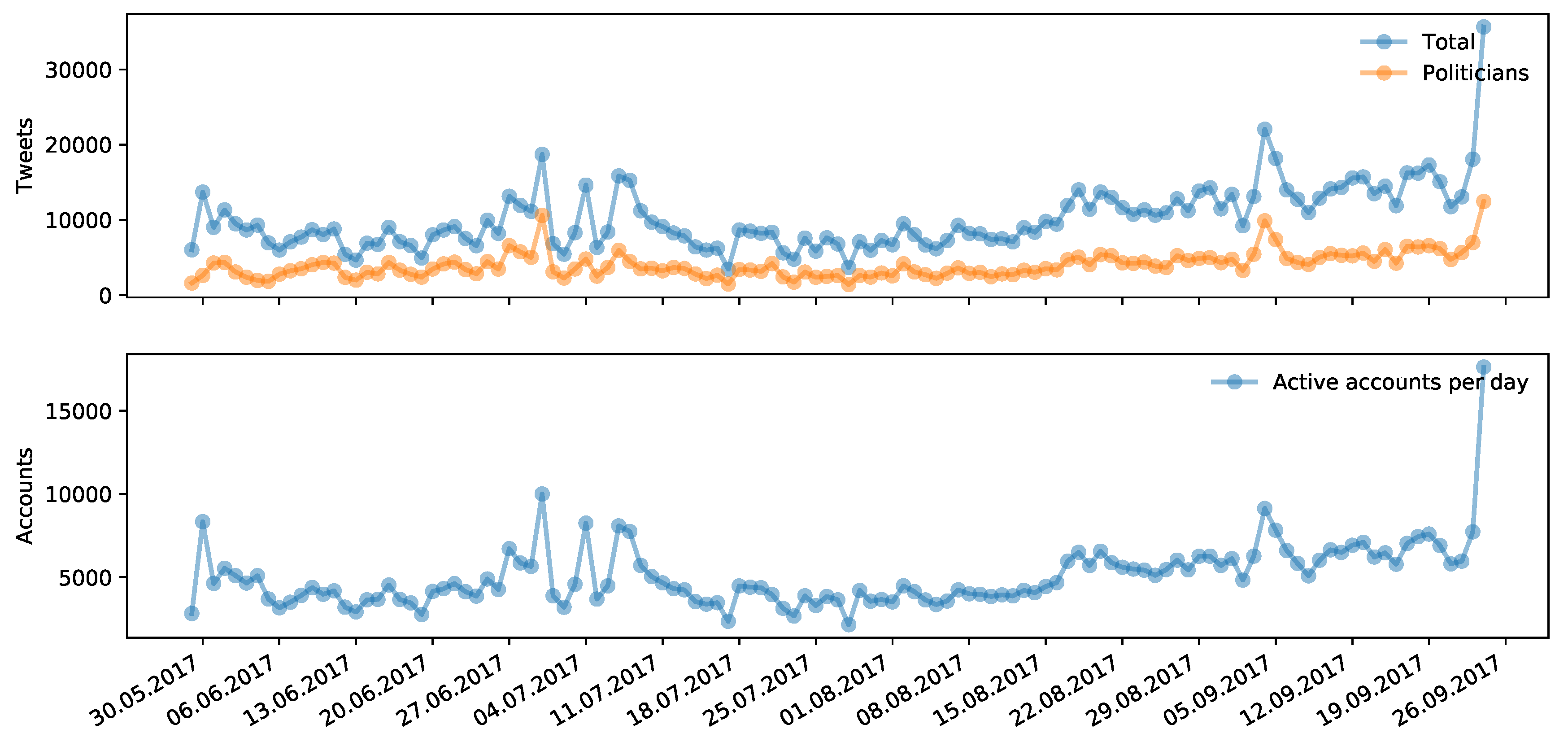
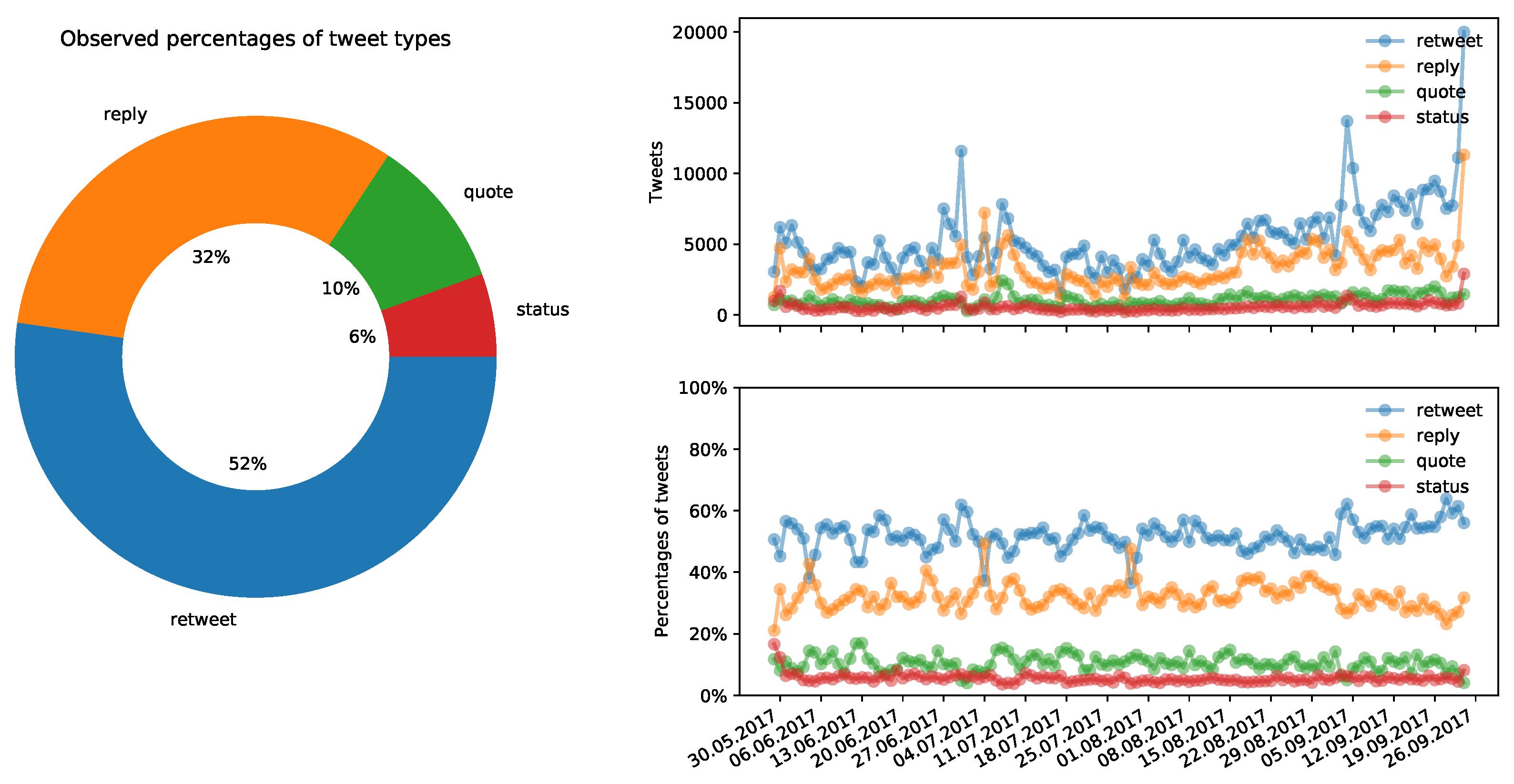
3.1. Volume of Tweets during Political Campaigns
- of the ballot on same-sex marriage in German Bundestag on 30 June 2017,
- around TV debates on 3–5 September 2017 and
- on the election day of 24 September 2017.
3.2. Percentages of Tweet Types
- half of all tweets are re-tweets,
- a third of all tweets are replies,
- a tenth of all tweets are quotes (which is a kind of re-tweet, but adds additional content or context that may change the intended message of the original tweet),
- and only 5% of all tweets are status messages (containing political content or statements).
- A quote is a kind of a re-tweet, but it adds additional content that might change the intended message of the original tweet. Whether the intended message is questioned or not must be analyzed using the content of the tweet. For that kind of analysis, natural language processing (NLP) can be applied. However, this kind of information is not used to build groups of users for this dataset description.
- A reply might be supporting, contradicting or simply questioning. However, that can be only determined by content-based text classification or other natural language processing and analyzing techniques. Therefore, this kind of information is not used to build descriptive groups of users for this dataset description.
- A status post (maybe mentioning a political actor) might mean everything (supporting, contradicting, questioning, spoofing or just mentioning and much more). Furthermore, for this kind of tweet, it is necessary to evaluate the tweet on a content basis. Therefore, this kind of information is not used either. Furthermore, the reader should remember that only 5% of all observed Tweets were status posts. Therefore, evaluating status posts might not be worth the effort (although this might sound contradictory at first).
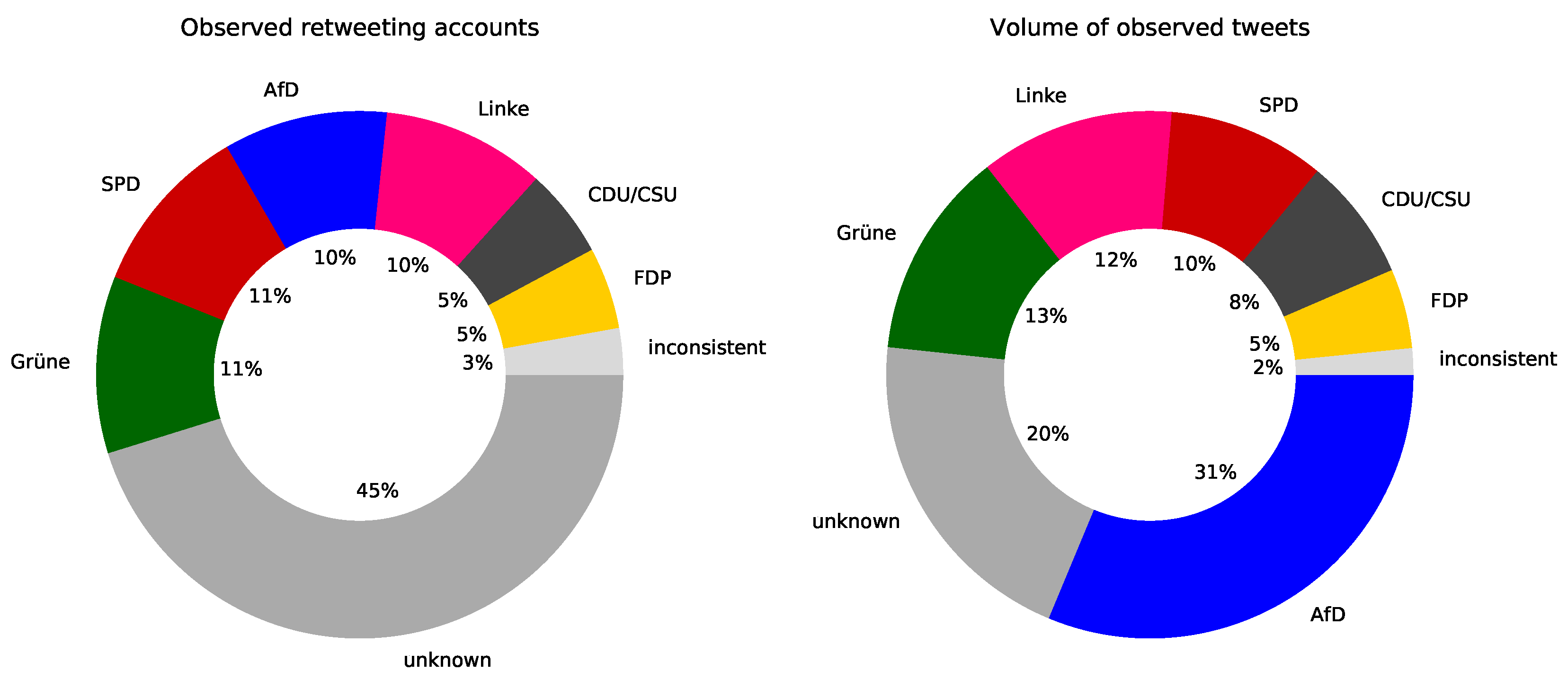
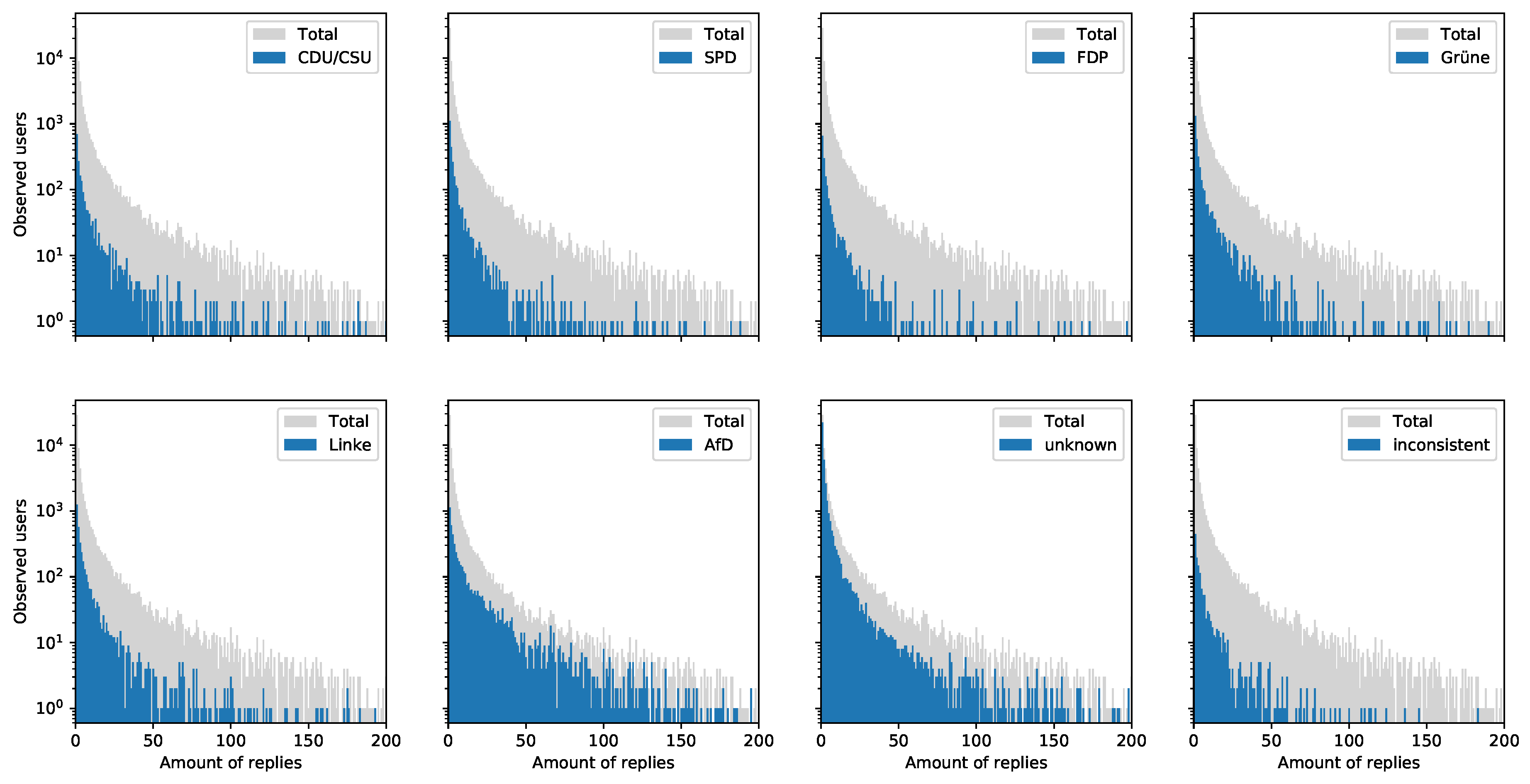
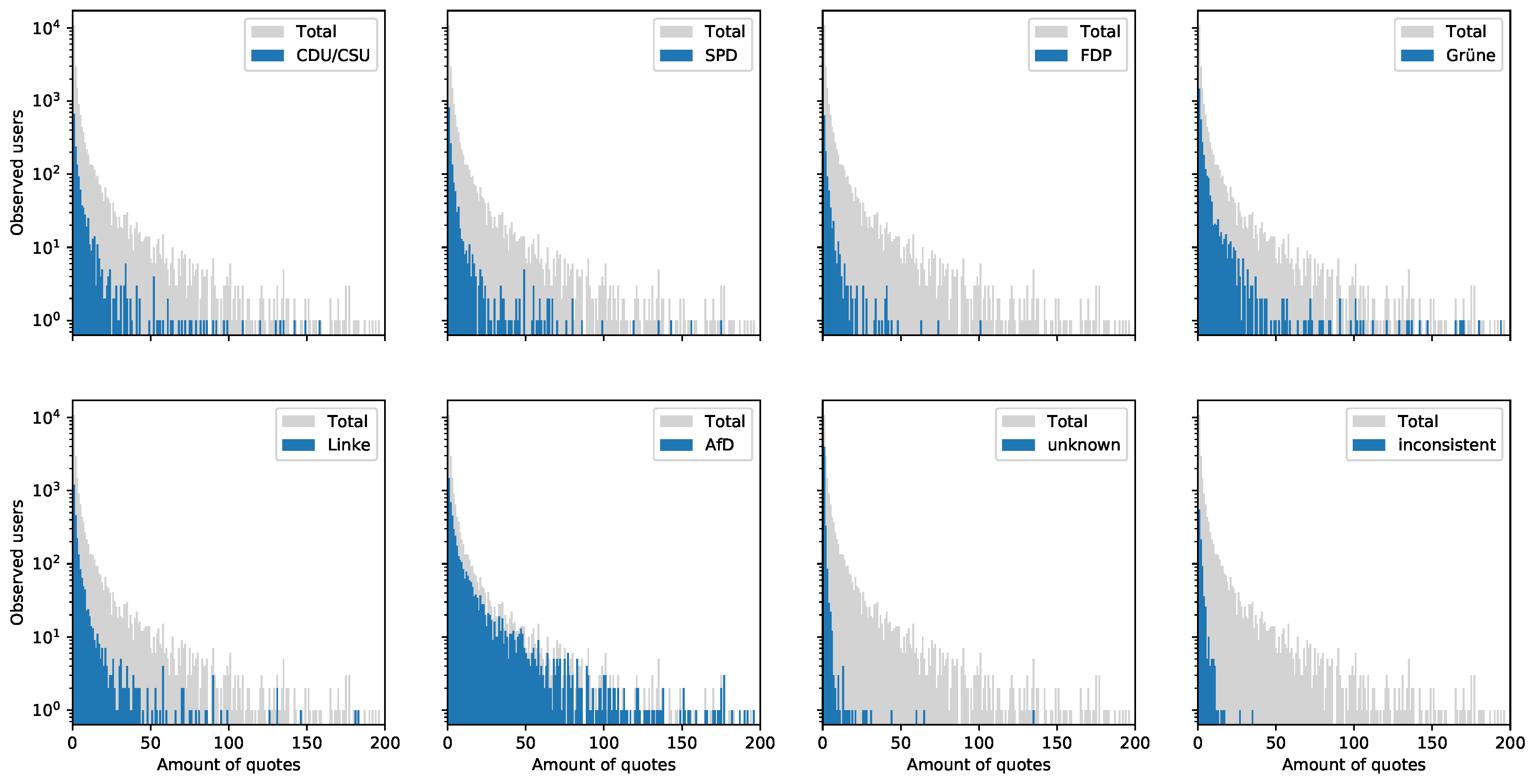
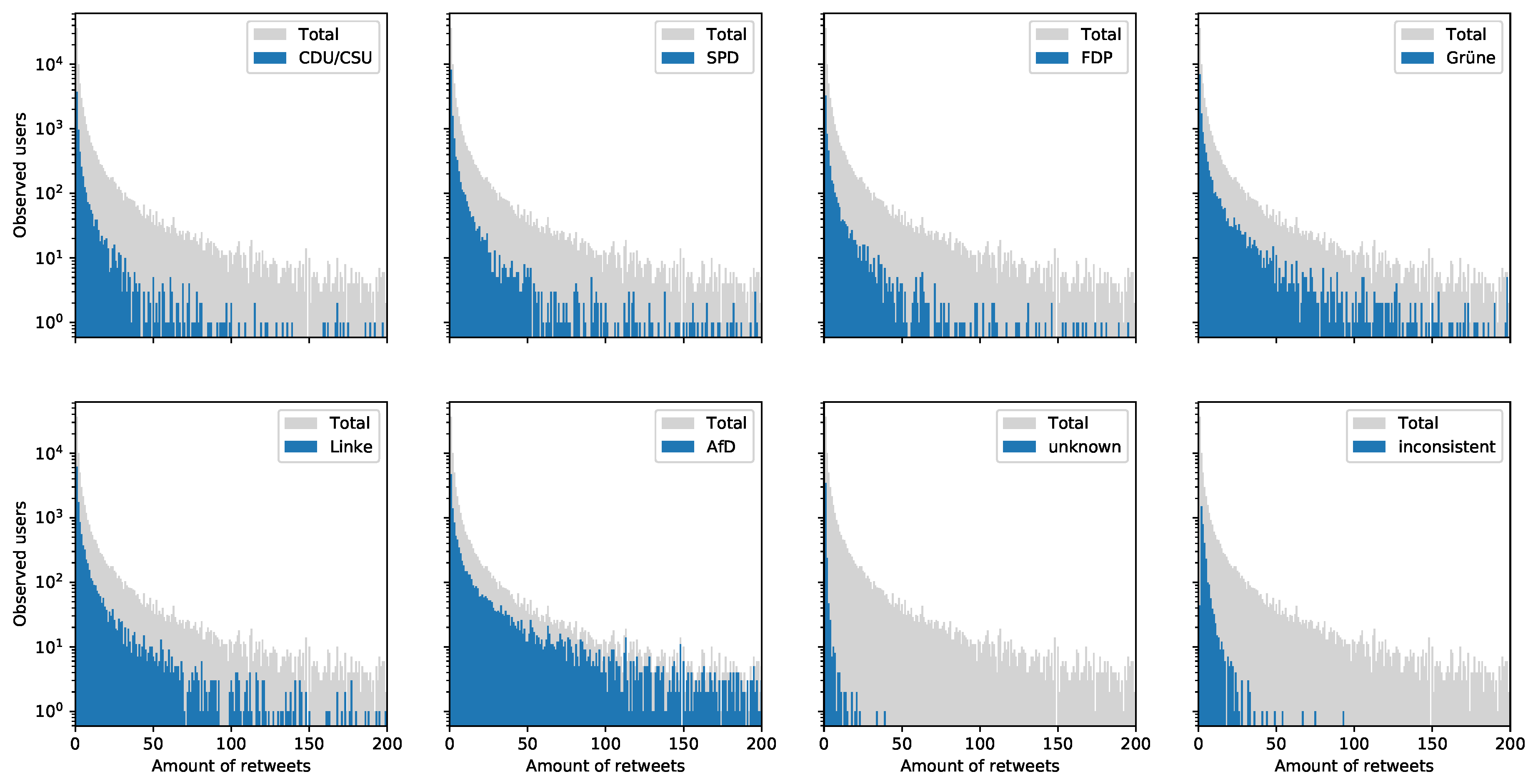
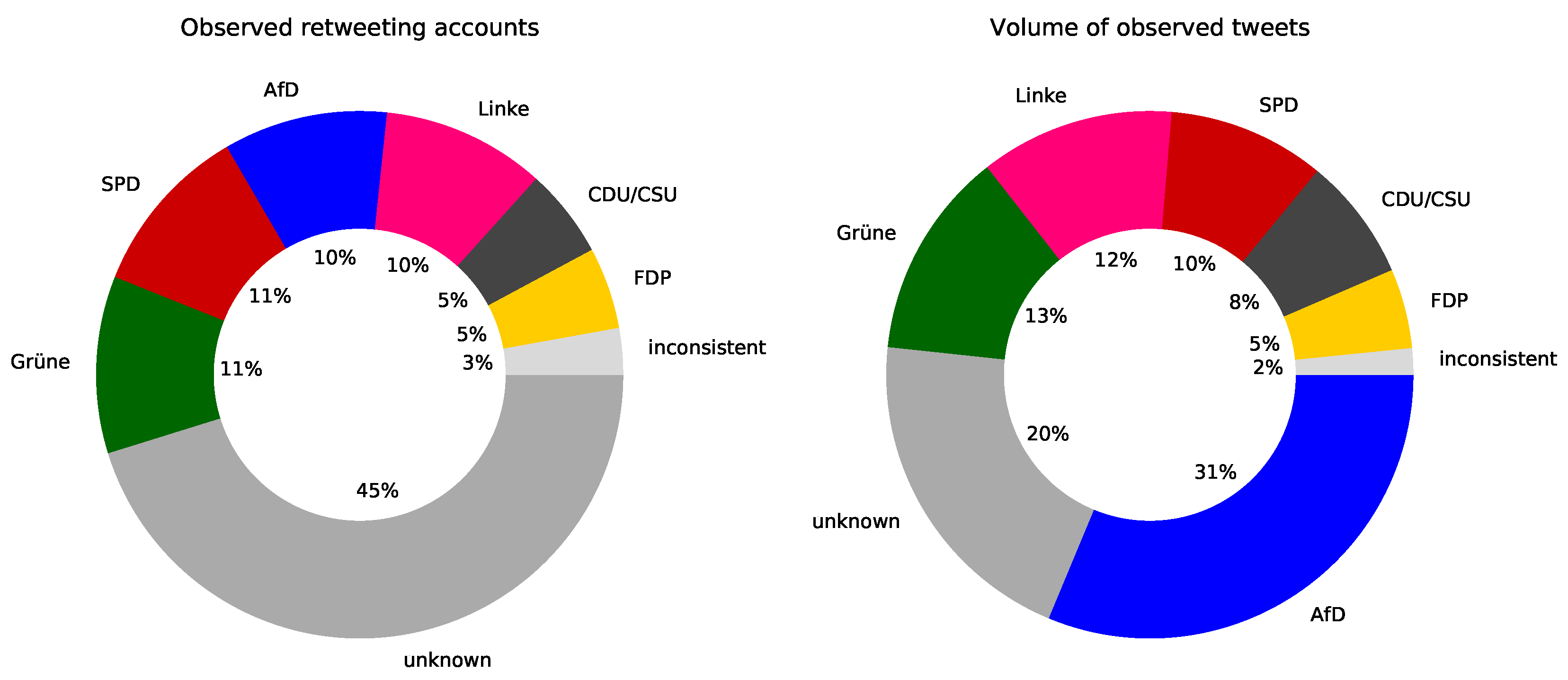
3.3. Re-Tweeting Twitter Users per Party
- If a Twitter user re-tweets mostly tweets of one political party, this user is assigned to that party. This group is likely to contain a higher-than-average amount of voting for the respective party.
- A user is assigned to the group ‘inconsistent’ if the user re-tweets tweets of more than one political party. This group may contain so called swing-voters. However and according to Figure 3, this group is quite small, and an in-depth analysis shows that many these kinds of accounts are newspapers, radio or TV-stations that try not to re-tweet disproportionately high content of a specific party.
- If a Twitter user re-tweets no tweets of any political party, this user is assigned to the group ‘unknown’. This group contain voters where little can be derived from the re-tweeting behavior. Figure 3 shows that approximately 45% of all observed Twitter users can not be assigned to a political party simply by looking at their re-tweeting behavior. This share of “unknowns” might be reducible by applying more sophisticated natural language processing-based analysis of quotes, replies and status messages (which was not done for this dataset description).
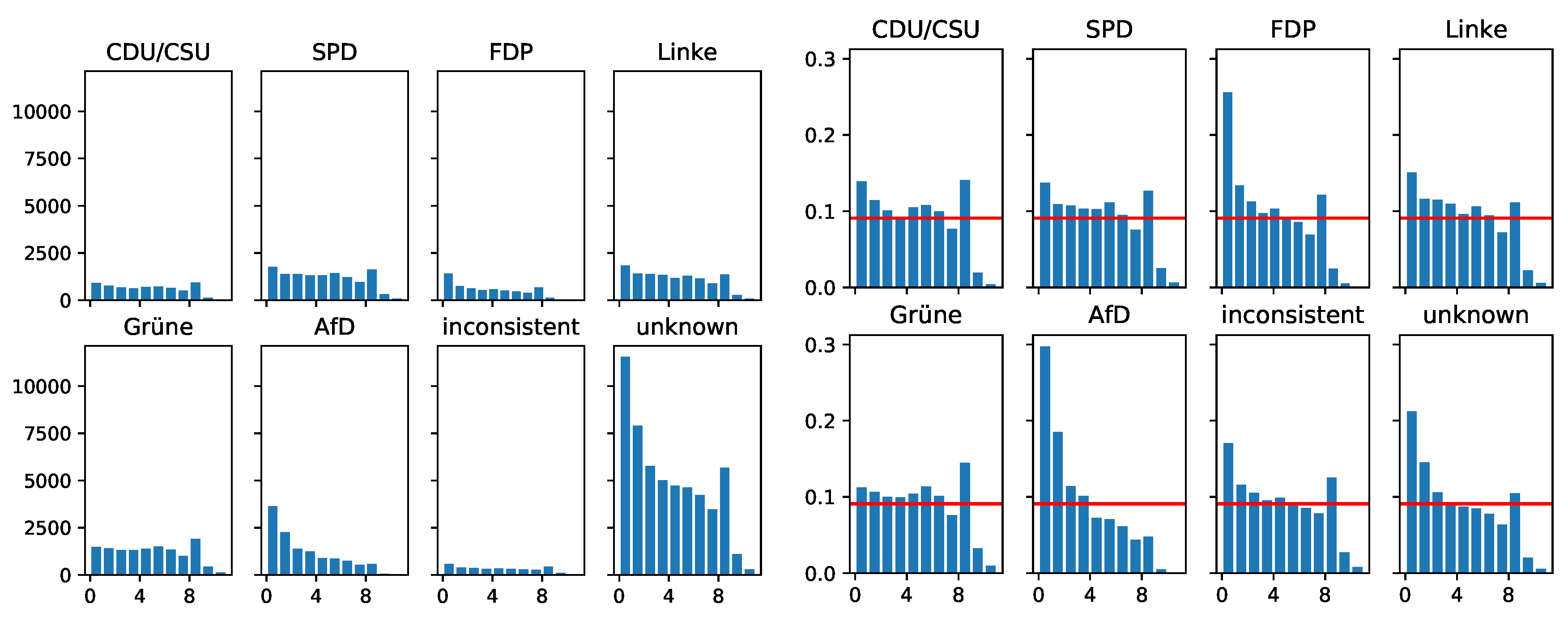
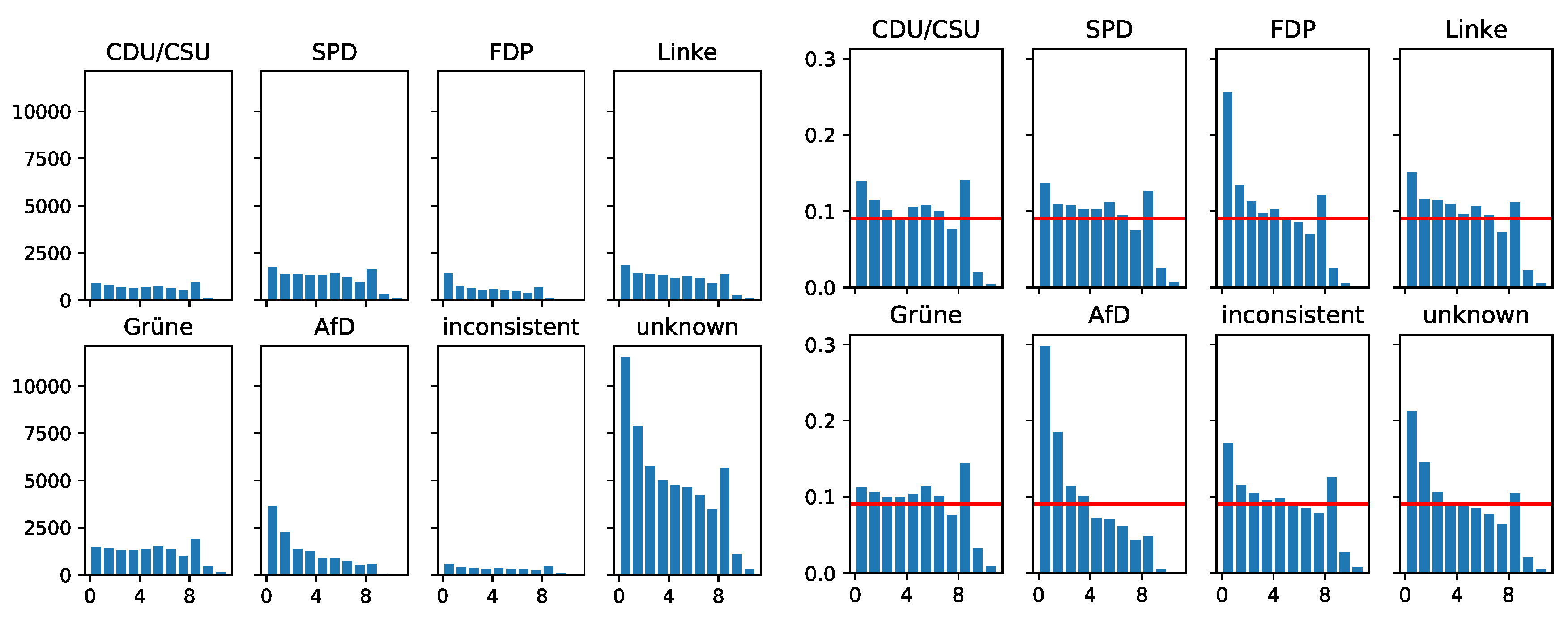
3.4. Account Ages of Party Re-Tweeters
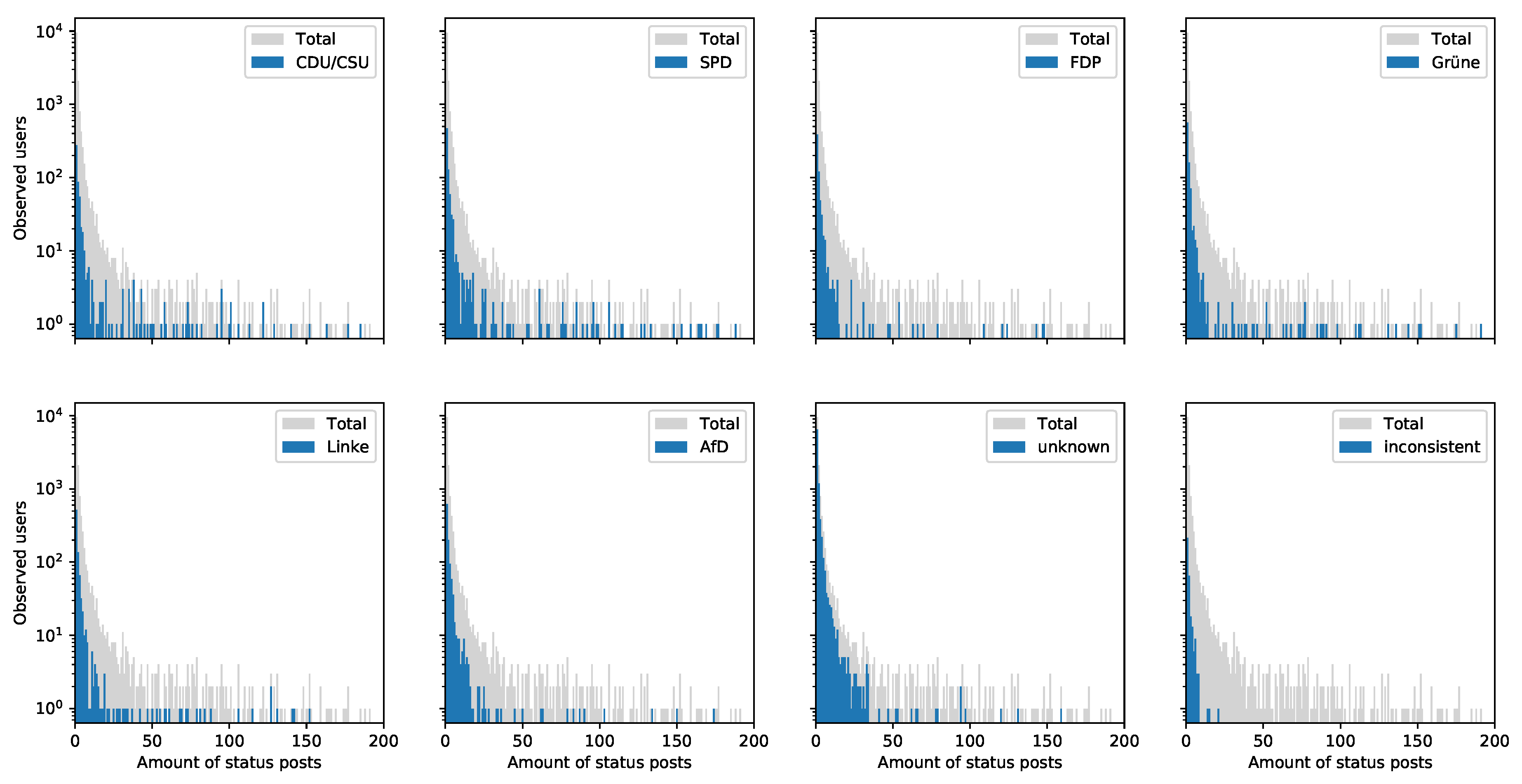
3.5. “Loudness” of Party Re-Tweeters
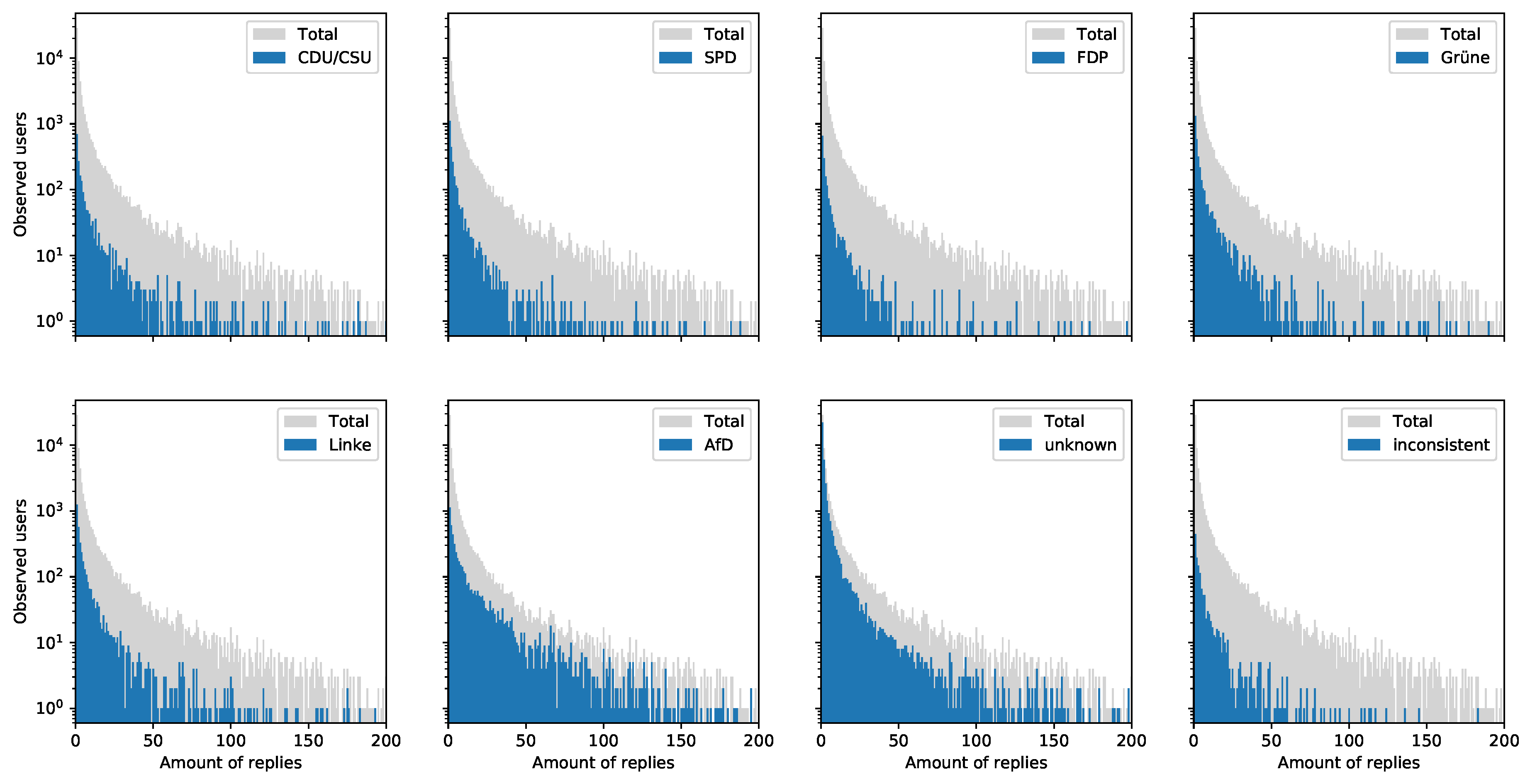
- Taking Figure 5, we see that only users with unknown party proximity tend to post slightly more status posts, but the status posting behavior seems quite comparable across all groups.
- Figure 6 shows that the reply behavior of re-tweeters of established parties like CDU/CSU, SPD, FDP, Grüne and Linke is comparable. However, re-tweeters of the right-wing populist AfD and the group of “unknowns” seem to dominate the reply space. It would be interesting to analyze whether these replies correlate with the postulated “hate-speech” phenomenon that was criticized mainly by established political parties during the election campaigns.
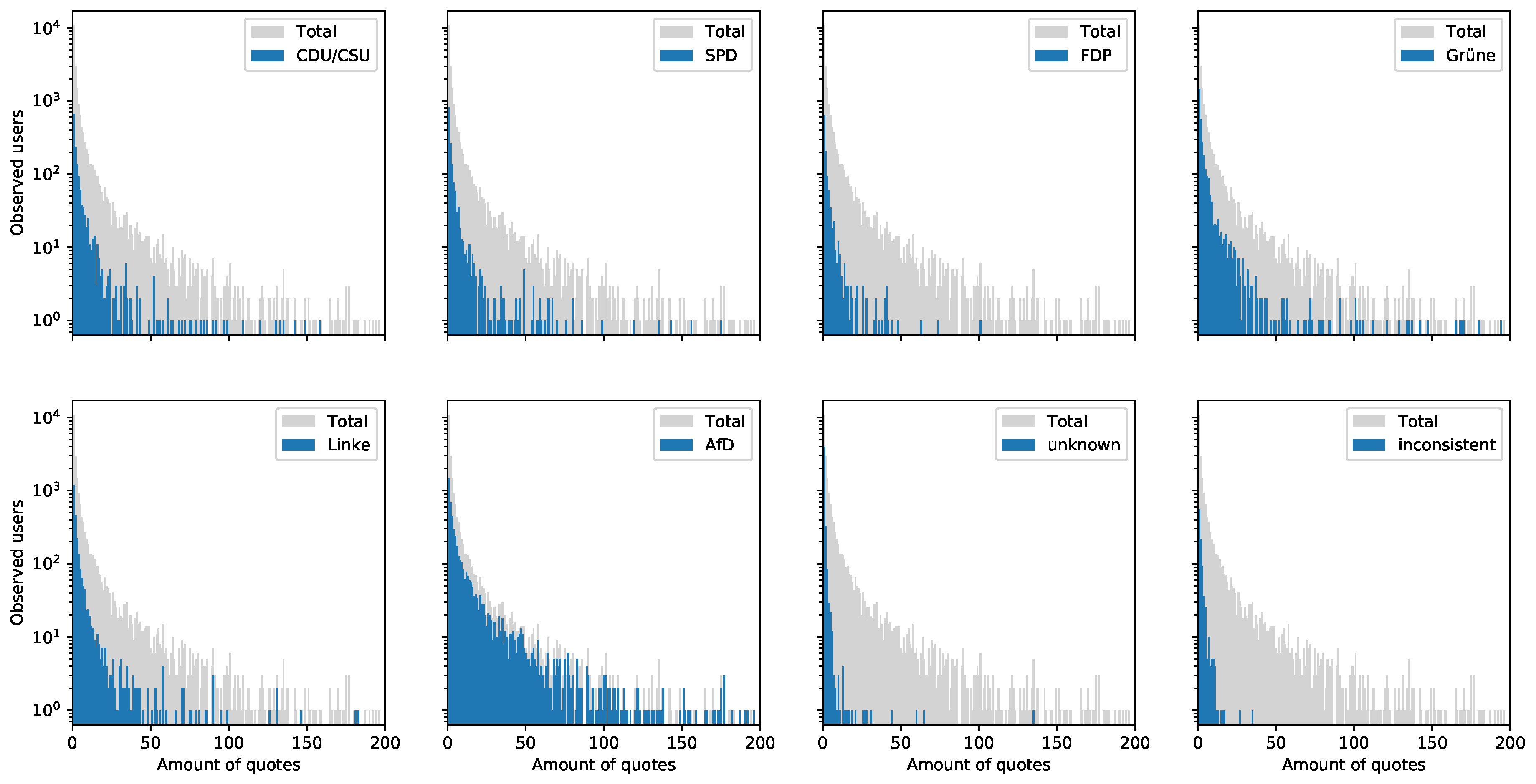
- Figure 7 visualizes the quoting loudness and clearly indicates that quoting is substantially done by re-tweeters of the right-wing populist AfD. It would be interesting to determine whether quoting is used to discredit systematically other political positions. This would be a behavior that is meant to be specific for populist parties.
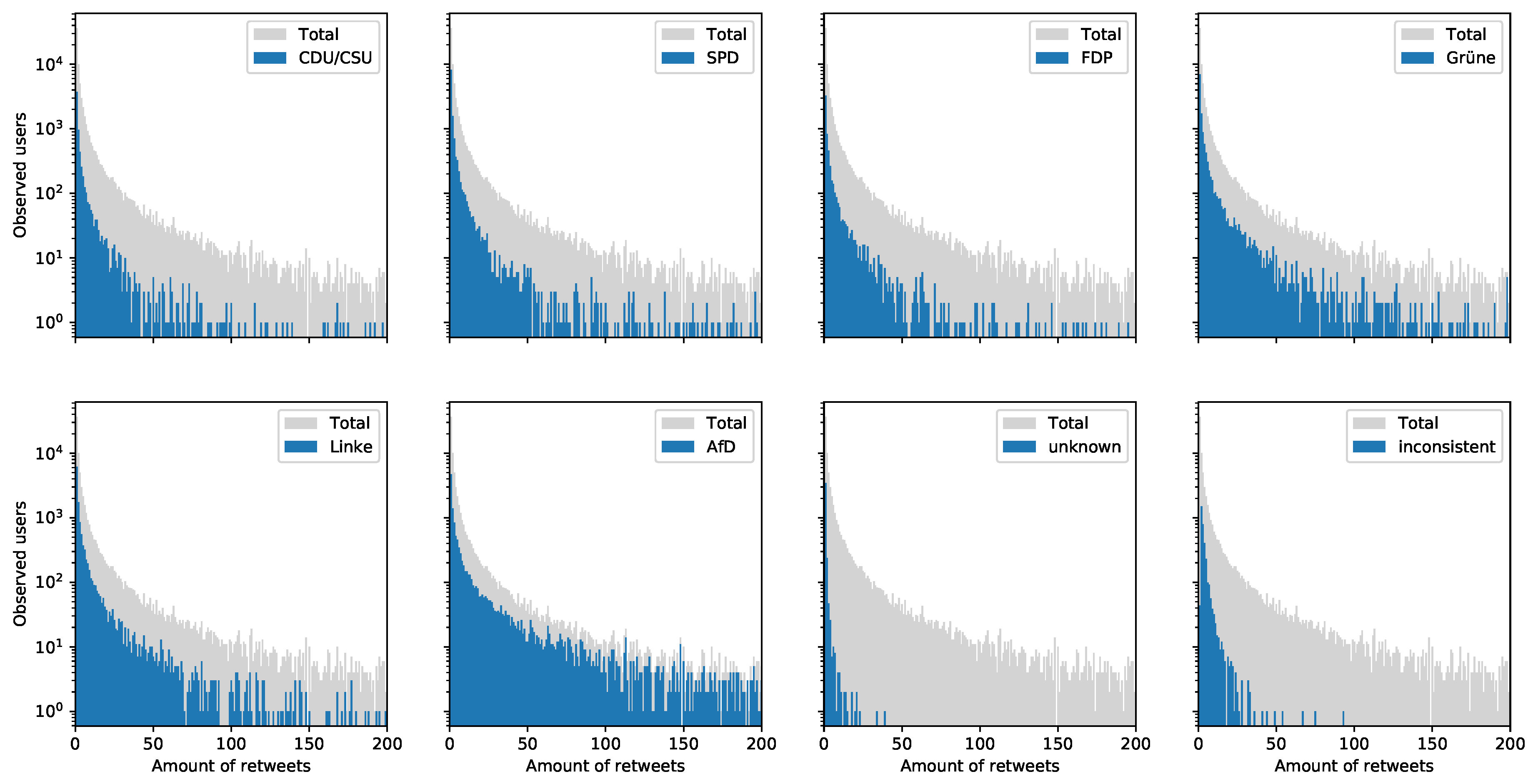
- Figure 8 shows that re-tweets are applied disproportionately high by the right-wing populist AfD and the group of “unknowns”. Left-wing parties like SPD, Linke and Grüne seem to have slightly more re-tweets than conservative or liberal parties like CDU/CSU and FDP. Furthermore, it would be interesting to analyze what kind of tweets are re-tweeted more often. That would be valuable for parties in order to curate attractive political content.
4. Data Use and Application
4.1. Limitations due to Twitter User Protection Terms and Ethical Considerations
- A Twitter account does not automatically belong to a physical person. It is not unlikely that Twitter accounts belong to a company, an organization or is operated by staff of social media experts on behalf of a person of public interest or organizational function.
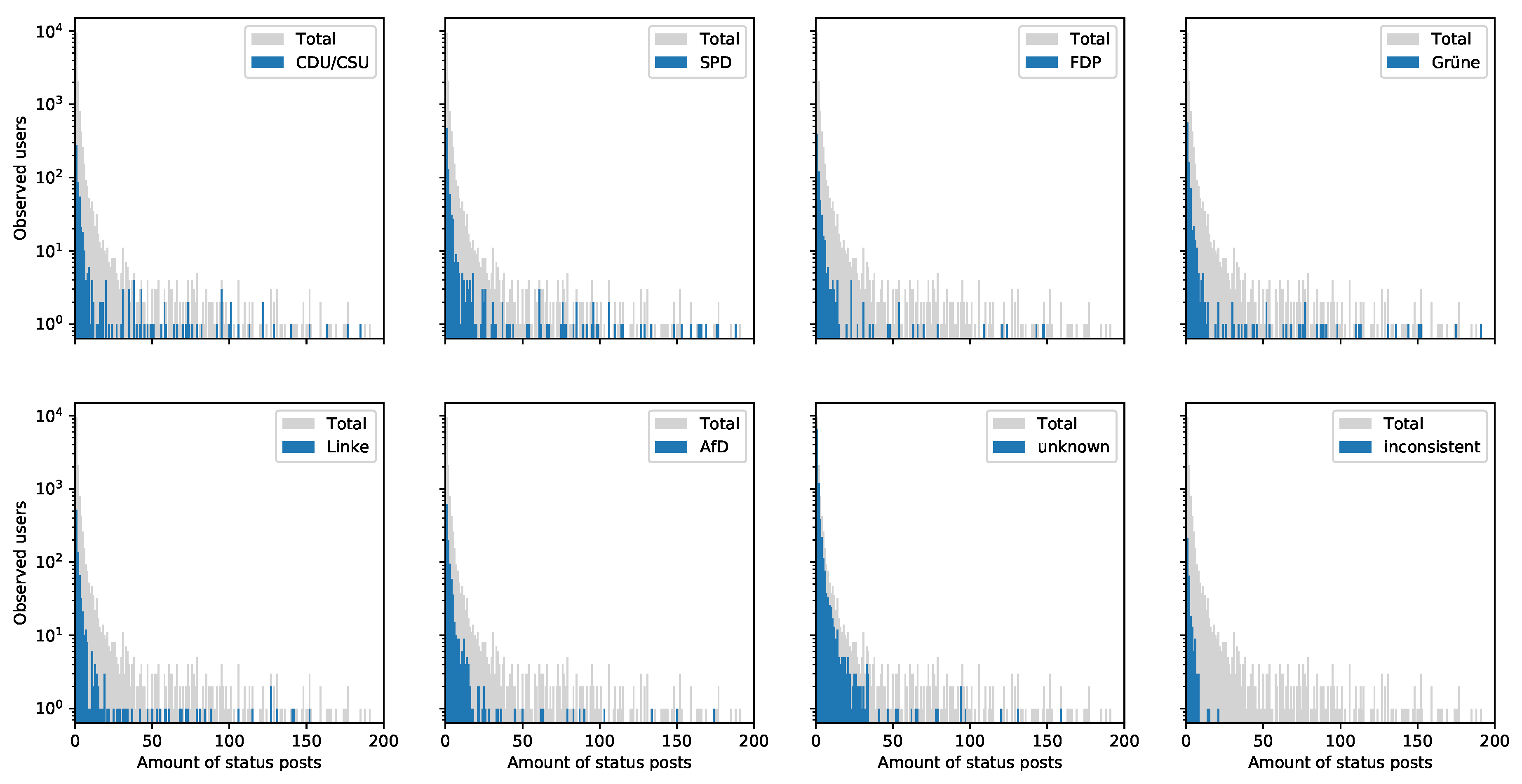
- To draw any conclusions for specific accounts is for the vast portion of this dataset statistically questionable. For instance, more than 75% of all observed users re-tweeted less than three times. To derive a party preference for a specific account on so few data is questionable. The dataset intends to enable deriving conclusions for the re-tweeted party, but not for specific re-tweeters. The reader should consider the following Section 4.2 to consider such statistical limitations.
4.2. Statistical Limitations to Determine the Party Proximity of Specific Accounts
4.3. Technical Recording Limitations for the Analysis to Be Considered
4.4. How This Dataset Can Be Used
- The dataset can be used to understand the mechanisms of hate-speech, populism and the correlated network structures better. It might be even used as training data for social media providers to identify German hate-speech more accurately.
- The dataset can be used to study how Twitter interactions like replies and quotes could be used to optimize the classification of Twitter accounts. This will likely involve the application of machine learning and NLP measures.
- Analyzing the network structure might help to identify influencing and multiplying Twitter accounts. These kind of accounts might be of particular interest for social media campaign strategists.
- The analysis of the strength and weaknesses in network structures can be analyzed to be considered effective in political communication.
- Election campaigns try to reach so-called swing-voters. However, according to the observed re-tweeting behavior, only 3% of all Twitter users re-tweet the content of different political parties. Therefore, the focus on hardly detectable swing-voters might have limited effects.
- The dataset can be used to investigate the limitations in targeting specific citizens. According to this dataset, most observed Twitter users seem to be inactive, making it hard to derive account-specific conclusions. Therefore, the question arises whether micro-targeting approaches are really useful for most social media users.
- Tweet data: https://dev.twitter.com/overview/api/tweets
- User data: https://dev.twitter.com/overview/api/users
- Entity data (hashtags, media URLs, user mentions): https://dev.twitter.com/overview/api/entities
4.5. Processing the Dataset Using Twista
| Listing 1: Installing Twista |
git clone https://github.com/nkratzke/twista.git |
cd twista |
pip3 install . |
5. Dataset Availability
6. Conclusions
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| JSON | JavaScript Object Notation (a text-based serialization format) |
| URL | Uniform Resource Locator |
| U.S. | United States (of America) |
| TV | Television |
| ZIP | An archive file format that supports lossless data compression |
Appendix A. Followed and Categorized Twitter Screen Names (follow.json)
| Listing 2: follow.json |
"CDU/CSU": [ |
"Klimke_CDU", "steffenbilger", "VolkmarKlein", "kretsc", "PSchnieder", "MatthiasHauer", "UweSchummer", |
"IngbertLiebing", "armin_schuster", "plengsfeld", "mechthildheil", "marcusweinberg", "drthomasfeist", |
"HGundelach", "fuchtel", "cducsubt", "ManderlaGisela", "SylviaPantel", "HBraun", "georgnuesslein", |
"rbrinkhaus", "Wellenreuther", "Axel_Fischer", "YvonneMagwas", "hoffmannmdb", "JohannesSingham", |
"AWidmannMauz", "JM_Luczak", "berndfabritius", "amattfeldt", "DrAndreasNick", "karstenmoering", |
"OstermannMdB", "olavgutting", "christianhirte", "SibyllePfeiffer", "jensspahn", "tj_tweets", |
"DoroBaer", "HHirte", "peteraltmaier", "SteinekeCDU", "MaikBeermann", "MGrosseBroemer", |
"StefanKaufmann", "juergenhardt", "charlesmhuber49", "berndsiebert", "meister_schafft", |
"Thomas_Bareiss", "petertauber", "kudlaleipzig", "franksteffel", "tschipanski", "DWoehrl", |
"AlexanderRadwan", "groehe", "AndreaLindholz", "MarkHauptmann", "frankheinrich", "smuellermdb", |
"matthiaszimmer", "julia_obermeier", "dieAlbsteigerin", "schroeder_k", "VolkerUllrich", "koschyk", |
"erwin_rueddel", "Stettenchris", "guenterkrings", "janmetzler", "Manfredbehrens", "stephanharbarth", |
"BettinaHornhues", "fj_josef", "SvenVolmering", "HPFriedrichCSU", "TinaSchwarzer", "KLeikert", |
"marlenemortler", "GudrunZollner", "ruedigerkruse", "thomasgebhart", "RKiesewetter", "kaiwegner", |
"XaverJung", "helmut_nowak", "drmfuchs", "anjaweisgerber", "josteiniger", "eckhardtrehberg", |
"wanderwitz", "NadineSchoen", "jenskoeppen", "PeterWeissMdB", "manfred_grund", "MatthiasHeider", |
"hahnflo", "bernhardkaster", "DerLenzMdB", "jungfj", "ninawarken", "RonjaSchmitt", "PatrickSensburg", |
"Kai_Whittaker" |
], |
"SPD": [ |
"MartinSchulz", "sebast_hartmann", "GabiKatzmarek", "thomashitschler", "EskenSaskia", "michaelaengel", |
"SPDuesseldorf", "UlrichKelber", "GabiWeberSPD", "KarambaDiaby", "baerbelbas", "ZieglerMdB", |
"MatthiasIlgen", "kerstin_tack", "AnnetteSawade", "dieschmidt", "josip_juratovic", "michael_thews", |
"DirkWiese4", "PErnstberger", "larscastellucci", "lischkab", "KerstinGriese", "karl_lauterbach", |
"FrankeEdgar", "MartinRabanus", "arnoklare", "Schwarz_MdB", "GabiHillerOhm", "Elke_Ferner", |
"rainerarnold", "soerenbartol", "CanselK", "ulifreese", "zierke", "evahoegl", "MechthildRawert", |
"KaczmarekOliver", "marcobuelow", "MetinHakverdi", "swenschulz", "hubertus_heil", "MartinRosemann", |
"MiRo_SPD", "g_reichenbach", "FrankSchwabe", "BetMueller", "UlliNissen", "larsklingbeil", |
"waltraud_wolff", "SCLemme", "achim_p", "A_Gloeckner", "DennisRohde", "HildeMattheis", "utevogt", |
"ChristianFlisek", "kahrs", "RebmannMdB", "edrossmann", "chstraesser", "danielakolbe", "JensZimmermann1", |
"SoenkeRix", "CPetryMdB", "BurkertMartin", "HellmichMdB", "lothar_binding", "matthiasbartke", "oezoguz", |
"FlorianPost", "brigittezypries", "juergencosse", "MarcusHeld_SPD", "NielsAnnen", "florianpronold", |
"HiltrudLotze", "michaelgrossmdb", "schneidercar", "rischwasu", "LangeMdB", "muellerchemnitz", |
"jakobmierscheid", "ThomasOppermann", "SpinrathNorbert", "W_Priesmeier" |
], |
"Gruene": [ |
"nouripour", "TabeaRoessner", "katdro", "katjadoerner", "PeterMeiwald", "KoenigsGruen", "agnieszka_mdb", |
"stephankuehn", "FOstendorff", "KonstantinNotz", "RenateKuenast", "MariaKlSchmeink", "IreneMihalic", |
"ekindeligoez", "jtrittin", "oezcanmutlu", "KaiGehring", "Luise_Amtsberg", "steffilemke", "MarkusTressel", |
"tobiaslindner", "GrueneBundestag", "fbrantner", "ChrisKuehn_mdb", "W_SK", "SteffiLemke", "GrueneBeate", |
"markuskurthmdb", "OezcanMutlu", "ulle_schauws", "ManuelSarrazin", "beatewaro", "terpeundteam", |
"petermeiwald", "GoeringEckardt", "kerstinandreae", "MarieluiseBeck", "Uwekekeritz", "BrigittePothmer", |
"Volker_Beck", "GruenSprecher", "ABaerbock", "gruenebundestag", "DorisWagner_MdB", "BriHasselmann", |
"die_gruenen", "ebner_sha", "monikalazar", "DieschbourgC", "NicoleMaisch", "renatekuenast", "cem_oezdemir", |
"DJanecek", "LisaPaus", "WilmsVal", "sven_kindler", "BaerbelHoehn", "julia_verlinden", "BabettesChefin", |
"crueffer", "Oliver_Krischer", "mdb_stroebele" |
], |
"Linke": [ |
"karinbinder", "Linksfraktion", "SevimDagdelen", "GUENGL", "Petra_Sitte_MdB", "DietmarBartsch", |
"HerbertBehrens", "Diether_Dehm", "ch_buchholz", "jankortemdb", "NicoleGohlke", "dielinke", |
"SuzaKarawanskij", "MWBirkwald", "ernst_klaus", "TeamPetraPau", "WolfgangGehrcke", "rosaluxstiftung", |
"AndrejHunko", "GregorGysi", "UllaJelpke", "HeikeHaensel", "WolfgangGehrcke", "RosemarieHein", |
"Annette_Groth", "berlinliebich", "jankortemdb", "Team_GLoetzsch", "JuttaKrellmann", "alexandersneu", |
"katjakipping", "conni_moehring", "NordMdb", "thlutze", "sabineleidig", "norbert_mdb", "SuzaKarawanskij", |
"MichaelLeutert", "niemamovassat", "frank_tempel", "HPetzold", "KirstenTackmann", "axeltroost", |
"Petra_Sitte_MdB", "PetraPauMaHe", "SWagenknecht", "katrin_werner", "haraldweinberg", "voglerk", |
"jwunderlichbt", "europeanleft", "NicoleGohlke", "CarenLay", "martinarenner", "halina_waw" |
], |
"FDP": [ |
"solms", "LFLindemann", "kielclaas", "christianduerr", "MarcoBuschmann", "Lambsdorff", "franksitta", |
"fdp", "HaukeHilz", "EUTheurer", "KatjaSuding", "michael_g_link", "dfoest", "c_lindner", "MAStrackZi", |
"Wissing", "johannesvogel", "kcortez66740", "MarcusFaber", "Heiner_Garg", "KemmerichThL", "Otto_Fricke", |
"KonstantinKuhle", "LindaTeuteberg", "JoachimStamp", "PascalKober", "KH_Paque", "ruppert_stefan", |
"jimmyschulz", "ManuelHoeferlin", "MarcelKlingeVS", "hansjoachimotto", "HAHNmeint", "JPirscher", |
"FlorianOtt", "Stefan_Birkner", "BundesLHG", "LoeningMarkus", "FDPEuropa" |
], |
"AfD": [ |
"poggenburgandre", "AfDKompakt", "arminpaulhampel", "fraukepetry", "joerg_meuthen", |
"beatrix_vstorch", "georg_pazderski", "julianflak", "marcuspretzell", "AfDKompakt", "afd_bund", |
"TrauDichDE" |
] |
Appendix B. Example Tweet (Raw Data)
| Listing 3: Example tweet (JSON format) " |
"created_at": "Thu Jun 01 20:20:00 +0000 2017", |
"id": 870374393628827648, |
"id_str": "870374393628827648", |
"text": "Unsere Gr\u00fcne Antwort auf Trumps Entscheidung: Raus aus der Kohle #Kohleausstieg [...]", |
"source": "<a href=\"http://twitter.com\" rel=\"nofollow\">Twitter Web Client</a>", |
"truncated": false, |
"in_reply_to_status_id": null, |
"in_reply_to_status_id_str": null, |
"in_reply_to_user_id": null, |
"in_reply_to_user_id_str": null, |
"in_reply_to_screen_name": null, |
"user": { |
"id": 4110374301, |
"id_str": "4110374301", |
"name": "Gerhard Schick", |
"screen_name": "SchickGerhard", |
"location": "Mannheim & Berlin", |
"url": "http://www.gerhardschick.net", |
"description": "Mitglied des Deutschen Bundestages, finanzpolitischer Sprecher bei @GrueneBundestag [...]", |
"protected": false, |
"verified": true, |
"followers_count": 4762, |
"friends_count": 176, |
"listed_count": 74, |
"favourites_count": 49, |
"statuses_count": 2373, |
"created_at": "Wed Nov 04 07:36:26 +0000 2015", |
"utc_offset": null, |
"time_zone": null, |
"geo_enabled": false, |
"lang": "de", |
"contributors_enabled": false, |
"is_translator": false, |
"following": null, |
"follow_request_sent": null, |
"notifications": null |
}, |
"geo": null, |
"coordinates": null, |
"place": null, |
"contributors": null, |
"is_quote_status": false, |
"retweet_count": 0, |
"favorite_count": 0, |
"entities": { |
"hashtags": [ |
{ "text": "Kohleausstieg", "indices": [65, 79] }, |
{ "text": "Divestment", "indices": [86, 97] }, |
{ "text": "Klimaschutzabkommen", "indices": [99, 119] } |
], |
"urls": [ |
{ |
"url": "https://t.co/0eJ0OM3kSH", |
"expanded_url": "https://dbtg.tv/fvid/7115264", |
"display_url": "dbtg.tv/fvid/7115264", |
"indices": [120, 143] |
} |
], |
"user_mentions": [], |
"symbols": [] |
}, |
"favorited": false, |
"retweeted": false, |
"possibly_sensitive": false, |
"filter_level": "low", |
"lang": "de", |
"timestamp_ms": "1496348400872" |
References
- Issenberg, S. How Obama’s Team Used Big Data to Rally Voters. MIT Technology Review. 19 December 2012. Available online: https://www.technologyreview.com/s/509026/how-obamas-team-used-big-data-to-rally-voters/ (accessed on 19 October 2017).
- Wagner, J. Clinton’s Data-Driven Campaign Relied Heavily on an Algorithm Named Ada. What Didn’t She See? Washington Post. 9 November 2016. Available online: https://www.washingtonpost.com/news/post-politics/wp/2016/11/09/clintons-data-driven-campaign-relied-heavily-on-an-algorithm-named-ada-what-didnt-she-see/?utmterm=.7f86c9d90768 (accessed on 19 October 2017).
- Barberá, P.; Rivero, G. Understanding the Political Representativeness of Twitter Users. Soc. Sci. Comput. Rev. 2015, 33, 712–729. [Google Scholar] [CrossRef]
- Morstatter, F.; Pfeffer, J.; Liu, H.; Carley, K.M. Is the Sample Good Enough? Comparing Data from Twitter’s Streaming API with Twitter’s Firehose. CoRR 2013, arXiv:1306.5204. [Google Scholar]
- Wang, Y.; Callan, J.; Zheng, B. Should We Use the Sample? Analyzing Datasets Sampled from Twitter’s Stream API. ACM Trans. Web 2015, 9, 1–23. [Google Scholar] [CrossRef]
- Abreu, J.; Almeida, P.; Silva, T. From Live TV Events to Twitter Status Updates—A Study on Delays. In Applications and Usability of Interactive TV; Springer International Publishing: Cham, Switzerland, 2016; Volume 605, pp. 105–120. [Google Scholar]
- Jungherr, A. Tweets and Votes, a Special Relationship: The 2009 Federal Election in Germany. In Proceedings of the 2nd Workshop on Politics, Elections and Data, PLEAD ’13, San Francisco, CA, USA, 28 October 2013; pp. 5–14. [Google Scholar]
- Wang, H.; Can, D.; Kazemzadeh, A.; Bar, F.; Narayanan, S.S. A System for Real-time Twitter Sentiment Analysis of 2012 U.S. Presidential Election Cycle. In Proceedings of the ACL 2012 System Demonstrations, ACL’12, Jeju Island, Korea, 10 July 2012. [Google Scholar]
- Gayo-Avello, D.; Metaxas, P.T.; Mustafaraj, E. Limits of Electorol Predictions Using Twitter. In Proceedings of the 5th International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Straus, J.R.; Glassman, M.E. Social Media in Congress: The Impact of Electronic Media on Member Communications Analyst on the Congress; Technical Report; Congressional Research Service: Washington, DC, USA, 2016.
- Cook, J.M. Twitter Adoption and Activity in U.S. Legislatures: A 50-State Study. Am. Behav. Sci. 2017, 61, 724–740. [Google Scholar] [CrossRef]
- Waisbord, S.; Amado, A. Populist communication by digital means: Presidential Twitter in Latin America. Inf. Commun. Soc. 2017, 20, 1330–1346. [Google Scholar] [CrossRef]
- Sang, E.T.K.; Bos, J. Predicting the 2011 Dutch Senate Election Results with Twitter. In Proceedings of the Workshop on Semantic Analysis in Social Media, Avignon, France, 23 April 2012. [Google Scholar]
- Tumasjan, A.; Sprenger, T.; Sandner, P.; Welpe, I. Predicting elections with twitter: What 140 characters reveal about political sentiment. In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010; pp. 178–185. [Google Scholar]
- Papakyriakopoulos, O.; Shahrezaye, M.; Thieltges, A.; Medina Serrano, J.C.; Hegelich, S. Social Media und Microtargeting in Deutschland. Inform. Spektrum 2017, 40, 327–335. [Google Scholar] [CrossRef]
- Speriosu, M.; Sudan, N.; Upadhyay, S.; Baldridge, J. Twitter Polarity Classification with Label Propagation over Lexical Links and the Follower Graph. In Proceedings of the 1st Workshop on Unsupervised Learning in NLP, EMNLP’11, Edinburgh, Scotland, 30 July 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 53–63. [Google Scholar]
- Fraisier, O.; Cabanac, G.; Pitarch, Y.; Besançon, R.; Boughanem, M. Uncovering Like-minded Political Communities on Twitter. In Proceedings of the ACM SIGIR International Conference on Theory of Information Retrieval, ICTIR 2017, Amsterdam, The Netherlands, 1–4 October 2017; pp. 261–264. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Hagberg, A.A.; Schult, D.A.; Swart, P.J. Exploring network structure, dynamics, and function using NetworkX. In Proceedings of the 7th Python in Science Conference (SciPy2008), Pasadena, CA, USA, 19–24 August 2008; pp. 11–15. [Google Scholar]
- Kratzke, N. Twista—A Twitter Streaming and Analysis Tool Suite. 2017. Available online: https://doi.org/10.5281/zenodo.845857 (accessed on 19 October 2017).
- Manola, N.; Rettberg, N.; Manghi, P. OpenAIREplus Project Executive Report. Technical Report. 2015. Available online: https://doi.org/10.5281/zenodo.15464 (accessed on 19 October 2017).
| 1. | Martin Schulz was the President of the European Parliament before being nominated as chancellor candidate by the Social Democratic Party (SPD). |
| 2. | It is important to note that it is not shown how old the owner of the Twitter account is. It is shown how old the Twitter accounts since creation are. |
| 3. | See https://dev.twitter.com/overview/terms/agreement-and-policy (especially Part VII. Other Important Terms; A–User Protection). |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Party | Twitter Accounts | Seats in | Description | |
|---|---|---|---|---|
| Crawled | Active | 18th Bundestag | ||
| CDU/CSU | 105 (34%) | 93 (89%) | 309 | The Christian Democratic Union of Germany is a Christian democratic (German: Christlich Demokratische Union Deutschlands) and liberal-conservative political party in Germany. It is the major catch-all party of the center-right in German politics. The CDU forms the CDU/CSU faction, also known as the Union, in the Bundestag with its Bavarian counterpart the Christian Social Union in Bavaria (CSU). |
| SPD | 86 (45%) | 84 (98%) | 193 | The Social Democratic Party of Germany (German: Sozialdemokratische Partei Deutschlands, SPD) is a social-democratic political party in Germany. The party is one of the two major contemporary political parties in Germany, along with the Christian Democratic Union (CDU). |
| Linke | 60 (94%) | 49 (82%) | 64 | The Left (German: Die Linke), also commonly referred to as the Left Party, is a democratic socialist and left-wing populist political party in Germany. The party was founded in 2007 as the merger of the Party of Democratic Socialism (PDS) and the Electoral Alternative for Labour and Social Justice (WASG). |
| Grüne | 62 (98%) | 56 (90%) | 63 | Alliance 90/The Greens, often simply Greens, (German: Bündnis 90/Die Grünen or Grüne) is a green political party in Germany, formed from the merger of the German Green Party (founded in West Germany in 1980) and Alliance 90 (founded during the Revolution of 1989–1990 in East Germany) in 1993. The focus of the party is on ecological, economic and social sustainability. |
| FDP | 39 (-) | 36 (92%) | 0 | The Free Democratic Party (German: Freie Demokratische Partei, FDP) is a classical liberal political party in Germany. In the 2013 federal election, the FDP failed to win any directly-elected seats in the Bundestag and came up short of the 5 percent threshold to qualify for list representation. The FDP was therefore left without representation in the Bundestag for the first time in its history. |
| AfD | 12 (-) | 10 (83%) | 0 | Alternative for Germany (German: Alternative für Deutschland, AfD) is a right-wing populist and Eurosceptic political party in Germany founded in 2012/2013. The AfD was founded as a center-right conservative party of the middle class with a ‘soft’ Euroscepticism, being generally supportive of Germany’s membership in the European Union, but critical of further European integration, the existence of the euro currency and the bailouts by the Eurozone for countries such as Greece. Over the years, the party has become more and more nationalistic. |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kratzke, N. The #BTW17 Twitter Dataset–Recorded Tweets of the Federal Election Campaigns of 2017 for the 19th German Bundestag. Data 2017, 2, 34. https://doi.org/10.3390/data2040034
Kratzke N. The #BTW17 Twitter Dataset–Recorded Tweets of the Federal Election Campaigns of 2017 for the 19th German Bundestag. Data. 2017; 2(4):34. https://doi.org/10.3390/data2040034
Chicago/Turabian StyleKratzke, Nane. 2017. "The #BTW17 Twitter Dataset–Recorded Tweets of the Federal Election Campaigns of 2017 for the 19th German Bundestag" Data 2, no. 4: 34. https://doi.org/10.3390/data2040034
APA StyleKratzke, N. (2017). The #BTW17 Twitter Dataset–Recorded Tweets of the Federal Election Campaigns of 2017 for the 19th German Bundestag. Data, 2(4), 34. https://doi.org/10.3390/data2040034