
Contrastive Self-Supervised Learning for Stress Detection from ECG Data


Abstract
:1. Introduction
2. Related Works
2.1. Stress Detection from ECG Data
2.2. Self-Supervised Learning Applied to ECG Data
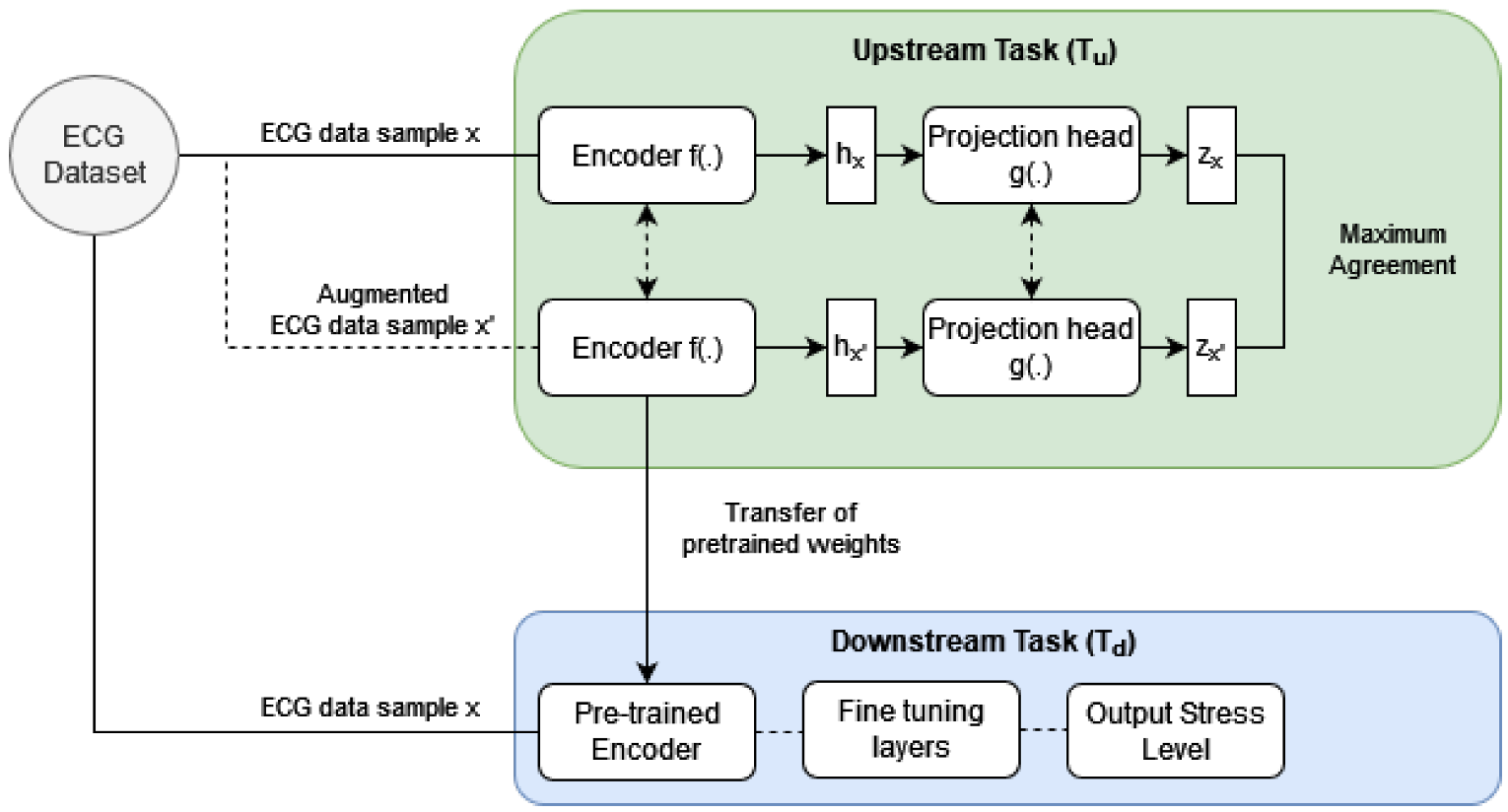
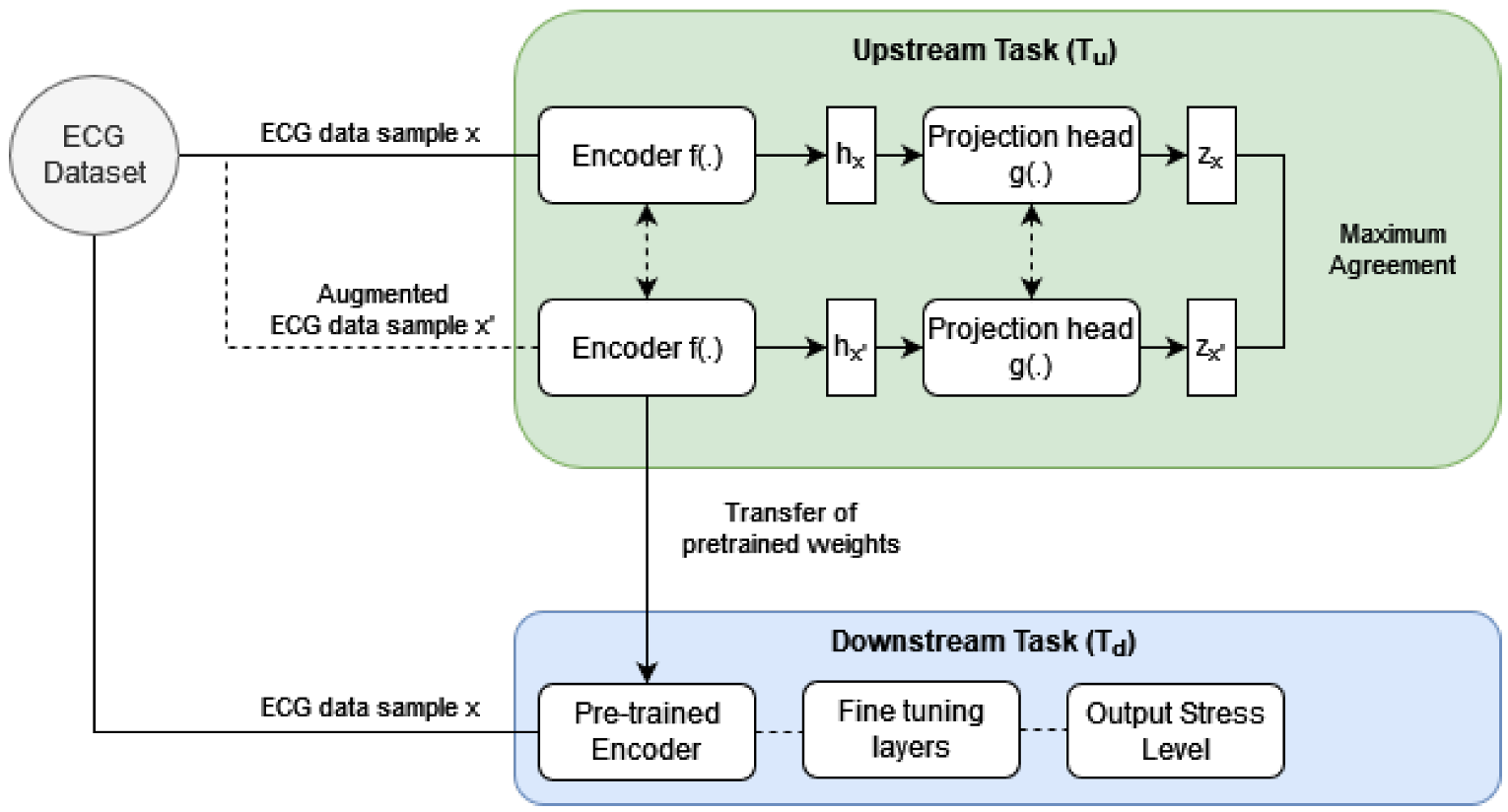
3. Proposed Method
3.1. Overview of the Upstream Task ()
3.1.1. Upstream Task: Encoder f(.)
3.2. Upstream Task: Projection Head g(.)
3.3. Upstream Task: Data Transformation (Augmentation) Task
3.4. Upstream Task: Objective Function
3.5. Downstream Task
3.6. Dataset
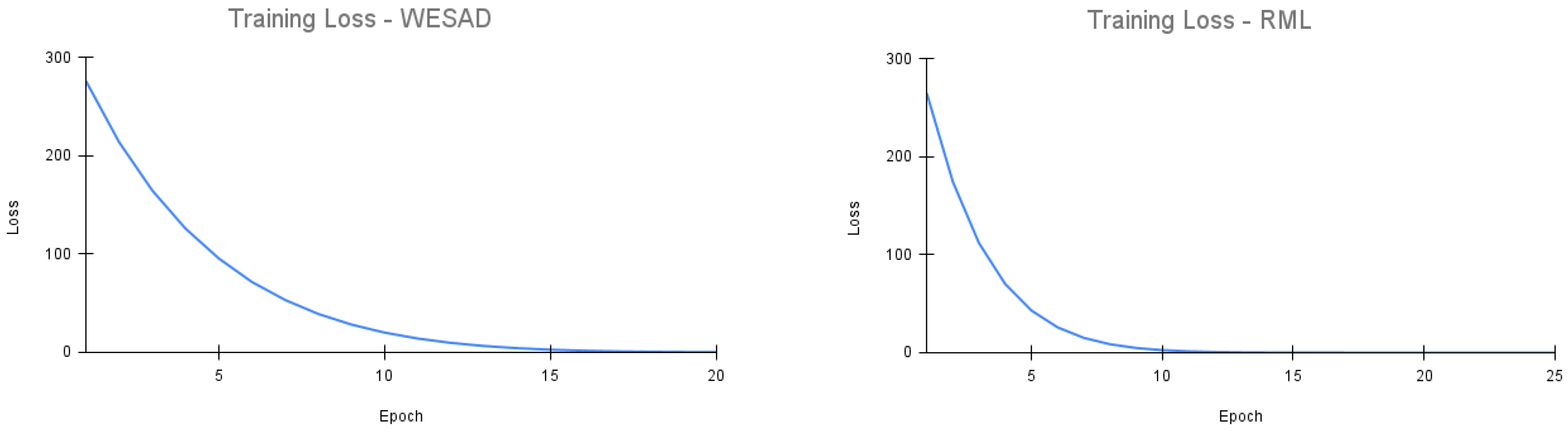
3.7. Experimentation
4. Results
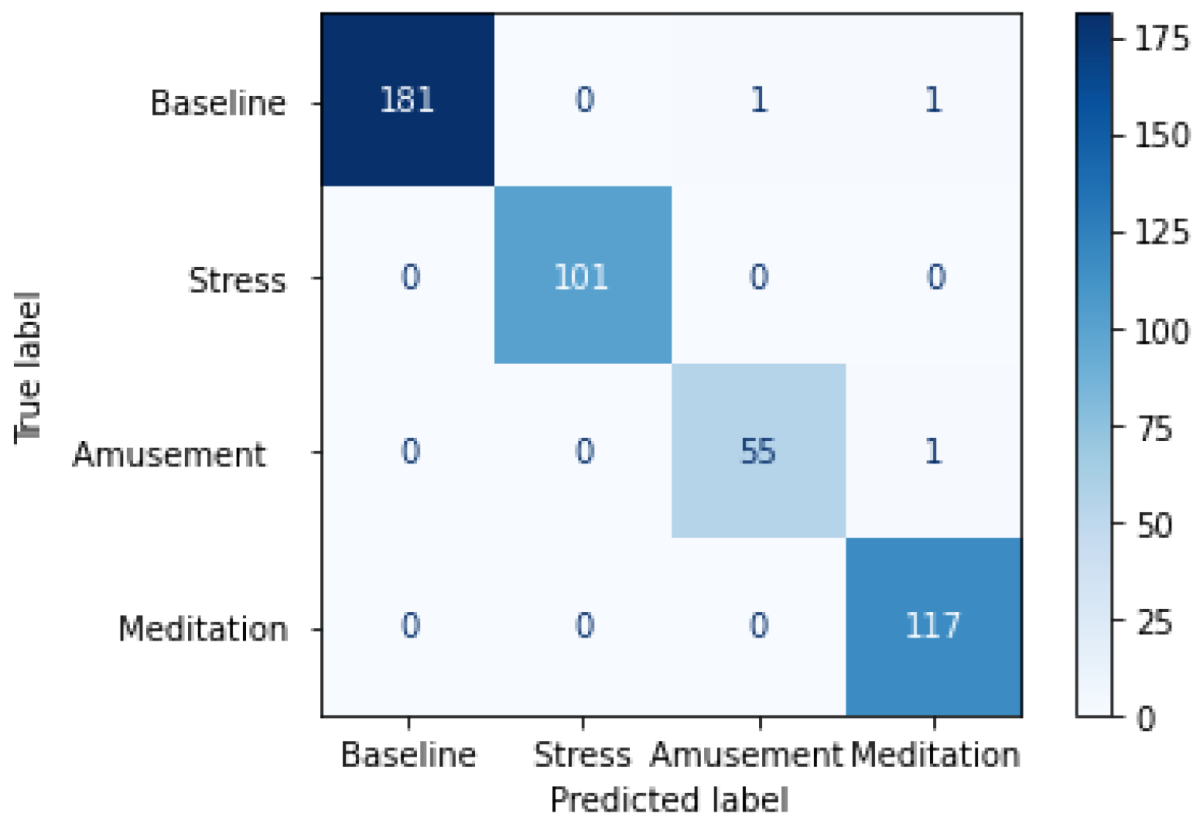
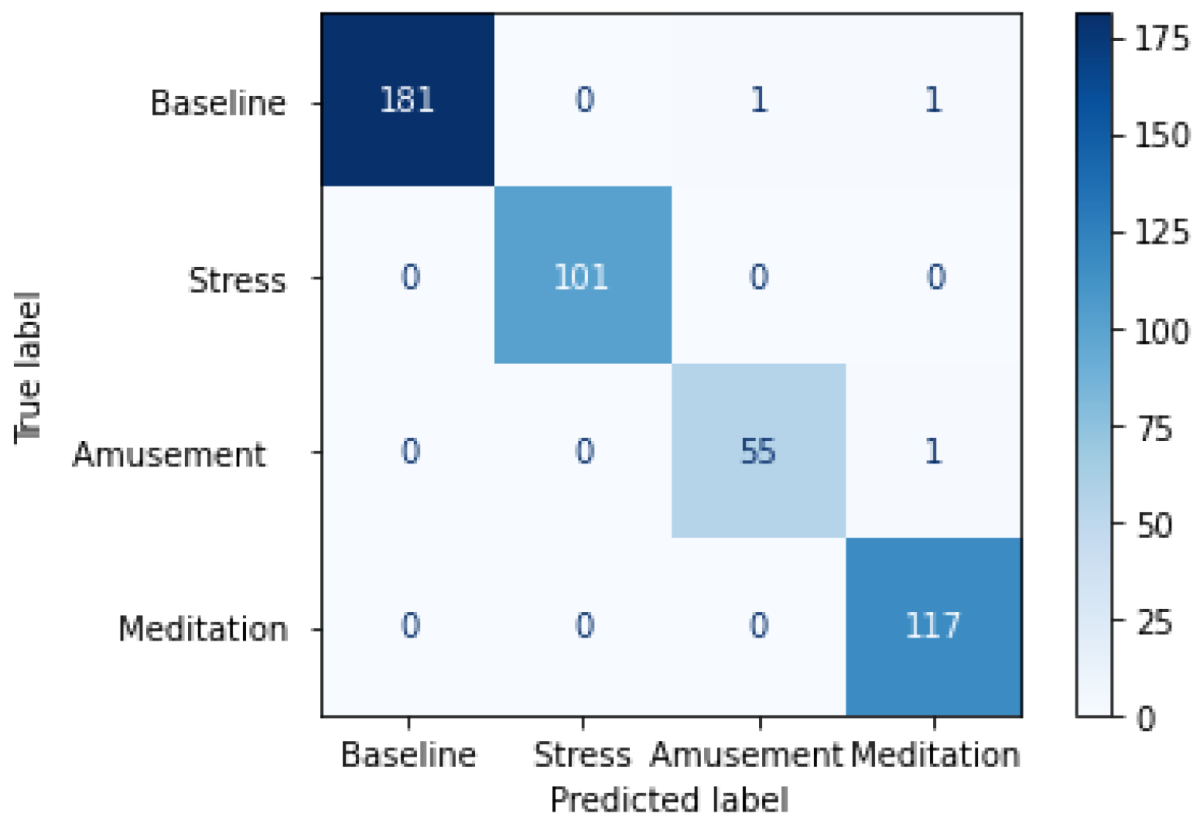
4.1. Results on WESAD Dataset
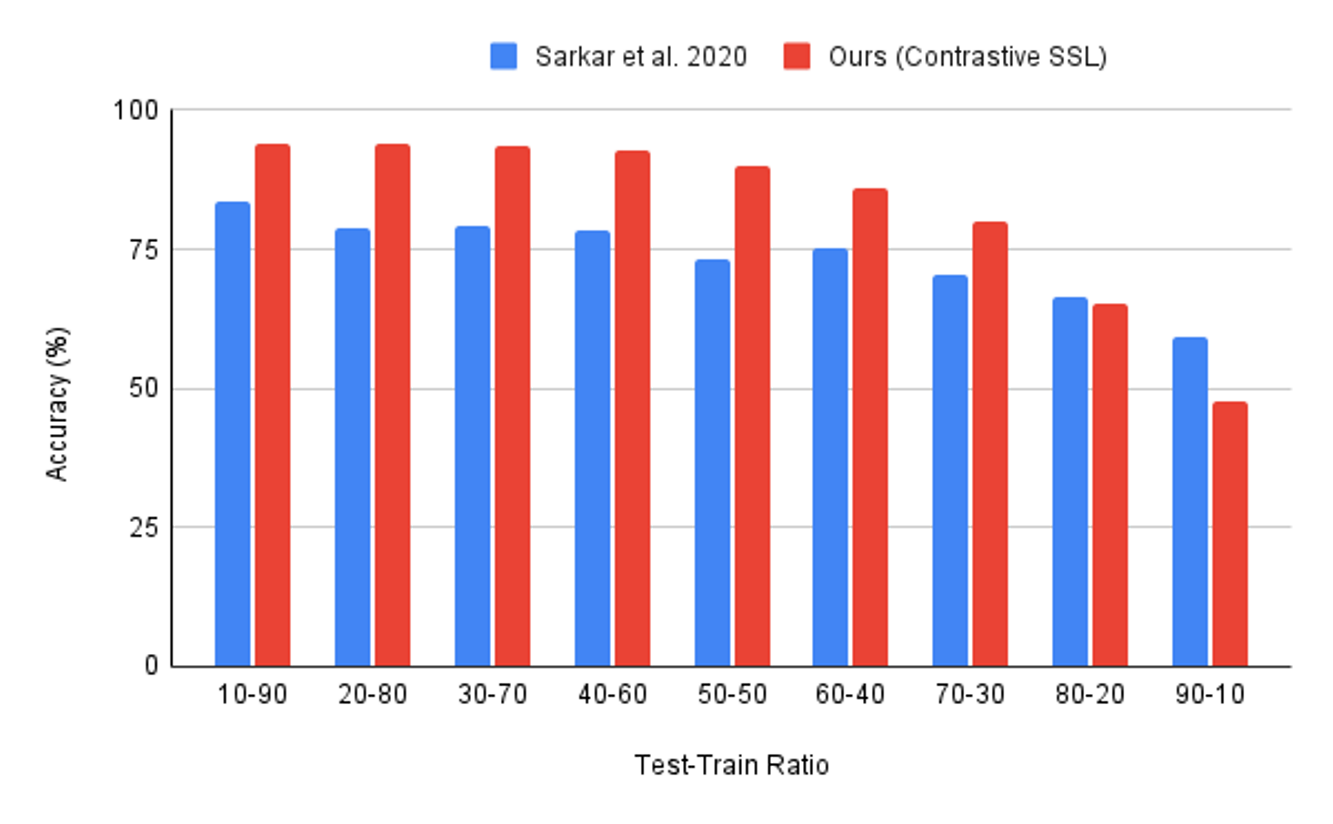
4.1.1. WESAD: Comparison of Results with State-of-Art
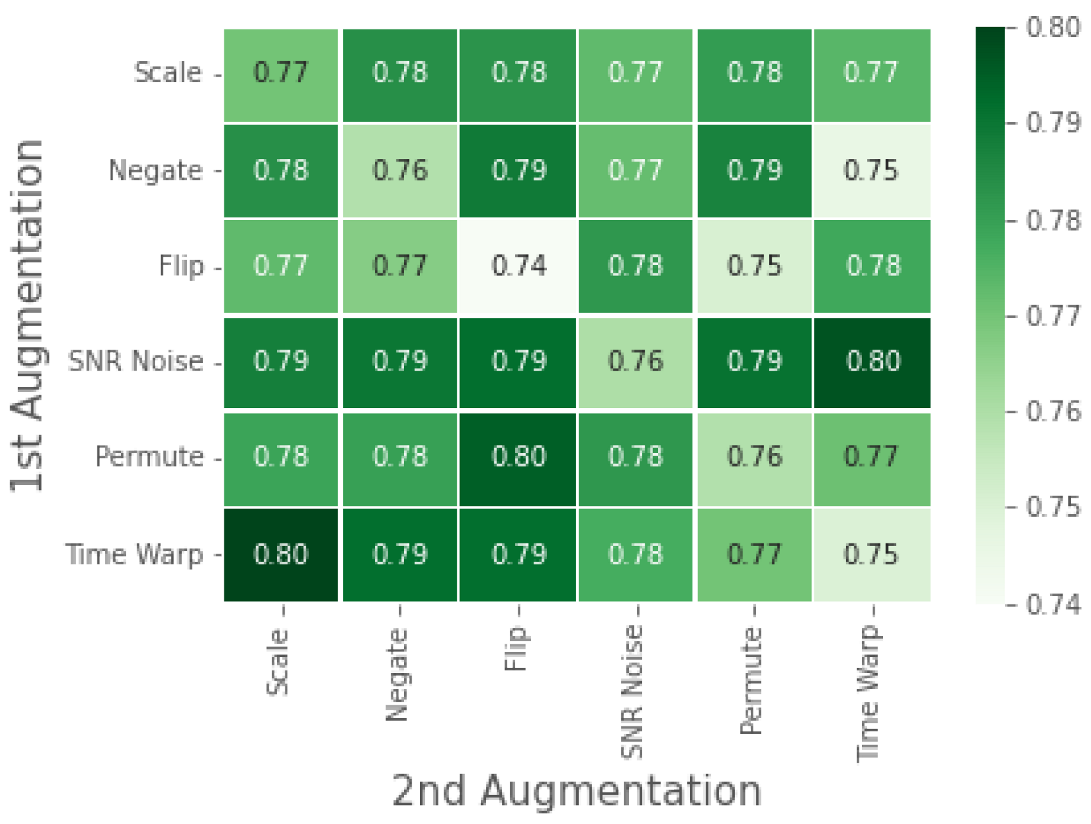
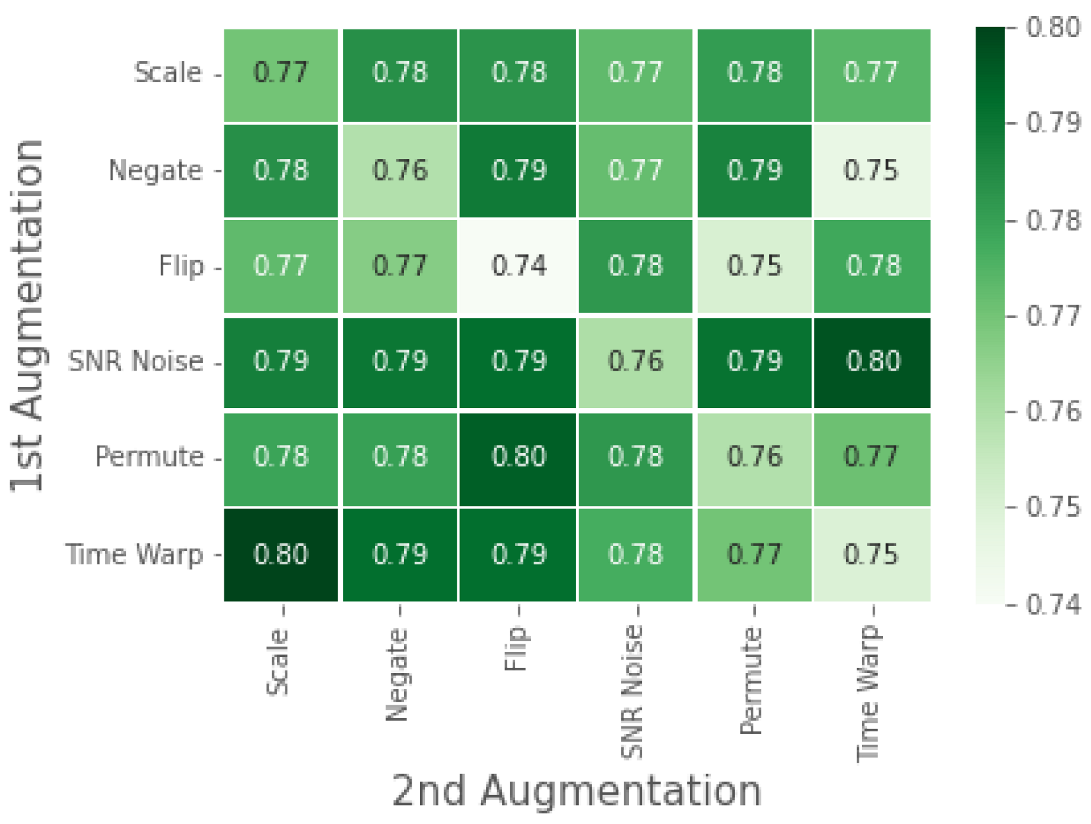
4.1.2. WESAD: Ablation Study
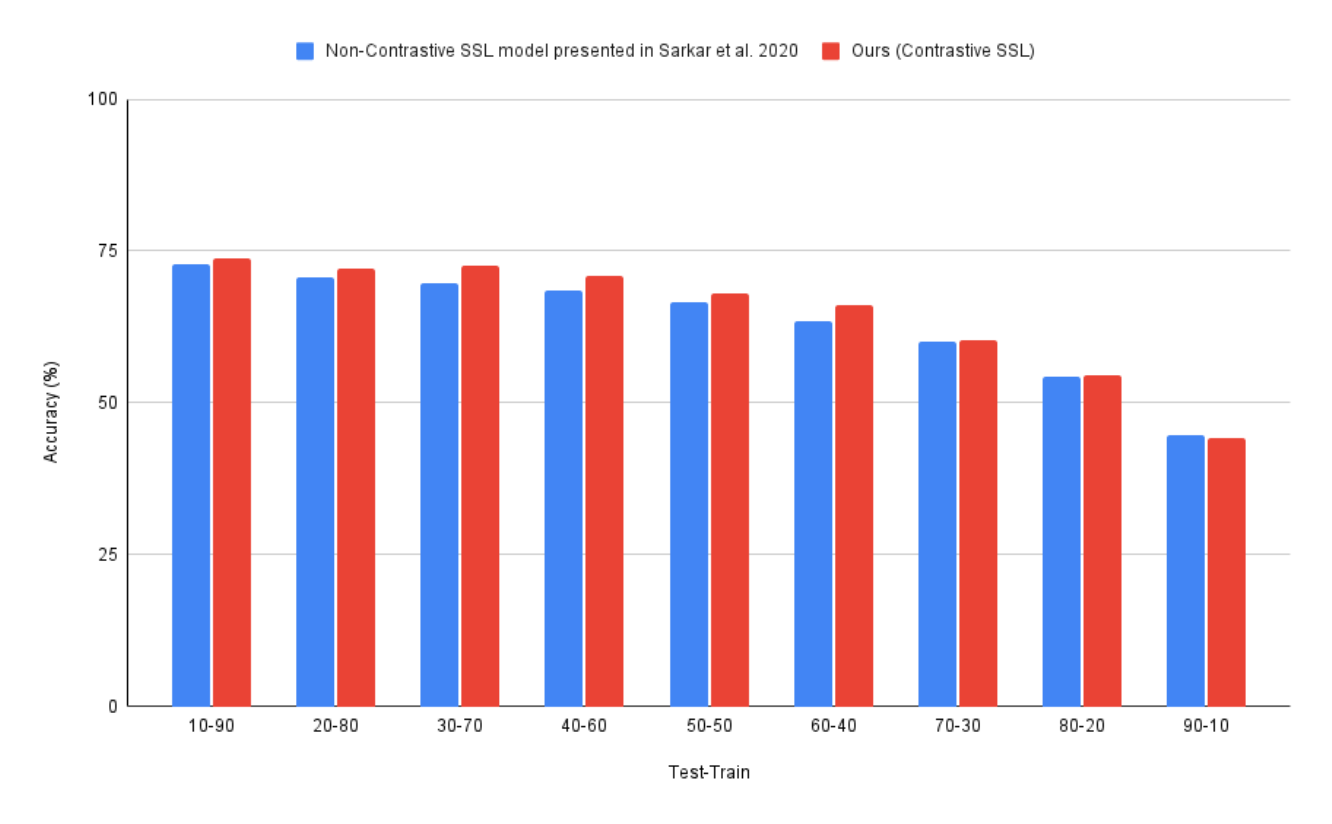
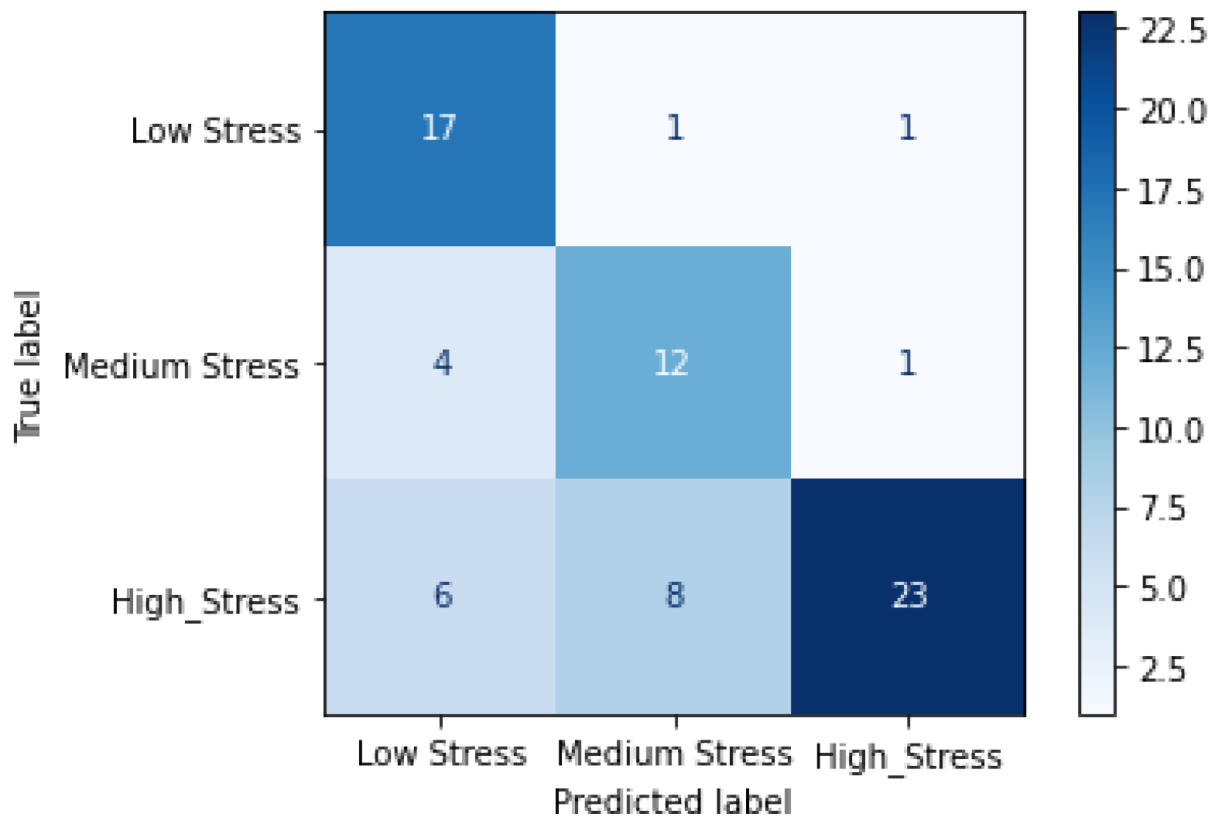
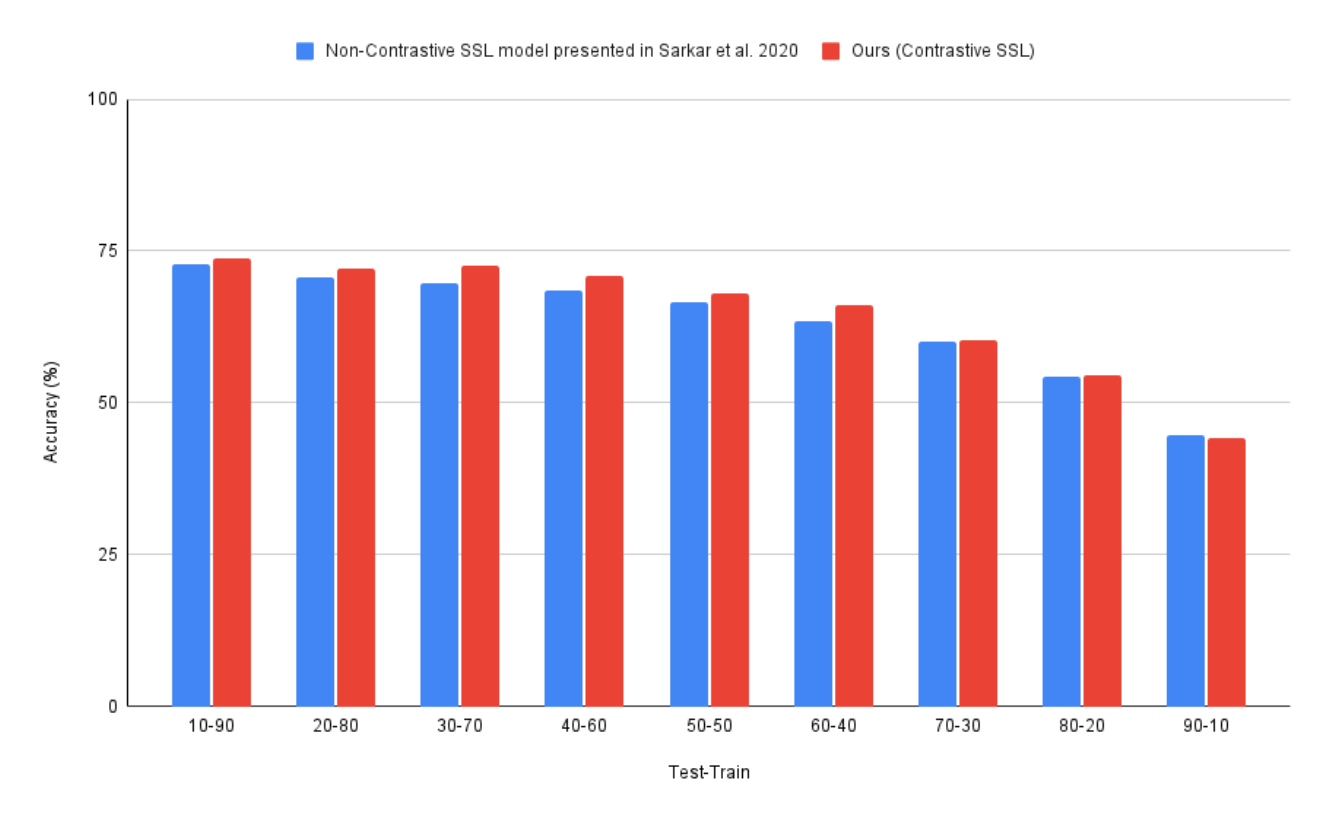
4.2. Results on RML Dataset
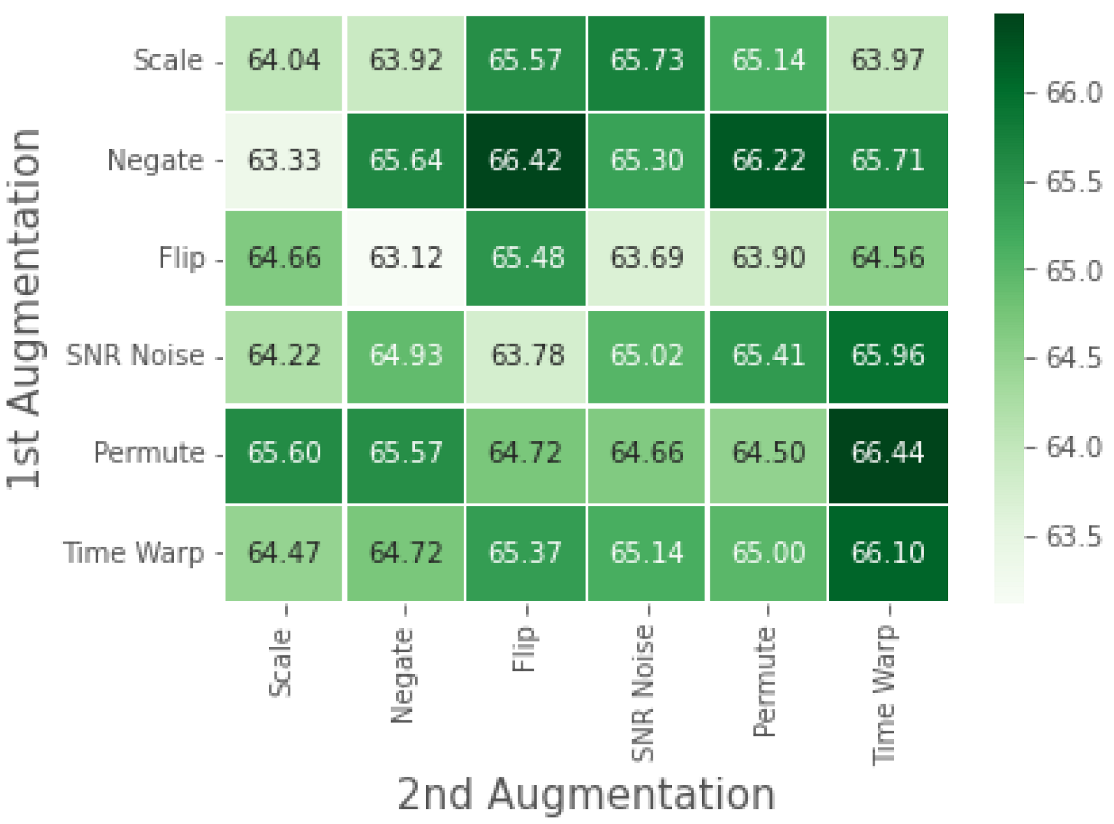
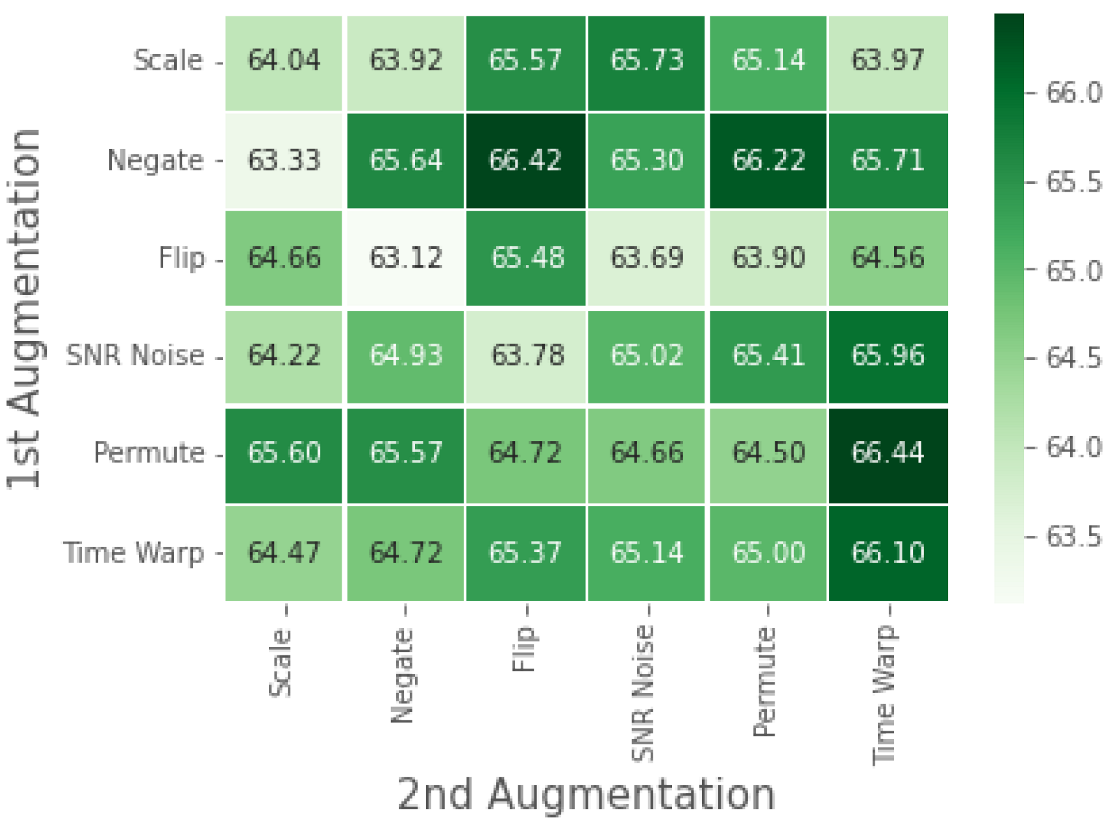
4.3. RML: Ablation Study
4.4. Class Imbalance in RML Dataset—Influence of SMOTE
5. Discussion
5.1. Analysis of Results on the WESAD Dataset
5.2. Analysis of Results on the RML Dataset
5.3. Real World Applications
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cohen, S.; Janicki-Deverts, D.; Miller, G.E. Psychological Stress and Disease. JAMA 2007, 298, 1685. [Google Scholar] [CrossRef] [PubMed]
- Schneiderman, N.; Ironson, G.; Siegel, S.D. Stress and Health: Psychological, Behavioral, and Biological Determinants. Annu. Rev. Clin. Psychol. 2005, 1, 607–628. [Google Scholar] [CrossRef] [PubMed]
- Epel, E.S.; Crosswell, A.D.; Mayer, S.E.; Prather, A.A.; Slavich, G.M.; Puterman, E.; Mendes, W.B. More than a feeling: A unified view of stress measurement for population science. Front. Neuroendocrinol. 2018, 49, 146–169. [Google Scholar] [CrossRef] [PubMed]
- Cipresso, P.; Serino, S.; Villani, D.; Repetto, C.; Sellitti, L.; Albani, G.; Mauro, A.; Gaggioli, A.; Riva, G. Is your phone so smart to affect your state? An exploratory study based on psychophysiological measures. Neurocomputing 2012, 84, 23–30. [Google Scholar] [CrossRef]
- Kim, H.G.; Cheon, E.J.; Bai, D.S.; Lee, Y.H.; Koo, B.H. Stress and Heart Rate Variability: A Meta-Analysis and Review of the Literature. Psychiatry Investig. 2018, 15, 235–245. [Google Scholar] [CrossRef]
- Hasnul, M.A.; Aziz, N.A.A.; Alelyani, S.; Mohana, M.; Aziz, A.A. Electrocardiogram-Based Emotion Recognition Systems and Their Applications in Healthcare—A Review. Sensors 2021, 21, 5015. [Google Scholar] [CrossRef]
- Geiger, R.S.; Cope, D.; Ip, J.; Lotosh, M.; Shah, A.; Weng, J.; Tang, R. “Garbage in, garbage out” revisited: What do machine learning application papers report about human-labeled training data? Quant. Sci. Stud. 2021, 2, 795–827. [Google Scholar] [CrossRef]
- Sarkar, P.; Etemad, A. Self-supervised ECG Representation Learning for Emotion Recognition. IEEE Trans. Affect. Comput. 2020, 1. [Google Scholar] [CrossRef]
- Dhabhar, F.S. A hassle a day may keep the pathogens away: The fight-or-flight stress response and the augmentation of immune function. Integr. Comp. Biol. 2009, 49, 215–236. [Google Scholar] [CrossRef]
- Healey, J.; Picard, R. Detecting Stress During Real-World Driving Tasks Using Physiological Sensors. IEEE Trans. Intell. Transp. Syst. 2005, 6, 156–166. [Google Scholar] [CrossRef]
- Liu, H.; Zhao, Z.; She, Q. Self-supervised ECG pre-training. Biomed. Signal Process. Control 2021, 70, 103010. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved Baselines with Momentum Contrastive Learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent: A new approach to self-supervised Learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Chen, X.; He, K. Exploring Simple Siamese Representation Learning. arXiv 2020, arXiv:2011.10566. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. arXiv 2021, arXiv:2006.09882. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2019, arXiv:1807.03748. [Google Scholar]
- Kiyasseh, D.; Zhu, T.; Clifton, D.A. CLOCS: Contrastive Learning of Cardiac Signals Across Space, Time, and Patients. arXiv 2021, arXiv:2005.13249. [Google Scholar]
- Mehari, T.; Strodthoff, N. Self-supervised representation learning from 12-lead ECG data. arXiv 2021, arXiv:2103.12676. [Google Scholar] [CrossRef]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A Survey on Contrastive Self-supervised Learning. arXiv 2021, arXiv:2011.00362. [Google Scholar] [CrossRef]
- Antoniou, A.; Edwards, H.; Storkey, A. How to train your MAML. arXiv 2019, arXiv:1810.09502. [Google Scholar]
- Saeed, A.; Ozcelebi, T.; Lukkien, J. Multi-task Self-Supervised Learning for Human Activity Detection. Proc. Acm Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–30. [Google Scholar] [CrossRef]
- Schmidt, P.; Reiss, A.; Duerichen, R.; Marberger, C.; Laerhoven, K.V. Introducing WESAD, a Multimodal Dataset for Wearable Stress and Affect Detection. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018. [Google Scholar] [CrossRef]
- Ahmad, Z.; Rabbani, S.; Zafar, M.R.; Ishaque, S.; Krishnan, S.; Khan, N. Multi-level Stress Assessment from ECG in a Virtual Reality Environment using Multimodal Fusion. arXiv 2021, arXiv:2107.04566. [Google Scholar]
- Benezeth, Y.; Li, P.; Macwan, R.; Nakamura, K.; Gomez, R.; Yang, F. Remote heart rate variability for emotional state monitoring. In Proceedings of the IEEE EMBS international conference on biomedical & health informatics (BHI), Las Vegas, NV, USA, 4–7 March 2018; pp. 153–156. [Google Scholar] [CrossRef]
- Ottesen, C.A. Investigating Heart Rate Variability: A Machine Learning Approach. Ph.D. Thesis, Queen Mary University of London, London, UK, 2017. [Google Scholar]
- Fan, H.; Zhang, F.; Gao, Y. Self-Supervised Time Series Representation Learning by Inter-Intra Relational Reasoning. In Proceedings of the Conference on Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Picard, R.W. Affective Computing; Mit Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Frank, D.L.; Khorshid, L.; Kiffer, J.F.; Moravec, C.S.; McKee, M.G. Biofeedback in medicine: Who, when, why and how? Ment. Health Fam. Med. 2010, 7, 85. [Google Scholar] [PubMed]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G.E. Big self-supervised models are strong semi-supervised learners. Adv. Neural Inf. Process. Syst. 2020, 33, 22243–22255. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy ± Standard Deviation |
|---|---|
| Machine Learning - SVM | 46.43 ± 1.53% |
| Fully Supervised | 93.02 ± 3.03 % |
| Non-contrastive SSL [8] | 87% 1 |
| Ours (Contrastive SSL) | 94.09 ± 1.30 % |
| Signal Transformation Task | |||||||
|---|---|---|---|---|---|---|---|
| Test-Train Ratio | No Augmentation | Scale | Negate | H-Flip | SNR Noise | Time Warp | Permute |
| 10–90 | 93.0 | 92.0 | 93.5 | 93.4 | 94.6 | 93.6 | 94.2 |
| 20–80 | 92.8 | 93.0 | 92.7 | 92.4 | 92.4 | 93.6 | 92.5 |
| 30–70 | 91.9 | 90.6 | 91.8 | 90.8 | 92.0 | 88.7 | 90.1 |
| 40–60 | 89.9 | 91.0 | 88.9 | 91.0 | 89.7 | 89.8 | 91.7 |
| 50–50 | 85.9 | 84.9 | 86.2 | 88.5 | 87.4 | 88.6 | 87.7 |
| 60–40 | 80.6 | 82.3 | 82.1 | 83.9 | 83.8 | 84.0 | 85.4 |
| 70–30 | 67.1 | 77.01 | 75.9 | 74.0 | 76.0 | 75.0 | 75.9 |
| 80–20 | 55.8 | 59.6 | 58.3 | 62.2 | 60.8 | 62.6 | 60.9 |
| 90–10 | 43.4 | 48.4 | 48.1 | 48.6 | 45.9 | 46.4 | 45.5 |
| Method | Mean Accuracy ± Standard Deviation |
|---|---|
| Machine Learning - SVM | 59.5 ± 4.97% |
| Fully-Supervised | 72.9 ± 4.3% |
| Non-contrastive SSL [8] | 70.1 ± 3.4 % |
| Contrastive SSL (ours) | 73.8 ± 8.7% |
| Signal Transformation | |||||||
|---|---|---|---|---|---|---|---|
| Test-Train Ratio | No Augmentation | Scale | Negate | H-Flip | SNR Noise | Time Warp | Permute |
| 10–90 | 72.9 | 76.6 | 74.1 | 73.0 | 74.7 | 73.8 | 75.2 |
| 20–80 | 70.8 | 72.9 | 74.8 | 72.6 | 72.3 | 72.1 | 72.7 |
| 30–70 | 69.6 | 70.9 | 73.8 | 72.7 | 72.7 | 72.6 | 72.9 |
| 40–60 | 68.6 | 70.7 | 69.7 | 71.4 | 71.3 | 70.8 | 72.1 |
| 50–50 | 66.7 | 68.3 | 69.6 | 68.9 | 69.7 | 68.0 | 67.5 |
| 60–40 | 63.3 | 64.0 | 65.6 | 65.6 | 65.0 | 66.1 | 64.5 |
| 70–30 | 60.1 | 61.2 | 59.7 | 60.6 | 61.0 | 60.3 | 60.9 |
| 80–20 | 54.3 | 54.5 | 53.6 | 55.5 | 53.9 | 54.5 | 54.9 |
| 90–10 | 44.8 | 44.9 | 43.9 | 43.7 | 44.0 | 44.1 | 44.6 |
| Class | Number of Samples in Dataset |
|---|---|
| Low Stress | 242 |
| Medium Stress | 88 |
| High Stress | 48 |
| Method | Mean Accuracy ± Standard Deviation |
|---|---|
| Fully Supervised Benchmark without SMOTE | 45.3 ± 4.04% |
| Fully Supervised Benchmark with SMOTE | 72.9 ± 4.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rabbani, S.; Khan, N. Contrastive Self-Supervised Learning for Stress Detection from ECG Data. Bioengineering 2022, 9, 374. https://doi.org/10.3390/bioengineering9080374
Rabbani S, Khan N. Contrastive Self-Supervised Learning for Stress Detection from ECG Data. Bioengineering. 2022; 9(8):374. https://doi.org/10.3390/bioengineering9080374
Chicago/Turabian StyleRabbani, Suha, and Naimul Khan. 2022. "Contrastive Self-Supervised Learning for Stress Detection from ECG Data" Bioengineering 9, no. 8: 374. https://doi.org/10.3390/bioengineering9080374
APA StyleRabbani, S., & Khan, N. (2022). Contrastive Self-Supervised Learning for Stress Detection from ECG Data. Bioengineering, 9(8), 374. https://doi.org/10.3390/bioengineering9080374