
Deep Learning for Live Cell Shape Detection and Automated AFM Navigation

 ,
,
Abstract
1. Introduction
- A high-speed DL-based automation to accelerate the AFM probe navigation when performing biomechanical measurements on cells with the desired shape.
- A transfer learning approach to adapt the cell shape detection model to low-quality images captured by the AFM stage navigation camera with limited training data.
- A closed-loop scanner trajectory control setup ensuring the accuracy and precision of the AFM probe navigation for biomechanical quantification.
- A nanomechanical property characterization for representative cell shapes using the proposed framework.
2. Materials and Methods
2.1. Live Cell Sample Preparation for AFM Experiments
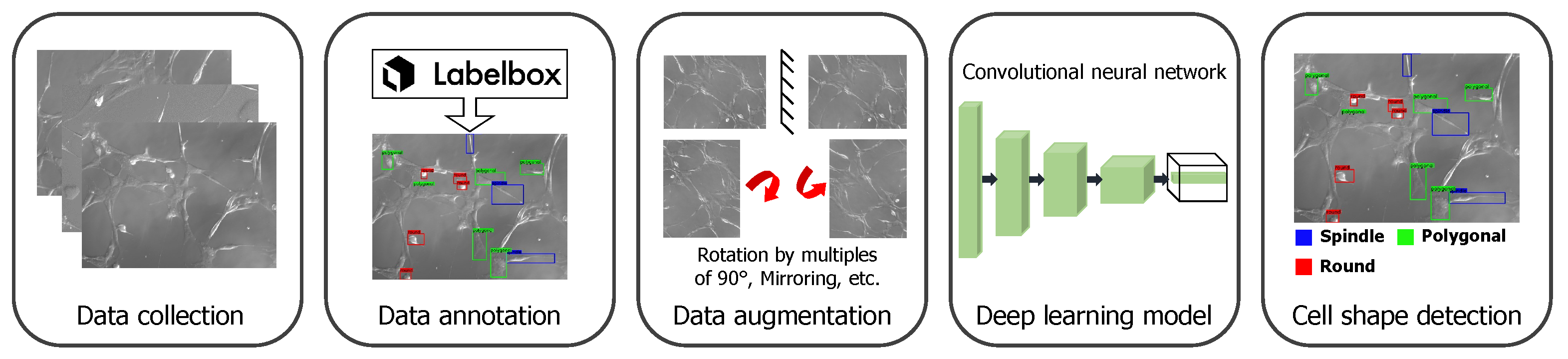
2.2. Cell Shape Detection from Microscopic Images
2.2.1. Dataset
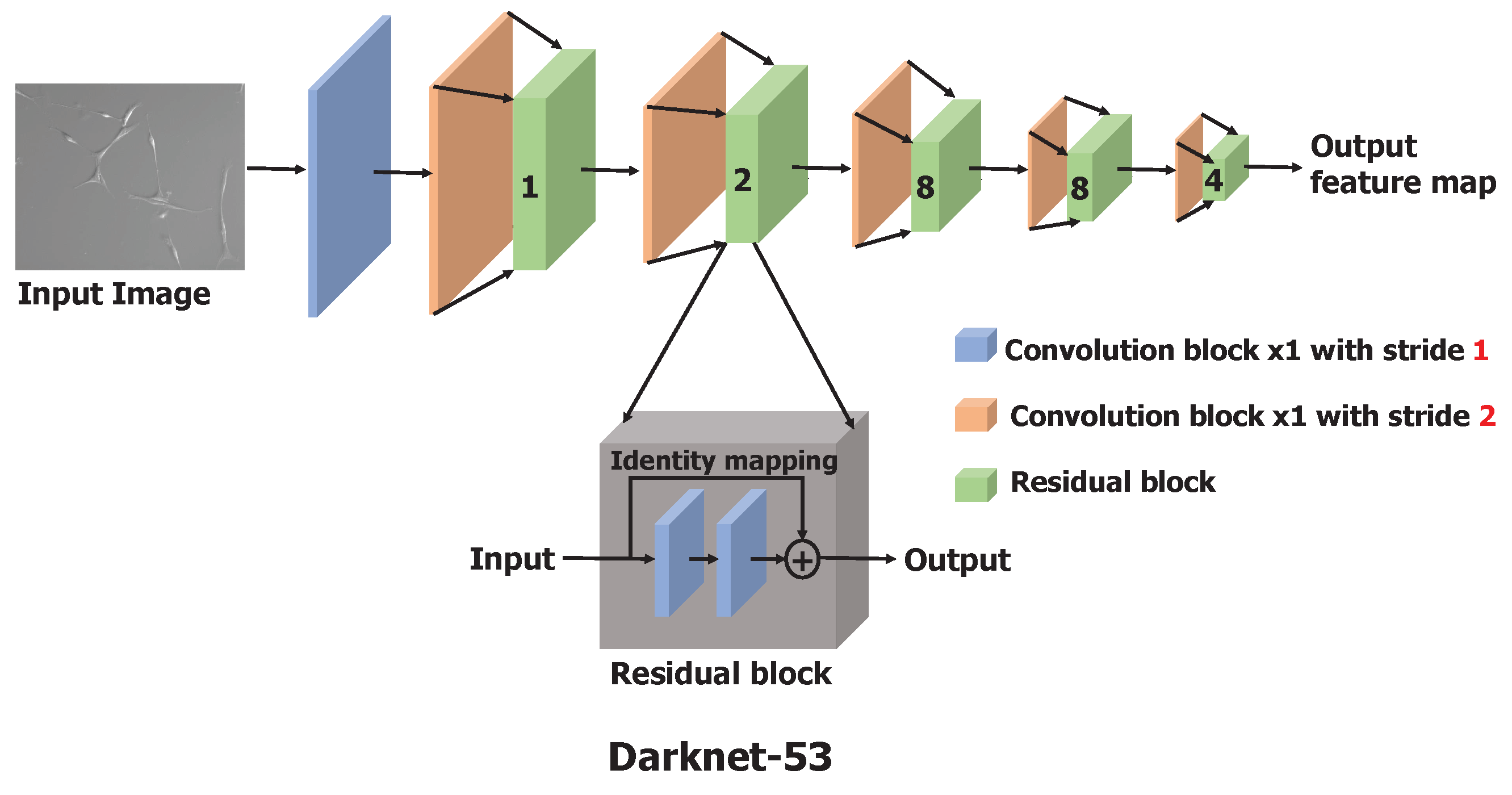
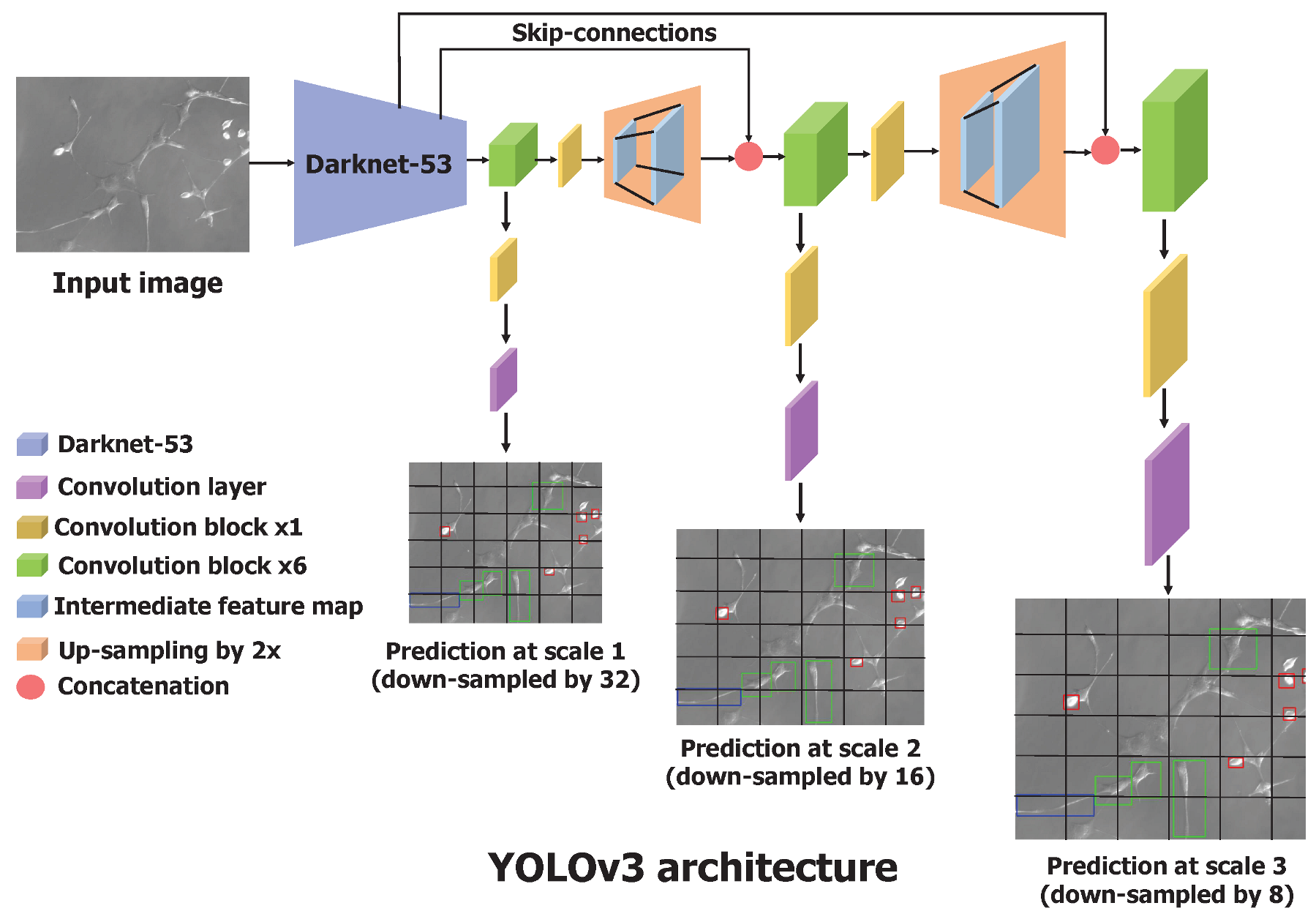
2.2.2. Training with Transfer Learning
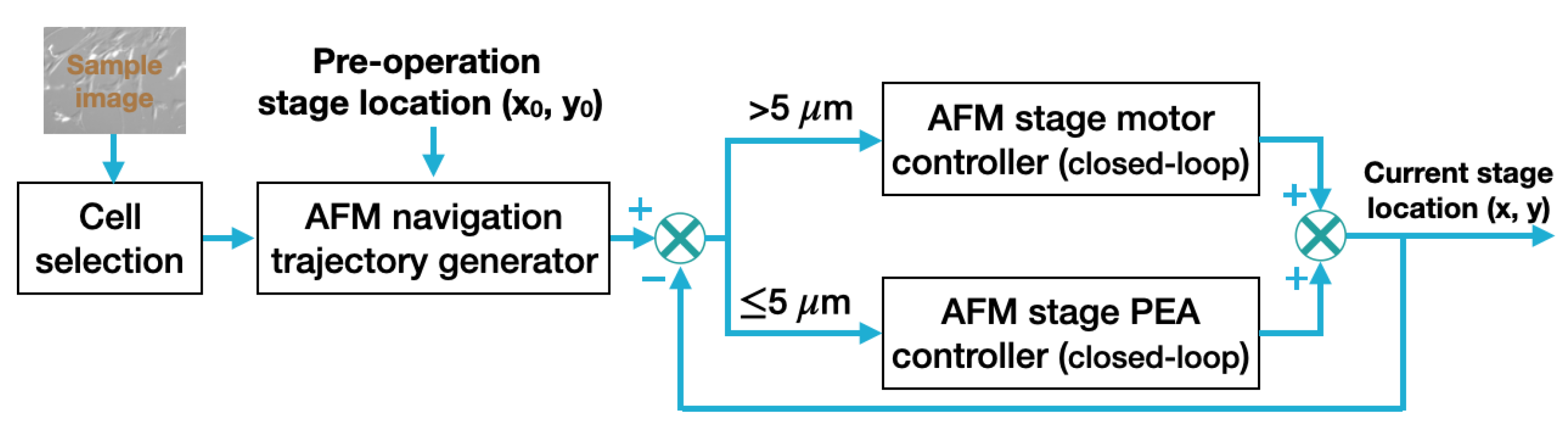
2.3. Closed-Loop Navigation of AFM Stage
3. Results and Discussion
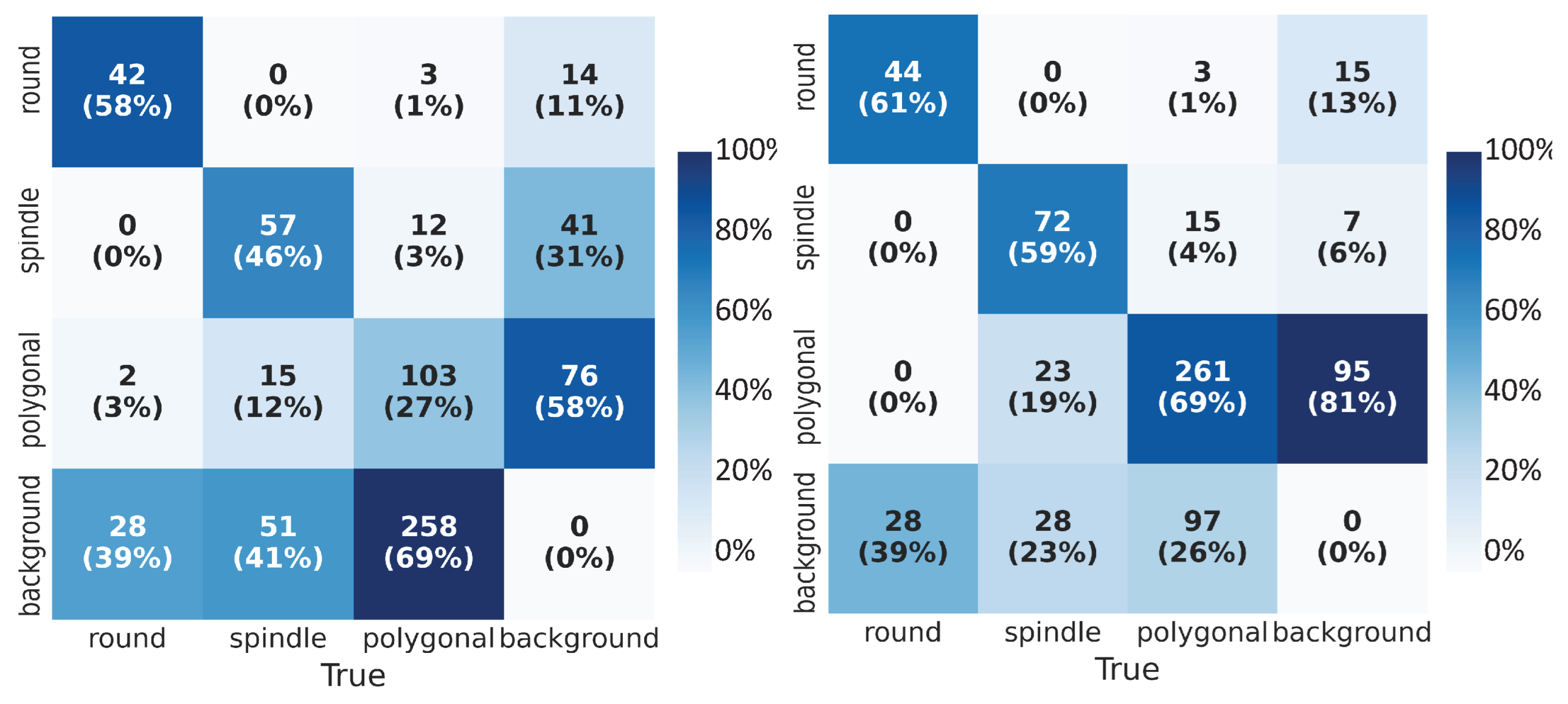
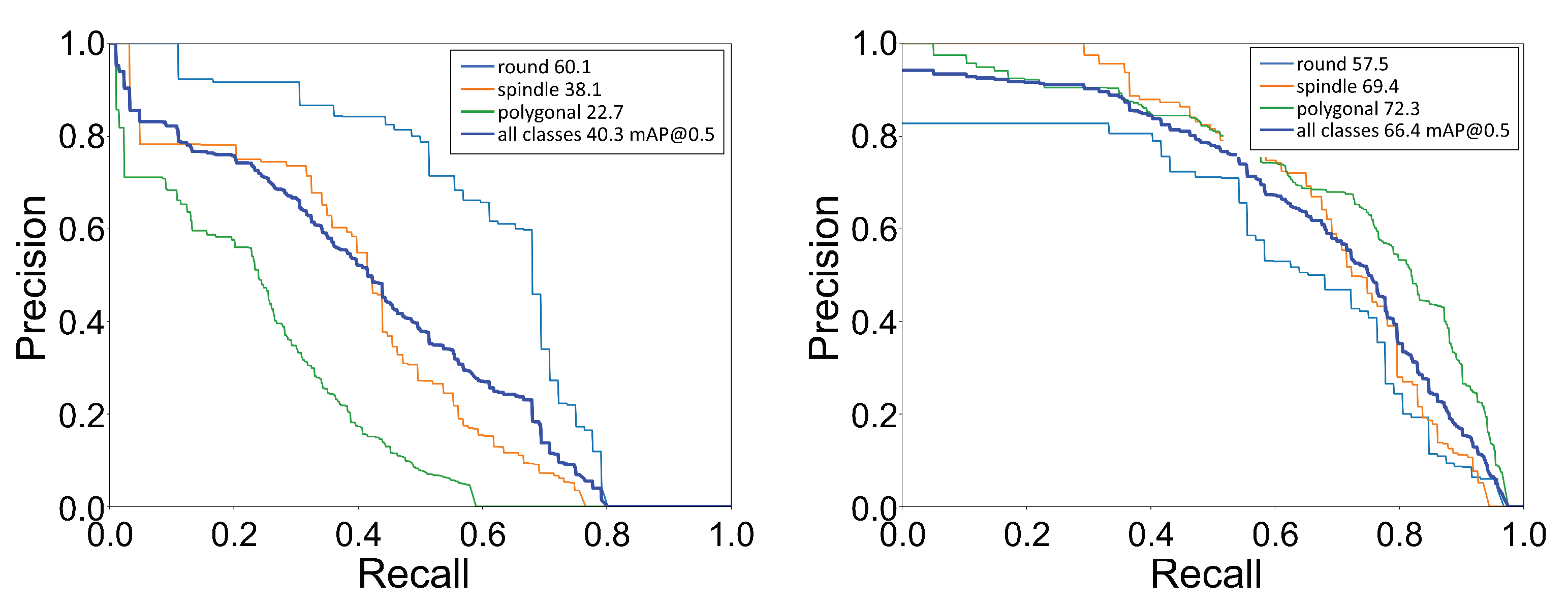
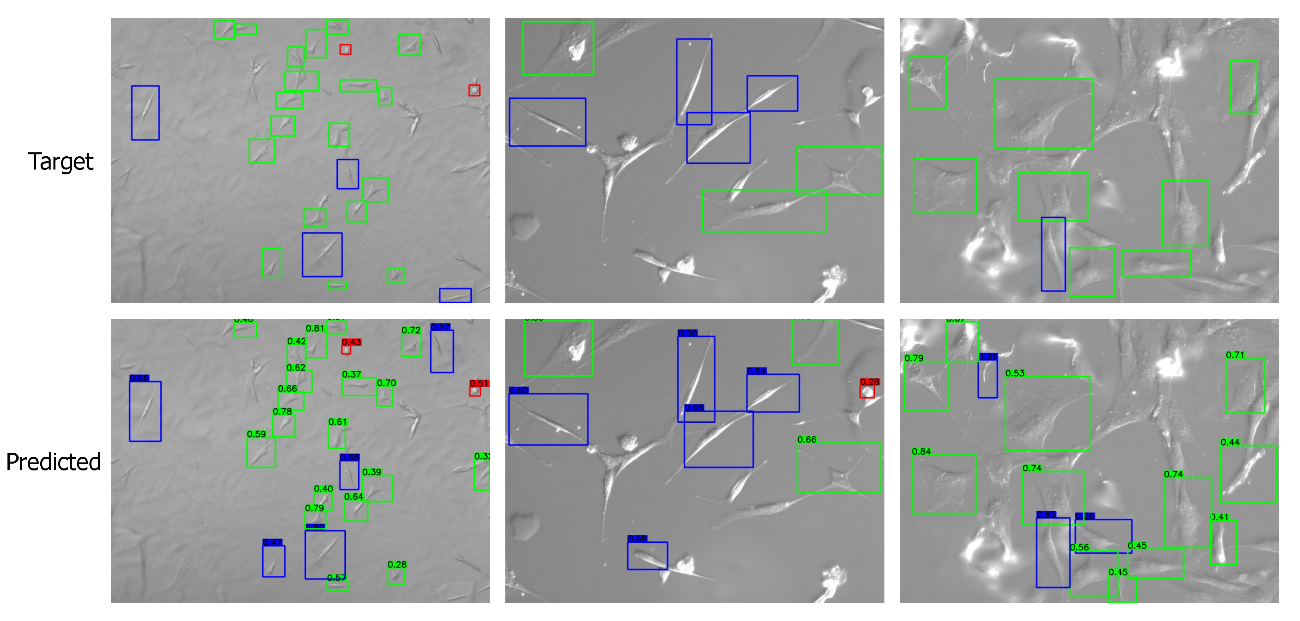
3.1. Cell Shape Detection and Localization
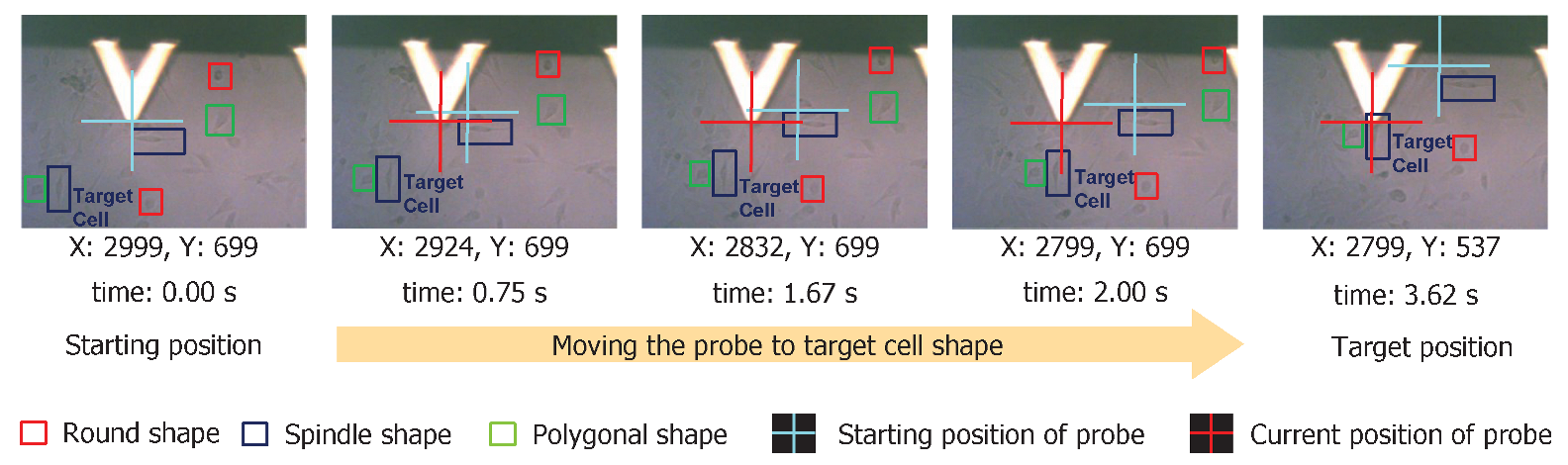
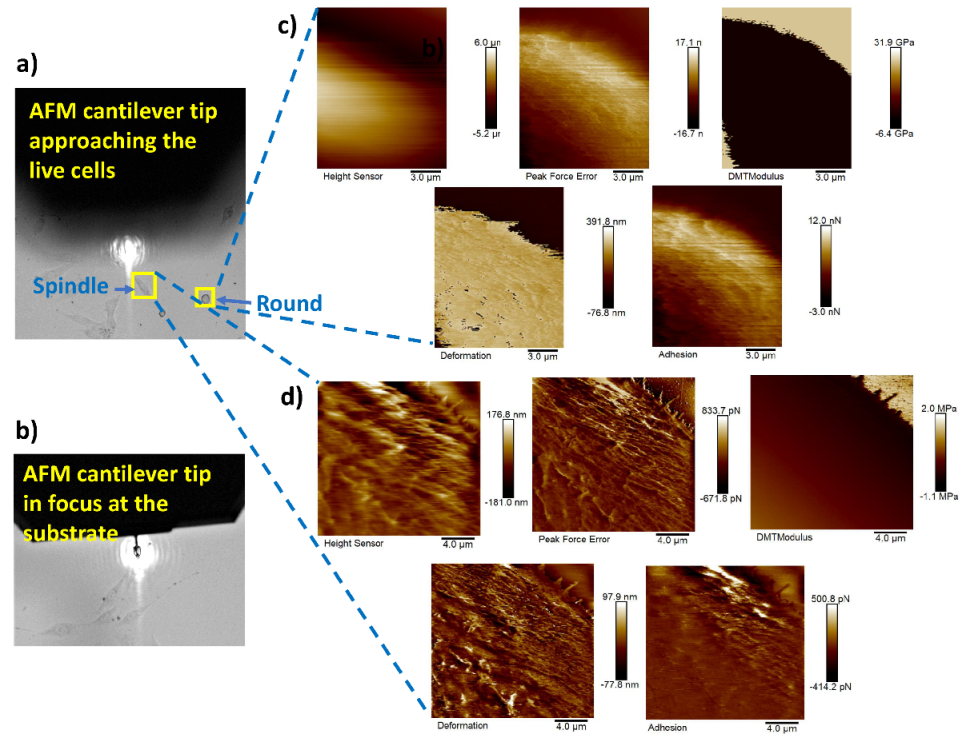
3.2. Tip Navigation
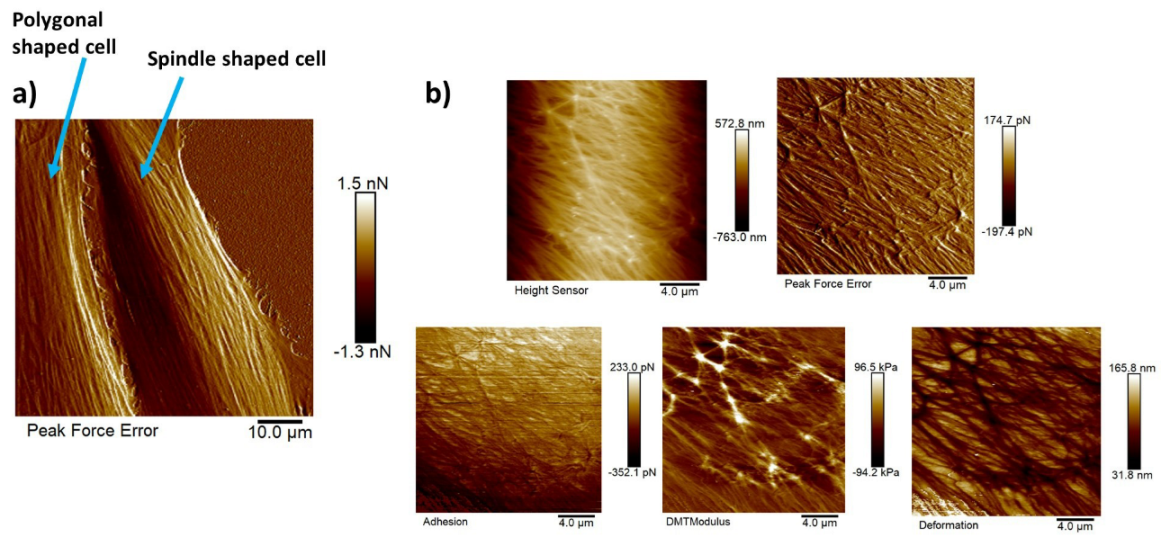
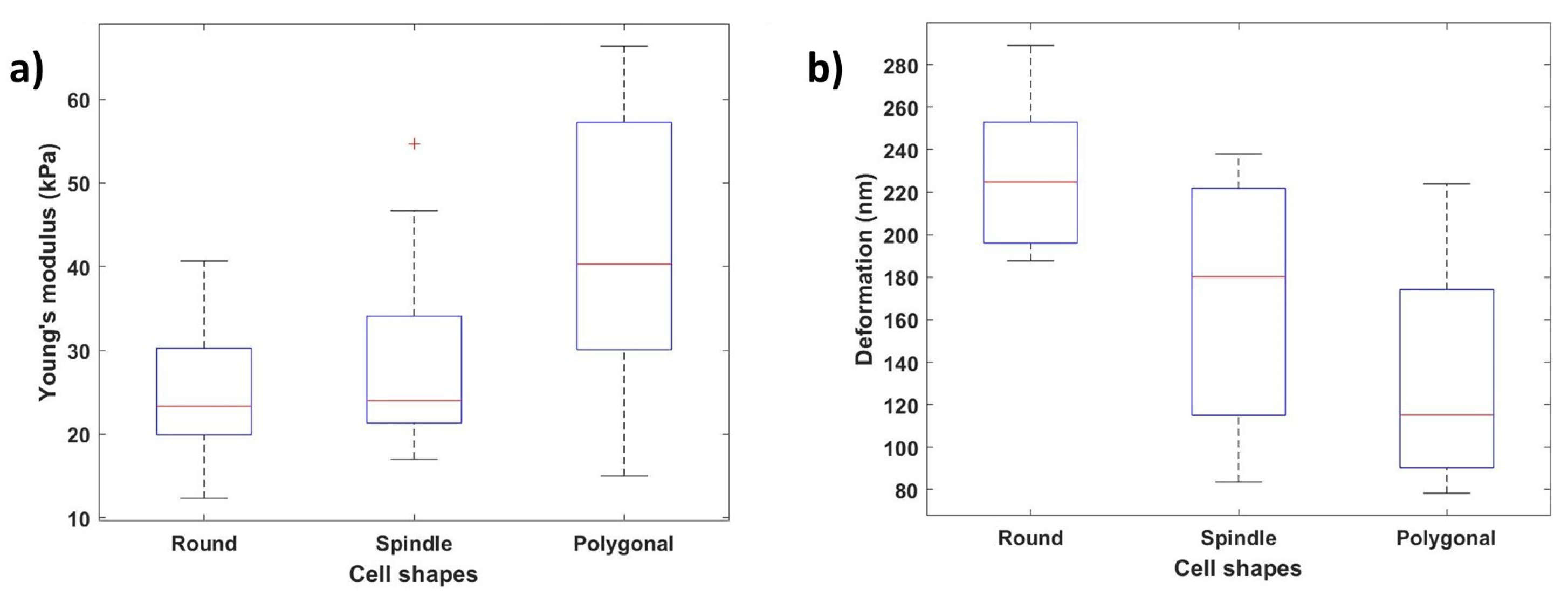
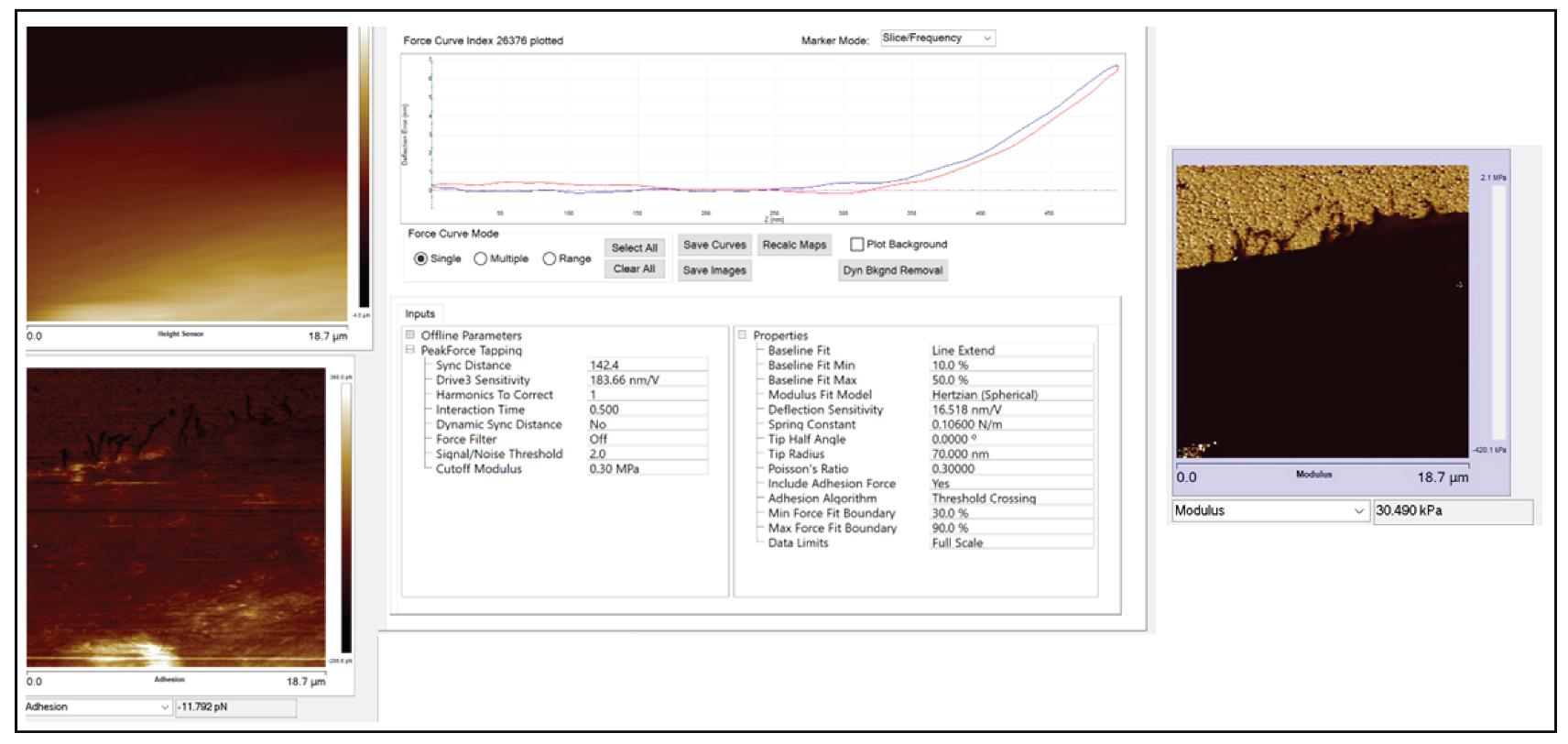
3.3. Nanomechanical Properties
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AFM | Atomic force microscopy |
| ECM | Extracellular matrix |
| AI | Artificial intelligence |
| DL | Deep learning |
| DMEM | Dulbecco’s Modified Eagle Medium |
| YOLOv3 | You Only Look Once version 3 |
| CNN | Convolutional neural network |
| SGD | Stochastic gradient descent |
| IoU | Intersection over union |
| PEA | Piezoelectric actuator |
| MPC | Model predictive control |
| CM | Confusion matrix |
| AP | Average precision |
| mAP | Mean average precision |
Appendix A. Detecting the Cantilever Probe

Appendix B. Implementation Details
| Algorithm A1: Training Algorithm. |
| Input: Input AFM image, neural network |
| Initialization: Initialize the weights for all layers |
| Use the pretrained weights if using transfer learning |
| Data Loading: Load the training data D and testing data DT |
 |
Appendix C. More Visual Results


Appendix D. Example PFC file

References
- Sarkar, A.; Zhao, Y.; Wang, Y.; Wang, X. Force-activatable coating enables high-resolution cellular force imaging directly on regular cell culture surfaces. Phys. Biol. 2018, 15, 065002. [Google Scholar] [CrossRef] [PubMed]
- Sarkar, A.; LeVine, D.N.; Kuzmina, N.; Zhao, Y.; Wang, X. Cell migration driven by self-generated integrin ligand gradient on ligand-labile surfaces. Curr. Biol. 2020, 30, 4022–4032. [Google Scholar] [CrossRef] [PubMed]
- Sarkar, A.; LeVine, D.; Zhao, Y.; Mollaeian, K.; Ren, J.; Wang, X. Tandem tension sensor reveals substrate rigidity-dependence of integrin molecular tensions in live cells. bioRxiv 2020. [Google Scholar]
- Mao, S.; Sarkar, A.; Wang, Y.; Song, C.; LeVine, D.; Wang, X.; Que, L. Microfluidic chip grafted with integrin tension sensors for evaluating the effects of flowing shear stress and ROCK inhibitor on platelets. Lab Chip 2021, 21, 3128–3136. [Google Scholar] [CrossRef] [PubMed]
- Raudenska, M.; Kratochvilova, M.; Vicar, T.; Gumulec, J.; Balvan, J.; Polanska, H.; Pribyl, J.; Masarik, M. Cisplatin enhances cell stiffness and decreases invasiveness rate in prostate cancer cells by actin accumulation. Sci. Rep. 2019, 9, 1–11. [Google Scholar] [CrossRef]
- Fletcher, D.A.; Mullins, R.D. Cell mechanics and the cytoskeleton. Nature 2010, 463, 485–492. [Google Scholar] [CrossRef]
- Haupt, A.; Minc, N. How cells sense their own shape–mechanisms to probe cell geometry and their implications in cellular organization and function. J. Cell Sci. 2018, 131, jcs214015. [Google Scholar] [CrossRef]
- Clark, A.G.; Paluch, E. Mechanics and regulation of cell shape during the cell cycle. Cell Cycle Dev. 2011, 53, 31–73. [Google Scholar]
- Fleming, A. Shape Control: Cell Growth Hits the Mechanical Buffers. Curr. Biol. 2017, 27, R1231–R1233. [Google Scholar] [CrossRef]
- Paluch, E.; Heisenberg, C.P. Biology and physics of cell shape changes in development. Curr. Biol. 2009, 19, R790–R799. [Google Scholar] [CrossRef]
- Dufrêne, Y.F. Atomic force microscopy, a powerful tool in microbiology. J. Bacteriol. 2002, 184, 5205–5213. [Google Scholar] [CrossRef] [PubMed]
- Burnham, N.A.; Colton, R.J. Measuring the nanomechanical properties and surface forces of materials using an atomic force microscope. J. Vac. Sci. Technol. Vacuum Surfaces Film. 1989, 7, 2906–2913. [Google Scholar] [CrossRef]
- Meyer, E. Atomic force microscopy. Prog. Surf. Sci. 1992, 41, 3–49. [Google Scholar] [CrossRef]
- Kada, G.; Kienberger, F.; Hinterdorfer, P. Atomic force microscopy in bionanotechnology. Nano Today 2008, 3, 12–19. [Google Scholar] [CrossRef]
- Cappella, B.; Dietler, G. Force-distance curves by atomic force microscopy. Surf. Sci. Rep. 1999, 34, 1–104. [Google Scholar] [CrossRef]
- Sarkar, A. Biosensing, characterization of biosensors, and improved drug delivery approaches using Atomic Force Microscopy: A review. Front. Nanotechnol. 2021, 3, 102. [Google Scholar] [CrossRef]
- Jones, S.K.; Sarkar, A.; Feldmann, D.P.; Hoffmann, P.; Merkel, O.M. Revisiting the value of competition assays in folate receptor-mediated drug delivery. Biomaterials 2017, 138, 35–45. [Google Scholar] [CrossRef]
- Sarkar, A.; Sohail, A.; Dong, J.; Prunotto, M.; Shinki, K.; Fridman, R.; Hoffmann, P.M. Live cell measurements of interaction forces and binding kinetics between Discoidin Domain Receptor 1 (DDR1) and collagen I with atomic force microscopy. Biochim. Biophys. Acta Gen. Subj. 2019, 1863, 129402. [Google Scholar] [CrossRef]
- Hu, J.; Chen, S.; Huang, D.; Zhang, Y.; Lü, S.; Long, M. Global mapping of live cell mechanical features using PeakForce QNM AFM. Biophys. Rep. 2020, 6, 9–18. [Google Scholar] [CrossRef]
- Nahar, S.; Schmets, A.; Schitter, G.; Skarpas, A. Quantitative nanomechanical property mapping of bitumen micro-phases by peak-force Atomic Force Microscopy. In Proceedings of the International Conference on Asphalt Pavements, ISAP, Raleigh, NC, USA, 1–5 June 2014; Volume 2, pp. 1397–1406. [Google Scholar]
- Schillers, H.; Medalsy, I.; Hu, S.; Slade, A.L.; Shaw, J.E. PeakForce Tapping resolves individual microvilli on living cells. J. Mol. Recognit. 2016, 29, 95–101. [Google Scholar] [CrossRef]
- Holmatro’s new hand pump, R. Bioscope resolve high-resolution bioAFM system. Tribol. Lubr. Technol. 2015, 5, 9. [Google Scholar]
- Akintayo, A.; Tylka, G.L.; Singh, A.K.; Ganapathysubramanian, B.; Singh, A.; Sarkar, S. A deep learning framework to discern and count microscopic nematode eggs. Sci. Rep. 2018, 8, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Rade, J.; Balu, A.; Herron, E.; Pathak, J.; Ranade, R.; Sarkar, S.; Krishnamurthy, A. Algorithmically-consistent deep learning frameworks for structural topology optimization. Eng. Appl. Artif. Intell. 2021, 106, 104483. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Saikumar, N.; Sinha, R.K.; HosseinNia, S.H. Resetting disturbance observers with application in compensation of bounded nonlinearities like hysteresis in piezo-actuators. Control. Eng. Pract. 2019, 82, 36–49. [Google Scholar] [CrossRef]
- Xie, S.; Ren, J. Recurrent-neural-network-based predictive control of piezo actuators for trajectory tracking. IEEE/ASME Trans. Mechatronics 2019, 24, 2885–2896. [Google Scholar] [CrossRef]
- Xie, S.; Ren, J. High-speed AFM imaging via iterative learning-based model predictive control. Mechatronics 2019, 57, 86–94. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar]
- Pittenger, B.; Erina, N.; Su, C. Quantitative mechanical property mapping at the nanoscale with PeakForce QNM. Bruker Appl. Note AN128 Rev. A 2010, 1, 1–11. [Google Scholar]
- Pittenger, B.; Erina, N.; Su, C. Mechanical property mapping at the nanoscale using PeakForce QNM scanning probe technique. In Nanomechanical Analysis of High Performance Materials; Springer: Berlin/Heidelberg, Germany, 2014; pp. 31–51. [Google Scholar]
- Zhao, B.; Song, Y.; Wang, S.; Dai, B.; Zhang, L.; Dong, Y.; Lü, J.; Hu, J. Mechanical mapping of nanobubbles by PeakForce atomic force microscopy. Soft Matter 2013, 9, 8837–8843. [Google Scholar] [CrossRef]
- Dokukin, M.E.; Sokolov, I. Quantitative mapping of the elastic modulus of soft materials with HarmoniX and PeakForce QNM AFM modes. Langmuir 2012, 28, 16060–16071. [Google Scholar] [CrossRef]
- Shulha, H.; Kovalev, A.; Myshkin, N.; Tsukruk, V.V. Some aspects of AFM nanomechanical probing of surface polymer films. Eur. Polym. J. 2004, 40, 949–956. [Google Scholar] [CrossRef]
- Tranchida, D.; Piccarolo, S.; Soliman, M. Nanoscale Mechanical Characterization of Polymers by AFM Nanoindentations: Critical Approach to the Elastic Characterization. Macromolecules 2006, 39, 4547–4556. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Optimizer | Batch Size | Epochs | Learning Rate | mAP |
|---|---|---|---|---|
| Adam | 16 | 500 | 0.01 | 47.8 |
| Adam | 32 | 500 | 0.01 | 44.7 |
| Adam | 16 | 1000 | 0.01 | 47.3 |
| Adam | 32 | 500 | 0.01 | 45.9 |
| SGD | 16 | 500 | 0.01 | 63.8 |
| SGD | 16 | 1000 | 0.01 | 62.3 |
| SGD | 32 | 500 | 0.01 | 64.8 |
| SGD | 32 | 1000 | 0.01 | 64.4 |
| SGD | 16 | 500 | 0.0001 | 63.7 |
| SGD | 32 | 500 | 0.001 | 66.1 |
| SGD (best) | 16 | 500 | 0.001 | 66.4 |
| Experiment | Round | Spindle | Polygonal | Mean |
|---|---|---|---|---|
| Trained on only low-quality images | 0.73 | 0.64 | 0.42 | 0.60 |
| Transfer learning | 0.74 | 0.77 | 0.77 | 0.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rade, J.; Zhang, J.; Sarkar, S.; Krishnamurthy, A.; Ren, J.; Sarkar, A. Deep Learning for Live Cell Shape Detection and Automated AFM Navigation. Bioengineering 2022, 9, 522. https://doi.org/10.3390/bioengineering9100522
Rade J, Zhang J, Sarkar S, Krishnamurthy A, Ren J, Sarkar A. Deep Learning for Live Cell Shape Detection and Automated AFM Navigation. Bioengineering. 2022; 9(10):522. https://doi.org/10.3390/bioengineering9100522
Chicago/Turabian StyleRade, Jaydeep, Juntao Zhang, Soumik Sarkar, Adarsh Krishnamurthy, Juan Ren, and Anwesha Sarkar. 2022. "Deep Learning for Live Cell Shape Detection and Automated AFM Navigation" Bioengineering 9, no. 10: 522. https://doi.org/10.3390/bioengineering9100522
APA StyleRade, J., Zhang, J., Sarkar, S., Krishnamurthy, A., Ren, J., & Sarkar, A. (2022). Deep Learning for Live Cell Shape Detection and Automated AFM Navigation. Bioengineering, 9(10), 522. https://doi.org/10.3390/bioengineering9100522