1. Introduction
Alzheimer’s disease (AD) presents a growing challenge to global public health due to its impact on cognitive function and quality of life. As the population ages, the prevalence of AD is expected to increase, underscoring the need for effective early intervention. Detecting AD at its earliest stages, particularly in the preclinical phase (preAD), is critical for timely interventions and dementia prevention.
AD is characterized by a sequence of biological events that begins years before clinical symptoms [
1]. Amyloid-
(A
) deposition on PET scans or low A
levels in Cerebrospinal fluid (CSF) are considered early indicators of AD in normal older individuals, who may be classified as having preclinical AD (preAD) [
2]. A
peptides are known to influence synaptic activity with inhibitory effects at post-synaptic sites and excitatory effects at pre-synaptic sites [
3,
4]. Their pathological accumulation disrupts synaptic transmission [
5], alters network-level neuronal activity [
3,
4], and causes synaptic loss [
6,
7]. Synaptic abnormalities may occur before amyloid plaque deposition [
3,
8] and are central to the pathophysiology of AD in preclinical and symptomatic stages [
9]. Synaptic loss is strongly associated with the severity of clinical symptoms [
10], underscoring the value of identifying biomarkers that can detect early synaptic dysfunction.
EEGs capture summated excitatory and inhibitory postsynaptic potentials [
11] and provide a non-invasive measure of synaptic and network functions. EEG-derived measures, such as event-related brain potentials (ERPs), are sensitive to subtle brain changes in early AD [
12,
13], even in the preclinical stage [
14,
15]. With its high temporal resolution, EEG is well-suited to track changes in cognitive processes such as memory. Using a word repetition paradigm that elicits language- and memory-related brain activity, our group has identified several ERP measures that distinguish individuals across different AD stages from healthy controls [
15,
16,
17,
18,
19,
20]. For example, the N400 (linked to semantic processing) and the P600 or ‘Late Positive Component’ (LPC, linked to verbal memory) are reliably observed in healthy elderly but not in mild cognitive impairment (MCI) or AD patients [
15,
18,
19,
20]. Abnormalities in these ERP components have also been found in preAD [
15], suggesting that EEG/ERP paradigms may provide sensitive biomarkers of synaptic and network alterations before any detectable cognitive dysfunction.
A limitation of traditional EEG analyses is their usual focus on pre-defined time windows, electrode locations, and frequency bands, at the expense of the overall pattern and complexity of EEG data. Methodological differences between studies also limit their scalability in large-scale studies. To address these limitations, we applied visibility graph (VG) features and machine learning to the word repetition EEG data [
21]. The VG method maps one-dimensional, non-stationary time series into two-dimensional graphs based on mutual visibility between data points, allowing the exploration of the underlying dynamics of EEG data through graph-theoretical analysis [
22,
23]. VG is shown to preserve certain properties of the time series. For instance, periodic series yield regular graphs, while random series produce randomness [
23]. Prior work demonstrates that VG is an effective approach for probing the underlying dynamics from EEG data [
24], but often ignores the variable strength of network connections, which offer additional information. Therefore, we consider an improved VG method that can weigh network connections accordingly.
This paper proposes a novel analytical framework that integrates Weighted Visibility Graphs (WVG) with ensemble learning for the early detection of preAD using multichannel scalp EEG recorded during word repetition. WVG extends the natural VG approach by incorporating edge weights that reflect the visibility degree between time points, providing more correlation information of EEG dynamics [
25,
26]. WVG also enhances traditional ERP analysis methods by providing a more comprehensive representation of brain dynamics. Applied to the word repetition EEG data, this framework may also offer insight into how cerebral amyloidosis affects brain function in preAD.
Specifically, the framework transforms each EEG channel into a WVG, from which graph features are extracted. To reduce feature noise, t-tests are used for feature selection. Statistical analyses reveal structural differences in WVG networks between preAD and normal elderly participants, supporting the identification of preAD.
Next, Principal Component Analysis (PCA) reduces the input data into their principal components, which are then fed into various machine learning algorithms. To improve classification accuracy and generalization, we apply an ensemble method, which helps mitigate the tendency of individual models to overfit certain EEG trials, especially when training data are limited [
27]. Our experiments demonstrate the framework’s effectiveness in distinguishing preAD from normal old participants/individuals, using both linear and non-linear classifiers.
2. Methods
2.1. Participants
Participants were recruited from the University of California, Davis (UCD) Alzheimer’s Disease Research Center (ADRC) and the UC San Diego (UCSD) Shiley-Marcos ADRC. All participants provided informed written consent in accordance with the guidelines of the UCD and UCSD Human Research Protection Programs.
Participants exhibited no significant cognitive impairment on detailed neuropsychological testing and were given a clinical diagnosis of “normal cognition” by their ADRC following a comprehensive case conference review. They were classified as preclinical AD (preAD) if they had an abnormal amyloid PET scan, indicated by increased florbetapir binding in at least two brain regions per clinical read, and met current research criteria for preclinical AD in any of its three stages [
2]. Those whose amyloid PET scans were normal (no increased florbetapir binding or only mildly increased in a single brain region per clinical read) were classified as “normal old” (NO). The study included 20 patients diagnosed with preAD (mean age = 73.6 years; range: 69–81). Additionally, 20 normal old persons participated (mean age = 72.8 years; range: 64–85).
2.2. Word Repetition Paradigm
During each trial, participants were exposed to an auditory phrase indicating a category (e.g., “a type of wood”, “a breakfast food”), followed by the presentation of a visual target word approximately 1 s later (stimulus duration = 0.3 s, visual angle 0.4 degrees). These target words, which were nouns, had a fifty-fifty chance of being semantically congruous (e.g., ‘cedar’) or incongruous with the preceding category phrase. The congruous and incongruous words were carefully matched on usage frequency (mean = 32, SD = 48) and word length (mean = 5.8 characters, SD = 1.6).
Participants were instructed to wait for 3 s following the onset of each target word, then read/articulate the word aloud, and follow it with a yes/no judgment regarding its congruity with the preceding category. No time constraint was placed on participants’ responses. Among all category-word pairs, one-third were presented only once, one-third were presented twice, and the remaining one-third were presented three times (with congruous and incongruous pairs being counterbalanced). For items presented twice, the interval between the first and second presentations was brief (ranging from 0 to 3 intervening trials, spanning approximately 10 to 40 s). For items presented three times, the intervals between presentations were longer (ranging from 10 to 13 intervening trials, spanning approximately 100 to 140 s). The experimental data were parsed into six conditions: All New (AN), New Congruous (NC), New Incongruous (NI), All Old (AO), Old Congruous (OC), and Old Incongruous (OI) words. Further details of the experimental design have been published previously [
20,
21,
28].
2.3. EEG Signal Preparation
EEG recordings were obtained across participants using 32 channels [
21,
28] embedded in an elastic cap (ElectroCap, Eaton OH). Electrode placements were defined by the International 10–20 system from midline (Fz, Cz, Pz, Poz), lateral frontal (F3, F4, F7, F8, FC1, FC2, FP1, FP2), temporal (T5, T6), parietal (P3, P4, CP1, CP2), and occipital sites (O1, O2, PO7, PO8). Additional sites included approximate locations of Broca’s area (Bl/Br), Wernicke’s area (Wl/Wr) and their right hemisphere homologues, and Brodmann area 41 (L41/R41). The EEG signals were sampled at 250 Hz, band-pass filtered within the range of 0.016 to 100 Hz, and offline re-referenced to averaged mastoids. Electrode impedances were kept below 5 k
. Data preprocessing and artifact rejection were carried out using MATLAB with the EEGLAB [
29] and Fieldtrip toolboxes [
30]. EEG epochs, time-locked to the onset of target words, were extracted with a duration of 2 s before and 2 s after visual word onset. Visual inspection was conducted to identify and discard non-physiological artifacts. Subsequently, independent component analysis was employed to isolate and remove eye movement artifacts.
The artifact-free EEG epochs were then extended to 8 s by mirror-padding (adding 2 s to both the beginning and end). Subsequently, they were band-pass filtered into five frequency bands (: 1–4 Hz, : 4–8 Hz, : 8–13 Hz, : 13–30 Hz, : 30–45 Hz) using zero-phase Hamming-windowed sync finite impulse response filters, as implemented in EEGLAB (pop_eegfiltnew). This function automatically determined the optimal filter order and transition bandwidth to minimize distortions and maximize time precision.
For each of the five frequency bands of interest, a high-pass filter was initially applied, followed by a low-pass filter. Transition band widths were set to be 25% of the passband edge for passband edges >4 Hz, with a −6 dB cutoff frequency at the center of the transition band. Specifically, for the 4 Hz passband, a transition bandwidth of 2 Hz was employed, while for the 1 Hz passband ( band), a transition bandwidth of 1 Hz was utilized. Finally, both raw and band-pass filtered EEG segments were extracted, covering 1 s before and 2 s after the word onset, to facilitate further analyses.
2.4. Time Series Preprocessing
For each patient, we conducted 72 word repetition trials across each experimental condition. To enhance the signal-to-noise ratio in the EEG data and extract event-related information, we averaged the trials within each condition, resulting in a single averaged EEG time series per (condition, frequency band, channel) combination for each individual. Each time series was subsequently averaged into non-overlapping epochs of 80 ms, with the values of every 20 timesteps being averaged together. All-time series were uniformly shortened to cover 1 s before the stimulus onset and 2 s after it. This approach reduces signal noise and improves analysis efficiency:
Noise Reduction: This step effectively mitigated the risk of overfitting and minimized signal noise. The preprocessing technique acted as a low-pass filter, reducing the variance within individual EEG signals.
Efficiency: By reducing the signal length, we expedited the data analysis process.
2.5. Weighted Visibility Graphs (WVG)
The EEG signal represents the electrical activity of neurons in the brain, detected at the scalp. It exhibits prominent characteristics of non-stationarity, non-linearity, and dynamics. The VG method offers a way to explore the underlying dynamics of EEG data, converting time series into two-dimensional visual representations. Different EEG signal channels capture electrophysiological information from distinct scalp regions, enabling the creation of single-channel complex networks.1 Multiple channels yield multi-layer networks. WVG is an advanced variant of natural VG, incorporating weighted edges based on the visibility degree between corresponding data points. The construction of brain networks via WVG is illustrated schematically in
Figure 1.
In constructing a WVG from univariate EEG data
, where
, individual observations are treated as vertices. The weighted adjacency matrix
with size
is derived. Nodes in the WVG network correspond to time points
, with each edge representing a connection between two time points [
31]. The nodes
and
are considered connected if they are “visible” from each other, which means the equation
is satisfied for all time points
, where
. The absolute value of the edge weight between two nodes is then determined as follows:
2.6. Feature Extraction
To capture the characteristics of the WVG networks associated with Preclinical Alzheimer’s disease (PreAD) and those of normal subjects, we compute 17 different topological features. A previous study of mild AD dementia and MCI converters introduced 12 of these features [
21], including Clustering Coefficient (CC), Graph Index Complexity (GIC), Local Efficiency (LE), Global Efficiency (GE), Clustering Coefficient Sequence Similarity (CCSS), Small-worldness (SW), Size of Max Clique (SMaC), Cost of TSP (CTSP), Graph Density (GD), Independence Number (IN), Size of Minimum Cut (SMiC), Vertex Coloring Number (VCN). In this section, we introduce an additional five features: Average Weighted Degree (AWD), Degree Distribution (DD), Network Entropy (NE), Modularity (M), and Average Path Length (APL).
2.6.1. Average Weighted Degree
The Average Weighted Degree is the average of the weights of all edges connected to a node. It captures the average strength of connections that each node has with its neighbors in the graph. It serves as a significant metric in discerning networks with varying topologies. This parameter is computed by averaging the weights of the links incident upon all nodes within the network [
32]:
2.6.2. Degree Distribution Index
The degree distribution refers to the statistical distribution of node degrees across the graph. It tells us how degrees are spread out among all nodes. This metric
is commonly utilized to categorize complex networks, derived by tallying the occurrence of each degree across nodes. In this study, a probability distribution entity is acquired by aligning the Poisson distribution with the degree distribution vector. The degree distribution
is articulated as follows:
The degree distribution index is characterized by the
values of the fitted distribution [
33].
2.6.3. Network Entropy
The network entropy measures the distribution of edge weights and connectivity patterns across the graph. The computation of network entropy relies on the degree distribution.
2.6.4. Modularity
Modularity measures the degree to which a network can be divided into distinct, non-overlapping communities or modules. It serves as a significant metric for assessing the quality of clusters, or communities, derived from network partitioning [
32]. The modularity
Q of a weighted network is defined as follows:
Here,
m represents the sum of weights of all links in the network,
denotes the sum of weights of links attached to node
i,
indicates the community to which vertex
i belongs, and the function
equals 1 if nodes
i and
j are in the same community and 0 otherwise. In our study, we applied the Louvain method [
34] to allocate nodes into various communities. This method comprises two steps. Initially, each node is allocated to neighboring communities to maximize the gain in modularity
Q. Subsequently, a new network is constructed, where each node represents a small community from the first step, and the weights of new links are determined by the sum of weights of links between nodes in the corresponding original communities. These steps are iterated until maximal modularity is achieved, and nodes cease to move. The modularity gain
is defined as follows [
35]:
where
denotes the sum of weights of links within the community
C,
represents the sum of weights of links attached to nodes in
C,
signifies the sum of weights of links attached to node
i,
indicates the sum of weights of links from node
i to nodes in
C, and
m represents the sum of weights of all links in the network.
2.6.5. Average Path Length
Average Path measures the average number of steps or connections required to travel between any two nodes in the graph. It stands as a crucial metric for gauging the information transmission capability of networks. It serves to assess the connectivity of the overall functional network, encompassing both local and distant connections. The average path length
L is defined as follows:
5. Ensemble
To enhance the reliability and robustness of the classifiers, we incorporate an ensemble method in conjunction with the classifiers. In our dataset, each channel comprises 72 trials, which we systematically divide into 31 distinct non-overlapping subgroups. For each of these subgroups, we independently train the classifiers, allowing them to learn from different subsets of the data. Subsequently, we employ a majority voting mechanism to aggregate the predictions generated by the individual classifiers.
This ensemble strategy leverages the diversity inherent in the training data subsets, thereby mitigating the risk of overfitting and enhancing the generalization capacity of our classification model. By combining the predictions from multiple classifiers trained on diverse data subsets, we aim for a more robust and accurate classification outcome.
6. Statistical Analysis on Features
As stated in
Section 3.1, to address the issue of data leakage, we use a randomized approach to select 85% of the original data (40 subjects) as the training dataset. The remaining 15% serves as the testing dataset, with this process repeated for 100 rounds. Feature selection using two-tailed
t-tests is conducted only on the training set.
The feature extraction produces a total of 8676 features across different channels, bands, and conditions. We evaluated the statistical differences between preAD patients and normal groups feature by feature.
Table 1 presents the number of features selected by each frequency band and word repetition paradigm condition using the two-tailed
t-tests, including the mean and standard deviation (std) of the 100 splits. Only features with a significance level of
p < 0.01 are selected. We can see that the largest number of features comes from the raw band. Among the different conditions, the OI condition contributes the highest number of features.
Table 2 summarizes feature distribution after a two-tailed
t-test across different channels, revealing potential variations in neural responses across distinct brain regions. This analysis enables us to identify channels that are particularly informative in discriminating between subject groups, thereby enhancing our understanding of the underlying neural mechanisms at play.
Table 2 reveals that most selected features are derived from Fz, Pz, and Cz. This observation leads us to believe that focusing on midline sites may provide more substantial assistance in identifying preAD. The next three most helpful sites were over the temporal scalp (Wl, Wr, T6).
Moreover,
Table 3 provides a summary of the most frequently selected features after the two-tailed
t-test, offering insight into which features are particularly beneficial for distinguishing between preAD patients and normal participants in our approach.
Table 3 highlights that features, such as Clustering Coefficient, Local Efficiency and Clustering Coefficient Sequence Similarity are the most selected features.
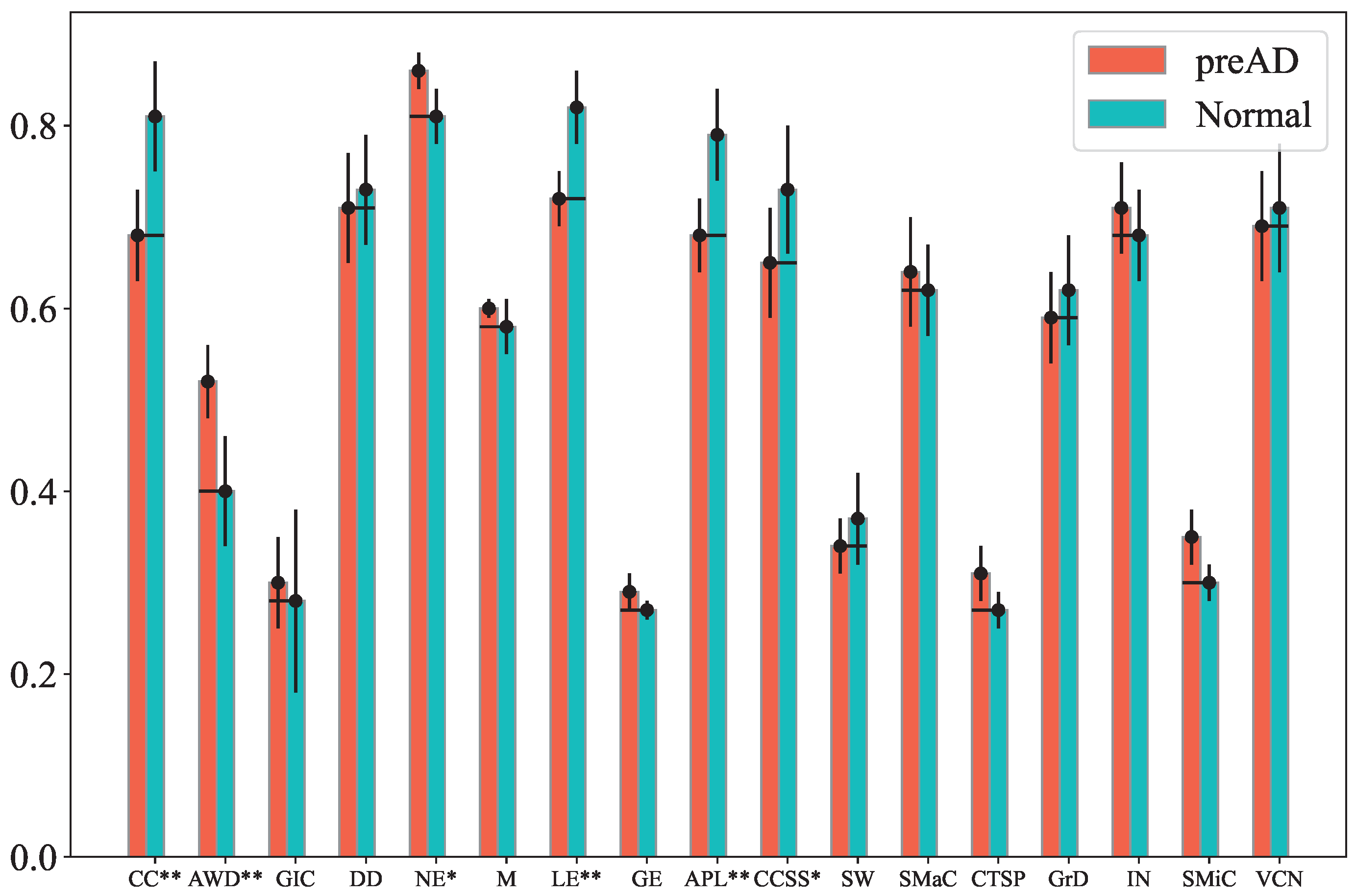
Figure 2 presents the normalized feature values (averaged across subjects) for both preAD and control groups under the OI condition, raw band, and Cz channel. Notably, the Clustering Coefficient, Local Efficiency, and CCSS values of the preAD group are lower than those of the normal group with
p < 0.01 (marked by **). Additionally, the Average Weighted Degree, Graph Index Complexity and network entropy of the preAD group are higher than those of the normal group with
p < 0.05, while the Average Path Length of the preAD group is lower than that of the normal group with
p < 0.05 (marked by *). Similar distinguishable results can be observed for other conditions, bands and channel combinations.
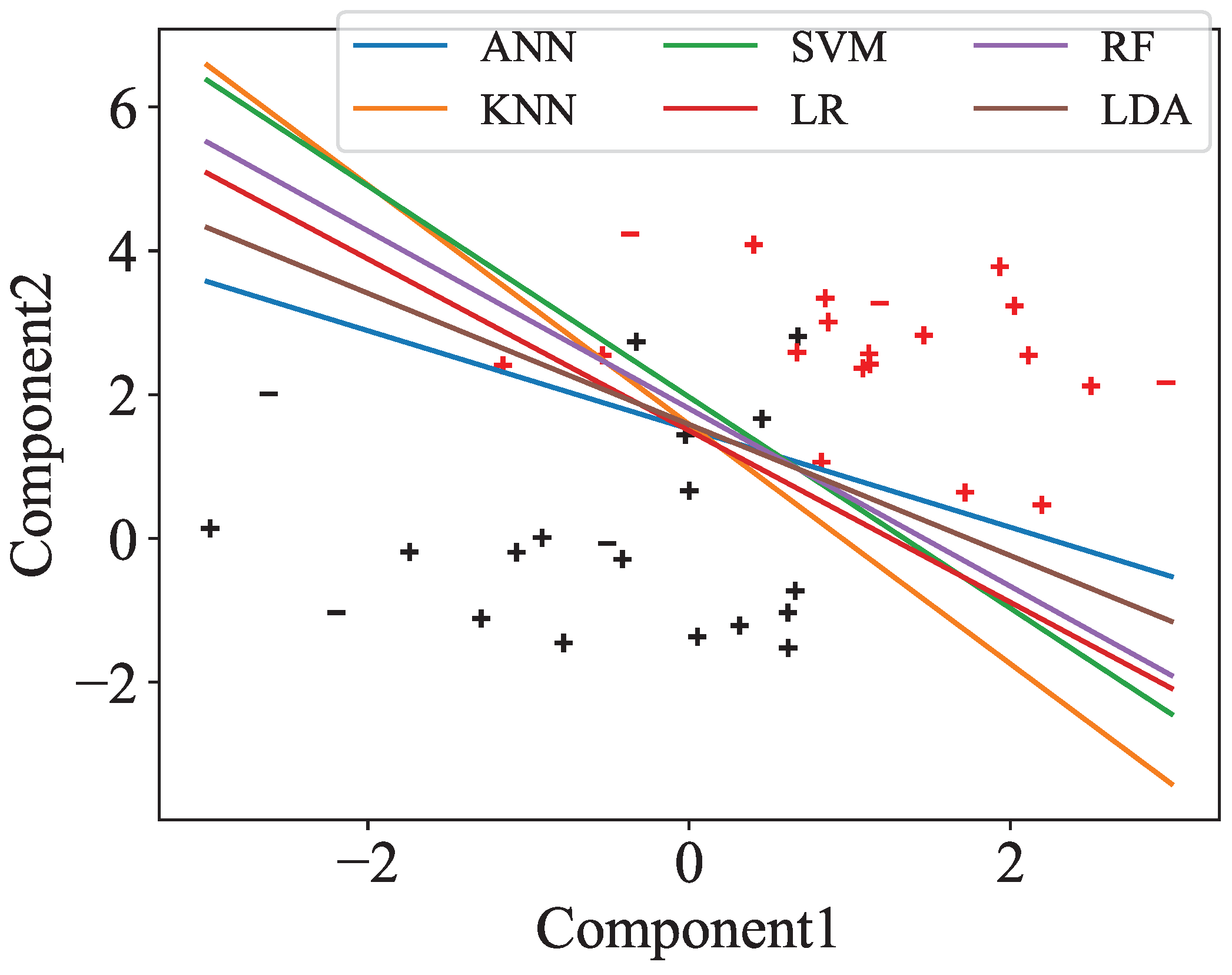
Moreover, we visualize the separation between preAD and normal by projecting the selected features down to two dimensions using PCA, based on one representative split out of 100, as shown in
Figure 3. All classifiers are able to separate the two groups, even in two dimensions, although there are a small number of misclassified points.
The ten most important features for each two-dimensional PCA projection from
Figure 3 are listed in
Table 4. The raw and delta bands produced the largest number of features, with the most common being Clustering Coefficient and Local Efficiency in electrodes Fz, Pz, and Cz, as well as Clustering Coefficient Sequence Similarity across all channels.
8. Discussion
The primary contribution of this paper lies in the development and validation of a novel analytical framework for the early detection of preclinical Alzheimer’s disease using cognitive ERP/EEG. The integration of Weighted Visibility Graphs (WVG) with ensemble learning techniques offers a robust approach to identify preAD participants with classification accuracy up to 92%. This degree of classification accuracy is comparable to AD biomarker platforms recently approved by the FDA to identify patients with amyloid pathology associated with AD [
38]. Also remarkable is that this high degree of accuracy was achieved in a sample of preclinical AD, who have increased amyloid binding on florbetapir PET scans, but no significant cognitive deficits were evident on comprehensive neuropsychological testing conducted in an ADRC setting.
Specifically, this paper makes the following contributions:
Integration of WVG with Ensemble Learning: Our framework of integrating WVG and ensemble Learning enhances traditional ERP and EEG analysis methods for the early detection of AD in its preclinical stages.
Experimental Validation: The efficacy of the proposed framework was demonstrated through experimentation on a dataset comprising 20 preAD and 20 normal old. The results showed that the framework achieves an accuracy up to 92% with both linear and non-linear classifiers, highlighting its potential clinical utility. Some specific strengths of our analytic approach are highlighted below in
Section 8.1 and
Section 8.2.
Improving clinical efficiency: Our experimental results demonstrate that our framework can achieve comparable classification results while utilizing less data, e.g., by employing fewer task conditions, a reduced number of channels and filter bands, and a smaller number of trials per channel. These outcomes indicate the potential of saving valuable clinical time.
An important study limitation is the modest size of our preclinical AD sample (n = 20). Therefore, the replication of these results in larger and independent samples is essential and will be a focus of our future research. Another limitation is that we did not obtain tau PET or tau biomarkers from CSF or plasma in the majority of these participants.
8.1. Ensemble
Ensemble learning is a powerful technique in machine learning where multiple models are combined to improve overall performance and robustness. By combining the predictions of multiple models, ensemble methods often achieve better accuracy than any individual model. This is because the errors of individual models can cancel each other out. Ensembles can also reduce the variance of the model. Moreover, ensemble models are generally more robust to noise and outliers in the data. The combined decision-making process helps in smoothing out irregularities and makes the model less sensitive to the peculiarities of the training data.
8.2. Classification Significance of Conditions/Bands/Channels/Features
Among the different conditions analyzed, the OI condition (Old incongruous words) contributes the highest number of features, as shown in
Table 1. This finding suggests that the OI condition may be particularly sensitive to neural changes associated with preAD. Moreover, we can see that the largest number of features comes from the raw band. This indicates that raw EEG signals hold significant information beyond that obtained within any single traditional EEG frequency band (e.g.,
,
), which is critical for distinguishing between preAD and normal subjects.
The majority of selected features are derived from midline sites, specifically Fz, Pz, and Cz, as shown in
Table 2. These midline channels are known to be sensitive to changes in preAD relative to robust normal elderly on the ERP word repetition and congruity effects [
15]. For example, the preAD group showed a severe reduction in the size of the P600 repetition effect, which was largest over the centro-parietal midline channels in robust normal elderly [
15]. The same group of preAD also showed a reduction in the typical centro-posterior N400 effect; their N400 effect was largest over centro-anterior scalp sites. The midline sites are known to be involved in a variety of cognitive functions, including attention, executive function, and memory processing [
39]. Midline/medial brain regions such as the posterior cingulate and precuneus are among the earliest brain predilection sites for early amyloid deposition in AD [
40]. Our observations may help future research on EEG source localization techniques—which, due to poor spatial resolution, struggle to accurately pinpoint the precise location of brain activity [
41]—in determining whether these brain regions generate the midline cognitive ERP effects. Nevertheless, focusing on these midline sites may provide more substantial assistance in identifying preclinical AD. It is possible that changes in the connectivity and activity patterns in these regions are more pronounced or detectable, making them reliable indicators for early diagnosis.
Following the midline channels, we found that left and right temporal channels (Wl, Wr, T6, T5) provided the next largest number of features used in discriminating PreAD from normal old (
Table 2). This may reflect that the temporal cortex is a predilection site for neurofibrillary tangles in early AD (Braak stage II–III). Also, the temporal cortex is particularly critical for semantic processing and the classification task used in our ERP experiment.
Table 3 and
Figure 2 highlight that features, such as Clustering Coefficient, Local Efficiency, and Clustering Coefficient Sequence Similarity are the most selected features. In graph theory, the clustering coefficient of a node measures the extent to which its neighbors form a complete graph (i.e., how interconnected the neighbors are). In the context of visibility graphs constructed from EEG signals, a high clustering coefficient indicates that the neighboring time points (nodes) have strong mutual visibility, reflecting a robust local network structure. AD is characterized by progressive neural degeneration, which disrupts both local and global brain connectivity [
42]. This disruption can manifest as changes in the clustering coefficient within EEG-derived visibility graphs. A decrease in the clustering coefficient in EEG visibility graphs could indicate a decrease in local synaptic density, the loss of neuronal connectivity and synaptic dysfunction, all of which are early signs of AD. Because synaptic density is one of the strongest predictors of AD severity [
10], tracking changes in the clustering coefficient over time may allow clinicians to sensitively monitor AD progression.
Local efficiency of a node in a graph measures the efficiency of information transfer within its immediate neighborhood. It is calculated as the average efficiency of the subnetwork formed by the node’s neighbors, excluding the node itself. High local efficiency indicates that the neighbors are well-connected, facilitating efficient local information processing. A decrease in local efficiency in EEG visibility graphs can indicate early disruptions in local neural circuits. This can be an early biomarker for AD, as synaptic dysfunction and local network breakdown are early pathological features of the disease.
Clustering Coefficient Sequence Similarity (CCSS) measures the resemblance between the clustering coefficient sequences of nodes across visibility graphs (VGs) derived from different EEG time series channels. AD disrupts normal brain network organization, leading to alterations in local clustering properties across different brain regions. This can result in reduced CCSS, as the similarity in local network organization between different regions becomes less pronounced. A decrease in CCSS between EEG channels could indicate early disruptions in brain connectivity, especially in neural networks associated with AD pathology.



 ,
, 
{kind=link}
{kind=link}
{kind=link}