

Accelerating Wound Healing Through Deep Reinforcement Learning: A Data-Driven Approach to Optimal Treatment

 ,
,  , , , , and
, , , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
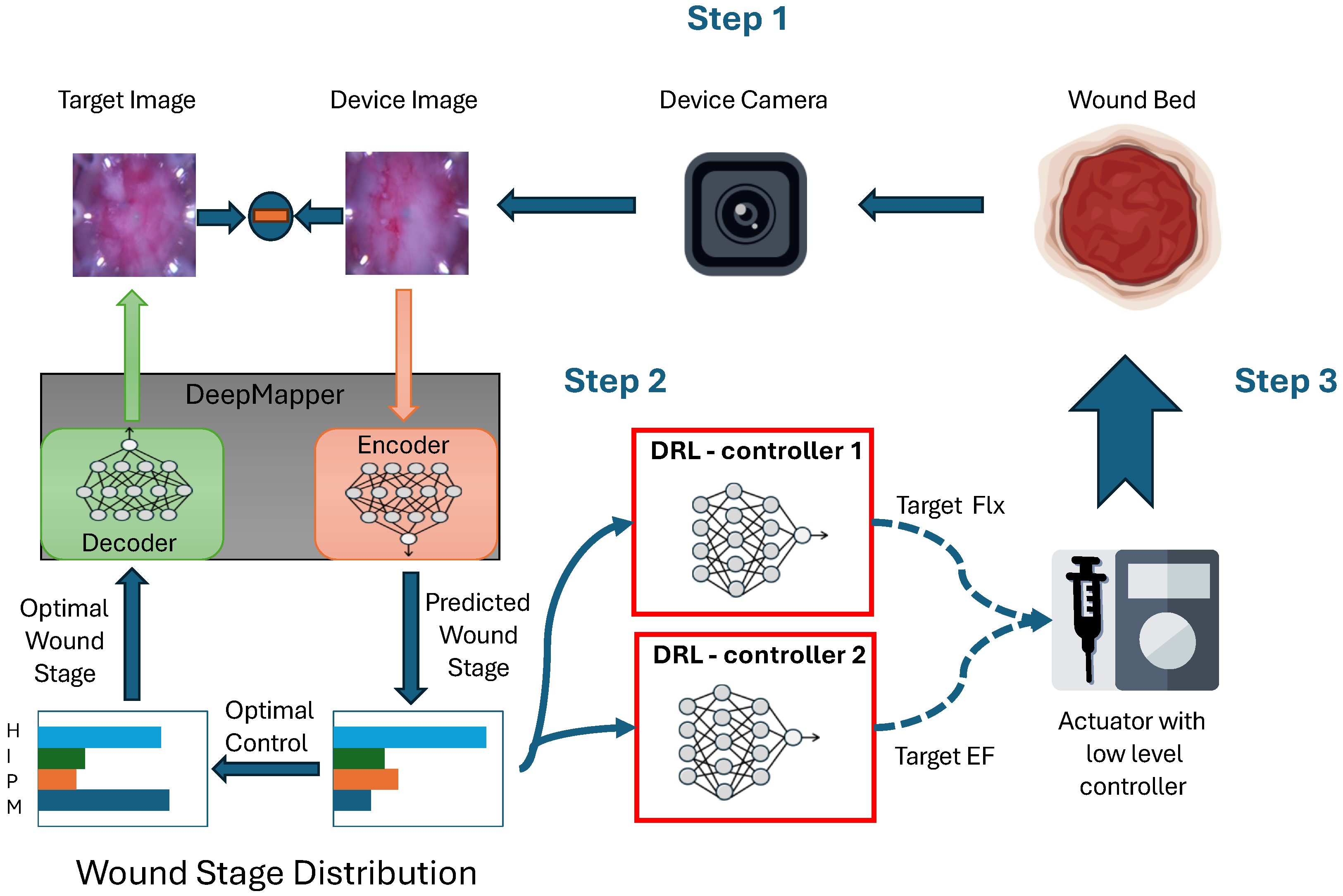
2.1. DeepMapper: Linearization of Nonlinear Wound-Healing Dynamics
2.2. Design of the Reinforcement Learning Algorithm
2.3. Description of the Advantage Actor-Critic (A2C) Algorithm
| Algorithm 1: Closed-loop control of wound healing with A2C. |
| Initialize DeepMapper; Optimize DeepMapper with historical wound images; Initialize actor and critic networks; while termination criteria not met do  |
| end |
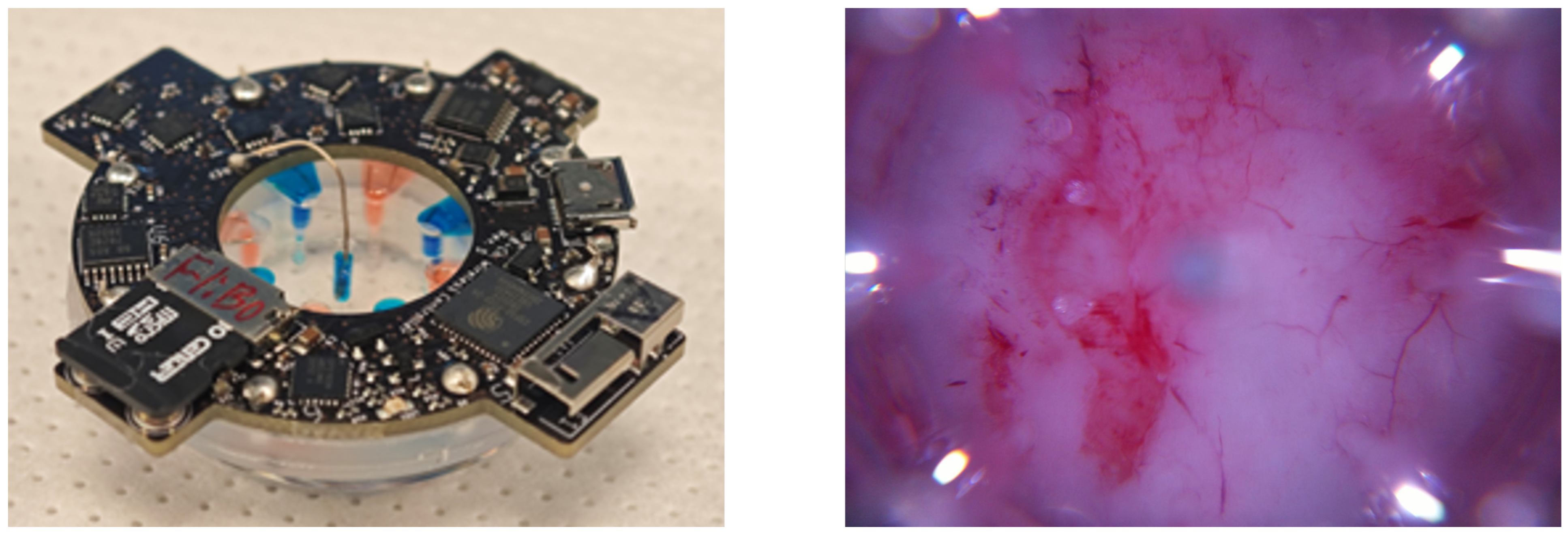
2.4. Experiments in a Porcine Model
3. Results
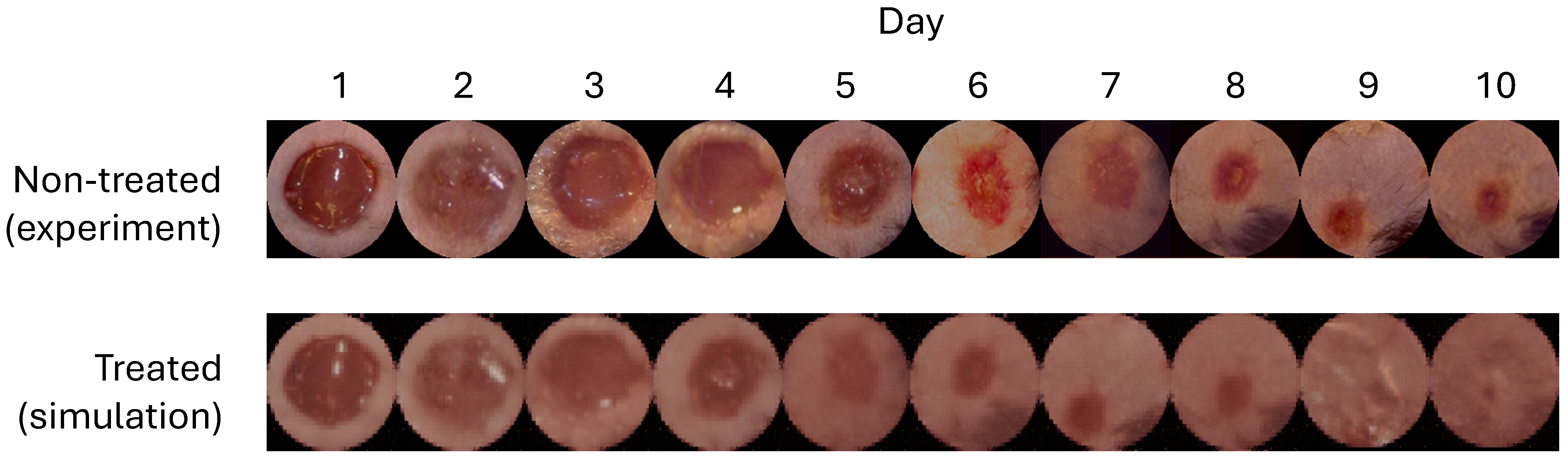
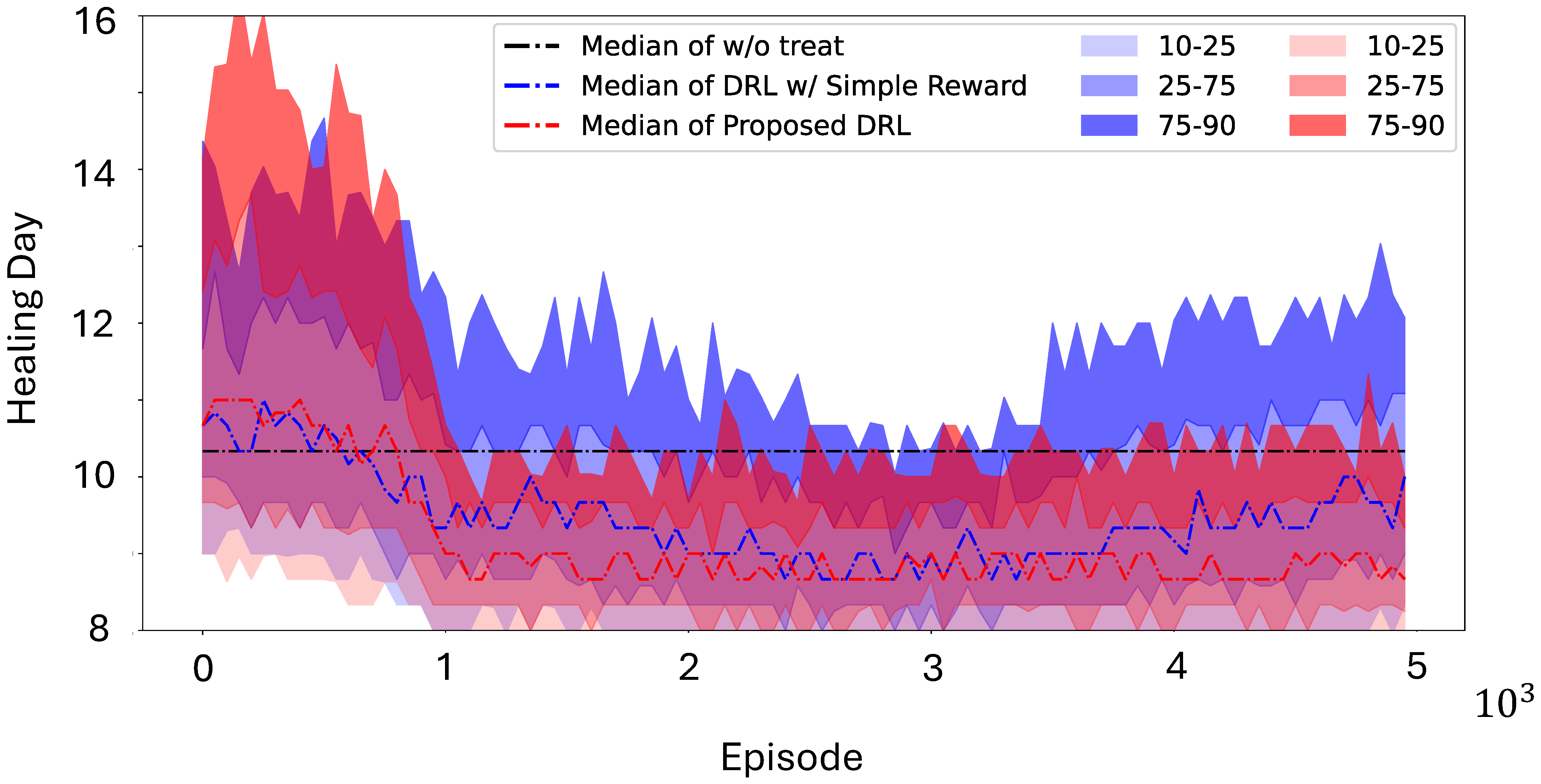
3.1. Simulation Using Mouse Data
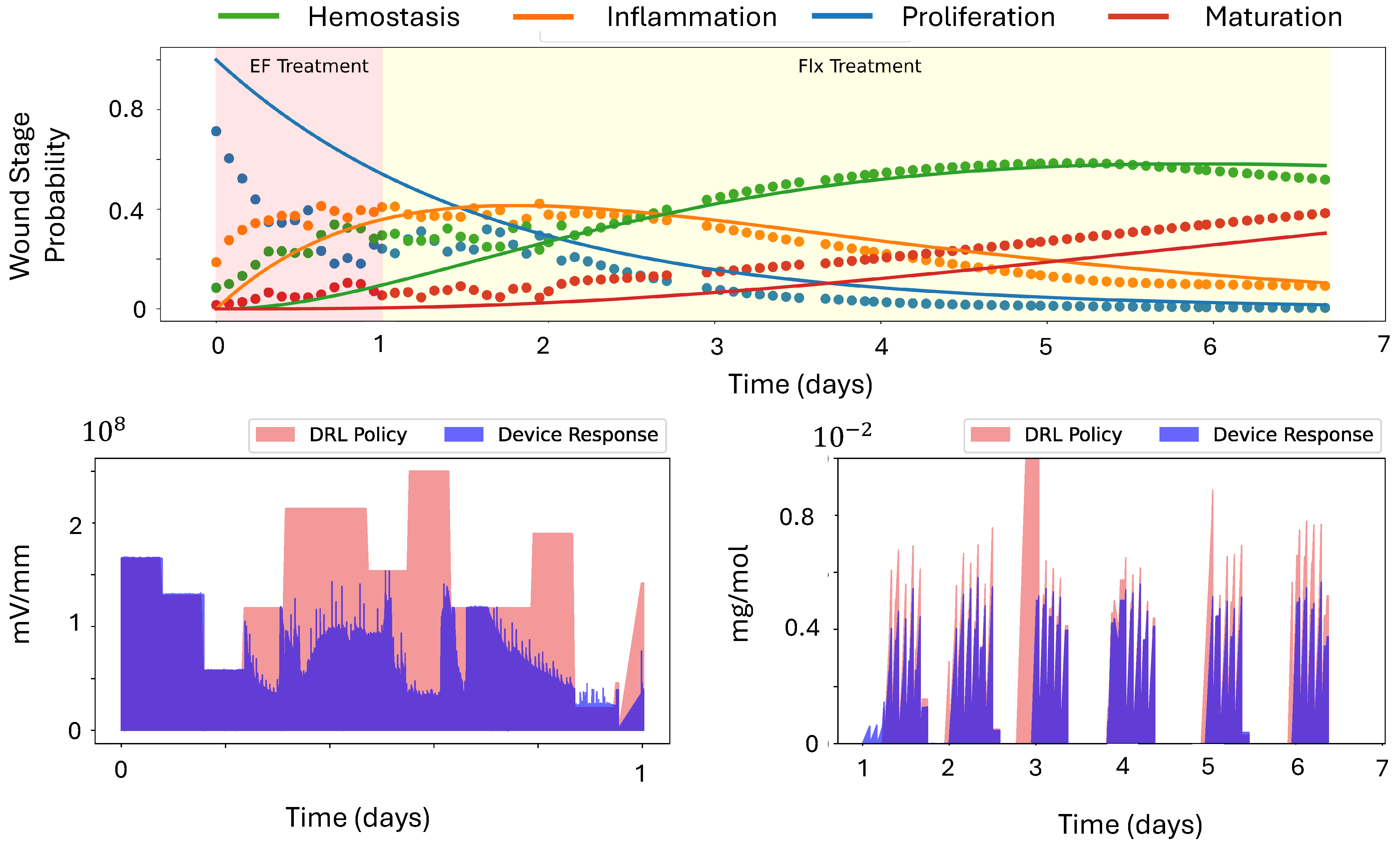
3.2. In Vivo Application
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Portou, M.; Baker, D.; Abraham, D.; Tsui, J. The innate immune system, toll-like receptors and dermal wound healing: A review. Vasc. Pharmacol. 2015, 71, 31–36. [Google Scholar] [CrossRef]
- Zlobina, K.; Jafari, M.; Rolandi, M.; Gomez, M. The role of machine learning in advancing precision medicine with feedback control. Cell Rep. Phys. Sci. 2022, 3, 101149. [Google Scholar] [CrossRef]
- Dias, R.; Torkamani, A. Artificial intelligence in clinical and genomic diagnostics. Genome Med. 2019, 11, 70. [Google Scholar] [CrossRef]
- Krittanawong, C.; Zhang, H.; Wang, Z.; Aydar, M.; Kitai, T. Artificial Intelligence in Precision Cardiovascular Medicine. J. Am. Coll. Cardiol. 2017, 69, 2657–2664. [Google Scholar] [CrossRef]
- Roden, D.M.; George, A.L., Jr. The genetic basis of variability in drug responses. Nat. Rev. Drug Discov. 2002, 1, 37–44. [Google Scholar] [CrossRef]
- Bielinski, S.J.; Olson, J.E.; Pathak, J.; Weinshilboum, R.M.; Wang, L.; Lyke, K.J.; Ryu, E.; Targonski, P.V.; Van Norstrand, M.D.; Hathcock, M.A.; et al. Preemptive genotyping for personalized medicine: Design of the right drug, right dose, right time—Using genomic data to individualize treatment protocol. In Proceedings of the Mayo Clinic Proceedings; Elsevier: Amsterdam, The Netherlands, 2014; Volume 89, pp. 25–33. [Google Scholar]
- Zhao, M. Electrical fields in wound healing—An overriding signal that directs cell migration. In Proceedings of the Seminars in Cell & Developmental Biology; Elsevier: Amsterdam, The Netherlands, 2009; Volume 20, pp. 674–682. [Google Scholar]
- Farahani, R.M.Z.; Sadr, K.; Rad, J.S.; Mesgari, M. Fluoxetine enhances cutaneous wound healing in chronically stressed Wistar rats. Adv. Ski. Wound Care 2007, 20, 157–165. [Google Scholar] [CrossRef]
- Yoon, D.J.; Nguyen, C.; Bagood, M.D.; Fregoso, D.R.; Yang, H.y.; Lopez, A.I.M.; Crawford, R.W.; Tran, J.; Isseroff, R.R. Topical fluoxetine as a potential nonantibiotic adjunctive therapy for infected wounds. J. Investig. Dermatol. 2021, 141, 1608–1612. [Google Scholar] [CrossRef]
- Zlobina, K.; Xue, J.; Gomez, M. Effective spatio-temporal regimes for wound treatment by way of macrophage polarization: A mathematical model. Front. Appl. Math. Stat. 2022, 8, 791064. [Google Scholar] [CrossRef]
- Li, H.; Asefifeyzabadi, N.; Schorger, K.; Baniya, P.; Yang, H.y.; Tebyani, M.; Barbee, A.; Hee, W.S.; Gallegos, A.; Zhu, K.; et al. Remote-Controlled Wireless Bioelectronics for Fluoxetine Therapy to Promote Wound Healing in a Porcine Model. Adv. Mater. Technol. 2024, 70039. [Google Scholar] [CrossRef]
- Gallegos, A.; Li, H.; Yang, H.y.; Villa-Martinez, G.; Bazzi, I.; Sathyanarayanan, S.; Asefifeyzabadi, N.; Baniya, P.; Hee, W.S.; Siadat, M.; et al. Fluoxetine Delivery for Wound Treatment Through an Integrated Bioelectronic Device–Pharmacokinetic Parameters and Safety Profile in Swine. bioRxiv 2025. [Google Scholar] [CrossRef]
- Gholami, B.; Haddad, W.M.; Bailey, J.M.; Tannenbaum, A.R. Optimal drug dosing control for intensive care unit sedation by using a hybrid deterministic–stochastic pharmacokinetic and pharmacodynamic model. Optim. Control Appl. Methods 2013, 34, 547–561. [Google Scholar] [CrossRef]
- Van Overschee, P.; De Moor, B. Subspace Identification for Linear Systems: Theory—Implementation—Applications; Springer Science & Business Media: Heidelberg, Germany, 2012. [Google Scholar]
- Paraskevopoulos, P.N. Modern Control Engineering; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Koopman, B.O. Hamiltonian systems and transformation in Hilbert space. Proc. Natl. Acad. Sci. USA 1931, 17, 315–318. [Google Scholar] [CrossRef]
- Mezić, I.; Banaszuk, A. Comparison of systems with complex behavior. Phys. Nonlinear Phenom. 2004, 197, 101–133. [Google Scholar] [CrossRef]
- Mezić, I. Spectral properties of dynamical systems, model reduction and decompositions. Nonlinear Dyn. 2005, 41, 309–325. [Google Scholar] [CrossRef]
- Proctor, J.L.; Brunton, S.L.; Kutz, J.N. Generalizing Koopman theory to allow for inputs and control. Siam J. Appl. Dyn. Syst. 2018, 17, 909–930. [Google Scholar] [CrossRef]
- Lian, Y.; Wang, R.; Jones, C.N. Koopman based data-driven predictive control. arXiv 2021, arXiv:2102.05122. [Google Scholar]
- Kaiser, E.; Kutz, J.N.; Brunton, S.L. Data-driven discovery of Koopman eigenfunctions for control. Mach. Learn. Sci. Technol. 2021, 2, 035023. [Google Scholar] [CrossRef]
- Ahmed, A.; del Rio-Chanona, E.A.; Mercangöz, M. Learning Linear Representations of Nonlinear Dynamics Using Deep Learning. IFAC-PapersOnLine 2022, 55, 162–169. [Google Scholar] [CrossRef]
- Lu, F.; Zlobina, K.; Rondoni, N.A.; Teymoori, S.; Gomez, M. Enhancing wound healing through deep reinforcement learning for optimal therapeutics. R. Soc. Open Sci. 2024, 11, 240228. [Google Scholar] [CrossRef]
- Li, H.; Yang, H.y.; Lu, F.; Hee, W.S.; Asefifeyzabadi, N.; Baniya, P.; Gallegos, A.; Schorger, K.; Zhu, K.; Recendez, C.; et al. Real-time diagnostics and personalized wound therapy powered by AI and bioelectronics. medRxiv 2025. [Google Scholar] [CrossRef]
- Melai, B.; Salvo, P.; Calisi, N.; Moni, L.; Bonini, A.; Paoletti, C. A graphene oxide pH sensor for wound monitoring. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 1898–1901. [Google Scholar]
- Seo, H.; Lim, H.; Lim, T.; Seo, K.; Yang, J.; Kang, Y.; Han, S.; Ju, S.; Jeong, S. Facile and cost-effective fabrication of wearable alpha-naphtholphthalein-based halochromic sensor for wound pH monitoring. Nanotechnology 2024, 35, 245502. [Google Scholar] [CrossRef]
- Schreml, S.; Meier, R.; Weiß, K.; Cattani, J.; Flittner, D.; Gehmert, S.; Wolfbeis, O.; Landthaler, M.; Babilas, P. A sprayable luminescent pH sensor and its use for wound imaging in vivo. Exp. Dermatol. 2012, 21, 951–953. [Google Scholar] [CrossRef]
- Mirani, B.; Hadisi, Z.; Pagan, E.; Dabiri, S.; van Rijt, A.; Almutairi, L.; Noshadi, I.; Armstrong, D.; Akbari, M. Smart Dual-Sensor Wound Dressing for Monitoring Cutaneous Wounds. Adv. Healthc. Mater. 2023, 12, e2203233. [Google Scholar] [CrossRef]
- Zheng, X.; Yang, Z.; Sutarlie, L.; Thangaveloo, M.; Yu, Y.; Salleh, N.; Chin, J.; Xiong, Z.; Becker, D.; Loh, X.; et al. Battery-free and AI-enabled multiplexed sensor patches for wound monitoring. Sci. Adv. 2023, 9, eadg6670. [Google Scholar] [CrossRef]
- Tang, N.; Zheng, Y.; Jiang, X.; Zhou, C.; Jin, H.; Jin, K.; Wu, W.; Haick, H. Wearable Sensors and Systems for Wound Healing-Related pH and Temperature Detection. Micromachines 2021, 12, 430. [Google Scholar] [CrossRef]
- Carrión, H.; Jafari, M.; Yang, H.Y.; Isseroff, R.R.; Rolandi, M.; Gomez, M.; Norouzi, N. HealNet-Self-Supervised Acute Wound Heal-Stage Classification. In Proceedings of the International Workshop on Machine Learning in Medical Imaging; Springer: Heidelberg, Germany, 2022; pp. 446–455. [Google Scholar]
- Ogata, K. Modern Control Engineering, 5th ed.; Pearson: Tokyo, Japan, 2010. [Google Scholar]
- Lu, F.; Zlobina, K.; Osorio, S.; Yang, H.Y.; Nava, A.; Bagood, M.D.; Rolandi, M.; Isseroff, R.R.; Gomez, M. DeepMapper: Attention-based autoencoder for system identification in wound healing and stage prediction. bioRxiv 2024. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. Proc. Int. Conf. Mach. Learn. PMLR 2016, 48, 1928–1937. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1057–1063. [Google Scholar]
- Polyak, B.T.; Juditsky, A.B. Acceleration of stochastic approximation by averaging. Siam J. Control Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef]
- Spain, K.C. The relation between the structure of the epidermis of the rat and the guinea pig, and the proliferative power of normal and regenerating epithelial cells of the same species. J. Exp. Med. 1915, 21, 193–202. [Google Scholar] [CrossRef]
- Sullivan, T.P.; Eaglstein, W.H.; Davis, S.C.; Mertz, P. The pig as a model for human wound healing. Wound Repair Regen. 2001, 9, 66–76. [Google Scholar] [CrossRef]
- Lindblad, W.J. Considerations for selecting the correct animal model for dermal wound-healing studies. J. Biomater. Sci. Polym. Ed. 2008, 19, 1087–1096. [Google Scholar] [CrossRef]
- William Montagna, P.D.; Yen, J.S. The skin of the domestic pig. J. Investig. Dermatol. 1963, 42, 11–21. [Google Scholar]
- Carrión, H.; Jafari, M.; Bagood, M.D.; Yang, H.y.; Isseroff, R.R.; Gomez, M. Automatic wound detection and size estimation using deep learning algorithms. Plos Comput. Biol. 2022, 18, e1009852. [Google Scholar] [CrossRef]
- Hee, W.S.; Tebyani, M.; Baniya, P.; Franco, C.; Keller, G.; Lu, F.; Li, H.; Asefifeyzabadi, N.; Yang, H.y.; Villa-Martinez, G.; et al. Design and validation of a wearable imaging system for automated wound monitoring in porcine model. bioRxiv 2024. [Google Scholar] [CrossRef]
- Baniya, P.; Tebyani, M.; Hee, W.S.; Li, H.; Asefifeyzabadi, N.; Yang, H.y.; Zhu, K.; Keller, G.; Franco, C.; Schorger, K.; et al. Wireless bioelectronic device for wound healing. bioRxiv 2024. [Google Scholar]
- Cullum, J.K.; Willoughby, R.A. Lanczos Algorithms for Large Symmetric Eigenvalue Computations: Vol. I: Theory; SIAM: Philadelphia, PA, USA, 2002. [Google Scholar]
- Lu, F.; Meyn, S. Convex Q Learning in a Stochastic Environment: Extended Version. arXiv 2023, arXiv:2309.05105. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, F.; Zlobina, K.; Baniya, P.; Li, H.; Rondoni, N.; Asefifeyzabadi, N.; Hee, W.S.; Tebyani, M.; Schorger, K.; Franco, C.; et al. Accelerating Wound Healing Through Deep Reinforcement Learning: A Data-Driven Approach to Optimal Treatment. Bioengineering 2025, 12, 756. https://doi.org/10.3390/bioengineering12070756
Lu F, Zlobina K, Baniya P, Li H, Rondoni N, Asefifeyzabadi N, Hee WS, Tebyani M, Schorger K, Franco C, et al. Accelerating Wound Healing Through Deep Reinforcement Learning: A Data-Driven Approach to Optimal Treatment. Bioengineering. 2025; 12(7):756. https://doi.org/10.3390/bioengineering12070756
Chicago/Turabian StyleLu, Fan, Ksenia Zlobina, Prabhat Baniya, Houpu Li, Nicholas Rondoni, Narges Asefifeyzabadi, Wan Shen Hee, Maryam Tebyani, Kaelan Schorger, Celeste Franco, and et al. 2025. "Accelerating Wound Healing Through Deep Reinforcement Learning: A Data-Driven Approach to Optimal Treatment" Bioengineering 12, no. 7: 756. https://doi.org/10.3390/bioengineering12070756
APA StyleLu, F., Zlobina, K., Baniya, P., Li, H., Rondoni, N., Asefifeyzabadi, N., Hee, W. S., Tebyani, M., Schorger, K., Franco, C., Bagood, M., Teodorescu, M., Rolandi, M., Isseroff, R., & Gomez, M. (2025). Accelerating Wound Healing Through Deep Reinforcement Learning: A Data-Driven Approach to Optimal Treatment. Bioengineering, 12(7), 756. https://doi.org/10.3390/bioengineering12070756