

Speech-Based Parkinson’s Detection Using Pre-Trained Self-Supervised Automatic Speech Recognition (ASR) Models and Supervised Contrastive Learning


Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Data Preprocessing
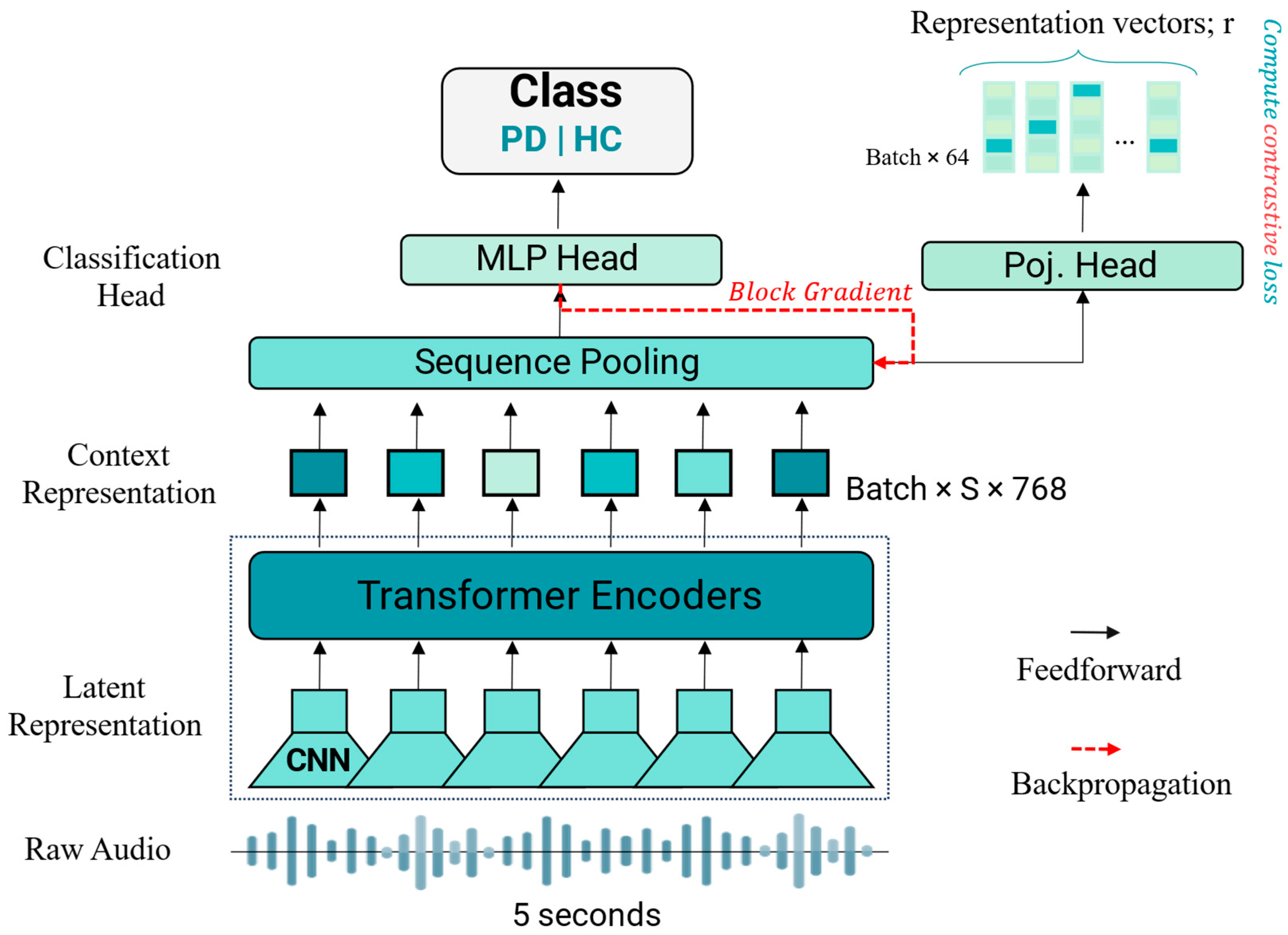
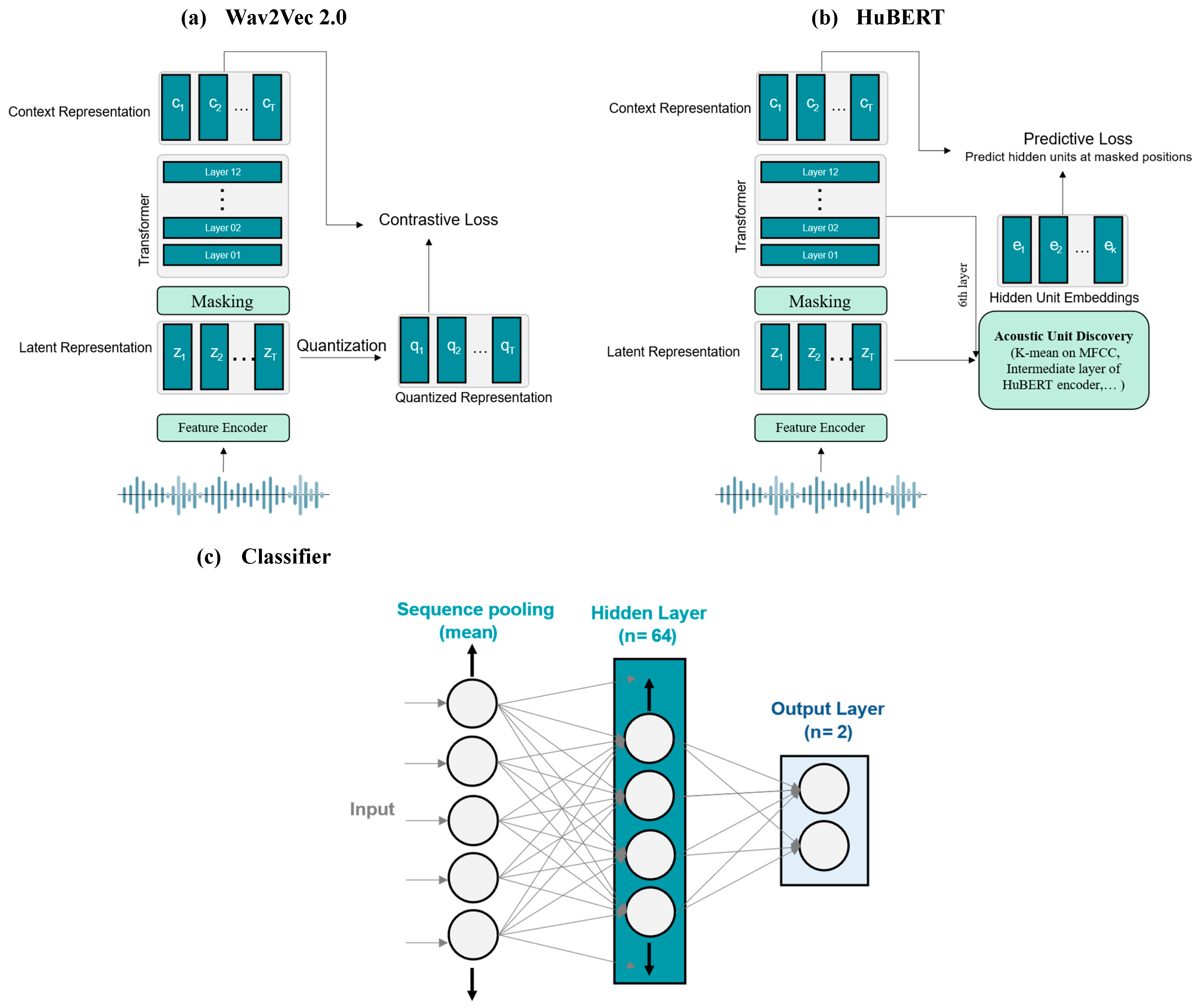
2.3. Deep Learning Models
2.4. Supervised Contrastive Learning
2.5. Baseline Features and Models
2.6. Experimental Setup and Training Parameters
2.7. Evaluation Metrics
2.8. The Grad-CAM Technique for Visual Explanations
3. Results and Discussion
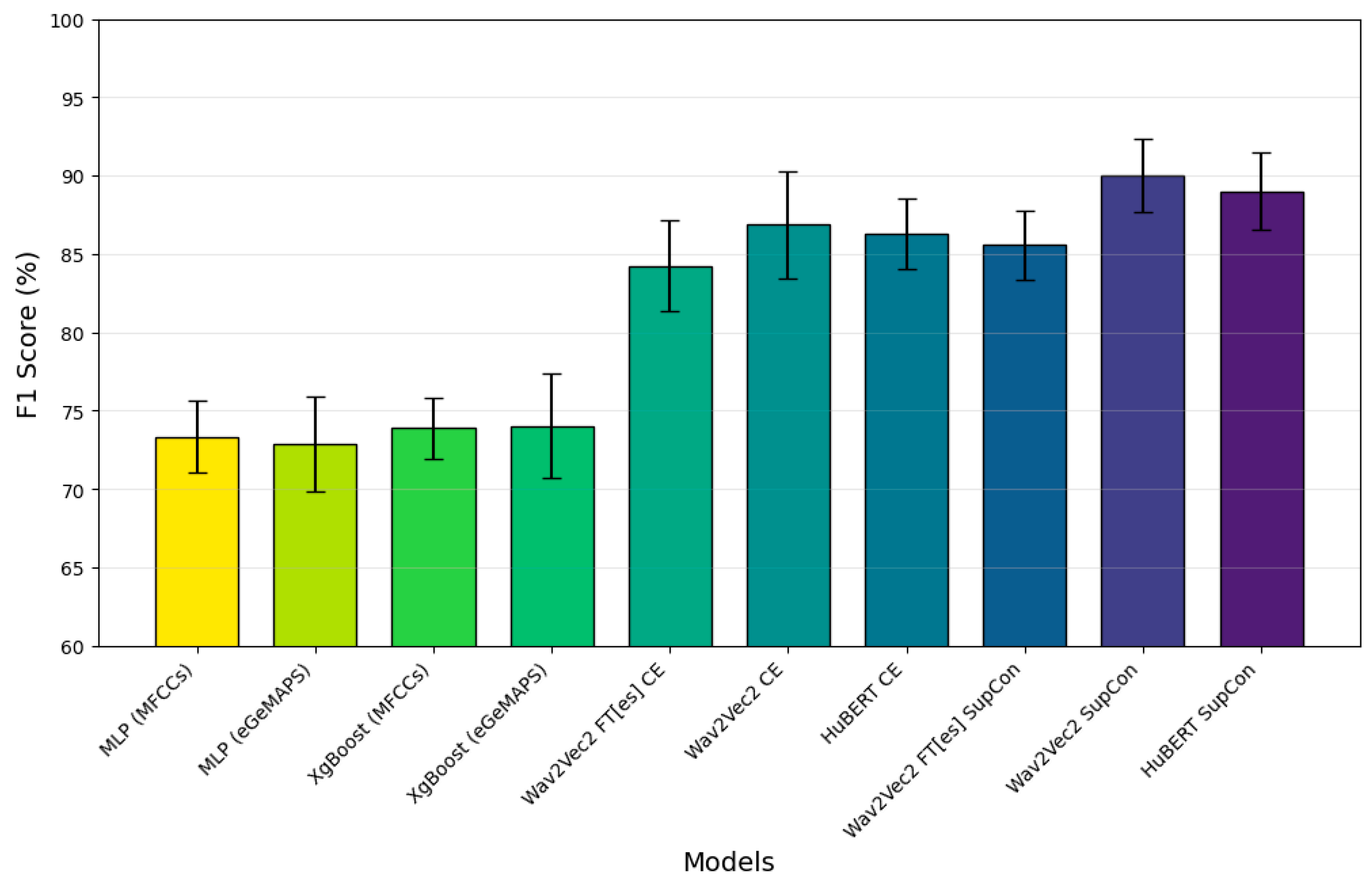
3.1. Classification Performance
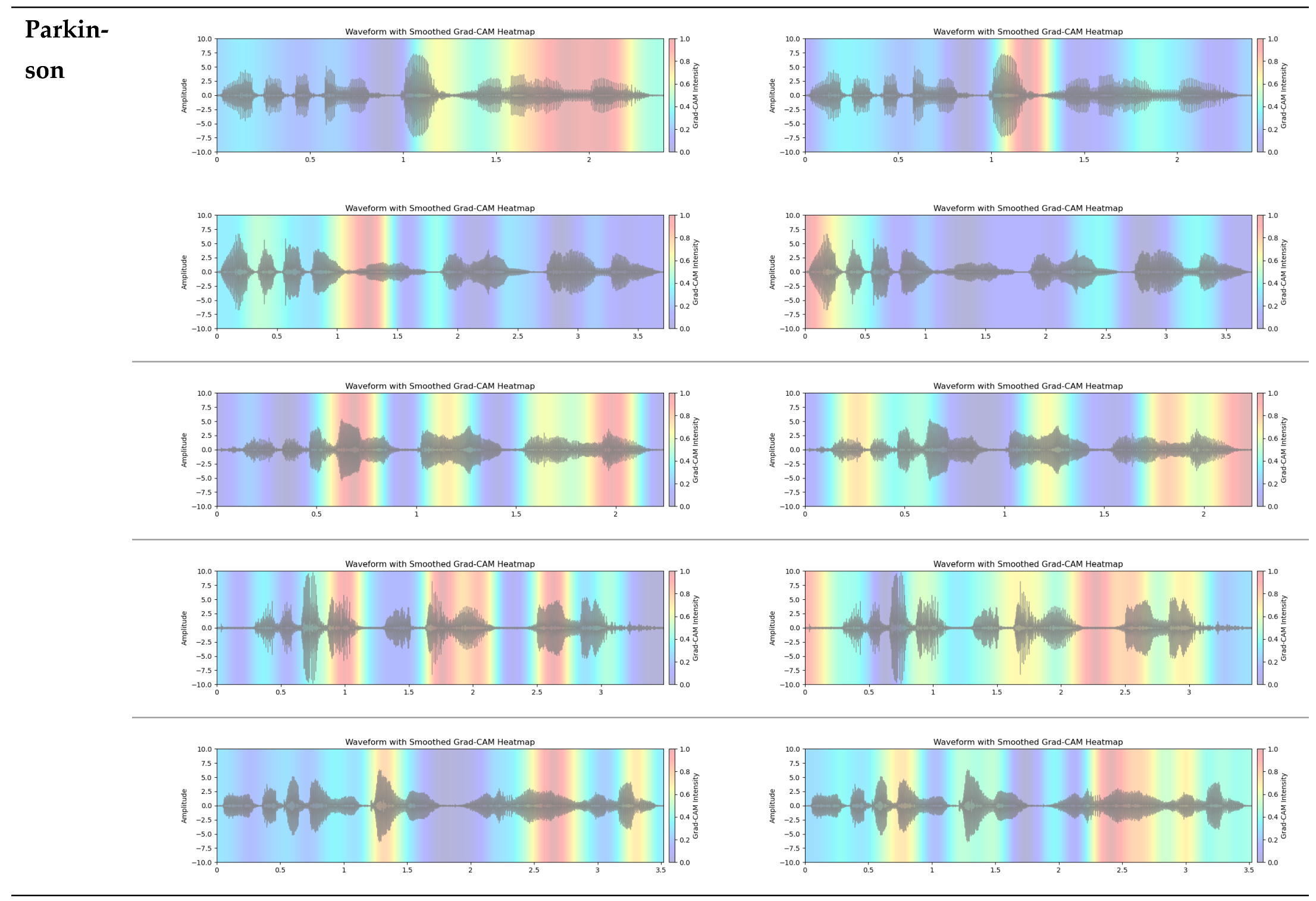
3.2. Grad-CAM Feature Visualization
3.3. Ablation Study
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AUC | Area Under the Receiver Operating Characteristic Curve |
| ASR | Automatic Speech Recognition |
| CE | Cross-Entropy |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| DDK | Diadochokinetic |
| eGeMAPS | extended Geneva Minimalistic Acoustic Parameter Set |
| FN | False Negative |
| FP | False Positive |
| FT | Fine-Tuned |
| F1 | F1 Score (harmonic mean of precision and recall) |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
| HC | Healthy Control |
| kNNs | k-Nearest Neighbors |
| MLP | Multilayer Perceptron |
| MFCCs | Mel-Frequency Cepstral Coefficients |
| ML | Machine Learning |
| PD | Parkinson’s Disease |
| RNN | Recurrent Neural Network |
| ROC | Receiver Operating Characteristic |
| SVM | Support Vector Machine |
| SN | Sensitivity (Recall) |
| SP | Specificity |
| SupCon | Supervised Contrastive Learning |
| TN | True Negative |
| TP | True Positive |
| UPDRS | Unified Parkinson’s Disease Rating Scale |
| Wav2Vec 2.0 | A self-supervised speech model developed by Facebook AI |
| τ | Temperature parameter (used in contrastive loss function) |
References
- Moustafa, A.A.; Chakravarthy, S.; Phillips, J.R.; Gupta, A.; Keri, S.; Polner, B.; Frank, M.J.; Jahanshahi, M. Motor Symptoms in Parkinson’s Disease: A Unified Framework. Neurosci. Biobehav. Rev. 2016, 68, 727–740. [Google Scholar] [CrossRef] [PubMed]
- Mei, J.; Desrosiers, C.; Frasnelli, J. Machine Learning for the Diagnosis of Parkinson’s Disease: A Review of Literature. Front. Aging Neurosci. 2021, 13, 633752. [Google Scholar] [CrossRef]
- Dorsey, E.R.; Sherer, T.; Okun, M.S.; Bloem, B.R. The Emerging Evidence of the Parkinson Pandemic. J. Park. Dis. 2018, 8, S3–S8. [Google Scholar] [CrossRef]
- GBD. 2016 Neurology Collaborators Global, Regional, and National Burden of Neurological Disorders, 1990–2016: A Systematic Analysis for the Global Burden of Disease Study 2016. Lancet Neurol. 2019, 18, 459–480. [Google Scholar] [CrossRef]
- Etoom, M.; Alwardat, M.; Aburub, A.S.; Lena, F.; Fabbrizo, R.; Modugno, N.; Centonze, D. Therapeutic Interventions for Pisa Syndrome in Idiopathic Parkinson’s Disease. A Scoping Systematic Review. Clin. Neurol. Neurosurg. 2020, 198, 106242. [Google Scholar] [CrossRef] [PubMed]
- Bridges, B.; Taylor, J.; Weber, J.T. Evaluation of the Parkinson’s Remote Interactive Monitoring System in a Clinical Setting: Usability Study. JMIR Hum. Factors 2024, 11, e54145. [Google Scholar] [CrossRef] [PubMed]
- Hssayeni, M.D.; Jimenez-Shahed, J.; Burack, M.A.; Ghoraani, B. Symptom-Based, Dual-Channel LSTM Network for The Estimation of Unified Parkinson’s Disease Rating Scale III. In Proceedings of the 2019 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Chicago, IL, USA, 19–22 May 2019; pp. 1–4. [Google Scholar]
- Cao, F.; Vogel, A.P.; Gharahkhani, P.; Renteria, M.E. Speech and Language Biomarkers for Parkinson’s Disease Prediction, Early Diagnosis and Progression. Npj Park. Dis. 2025, 11, 57. [Google Scholar] [CrossRef]
- Maffia, M.; De Micco, R.; Pettorino, M.; Siciliano, M.; Tessitore, A.; De Meo, A. Speech Rhythm Variation in Early-Stage Parkinson’s Disease: A Study on Different Speaking Tasks. Front. Psychol. 2021, 12, 668291. [Google Scholar] [CrossRef]
- Postuma, R.B. Voice Changes in Prodromal Parkinson’s Disease: Is a New Biomarker within Earshot? Sleep Med. 2016, 19, 148–149. [Google Scholar] [CrossRef]
- Rahman, S.; Hasan, M.; Sarkar, A.K.; Khan, F. Classification of Parkinson’s Disease Using Speech Signal with Machine Learning and Deep Learning Approaches. Eur. J. Electr. Eng. Comput. Sci. 2023, 7, 20–27. [Google Scholar] [CrossRef]
- Moro-Velazquez, L.; Gomez-Garcia, J.A.; Arias-Londoño, J.D.; Dehak, N.; Godino-Llorente, J.I. Advances in Parkinson’s Disease Detection and Assessment Using Voice and Speech: A Review of the Articulatory and Phonatory Aspects. Biomed. Signal Process. Control 2021, 66, 102418. [Google Scholar] [CrossRef]
- Ngo, Q.C.; Motin, M.A.; Pah, N.D.; Drotár, P.; Kempster, P.; Kumar, D. Computerized Analysis of Speech and Voice for Parkinson’s Disease: A Systematic Review. Comput. Methods Programs Biomed. 2022, 226, 107133. [Google Scholar] [CrossRef] [PubMed]
- Kodali, M.; Kadiri, S.R.; Alku, P. Automatic Classification of the Severity Level of Parkinson’s Disease: A Comparison of Speaking Tasks, Features, and Classifiers. Comput. Speech Lang. 2024, 83, 101548. [Google Scholar] [CrossRef]
- Govindu, A.; Palwe, S. Early Detection of Parkinson’s Disease Using Machine Learning. Procedia Comput. Sci. 2023, 218, 249–261. [Google Scholar] [CrossRef]
- Wang, Q.; Fu, Y.; Shao, B.; Chang, L.; Ren, K.; Chen, Z.; Ling, Y. Early Detection of Parkinson’s Disease from Multiple Signal Speech: Based on Mandarin Language Dataset. Front. Aging Neurosci. 2022, 14, 1036588. [Google Scholar] [CrossRef]
- Motin, M.A.; Pah, N.D.; Raghav, S.; Kumar, D.K. Parkinson’s Disease Detection Using Smartphone Recorded Phonemes in Real World Conditions. IEEE Access 2022, 10, 97600–97609. [Google Scholar] [CrossRef]
- Mamun, M.; Mahmud, M.I.; Hossain, M.I.; Islam, A.M.; Ahammed, M.S.; Uddin, M.M. Vocal Feature Guided Detection of Parkinson’s Disease Using Machine Learning Algorithms. In Proceedings of the 2022 IEEE 13th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 26–29 October 2022; IEEE: New York, NY, USA, 2022; pp. 0566–0572. [Google Scholar]
- Jeong, S.-M.; Song, Y.-D.; Seok, C.-L.; Lee, J.-Y.; Lee, E.C.; Kim, H.-J. Machine Learning-Based Classification of Parkinson’s Disease Using Acoustic Features: Insights from Multilingual Speech Tasks. Comput. Biol. Med. 2024, 182, 109078. [Google Scholar] [CrossRef]
- Ibarra, E.J.; Arias-Londoño, J.D.; Zañartu, M.; Godino-Llorente, J.I. Towards a Corpus (and Language)-Independent Screening of Parkinson’s Disease from Voice and Speech through Domain Adaptation. Bioengineering 2023, 10, 1316. [Google Scholar] [CrossRef]
- Hireš, M.; Gazda, M.; Drotár, P.; Pah, N.D.; Motin, M.A.; Kumar, D.K. Convolutional Neural Network Ensemble for Parkinson’s Disease Detection from Voice Recordings. Comput. Biol. Med. 2022, 141, 105021. [Google Scholar] [CrossRef]
- Quan, C.; Ren, K.; Luo, Z.; Chen, Z.; Ling, Y. End-to-End Deep Learning Approach for Parkinson’s Disease Detection from Speech Signals. Biocybern. Biomed. Eng. 2022, 42, 556–574. [Google Scholar] [CrossRef]
- Hireš, M.; Drotár, P.; Pah, N.D.; Ngo, Q.C.; Kumar, D.K. On the Inter-Dataset Generalization of Machine Learning Approaches to Parkinson’s Disease Detection from Voice. Int. J. Med. Inf. 2023, 179, 105237. [Google Scholar] [CrossRef] [PubMed]
- Aversano, L.; Bernardi, M.L.; Cimitile, M.; Iammarino, M.; Montano, D.; Verdone, C. A Machine Learning Approach for Early Detection of Parkinson’s Disease Using Acoustic Traces. In Proceedings of the 2022 IEEE International Conference on Evolving and Adaptive Intelligent Systems (EAIS), Larnaca, Cyprus, 25–26 May 2022; IEEE: Larnaca, Cyprus, 2022; pp. 1–8. [Google Scholar]
- Malekroodi, H.S.; Madusanka, N.; Lee, B.; Yi, M. Leveraging Deep Learning for Fine-Grained Categorization of Parkinson’s Disease Progression Levels through Analysis of Vocal Acoustic Patterns. Bioengineering 2024, 11, 295. [Google Scholar] [CrossRef] [PubMed]
- Rezaee, K.; Savarkar, S.; Yu, X.; Zhang, J. A Hybrid Deep Transfer Learning-Based Approach for Parkinson’s Disease Classification in Surface Electromyography Signals. Biomed. Signal Process. Control 2022, 71, 103161. [Google Scholar] [CrossRef]
- Valarmathi, P.; Suganya, Y.; Saranya, K.R.; Shanmuga Priya, S. Enhancing Parkinson Disease Detection through Feature Based Deep Learning with Autoencoders and Neural Networks. Sci. Rep. 2025, 15, 8624. [Google Scholar] [CrossRef]
- Xu, H.; Xie, W.; Pang, M.; Li, Y.; Jin, L.; Huang, F.; Shao, X. Non-Invasive Detection of Parkinson’s Disease Based on Speech Analysis and Interpretable Machine Learning. Front. Aging Neurosci. 2025, 17, 1586273. [Google Scholar] [CrossRef]
- van Gelderen, L.; Tejedor-García, C. Innovative Speech-Based Deep Learning Approaches for Parkinson’s Disease Classification: A Systematic Review. Appl. Sci. 2024, 14, 7873. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Hsu, W.-N.; Bolte, B.; Tsai, Y.-H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. IEEEACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Javanmardi, F.; Kadiri, S.R.; Alku, P. Pre-Trained Models for Detection and Severity Level Classification of Dysarthria from Speech. Speech Commun. 2024, 158, 103047. [Google Scholar] [CrossRef]
- Kunešová, M.; Zajíc, Z. Multitask Detection of Speaker Changes, Overlapping Speech and Voice Activity Using Wav2vec 2.0. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Zhao, W.; Yang, Z. An Emotion Speech Synthesis Method Based on VITS. Appl. Sci. 2023, 13, 2225. [Google Scholar] [CrossRef]
- Fan, Z.; Li, M.; Zhou, S.; Xu, B. Exploring Wav2vec 2.0 on Speaker Verification and Language Identification. arXiv 2021, arXiv:2012.06185. [Google Scholar]
- Klempíř, O.; Příhoda, D.; Krupička, R. Evaluating the Performance of Wav2vec Embedding for Parkinson’s Disease Detection. Meas. Sci. Rev. 2023, 23, 260–267. [Google Scholar] [CrossRef]
- Klempir, O.; Skryjova, A.; Tichopad, A.; Krupicka, R. Ranking Pretrained Speech Embeddings in Parkinson’s Disease Detection: Does Wav2Vec 2.0 Outperform Its 1.0 Version Across Speech Modes and Languages? medRxiv 2025. [Google Scholar] [CrossRef]
- Purohit, T.; Ruvolo, B.; Orozco-Arroyave, J.R.; Magimai-Doss, M. Automatic Parkinson’s Disease Detection from Speech: Layer Selection vs Adaptation of Foundation Models. In Proceedings of the ICASSP 2025—2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025; IEEE: Hyderabad, India, 2025; pp. 1–5. [Google Scholar]
- Chronowski, M.; Kłaczyński, M.; Dec-Ćwiek, M.; Porębska, K. Parkinson’s Disease Diagnostics Using Ai and Natural Language Knowledge Transfer. Diagnostyka 2023, 25, 1–6. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. arXiv 2021, arXiv:2004.11362. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; Andre, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The Geneva Minimalistic Acoustic Parameter Set (GeMAPS) for Voice Research and Affective Computing. IEEE Trans. Affect. Comput. 2016, 7, 190–202. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Mendes-Laureano, J.; Gómez-García, J.A.; Guerrero-López, A.; Luque-Buzo, E.; Arias-Londoño, J.D.; Grandas-Pérez, F.J.; Godino-Llorente, J.I. NeuroVoz: A Castillian Spanish Corpus of Parkinsonian Speech. arXiv 2024, arXiv:2403.02371. [Google Scholar] [CrossRef]
- Mendes-Laureano, J.; Gómez-García, J.A.; Guerrero-López, A.; Luque-Buzo, E.; Arias-Londoño, J.D.; Gran-das-Pérez, F.J.; Godino Llorente, J.I. NeuroVoz: A Castillian Spanish corpus of parkinsonian speech (1.0.0) [Data set]. Zenodo 2024. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Moya-Galé, G.; Walsh, S.J.; Goudarzi, A. Automatic Assessment of Intelligibility in Noise in Parkinson Disease: Validation Study. J. Med. Internet Res. 2022, 24, e40567. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Gidaris, S.; Bursuc, A.; Simeoni, O.; Vobecky, A.; Komodakis, N.; Cord, M.; Pérez, P. MOCA: Self-Supervised Representation Learning by Predicting Masked Online Codebook Assignments. arXiv 2024, arXiv:2307.09361. [Google Scholar]
- Wang, Y.; Liang, Q.; Xiao, C.; Li, Y.; Moubayed, N.A.; Lin, C. Audio Contrastive Based Fine-Tuning. arXiv 2023, arXiv:2309.11895. [Google Scholar]
- Corrêa Dias, A.; Dias, F.; Moreira, H.; Moreira, V.; Comba, J.L. Team INF-UFRGS at SemEval-2023 Task 7: Supervised Contrastive Learning for Pair-Level Sentence Classification and Evidence Retrieval. In Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023), Toronto, Canada, 17–18 July 2023; Ojha, A.K., Doğruöz, A.S., Da San Martino, G., Tayyar Madabushi, H., Kumar, R., Sartori, E., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2023; pp. 700–706. [Google Scholar]
- Li, S.; Hu, X.; Lin, L.; Wen, L. Pair-Level Supervised Contrastive Learning for Natural Language Inference. arXiv 2022, arXiv:2201.10927. [Google Scholar]
- Wang, X.; Han, X.; Huang, W.; Dong, D.; Scott, M.R. Multi-Similarity Loss with General Pair Weighting for Deep Metric Learning. arXiv 2020, arXiv:1904.06627. [Google Scholar]
- Narendra, N.P.; Alku, P. Dysarthric Speech Classification from Coded Telephone Speech Using Glottal Features. Speech Commun. 2019, 110, 47–55. [Google Scholar] [CrossRef]
- Gurugubelli, K.; Vuppala, A.K. Perceptually Enhanced Single Frequency Filtering for Dysarthric Speech Detection and Intelligibility Assessment. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6410–6414. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.W.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and Music Signal Analysis in Python. In Proceedings of the Python in Science Conference, Austin, TX, USA, 6–12 July 2015. [Google Scholar] [CrossRef]
- Eyben, F.; Weninger, F.; Gross, F.; Schuller, B. Recent Developments in openSMILE, the Munich Open-Source Multimedia Feature Extractor. In Proceedings of the 21st ACM International Conference on Multimedia, Barcelona, Spain, 21–25 October 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 835–838. [Google Scholar]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; Walt, S., van der Millman, J., Eds.; pp. 56–61. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array Programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]
- Mellak, Y.; Achim, A.; Ward, A.; Descombes, X. A Machine Learning Framework for the 2 Quantification of Experimental Uveitis in Murine 3 OCT. Biomed. Opt. Express. 2023, 14, 3413–3432. [Google Scholar] [CrossRef] [PubMed]
- Lim, W.S.; Chiu, S.-I.; Peng, P.-L.; Jang, J.-S.R.; Lee, S.-H.; Lin, C.-H.; Kim, H.-J. A Cross-Language Speech Model for Detection of Parkinson’s Disease. J. Neural Transm. 2025, 132, 579–590. [Google Scholar] [CrossRef]
- La Quatra, M.; Orozco-Arroyave, J.R.; Siniscalchi, M.S. Bilingual Dual-Head Deep Model for Parkinson’s Disease Detection from Speech. In Proceedings of the ICASSP 2025—2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025; pp. 1–5. [Google Scholar]
- Chakraborty, S.; Bhattacharya, S. Application of XGBoost Algorithm as a Predictive Tool in a CNC. Rep. Mech. Eng. 2021, 2, 190–201. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Values |
|---|---|
| Epochs | 100 |
| Batch size | 32 |
| Initial learning rate | 2 × 10−5 |
| Optimizer | AdamW (β1 = 0.9, β2 = 0.999, Weight decay = 0.01) |
| Loss function | Cross-entropy loss and supervised contrastive loss |
| Dropout | 0.2 |
| Metric | AC [%] | F1 [%] | P [%] | SN [%] | SP [%] | |
|---|---|---|---|---|---|---|
| Model | ||||||
| MLP | ||||||
| +MFCC Features | 72.51 (±2.28) | 73.33 (±2.85) | 71.14 (±1.82) | 75.77 (±4.99) | 69.26 (±2.84) | |
| +eGeMAPS Features | 72.86 (±3.05) | 74.51 (±3.03) | 70.19 (±2.47) | 79.43 (±3.98) | 66.29 (±2.77) | |
| XgBoost | ||||||
| +MFCC Features | 72.74 (±2.02) | 73.86 (±1.02) | 70.98 (±2.10) | 77.03 (±2.60) | 68.46 (±2.95) | |
| +eGeMAPS Features | 73.60 (±3.19) | 74.02 (±3.36) | 72.83 (±2.96) | 75.31 (±4.49) | 71.89 (±3.60) | |
| Wav2Vec 2.0 | ||||||
| +CE | 85.89 (±4.27) | 86.86 (±3.42) | 82.02 (±5.89) | 92.69 (±4.30) | 79.09 (±9.09) | |
| + SupCon | 89.43 (±2.31) | 90.00 (±2.35) | 85.31 (±2.77) | 95.43 (±4.83) | 83.43 (±4.00) | |
| HuBERT | ||||||
| +CE | 85.49 (±2.41) | 86.27 (±2.26) | 82.10 (±24) | 91.31 (±5.86) | 79.66 (±6.88) | |
| + SupCon | 88.06 (±2.97) | 88.99 (±2.48) | 83.02 (±24) | 96.11 (±3.11) | 80.00 (±6.60) | |
| Wav2Vec 2.0-FT [Spanish] | ||||||
| +CE | 83.83 (±2.45) | 84.21 (±2.90) | 82.24 (±3.63) | 86.74 (±7.33) | 80.91 (±6.14) | |
| + SupCon | 84.40 (±2.84) | 85.56 (±2.18) | 80.17 (±4.83) | 92.11 (±4.61) | 76.69 (±8.18) | |
| Study | Method | Dataset | Performance |
|---|---|---|---|
| Javanmardi et al. [32] | Wav2Vec 2.0 and HuBERT | UA-Speech | 85–92% accuracy |
| Klempíř et al. [36] | Wav2Vec embeddings | Multiple | 0.77–0.98 AUC |
| Chronowski et al. [39] | Wav2Vec 2.0 | Smartphone data | 97.92% accuracy |
| Our study | Wav2Vec 2.0 + SupCon | NeuroVoz | 90.0% F1, 0.92 AUC |
| Metric | Projection Head Size | AC [%] | F1 [%] | P [%] | SN [%] | SP [%] | |
|---|---|---|---|---|---|---|---|
| Model | |||||||
| Wav2Vec 2.0 + SupCon | |||||||
| 32 | 89.43 (±2.31) | 90.00 (±2.35) | 85.31 (±2.77) | 95.43 (±4.83) | 83.43 (±4.00) | ||
| 64 | 89.09 (±1.75) | 89.63 (±1.53) | 85.65 (±3.47) | 94.17 (±3.29) | 84.00 (±4.83) | ||
| 128 | 87.60 (±1.33) | 88.17 (±1.42) | 84.25 (±1.67) | 92.57 (±3.45) | 82.63 (±2.41) | ||
| 256 | 87.43 (±2.99) | 88.29 (±2.49) | 83.01 (±3.93) | 94.40 (±2.15) | 80.46 (±5.79) | ||
| HuBERT+ SupCon | |||||||
| 32 | 88.06 (±2.97) | 88.99 (±2.48) | 83.02 (±4.52) | 96.11 (±3.11) | 80.00 (±6.60) | ||
| 64 | 87.83 (±1.55) | 88.72 (±1.38) | 82.77 (±2.27) | 95.66 (±2.51) | 80.00 (±3.38) | ||
| 128 | 87.49 (±2.57) | 88.45 (±2.03) | 82.67 (±4.73) | 95.43 (±3.90) | 79.54 (±7.24) | ||
| 256 | 87.60 (±0.87) | 88.42 (±0.65) | 83.07 (±2.40) | 94.63 (±2.67) | 80.57 (±3.77) | ||
| Metric | Fine-Tuning of Model? | AC [%] | F1 [%] | P [%] | SN [%] | SP [%] | |
|---|---|---|---|---|---|---|---|
| Model | |||||||
| Wav2Vec 2.0 + CE | |||||||
| √ | 85.89 (±4.27) | 86.86 (±3.42) | 82.02 (±5.89) | 92.69 (±4.30) | 79.09 (±1.97) | ||
| × | 70.29 (±1.82) | 65.36 (±5.35) | 78.39 (±4.72) | 57.14 (±10.55) | 83.43 (±7.45) | ||
| HuBERT+ CE | |||||||
| √ | 85.49 (±2.41) | 86.27 (±2.26) | 82.10 (±24) | 91.31 (±5.86) | 79.66 (±6.88) | ||
| × | 82.69 (±1.21) | 84.30 (±0.96) | 77.17 (±1.68) | 92.91 (±1.32) | 72.46 (±2.69) | ||
| Wav2Vec 2.0-FT[es] + CE | |||||||
| √ | 83.83 (±2.45) | 84.21 (±2.90) | 82.24 (±3.63) | 86.74 (±7.33) | 80.91 (±6.14) | ||
| × | 65.54 (±2.05) | 84.21 (±62.95) | 67.97 (±1.73) | 58.74 (±4.94) | 72.34 (±3.34) | ||
| Metric | Temperature | AC [%] | F1 [%] | P [%] | SN [%] | SP [%] | |
|---|---|---|---|---|---|---|---|
| Model | |||||||
| Wav2Vec 2.0 + SupCon | |||||||
| 0.03 | 87.43 (±1.34) | 87.86 (±1.24) | 85.11 (±5.09) | 90.97 (±3.49) | 79.66 (±7.34) | ||
| 0.07 | 89.43 (±2.31) | 90.00 (±2.35) | 85.31 (±2.77) | 95.43 (±4.83) | 83.43 (±4.00) | ||
| 0.10 | 87.89 (±2.82) | 88.32 (±2.67) | 85.39 (±3.73) | 91.66 (±4.6) | 84.11 (±5.12) | ||
| HuBERT + SupCon | |||||||
| 0.03 | 87.54 (±3.58) | 88.52 (±3.03) | 82.70 (±5.09) | 95.43 (±2.91) | 79.66 (±7.34) | ||
| 0.07 | 88.06 (±2.97) | 88.99 (±2.48) | 83.02 (±4.52) | 96.11 (±3.11) | 80.00 (±6.60) | ||
| 0.10 | 86.69 (±0.87) | 87.97 (±1.57) | 80.55 (±3.45) | 97.03 (±1.48) | 76.34 (±5.40) | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sedigh Malekroodi, H.; Madusanka, N.; Lee, B.-i.; Yi, M. Speech-Based Parkinson’s Detection Using Pre-Trained Self-Supervised Automatic Speech Recognition (ASR) Models and Supervised Contrastive Learning. Bioengineering 2025, 12, 728. https://doi.org/10.3390/bioengineering12070728
Sedigh Malekroodi H, Madusanka N, Lee B-i, Yi M. Speech-Based Parkinson’s Detection Using Pre-Trained Self-Supervised Automatic Speech Recognition (ASR) Models and Supervised Contrastive Learning. Bioengineering. 2025; 12(7):728. https://doi.org/10.3390/bioengineering12070728
Chicago/Turabian StyleSedigh Malekroodi, Hadi, Nuwan Madusanka, Byeong-il Lee, and Myunggi Yi. 2025. "Speech-Based Parkinson’s Detection Using Pre-Trained Self-Supervised Automatic Speech Recognition (ASR) Models and Supervised Contrastive Learning" Bioengineering 12, no. 7: 728. https://doi.org/10.3390/bioengineering12070728
APA StyleSedigh Malekroodi, H., Madusanka, N., Lee, B.-i., & Yi, M. (2025). Speech-Based Parkinson’s Detection Using Pre-Trained Self-Supervised Automatic Speech Recognition (ASR) Models and Supervised Contrastive Learning. Bioengineering, 12(7), 728. https://doi.org/10.3390/bioengineering12070728