

OMGMed: Advanced System for Ocular Myasthenia Gravis Diagnosis via Eye Image Segmentation


 and
and
Abstract
1. Introduction
2. Methods
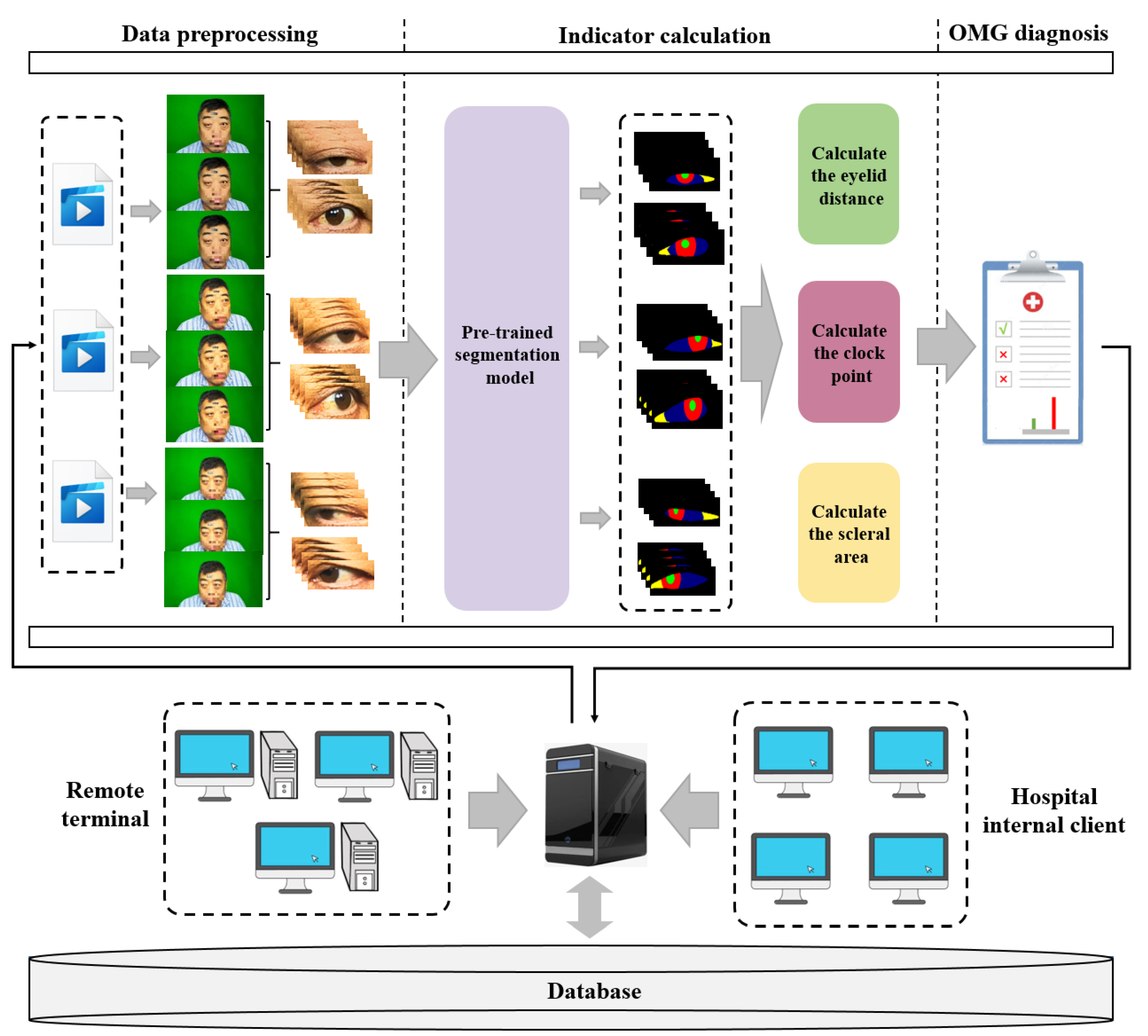
2.1. The Framework of OMGMed
- Data preprocessing moduleGiven the abundance of redundant features within facial images, we employed the face key point detection model from the Dlib library to isolate the key region of the human eye, thereby minimizing the impact of unnecessary features. Acknowledging the diverse shapes of human eyes, we extended a part of the pixels in each of the four directions to ensure the integrity of the eye in the cropped image. Finally, we get the two-eye images corresponding to the face image (left eye and right eye), and the processed two-eye images are then input into the indicator calculation module for further analysis.
- Indicator calculation moduleInitially, we conducted fine-grained multi-class segmentation on the eye images. Following the segmentation outcomes, we calculated the pixel distances (area) for three key indicators: eyelid distance, clock point, and scleral area, with reference to the Common Muscle Weakness Scale: Quantitative Myasthenia Gravis Score (QMGS) and the Absolute and Relative Score of Myasthenia Gravis (ARS-MG) as depicted in Figure 3.Eyelid distance: Eyelid distance is the distance between the upper and lower eyelids when the patient is in front view and maximum eyelid view.Clock point: the cornea is regarded as a clock face, and the positions of the left and right numerical lines of the dial were used as the basis for division into seven clock positions, 12 o’clock, 11–1 o’clock, 10–2 o’clock, 9–3 o’clock, 8–4 o’clock, 7–5 o’clock, and 6 o’clock, in which the patient’s upper eyelid ptoticized to the position of the clock in the palpebral superior fatigability test.Scleral area: It is the maximum area that the sclera is exposed in the corresponding direction when the patient gazes to the left or to the right.After many discussions and communication with doctors in Beijing Hospital, we will no longer measure the scleral distance indicator but instead measure the scleral area. The advantages are as follows: (1) From the computer point of view, compared with a single distance, the two-dimensional area can more accurately reflect the horizontal movement of the patient’s eye. (2) From a clinical point of view, the doctor can independently use the caliper or visual estimation of distance, but can not estimate the area, therefore, measuring the scleral area can better assist the doctor in diagnosis.
- OMG diagnosis moduleWith reference to QMGS and ARS-MG, and after many exchanges with doctors specializing in myasthenia gravis in Beijing Hospital, we decided to use the key indicator—scleral area as the basis for diagnosis. We will calculate the proportion of the scleral area to the entire eye area, using 3% as the threshold (considering that the segmentation results may be inaccurate). If the scleral area proportion is less than 3%, we consider it to be normal; If the scleral area is greater than 3%, it indicates that the subject is unable to move the eyes normally, which is a diagnosis of ocular myasthenia gravis. From the perspective of the process, we diagnose the left eye and the right eye respectively according to the calculated indicators, and finally comprehensively output the comprehensive diagnosis results to the expert doctor or the patient.
2.2. Analysis of Network Structure
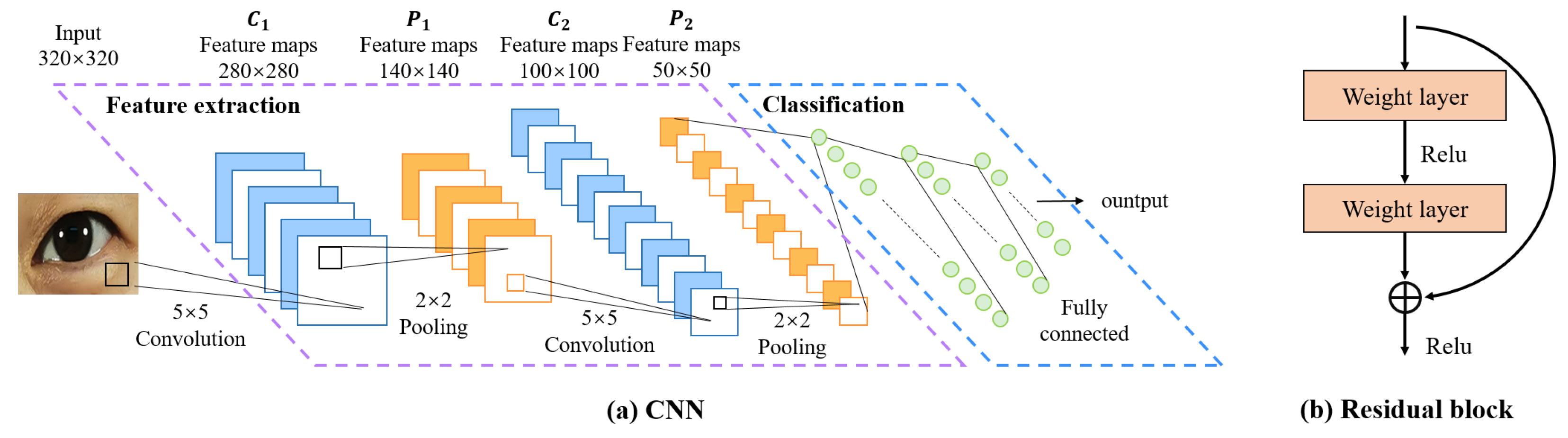
- Convolutional Neural Networks (CNNs)CNN was initially proposed by Fukushima [23] in his seminal paper on the “Neocognitron”, which is one of the most classic and widely used architectures for computer vision tasks [24]. We believe it’s also suitable for eye image segmentation. As depicted in Figure 5, a CNN is typically structured into three key layers: (i) a convolutional layer, where kernels (or filters) equipped with learnable weights are applied to extract image features; (ii) a nonlinear layer, which applies an activation function to feature maps to enable the modeling of nonlinear relationships; and (iii) a pooling layer, which reduces the feature map resolution—and consequently, the computational burden—by aggregating neighboring information (e.g., maxima, averages) through a predefined rule. In the following, we will describe the CNN structure-based network.
- FCN: Fully Convolutional Networks (FCN) is a milestone in DL-based semantic image segmentation models. It includes only convolutional layers, which enables it to output a segmentation map whose size is the same as that of the input image.
- U-Net: The structure of U-Net consists of a contracting path to capture context and a symmetric expanding path that enables precise localization, which was initially used for efficient segmentation of biomicroscopy images, and has since been widely used for image segmentation in other domains as well.
- SegNet: The core structure of SegNet consists of an encoder network, and a corresponding decoder network followed by a pixel-wise classification layer. The innovation lies in the manner in which the decoder upsamples its lower-resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling.
- U-Net++: U-Net++ adds a series of nested, dense skip pathways to unet, with the re-designed skip pathways aimed at reducing the semantic gap between the feature maps of the encoder and decoder sub-networks
- Deeplabv3+: Deeplabv3+ applies the depthwise separable convolution to both Atrous Spatial Pyramid Pooling and decoder modules, resulting in a faster and stronger encoder-decoder network.
- U2-Net: U2-Net is a two-level nested U-structure that is able to capture more contextual information from different scales without significantly increasing the computational cost. It is initially used for salient object detection(SOD).
- nnU-Net: nnU-Net can be considered as an adaptive version of U-Net that automatically configures itself, including preprocessing, network architecture, training, and post-processing for any new task in the biomedical field. Without manual intervention, nnU-Net surpasses most existing approaches, including highly specialized solutions on 23 public datasets used in international biomedical segmentation competitions.
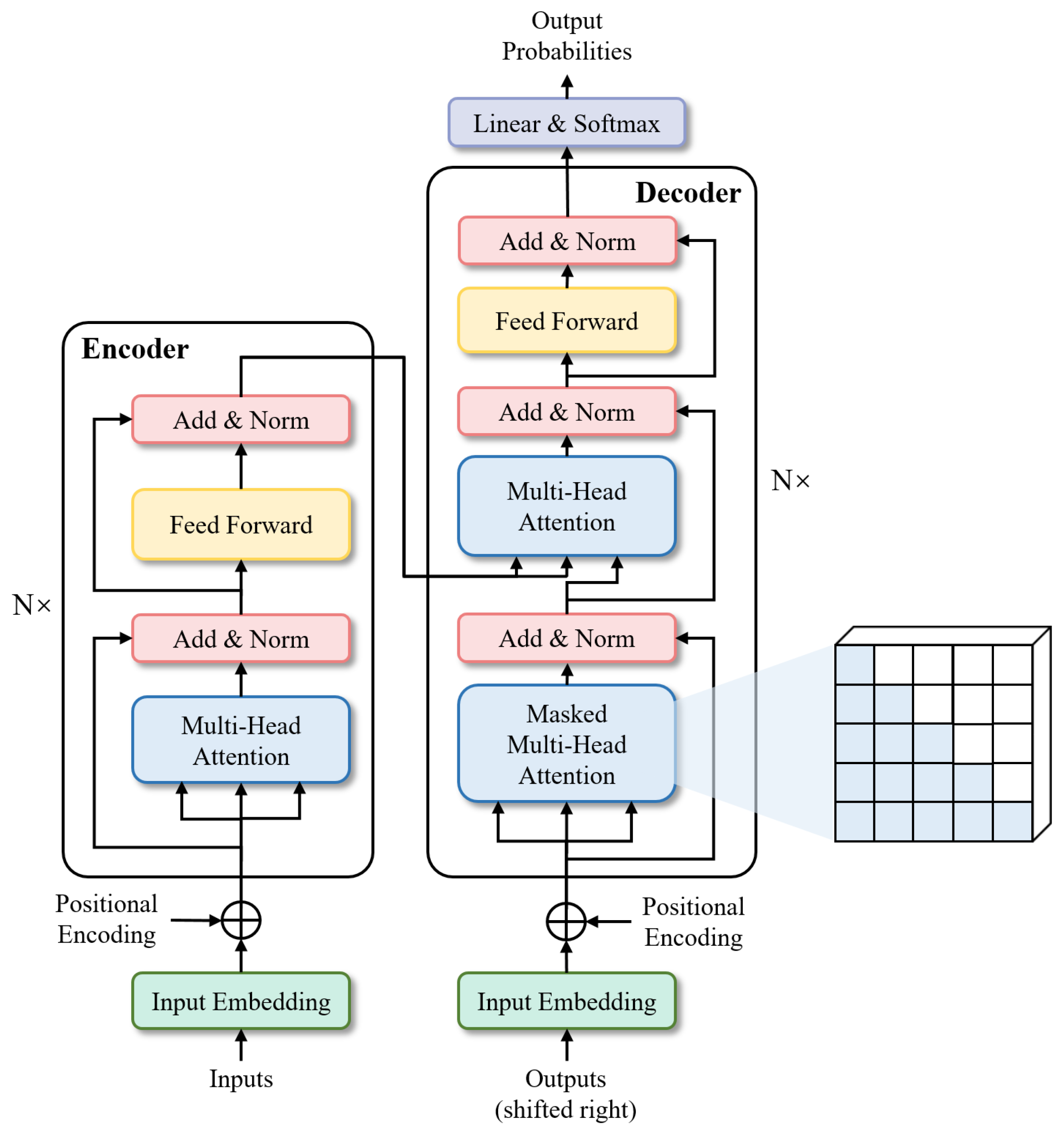
- TransformersTransformers were first proposed by [25] for machine translation and established state-of-the-arts in many NLP tasks. Illustrated in Figure 6, its inputs and outputs are one-dimensional sequences, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely to enhance capabilities at modeling global contexts. This is precisely the capability required for the multi-class segmentation task of fine-grained eye images. To extend the Transformer’s application to computer vision, Dosovitskiy et al. [26] proposed Vision Transformer (ViT) model, which achieved state-of-the-art on ImageNet classification by directly applying Transformers with global self-attention to full-sized images. In the following, we will briefly describe the Transformer structure-based network.
- Segmenter: Extending the visual transformer (ViT) to semantic segmentation, segmenter relies on the output embeddings corresponding to image patches and obtains class labels from these embeddings with a point-wise linear decoder or a mask transformer decoder. The network outperforms the state-of-the-art on both ADE20K and Pascal Context datasets and is competitive on Cityscapes.
- TransUNet: TransUNet merits both Transformers and U-Net, not only encoding strong global context by treating the image features as sequences but also utilizing the low-level CNN features via a u-shaped hybrid architectural design. It achieves superior performances to various competing methods on different medical applications including multi-organ segmentation and cardiac segmentation.
2.3. Analysis of Loss Function
- Cross-entropy loss [28]) (CE loss): It quantifies the disparity between the predicted value and the actual value on a per-pixel basis, considering all pixels within the image equally. It belongs to global loss.
- Weighted cross-entropy loss [29] (WCE loss): It further adds category weights to the cross-entropy loss, which belongs to global loss.
- IOU loss [30]: It only focuses on the segmentation targets, assessing the intersection and union ratio between true pixel values and their predicted probabilities. Belonging to local loss.
- Dice loss [31]: It only focuses on the segmentation targets, and further emphasizes the repeated computation component based on IOU loss. Belonging to local loss.
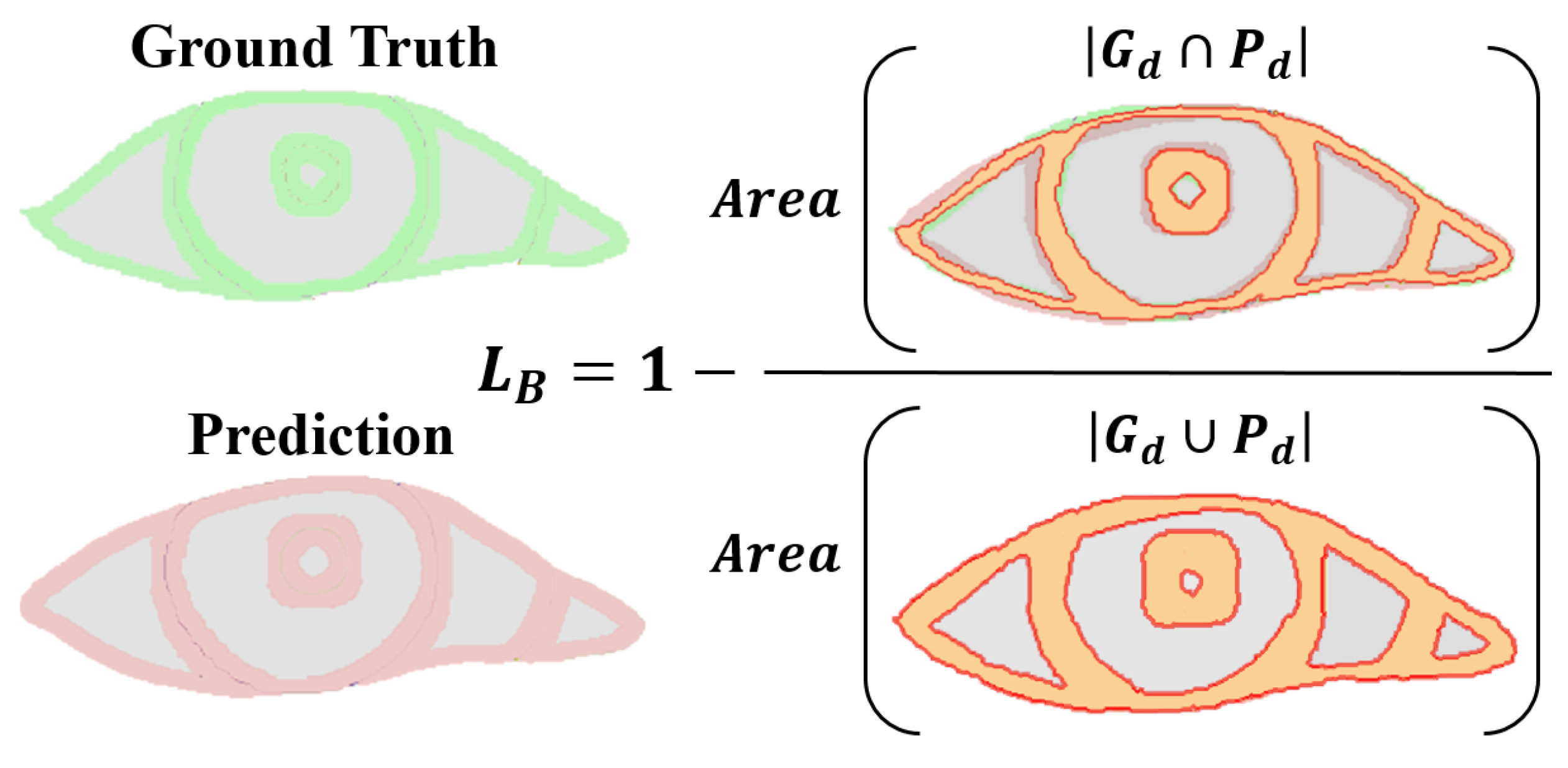
- Boundary loss: Focusing on the boundary pixels of the segmentation target, assessing the intersection and union ratio between true boundary pixel values and their predicted probabilities. Specifically, it only pays attention to the boundary pixels of the pupil, iris, sclera, and tear caruncle, respectively (in Figure 7), and the numerator is to multiply the predicted probability value of each category with the true value of the target pixel by pixel and then sum it; the denominator is to add the predicted probability value and the true value of each category pixel by pixel, and then to subtract the part of the “repeated computation component”. This loss has the advantages of symmetry (labels and prediction maps can be swapped without affecting computational results) and no preference (no preference for large or small targets) [33].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Loss Function | Definition | Stability | BC * | Insensitivity | |
|---|---|---|---|---|---|
| Global loss | CE Loss | high | × | √ | |
| WCE Loss | high | × | √ | ||
| Local loss | IOU Loss | low | × | — | |
| Dice Loss | low | × | — | ||
| Boundary loss | Boundary Loss | very low | √ | — |
3. Experiments and Results
3.1. Datasets
3.2. Implementation Details
3.3. Empirical Experiment of Network Structure
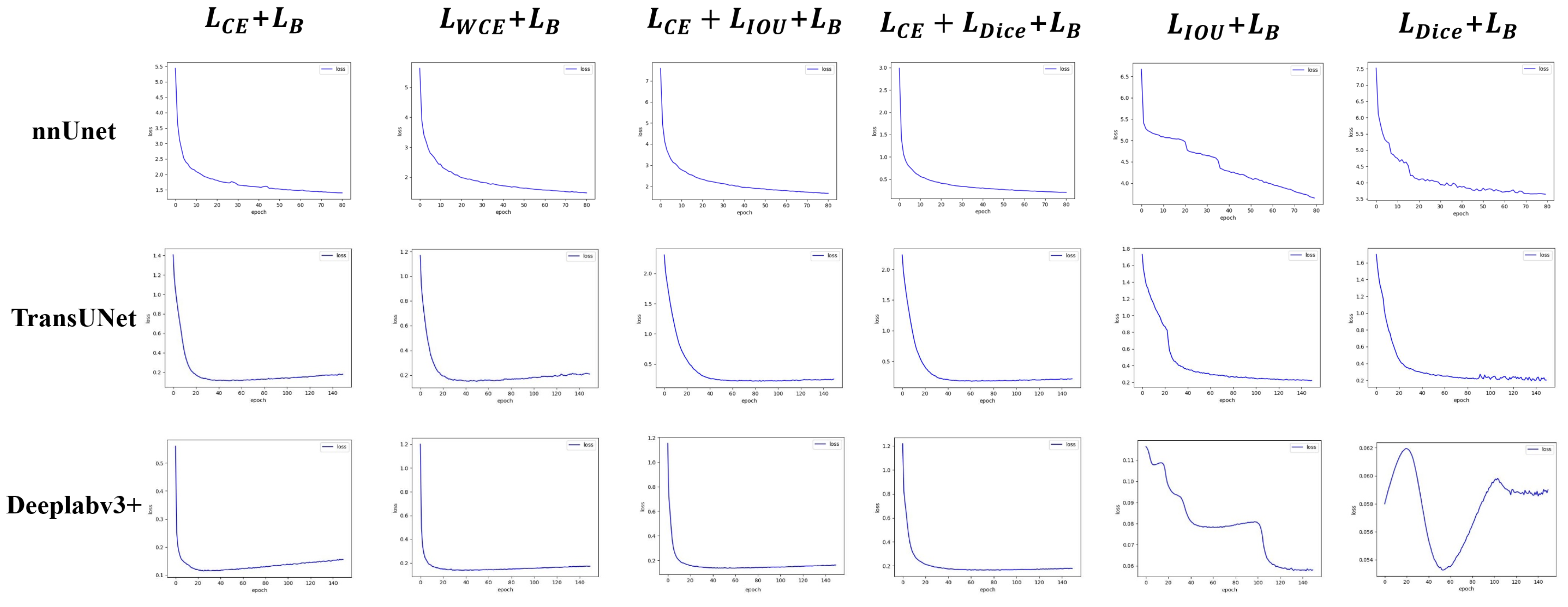
3.4. Empirical Experiment of Hybrid Loss Function
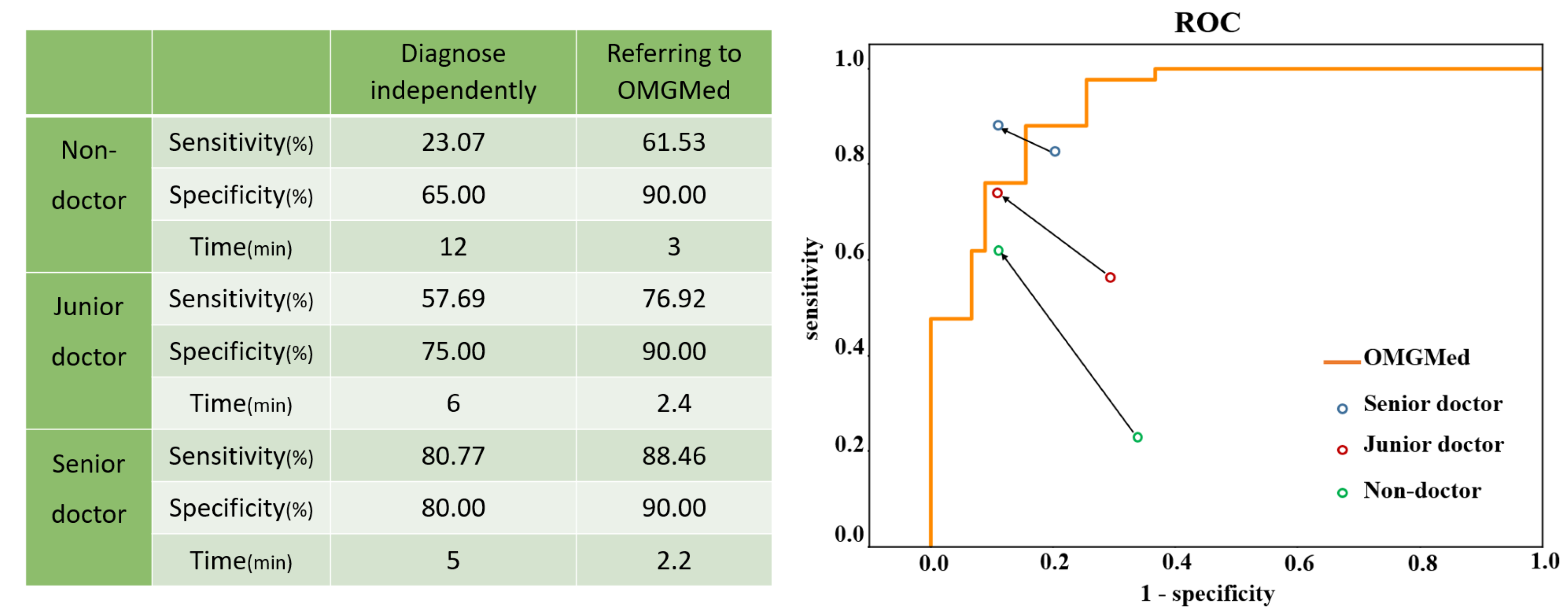
3.5. Accuracy of Diagnosing OMG by Doctors with the Assistance of OMGMed
4. Discussion
4.1. Eye Segmentation Performance
4.1.1. Network Structure
4.1.2. Loss Function
4.2. Practical Implication
4.3. Limitations and Future Work
4.3.1. Image Quality Varies
4.3.2. Single Diagnostic Basis
5. Proactive Healthcare Service
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Global Myasthenia Gravis Therapeutics Market Size Status and Manufacturers Analysis. 2022. Available online: https://www.sohu.com/a/548235609_372052 (accessed on 16 March 2024).
- Ruiter, A.M.; Wang, Z.; Yin, Z.; Naber, W.C.; Simons, J.; Blom, J.T.; van Gemert, J.C.; Verschuuren, J.J.; Tannemaat, M.R. Assessing facial weakness in myasthenia gravis with facial recognition software and deep learning. Ann. Clin. Transl. Neurol. 2023, 10, 1314–1325. [Google Scholar] [CrossRef] [PubMed]
- Thanvi, B.; Lo, T. Update on myasthenia gravis. Postgrad. Med. J. 2004, 80, 690–700. [Google Scholar] [CrossRef] [PubMed]
- Antonio-Santos, A.A.; Eggenberger, E.R. Medical treatment options for ocular myasthenia gravis. Curr. Opin. Ophthalmol. 2008, 19, 468–478. [Google Scholar] [CrossRef] [PubMed]
- Nair, A.G.; Patil-Chhablani, P.; Venkatramani, D.V.; Gandhi, R.A. Ocular myasthenia gravis: A review. Indian J. Ophthalmol. 2014, 62, 985–991. [Google Scholar] [PubMed]
- Jaretzki III, A. Thymectomy for myasthenia gravis: Analysis of the controversies regarding technique and results. Neurology 1997, 48, 52S–63S. [Google Scholar] [CrossRef]
- Chen, J.; Tian, D.C.; Zhang, C.; Li, Z.; Zhai, Y.; Xiu, Y.; Gu, H.; Li, H.; Wang, Y.; Shi, F.D. Incidence, mortality, and economic burden of myasthenia gravis in China: A nationwide population-based study. Lancet Reg. Health- Pac. 2020, 5, 100063. [Google Scholar] [CrossRef] [PubMed]
- Banzi, J.F.; Xue, Z. An automated tool for non-contact, real time early detection of diabetes by computer vision. Int. J. Mach. Learn. Comput. 2015, 5, 225. [Google Scholar] [CrossRef]
- Muzamil, S.; Hussain, T.; Haider, A.; Waraich, U.; Ashiq, U.; Ayguadé, E. An Intelligent Iris Based Chronic Kidney Identification System. Symmetry 2020, 12, 2066. [Google Scholar] [CrossRef]
- Arslan, A.; Sen, B.; Celebi, F.V.; Uysal, B.S. Automatic segmentation of region of interest for dry eye disease diagnosis system. In Proceedings of the 24th Signal Processing and Communication Application Conference, SIU 2016, Zonguldak, Turkey, 16–19 May 2016; pp. 1817–1820. [Google Scholar]
- Liu, G.; Wei, Y.; Xie, Y.; Li, J.; Qiao, L.; Yang, J.j. A computer-aided system for ocular myasthenia gravis diagnosis. Tsinghua Sci. Technol. 2021, 26, 749–758. [Google Scholar] [CrossRef]
- Wang, C.; Li, H.; Ma, W.; Zhao, G.; He, Z. MetaScleraSeg: An effective meta-learning framework for generalized sclera segmentation. Neural Comput. Appl. 2023, 35, 21797–21826. [Google Scholar] [CrossRef]
- Proença, H.; Filipe, S.; Santos, R.; Oliveira, J.; Alexandre, L.A. The UBIRIS. v2: A database of visible wavelength iris images captured on-the-move and at-a-distance. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1529–1535. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015—18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III. Volume 9351, pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep Learning in Medical Image Analysis—and—Multimodal Learning for Clinical Decision Support—4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings. Volume 11045, pp. 3–11. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part VII; Lecture Notes in Computer Science. Volume 11211, pp. 833–851. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaïane, O.R.; Jägersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef] [PubMed]
- Strudel, R.; Pinel, R.G.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7242–7252. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef] [PubMed]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual, 3–7 May 2021. [Google Scholar]
- Lai, H.; Luo, Y.; Zhang, G.; Shen, X.; Li, B.; Lu, J. Toward accurate polyp segmentation with cascade boundary-guided attention. Vis. Comput. 2023, 39, 1453–1469. [Google Scholar] [CrossRef]
- Hsu, C.Y.; Hu, R.; Xiang, Y.; Long, X.; Li, Z. Improving the Deeplabv3+ model with attention mechanisms applied to eye detection and segmentation. Mathematics 2022, 10, 2597. [Google Scholar] [CrossRef]
- Liu, X.; Wang, S.; Zhang, Y.; Liu, D.; Hu, W. Automatic fluid segmentation in retinal optical coherence tomography images using attention based deep learning. Neurocomputing 2021, 452, 576–591. [Google Scholar] [CrossRef]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation. In Advances in Visual Computing, Proceedings of the 12th International Symposium, ISVC 2016, Las Vegas, NV, USA, 12–14 December 2016; Proceedings, Part I; Springer: Berlin/Heidelberg, Germany, 2016; Volume 10072, pp. 234–244. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the Fourth International Conference on 3D Vision, 3DV 2016, Stanford, CA, USA, 25–28 October 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 565–571. [Google Scholar]
- Luo, Z.; Mishra, A.K.; Achkar, A.; Eichel, J.A.; Li, S.; Jodoin, P. Non-local Deep Features for Salient Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 6593–6601. [Google Scholar]
- Cheng, B.; Girshick, R.B.; Dollár, P.; Berg, A.C.; Kirillov, A. Boundary IoU: Improving Object-Centric Image Segmentation Evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; Computer Vision Foundation. IEEE: Piscataway, NJ, USA, 2021; pp. 15334–15342. [Google Scholar]
- Guo, H.; Hu, S.; Wang, X.; Chang, M.; Lyu, S. Eyes Tell All: Irregular Pupil Shapes Reveal GAN-Generated Faces. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2022, Virtual, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2904–2908. [Google Scholar]
- Mancini, M.; Akata, Z.; Ricci, E.; Caputo, B. Towards Recognizing Unseen Categories in Unseen Domains. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIII; Springer: Berlin/Heidelberg, Germany, 2020; Lecture Notes in Computer Science; Volume 12368, pp. 466–483. [Google Scholar]
- You, A.; Kim, J.K.; Ryu, I.H.; Yoo, T.K. Application of generative adversarial networks (GAN) for ophthalmology image domains: A survey. Eye Vis. 2022, 9, 6. [Google Scholar] [CrossRef]
- Sorin, V.; Barash, Y.; Konen, E.; Klang, E. Creating artificial images for radiology applications using generative adversarial networks (GANs)—A systematic review. Acad. Radiol. 2020, 27, 1175–1185. [Google Scholar] [CrossRef]
- Cheong, H.; Devalla, S.K.; Pham, T.H.; Zhang, L.; Tun, T.A.; Wang, X.; Perera, S.; Schmetterer, L.; Aung, T.; Boote, C.; et al. DeshadowGAN: A deep learning approach to remove shadows from optical coherence tomography images. Transl. Vis. Sci. Technol. 2020, 9, 23. [Google Scholar] [CrossRef]
- Iqbal, T.; Ali, H. Generative Adversarial Network for Medical Images (MI-GAN). J. Med Syst. 2018, 42, 231:1–231:11. [Google Scholar] [CrossRef]
- Rammy, S.A.; Abbas, W.; Hassan, N.; Raza, A.; Zhang, W. CPGAN: Conditional patch-based generative adversarial network for retinal vessel segmentation. IET Image Process. 2020, 14, 1081–1090. [Google Scholar] [CrossRef]
- Yang, J.; Dong, X.; Hu, Y.; Peng, Q.; Tao, G.; Ou, Y.; Cai, H.; Yang, X. Fully automatic arteriovenous segmentation in retinal images via topology-aware generative adversarial networks. Interdiscip. Sci. Comput. Life Sci. 2020, 12, 323–334. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Ma, L.; Liang, L. Adaptive Adversarial Training to Improve Adversarial Robustness of DNNs for Medical Image Segmentation and Detection. arXiv 2022, arXiv:2206.01736. [Google Scholar]





| Test Item | Grade | ||||
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | |
| Clock point | 11∼1 point | 10∼2 point | 9∼3 point | 8∼4 point | 7∼5 point |
| Scleral distance | ≤2 mm | 3∼4 mm | 5∼8 mm | 9∼12 mm | >12 mm |
| Network Name | Characteristic | |
|---|---|---|
| CNN-based structure | FCN [14] | Including only convolutional layers |
| U-Net [15] | A contracting path and a symmetric expanding path | |
| SegNet [16] | The decoder uses pooling indices to perform non-linear upsampling | |
| U-Net++ [17] | Nested, dense skip pathways | |
| Deeplabv3+ [18] | Applying the depthwise separable convolution to both Atrous Spatial Pyramid Pooling and decoder modules | |
| U2-Net [19] | A two-level nested U-structure | |
| nnUnet [20] | Automatically configuring preprocessing, network architecture, training and post-processing | |
| Transformer-based structure | Segmenter [21] | Extending the visual transformer (ViT) to semantic segmentation |
| TransUNet [22] | Combining Transformer and U-Net Architecture |
| Notion | Definition |
|---|---|
| m | Number of pixel classes |
| N | Number of pixels |
| The true value of the ith pixel on class j | |
| Predicted probability of the ith pixel on class j | |
| Weight of class j | |
| d | Pixel width of the boundary region |
| Network Name | MIOU (%) | MDice (%) | MPrecision (%) | MRecall (%) | MF1 (%) | MBIOU (%) | Avg_time (s) | |
|---|---|---|---|---|---|---|---|---|
| CNN-based structure | FCN | 68.40 | 79.27 | 84.96 | 78.03 | 81.35 | 50.39 | 0.0117s |
| U-Net | 70.16 | 80.44 | 88.38 | 77.16 | 82.39 | 50.50 | 0.0142 | |
| SegNet | 74.03 | 83.71 | 88.40 | 81.89 | 85.02 | 55.81 | 0.0136 | |
| U-Net++ | 73.69 | 83.48 | 86.78 | 83.15 | 84.93 | 55.10 | 0.0186 | |
| Deeplabv3+ | 75.10 | 84.64 | 83.96 | 88.05 | 85.96 | 56.36 | 0.0259 | |
| U2-Net | 73.77 | 82.54 | 83.16 | 83.89 | 83.52 | 53.37 | 0.0152 | |
| nnUnet | 81.43 | 88.76 | 90.83 | 88.33 | 89.56 | 59.43 | 0.0220 | |
| Transformer-based structure | Segmenter | 72.47 | 81.65 | 87.47 | 79.13 | 83.09 | 47.13 | 0.0108 |
| TransUNet | 80.89 | 88.53 | 90.10 | 88.38 | 89.23 | 57.72 | 0.0173 |
| Network Name | MIOU (%) | MDice (%) | MPrecision (%) | MReca (%) | MF1 (%) | MBIOU (%) | Avg_time (s) | |
|---|---|---|---|---|---|---|---|---|
| CNN-based structure | FCN | 56.33 | 67.98 | 73.82 | 69.70 | 71.70 | 38.04 | 0.0286 |
| U-Net | 71.24 | 80.87 | 85.64 | 80.22 | 82.84 | 50.64 | 0.0301 | |
| SegNet | 67.73 | 78.37 | 79.85 | 80.45 | 80.15 | 46.93 | 0.0327 | |
| U-Net++ | 68.44 | 78.17 | 82.40 | 78.20 | 80.24 | 49.87 | 0.0332 | |
| Deeplabv3+ | 72.11 | 81.97 | 80.44 | 87.31 | 83.74 | 49.35 | 0.0433 | |
| U2-Net | 68.49 | 77.73 | 79.36 | 79.25 | 79.30 | 39.81 | 0.0231 | |
| nnUnet | 82.67 | 89.44 | 90.01 | 90.63 | 90.32 | 59.81 | 0.0320 | |
| Transformer-based structure | Segmenter | 71.87 | 80.96 | 85.62 | 79.85 | 82.63 | 44.08 | 0.0381 |
| TransUNet | 81.62 | 88.71 | 89.02 | 89.95 | 89.49 | 57.35 | 0.0271 |
| Loss | MIOU (%) | MDice (%) | MPrecision (%) | MRecall (%) | MF1 (%) | MBIOU (%) | Avg_time (s) |
|---|---|---|---|---|---|---|---|
| 81.43/82.67 | 88.76/89.44 | 90.83/90.01 | 88.33/90.63 | 89.56/90.32 | 59.43/59.81 | 0.0220/0.0320 | |
| + | 81.77/83.40 | 89.07/89.96 | 90.79/90.38 | 88.89/91.18 | 89.83/90.77 | 60.76/61.50 | 0.0291/0.0350 |
| 82.08/82.38 | 89.28/89.19 | 88.55/88.48 | 91.75/91.85 | 90.12/90.13 | 60.04/59.31 | 0.0240/0.0303 | |
| + | 82.41/83.12 | 89.52/89.73 | 90.10/89.25 | 90.39/91.93 | 90.24/90.57 | 60.66/60.72 | 0.0312/0.0310 |
| + | 81.63/82.94 | 88.90/89.63 | 91.12/90.22 | 88.33/90.70 | 89.70/90.46 | 59.71/59.92 | 0.0241/0.0360 |
| + + | 82.13/83.64 | 89.29/90.03 | 91.44/90.34 | 88.63/91.29 | 90.01/90.81 | 60.44/61.75 | 0.0270/0.0320 |
| + | 82.06/83.21 | 89.25/89.76 | 91.30/90.34 | 88.70/90.91 | 89.98/90.63 | 60.45/60.90 | 0.0280/0.0310 |
| + + | 82.10/83.48 | 89.27/89.95 | 91.81/90.55 | 88.54/90.94 | 89.99/90.74 | 60.51/61.39 | 0.0301/0.0360 |
| + | 69.16/70.75 | 73.79/74.66 | 75.02/74.37 | 73.29/75.57 | 74.14/74.96 | 51.03/50.55 | 0.0350/0.0320 |
| + | 69.16/67.71 | 73.80/72.43 | 74.95/73.23 | 73.35/72.85 | 74.14/73.04 | 51.03/56.96 | 0.0320/0.0310 |
| Loss | MIOU (%) | MDice (%) | MPrecision (%) | MRecall (%) | MF1 (%) | MBIOU (%) | Avg_time (s) |
|---|---|---|---|---|---|---|---|
| 80.91/81.62 | 88.53/88.71 | 90.10/89.02 | 88.38/89.95 | 89.23/89.49 | 57.72/57.35 | 0.0173/0.0271 | |
| + | 81.03/81.98 | 88.64/88.90 | 89.41/89.17 | 89.27/90.15 | 89.34/89.66 | 57.80/58.34 | 0.0161/0.0289 |
| 81.11/80.67 | 88.72/88.19 | 88.41/86.63 | 90.65/91.56 | 89.52/89.02 | 57.43/54.94 | 0.0178/0.0288 | |
| + | 81.19/81.40 | 88.79/88.61 | 88.86/87.72 | 90.08/91.2 | 89.42/89.47 | 58.19/56.87 | 0.0167/0.0293 |
| + | 80.99/81.85 | 88.60/88.93 | 89.86/88.58 | 88.83/90.77 | 89.34/89.66 | 57.40/57.92 | 0.0171/0.0284 |
| + + | 81.55/81.89 | 89.02/88.94 | 90.10/88.92 | 89.27/90.61 | 89.68/89.76 | 58.43/58.55 | 0.0172/0.0273 |
| + | 81.23/81.68 | 88.80/88.77 | 90.44/89.53 | 88.60/89.57 | 89.51/89.55 | 57.97/57.64 | 0.0168/0.0283 |
| + + | 81.24/81.74 | 88.74/88.74 | 89.13/89.42 | 89.84/89.60 | 89.48/89.51 | 58.29/58.29 | 0.0169/0.0284 |
| + | 70.12/81.11 | 78.85/88.35 | 83.90/88.61 | 77.42/89.62 | 80.53/89.11 | 44.86/56.51 | 0.0174/0.0272 |
| + | 70.11/81.58 | 79.25/88.67 | 81.19/89.44 | 80.40/89.37 | 80.79/89.40 | 43.63/57.46 | 0.0174/0.0298 |
| Loss | MIOU (%) | MDice (%) | MPrecision (%) | MRecall (%) | MF1 (%) | MBIOU (%) | Avg_time (s) |
|---|---|---|---|---|---|---|---|
| 75.10/72.11 | 84.64/81.97 | 83.96/80.44 | 88.05/87.31 | 85.96/83.74 | 56.36/49.35 | 0.0259/0.0433 | |
| + | 76.35/73.34 | 85.61/83.25 | 83.76/80.22 | 89.86/89.78 | 86.71/84.73 | 58.24/51.78 | 0.0311/0.0412 |
| 75.80/73.88 | 85.20/83.52 | 82.41/79.96 | 90.73/90.51 | 86.37/84.91 | 57.14/51.30 | 0.0253/0.0425 | |
| + | 76.84/75.22 | 85.95/84.65 | 85.71/81.76 | 88.33/90.58 | 87.00/85.94 | 58.67/54.40 | 0.0253/0.0424 |
| + | 77.20/76.14 | 86.24/85.08 | 86.66/85.00 | 87.60/87.86 | 87.12/86.40 | 58.97/56.06 | 0.0254/0.0365 |
| + + | 77.42/76.45 | 86.38/85.42 | 87.10/84.38 | 87.46/89.30 | 87.28/86.77 | 59.53/56.20 | 0.0252/0.0355 |
| + | 76.59/75.61 | 85.80/84.84 | 86.46/84.62 | 87.10/87.90 | 86.78/86.23 | 58.15/54.61 | 0.0253/0.0428 |
| + + | 77.29/76.13 | 86.29/85.29 | 87.20/84.00 | 87.26/89.23 | 87.23/86.53 | 59.30/55.71 | 0.0252/0.0429 |
| + | 55.85/37.68 | 63.36/42.78 | 60.52/40.86 | 68.05/46.55 | 64.07/43.52 | 40.14/21.81 | 0.0250/0.0426 |
| + | 54.80/49.96 | 62.63/58.71 | 59.20/54.24 | 68.25/67.37 | 63.40/60.10 | 38.13/27.90 | 0.0251/0.0407 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhu, C.; Zhao, M.; Xu, X.; Zhao, L.; Cheng, W.; Liu, S.; Zou, J.; Yang, J.-J.; Yin, J. OMGMed: Advanced System for Ocular Myasthenia Gravis Diagnosis via Eye Image Segmentation. Bioengineering 2024, 11, 595. https://doi.org/10.3390/bioengineering11060595
Li J, Zhu C, Zhao M, Xu X, Zhao L, Cheng W, Liu S, Zou J, Yang J-J, Yin J. OMGMed: Advanced System for Ocular Myasthenia Gravis Diagnosis via Eye Image Segmentation. Bioengineering. 2024; 11(6):595. https://doi.org/10.3390/bioengineering11060595
Chicago/Turabian StyleLi, Jianqiang, Chujie Zhu, Mingming Zhao, Xi Xu, Linna Zhao, Wenxiu Cheng, Suqin Liu, Jingchen Zou, Ji-Jiang Yang, and Jian Yin. 2024. "OMGMed: Advanced System for Ocular Myasthenia Gravis Diagnosis via Eye Image Segmentation" Bioengineering 11, no. 6: 595. https://doi.org/10.3390/bioengineering11060595
APA StyleLi, J., Zhu, C., Zhao, M., Xu, X., Zhao, L., Cheng, W., Liu, S., Zou, J., Yang, J.-J., & Yin, J. (2024). OMGMed: Advanced System for Ocular Myasthenia Gravis Diagnosis via Eye Image Segmentation. Bioengineering, 11(6), 595. https://doi.org/10.3390/bioengineering11060595