1. Introduction
Big data analysis is a process that helps organize a massive amount of data. It also correlates raw data to processed data, minimizing the complexity of the decision-making process [
1]. Healthcare applications contain various datasets that require proper analysis processes to enhance the performance range of the systems [
2]. Big data analysis in healthcare improves the overall development and feasibility level of healthcare applications. Medical health records maintained in healthcare contain necessary patient details [
3], including personal data, health conditions, types of diseases, medications, and the process of diagnosing diseases for patients. An intelligent-enabled big data analysis technique is commonly used in healthcare applications [
4]. This technique analyzes structured and unstructured healthcare data in the management system. The analyzed information produces relevant data for further disease detection and diagnosis processes. The analysis technique also increases the accuracy of disease prediction, reducing latency in providing services to patients [
5].
Error reduction is a crucial task to perform in the big data analytics process. Big data analytics eliminates unwanted raw data from the database [
6]. Error reduction in data analytics is mainly used to improve the data quality required for further data processing. Errors such as noisy data, negative data, and inconsistent data are present in healthcare management systems [
7]. Big data analytics produces optimal information for healthcare applications. Natural language processing (NLP)-based big data analysis is used in healthcare to reduce errors in computational processes [
8]. The NLP data processing tool analyzes the critical clinical data necessary for diagnosis [
9]. The NLP identifies the negative data that causes errors during data processing and analysis. The identified errors are eliminated immediately to reduce unwanted challenges or issues in big data analytics systems. The NLP-based technique improves the overall functional capability level of the analytics process in healthcare applications [
10,
11].
Fuzzy methods are widely used in various fields to solve the problems presented in systems. They are also employed in big data analytics to enhance the effectiveness of the systems [
12]. A fuzzy-optimized data management (FDM) approach is utilized in big data analytics. This approach employs an extraction technique to extract useful information from datasets [
13]. The extracted information provides accumulated data to perform tasks for healthcare systems. The FDM approach analyzes the exact relationship between data and produces feasible data for further analysis [
14], thereby improving the feasibility and significance of the analytics process. Additionally, a novel big data analytic technique using a fuzzy similarity measure model is employed in healthcare applications [
15]. This analytic technique analyzes the potential data required to perform specific tasks in healthcare centers [
16] and manages critical information collected from various divisions. The fuzzy-based technique reduces the data analysis inaccuracy ratio, enhancing the significance of healthcare applications [
17].
Now, the key objectives and highlights of the research are stated as:
To design a Cooperative-Trivial State Fuzzy Processing (CTSFP) method for significant data analysis with possible derivatives.
To apply fuzzy optimization techniques for grouping data based on functional and irrelevant factors.
To enhance diagnostic progression by employing various fuzzy derivatives to minimize analysis errors.
Conduct data and metrics analysis to assess the effectiveness and validate the proposed method.
Hypothesis 1: Big data analytics positively impacts the innovation system of medical diagnosis.
Hypothesis 2: There will be a positive correlation between learning objectives and healthcare data analytics abilities and between learning objectives and performance results in data analytics.
2. Related Works
This literature review highlights significant strides in healthcare data analytics and machine learning applications. In [
18], the authors developed a specialized data analytics suite for the management of type 2 diabetes. This suite comprised multi-tier classifiers and advanced analytical methods such as exploratory, predictive, and visual analyses to elucidate the complex interplay between patients’ biological markers, enabling more accurate disease classification and streamlined decision-making processes. A sensor-based data analytics (SBDA) model for real-time patient monitoring in connected healthcare systems addresses the growing need for timely emergency detection and improved efficiency in healthcare applications [
19]. Big data analytics gathers various biomedical sensor data for disease detection and prediction. The proposed model is commonly used for real-time patient monitoring, providing feasible emergency detection datasets. These advancements underscore the potential of data-driven approaches to revolutionize disease management and enhance patient care outcomes. Similarly, another study [
20] crafted a specialized big data analytics technique for facilitating decision-making within healthcare centers. This technique was designed to gather data from structured and unstructured sources, streamlining the complexity of detection processes. Big data management ensures the generation of optimal datasets, which are essential for effective decision-making. Consequently, the developed technique has been shown to improve the accuracy rate in clinical decision-making, thereby enhancing the feasibility of diagnostic services.
In addressing the pressing concern of data privacy in healthcare, Elayan et al. presented a novel privacy-preserving framework, namely deep federated learning [
21]. This framework ensures the safety and confidentiality of patient data while maximizing performance and reducing operational costs by leveraging Internet of Things-enabled devices. Furthermore, a hybrid deep learning technique for healthcare data analytics focuses mainly on disease diagnosis [
22]. This technique demonstrates promising results in improving diagnostic accuracy and enhancing the efficiency of diagnostic services, highlighting the transformative impact of machine learning in healthcare. In recent years, wearable sensors have emerged as vital technology applications for monitoring users’ physiological signs, offering valuable insights into health trends. This capability to gather and analyze physiological data has significant implications for enhancing healthcare solutions. An UnSynchronized Sensor Data Analytics (USDA) model has been developed [
23], addressing the need to effectively manage wearable device data, particularly in time-sensitive healthcare scenarios. By classifying data based on timing and occurrence frequency, coupled with a diagnosis module, the USDA model identifies defects and addresses missing sensor data crucial for accurate analyses. Utilizing sophisticated machine learning methods enhances diagnostic accuracy and enables timely healthcare solutions, ultimately improving system efficiency and reducing complications in healthcare performance assessment.
In recent literature, researchers have unveiled a groundbreaking healthcare facility management approach by integrating Building Information Modeling (BIM) with big data analytics. This innovative method, rooted in BIM, is designed to harness the information available within building models, thereby generating optimal data for improved detection and diagnosis within healthcare facilities [
24]. By leveraging this BIM-based approach, healthcare systems can be transformed, offering enhanced efficiency and effectiveness in patient care delivery. Moreover, a sophisticated smart health monitoring system, grounded in big data principles, has been developed to advance patient care [
25]. The proposed model applies Hybrid Dingo Coyote Optimization (HDCO) for optimal feature selection and utilizes a Deep Ensemble Learning algorithm (DEL). This model (HDCO-DEL) accurately classifies various types and classes of medical data, ensuring precise analysis. Integration with Internet of Medical Things devices enables seamless data collection from wireless sensors, thereby minimizing latency in the classification process. Through these innovations, the proposed model significantly elevates the performance standards of healthcare monitoring systems, promising enhanced efficiency and effectiveness in the delivery of patient care. Similarly, Feng et al. introduced a pioneering approach, the confidential information coverage hole prediction, tailored for collecting healthcare big data [
26]. Primarily applied within large-scale hybrid wireless sensor networks, this model monitors essential data for detection. Its core objective is leveraging sensor nodes to forecast prior information, mitigating energy consumption in subsequent processes.
Nowadays, healthcare policies worldwide are increasingly emphasizing the importance of leveraging information instruments and digital technologies to enhance public health and quality of life. Therefore, health policies have evolved to incorporate big data analytics as a key driver of digital social innovation in healthcare. In the study [
27], the authors introduced digital social innovation-based big data analytics for healthcare applications. Critical analysis is used here to analyze the necessary features and data from medical information. Digital social innovation is mainly used to enhance society’s overall well-being, increasing the efficiency of digital data in smart cities. The introduced method increases the development range of healthcare centers.
Similarly, Khan et al. [
28] introduced a systematic analysis framework for healthcare big data analytics to enhance the accuracy and efficiency of disease diagnosis. The model integrates a feature extraction technique to extract pertinent medical data crucial for disease prediction and detection. Notably, the proposed model demonstrates an expanded effectiveness scope for healthcare centers compared to existing approaches.
The prevalence of diabetes mellitus, a chronic metabolic disorder, remains a significant global health challenge, with a concerning proportion of cases going undiagnosed. Early detection and effective management are pivotal in preventing complications and improving patient outcomes. Many studies have focused on the early detection of diabetes by leveraging various machine learning and deep learning models, including stacking algorithms. Therefore, a diabetes patient classification model utilizing the stacking ensemble method is introduced for local healthcare centers [
29]. Employing cross-validation techniques enhances the precision of patient classification. By leveraging medical data sourced from local healthcare centers, the model bolsters the robustness of the detection process, ultimately elevating the accuracy of disease detection. In [
30], the authors have presented a novel approach to predicting obstructive sleep apnea visit costs in healthcare settings. The method generates viable data inputs for prediction by leveraging electronic healthcare records and Transformer models. These inputs are derived from short visit histories maintained within healthcare centers. Introducing this method maximizes the precision ratio in obstructive sleep apnea prediction, significantly enhancing the robustness of the predictive systems.
Furthermore, Razzak et al. introduced multimedia big data analytics tailored for healthcare centers to improve outcomes in healthcare applications [
31]. This automated data processing framework analyzes patients’ health condition data, commonly employed for decision-making and prediction tasks to mitigate computational costs. The experimental findings indicate that the proposed model enhances the quality of patient care, marking a significant advancement in healthcare analytics.
Data storage and transmission formats used by healthcare information technology systems based on CTSFP might be inconsistent and based on diverse standards. Obstacles to interoperability must be overcome so that different systems can communicate data without difficulties and integrate these systems. Unstructured text data, such as patient reports, social media conversations, clinical notes, and medical literature, may be analyzed, and insights may be extracted using NLP algorithms. NLP techniques make it possible to glean useful information from unstructured text, making it easier to accomplish things like sentiment analysis, entity identification, and document summarization.
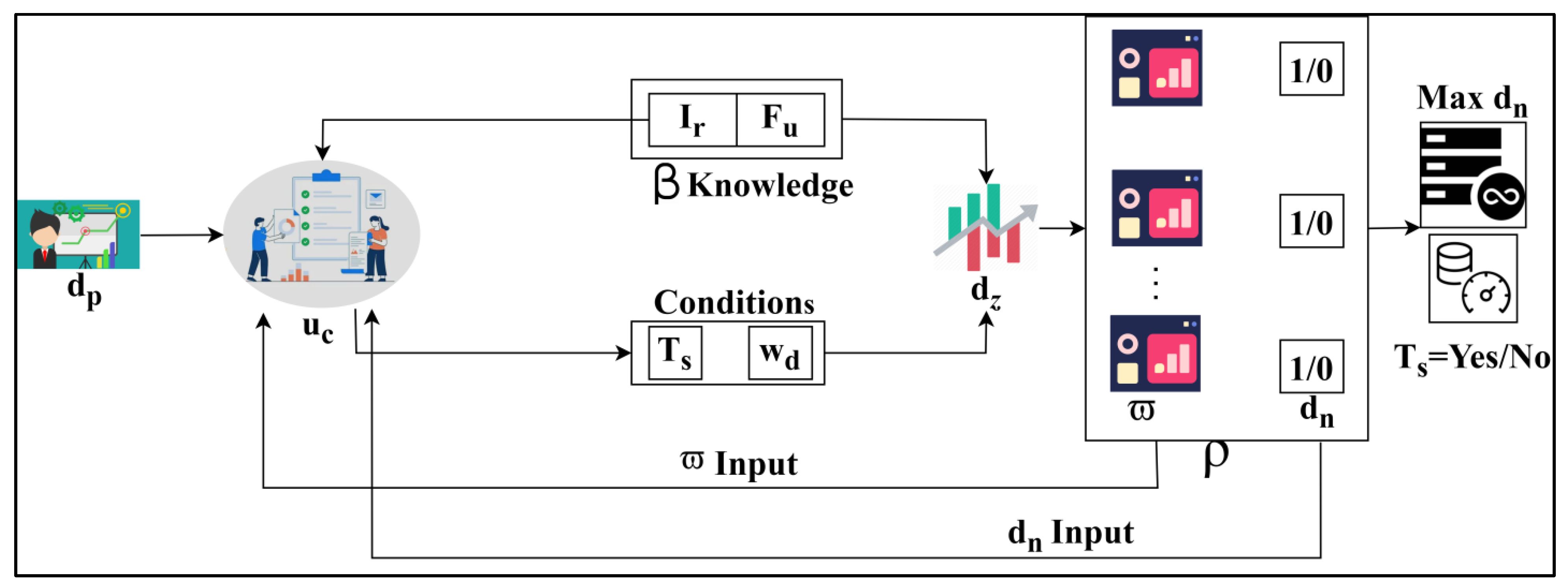
4. Cooperative-Trivial State Fuzzy Processing Method
In healthcare management systems, the trivial state reduces big data analytics errors. It defines some significance or uncertainty in the medical data, which decreases the precision of diagnosis. The data points and states are deployed to this trivial state, reducing the importance of the healthcare data. It involves data grouping in this approach where the trivial state data are detected in the healthcare management system and provide efficient results. This concept indicates the big data input and forwards to the detection phase, where the state and data points are recognized. The key idea of this work is to reduce errors and improve the precision of diagnosis. This analysis (CTSFP) is proposed along with this fuzzy model to address the error rate and enhance the diagnosis. In
Figure 2, the functional parts of the proposed method are described. Computer resources for the proposed trivial state fuzzy processing include processing power with multi-core processors and adequate memory space for storing healthcare data.
This detection category illustrates the relevant and irrelevant data that are matched with the history of medical data. This analysis is carried out from the stored data, including the diagnosis, which holds the patient’s previous history and the progression report, which illustrates the patient’s update of the prior observation. Based on this stored data, the grouping is performed to handle trivial states better. In this process, a fuzzy processing model is developed to find the n-number of derivations; based on this, invertible and non-veritable are differentiated and the result is provided. The preliminary step in this paper is to handle the trivial state of the healthcare data formulated below.
The trivial state of healthcare data processing, including precision diagnosis and handling, is represented as , the healthcare data is which includes the missing value, outlier, and data points, and they are symbolized as . The diagnosis is described as . Based on this approach, missing and inconsistent data are detected. This is used to identify the healthcare data better, allowing for better data quality and reliability in this proposed work. This processing step involves the data points where the outliers are detected in this methodology, and from this processing, reduction is observed. In this computation step, trivial data is handled to detect better precision among inconsistent and missing values.
The missing value, outlier, and data points are used to deploy the healthcare data and provide the efficient handling of constraints, which is formulated as
. In this category, the analysis examines the trivial state and provides a better progression report for diagnosing the healthcare data. Medical history is analyzed for precision diagnosis, and based on this, the fuzzy model is developed for the n-number of derivations. This trivial state illustrates the derivation from the fuzzy process where the analysis is carried out appropriately. In this method, handling is based on the trivial state of the healthcare data and illustrates the missing value and outlier in the data. From the trivial state handling, the analysis is performed for the varying healthcare data in the stored format, which is equated below.
The missing and inconsistent data are reasonable in the handling phase, and from this, the analysis is performed, and it is equated as . A trivial state is represented as , detection is , and inconsistent is described as . Here, it states that better processing of the diagnosis of healthcare data is needed and provides reliable computation. In this case, the analysis is carried out to improve the data processing. By examining this analysis, the healthcare data are fetched from the database, and from that, matching is achieved with the previous history, and the data is detected similarly to this analysis procedure.
The handling of the trivial state is observed in this approach where the error rate is included, and from this, diagnosis is carried out and is represented as
. In this category, the pragmatic data is analyzed for the better output from this trivial state of healthcare data. The existing process detects missing values, and the upcoming methodology is addressed here. In this concept, the trivial state is handled to deploy the quality and reliability of the medical data. Thus, the analysis is carried out for the varying data computation methods in this field, and from this
is performed. Then comes the data grouping process in this work, illustrated in the Equation below.
The data grouping classification is derived from irrelevant data and functional data, which are symbolized as
. The data grouping classification is labelled as
, acquiring is
, the progression report is represented as
, and the n-number of derivations is
. The first stage regards the irrelevant data acquired from the progression report and diagnosis. This history of data and the update of the current scenarios are stored in the database and used for the classification process. The first case indicates the irrelevant process that deploys the acquisition of the data from the dataset and performs a better analysis rate. Handling trivial data involves healthcare data, and it is represented as
. The pseudocode for data grouping is presented in Algorithm 1.
| Algorithm 1: Pseudocode for |
![Bioengineering 11 00539 i001]() | ![Bioengineering 11 00539 i002]() |
This trivial state indicates healthcare data that includes inconsistent and missing values. The acquisition of the desired data is used to provide trivial data, and the analysis is followed up for the missing value, in which the inconsistency is examined. The second condition is derived from the stored data in which the trivial data are used to better detect the diagnosis among the patients. This approach uses detection to classify the irrelevant and function values. Both classifications are grouped and fetch the data from the storage space. Thus, the data grouping is classified in this concept, and from this, the stored data is observed in the Equation below.
This is used to acquire specific data from storage derived from the data grouping. The n-number of derivations is used to perform the better role in this healthcare data processing step, which is described as
. This approach includes the classification model for reliable computation of trivial data. Acquiring this data indicates the patient’s previous history, where the matching is processed with the current scenario. In this case, the computation rate is improved by deploying the progression report and diagnosis. This progression report analyses the regular updates for the upcoming process. In
Table 1, the input data state is classified and represented.
Table 1 represents the
or
state analysis of the healthcare data accumulated. The
indicates the fields used in the filtered data; their range values are regarded in red (or) green or yellow. Green color denotes the health state low, normal and available ranges from [0,1,2]. Red color indicates the health state high, abnormal and unavailable ranges from [3,4,5]. Considerably, the
determines the overall output of the state as
or
. If the abnormal case is high, then
is yet to be completed, for which further derivations are required. In the alternating case, if
is the maximum possibility, then the data is
to be denied. Therefore, the state of the data is functional/irrelevant for grouping. Here, the diagnosis and the progressive report indicate a better computation factor and provide efficient derivation matching with the processing history. The n-number of derivations is associated with the analysis where the diagnosis and progressive report are included for further processing, and it is formulated as
. Thus, stored data are used in this trivial processing state where the error is reduced. Since the referred stored data are used in this case, and from this step, the irrelevant and function are differentiated and mapped using the fuzzy optimization model, which is deliberated in the section below.
5. Fuzzy Optimization for
and Derivatives
The fuzzy optimization method finds reliable results in the healthcare system where the irrelevant and function are differentiated. This fuzzy logic states whether it is 0 or 1; this paper describes whether it is invertible or non-invertible. This process uses the decision-making method, leading to error identification or improvement. Based on this decision-making approach, the required data are acquired from the stored data, providing a better result. Here, it deploys the trivial state of computation where it indicates the healthcare data for the data grouping methodology. From this, the fuzzification is performed in Equation (5):
The fuzzification is performed where the input is fetched from the previous step and forwards to the n-number of derivations. The fuzzification is described as , the forwarding is . This category uses the analysis to forward the necessary process and provide a reliable classification. This classification states the progressive report and the diagnosis of the healthcare data. Based on this section, the n-number of derivations provides efficient processing in trivial states. For the n-number of derivations, the fuzzification is pragmatic and from which the forwarding is examined in five stages, e.g., is large positive, medium positive, small, medium negative, and significant negative.
All these are split in this fuzzification methodology, where healthcare data are acquired for reliable computation from the existing step, including the data grouping. The data grouping indicates the diagnosis and the progressive report, which deploys invertible and non-invertible data. Based on this detection, the performance is measured to process reliable results among the derivation values. The derivation is used to provide better processing, which uses the fuzzy model in this Equation. This fuzzification output equates to the defuzzification in Equation (6).
The defuzzification model is the reverse of the process from the fuzzification where the crisp value is obtained. Equation (6) relies on the healthcare data acquisition and derives the stored data as a diagnosis and progressive report, and the defuzzification is labelled as
. The fuzzification and defuzzification for the grouping are illustrated in
Figure 3.
The
process is initiated with
input for
entries. This process is later defuzzified through
conditions:
(or)
. The satisfying conditions generate
and
which are the defuzzified derivatives used to analyze data states. From these
sequences,
and
is obtained. The
outputs are further used for sequence classification from
to verify
knowledge satisfaction (
Figure 3). The inconsistent data are acquired from this category and forward the derivation to the next level that indicates the handling phase, and it is formulated as
. Detecting this trivial state is associated with fuzzification, which computes the error reduction. The membership function is accomplished by formulating Equation (7) from above fuzzification and defuzzification.
The membership function in fuzzy logic is used to find the 0 or 1 here, and it is defined as either an error or not. If it is not an error, then the improvement is performed. The membership function is
, and the value range from [0, 1] is invertible data and is represented as
. Universal information is healthcare data; the set of ordered pairs refers to the grouped classifications from the stored data. This observation is performed in the membership function to find the ordered pairs in the trivial state. Here, the invertible data are acquired from the derivation, where the analysis is carried out appropriately. Posted to this membership function in the fuzzy model, the separation is examined from the derivation, whether invertible, non-invertible, or formulated in Equation (8).
The separation of trivial states depends on the data that is invertible and non-invertible. Based on this process, the stored data are acquired and perform better data grouping for the irrelevant and function data. The separation is described as
, where the value equal to 0 states the invertible, whereas the value not equal to 0 defines non-invertible. The separation process pseudocode is presented in Algorithm 2.
| Algorithm 2: Pseudocode for |
![Bioengineering 11 00539 i003]() | ![Bioengineering 11 00539 i004]() |
Based on this classification, trivial data are obtained. In this category, detection is observed on the irrelevant function from which the stored data are acquired. Here, data grouping classification is performed for the varying trivial state that deploys the big data as the input for this processing. This derivation is pragmatic for separating invertible and non-invertible data computation. This separation process evaluates the decision-making to find whether it is invertible, equated below.
The separation of invertible and non-invertible data follows up the decision-making and provides the changes that occur during the trivial state dispensation, where non-invertible is represented as
. The decision-making is
defined in
if and
otherwise conditions where it deploys the trivial state for the pragmatic healthcare data in this methodology. These functional data are associated with the analysis where the derivations are used to provide better separation among the errors that occur due to the uncertainty due to the missing value. Based on the separation, the fuzzy outputs for
are analyzed for F1 to F6 in
Figure 4.
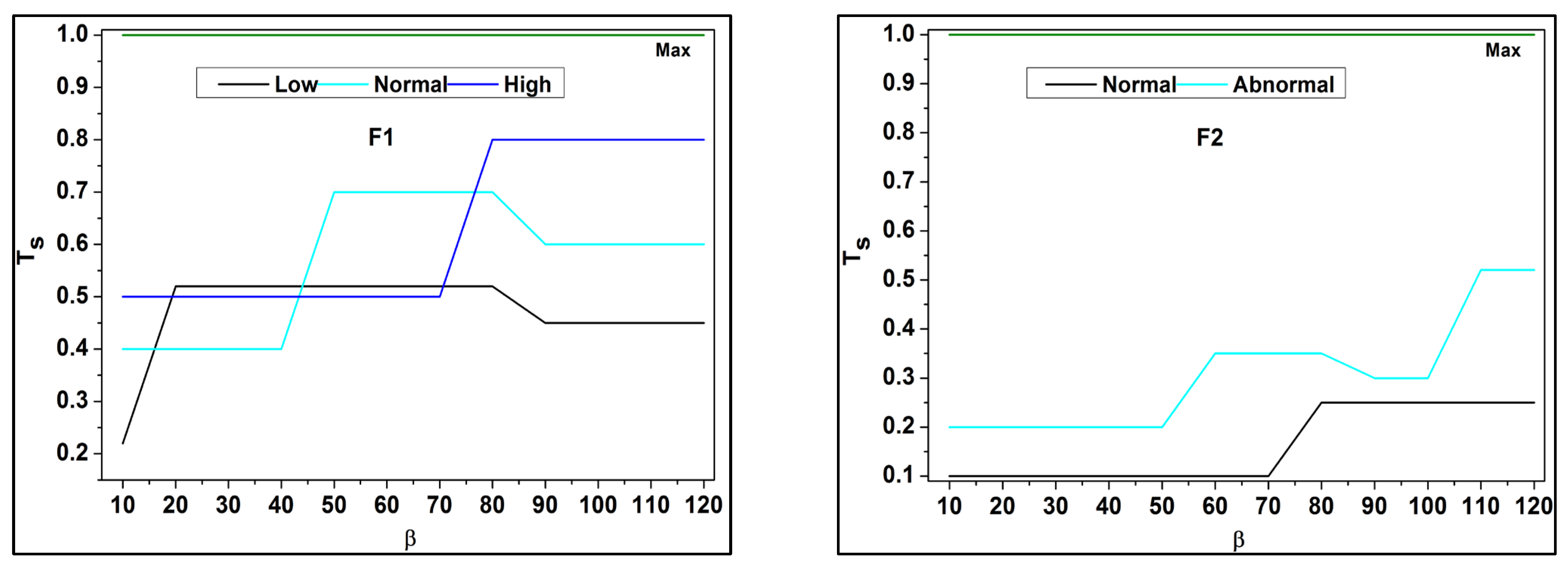
In
Figure 4 above, the classifications under
for different data input fields are validated. The
Y-axis denotes the trivial state
and the
X-axis indicates the data grouping process
. Based on the available
and it is corresponding
, the
the analysis is presented. If the
and
processes are tallied, then
is high, otherwise it is low. This demands data acquisition for further
and
processes (
Figure 4). These derivations are used to examine the invertible, where it is associated with it, and the condition of the
otherwise function. This condition is followed through the decision-making process, in which fuzzy optimization plays a significant role in this derivation. Here, the invertible condition is satisfied after this identification of functional data runs through the analysis and is equated below.
The identification of functional data is derived and is formulated as
; in this stage, the decision-making is carried out for the reliable computation based on the invertible data, and the uncertainty is labelled as
. The decisions are made from the n-number of derivations and followed up. The healthcare data are integrated with the fuzzy processing in which the membership function is introduced for precision diagnosis. The derivations are associated with irrelevant and functional data processing in this stage. Here, extensive data analysis is performed for the trivial state computation and continues towards the data grouping. Thus, the identification of functional data is examined with the decision-making approach. Then the diagnosis and progression from the stored data are identified and updated based on the current user details. This diagnosis and progression are expressed in Equation (11).
Here, the identification runs through the diagnosis and progression report that includes the status of the patient information. These processes are built into the stored data function. The stored data reflects the changes if any update or changes occur during a short time interval. These changes are identified based on the uncertainty occurrences in the healthcare data for the varying derivations. The relationship between
and
for invertible analysis is tabulated in
Table 2.
In
Table 2, the relationship between
and
based on valued
is presented. The field-to-field with normal/available conditions represents the highest relationship (i.e.,
). The rest of the cases are validated based on
across
and
separations. These two cases are derived from multiple
and
derivatives such that the
is mitigated. Thus, the separation for
incurring instances (above) are high compared to
incurring cases (below). This process is repeated until the least possible derivatives
are extracted/identified. The
derivations are associated with the trivial state in which the decision-making concept is used for the state forwarding. Based on the update, the changes in the derivation are observed, and the trivial state is used to define the processing step for the different states of the approach. Thus, the identification is carried out for the diagnosis and the progressive report, and the invertible data is detected from the decision-making approach and is equated in the Equation below.
The invertible data analysis is pragmatic based on the diagnosis and progressive report update. In this approach, functional data is identified, and it is labelled as
; in this classification, it is followed up for the decision-making concept from the fuzzy model. This analysis is executed for the data grouping model and the decision-making of data, whether it is invertible or not. This Equation is used to acquire the input from the big data where the function changes to irrelevant, and then it is said to be invertible; on the other hand, if irrelevant changes to function are observed, it is non-invertible. Thus, the analysis is processed for the invertible data in a trivial state, and the error is detected from this data computation which is equated below.
The trivial state error is detected from Equation (13), where the functional data are handled for functional usage. The detection is formulated as
, the error is symbolized as
, and improvement is described as
, where the diagnosis is executed from the derivation from the fuzzy process. In this, the membership function is used to provide the reduction phase for the derivation and order of the pairs. Thus, the error rate is detected in the first derivative and addressed to the upcoming derivations. Based on this error detection in the trivial state, precision diagnosis is improved using this method. With the
for
and
using
under data grouping towards progression, an error is analyzed, as shown in
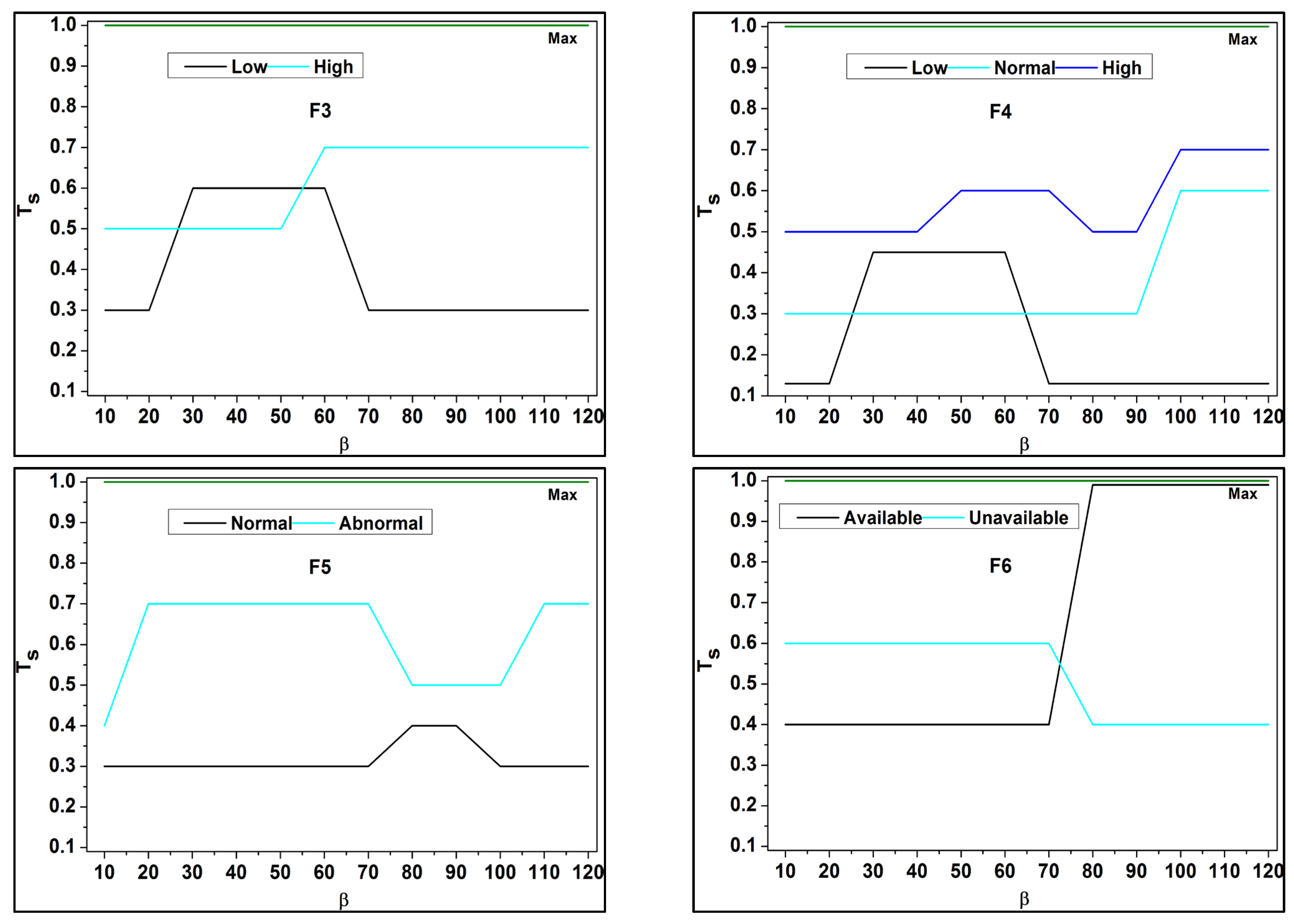
Figure 5.
In the above assessment for
and
under
and
the
impacts the performance using
. The derivatives are abrupt through the max
and
conditions for
improvements. Under different
knowledge conditions, the
separation is performed such that
is satisfied. Hence, the case of
for
is high
and
under different data inputs. The filtered data thus is utilized for its intense field-to-field matching for different
(refer to
Figure 5). The possible biases caused by fuzzy processing in healthcare data include sampling, measurement, patient selection, and algorithmic biases.
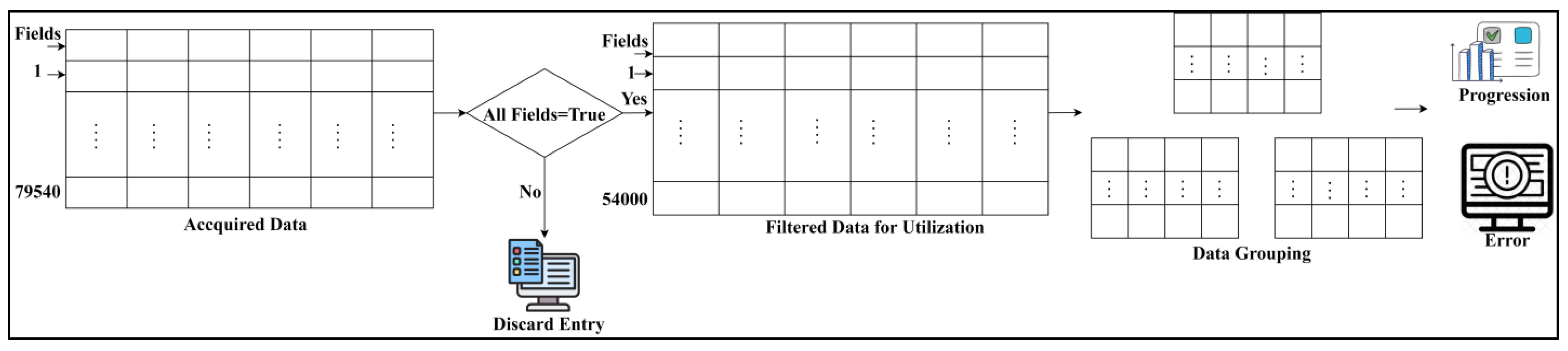
6. Performance Assessment
The performance assessment uses analysis rate, data grouping, irrelevance estimation, error, and analysis time. The number of data records considered is 52K, filtered from the dataset inputs, and a maximum of 120 groups are formed. In this assessment, the existing USDA [
23], SBDA [
19], and HDCO-DEL [
25] methods are added along with the proposed CTSFP method for efficacy verification. The data used in this article were acquired from the “health score” electronic health record for assessment (
https://www.kaggle.com/datasets/hansaniuma/patient-health-scores-for-ehr-data, accessed on 15 March 2024). The temperature, pulse, respiratory, blood pressure, dialysis, and imagery information are stored under 79,540 entries. This data is used to classify patient health as severe or normal using individual score values.
In healthcare data analysis, the CTSFP method outperforms existing methods like USDA [
23], SBDA [
19], and HDCO-DEL [
25] in terms of error reduction capabilities. Improved diagnosis accuracy and reliability are the results of the proposed method’s use of fuzzy logic-assisted processing to reduce the impact of uncertainties and mistakes in the structure of healthcare data.
By surpassing previous methods in detecting and classifying data important to diagnosis and unrelated data, the technique demonstrates notable advancements in data grouping and irrelevant estimation. The suggested approach improves data classification accuracy and relevance identification by relying on a recent understanding of diagnosis progression and using fuzzy logic in decision-making processes. CTSFP outperforms state-of-the-art approaches regarding concerns about managing healthcare data with trivial states. Compared to more traditional methods, this method can identify and fix data issues, including missing values, inaccurate information, and errors, making it a better foundation for accurate diagnosis and evaluation.
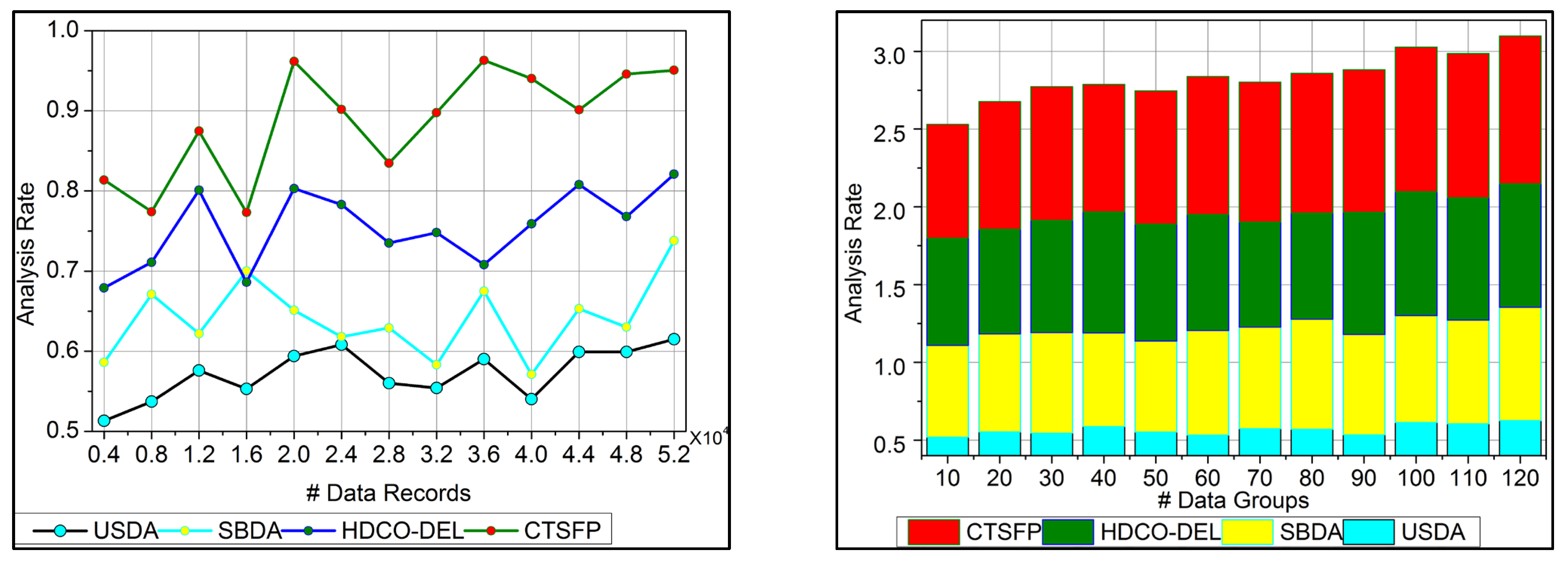
6.1. Analysis Rate
The analysis rate for the proposed work increases for the varying trivial state that deploys the fuzzy processing to detect the healthcare data. This approach is based on functional data, which provides the n-number of derivations. Here, the invertible concept is used to find the improvement in the detection process. The big data input is fetched from the healthcare system, and the diagnosis is processed precisely. In this stage, the analysis rate is enhanced by detecting the invertible in the data, which is proposed by the fuzzy optimization method. In this work, data storage is developed for the diagnosis that includes the history of patient data and the progression reports that hold the update of the patient’s health. The trivial state handling of healthcare data addresses the error or the outlier in the input data. This trivial state includes missing or inconsistent datapoints, and it is discussed in Equation (1) and is represented as
. The execution of the analysis rate in this work is improved by processing this fuzzy processing under healthcare data (
Figure 6).
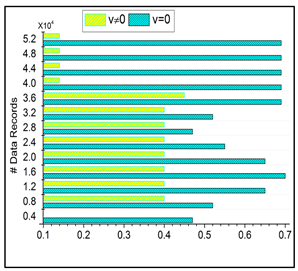
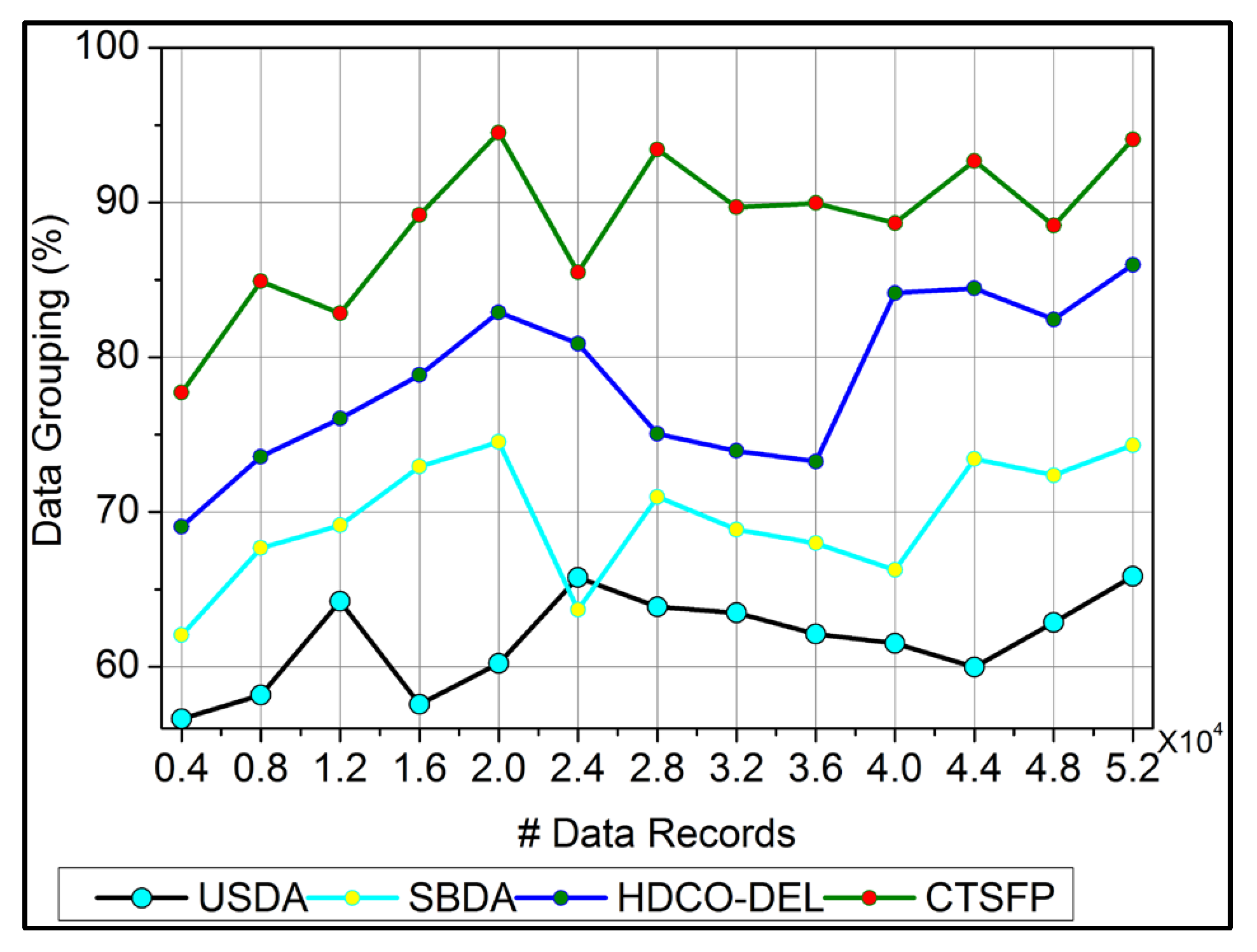
6.2. Data Grouping
In
Figure 7, data grouping is improved by the classification phase equated in Equation (3). Here, this computation relates to the n-derivation in the fuzzy process and determines the invertible under the input data. In this case, data forwarding to the end process relies on the precision of diagnosis. This concept is proposed to provide irrelevant and functional data in the healthcare system. The evaluation step includes the invertible and non-invertible data used to find the n-number of derivations and provides a better precision diagnosis. The detection process is used to improve the recommendation for the data grouping for healthcare data. The invertible is input to the improvement if the fuzzy process runs accurately for the big data analysis, and it is formulated as
. Here, the invertible and non-invertible data are examined to find the trivial state. This data grouping is used to represent the diagnosis and the progression report from the invertible data processing. This data grouping is extracted from the stored data, which shows better improvement.
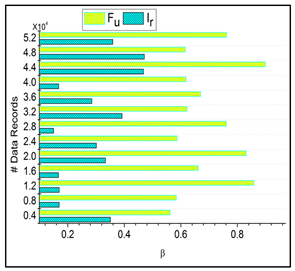
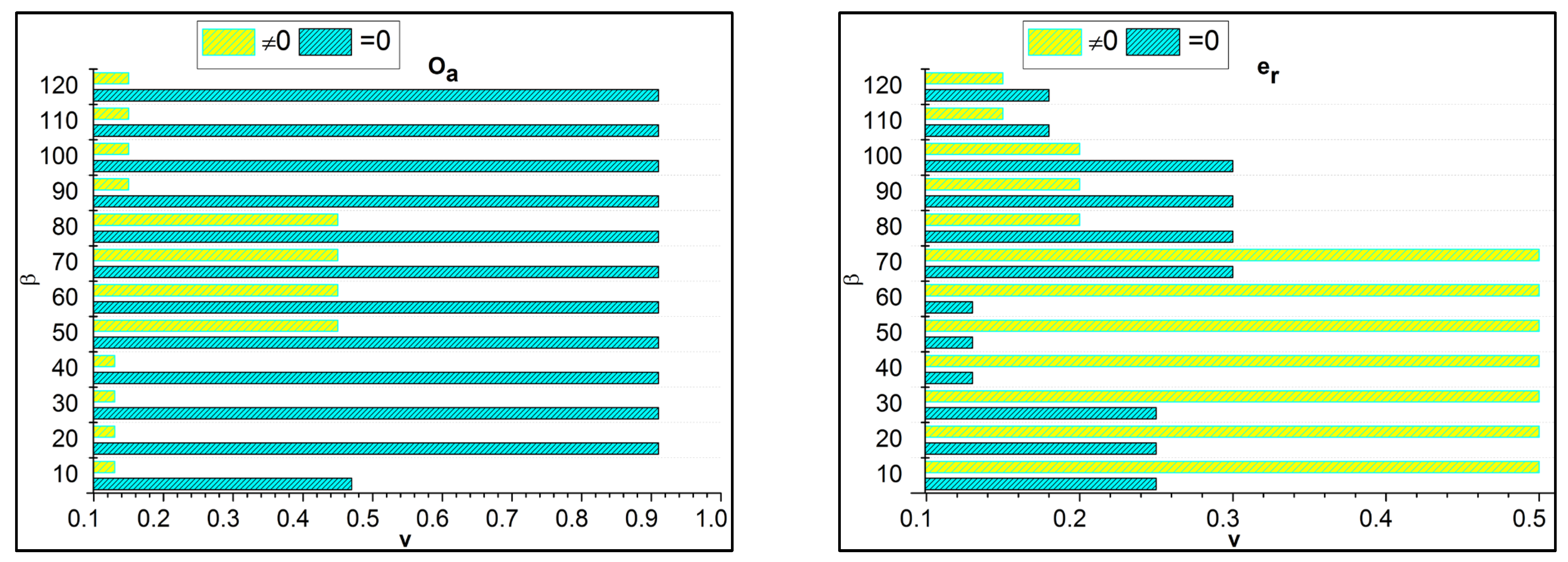
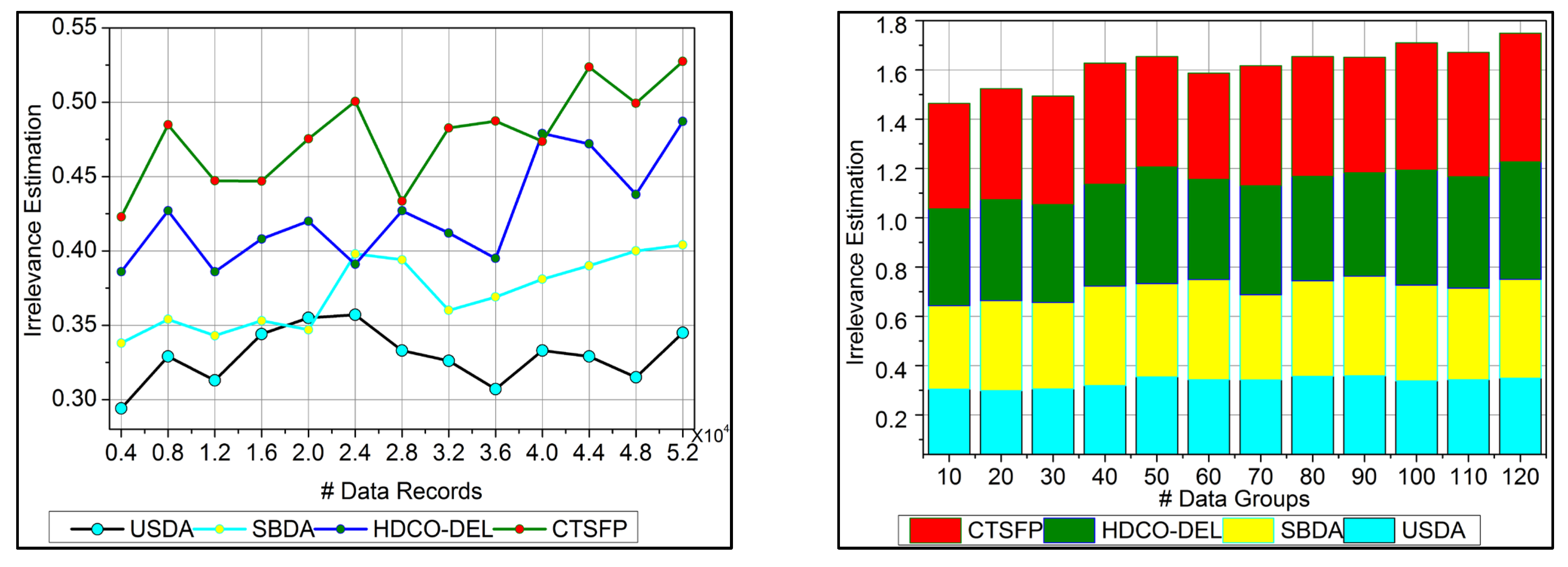
6.3. Irrelevance Estimation
The irrelevant estimation shows better improvement based on the trivial state data computation. Here, the decision-making approach, followed by fuzzy logic, is deployed. This fuzzy logic illustrates the membership function that defines the invertible and the data grouping. The irrelevant estimation is identified in this category based on these two structures. This is one approach; the precision diagnosis is used to define the better-stored data and find the trivial state by examining the missing value. The inconsistent and missing values are detected from the trivial state, providing better identification. The diagnosis and progressive report are based on the trivial state handling under healthcare data management, and it is represented as
. The classification phase is used in this work for the functional data and irrelevant identification from the data grouping. From this case, the irrelevant estimation shows the higher value range extracted from the data grouping concept. This estimation phase relies on detecting trivial states for the healthcare data (
Figure 8).
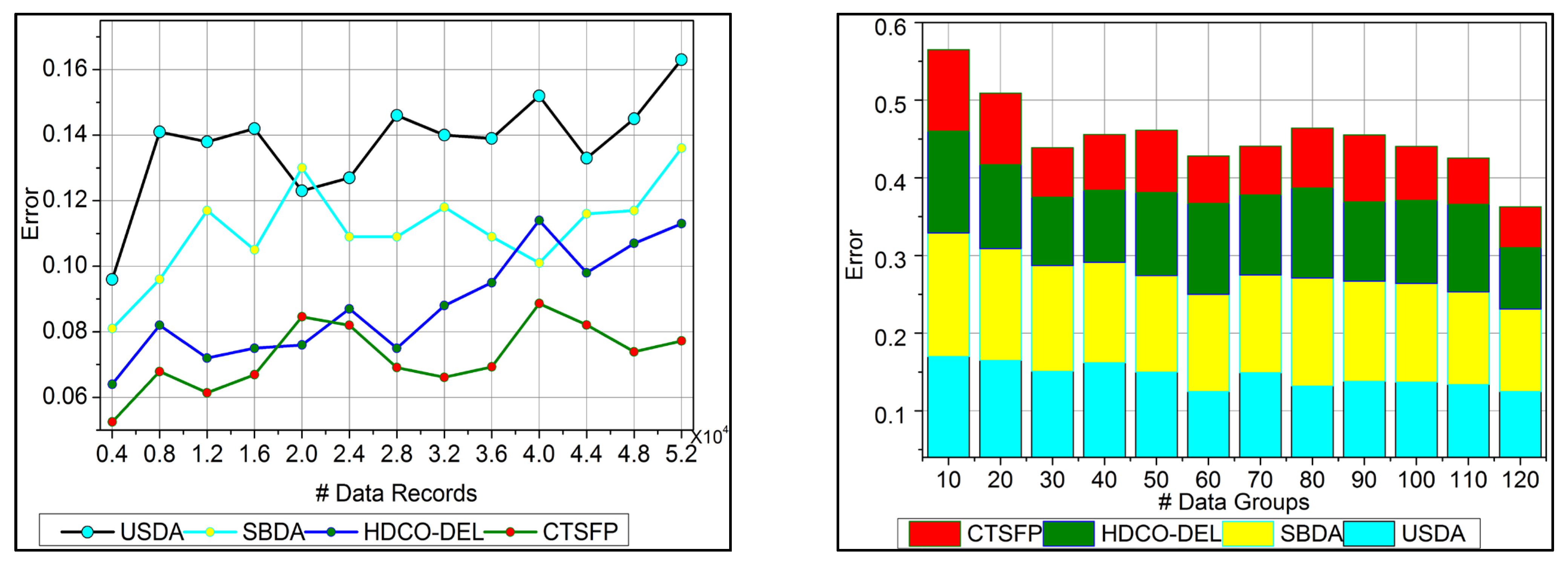
6.4. Error
In
Figure 9, the error is detected, and a lesser range is shown for the trivial state by deploying recommendations under the healthcare data. This analysis defines the irrelevant data extraction from the healthcare data and provides the invertible process. This approach is observed for the n-derivation, where the trivial state is examined to find the missing and the inconsistent data from the trivial state handling. This error detection is used to illustrate the data point and the classification under the reduction of constraint for the healthcare data. The detection is followed up for uncertainty and improves the invertible data computation in this approach. The n-derivation is associated with invertible data processing, where the trivial state is used to deploy the fuzzy model. Fuzzification and defuzzification are better used to reference the fuzzy model’s trivial state. Equation (13) is used to find the trivial state of detection and reduce the error factor, and it is equated as
. Here, the trivial state and functional data are acquired, and the invertible is found, reducing the error.
6.5. Analysis Time
In
Figure 10, the analysis time for the proposed work is reduced based on the data grouping concept. This approach indicates the n-derivation forwarding and provides reliable fuzzy processing. The diagnosis precision is improved in this work by reducing the error in this healthcare data. The uncertainty means the healthcare big data analysis where the identification provides functional data under fuzzy processing. This fuzzy processing is used to provide the invertible under the functional data. This stored data is used to define the diagnosis and the progression report to acquire the data grouping. The derivation is computed by classifying irrelevant or functional data in this optimization process. This identification is used to develop a precision diagnosis with reduced errors. From this stage, the analysis is used to propose the trivial state handling under the irrelevant computation. The analysis time is calculated for the healthcare data processing, and it is reduced and represented as
.
This study utilizes p-values to determine whether the sample estimate differs considerably from a hypothesized value. If there was no actual impact, the p-value indicates the probability that the observed effect within the research occurred by chance. Statistical significance is traditionally conferred upon data with a p-value of <0.05 or <0.01. Within a specified confidence level (e.g., 95%), a confidence interval gives a range of values, one of which is the precise value of the statistical constraint within the specified population. A confidence interval is a range that includes the most likely lower and upper bounds of a connection or difference for a given population. Confidence intervals, as opposed to p-values, provide greater evidence about the accuracy of an estimate; for example, a 95% confidence interval would mean that the range would include the real value in 95% of cases.
In this performance evaluation, the recommended CTSFP is selected for comparison assessment with the existing state-of-the-art methods like USDA, SBDA, and HDCO-DEL methodologies because of their significant advantages to healthcare big data analytics. Important vital aspects covered by each approach include managing data from wearable devices, monitoring patients in real-time, and using an advanced selection of features for accurate evaluation. Essential insights for healthcare management decision-making can be derived from analyzing their performance concerning accuracy, analysis rate, data grouping efficiency, irrelevance estimation, error detection and appropriateness of analysis time for healthcare applications.
In this comparison evaluation, the results across the considered metrics reveal the advantages and disadvantages of each strategy, giving helpful information about the best method to put them into practice in analyzing healthcare big data. For efficient and precise processing of missing information from sensors, the USDA model performs exceptionally well in the real-time monitoring of patients. Disease detection and forecasting are two areas where the SBDA model shines, demonstrating its strength in times of crisis. In contrast, the HDCO-DEL model is scalable and displays remarkable accuracy in medical data classification, making healthcare surveillance techniques more dependable.
Despite the methods’ strengths, they all have drawbacks, such as computational inefficiency and problems with data analysis. In contrast, the suggested CTSFP approach is used to preprocess healthcare big data to increase accuracy, data analysis time, and resilience to overcome these restrictions. The CTSFP method is an innovative new direction for healthcare management practices since it uses data normalization, noise reduction, and outlier detection to enhance healthcare analytics. Additional empirical testing is required to determine the method’s practical usefulness. Still, it offers a fresh perspective on the challenges associated with big data healthcare analysis and could lead to more reliable decision-making in the healthcare domain.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}