1. Introduction
Hypertension is a prevalent condition, impacting three out of every ten adults [
1]. Hypertension is dangerous because it leads to complications like arteriosclerosis, stroke, and heart failure. Heart failure (HF) is a disease in which the body is not supplied with the amount of blood required due to impaired diastolic or systolic function of the heart. On average, HF patients have a one-year mortality rate of 33%, indicating a very poor prognosis [
2]. Crucially, the incidence of HF is about three times higher in hypertensive patients than in nonhypertensive populations [
3]. Therefore, patients with hypertension need to be especially careful to avoid developing HF. We believe that identifying predictive factors for HF progression in hypertensive patients would be of great benefit.
The purpose of this study is to identify predictive factors for heart failure progression in hypertensive patients, and for this purpose, it was decided to use diagnosed medical conditions. Genetic data such as gene expression and DNA sequences can also be used to identify the predictive factors; however, genetic data on patients with hypertension and HF are not sufficient to build analytical models. Furthermore, even if analytical models are successfully constructed using genetic data, hypertension patients will need to obtain their genetic information in order to utilize the models. Predictive factors based on medical conditions, which are easily accessible to most hypertension patients, are expected to be highly useful.
Importantly, only medical histories recorded prior to the time of hypertension diagnosis were employed in this study. This will make it possible to predict heart failure at the exact point of hypertension diagnosis based on previous medical conditions. The reason for establishing this strategy is because preliminary analysis confirmed that most patients develop heart failure within a year after being diagnosed with hypertension, which represents a very rapid progression (refer to
Section 2.2 for more details).
There are many well-known predictive factors for heart failure derived from medical conditions, which can be broadly divided into two categories, i.e., cardiac dysfunctions and adult diseases [
4]. Coronary artery disease and valvular heart disease can be included in cardiac dysfunctions [
5,
6], and type 2 diabetes and obesity are associated with adult diseases [
7,
8]. Hypertension, known as a representative adult disease, is also one of the well-known predictive factors for HF [
9]. However, to our knowledge, this study is the first to identify predictors of HF in the setting of diagnosed hypertension. We hope that the results of this study will be of great help to hypertensive patients.
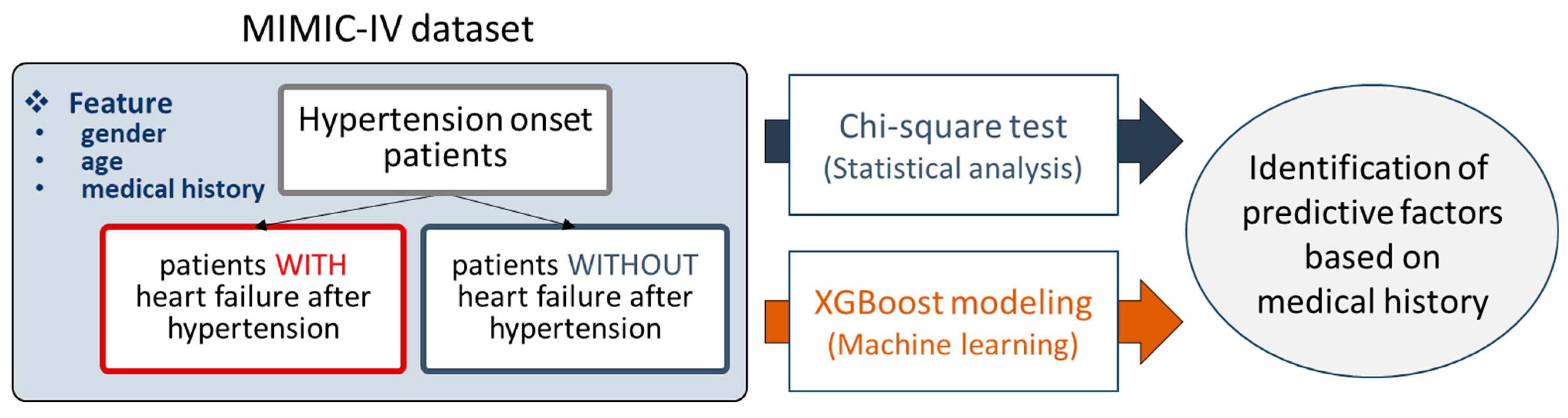
For this study, we decided to use the MIMIC-IV database, containing various kinds of clinical data such as diagnosed diseases and demographic information. Patients diagnosed with hypertension were selected from the MIMIC-IV dataset and divided into two groups: those who later developed HF and those who did not. For each patient, medical history prior to the point of hypertension diagnosis was processed and obtained, and age and gender information were added as well. Then, two analysis methods were applied to the preprocessed data, i.e., the chi-square test and XGBoost modeling. In the chi-square test, statistically significant medical conditions were characterized as predictive factors. By training XGBoost models, the feature importance scores of the trained models were employed to reveal predictive factors (
Figure 1).
We also prepared a detailed strategy overview for this study, shown in
Figure 2. The prepared hypertensive patients were divided into two groups according to the ICD systems used (9 and 10), because both ICD systems were used simultaneously in the MIMIC-IV database. Furthermore, they were further divided into four subgroups according to age: AL (all ages), G1 (0 to 65 years), G2 (65 to 80 years), and G3 (over 80 years). By applying both chi-square test and XGBoost modeling to the subgroups and integrating their outcomes, we characterized the 21 overall predictive factors, such as atrial fibrillation, the use of anticoagulants, kidney failure, pneumonia, and anemia. Then, they were assessed through an extensive review of the literature.
The manuscript begins with introduction outlining the importance of identifying predictive factors for heart failure progression in hypertensive patients. Following this, the materials and methods section details the utilization of the MIMIC-IV dataset, data preprocessing techniques, and analytical methods such as the chi-square test and XGBoost modeling. The results section presents findings from the chi-square test, XGBoost modeling, and overall predictive factor characterization. Subsequently, an evaluation of the results is conducted through a review of the literature, leading to a discussion and conclusions section. We assert that the following three aspects are the innovative contributions of this study: (1) Identification of predictive factors that anticipate the onset of heart failure at the time of hypertension diagnosis; (2) Integration of two analytical methods, the chi-square test and XGBoost modeling, to examine heart failure predictive factors; (3) Identification of heart failure predictive factors across four distinct age groups.
2. Materials and Methods
2.1. MIMIC-IV Dataset
In this study, we decided to use the MIMIC-IV (Medical Information Mart for Intensive Care IV) dataset, which is a comprehensive and widely utilized resource in the field of healthcare research [
10,
11]. The MIMIC-IV dataset contains deidentified electronic health records from patients admitted to the Beth Israel Deaconess Medical Center in Boston. It provides a rich and diverse collection of clinical data, including diagnosed diseases, laboratory results, medications, and demographic information, spanning over a decade [
12,
13]. Researchers can leverage this dataset to handle various medical issues, such as predicting patient outcomes and understanding disease trajectories [
14,
15]. Among all patients in MIMIC-IV, only data on patients diagnosed with hypertension (code 4019 for ICD-9 and I10 for ICD-10) were collected. As two types of ICD systems (9 and 10) were used for diagnosis in the MIMIC-IV database, we classified the patients into two groups based on the ICD systems used (top of
Figure 2). During this process, patients using both ICD systems were excluded.
2.2. Data Preprocessing
The three steps of data preprocessing were performed sequentially on the prepared data (top right side of
Figure 2): (1) subgroup generation; (2) class assignment; and (3) feature selection. Firstly, subgroups were generated based on age at the first diagnosis of hypertension (FDH), allowing four kinds of subgroups, i.e., AL (0 ≤ age, entire data), G1 (0 ≤ age < 65), G2 (65 ≤ age < 80), and G3 (80 ≤ age). Secondly, patients in each subgroup were divided into two classes (H0 and HF). Class H0 was assigned to patients without heart failure after the FDH, and class HF was assigned to patients diagnosed with heart failure after the FDH. The ICD codes in
Table S1 were used to determine which patients were diagnosed with HF. During this process, patients diagnosed with HF before the FDH were excluded. The number of patients in H0 and HF classes for each subgroup is summarized in
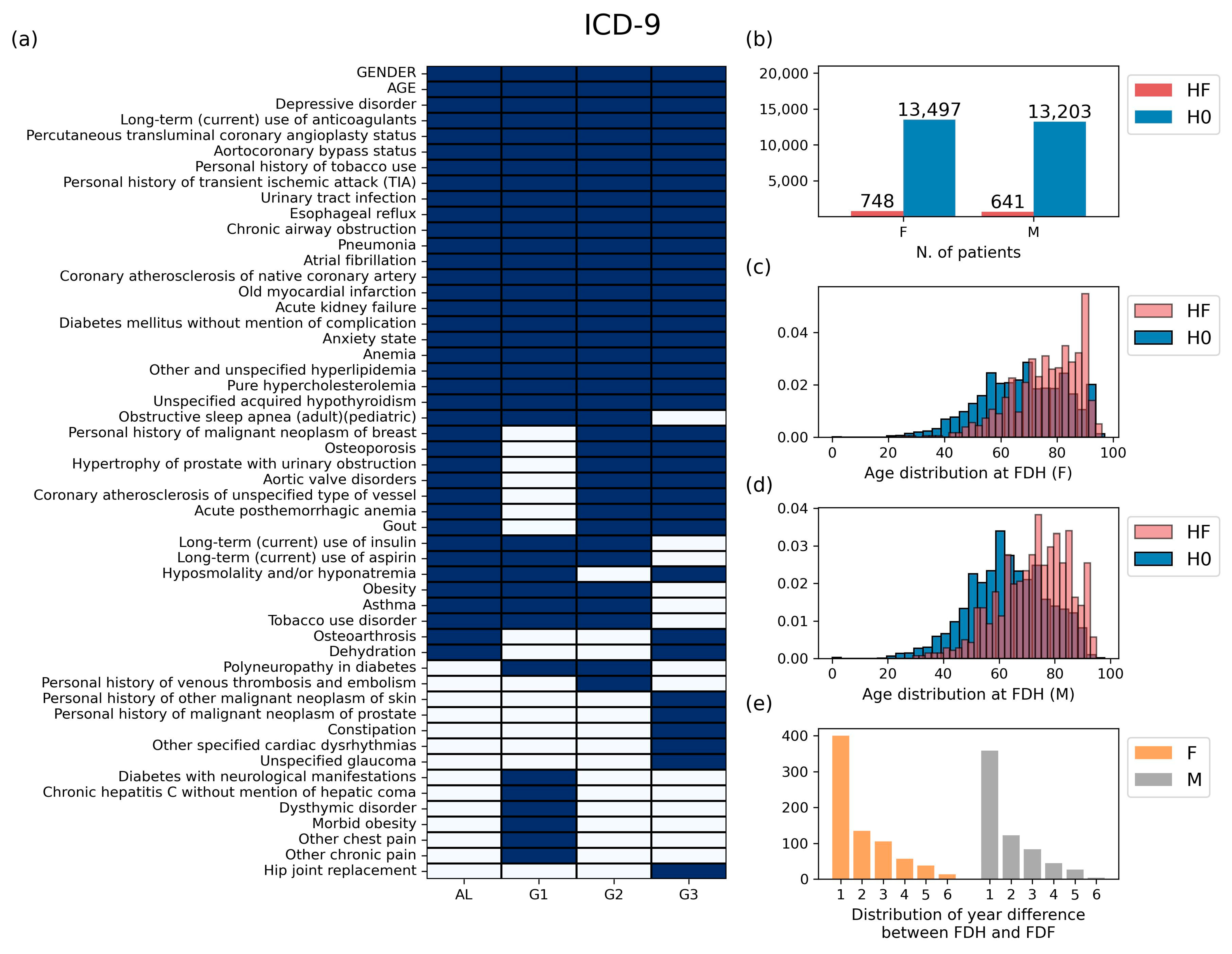
Table 1. Thirdly, features used in analytical methods were selected. Medical conditions diagnosed before FDH (i.e., the previous medical history at the time of FDH) were considered to be candidate features. We noticed that the number of medical conditions diagnosed before FDH was very large: more than 5000 in ICD-9 and more than 8000 in ICD-10. Therefore, for each group, only frequently diagnosed medical history data in patients of class HF (≥5%) were selected as the features for analytical methods. Additionally, two pieces of personal information, gender and age, were added.
The basic statistics for the data prepared through the preprocessing stage are shown in
Figure 3 for ICD-9 and
Figure S1 for ICD-10. In the ICD-9 case, the number of features selected in at least one group was 52, and the number of features selected in all four groups was 22 (
Figure 3a). The selected ICD codes and their full names are displayed in
Table S2. Patients belonging to class HF account for 5.25% in the female group and 4.63% in the male group (
Figure 3b). In both genders, the FDH distribution of class HF was more skewed to the right compared to that of class H0, indicating that the older the age of FDH presentation, the more likely patients are to develop heart failure later in life (
Figure 3c,d). We also found that the first diagnosis of heart failure (FDF) most frequently occurred within one year after FDH (
Figure 3e). The same kind of information corresponding to ICD-10 is provided in
Figure S1 and Table S3.
2.3. Analytical Methods
2.3.1. Chi-Square Test
Two kinds of analysis methods were used in this study: the chi-square test and XGBoost modeling. Chi-squared is a statistical test used to assess the association between categorical variables. It compares the observed distribution of data with the expected distribution, assuming that there is no significant relationship between the variables. Chi-squared tests are commonly employed in various fields, including biology and medical science, to examine the dependence of categorical variables [
16]. When using the chi2_contingency function in the Python scipy package (
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.chi2_contingency.html accessed on 22 May 2024), the chi-square test is applied between the class features, consisting of HF and H0, and each of the selected medical histories.
2.3.2. XGBoost Modeling
Among various machine learning models including decision trees, support vector machines, random forest, and logistic regression, we decided to use eXtreme Gradient Boosting (XGBoost) to predict heart failure progression, which is intensively used and shows outstanding performance in the biomedical field [
17,
18,
19,
20]. XGBoost is an ensemble learning method that combines multiple decision trees to create a robust and accurate predictive model. It is a powerful and versatile machine learning algorithm that has gained widespread popularity for its exceptional performance across various predictive modeling tasks [
21].
In this study, XGBoost models that classified the class feature consisting of HF and H0 were trained based on gender, age, and the medical history selected in each group, implemented using the Python xgboost package with default parameters (
https://xgboost.readthedocs.io/en/stable/python/ accessed on 22 May 2024). For each of the four groups, the XGBoost models were generated 1000 times with randomly sampled balanced datasets. In more detail, to build a single XGBoost model, a merged dataset was prepared by concatenating patients in class HF and a portion of patients in class H0 that were randomly sampled as many as the patients in class HF. Then, 80% of the merged data were used for training, and the remaining data were used for testing.
In this study, two types of outputs were extracted from the trained XGBoost models, i.e., area under the ROC curve (AUC) and feature importance (FI). AUC is one of the most frequently used performance metrics in machine learning modeling, and it has a higher value when a model predicts test samples more accurately. FI was assigned to each feature during the model training process, which indicates the extent of performance reduction when a certain feature is perturbed. A feature exhibiting a high FI suggests its critical role in class discrimination [
19]. To determine significant predictive factors by FI, we computed empirical
p-values for FIs because there is not a conventional cutoff for determining significance. To this end, we constructed a background distribution of FIs and decided to use 0.0251 as the significance cutoff, with an empirical
p-value of 0.01.
3. Results
3.1. Chi-Squared Test
For each of the four groups, a chi-square test was applied between the class feature and each piece of medical history information considered in the corresponding group. The significant predictive factors (
p-value < 0.01) are depicted in a heatmap for each ICD system in
Figure 4, where nonsignificant factors are grayed out. As shown on the left side of
Figure 4, for the case of ICD-9, 33 predictive factors were identified as significant in at least one group, and six predictive factors were identified in all four groups (i.e., age, atrial fibrillation, aortocoronary bypass graft, atherosclerosis disease, old myocardial infarction, and coronary angioplasty status). A total of 26, 21, 14, and 7 predictive factors were determined in AL, G1, G2, and G3 groups, respectively. We noticed that there were several group-specific predictive factors in each group, e.g., anemia for AL, obstructive sleep apnea for G1, and nicotine dependence for G2. Detailed results are shown in
Table S4.
As shown on the right side of
Figure 4, for the case of ICD-10, 28 predictive factors were identified as significant in at least one group. In addition, three predictive factors were identified in all four groups (i.e., unspecified atrial fibrillation, long-term use of anticoagulants, and long-term use of insulin). Overall, 24, 19, 14, and 5 predictive factors were determined in AL, G1, G2, and G3 groups, respectively. We also noticed that there were several group-specific predictive factors in each group, e.g., hypothyroidism for AL and major depressive disorder for G1. Detailed results are presented in
Table S5.
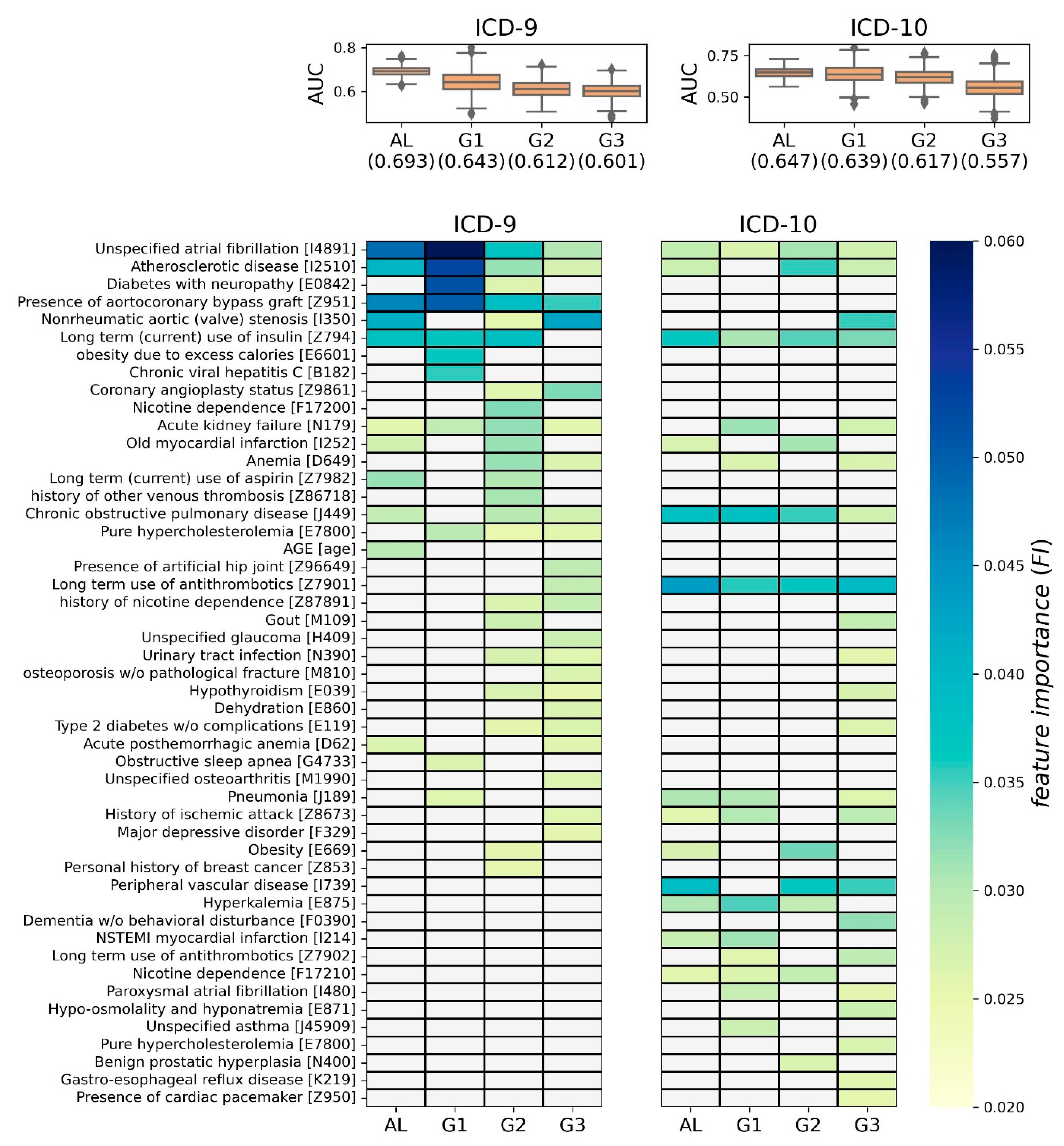
3.2. XGBoost Modeling
For each of the four groups, 1000 XGBoost models were generated. Then, their AUCs and FIs were depicted as boxplots and heatmaps, respectively (
Figure 5). In the
Supplementary Material, the average precision rate (APR) of the XGBoost models are also shown as boxplots in
Figure S2. Each cell in the heatmap represents the averaged FI (Ave.FI) of the 1000 XGBoost models, and Ave.FI is colored based on the color bar if significant (>0.0251); otherwise, it is grayed out (refer to
Section 2.3.2 for more details).
In the case of ICD-9, the average of 1000 AUC was highest in the AL group at 0.693, and lowest in the G3 group at 0.601. From a volatility perspective, the models in the AL group were the most stable, and those in the G1 group were associated with the largest variation. Using FI, 36 predictive factors were identified as significant in at least one group, and 4 predictive factors were identified in all four groups (i.e., atrial fibrillation, atherosclerotic heart disease, aortocoronary bypass graft, and acute kidney failure). Overall, 11, 11, 22, and 22 predictive factors were determined in AL, G1, G2, and G3 groups, respectively. We noticed that there were several group-specific predictive factors in each group, e.g., age for AL, obesity for G1, gout for G2, and long-term use of anticoagulants for G3 (left side of
Figure 5).
In the case of ICD-10, the average of 1000 AUC was highest in the AL group, at 0.647, and lowest in the G3 group at 0.557. From a volatility perspective, the models in the AL group were the most stable, and those in the G1 and G3 groups were associated with the largest variation. Using FI, 29 predictive factors were identified as significant in at least one group, and 4 predictive factors were identified in all four groups (i.e., long-term use of anticoagulants, chronic obstructive pulmonary disease, long-term use of insulin, and unspecified atrial fibrillation). Overall, 13, 14, 11, and 22 predictive factors were determined in AL, G1, G2, and G3 groups, respectively. We noticed that there were several group-specific predictive factors in each group, e.g., asthma for G1, benign prostatic hyperplasia for G2, and dementia without behavioral disturbance for G3 (right side of
Figure 5).
3.3. Overall Predictive Factor Characterization
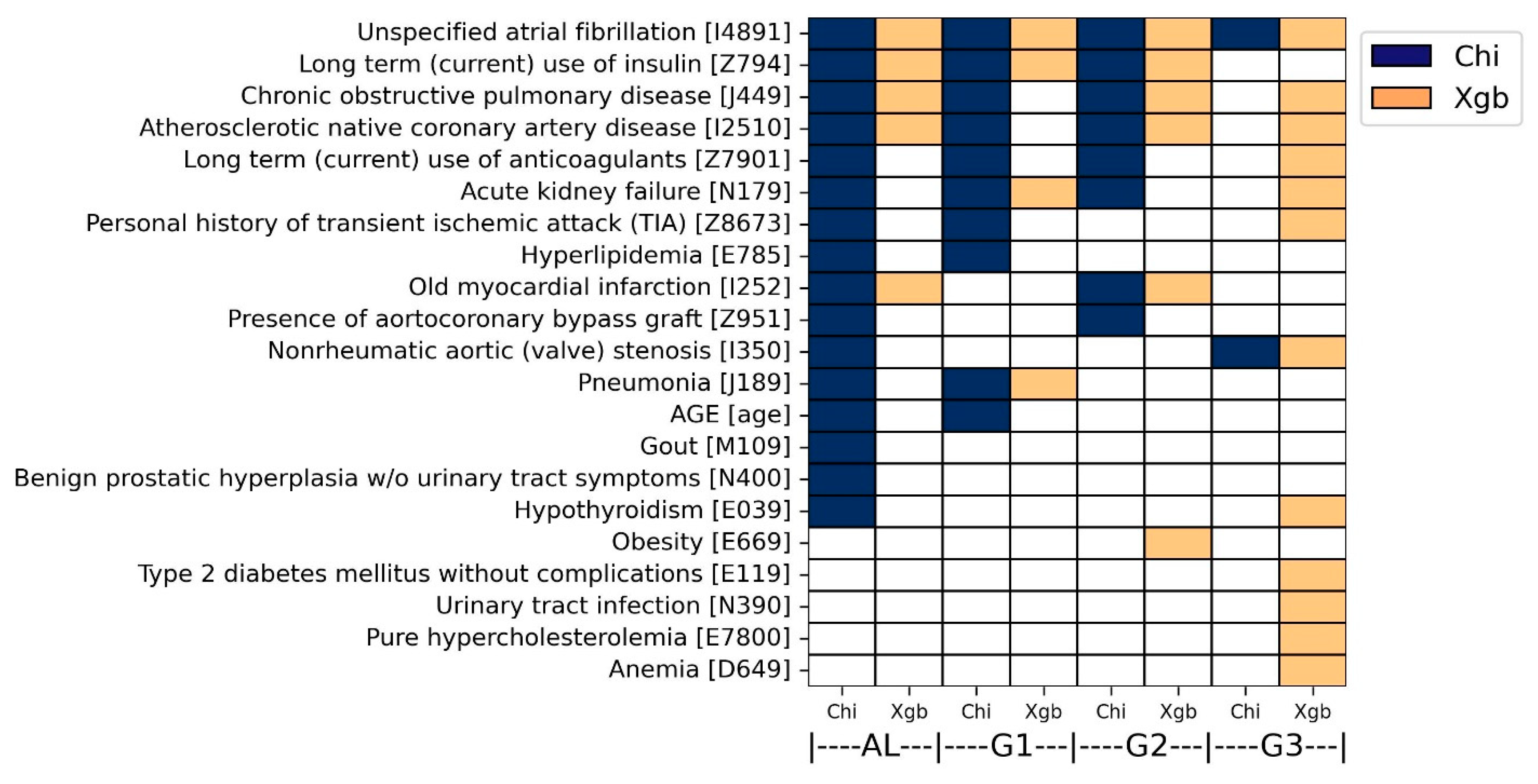
For each analytical method, predictive factors consistently characterized across both ICD systems were determined as overall predictive factors. This approach will help to reduce false positives and increase accuracy. Hence, each of the four subgroups possessed two sets of the overall predictive factors derived from chi-squared test and XGBoost modeling. To this end, the ICD-9 codes were converted to ICD-10 codes with the help of an online conversion program (
https://www.icd10data.com/Convert accessed on 22 May 2024).
As a result, 21 overall predictive factors were finally characterized by both analyses. More specifically, in the chi-square analysis, 16, 10, 8, and 2 predictive factors were commonly identified in AL, G1, G2, and G3 groups, respectively (colored dark blue in
Figure 6). Atrial fibrillation (ICD-10: I4891) was determined by both ICD systems in all four groups. In addition, five diseases were determined by both ICD systems in three groups, including acute kidney failure (ICD-10: N179), atherosclerotic native coronary artery disease (ICD-10: I2510), long-term use of anticoagulants (ICD-10: Z7901), long-term use of insulin (ICD-10: Z794), and chronic obstructive pulmonary disease (ICD-10: J449).
In the XGBoost analysis, 5, 4, 6, and 12 predictive factors were commonly identified in AL, G1, G2, and G3 groups, respectively (colored orange in
Figure 6). Atrial fibrillation (ICD-10: I4891) was determined by both ICD systems in all four groups. In addition, three diseases were determined by both ICD systems in three groups: chronic obstructive pulmonary disease (ICD-10: J449), atherosclerotic native coronary artery disease (ICD-10: I2510), and long-term use of insulin (ICD-10: Z794). The overall predictive factors are also described in
Table S8.
4. Evaluation
The overall predictive factors were assessed by exploring the evidence in the literature. Firstly, atrial fibrillation, selected from all four groups, is known to be one of the diseases that promotes the formation of blood clots in the atria [
22], which is a well-known factor that contributes to HF by impairing blood flow [
23]. The use of anticoagulants is part of the treatment to reduce blood clots, rather than a cause of HF. Transient ischemic attack can also occur due to blood clot formation, similar to HF, rather than being a predictive factor for heart failure [
24].
Similar to blood clots, elevated levels of lipids or glucose in the bloodstream can cause arteries to narrow and harden, impairing blood flow to the heart muscles [
25]. Among the overall predictive factors associated with this phenomenon are hyperlipidemia, hypercholesterolemia, diabetes, and the use of insulin.
Several medical conditions related to weakened heart function have been identified as predictive factors, including coronary artery disease (CAD), coronary bypass graft surgery, and aortic valve stenosis. Coronary arteries are blood vessels that supply oxygen and nutrients to the heart muscles, and CAD is a disease that causes a narrowing of the coronary arteries. Thus, CAD can weaken the heart muscles, which may lead to HF [
26]. One of the methods of treating blocked or narrowed arteries is to bypass the blockage using a piece of healthy blood vessel from somewhere else in the body, which is called coronary artery bypass graft surgery [
27]. In addition, aortic value stenosis is a disease in which the opening of the aortic valve narrows, restricting blood flow from the left ventricle to the aorta. It causes the heart’s left ventricle to pump harder to push blood through the narrowed aortic valve, which may lead to HF if not treated properly [
28].
We also found evidence in the literature claiming that kidney failure causes HF. Dhingra’s group revealed that kidney disease places men at a higher risk of developing HF, even without diabetes or high blood pressure [
29]. Hyperuricemia (although not included in the list of the overall predictive factors) is one of the links between kidney failure and HF. Reduced uric acid excretion due to kidney disease can lead to hyperuricemia, which is an elevated level of uric acid in the blood [
30]. Subsequently, elevated uric acid levels are known to be one of the risk factors for HF [
31,
32]. Gout, identified as one of the overall predictive factors, also represents a prominent symptom associated with elevated levels of uric acid [
33].
Evidence in the literature for other risk factors such as pneumonia and anemia is also available. Regarding the relationship between pneumonia and HF, Eurich et al.’s group showed that pneumonia significantly increases the risk of HF across a range of ages and severity of cases, which is the same consequence as that found in this study [
34]. We also found research papers reporting the relationship between anemia and HF. It is known that anemia is one of the common comorbidities that often coexists in patients with heart failure, and is associated with poor clinical outcomes. Despite many studies on the relationship between HF and anemia, it is not entirely clear whether anemia is merely an indicator of HF severity or a mediator of HF progression [
35,
36]. The results of this study allow us to consider the possibility that anemia acts as one of the causes of HF.
5. Discussion and Conclusions
The objective of this study is to identify medical histories that could predict the progression of heart failure in patients with hypertension. However, upon analysis, it was observed that many direct predictive factors for heart failure, independent of hypertension, were prominently identified, such as coronary artery disease, kidney failure, hyperlipidemia, and atrial fibrillation. Nevertheless, factors with a less direct association with heart failure, such as pneumonia, hyperthyroidism, and anemia, were also extracted, prompting a consideration of whether these factors elevate the risk of developing heart failure due to hypertension.
The basic strategy is to identify items in a medical history that can predict the progression of disease B in the presence of disease A. In this study, for the purpose of ensuring a stable and robust analysis, disease A was defined as hypertension and disease B was selected as heart failure, given its substantial patient population. However, as hypertension and heart failure are extensively studied diseases, the analysis predominantly revealed well-established results. With the acquisition of more medical data, it would be useful to apply the analysis designed here to other diseases that are less well explored and, hence, more intriguing.
When examining the AUCs of XGBoost models, it can be observed that the overall performance was not strong. One possible reason for the low AUC may be the omission of medical conditions occurring after hypertension, which may be crucial information for the onset of heart failure. Only medical history recorded before hypertension diagnosis was utilized for the purpose of this study, which is to identify the predictive factors at the point of hypertension diagnosis.
We believe that adding dietary habit data and analyzing it comprehensively could be a beneficial research strategy. In addition, incorporating hypertension treatment data will also further strengthen this research. Specifically, utilizing the treatment data to examine cohorts receiving appropriate treatment for hypertension alongside those not receiving such treatment would enable a more targeted analysis. We anticipate that these data will be well constructed and effectively leveraged in the future.
In this investigation, we uncovered predictive factors of heart failure progression in hypertensive patients, utilizing medical diagnosis data from the MIMIC-IV database. Employing two analytical methodologies, chi-squared tests and XGBoost modeling, we generated age-specific and ICD system-specific predictive factors. Ultimately, our investigation unveiled 21 overall predictive factors. We anticipate that these findings will provide valuable insights for the risk assessment of heart failure in hypertensive patients.
Supplementary Materials
The following supporting information can be downloaded at:
https://www.mdpi.com/article/10.3390/bioengineering11060531/s1, Figure S1: Basic statistics of the preprocessing data for patients using the ICD-10 system; Figure S2: The boxplots of APRs (Average Precision Rate) of the 1000 trained XGBoost models; Table S1: ICD codes associated to heart failure; Table S2: The selected features for analysis process (ICD9); Table S3: The selected features for analysis process (ICD10); Table S4: The predictive factors by chi-square tests (ICD9); Table S5: The predictive factors by chi-square tests (ICD10); Table S6: The predictive factors by XGBoost modeling (ICD9); Table S7: The predictive factors by XGBoost modeling (ICD10); Table S8: The 21 overall predictive factors.
Author Contributions
J.J.: Conceptualization, supervision, investigation, methodology, writing (original draft), writing (review and editing), funding acquisition. D.K.: Data curation, resources, software, literature search. I.H.: Data curation, visualization, software, literature search. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by a National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT) (NRF-2022R1C1C1008823), and by the research grant of The University of Suwon in 2023.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that might affect the research reported in this paper.
References
- Mills, K.T.; Stefanescu, A.; He, J. The global epidemiology of hypertension. Nat. Rev. Nephrol. 2020, 16, 223–237. [Google Scholar] [CrossRef] [PubMed]
- Emmons-Bell, S.; Johnson, C.; Roth, G. Prevalence, incidence and survival of heart failure: A systematic review. Heart 2022, 108, 1351–1360. [Google Scholar] [CrossRef]
- Messerli, F.H.; Rimoldi, S.F.; Bangalore, S. The transition from hypertension to heart failure: Contemporary update. JACC Heart Fail. 2017, 5, 543–551. [Google Scholar] [CrossRef] [PubMed]
- Khatibzadeh, S.; Farzadfar, F.; Oliver, J.; Ezzati, M.; Moran, A. Worldwide risk factors for heart failure: A systematic review and pooled analysis. Int. J. Cardiol. 2013, 168, 1186–1194. [Google Scholar] [CrossRef] [PubMed]
- Update, A.S. Heart disease and stroke statistics–2017 update. Circulation 2017, 135, e146–e603. [Google Scholar]
- Nkomo, V.T.; Gardin, J.M.; Skelton, T.N.; Gottdiener, J.S.; Scott, C.G.; Enriquez-Sarano, M. Burden of valvular heart diseases: A population-based study. Lancet 2006, 368, 1005–1011. [Google Scholar] [CrossRef] [PubMed]
- UKPDS, U. The incidence of congestive heart failure in type 2 diabetes. Diabetes Care 2004, 27, 1879–1884. [Google Scholar]
- Kenchaiah, S.; Evans, J.C.; Levy, D.; Wilson, P.W.; Benjamin, E.J.; Larson, M.G.; Kannel, W.B.; Vasan, R.S. Obesity and the risk of heart failure. N. Engl. J. Med. 2002, 347, 305–313. [Google Scholar] [CrossRef]
- UK, N.A.-A.; Atherton, J.J.; Bauersachs, J.; UK, A.J.C.; Carerj, S.; Ceconi, C.; Coca, A.; UK, P.E.; Erol, Ç.; Ezekowitz, J. 2016 ESC Guidelines for the diagnosis and treatment of acute and chronic heart failure. Eur. Heart J. 2016, 37, 2129–2200. [Google Scholar]
- Meng, C.; Trinh, L.; Xu, N.; Enouen, J.; Liu, Y. Interpretability and fairness evaluation of deep learning models on MIMIC-IV dataset. Sci. Rep. 2022, 12, 7166. [Google Scholar] [CrossRef]
- Liu, W.; Tao, G.; Zhang, Y.; Xiao, W.; Zhang, J.; Liu, Y.; Lu, Z.; Hua, T.; Yang, M. A simple weaning model based on interpretable machine learning algorithm for patients with sepsis: A research of MIMIC-IV and eICU databases. Front. Med. 2022, 8, 814566. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.; Bulgarelli, L.; Pollard, T.; Horng, S.; Celi, L.A.; Mark, R. Mimic-iv. PhysioNet. Available online: https://physionet.org/content/mimiciv/1.0/ (accessed on 23 August 2021).
- Johnson, A.E.; Bulgarelli, L.; Shen, L.; Gayles, A.; Shammout, A.; Horng, S.; Pollard, T.J.; Hao, S.; Moody, B.; Gow, B. MIMIC-IV, a freely accessible electronic health record dataset. Sci. Data 2023, 10, 1. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; He, Z.; Ren, J.; Wu, Y. Prediction model of in-hospital mortality in intensive care unit patients with cardiac arrest: A retrospective analysis of MIMIC-IV database based on machine learning. BMC Anesthesiol. 2023, 23, 178. [Google Scholar] [CrossRef]
- Pang, K.; Li, L.; Ouyang, W.; Liu, X.; Tang, Y. Establishment of ICU Mortality Risk Prediction Models with Machine Learning Algorithm Using MIMIC-IV Database. Diagnostics 2022, 12, 1068. [Google Scholar] [CrossRef] [PubMed]
- Kao, H.-Y.; Chang, C.-C.; Chang, C.-F.; Chen, Y.-C.; Cheewakriangkrai, C.; Tu, Y.-L. Associations between sex and risk factors for predicting chronic kidney disease. Int. J. Environ. Res. Public Health 2022, 19, 1219. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wu, J.; Liu, S.; Li, M.; Hu, K.; Li, K. Predicting mortality of patients with acute kidney injury in the ICU using XGBoost model. PLoS ONE 2021, 16, e0246306. [Google Scholar] [CrossRef] [PubMed]
- Chang, W.; Liu, Y.; Xiao, Y.; Yuan, X.; Xu, X.; Zhang, S.; Zhou, S. A machine-learning-based prediction method for hypertension outcomes based on medical data. Diagnostics 2019, 9, 178. [Google Scholar] [CrossRef]
- Jung, J.; Yoo, S. Identification of Breast Cancer Metastasis Markers from Gene Expression Profiles Using Machine Learning Approaches. Genes 2023, 14, 1820. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, M.; He, Y.; Zhang, L.; Zou, J.; Yan, Y.; Guo, Y. Predicting the risk of incident type 2 diabetes mellitus in Chinese elderly using machine learning techniques. J. Pers. Med. 2022, 12, 905. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ames, A.; Stevenson, W.G. Catheter ablation of atrial fibrillation. Circulation 2006, 113, e666–e668. [Google Scholar] [CrossRef]
- Goh, F.Q.; Kong, W.K.; Wong, R.C.; Chong, Y.F.; Chew, N.W.; Yeo, T.-C.; Sharma, V.K.; Poh, K.K.; Sia, C.-H. Cognitive impairment in heart failure—A review. Biology 2022, 11, 179. [Google Scholar] [CrossRef] [PubMed]
- Tutwiler, V.; Peshkova, A.D.; Andrianova, I.A.; Khasanova, D.R.; Weisel, J.W.; Litvinov, R.I. Contraction of blood clots is impaired in acute ischemic stroke. Arterioscler. Thromb. Vasc. Biol. 2017, 37, 271–279. [Google Scholar] [CrossRef] [PubMed]
- Velagaleti, R.S.; Massaro, J.; Vasan, R.S.; Robins, S.J.; Kannel, W.B.; Levy, D. Relations of lipid concentrations to heart failure incidence: The Framingham Heart Study. Circulation 2009, 120, 2345–2351. [Google Scholar] [CrossRef] [PubMed]
- Velagaleti, R.S.; Vasan, R.S. Heart failure in the twenty-first century: Is it a coronary artery disease or hypertension problem? Cardiol. Clin. 2007, 25, 487–495. [Google Scholar] [CrossRef] [PubMed]
- Abu-Omar, Y.; Taggart, D.P. Coronary artery bypass surgery. Medicine 2014, 42, 527–531. [Google Scholar] [CrossRef]
- Lindman, B.R.; Lindenfeld, J. Prevention and mitigation of heart failure in the treatment of calcific aortic stenosis: A unifying therapeutic principle. JAMA Cardiol. 2021, 6, 993–994. [Google Scholar] [CrossRef] [PubMed]
- Dhingra, R.; Gaziano, J.M.; Djoussé, L. Chronic kidney disease and the risk of heart failure in men. Circ. Heart Fail. 2011, 4, 138–144. [Google Scholar] [CrossRef] [PubMed]
- Johnson, R.J.; Lozada, L.G.S.; Lanaspa, M.A.; Piani, F.; Borghi, C. Uric acid and chronic kidney disease: Still more to do. Kidney Int. Rep. 2023, 8, 229–239. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Huang, B.; Li, Y.; Huang, Y.; Li, J.; Yao, H.; Jing, X.; Chen, J.; Wang, J. Uric acid and risk of heart failure: A systematic review and meta-analysis. Eur. J. Heart Fail. 2014, 16, 15–24. [Google Scholar] [CrossRef]
- Wei, X.; Zhang, M.; Huang, S.; Lan, X.; Zheng, J.; Luo, H.; He, Y.; Lei, W. Hyperuricemia: A key contributor to endothelial dysfunction in cardiovascular diseases. FASEB J. 2023, 37, e23012. [Google Scholar] [CrossRef]
- Kutzing, M.K.; Firestein, B.L. Altered uric acid levels and disease states. J. Pharmacol. Exp. Ther. 2008, 324, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Eurich, D.T.; Marrie, T.J.; Minhas-Sandhu, J.K.; Majumdar, S.R. Risk of heart failure after community acquired pneumonia: Prospective controlled study with 10 years of follow-up. BMJ 2017, 356, j413. [Google Scholar] [CrossRef] [PubMed]
- Anand, I.S.; Gupta, P. Anemia and iron deficiency in heart failure: Current concepts and emerging therapies. Circulation 2018, 138, 80–98. [Google Scholar] [CrossRef] [PubMed]
- Grote Beverborg, N.; van Veldhuisen, D.J.; van der Meer, P. Anemia in heart failure: Still relevant? JACC Heart Fail. 2018, 6, 201–208. [Google Scholar] [CrossRef] [PubMed]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}