


BioDiffusion: A Versatile Diffusion Model for Biomedical Signal Synthesis

Abstract
1. Introduction
- Presentation of the BioDiffusion model, our innovative diffusion-based probabilistic approach tailored to address the complexities inherent in biomedical signal generation.
- Demonstration of our model’s versatility in handling diverse generation tasks, presenting a unified solution to biomedical signal synthesis.
- Comprehensive evaluation of the BioDiffusion model through both qualitative and quantitative metrics, underscoring its effectiveness and precision.
- Comparative analysis highlighting the superior capability of BioDiffusion in biomedical signal synthesis relative to existing state-of-the-art models.
2. Related Work
2.1. Generative Models in Signal Synthesis
- Generative Adversarial Networks (GANs): Composed of two adversarial networks— the generator and the discriminator—GANs aim for the generator to improve its synthetic data samples to deceive the discriminator. Their capabilities extend to various data types including time-series signals. Notable implementations include the transformer-based GAN by Xiaomin L. et al. [6] which sets a benchmark for synthetic time-series signal fidelity, TimeGAN by Jinsung Y. et al. [7] tailoring GANs for realistic time-series data, and the Recurrent Conditional GAN (RCGAN) by Cristóbal E. et al. [8] for time-series generation. Despite their proficiency in crafting realistic samples, GANs can exhibit training instability and suffer from mode collapse.
- Variational Autoencoders (VAEs): VAEs, through their encoder–decoder architecture, learn a probabilistic representation of data. Works such as that by Vincent F. et al. [9] exploit VAEs for imputing missing multivariate time-series values, while Fu et al. [10] leverage VAEs for augmenting time-series in human activity recognition. VAEs offer more consistent training than GANs but may produce less diverse samples, contingent on latent space distribution choices.
- Autoregressive Models: These models sequentially generate samples, with each new element contingent on prior elements. WaveNet by Aaron van den Oord et al. [11] exemplifies this, producing raw audio waveforms using dilated causal convolutions for long-range temporal relationship capture. Although proficient in modeling temporal dynamics, their sequential nature can be computationally slow and may falter in grasping extended dependencies.
- Other generative paradigms like Normalizing Flows, Restricted Boltzmann Machines, and Non-negative Matrix Factorization have been explored. However, their efficacy diminishes with multidimensional non-stationary time-series signals.
2.2. Diffusion Models for Time-Series Synthesis
- Yang L. et al.’s comprehensive discourse on deep learning-based diffusion models and their applicability to time-series tasks [12].
- Garnier O. et al. augmenting diffusion models for infinite-dimensional spaces, targeting audio signals and time series [14].
- Alcaraz et al.’s pursuit of time-series forecasting using diffusion models [17].
3. Diffusion Probabilistic Models
4. Methodology
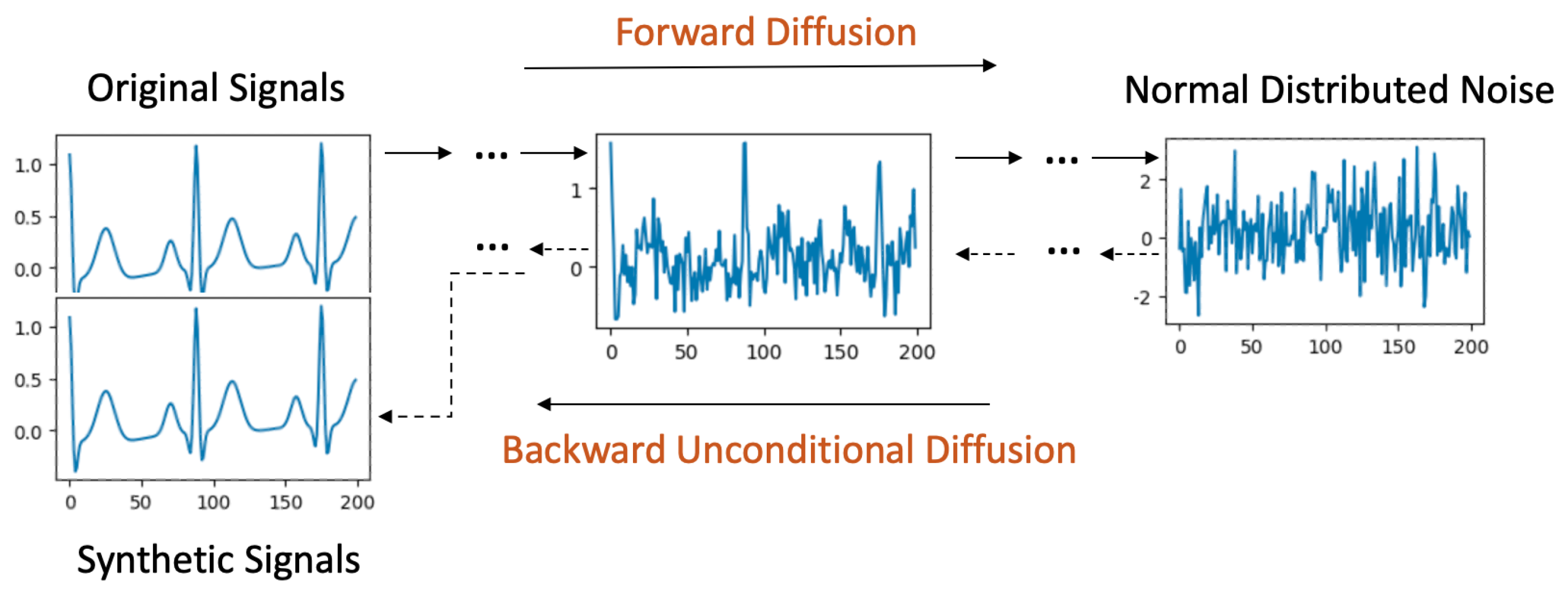
4.1. Unconditional Diffusion Models
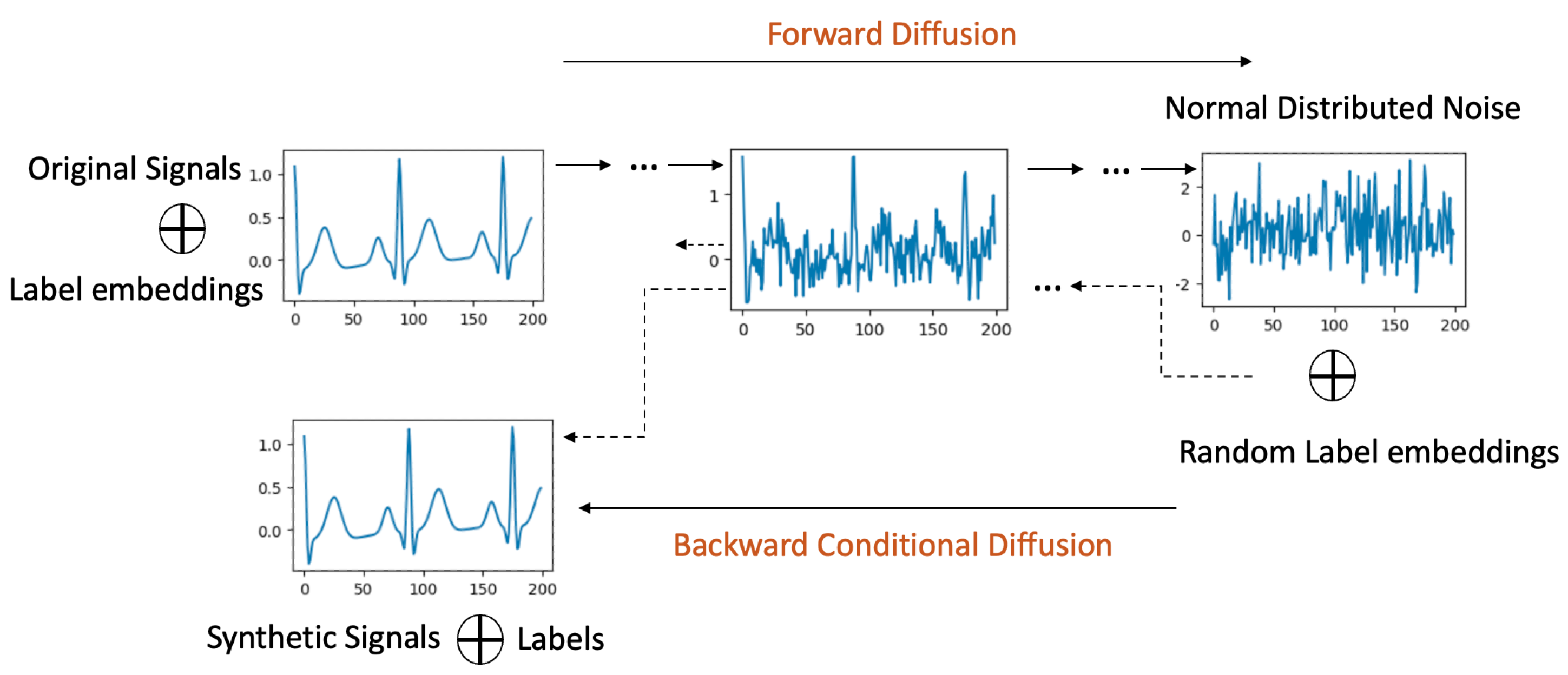
4.2. Label-Conditional Diffusion Models
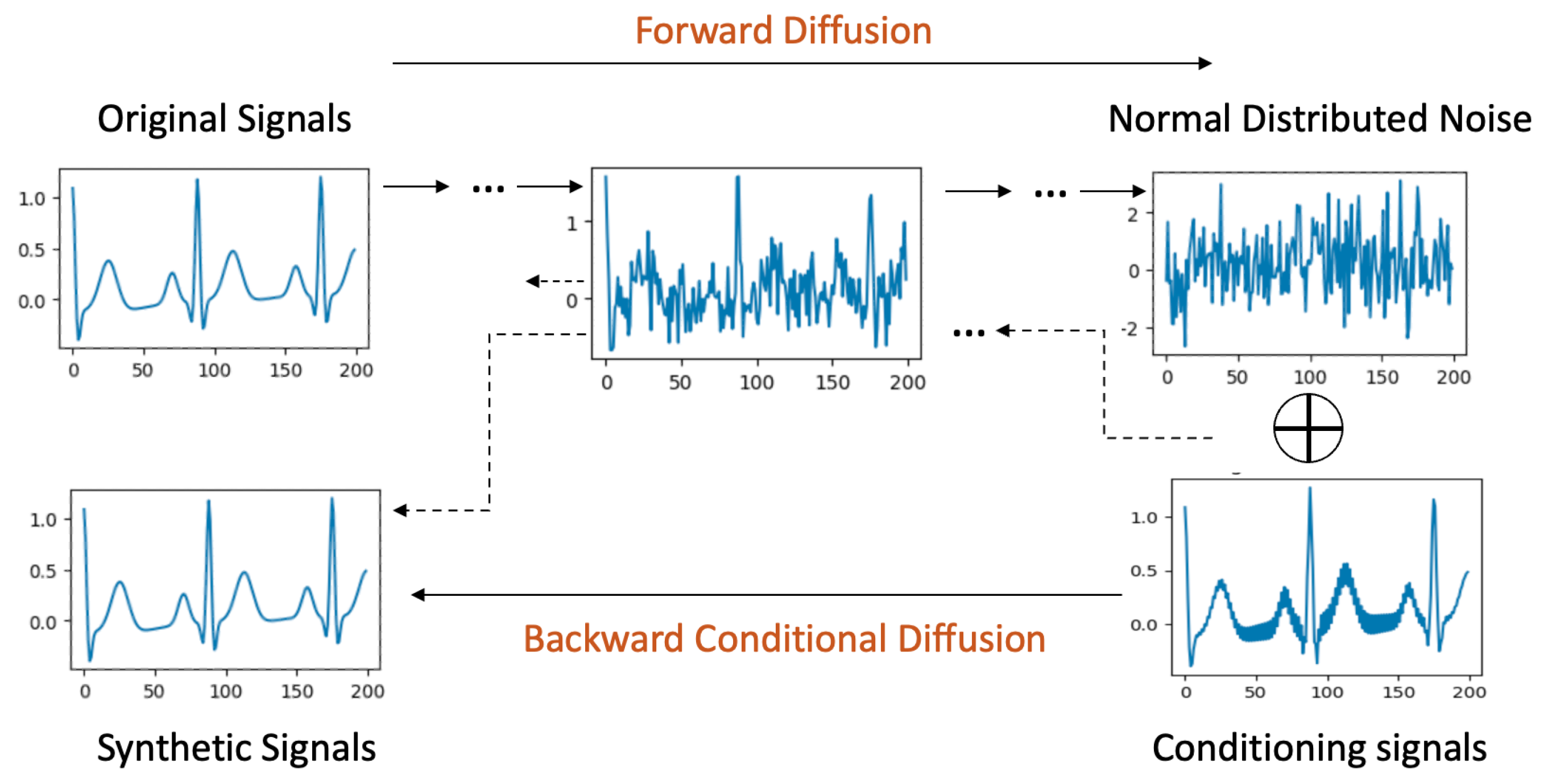
4.3. Signal-Conditional Diffusion Models
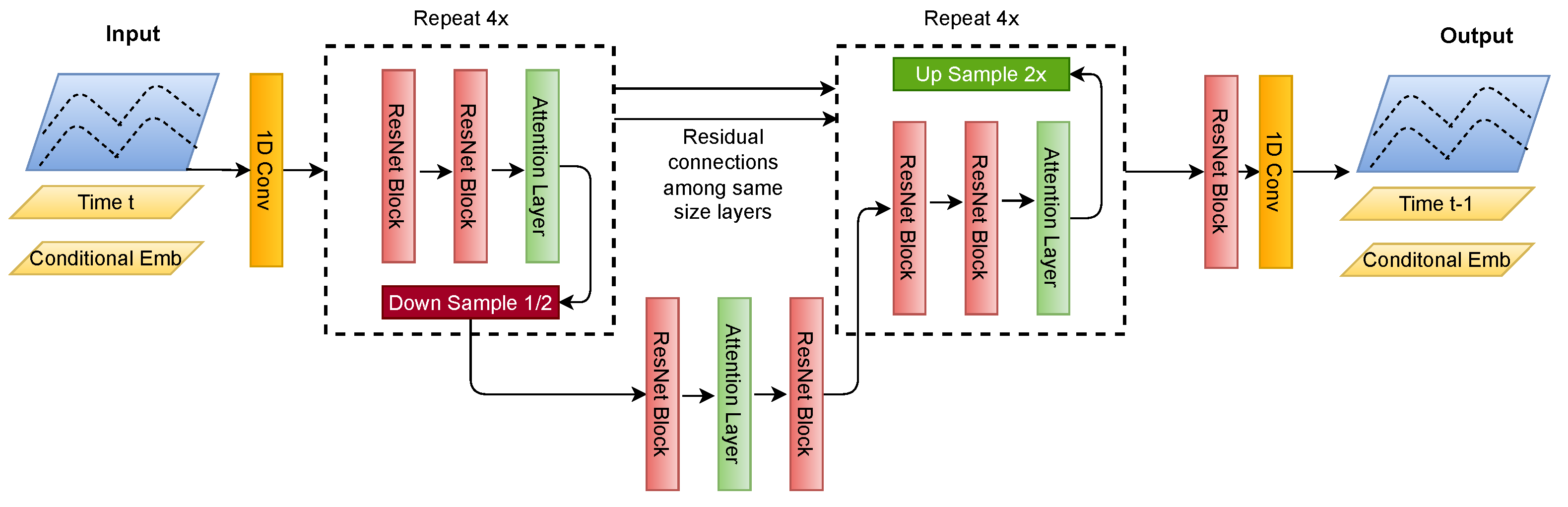
4.4. U-Net Architecture
4.5. Synthetic Sisnals Validation Metrics
4.5.1. Wavelet Coherence Score
4.5.2. Discriminative Score
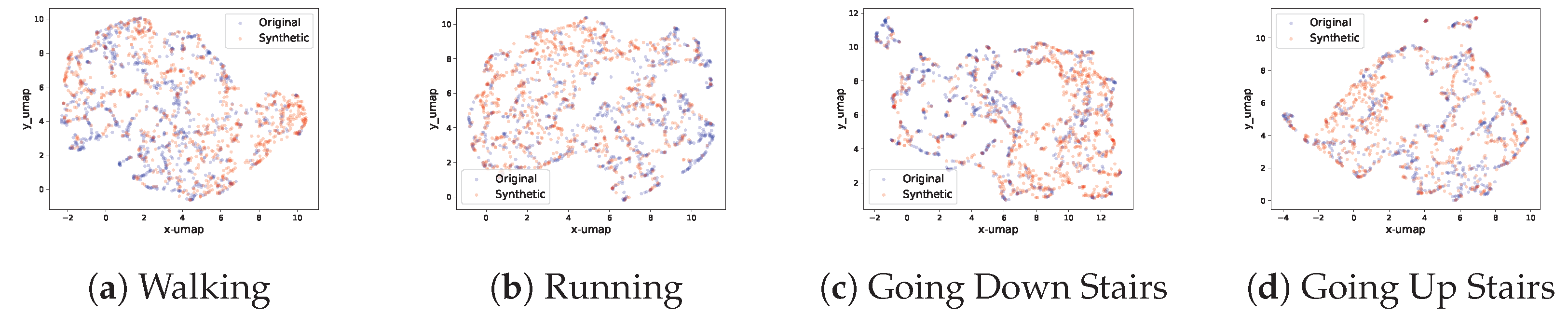
4.5.3. Umap Visualizations for Qualitative Signal Similarity Comparison
- Preparation of Signal Data: Flattening of both real set and synthetic set of signals into feature vectors.
- Dimensionality Reduction: Application of UMAP to reduce the high-dimensional feature space of each signal set to a two-dimensional (2D) embedding.
- Visualization: Plotting of the UMAP embeddings of both signal sets in the same coordinate system. Then, observation of the overlap and distribution of the two sets in the reduced space. Clusters of points from different sets that co-locate in the embedding space indicate a higher similarity.
4.5.4. F1-Score for Imbalanced Dataset Classification Performance Evaluation
5. Experimental Results
5.1. Datasets
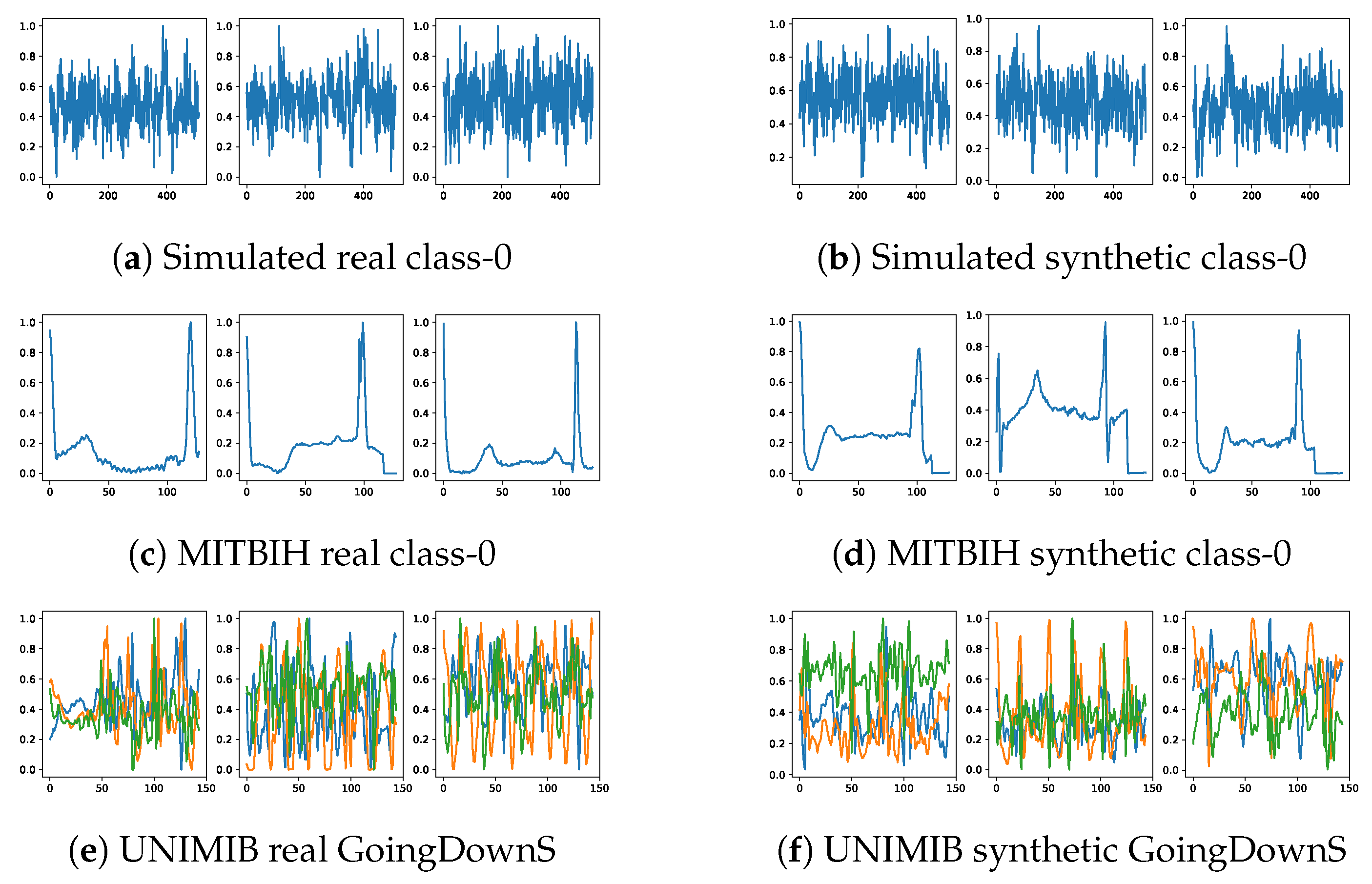
- The Simulated dataset is a synthetic dataset with different signal patterns. These synthetic patterns are created using a combination of bell, funnel, and cylinder shapes. The dataset is generated for five classes, each with different characteristics, which are determined by their parameters. The parameters can be average amplitude, variance amplitude, variance pattern, etc. Each signal has 512 timesteps and one channel dimension. We can choose them to be any length and any dimension. Each class of signals in this dataset is evenly distributed. We use this dataset to test whether the diffusion model can learn the signal patterns properly before learning on more complicated, imbalanced real-world datasets.
- The UniMiB Dataset [24] is gathered using smartwatches; this dataset contains nine human activity classes with each signal capturing 151 timesteps across three acceleration dimensions. Adapted to our U-Net architecture, signals are resized to 128 timesteps. The training set contains 6055 samples, with class distributions that peak at 1572 and trough at 119 samples per class. The test set has 1524 samples, ranging from 32 to 413 samples per class, highlighting the dataset’s imbalance.
- The MIT-BIH Arrhythmia Dataset features 48 snippets of ambulatory ECG recordings spanning half an hour each from 47 subjects across five heart conditions [25,26]. The samples, originally recorded at 125 Hz, are adjusted to 144 in length for U-Net compatibility. The training set has 87,554 samples, with the majority class having 72,471 samples and the smallest class having 641. The test set includes 21,892 samples, ranging from 162 to 18118 samples per class, again underlining the dataset’s imbalance.
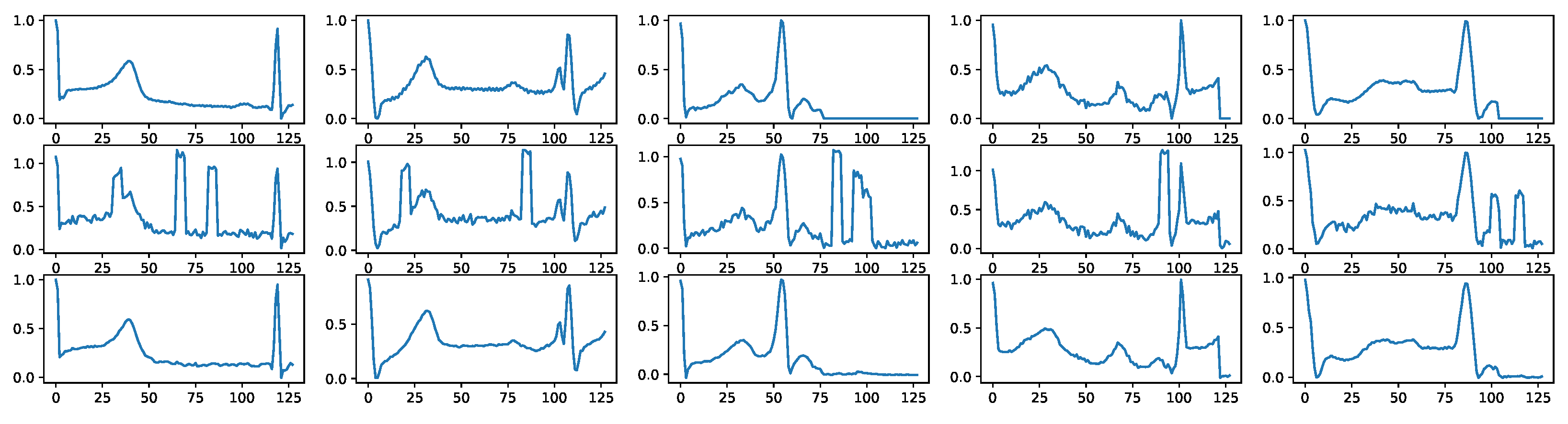
5.2. Visualization of Raw Signals
5.3. Projection through Dimension Reduction
5.4. Similarity Scores
- C-RNN-GAN: A pioneering GAN-based solution for sequential data synthesis using two-layer LSTM for both generator and discriminator [27].
- RCWGAN: An enhanced version of C-RNN-GAN with conditional data input for controlled generation [8].
- TimeGAN: A groundbreaking GAN framework that harnesses a latent space for time-series synthesis, augmented with both supervised and unsupervised losses [7].
- SigCWGAN: Enhances the GAN process with conditional data and the Wasserstein loss for stable training [28].
- TTS-GAN: A novel transformer-centric GAN model focusing on high-fidelity single-class time-series generation [6].
- TTS-CGAN: An iterative version of TTS-GAN introducing a label-conditional transformer GAN, facilitating multi-class synthesis through a singular model [29].
5.5. Utility of Synthetic Signals in Addressing Class Imbalance
5.6. Biodiffusion in Biomedical Signal Denoising, Imputation, and Upsampling
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Dataset Details

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Signal Type | N Channels | Type | Total Samples | Classes | Class Ratio | Sample Length |
|---|---|---|---|---|---|---|---|
| Simulated | Simulated signals | 1 | Train | 20,000 | 5 | 1:1:1:1:1 | 512 |
| 1 | Test | 2000 | 5 | 1:1:1:1:1 | 512 | ||
| UNIMIB | Accelerometer signals | 3 | Train | 6055 | 9 | 119:169:1394: 1572:737:600: 1068:228:168 | 128 |
| 3 | Test | 1524 | 9 | 34:47:344: 413:184:146: 256:68:32 | 128 | ||
| MITBIH | ECG signals | 1 | Train | 87,554 | 5 | 72,471:2223: 5788:641:6431 | 144 |
| 1 | Test | 21,892 | 5 | 18,118:556: 1448:162:1608 | 144 |
Appendix B. Training Details
| Architecture | Training | Diffusion |
|---|---|---|
| Base channels: 64 | Optimizer: Adam | Timesteps: 1000 |
| Channel multipliers: 1, 2, 4, 8, 8 (Simulated Dataset) | Batch size: 32 | Noise schedule: cosine |
| Channel multipliers: 1, 2, 4, 8 (UNIMIB and MITBIH) | Learning rate: 3 × 10−4 | Loss: l1 |
| Residual blocks groups: 8 | Epochs: 100 | |
| Attention heads: 4 | Hardware: NVIDIA RTX A5000 |
| Architecture | Training | Diffusion |
|---|---|---|
| Base dimensions: 64 | Optimizer: Adam | Diffusion timesteps: 1000 |
| Channel multipliers: 1, 2, 4, 8, 8 (Simulated Dataset) | Batch size: 32 | Noise schedule: cosine |
| Channel multipliers: 1, 2, 4, 8 (UNIMIB and MITBIH) | Learning rate: 3 × 10−4 | Loss: l1 |
| Number classes: 5 (Simulated and MITBIH dataset) | Epochs: 100 | |
| Number classes: 9 (UNIMIB dataset) | Hardware: NVIDIA GeForce 1080 | |
| Residual blocks groups: 8 | ||
| Attention heads: 4 | ||
| Conditional drop prob: 0.5 |
| Architecture | Training | Diffusion |
|---|---|---|
| Base channels: 64 | Optimizer: Adam | Timesteps: 2000 |
| Channel multipliers: 1, 2, 4, 8, 8 | Batch size: 32 | Noise schedule: linear |
| Residual blocks groups: 2 | Learning rate: 1 × 10−4 | Loss: l1 |
| Attention heads: 4 | Iterations: 1,000,000 | |
| Hardware: NVIDIA GeForce 1080 |
Appendix C. More Visualizations about Label-Conditional Generation


Appendix D. More Visualizations about Signal-Conditional Generation
Appendix D.1. Signal Denoising
- Thermal noise, also known as white noise, a type of random electrical noise that occurs in electronic circuits and arises from the thermal agitation of electrons, which results in a fluctuation of the voltage or current that is independent of the signal being measured.
- Electrode contact noise, also known as low-frequency drift, a type of noise that arises in electronic measurements due to changes in the electrical characteristics of the contact between the electrode and the surface being measured, which can cause fluctuations in the baseline signal over time.
- Motion artifacts, also known as random spikes, unwanted signals that can occur in physiological or biological measurements due to movement or other physical disturbances, which can cause sudden, brief spikes in the recorded signal that are not related to the underlying biological activity being measured.


Appendix D.2. Signal Imputation
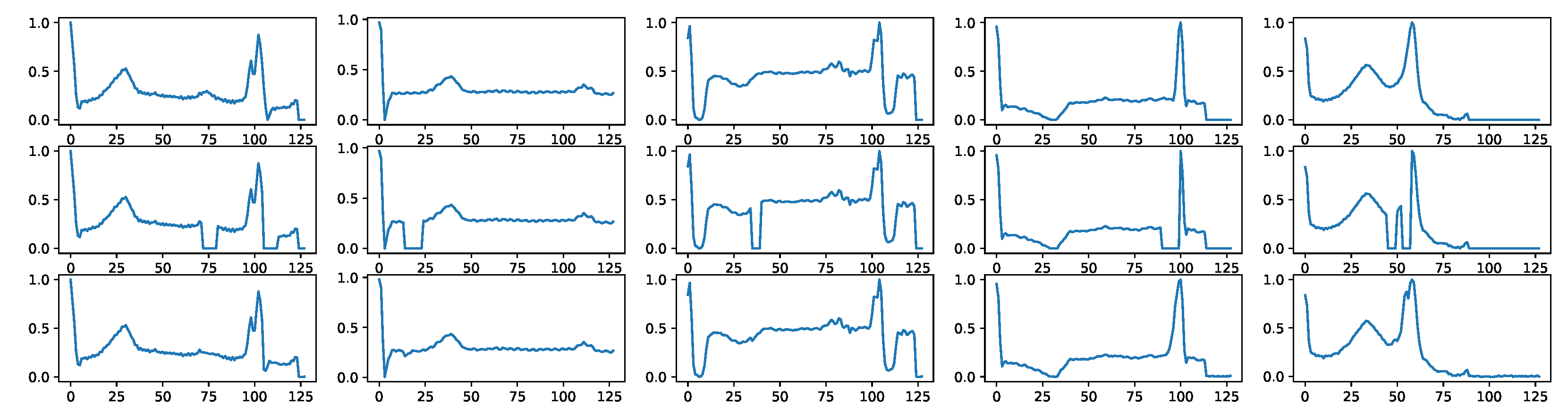
Appendix D.3. Signal Super-Resolution
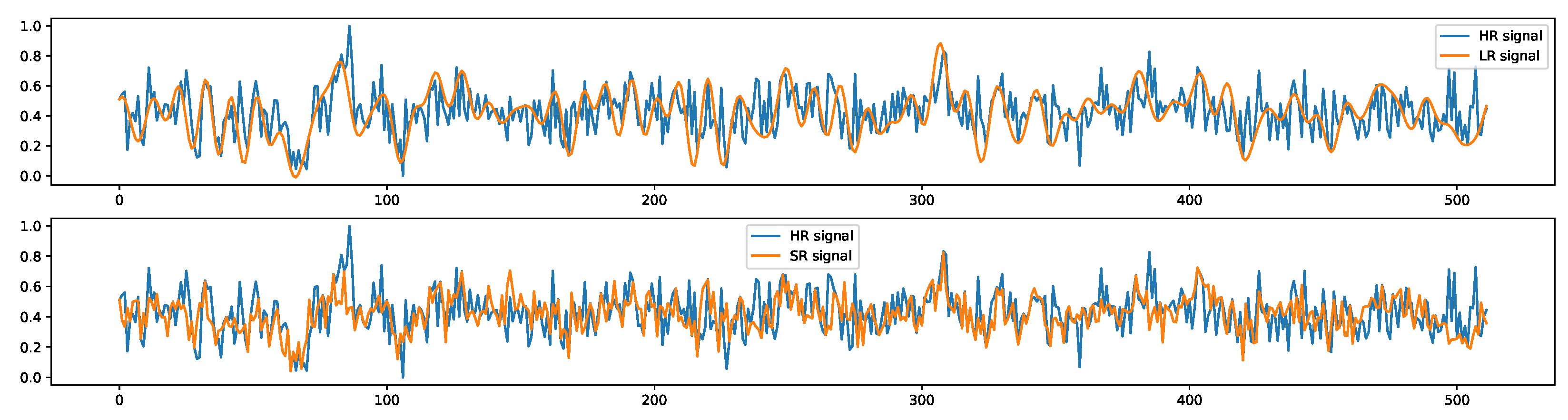
Appendix D.4. Individual Signal Generation

References
- Kachuee, M.; Fazeli, S.; Sarrafzadeh, M. Ecg heartbeat classification: A deep transferable representation. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York, NY, USA, 4–7 June 2018; pp. 443–444. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef] [PubMed]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv 2021, arXiv:2112.10752. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Li, X.; Metsis, V.; Wang, H.; Ngu, A.H.H. Tts-gan: A transformer-based time-series generative adversarial network. In Proceedings of the Artificial Intelligence in Medicine: 20th International Conference on Artificial Intelligence in Medicine, AIME 2022, Halifax, NS, Canada, 14–17 June 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 133–143. [Google Scholar]
- Yoon, J.; Jarrett, D.; Van der Schaar, M. Time-series generative adversarial networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (medical) time series generation with recurrent conditional gans. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Fortuin, V.; Rätsch, G.; Mandt, S. Multivariate time series imputation with variational autoencoders. arXiv 2019, arXiv:1907.04155. [Google Scholar]
- Fu, B.; Kirchbuchner, F.; Kuijper, A. Data Augmentation for Time Series: Traditional vs. Generative Models on Capacitive Proximity Time Series. In Proceedings of the 13th ACM International Conference on PErvasive Technologies Related to Assistive Environments, New York, NY, USA, 30 June–3 July 2020. PETRA ’20. [Google Scholar] [CrossRef]
- Oord, A.V.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Yang, L.; Zhang, Z.; Song, Y.; Hong, S.; Xu, R.; Zhao, Y.; Zhang, W.; Cui, B.; Yang, M.H. Diffusion Models: A Comprehensive Survey of Methods and Applications. arXiv 2022, arXiv:2209.00796. [Google Scholar] [CrossRef]
- Available online: https://www.unite.ai/diffusion-models-in-ai-everything-you-need-to-know/ (accessed on 5 March 2024).
- Garnier, O.; Rotskoff, G.M.; Vanden-Eijnden, E. Diffusion Generative Models in Infinite Dimensions. arXiv 2023, arXiv:2212.00886. [Google Scholar]
- Kong, Z.; Ping, W.; Huang, J.; Zhao, K.; Catanzaro, B. Diffwave: A versatile diffusion model for audio synthesis. arXiv 2020, arXiv:2009.09761. [Google Scholar]
- Tashiro, Y.; Song, J.; Song, Y.; Ermon, S. CSDI: Conditional score-based diffusion models for probabilistic time series imputation. Adv. Neural Inf. Process. Syst. 2021, 34, 24804–24816. [Google Scholar]
- Alcaraz, J.M.L.; Strodthoff, N. Diffusion-based time series imputation and forecasting with structured state space models. arXiv 2022, arXiv:2208.09399. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 2256–2265. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Ganguly, A.; Earp, S.W. An Introduction to Variational Inference. arXiv 2021, arXiv:2108.13083. [Google Scholar]
- Song, Y.; Ermon, S. Improved techniques for training score-based generative models. Adv. Neural Inf. Process. Syst. 2020, 33, 12438–12448. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Saharia, C.; Ho, J.; Chan, W.; Salimans, T.; Fleet, D.J.; Norouzi, M. Image super-resolution via iterative refinement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4713–4726. [Google Scholar] [CrossRef]
- Micucci, D.; Mobilio, M.; Napoletano, P. UniMiB SHAR: A Dataset for Human Activity Recognition Using Acceleration Data from Smartphones. Appl. Sci. 2017, 7, 1101. [Google Scholar] [CrossRef]
- Moody, G.B.; Mark, R.G. The impact of the MIT-BIH arrhythmia database. IEEE Eng. Med. Biol. Mag. 2001, 20, 45–50. [Google Scholar] [CrossRef]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed]
- Mogren, O. C-RNN-GAN: Continuous recurrent neural networks with adversarial training. arXiv 2016, arXiv:1611.09904. [Google Scholar]
- Ni, H.; Szpruch, L.; Wiese, M.; Liao, S.; Xiao, B. Conditional sig-wasserstein gans for time series generation. arXiv 2020, arXiv:2006.05421. [Google Scholar] [CrossRef]
- Li, X.; Ngu, A.H.H.; Metsis, V. TTS-CGAN: A Transformer Time-Series Conditional GAN for Biosignal Data Augmentation. arXiv 2022, arXiv:2206.13676. [Google Scholar]


| Symbol | Description |
|---|---|
| Original data point | |
| q | Forward diffusion process transaction kernel |
| T | Total number of iterations in the forward process |
| t | Specific iteration step in the forward and reverse processes |
| Data point at iteration t | |
| The general notation for the Gaussian distribution of x with the mean and the covariance | |
| Variance schedule parameter at iteration t | |
| Identity matrix | |
| p | Reverse diffusion process transaction kernel |
| Mean of the reverse process distribution at time t | |
| Covariance of the reverse process distribution at time t | |
| Loss function for the diffusion model parameterized by | |
| Expectation of the reverse process q | |
| Kullback–Leibler divergence | |
| Mean of the reverse process at time t, parameterized by | |
| Diagonal covariance matrix of the reverse process at time t, parameterized by | |
| Variance accumulation parameter at iteration t | |
| Cumulative product of from time 1 to t | |
| Adjusted variance schedule parameter at iteration t | |
| c | Set of conditions or additional information provided externally |
| Reverse diffusion process of given and conditions c, parameterized by |
| Wavelet Coherence score (the higher the better) | ||||
| Models | SittingDown | Jumping | Non-Ectopic | FusionBeats |
| C-RNN-GAN | 41.10 | 40.29 | 30.44 | 25.51 |
| RCWGAN | 39.90 | 38.85 | 29.72 | 22.97 |
| TimeGAN | 40.45 | 39.42 | 31.55 | 21.98 |
| SigCWGAN | 41.60 | 41.02 | 31.36 | 22.87 |
| TTS-GAN | 43.92 | 47.64 | 45.30 | 55.64 |
| TTS-CGAN | 45.07 | 47.64 | 47.79 | 58.34 |
| BioDiffusion | 78.17 | 90.30 | 89.30 | 91.81 |
| Discriminative score (the lower the better) | ||||
| Models | SittingDown | Jumping | Non-Ectopic | FusionBeats |
| C-RNN-GAN | 0.308 | 0.304 | 0.189 | 0.493 |
| RCWGAN | 0.294 | 0.311 | 0.483 | 0.499 |
| TimeGAN | 0.261 | 0.217 | 0.464 | 0.312 |
| SigCWGAN | 0.310 | 0.308 | 0.413 | 0.491 |
| TTS-GAN | 0.294 | 0.167 | 0.107 | 0.380 |
| TTS-CGAN | 0.191 | 0.057 | 0.162 | 0.261 |
| BioDiffusion | 0.126 | 0.121 | 0.159 | 0.231 |
| N | A | V | Q | F | Average | |
|---|---|---|---|---|---|---|
| Imbalanced | 0.97 | 0.25 | 0.75 | 0.38 | 0.89 | 0.648 |
| Re-sampling | 0.50 | 0.65 | 0.64 | 0.81 | 0.85 | 0.69 |
| TimeGAN | 0.60 | 0.48 | 0.75 | 0.48 | 0.93 | 0.648 |
| SigCWGAN | 0.59 | 0.60 | 0.80 | 0.58 | 0.93 | 0.7 |
| TTS-GAN | 0.60 | 0.77 | 0.75 | 0.60 | 0.91 | 0.726 |
| TTS-CGAN | 0.66 | 0.78 | 0.77 | 0.85 | 0.93 | 0.798 |
| BioDiffusion | 0.73 | 0.79 | 0.86 | 0.84 | 0.95 | 0.834 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Sakevych, M.; Atkinson, G.; Metsis, V. BioDiffusion: A Versatile Diffusion Model for Biomedical Signal Synthesis. Bioengineering 2024, 11, 299. https://doi.org/10.3390/bioengineering11040299
Li X, Sakevych M, Atkinson G, Metsis V. BioDiffusion: A Versatile Diffusion Model for Biomedical Signal Synthesis. Bioengineering. 2024; 11(4):299. https://doi.org/10.3390/bioengineering11040299
Chicago/Turabian StyleLi, Xiaomin, Mykhailo Sakevych, Gentry Atkinson, and Vangelis Metsis. 2024. "BioDiffusion: A Versatile Diffusion Model for Biomedical Signal Synthesis" Bioengineering 11, no. 4: 299. https://doi.org/10.3390/bioengineering11040299
APA StyleLi, X., Sakevych, M., Atkinson, G., & Metsis, V. (2024). BioDiffusion: A Versatile Diffusion Model for Biomedical Signal Synthesis. Bioengineering, 11(4), 299. https://doi.org/10.3390/bioengineering11040299