
Concurrent Learning Approach for Estimation of Pelvic Tilt from Anterior–Posterior Radiograph


 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
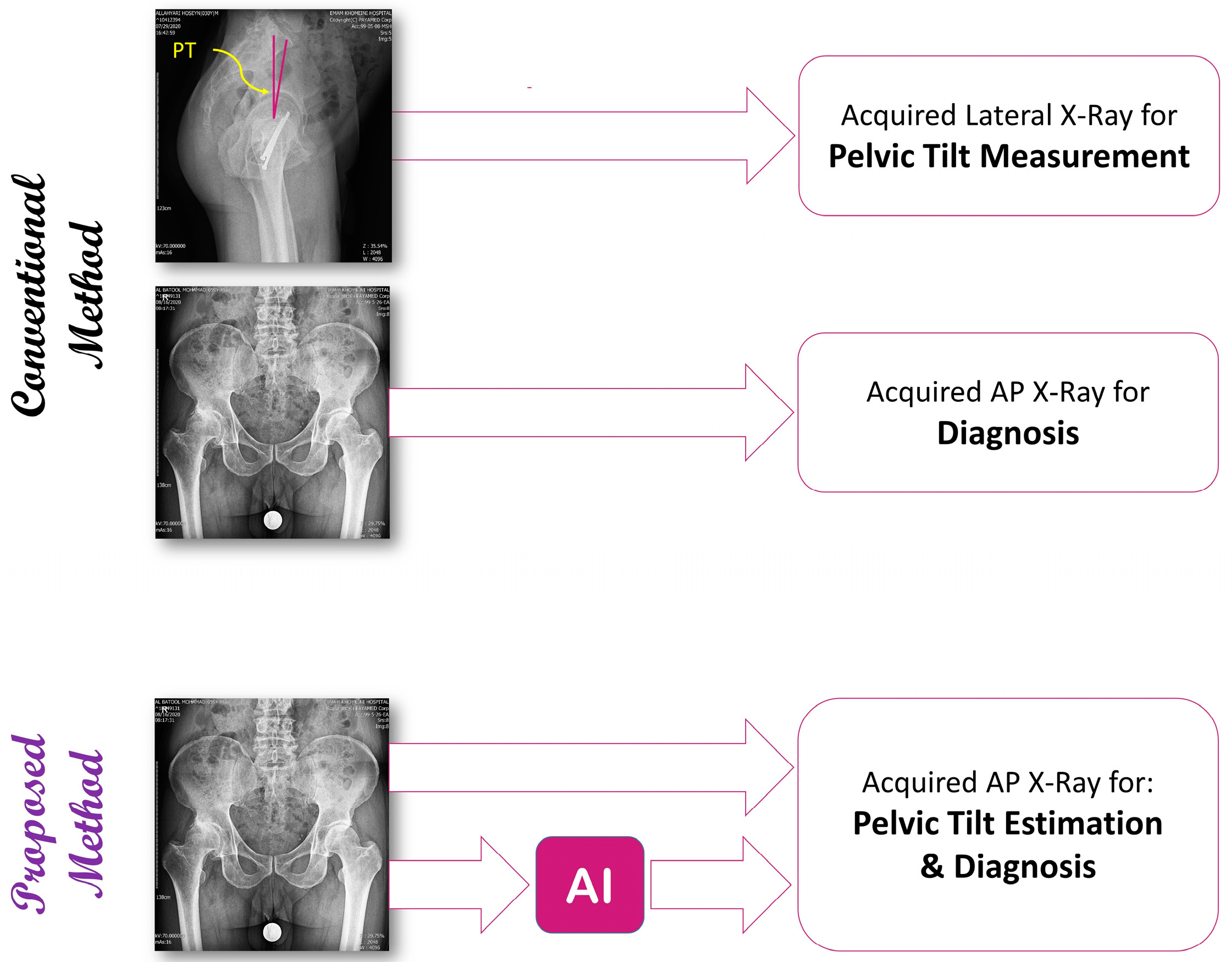
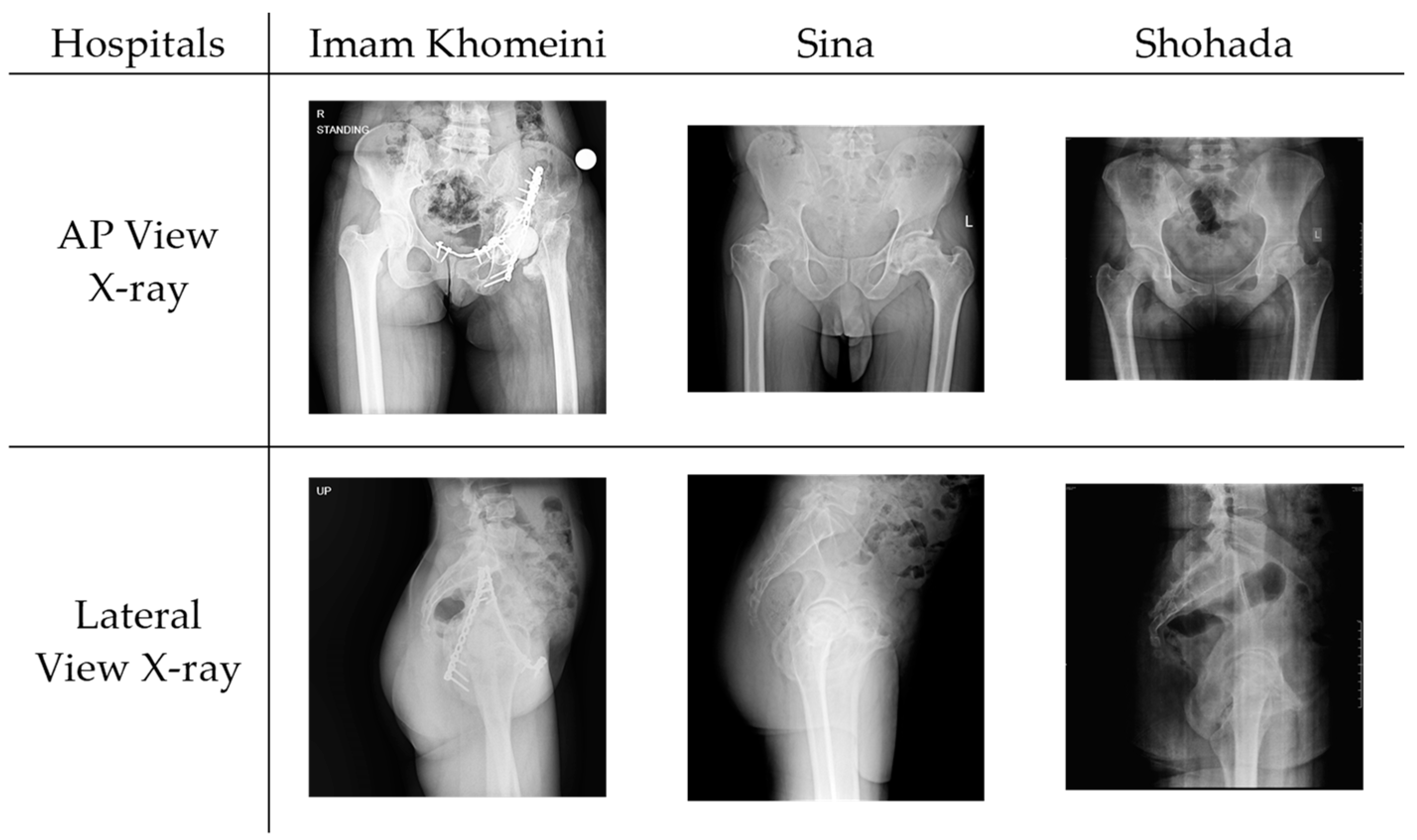
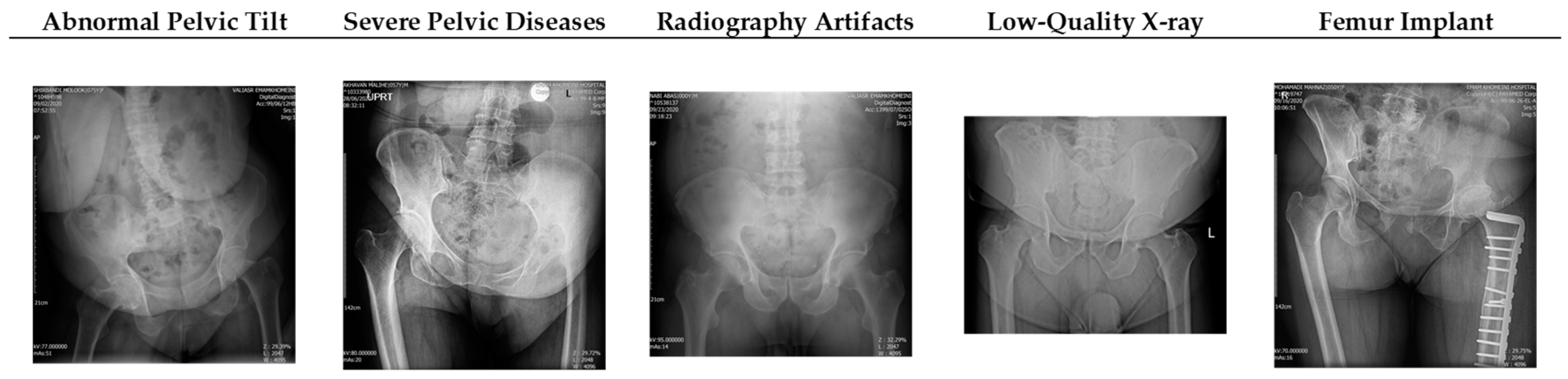
2.1. Dataset Acquisition and Preparation
- Age: The mean age of the patients is 41.8 years, with a standard deviation of 14.1.
- Gender: The dataset is approximately evenly distributed, with 54.4% male patients.
- Pelvic tilt (PT): The mean pelvic tilt is 3.47, with a standard deviation of 3.10.
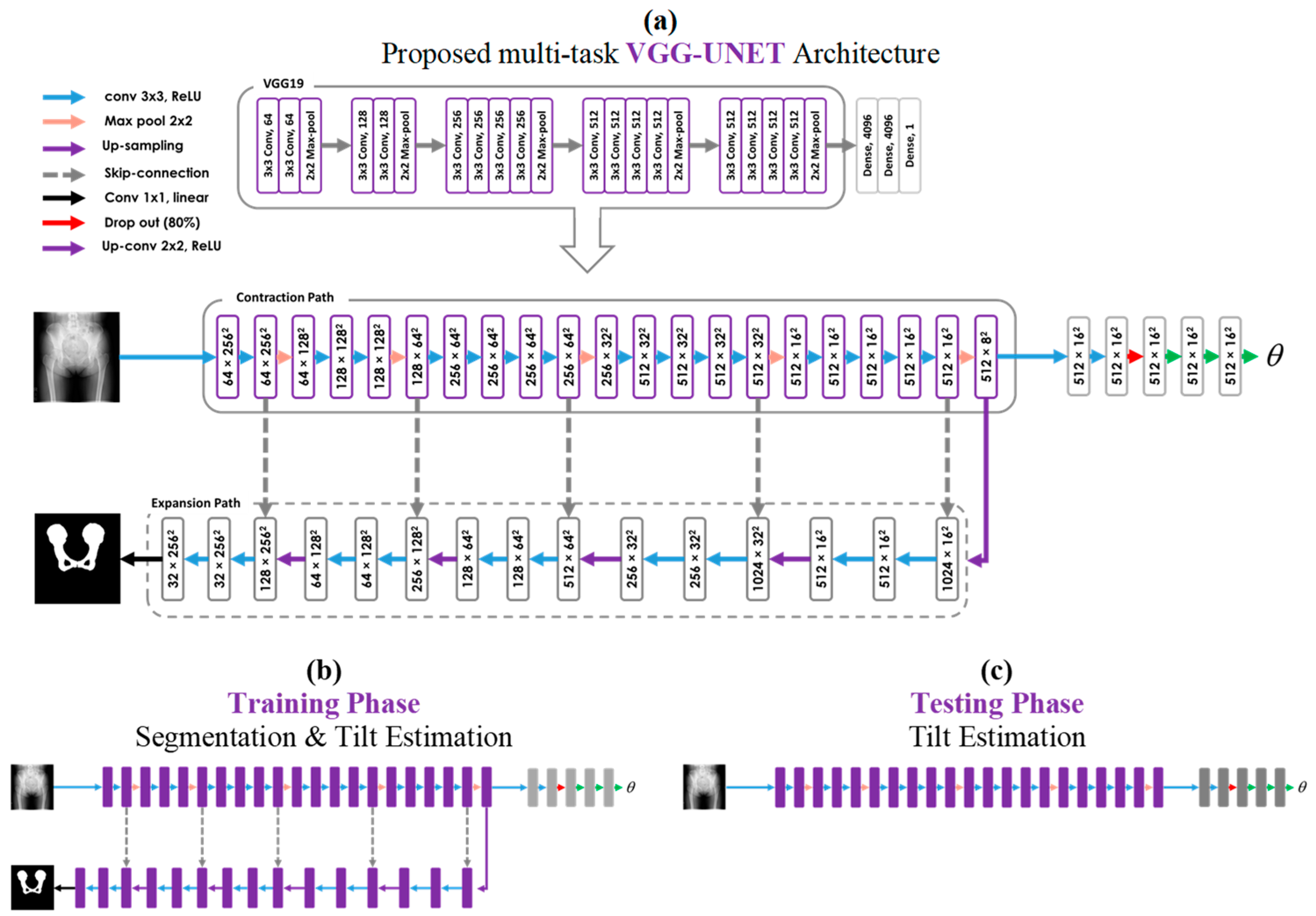
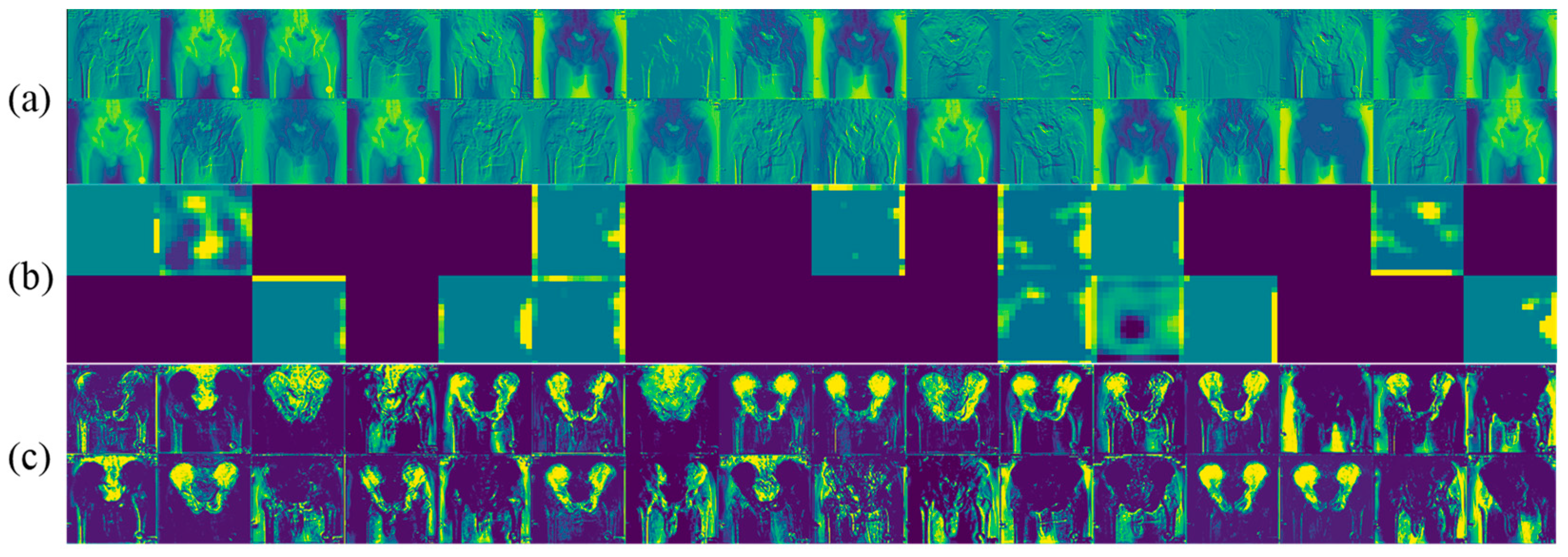
2.2. Segmentation Network
2.3. VGG Architecture
2.4. Proposed Multi-Task Learning Model
Multi-Task Training and Single-Task Testing Strategy
3. Experiments
3.1. Evaluation Metrics
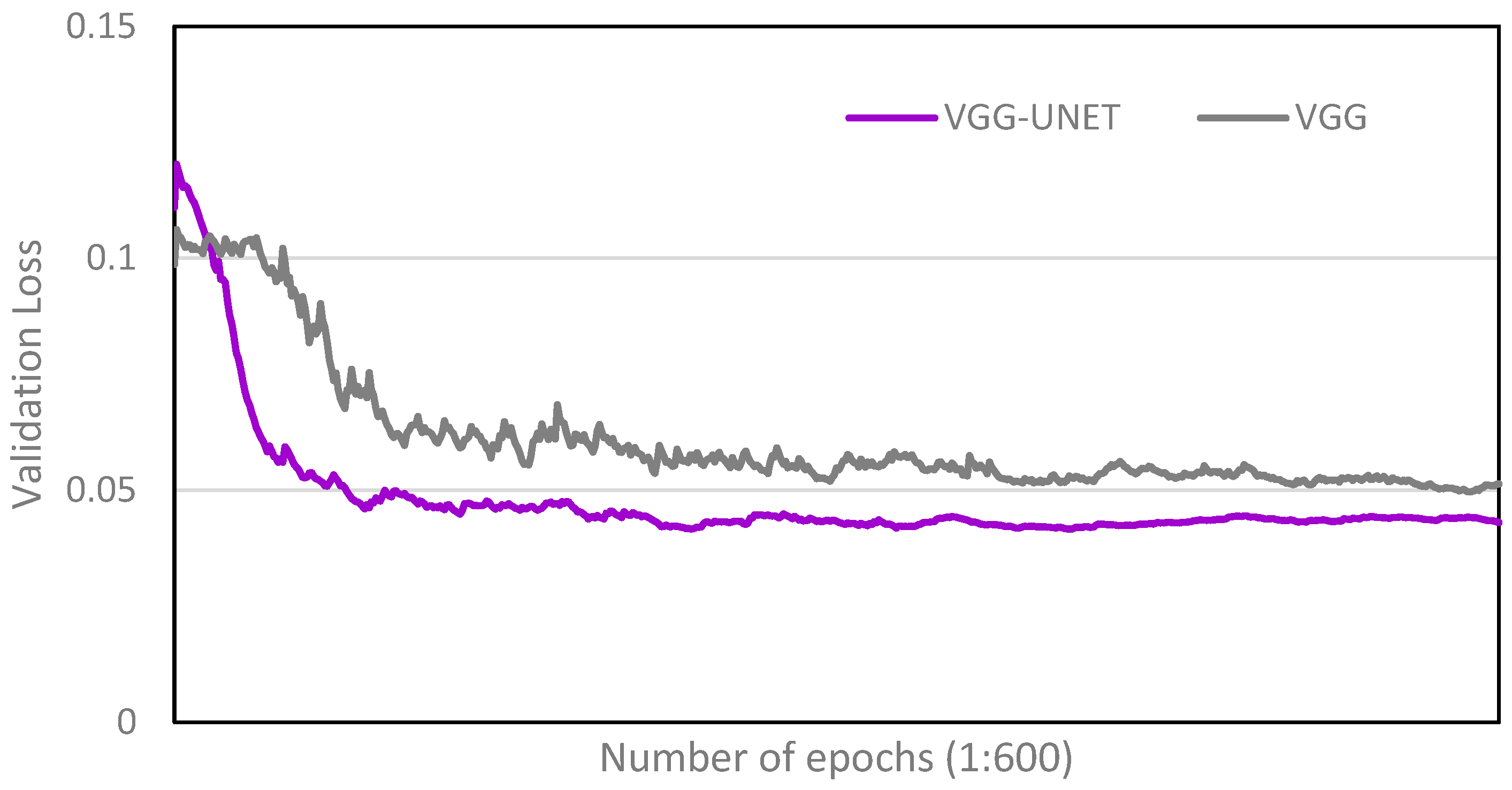
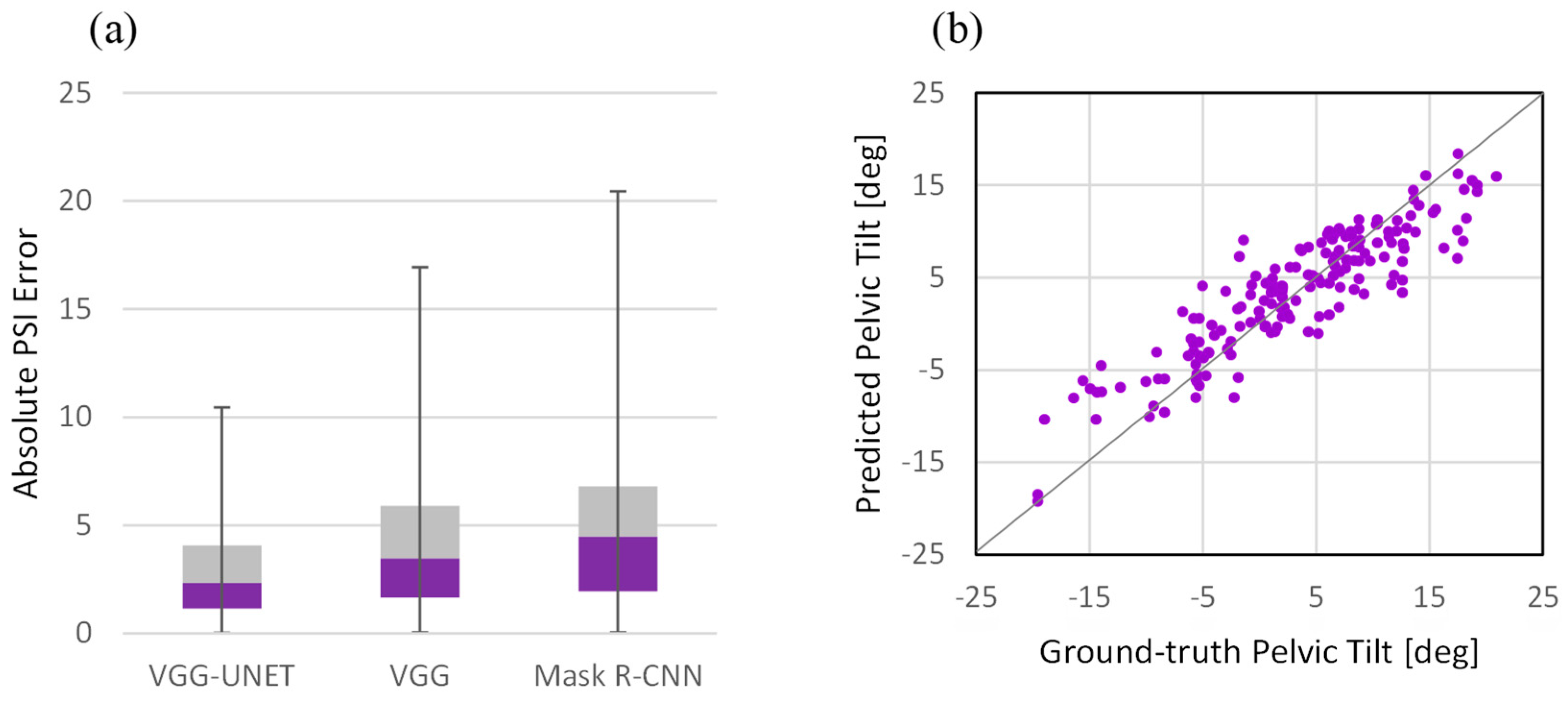
3.2. Performance Analysis
- Single-task network with learning only on the target task (VGG): The proposed network for use in the test phase, which consists of a VGG network and a light-weight convolutional network on top, was used for both training and testing. Regardless of segmentation, a deep network was used for direct learning to see if segmentation as a secondary task could be beneficial.
- Cascaded networks with independent learning (Mask R-CNN): This experiment is meant to compare the proposed method with the state-of-the-art method [14] for PT estimation from a single radiography image. It has been shown that employing the Mask R-CNN instead of the standard U-Net for pelvic segmentation improves efficiency in terms of the Dice coefficient. So firstly, the Mask R-CNN framework was employed to segment the pelvic shape from the background in the radiography images. Then, following the segmentation network, another convolutional network regressed the PT angle. All networks’ structures and hyper-parameters were set according to the original paper. For convenience, we refer to the cascaded network as its segmentation network name, i.e., Mask R-CNN.
4. Results and Discussion
4.1. Comparison with Single-Task Network
4.2. Performance Analysis
4.3. Comparison with Surgeon Specialists
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hasegawa, K.; Okamoto, M.; Hatsushikano, S.; Shimoda, H.; Ono, M.; Homma, T.; Watanabe, K. Standing sagittal alignment of the whole axial skeleton with reference to the gravity line in humans. J. Anat. 2017, 230, 619–630. [Google Scholar] [CrossRef]
- Bhaskar, D.; Rajpura, A.; Board, T. Current Concepts in Acetabular Positioning in Total Hip Arthroplasty. Indian. J. Orthop. 2017, 51, 386. [Google Scholar] [CrossRef]
- Kennedy, J.G.; Rogers, W.B.; Soffe, K.E.; Sullivan, R.J.; Griffen, D.G.; Sheehan, L.J. Effect of acetabular component orientation on recurrent dislocation, pelvic osteolysis, polyethylene wear, and component migration. J. Arthroplast. 1998, 13, 530–534. [Google Scholar] [CrossRef]
- Roussouly, P.; Gollogly, S.; Berthonnaud, E.; Dimnet, J. Classification of the normal variation in the sagittal alignment of the human lumbar spine and pelvis in the standing position. Spine 2005, 30, 346–353. [Google Scholar] [CrossRef]
- Lewinnek, G.E.; Lewis, J.L.; Tarr, R.; Compere, C.L.; Zimmerman, J.R. Dislocations after total hip-replacement arthroplasties. J. Bone Jt. Surg. Am. 1978, 60, 217–220. [Google Scholar] [CrossRef]
- Le Huec, J.C.; Aunoble, S.; Philippe, L.; Nicolas, P. Pelvic parameters: Origin and significance. Eur. Spine J. 2011, 20 (Suppl. S5), 564–571. [Google Scholar] [CrossRef] [PubMed]
- Widmer, K.H. A simplified method to determine acetabular cup anteversion from plain radiographs. J. Arthroplast. 2004, 19, 387–390. [Google Scholar] [CrossRef] [PubMed]
- Wan, Z.; Malik, A.; Jaramaz, B.; Chao, L.; Dorr, L.D. Imaging and navigation measurement of acetabular component position in THA. Clin. Orthop. Relat. Res. 2009, 467, 32–42. [Google Scholar] [CrossRef] [PubMed]
- Babisch, J.W.; Layher, F.; Amiot, L.P. The rationale for tilt-adjusted acetabular cup navigation. J. Bone Jt. Surg. Am. 2008, 90, 357–365. [Google Scholar] [CrossRef] [PubMed]
- Blondel, B.; Schwab, F.; Patel, A.; Demakakos, J.; Moal, B.; Farcy, J.P.; Lafage, V. Sacro-femoral-pubic angle: A coronal parameter to estimate pelvic tilt. Eur. Spine J. 2012, 21, 719–724. [Google Scholar] [CrossRef] [PubMed]
- Ranawat, C.S.; Ranawat, A.S.; Lipman, J.D.; White, P.B.; Meftah, M. Effect of Spinal Deformity on Pelvic Orientation from Standing to Sitting Position. J. Arthroplast. 2016, 31, 1222–1227. [Google Scholar] [CrossRef] [PubMed]
- Tyrakowski, M.; Yu, H.; Siemionow, K. Pelvic incidence and pelvic tilt measurements using femoral heads or acetabular domes to identify centers of the hips: Comparison of two methods. Eur. Spine J. 2015, 24, 1259–1264. [Google Scholar] [CrossRef] [PubMed]
- Jodeiri, A.; Zoroofi, R.A.; Takao, M.; Hiasa, Y.; Sato, Y.; Otake, Y.; Uemura, K.; Sugano, N. Estimation of Pelvic Sagital Inclanation from Anteroposterior Radiograph Using Convolutional Neural Networks: Proof-of-Concept Study. In CAOS 2018. The 18th Annual Meeting of the International Society for Computer Assisted Orthopaedic Surgery; EasyChair Publications: Manchester, UK, 2018; Volume 2, pp. 114–118. [Google Scholar] [CrossRef]
- Jodeiri, A.; Zoroofi, R.A.; Hiasa, Y.; Takao, M.; Sugano, N.; Sato, Y.; Otake, Y. Fully automatic estimation of pelvic sagittal inclination from anterior-posterior radiography image using deep learning framework. Comput. Methods Programs Biomed. 2020, 184, 105282. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Liu, X.; Song, L.; Liu, S.; Zhang, Y. A review of deep-learning-based medical image segmentation methods. Sustainability 2021, 13, 1224. [Google Scholar] [CrossRef]
- Wang, R.; Lei, T.; Cui, R.; Zhang, B.; Meng, H.; Nandi, A.K. Medical image segmentation using deep learning: A survey. IET Image Process. 2022, 16, 1243–1267. [Google Scholar] [CrossRef]
- Krishnamoorthy, S.; Zhang, Y.; Kadry, S.; Yu, W. Framework to segment and evaluate multiple sclerosis lesion in MRI slices using VGG-UNet. Comput. Intell. Neurosci. 2022, 2022, 4928096. [Google Scholar] [CrossRef]
- Arshad, S.; Amjad, T.; Hussain, A.; Qureshi, I.; Abbas, Q. Dermo-Seg: ResNet-UNet Architecture and Hybrid Loss Function for Detection of Differential Patterns to Diagnose Pigmented Skin Lesions. Diagnostics 2023, 13, 2924. [Google Scholar] [CrossRef]
- Duarte, K.T.; Gobbi, D.G.; Sidhu, A.S.; McCreary, C.R.; Saad, F.; Camicioli, R.; Smith, E.E.; Frayne, R. Segmenting white matter hyperintensities in brain magnetic resonance images using convolution neural networks. Pattern Recognit. Lett. 2023, 175, 90–94. [Google Scholar] [CrossRef]
- Geethanjali, T.M.; Minavathi; Dinesh, M.S. Semantic Segmentation of Kidney and Tumors Using LinkNet Models. In International Conference on Cognition and Recongition; Springer: Cham, Switzerland, 2021; pp. 380–389. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Li, L.-J.; Li, K.; Li, F.F.; Deng, J.; Dong, W.; Socher, R.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar] [CrossRef]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016, Athens, Greece, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 424–432. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar] [CrossRef]
- Schwarz, T.; Benditz, A.; Springorum, H.R.; Matussek, J.; Heers, G.; Weber, M.; Renkawitz, T.; Grifka, J.; Craiovan, B. Assessment of pelvic tilt in anteroposterior radiographs by means of tilt ratios. Arch. Orthop. Trauma. Surg. 2018, 138, 1045–1052. [Google Scholar] [CrossRef] [PubMed]
- Malik, A.; Wan, Z.; Jaramaz, B.; Bowman, G.; Dorr, L.D. A validation model for measurement of acetabular component position. J. Arthroplast. 2010, 25, 812–819. [Google Scholar] [CrossRef] [PubMed]
- Pluchon, J.P.; Gérard, R.; Stindel, E.; Lefèvre, C.; Letissier, H.; Dardenne, G. Variations in pelvic tilt during day-to-day activities after total hip arthroplasty measured with an ultrasound system. Orthop. Traumatol. Surg. Res. 2023, 103792. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Absolute Error | R2 Coefficient | Prediction Quality (%) | |||
|---|---|---|---|---|---|---|
| Networks | Accurate | Acceptable | Poor | |||
| VGG-UNET | 3.04 ± 2.49 | 0.80 | 59.4 | 26.7 | 13.9 | |
| ResNet-UNET | 3.22 ± 2.82 | 0.79 | 57.1 | 22.9 | 20.0 | |
| VGG-LinkNet | 3.53 ± 3.01 | 0.78 | 53.6 | 31.2 | 15.2 | |
| ResNet-LinkNet | 3.67 ± 2.52 | 0.78 | 49.7 | 25.6 | 24.7 | |
| VGG | 3.92 ± 2.92 | 0.77 | 46.1 | 28.9 | 25.0 | |
| Mask R-CNN | 4.97 ± 3.87 | 0.77 | 38.3 | 30.6 | 31.1 | |
| Img# | Ground-Truth | Network Prediction | Surgeons’ Prediction | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||||
| 1 | A | (−6.3) | A | (−3.5) | P | U | U | A | A | U | U | U | A | U |
| 2 | A | (−2.8) | A | (−2.8) | A | A | A | A | A | U | U | P | A | A |
| 3 | A | (−9.8) | A | (−10.1) | A | A | U | U | A | A | P | U | A | A |
| 4 | P | (+4.7) | P | (+5.1) | A | P | U | U | P | U | P | U | U | P |
| 5 | A | (−4.2) | A | (−0.2) | P | P | U | P | P | U | P | U | P | P |
| 6 | A | (−14.4) | A | (−10.4) | A | A | A | A | A | A | A | A | A | A |
| 7 | P | (+4.5) | P | (+4.0) | A | U | A | A | A | A | A | A | A | A |
| 8 | P | (+1.2) | P | (+4.9) | A | A | A | A | A | A | A | A | A | A |
| 9 | A | (−5.8) | A | (−2.2) | A | A | A | A | U | A | A | A | U | U |
| 10 | P | (+6.0) | P | (+9.7) | A | A | A | P | U | U | U | U | P | U |
| 11 | A | (−4.9) | A | (−3.7) | A | A | A | A | A | A | A | A | A | A |
| 12 | P | (+6.2) | P | (+10.0) | U | U | P | U | P | U | P | U | P | P |
| 13 | P | (+5.8) | P | (+7.6) | P | P | P | P | P | P | P | P | P | P |
| 14 | P | (+18.0) | P | (+14.5) | P | P | P | P | P | P | P | P | U | U |
| 15 | P | (+5.5) | P | (+8.8) | P | P | P | P | U | P | U | P | P | P |
| 16 | A | (−5.4) | A | (−6.7) | A | A | U | N | U | A | A | U | A | U |
| 17 | P | (+13.6) | P | (+13.5) | P | P | P | U | P | P | P | P | P | P |
| 18 | P | (+11.3) | P | (+10.0) | U | U | P | U | U | U | P | U | U | U |
| 19 | P | (+4.3) | P | (+8.3) | U | U | P | U | U | P | P | U | P | P |
| 20 | P | (+10.3) | P | (+10.7) | P | P | P | P | P | P | U | P | U | U |
| Prediction Accuracy (%) | 100 | 55 | 60 | 60 | 50 | 55 | 55 | 55 | 40 | 60 | 50 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jodeiri, A.; Seyedarabi, H.; Danishvar, S.; Shafiei, S.H.; Sales, J.G.; Khoori, M.; Rahimi, S.; Mortazavi, S.M.J. Concurrent Learning Approach for Estimation of Pelvic Tilt from Anterior–Posterior Radiograph. Bioengineering 2024, 11, 194. https://doi.org/10.3390/bioengineering11020194
Jodeiri A, Seyedarabi H, Danishvar S, Shafiei SH, Sales JG, Khoori M, Rahimi S, Mortazavi SMJ. Concurrent Learning Approach for Estimation of Pelvic Tilt from Anterior–Posterior Radiograph. Bioengineering. 2024; 11(2):194. https://doi.org/10.3390/bioengineering11020194
Chicago/Turabian StyleJodeiri, Ata, Hadi Seyedarabi, Sebelan Danishvar, Seyyed Hossein Shafiei, Jafar Ganjpour Sales, Moein Khoori, Shakiba Rahimi, and Seyed Mohammad Javad Mortazavi. 2024. "Concurrent Learning Approach for Estimation of Pelvic Tilt from Anterior–Posterior Radiograph" Bioengineering 11, no. 2: 194. https://doi.org/10.3390/bioengineering11020194
APA StyleJodeiri, A., Seyedarabi, H., Danishvar, S., Shafiei, S. H., Sales, J. G., Khoori, M., Rahimi, S., & Mortazavi, S. M. J. (2024). Concurrent Learning Approach for Estimation of Pelvic Tilt from Anterior–Posterior Radiograph. Bioengineering, 11(2), 194. https://doi.org/10.3390/bioengineering11020194