1. Introduction
Conversational artificial intelligence (AI) chatbots have gained significant momentum over the last few years. OpenAI’s Chat Generative Pre-trained Transformer (ChatGPT), released November 2022, and Google’s Bard, launched March 2023, are two chatbots that are publicly available. These systems use large language models (LLMs) to process and generate text similar to human language. LLMs constitute a growing field of technology where computer models are pre-trained on large-scale data to then be adapted to a variety of tasks [
1]. While there are several LLMs available today, this work will focus its efforts on ChatGPT and Bard due to their widespread presence and public availability. There are a few key operational differences between the two systems. Namely, ChatGPT uses GPT-3.5 or GPT-4 chatbot models, whereas Bard uses PaLM 2 (Pathways Language Model 2). In addition, Bard draws its data live and directly from Google, whereas ChatGPT operates based on data from 2021, and must search papers to gather information [
2,
3].
These powerful tools are increasingly being considered for efficiency improvements across medicine, including in such applications as supporting clinical practice, scientific writing, image analysis, or immediate medical advice [
4,
5]. However, they are not without risk. It has been noted that LLMs can produce biased or harmful content due to the vast variability in quality of the data used to power them; in medicine in particular, the quality of chatbot output is of concern as it relates to patient care [
6]. There has recently been a strong interest in exploring the capabilities of these LLMs in medicine. Early work demonstrated that OpenAI’s GPT-3.5 performed at or near passing for all three exams in the United States Medical Licensing Exam (USMLE) series [
7]. With newer iterations, GPT-4, released March 2023, was found to outperform GPT-3.5 in correctly answering USMLE questions involving communication skills, ethics, empathy, and professionalism [
8]. More recent studies have compared GPT-4 and Bard in their performance of answering board-style questions in various subspecialties, and these showed that GPT-4 was superior to Bard [
9,
10,
11]. Within ophthalmology, there has been an interest as well, where in one study GPT-4 demonstrated an excellent performance, significantly better than GPT-3.5, in answering practice questions to the Ophthalmology Knowledge Assessment Program (OKAP) examination [
12].
As AI chatbots evolve, become more widely used by the general population, and are integrated into common internet search engines, it is increasingly imperative to assess their role in the patient care journey. It is a well-established trend that patients look to the internet for seeking information about their health [
13,
14] and often turn to the internet first for health advice before contacting health professionals [
15,
16]. Moreover, patients often have long wait times when they do contact their health providers, which is especially true in ophthalmology. A recent study projected that there will be a sizable shortage of ophthalmologists relative to demand by the year 2035 [
17], with limited ophthalmology coverage in emergency departments, especially in rural settings [
18]. As a result, non-ophthalmology providers, busy triage call centers, and patients may begin to look to technological solutions such as AI chatbots that can support addressing ophthalmic complaints and triage. It is therefore critical that the strengths and potential risks of these tools are evaluated thoroughly.
Recent studies have begun to explore the capabilities of AI chatbots as ocular symptom checkers or ophthalmic triage tools. Specifically, Pushpanathan et al. investigated accuracy and quality of responses (without examining triage capabilities) for GPT-3.5, GPT-4, and Bard in answering direct questions about specific ocular symptoms and found that GPT-4 had the highest accuracy [
19]. Lim et al. benchmarked performance of ChatGPT and Bard for myopia-related queries specifically, and also found that GPT-4.0 had superior accuracy [
20]. Lyons et al. compared the triage capabilities of GPT-4, Bing Chat, and WebMD Symptom Checker with ophthalmology trainees across 24 ophthalmic diagnoses. Notably, GPT-4 performed comparably with the trainees in diagnostic and triage accuracy [
21].
In this work, we aimed to evaluate and compare GPT-4 and Bard in their responses to commonly encountered ophthalmic complaints corresponding to 40 critical diagnoses in the form of simulated patient vignettes with targeted questions about proposed diagnoses and triage recommendations. We additionally analyzed how prompt descriptiveness impacts response quality with the aim to better understand how they would best be used in future patient-oriented settings. As we gain a better understanding of the values and limitations of this technology, we can move closer to determining how conversational AI can potentially be implemented in day-to-day society for meeting the demands of delivering timely, accurate, and safe ophthalmic health information for patient use and decision making.
2. Materials and Methods
The Northwestern University Institutional Review Board determined that this in silico research did not involve human subjects. At the time of data collection, GPT-4 was publicly available by paid subscription through ChatGPT Plus, and Bard was freely accessible.
2.1. Creation of Simulated Patient Prompts in Ophthalmology
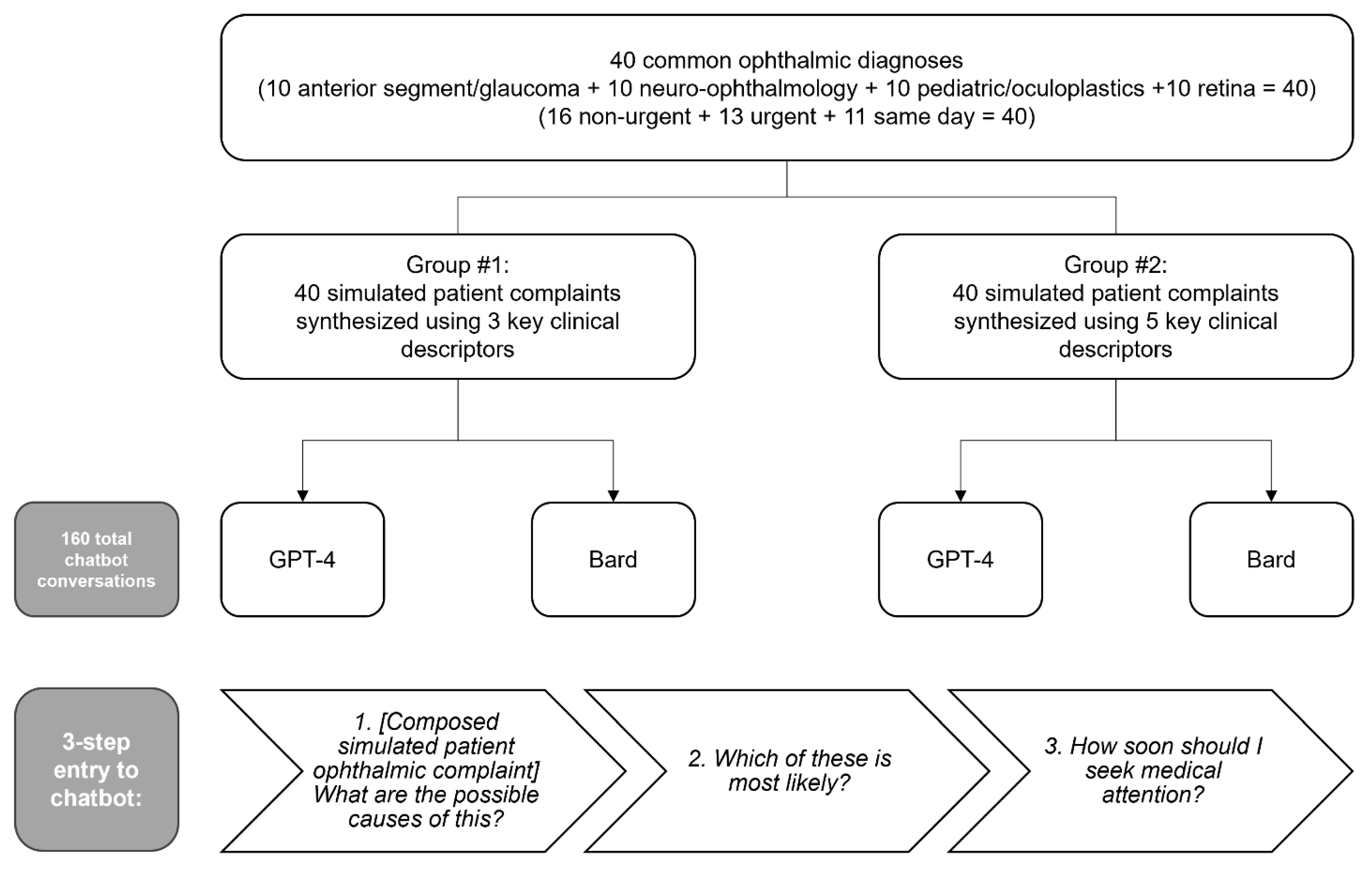
We systematically constructed common scenarios encountered in ophthalmology from the perspective of a patient. Forty common diagnoses, including “cannot miss diagnoses” [
22], were identified and distributed evenly among four groups of ophthalmic specialties: anterior segment/glaucoma, neuro-ophthalmology, pediatric ophthalmology/oculoplastics, and retina. An urgency level to seek care was designated for each diagnosis as either same day, urgent (<1 week), or non-urgent (>1 week). For each diagnosis, two prompts were created, one with three key clinical descriptors and one with five descriptors (
Scheme 1). A descriptor was defined as a clinically relevant piece of information that addressed any of the following: relevant history, onset, duration, laterality, mention of specific ocular anatomy, vision, dyschromatopsia, pain, photophobia, visual disturbances, or any other clinical characteristic. For each patient scenario, consensus was reached among experienced ophthalmologists (P.B., A.E.B., and R.C.B) regarding both intended diagnosis and urgency level based on expert opinion (
Supplemental Tables S1–S4).
2.2. Input to Artificial Intelligence Chatbots
The simulated patient prompts were entered into the AI chatbots between 14 June 2023 and 20 June 2023 using GPT-4 version 2023.05.24 and Bard version 2023.06.07. While many chatbots exist, including Microsoft Bing AI, Claude AI, or Meta’s LLaMA, we chose these two as they are among the most commonly used and referenced chatbots at the time of publication, and they are publicly available. Each prompt was entered into the chatbot using a standardized 3-part stepwise approach. First, the simulated patient scenario followed by the question “What are the possible causes of this?” was entered to the chatbot. The second entry was “Which of these is most likely?”. Finally, the third input was “How soon should I seek medical attention?” Chatbot history was reset prior to starting each 3-part entry. These sequential questions were to ensure that the chatbot addressed a differential diagnosis, leading diagnosis, and provided triage recommendations.
2.3. Grading of Chatbot Responses
To evaluate the response generated by the chatbots, a seven-question questionnaire was designed using both a 4-point Likert scale and binary (yes/no) style questions (
Supplemental Table S5). Prior to grading, chatbot identifiers (e.g., “I’m an AI developed by OpenAI”) were removed from chatbot responses to eliminate potential grader bias toward a particular chatbot. Two experienced ophthalmologists graded each chatbot conversation for accuracy of diagnosis and appropriateness of triage recommendations (primary outcomes), as well as relevance of differential diagnosis, satisfaction with quality of responses for real patient use, and potential harm that responses may pose to real patients (secondary outcomes). A third experienced ophthalmologist served as arbiter for any grading disagreements. All graders were blinded to the chatbot source. For the purposes of this analysis, responses of 3 or 4 on the 4-point Likert scale were treated as “agree” and responses of 1 or 2 were treated as “disagree” to provide binary data.
2.4. Statistical Analysis
Descriptive statistics were generated for all variables of interest where frequencies along with percentages were reported. To compare the outcomes of interest between ChatGPT and Bard, as well as between 5 and 3 descriptors, Pearson’s Chi-squared test or Fisher’s exact test was used when appropriate. Sub-analyses for sub-specialty categories and urgency levels were conducted using the same method. Logistic regression models were applied to the primary outcomes with the degree of detail in prompt as the predictor, and the models were fit separately for ChatGPT and Bard. Model performance was estimated using Area under Curve (AUC) and receiver operating characteristic (ROC) curves. All analyses were conducted using R version 4.3.1.
3. Results
Eighty unique entries were supplied to both GPT-4 and Bard, resulting in a total of 160 chatbot generated responses. 40 entries had 3 prompt descriptors and a counterpart 40 entries had 5 prompt descriptors. The 40 diagnoses were broken down into 4 sub-specialty categories (10 general, 10 neuro-ophthalmology, 10 pediatrics/oculoplastics, and 10 retina) and 3 urgency levels (16 non-urgent, 13 urgent, and 11 same day) (
Scheme 1). The diagnosis rates (i.e., providing the correct diagnosis as the stated most likely cause of the patient’s symptoms) for GPT-4 and Bard were 53.8% and 43.8%, respectively (
p = 0.2). Interestingly, both chatbots were significantly better at providing triage recommendations than at providing the correct leading diagnosis (GPT-4:
p < 0.001, Bard:
p < 0.001). The rates of generally appropriate triage recommendations for GPT-4 and Bard were 96.3% and 83.8%, respectively (
p = 0.008) (
Table 1).
Secondary outcomes included relevance of differential diagnosis, grader satisfaction with chatbot responses, and expert opinion as to whether the chatbot response could pose harm if provided to an actual patient. Of all the 160 responses, the differential diagnoses were generally relevant (87.5%). Additionally, graders indicated satisfaction with 109 responses (68.1%); the satisfaction rate was significantly higher for responses from GPT-4 than from Bard (81.3% vs. 55.0%, respectively;
p < 0.001). Graders reported that 21 of 160 chatbot responses (13.1%) would pose harm if provided to an actual patient; GPT-4 had a lower potential harm rate than Bard (6.3% vs. 20.0%;
p = 0.010) (
Table 1).
Additional sub-analyses were performed comparing the 3 and 5 descriptor cohorts. Notably, increasing the degree of prompt descriptiveness resulted in significant improvement in diagnosis rates for both GPT-4 and Bard (GPT-4: 42.5% vs. 65.0%, respectively;
p = 0.044, Bard: 32.5% vs. 55.0%, respectively;
p = 0.043), whereas triage recommendations did not significantly improve (
Table 2). However, the model performance of prompt descriptiveness predicting appropriate triage for ChatGPT (AUC 0.587) was better than Bard (AUC 0.523) (
Supplemental Figure S1). Of note, increasing the number of descriptors (from 3 to 5) resulted in significantly higher grader satisfaction for GPT-4 (70.0% vs. 92.5%;
p = 0.010), but not for Bard (47.5% vs. 62.5%;
p = 0.2) (
Table 2).
Further sub-analyses were performed to compare GPT-4 with Bard and this demonstrated that GPT-4 performed better than Bard in the 5 descriptor cohort when considering the responses that listed the correct diagnosis anywhere within the chatbot response (92.5% vs. 72.5%;
p = 0.019). GPT-4 also performed significantly better than Bard in the 5 descriptor cohort in generating relevant differential diagnoses (95.0% vs. 77.5%;
p = 0.023). The satisfaction rate was also significantly higher for GPT-4 than Bard (3 descriptor group: 70.0% vs. 47.5%;
p = 0.041, 5 descriptor group: 92.5% vs. 62.5%;
p = 0.001). Within the 5 descriptor cohort, the rate of potential to cause patient harm was zero for GPT-4 and 15.0% for Bard (
p = 0.026) (
Table 3).
Additional sub-analyses of the GPT-4–5 descriptor cohort revealed that the chatbot performed similarly for all outcome measures regardless of urgency level and subspecialty of diagnosis (
Supplemental Tables S6 and S7).
4. Discussion
To our knowledge, this is the first work to investigate both the diagnostic accuracy and appropriateness of triage recommendations of GPT-4 and Bard in response to simulated ophthalmic complaints of varying degrees of descriptiveness. It also uses the largest sample size of responses. Overall, the chatbots were significantly better at ophthalmic triage than at providing the correct diagnosis; notably, GPT-4 displayed high rates of appropriate triage—which supports data found in another recent study [
21]. Our work demonstrates that GPT-4 performed significantly better than Bard in the domains of appropriate triage recommendations, responses that experts were satisfied with for patient use, and responses that were not considered to cause harm if given to real patients. While some of the results were not statistically significant in the sub-analyses, this was likely due to the smaller sample size. It should be highlighted, however, that in the 5 descriptor sub-analysis, GPT-4 performed significantly better than Bard in considering the correct diagnosis as either the most likely diagnosis or as one of the possible diagnoses in the differential diagnosis (92.5% vs. 72.5%;
p = 0.019). This is in agreement with recent research demonstrating the superiority of GPT-4 to Bard in correctly answering questions related to ocular symptoms [
19] and myopia-related queries [
20]. In addition, our work uniquely reveals that increasing the detail of chatbot input (more descriptors) generally improved the quality of output. It should be emphasized that the chatbots were able to provide appropriate triage recommendations without necessarily recognizing the exact diagnosis which better lends itself as an ophthalmic triage tool than as a diagnostic tool.
Another critical question to consider is the performance of these chatbots in the context of do-not-miss diagnoses that are vision- or life-threatening, such as an oculomotor nerve palsy, endophthalmitis, or acute angle closure crisis. In these cases, humans might be trained to take extreme caution when giving guidance to patients, and adoption of conversational AI tools in this space may depend on the responses in such cases. Here, we examined the superior performing chatbot (GPT-4) under optimal conditions (5 descriptor prompts), and we found that all 11 entries with do-not-miss diagnoses resulted in generally appropriate triage recommendations and responses that senior ophthalmologists were satisfied with for patient use. Moreover, there were no responses (0 of 40) in the GPT-4–5 descriptor subgroup that were considered to be potentially harmful. This is particularly valuable as we consider the potential applications of this technology for future patient use, either as a self-inquiry tool or as an adjunct tool for medical staff to execute timely, appropriate, and safe patient triage.
This study’s moderate sample size of chatbot responses is one of its many strengths. We used a highly systematic approach to develop and input all chatbot entries, with chatbot history being reset following each entry to eliminate the variable of chatbot growth over the course of data collection. In addition, our 3-step approach to inputting entries for each “conversation” attempted to take advantage of the conversational capabilities of these chatbots. Lastly, the chatbot responses were all gathered within a one-week time-frame during which all responses were generated from a single iteration of either GPT-4 or Bard, then statistical analysis was performed.
Based on the results found in this work, chatbot responses in the current state of technology are promising but not a sufficient substitute for professional medical advice, yet only in a handful of chatbot responses, GPT-4 more often than Bard, were there such explicit disclaimers. Some examples from GPT-4 include: “I’m an AI developed by OpenAI and while I can help suggest some potential causes for your symptoms, I’m not a substitute for professional medical advice”, “Please note that this advice does not substitute professional medical advice. Always consult with a healthcare provider for medical concerns”, or “Remember that while the internet can provide useful general advice, it’s no substitute for the professional judgment of a healthcare provider who can evaluate your child in person”. It should also be added that in less than half of the GPT-4 responses (28 of 80) and in only one Bard response, was there a specific comment about being an AI; interestingly, Bard only indicated itself as such when unable to respond [“I’m a text-based AI and can’t assist with that.”]. In this work, we inputted the chatbot prompts from the perspective of a simulated patient; in the future, it would be worthwhile to assess how chatbot responses would differ if the chatbot was prompted to answer questions while identifying itself as an AI-generated ophthalmic triage staff. Nonetheless, the chatbot’s recognition of self-limitations as an AI and its recommendation to seek professional medical evaluation are important elements that serve as safety checks to the general public who may already be using this technology to answer their own health-related questions.
5. Limitations
Prior to considering the implementation of such technology for clinical use, further studies with larger data sets should be performed. Another shortcoming of this study is the relatively subjective definition of a “descriptor”, where some modifiers might be more informative than others; nonetheless, our results overall do show that a more descriptive chatbot prompt is desirable. A general concern of conversational AI that must also be highlighted is the risk of generating “hallucinations”, seemingly accurate information that are in fact false [
23]. While our study found that chatbot responses, especially GPT-4, were typically not harmful, we did not specifically investigate the number of hallucinatory responses. The potential of generating convincing misinformation is a serious concern that should not be taken lightly and should be further explored, especially as different iterations of these software are developed.
6. Conclusions
In this work we have evaluated two AI chatbots for their use in ophthalmology; however, as the usage of these tools increases over the coming years, it is imperative to continue their evaluation. As future iterations of GPT-4, Bard, or other LLMs are published, each of these should be tested anew. Additionally, more reviewers could assess a larger sample size of chatbot responses in order to provide greater accountability for the variability in AI responses. In addition, the language of prompts can be more varied in future studies to allow for variability from the user. Finally, more in-depth studies of chatbots’ use may be performed over a longitudinal study following patients’ real-time diagnoses and the chatbots’ capabilities in diagnosis and triage.
Another aspect of AI chatbots to study further includes incorporating images with written text of patient concerns to assess how diagnostic accuracy and triage recommendations vary with the added variable of clinical photos. Given that ophthalmology is a highly visual discipline, it would be interesting to assess how external photos of the eye (i.e., the type of photo that a patient could realistically provide) in conjunction with clinical context would impact chatbot responses.
While this work sheds light on the performance and potential utility of GPT-4 and Bard in the domain of ophthalmic diagnostics and triage, the broader scientific understanding of conversational AI in medicine is still in its infancy as there is an endless number of ways to engage with these chatbots. Recognizing the optimal approach of feeding information into the chatbot and evaluating the quality of the resultant response is imperative to advancing towards real-world application of conversational AI for patient use, either as a self-triage tool or as an adjunct triage tool for medical staff. Our results herein suggest that currently, GPT-4 outperforms Bard and that a greater number of key clinical descriptors for chatbot input is desirable. But only until we have established a full understanding of the strengths and weaknesses of AI chatbots and have been able to consistently achieve a high level of excellence in the quality of responses should we consider their incorporation in patient care. As the world quickly moves towards greater use of conversational AI and a greater need in clinical settings for technological solutions, the urgency for investigative studies like this one will only increase.
Supplementary Materials
The following supporting information can be downloaded at:
https://www.mdpi.com/article/10.3390/bioengineering11020120/s1, Table S1: Compilation of anterior segment/glaucoma/comprehensive simulated patient complaints; Table S2: Compilation of neuro-ophthalmology simulated patient complaints; Table S3: Compilation of pediatric/oculoplastic simulated patient complaints; Table S4: Compilation of retina simulated patient complaints; Table S5: Questionnaire to grade chatbot responses; Table S6: Sub-analysis of primary and secondary outcomes of GPT-4–5 descriptor cohort by urgency level; Table S7: Sub-analysis of primary and secondary outcomes of GPT-4–5 descriptor cohort by subspecialty; Figure S1: Receiver operating characteristic curves for Bard and GPT-4 in providing triage recommendations.
Author Contributions
Conceptualization: R.G.M.; Data curation: R.Z., J.D.F., M.D. and J.M.B.; Funding acquisition: R.G.M.; Formal analysis: S.D.; Investigation: R.Z.; Methodology: R.Z., M.D., P.J.B., A.E.B., R.C.B., J.A.L. and R.G.M.; Project Administration: R.Z. and R.G.M.; Software: R version 4.3.1; Supervision: R.G.M.; Validation: P.J.B., A.E.B. and R.C.B.; Visualization: R.Z. and R.G.M.; Writing—original draft preparation: R.Z. and S.D.; Writing—review and editing: R.G.M. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded in part by an unrestricted departmental grant from Research to Prevent Blindness. JAL was supported by NIH grant K08 EY030923, R01 EY034486, and the Research to Prevent Blindness Sybil B. Harrington Career Development Award for Macular Degeneration. The funding agency had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Institutional Review Board Statement
The Institutional Review Board of Northwestern University determined that this work was not human research and therefore did not require ethical approval.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article/
supplementary material, further inquiries can be directed to the corresponding author.
Conflicts of Interest
J.A.L. is a consultant for Genentech, Inc. R.C.B. is a cofounder of Stream Dx, Inc. R.G.M. has received research support from Google Inc. No party had any role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- Tian, S.; Jin, Q.; Yeganova, L.; Lai, P.-T.; Zhu, Q.; Chen, X.; Yang, Y.; Chen, Q.; Kim, W.; Comeau, D.C. Opportunities and challenges for ChatGPT and large language models in biomedicine and health. Brief. Bioinform. 2024, 25, bbad493. [Google Scholar] [CrossRef]
- Singh, S.K.; Kumar, S.; Mehra, P.S. Chat GPT & Google Bard AI: A Review. In Proceedings of the 2023 International Conference on IoT, Communication and Automation Technology (ICICAT), Online, 23–24 June 2023; pp. 1–6. [Google Scholar]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef]
- Cascella, M.; Montomoli, J.; Bellini, V.; Bignami, E. Evaluating the feasibility of ChatGPT in healthcare: An analysis of multiple clinical and research scenarios. J. Med. Syst. 2023, 47, 33. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Wang, L.; Feng, B.; Zhao, A.; Wu, Y. Innovating healthcare: The role of ChatGPT in streamlining hospital workflow in the future. Ann. Biomed. Eng. 2023, 18, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef] [PubMed]
- Brin, D.; Sorin, V.; Vaid, A.; Soroush, A.; Glicksberg, B.S.; Charney, A.W.; Nadkarni, G.; Klang, E. Comparing ChatGPT and GPT-4 performance in USMLE soft skill assessments. Sci. Rep. 2023, 13, 16492. [Google Scholar] [CrossRef]
- Ali, R.; Tang, O.Y.; Connolly, I.D.; Fridley, J.S.; Shin, J.H.; Sullivan, P.L.Z.; Cielo, D.; Oyelese, A.A.; Doberstein, C.E.; Telfeian, A.E. Performance of ChatGPT, GPT-4, and Google bard on a neurosurgery oral boards preparation question bank. Neurosurgery 2022, 93, 1090–1098. [Google Scholar] [CrossRef]
- Patil, N.S.; Huang, R.S.; van der Pol, C.B.; Larocque, N. Comparative performance of ChatGPT and bard in a text-based radiology knowledge assessment. Can. Assoc. Radiol. J. 2023. [Google Scholar] [CrossRef] [PubMed]
- Noda, R.; Izaki, Y.; Kitano, F.; Komatsu, J.; Ichikawa, D.; Shibagaki, Y. Performance of ChatGPT and Bard in Self-Assessment Questions for Nephrology Board Renewal. medRxiv 2023. [Google Scholar] [CrossRef]
- Teebagy, S.; Colwell, L.; Wood, E.; Yaghy, A.; Faustina, M. Improved Performance of ChatGPT-4 on the OKAP Examination: A Comparative Study with ChatGPT-3.5. J. Acad. Ophthalmol. 2023, 15, e184–e187. [Google Scholar] [CrossRef] [PubMed]
- Thapa, D.K.; Visentin, D.C.; Kornhaber, R.; West, S.; Cleary, M. The influence of online health information on health decisions: A systematic review. Patient Educ. Couns. 2021, 104, 770–784. [Google Scholar] [CrossRef]
- Calixte, R.; Rivera, A.; Oridota, O.; Beauchamp, W.; Camacho-Rivera, M. Social and demographic patterns of health-related Internet use among adults in the United States: A secondary data analysis of the health information national trends survey. Int. J. Environ. Res. Public Health 2020, 17, 6856. [Google Scholar] [CrossRef] [PubMed]
- Hesse, B.W.; Nelson, D.E.; Kreps, G.L.; Croyle, R.T.; Arora, N.K.; Rimer, B.K.; Viswanath, K. Trust and sources of health information: The impact of the Internet and its implications for health care providers: Findings from the first Health Information National Trends Survey. Arch. Intern. Med. 2005, 165, 2618–2624. [Google Scholar] [CrossRef]
- Fox, S.D. Maeve. In Health Online 2013; Pew Research Center: Washington, DC, USA, 2013. [Google Scholar]
- Berkowitz, S.T.; Finn, A.P.; Parikh, R.; Kuriyan, A.E.; Patel, S. Ophthalmology Workforce Projections in the United States, 2020–2035. Ophthalmology 2023, 131, 133–139. [Google Scholar] [CrossRef]
- Wedekind, L.; Sainani, K.; Pershing, S. Supply and perceived demand for teleophthalmology in triage and consultations in California emergency departments. JAMA Ophthalmol. 2016, 134, 537–543. [Google Scholar] [CrossRef]
- Pushpanathan, K.; Lim, Z.W.; Yew, S.M.E.; Chen, D.Z.; Lin, H.A.H.E.; Goh, J.H.L.; Wong, W.M.; Wang, X.; Tan, M.C.J.; Koh, V.T.C. Popular Large Language Model Chatbots’ Accuracy, Comprehensiveness, and Self-Awareness in Answering Ocular Symptom Queries. iScience 2023, 26, 108163. [Google Scholar] [CrossRef]
- Lim, Z.W.; Pushpanathan, K.; Yew, S.M.E.; Lai, Y.; Sun, C.-H.; Lam, J.S.H.; Chen, D.Z.; Goh, J.H.L.; Tan, M.C.J.; Sheng, B. Benchmarking large language models’ performances for myopia care: A comparative analysis of ChatGPT-3.5, ChatGPT-4.0, and Google Bard. EBioMedicine 2023, 95, 104770. [Google Scholar] [CrossRef]
- Lyons, R.J.; Arepalli, S.R.; Fromal, O.; Choi, J.D.; Jain, N. Artificial intelligence chatbot performance in triage of ophthalmic conditions. Can. J. Ophthalmol. 2023, in press. [CrossRef]
- Deaner, J.D.; Amarasekera, D.C.; Ozzello, D.J.; Swaminathan, V.; Bonafede, L.; Meeker, A.R.; Zhang, Q.; Haller, J.A. Accuracy of referral and phone-triage diagnoses in an eye emergency department. Ophthalmology 2021, 128, 471–473. [Google Scholar] [CrossRef]
- Azamfirei, R.; Kudchadkar, S.R.; Fackler, J. Large language models and the perils of their hallucinations. Crit. Care 2023, 27, 120. [Google Scholar] [CrossRef] [PubMed]
Scheme 1.
Flowchart of overall study design of chatbot prompts.
Scheme 1.
Flowchart of overall study design of chatbot prompts.
Table 1.
Primary and secondary outcomes of Bard and GPT-4.
Table 1.
Primary and secondary outcomes of Bard and GPT-4.
| | Overall
N = 160 1 | Bard
N = 80 1 | GPT-4
N = 80 1 | p-Value 2 |
|---|
| Primary outcomes of Bard and GPT-4 overall |
| Correct diagnosis as most likely cause of symptoms | 78
(48.75%) | 35
(43.75%) | 43
(53.75%) | 0.2 |
| Correct diagnosis somewhere in the chatbot conversation | 125
(78.13%) | 58
(72.50%) | 67
(83.75%) | 0.085 |
| “Somewhat” or “completely” appropriate triage recommendations | 144
(90.00%) | 67
(83.75%) | 77
(96.25%) | 0.008 * |
| “Completely” appropriate triage recommendations | 123
(76.88%) | 55
(68.75%) | 68
(85.00%) | 0.015 * |
| Secondary outcomes of Bard and GPT-4 overall |
| “Somewhat” or “very” relevant differential diagnosis | 140
(87.50%) | 66
(82.50%) | 74
(92.50%) | 0.056 |
| Graders “somewhat” or “very” satisfied with quality of chatbot response for actual patient use | 109
(68.13%) | 44
(55.00%) | 65
(81.25%) | <0.001 * |
| Potentially harmful for patients | 21
(13.13%) | 16
(20.00%) | 5
(6.25%) | 0.010 * |
Table 2.
Primary and secondary outcomes between 3 and 5 descriptors for Bard and GPT-4.
Table 2.
Primary and secondary outcomes between 3 and 5 descriptors for Bard and GPT-4.
| | Bard | GPT-4 |
|---|
| | 3 Descriptors N = 40 1 | 5 Descriptors N = 40 1 | p-Value 2 | 3 Descriptors N = 40 1 | 5 Descriptors N = 40 1 | p-Value 3 |
|---|
| Primary outcomes of Bard and GPT-4 overall |
| Correct diagnosis as most likely cause of symptoms | 13
(32.50%) | 22
(55.00%) | 0.043 * | 17
(42.50%) | 26
(65.00%) | 0.044 * |
| Correct diagnosis somewhere in the chatbot conversation | 29
(72.50%) | 29
(72.50%) | >0.9 | 30
(75.00%) | 37
(92.50%) | 0.034 * |
| “Somewhat” or “completely” appropriate triage recommendations | 33
(82.50%) | 34
(85.00%) | 0.8 | 38
(95.00%) | 39
(97.50%) | >0.9 |
| “Completely” appropriate triage recommendations | 24
(60.00%) | 31
(77.50%) | 0.091 | 32
(80.00%) | 36
(90.00%) | 0.2 |
| Secondary outcomes of Bard and GPT-4 overall |
| “Somewhat” or “very” relevant differential diagnosis | 35
(87.50%) | 31
(77.50%) | 0.2 | 36
(90.00%) | 38
(95.00%) | 0.7 |
| Graders “somewhat” or “very” satisfied with quality of chatbot response for actual patient use | 19
(47.50%) | 25
(62.50%) | 0.2 | 28
(70.00%) | 37
(92.50%) | 0.010 * |
| Potentially harmful for patients | 10
(25.00%) | 6
(15.00%) | 0.3 | 5
(12.50%) | 0
(0.00%) | 0.055 |
Table 3.
Primary and secondary outcomes between Bard and GPT-4 for 3 and 5 descriptor cohorts.
Table 3.
Primary and secondary outcomes between Bard and GPT-4 for 3 and 5 descriptor cohorts.
| | 3 Descriptors | 5 Descriptors |
|---|
| | Bard
N = 40 1 | GPT-4
N = 40 1 | p-Value 2 | Bard
N = 40 1 | GPT-4
N = 40 1 | p-Value 2 |
|---|
| Primary outcomes of Bard and GPT-4 overall |
| Correct diagnosis as most likely cause of symptoms | 13
(32.50%) | 17
(42.50%) | 0.4 | 22
(55.00%) | 26
(65.00%) | 0.4 |
| Correct diagnosis somewhere in the chatbot conversation | 29
(72.50%) | 30
(75.00%) | 0.8 | 29
(72.50%) | 37
(92.50%) | 0.019 * |
| “Somewhat” or “completely” appropriate triage recommendations | 33
(82.50%) | 38
(95.00%) | 0.2 | 34
(85.00%) | 39
(97.50%) | 0.11 |
| “Completely” appropriate triage recommendations | 24
(60.00%) | 32
(80.00%) | 0.051 | 31
(77.50%) | 36
90.00%) | 0.13 |
| Secondary outcomes of Bard and GPT-4 overall |
| “Somewhat” or “very” relevant differential diagnosis | 35
(87.50%) | 36
(90.00%) | >0.9 | 31
(77.50%) | 38
(95.00%) | 0.023 * |
| Graders “somewhat” or “very” satisfied with quality of chatbot response for actual patient use | 19
(47.50%) | 28
(70.00%) | 0.041 * | 25
(62.50%) | 37
92.50%) | 0.001 * |
| Potentially harmful for patients | 10
25.00%) | 5
(12.50%) | 0.2 | 6
(15.00%) | 0
(0.00%) | 0.026 * |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 

{kind=link}