



Artificial Intelligence and/or Machine Learning Algorithms in Microalgae Bioprocesses


Abstract
:1. Introduction
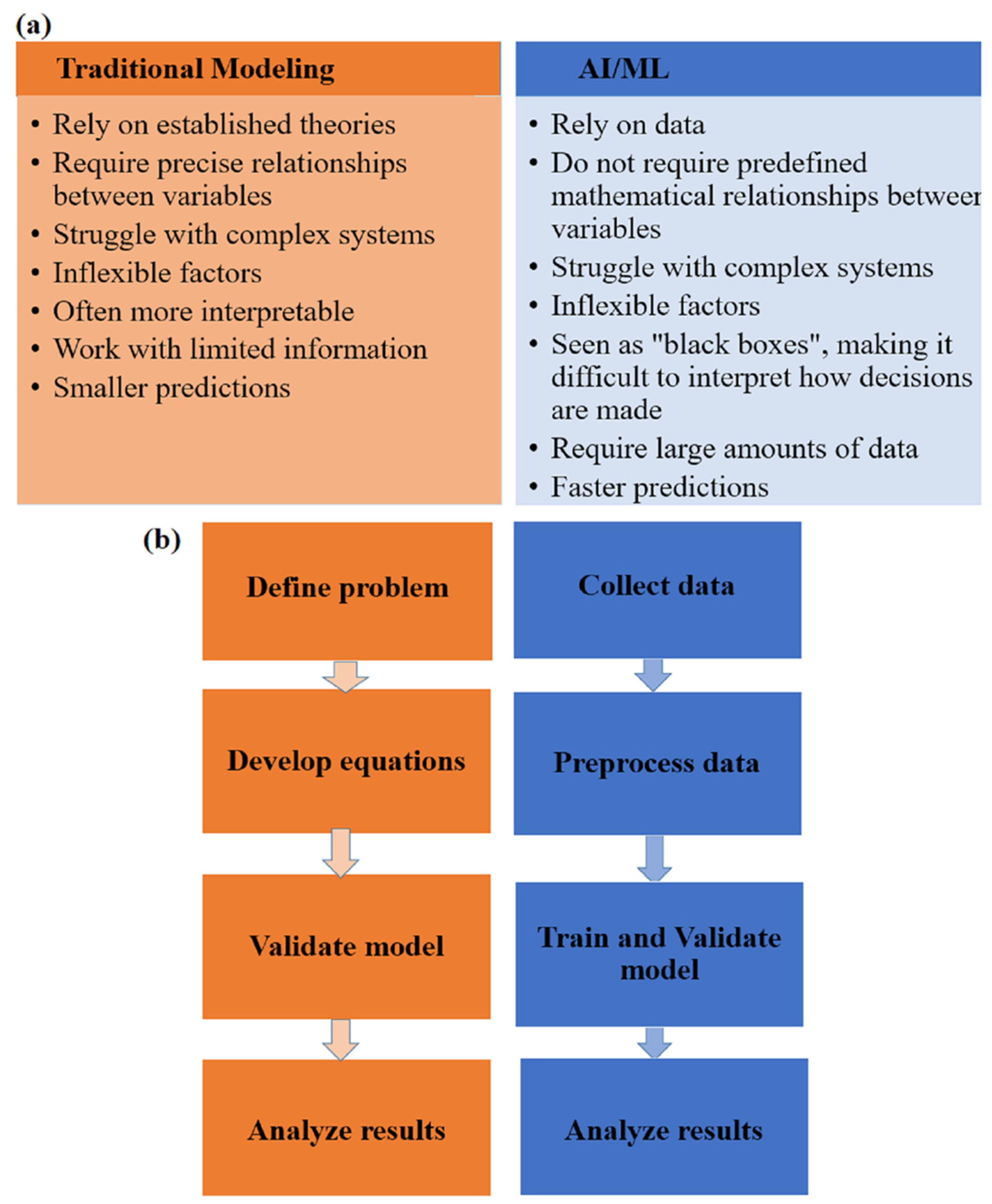
2. Transition from Traditional Mathematical Modeling and Simulation to AI/ML in Microalgae Processes
3. Artificial Intelligence
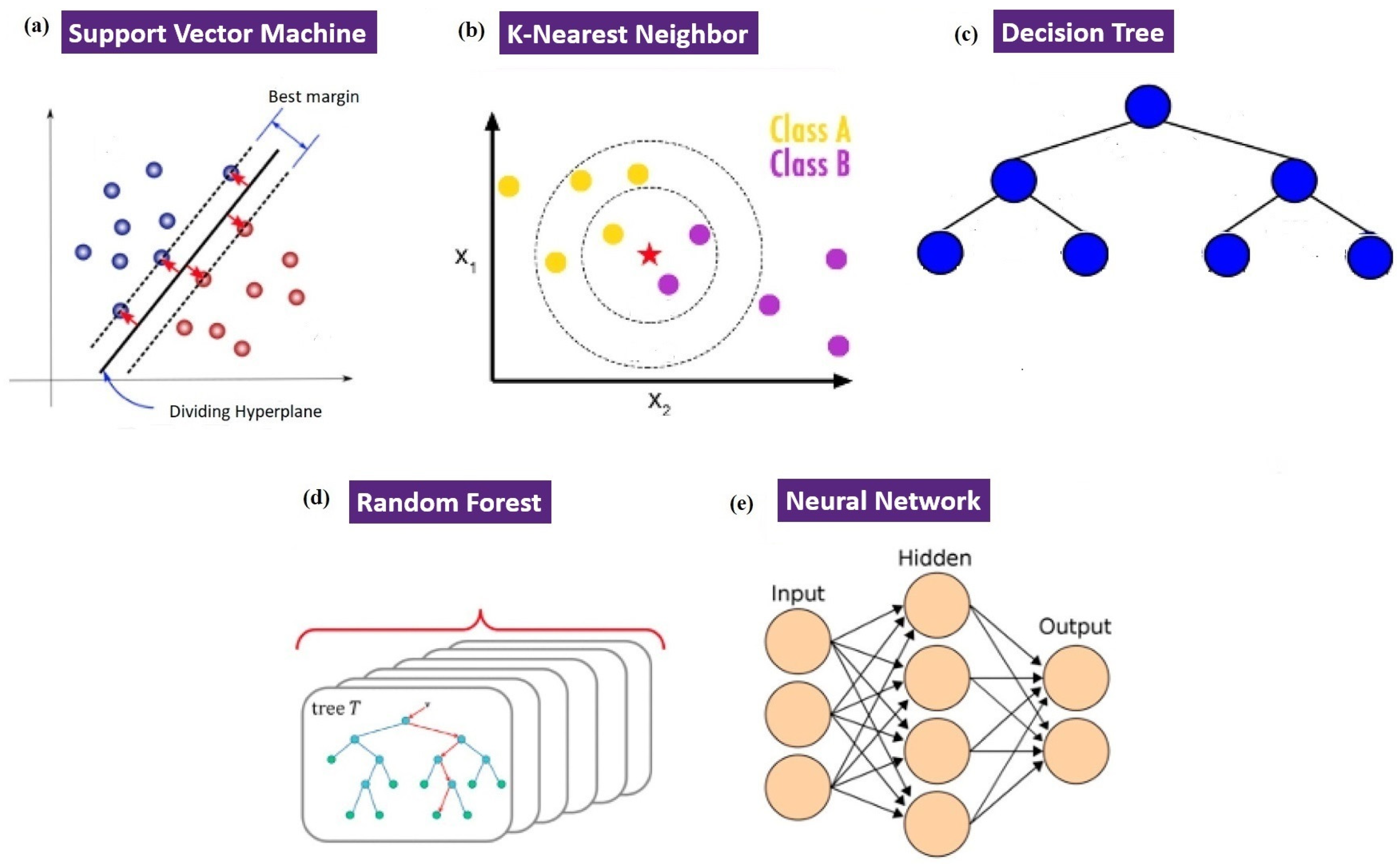
3.1. Machine Learning
3.1.1. Support Vector Machine
3.1.2. Genetic Algorithm
3.1.3. K-Nearest Neighbors
3.1.4. Decision Tree
3.1.5. Random Forest
3.2. Neural Networks
Adaptive Neuro-Fuzzy Inference System
3.3. Deep Learning
3.3.1. Convolutional Neural Networks
3.3.2. Recurrent Neural Networks
3.3.3. Autoencoders
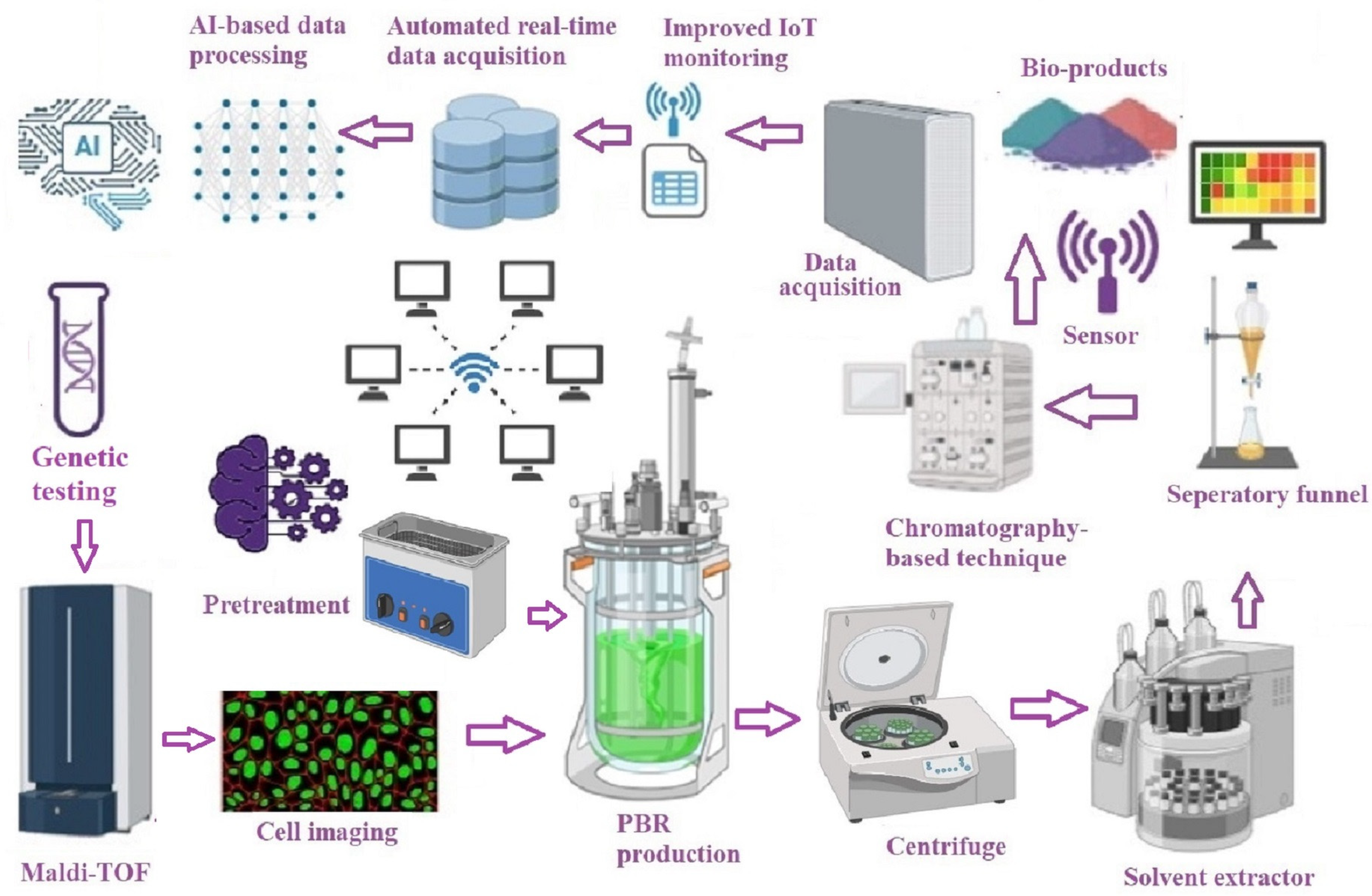
4. Intersection of IoT and AI/ML
5. Applications of AI/ML in Microalgae Processes
5.1. Classification
5.2. Upstream Microalgae Processes
5.3. Downstream Microalgae Processes
6. Ethical Issues and Challenges
7. Conclusions and Outlook for the Future
- AI/ML technologies in microalgae processes offer data-driven optimization, surpassing traditional methods in terms of efficiency, yield, and control.
- Key applications include species identification, the optimization of growth conditions, harvesting, extraction, and purification in microalgae processes.
- Popular ML algorithms used are SVM, GA, DT, RF, ANN, and DL, each with their strengths and limitations.
- AI/ML enhances performance, stability, and scalability and reduces manual labor, costs, downtime, and environmental risks.
- The challenges include data limitations, model complexity, scalability, cybersecurity, and regulatory concerns.
- Solutions, such as simulation-based data, modular design, and adaptive learning models, can overcome these challenges and foster innovation.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Udaypal; Goswami, R.K.; Mehariya, S.; Verma, P. Advances in Microalgae-Based Carbon Sequestration: Current Status and Future Perspectives. Environ. Res. 2024, 249, 118397. [Google Scholar] [CrossRef] [PubMed]
- Alzahmi, A.S.; Daakour, S.; Nelson, D.; Al-Khairy, D.; Twizere, J.C.; Salehi-Ashtiani, K. Enhancing Algal Production Strategies: Strain Selection, AI-Informed Cultivation, and Mutagenesis. Front. Sustain. Food Syst. 2024, 8, 1331251. [Google Scholar] [CrossRef]
- Diaz, C.J.; Douglas, K.J.; Kang, K.; Kolarik, A.L.; Malinovski, R.; Torres-Tiji, Y.; Molino, J.V.; Badary, A.; Mayfield, S.P. Developing Algae as a Sustainable Food Source. Front. Nutr. 2023, 9, 1029841. [Google Scholar] [CrossRef] [PubMed]
- Fu, W.; Nelson, D.R.; Mystikou, A.; Daakour, S.; Salehi-Ashtiani, K. Advances in Microalgal Research and Engineering Development. Curr. Opin. Biotechnol. 2019, 59, 157–164. [Google Scholar] [CrossRef]
- Igou, T.; Zhong, S.; Reid, E.; Chen, Y. Real-Time Sensor Data Profile-Based Deep Learning Method Applied to Open Raceway Pond Microalgal Productivity Prediction. Environ. Sci. Technol. 2023, 57, 17981–17989. [Google Scholar] [CrossRef]
- Chapman, R.L. Algae: The World’s Most Important “Plants”—An Introduction. Mitig. Adapt. Strateg. Glob. Chang. 2013, 18, 5–12. [Google Scholar] [CrossRef]
- Beal, C.M.; Gerber, L.N.; Thongrod, S.; Phromkunthong, W.; Kiron, V.; Granados, J.; Archibald, I.; Greene, C.H.; Huntley, M.E. Marine Microalgae Commercial Production Improves Sustainability of Global Fisheries and Aquaculture. Sci. Rep. 2018, 8, 15064. [Google Scholar] [CrossRef]
- Lim, H.R.; Khoo, K.S.; Chia, W.Y.; Chew, K.W.; Ho, S.H.; Show, P.L. Smart Microalgae Farming with Internet-of-Things for Sustainable Agriculture. Biotechnol. Adv. 2022, 57, 107931. [Google Scholar] [CrossRef]
- Lim, H.R.; Khoo, K.S.; Chew, K.W.; Chang, C.K.; Munawaroh, H.S.H.; Kumar, P.S.; Huy, N.D.; Show, P.L. Perspective of Spirulina Culture with Wastewater into a Sustainable Circular Bioeconomy. Environ. Pollut. 2021, 284, 117492. [Google Scholar] [CrossRef]
- Oruganti, R.K.; Biji, A.P.; Lanuyanger, T.; Show, P.L.; Sriariyanun, M.; Upadhyayula, V.K.K.; Gadhamshetty, V.; Bhattacharyya, D. Artificial Intelligence and Machine Learning Tools for High-Performance Microalgal Wastewater Treatment and Algal Biorefinery: A Critical Review. Sci. Total Environ. 2023, 876, 162797. [Google Scholar] [CrossRef]
- Kavitha, S.; Ravi, Y.K.; Kumar, G.; Kadapakkam Nandabalan, Y.; J, R.B. Microalgal Biorefineries: Advancement in Machine Learning Tools for Sustainable Biofuel Production and Value-Added Products Recovery. J. Environ. Manag. 2024, 353, 120135. [Google Scholar] [CrossRef]
- Torres-Tiji, Y.; Fields, F.J.; Mayfield, S.P. Microalgae as a Future Food Source. Biotechnol. Adv. 2020, 41, 107536. [Google Scholar] [CrossRef] [PubMed]
- Ganesan, R.; Manigandan, S.; Samuel, M.S.; Shanmuganathan, R.; Brindhadevi, K.; Lan Chi, N.T.; Duc, P.A.; Pugazhendhi, A. A Review on Prospective Production of Biofuel from Microalgae. Biotechnol. Rep. 2020, 27, e00509. [Google Scholar] [CrossRef] [PubMed]
- Zabed, H.M.; Akter, S.; Yun, J.; Zhang, G.; Zhang, Y.; Qi, X. Biogas from Microalgae: Technologies, Challenges and Opportunities. Renew. Sustain. Energy Rev. 2020, 117, 109503. [Google Scholar] [CrossRef]
- Adeniyi, O.M.; Azimov, U.; Burluka, A. Algae Biofuel: Current Status and Future Applications. Renew. Sustain. Energy Rev. 2018, 90, 316–335. [Google Scholar] [CrossRef]
- Bisht, B.; Begum, J.P.S.; Dmitriev, A.A.; Kurbatova, A.; Singh, N.; Nishinari, K.; Nanda, M.; Kumar, S.; Vlaskin, M.S.; Kumar, V. Unlocking the Potential of Future Version 3D Food Products with next Generation Microalgae Blue Protein Integration: A Review. Trends Food Sci. Technol. 2024, 147, 104471. [Google Scholar] [CrossRef]
- Fu, Y.; Chen, T.; Chen, S.H.Y.; Liu, B.; Sun, P.; Sun, H.; Chen, F. The Potentials and Challenges of Using Microalgae as an Ingredient to Produce Meat Analogues. Trends Food Sci. Technol. 2021, 112, 188–200. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, G.; Chong, S.; Mak, N.K.; Chen, F.; Jiang, Y. Ultraviolet-B Radiation Improves Astaxanthin Accumulation in Green Microalga Haematococcus pluvialis. Biotechnol. Lett. 2010, 32, 1911–1914. [Google Scholar] [CrossRef]
- Rafa, N.; Ahmed, S.F.; Badruddin, I.A.; Mofijur, M.; Kamangar, S. Strategies to Produce Cost-Effective Third-Generation Biofuel from Microalgae. Front. Energy Res. 2021, 9, 749968. [Google Scholar] [CrossRef]
- Chew, K.W.; Yap, J.Y.; Show, P.L.; Suan, N.H.; Juan, J.C.; Ling, T.C.; Lee, D.J.; Chang, J.S. Microalgae Biorefinery: High Value Products Perspectives. Bioresour. Technol. 2017, 229, 53–62. [Google Scholar] [CrossRef]
- Peter, A.P.; Chew, K.W.; Pandey, A.; Lau, S.Y.; Rajendran, S.; Ting, H.Y.; Munawaroh, H.S.H.; Van Phuong, N.; Show, P.L. Artificial Intelligence Model for Monitoring Biomass Growth in Semi-Batch Chlorella Vulgaris Cultivation. Fuel 2023, 333, 126438. [Google Scholar] [CrossRef]
- Biloria, N.; Thakkar, Y. Integrating Algae Building Technology in the Built Environment: A Cost and Benefit Perspective. Front. Archit. Res. 2020, 9, 370–384. [Google Scholar] [CrossRef]
- Kushwaha, O.S.; Uthayakumar, H.; Kumaresan, K. Modeling of Carbon Dioxide Fixation by Microalgae Using Hybrid Artificial Intelligence (AI) and Fuzzy Logic (FL) Methods and Optimization by Genetic Algorithm (GA). Environ. Sci. Pollut. Res. 2023, 30, 24927–24948. [Google Scholar] [CrossRef]
- Zhu, J.; Rong, J.; Zong, B. Factors in Mass Cultivation of Microalgae for Biodiesel. Cuihua Xuebao/Chin. J. Catal. 2013, 34, 80–100. [Google Scholar] [CrossRef]
- Lee, S.Y.; Khoiroh, I.; Vo, D.V.N.; Senthil Kumar, P.; Show, P.L. Techniques of Lipid Extraction from Microalgae for Biofuel Production: A Review. Environ. Chem. Lett. 2021, 19, 231–251. [Google Scholar] [CrossRef]
- Tan, C.H.; Nomanbhay, S.; Shamsuddin, A.H.; Show, P.L. Recent Progress in Harvest and Recovery Techniques of Mammalian and Algae Cells for Industries. Indian J. Microbiol. 2021, 61, 279–282. [Google Scholar] [CrossRef]
- Long, B.; Fischer, B.; Zeng, Y.; Amerigian, Z.; Li, Q.; Bryant, H.; Li, M.; Dai, S.Y.; Yuan, J.S. Machine Learning-Informed and Synthetic Biology-Enabled Semi-Continuous Algal Cultivation to Unleash Renewable Fuel Productivity. Nat. Commun. 2022, 13, 541. [Google Scholar] [CrossRef]
- Khoo, C.G.; Dasan, Y.K.; Lam, M.K.; Lee, K.T. Algae Biorefinery: Review on a Broad Spectrum of Downstream Processes and Products. Bioresour. Technol. 2019, 292, 121964. [Google Scholar] [CrossRef]
- Wang, S.; Wu, S.; Yang, G.; Pan, K.; Wang, L.; Hu, Z. A Review on the Progress, Challenges and Prospects in Commercializing Microalgal Fucoxanthin. Biotechnol. Adv. 2021, 53, 107865. [Google Scholar] [CrossRef]
- Chong, J.W.R.; Tang, D.Y.Y.; Leong, H.Y.; Khoo, K.S.; Show, P.L.; Chew, K.W. Bridging Artificial Intelligence and Fucoxanthin for the Recovery and Quantification from Microalgae. Bioengineered 2023, 14, 2244232. [Google Scholar] [CrossRef]
- Pocha, C.K.R.; Chia, W.Y.; Chew, K.W.; Munawaroh, H.S.H.; Show, P.L. Current Advances in Recovery and Biorefinery of Fucoxanthin from Phaeodactylum tricornutum. Algal Res. 2022, 65, 102735. [Google Scholar] [CrossRef]
- Seth, K.; Kumar, A.; Rastogi, R.P.; Meena, M.; Vinayak, V. Harish Bioprospecting of Fucoxanthin from Diatoms—Challenges and Perspectives. Algal Res. 2021, 60, 102475. [Google Scholar] [CrossRef]
- Ghosh, S.; Dasgupta, R. Machine Learning Methods. In Machine Learning in Biological Sciences: Updates and Future Prospects; Springer Nature: Singapore, 2022; pp. 29–43. [Google Scholar] [CrossRef]
- Huang, Y.; Zheng, Y.; Lu, X.; Zhao, Y.; Zhou, D.; Zhang, Y.; Liu, G. Simulation and Optimization: A New Direction in Supercritical Technology Based Nanomedicine. Bioengineering 2023, 10, 1404. [Google Scholar] [CrossRef] [PubMed]
- Aslanbay Guler, B.; Deniz, I.; Demirel, Z.; Imamoglu, E. Computational Fluid Dynamics Simulation in Scaling-up of Airlift Photobioreactor for Astaxanthin Production. J. Biosci. Bioeng. 2020, 129, 86–92. [Google Scholar] [CrossRef]
- Aslanbay Guler, B.; Deniz, I.; Demirel, Z.; Oncel, S.S.; Imamoglu, E. Computational Fluid Dynamics Modelling of Stirred Tank Photobioreactor for Haematococcus pluvialis Production: Hydrodynamics and Mixing Conditions. Algal Res. 2020, 47, 101854. [Google Scholar] [CrossRef]
- Imamoglu, E.; Demirel, Z.; Conk Dalay, M. Process Optimization and Modeling for the Cultivation of Nannochloropsis sp. and Tetraselmis striata via Response Surface Methodology. J. Phycol. 2015, 51, 442–453. [Google Scholar] [CrossRef]
- Kalwani, M.; Kumari, A.; Rudra, S.G.; Chhabra, D.; Pabbi, S.; Shukla, P. Application of ANN-MOGA for Nutrient Sequestration for Wastewater Remediation and Production of Polyunsaturated Fatty Acid (PUFA) by Chlorella sorokiniana MSP1. Chemosphere 2024, 349, 140835. [Google Scholar] [CrossRef]
- Srivastava, G.; Paul, A.K.; Goud, V.V. Optimization of Non-Catalytic Transesterification of Microalgae Oil to Biodiesel under Supercritical Methanol Condition. Energy Convers. Manag. 2018, 156, 269–278. [Google Scholar] [CrossRef]
- Schwendicke, F.; Samek, W.; Krois, J. Artificial Intelligence in Dentistry: Chances and Challenges. J. Dent. Res. 2020, 99, 769–774. [Google Scholar] [CrossRef]
- Naeimi, S.M.; Darvish, S.; Salman, B.N.; Luchian, I. Artificial Intelligence in Adult and Pediatric Dentistry: A Narrative Review. Bioengineering 2024, 11, 431. [Google Scholar] [CrossRef]
- Reyes, L.T.; Knorst, J.K.; Ortiz, F.R.; Ardenghi, T.M. Scope and Challenges of Machine Learning-Based Diagnosis and Prognosis in Clinical Dentistry: A Literature Review. J. Clin. Transl. Res. 2021, 7, 523–539. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, J.; Zhou, Y.; Zhang, X.; Liu, X. Artificial Intelligence-Based Microfluidic Platform for Detecting Contaminants in Water: A Review. Sensors 2024, 24, 4350. [Google Scholar] [CrossRef] [PubMed]
- Sahu, S.; Kaur, A.; Singh, G.; Kumar Arya, S. Harnessing the Potential of Microalgae-Bacteria Interaction for Eco-Friendly Wastewater Treatment: A Review on New Strategies Involving Machine Learning and Artificial Intelligence. J. Environ. Manag. 2023, 346, 119004. [Google Scholar] [CrossRef] [PubMed]
- Ganthavee, V.; Trzcinski, A.P. Artificial Intelligence and Machine Learning for the Optimization of Pharmaceutical Wastewater Treatment Systems: A Review. Environ. Chem. Lett. 2024, 22, 2293–2318. [Google Scholar] [CrossRef]
- Teng, S.Y.; Yew, G.Y.; Sukačová, K.; Show, P.L.; Máša, V.; Chang, J.S. Microalgae with Artificial Intelligence: A Digitalized Perspective on Genetics, Systems and Products. Biotechnol. Adv. 2020, 44, 107631. [Google Scholar] [CrossRef]
- Amirzadeh, R.; Nazari, A.; Thiruvady, D. Applying Artificial Intelligence in Cryptocurrency Markets: A Survey. Algorithms 2022, 15, 428. [Google Scholar] [CrossRef]
- Carbonell, J.G. Machine Learning Research. ACM SIGART Bull. 1981, 18, 29. [Google Scholar] [CrossRef]
- Ning, H.; Li, R.; Zhou, T. Machine Learning for Microalgae Detection and Utilization. Front. Mar. Sci. 2022, 9, 947394. [Google Scholar] [CrossRef]
- Vapnik, V.N. An Overview of Statistical Learning Theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef]
- Jha, K.; Doshi, A.; Patel, P.; Shah, M. A Comprehensive Review on Automation in Agriculture Using Artificial Intelligence. Artif. Intell. Agric. 2019, 2, 1–12. [Google Scholar] [CrossRef]
- Thornton, C.; Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; Part F1288. pp. 847–855. [Google Scholar] [CrossRef]
- Guo, H.-n.; Wu, S.-b.; Tian, Y.-j.; Zhang, J.; Liu, H.-t. Application of Machine Learning Methods for the Prediction of Organic Solid Waste Treatment and Recycling Processes: A Review. Bioresour. Technol. 2021, 319, 124114. [Google Scholar] [CrossRef] [PubMed]
- Al-Kharusi, G.; Dunne, N.J.; Little, S.; Levingstone, T.J. The Role of Machine Learning and Design of Experiments in the Advancement of Biomaterial and Tissue Engineering Research. Bioengineering 2022, 9, 561. [Google Scholar] [CrossRef] [PubMed]
- Rutland, H.; You, J.; Liu, H.; Bull, L.; Reynolds, D. A Systematic Review of Machine-Learning Solutions in Anaerobic Digestion. Bioengineering 2023, 10, 1410. [Google Scholar] [CrossRef] [PubMed]
- Lamberti, M.J.; Wilkinson, M.; Donzanti, B.A.; Wohlhieter, G.E.; Parikh, S.; Wilkins, R.G.; Getz, K. A Study on the Application and Use of Artificial Intelligence to Support Drug Development. Clin. Ther. 2019, 41, 1414–1426. [Google Scholar] [CrossRef]
- Ahmad Sobri, M.Z.; Redhwan, A.; Ameen, F.; Lim, J.W.; Liew, C.S.; Mong, G.R.; Daud, H.; Sokkalingam, R.; Ho, C.D.; Usman, A.; et al. A Review Unveiling Various Machine Learning Algorithms Adopted for Biohydrogen Productions from Microalgae. Fermentation 2023, 9, 243. [Google Scholar] [CrossRef]
- Chong, J.W.R.; Khoo, K.S.; Chew, K.W.; Ting, H.Y.; Iwamoto, K.; Ruan, R.; Ma, Z.; Show, P.L. Artificial Intelligence-Driven Microalgae Autotrophic Batch Cultivation: A Comparative Study of Machine and Deep Learning-Based Image Classification Models. Algal Res. 2024, 79, 103400. [Google Scholar] [CrossRef]
- Du, Y.H.; Wang, M.Y.; Yang, L.H.; Tong, L.L.; Guo, D.S.; Ji, X.J. Optimization and Scale-Up of Fermentation Processes Driven by Models. Bioengineering 2022, 9, 473. [Google Scholar] [CrossRef]
- Shahid, N.; Naqvi, I.H.; Qaisar, S. Bin One-Class Support Vector Machines: Analysis of Outlier Detection for Wireless Sensor Networks in Harsh Environments. Artif. Intell. Rev. 2015, 43, 515–563. [Google Scholar] [CrossRef]
- Wang, L.; Xi, Y.; Sung, S.; Qiao, H. RNA-Seq Assistant: Machine Learning Based Methods to Identify More Transcriptional Regulated Genes. BMC Genom. 2018, 19, 546. [Google Scholar] [CrossRef]
- Karimzadeh, M.; Basvoju, D.; Vakanski, A.; Charit, I.; Xu, F.; Zhang, X. Machine Learning for Additive Manufacturing of Functionally Graded Materials. Materials 2024, 17, 3673. [Google Scholar] [CrossRef]
- Belle, V.; Papantonis, I. Principles and Practice of Explainable Machine Learning. Front. Big Data 2021, 4, 688969. [Google Scholar] [CrossRef] [PubMed]
- Otchere, D.A.; Arbi Ganat, T.O.; Gholami, R.; Ridha, S. Application of Supervised Machine Learning Paradigms in the Prediction of Petroleum Reservoir Properties: Comparative Analysis of ANN and SVM Models. J. Pet. Sci. Eng. 2021, 200, 108182. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. An Assessment of the Effectiveness of Decision Tree Methods for Land Cover Classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Chen, Z.Q. Hybrid Decision Tree. Knowl.-Based Syst. 2002, 15, 515–528. [Google Scholar] [CrossRef]
- You, H.; Ma, Z.; Tang, Y.; Wang, Y.; Yan, J.; Ni, M.; Cen, K.; Huang, Q. Comparison of ANN (MLP), ANFIS, SVM, and RF Models for the Online Classification of Heating Value of Burning Municipal Solid Waste in Circulating Fluidized Bed Incinerators. Waste Manag. 2017, 68, 186–197. [Google Scholar] [CrossRef]
- Mohammed, A.; Kora, R. A Comprehensive Review on Ensemble Deep Learning: Opportunities and Challenges. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 757–774. [Google Scholar] [CrossRef]
- Abbasi, E.; Alavi Moghaddam, M.R.; Kowsari, E. A Systematic and Critical Review on Development of Machine Learning Based-Ensemble Models for Prediction of Adsorption Process Efficiency. J. Clean. Prod. 2022, 379, 134588. [Google Scholar] [CrossRef]
- Otálora, P.; Guzmán, J.L.; Acién, F.G.; Berenguel, M.; Reul, A. An Artificial Intelligence Approach for Identification of Microalgae Cultures. New Biotechnol. 2023, 77, 58–67. [Google Scholar] [CrossRef]
- Vimali, E.; Senthil Kumar, A.; Sakthi Vignesh, N.; Ashokkumar, B.; Dhakshinamoorthy, A.; Udayan, A.; Arumugam, M.; Pugazhendhi, A.; Varalakshmi, P. Enhancement of Lipid Accumulation in Microalga Desmodesmus sp. VV2: Response Surface Methodology and Artificial Neural Network Modeling for Biodiesel Production. Chemosphere 2022, 293, 133477. [Google Scholar] [CrossRef]
- Thangarasu, V.; Siddharth, R.; Ramanathan, A. Modeling of Process Intensification of Biodiesel Production from Aegle Marmelos Correa Seed Oil Using Microreactor Assisted with Ultrasonic Mixing. Ultrason. Sonochem. 2020, 60, 104764. [Google Scholar] [CrossRef]
- Sarve, A.; Sonawane, S.S.; Varma, M.N. Ultrasound Assisted Biodiesel Production from Sesame (Sesamum indicum L.) Oil Using Barium Hydroxide as a Heterogeneous Catalyst: Comparative Assessment of Prediction Abilities between Response Surface Methodology (RSM) and Artificial Neural Network (ANN). Ultrason. Sonochem. 2015, 26, 218–228. [Google Scholar] [CrossRef] [PubMed]
- Najafi, B.; Faizollahzadeh Ardabili, S. Application of ANFIS, ANN, and Logistic Methods in Estimating Biogas Production from Spent Mushroom Compost (SMC). Resour. Conserv. Recycl. 2018, 133, 169–178. [Google Scholar] [CrossRef]
- Khashei-Siuki, A.; Sarbazi, M. Evaluation of ANFIS, ANN, and Geostatistical Models to Spatial Distribution of Groundwater Quality (Case Study: Mashhad Plain in Iran). Arab. J. Geosci. 2015, 8, 903–912. [Google Scholar] [CrossRef]
- Nagi, R.; Aravinda, K.; Rakesh, N.; Gupta, R.; Pal, A.; Mann, A.K. Clinical Applications and Performance of Intelligent Systems in Dental and Maxillofacial Radiology: A Review. Imaging Sci. Dent. 2020, 50, 81–92. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Madkour, D.M.; Shapiai, M.I.; Mohamad, S.E.; Aly, H.H.; Ismail, Z.H.; Ibrahim, M.Z. A Systematic Review of Deep Learning Microalgae Classification and Detection. IEEE Access 2023, 11, 57529–57555. [Google Scholar] [CrossRef]
- Gashler, M.; Giraud-Carrier, C.; Martinez, T. Decision Tree Ensemble: Small Heterogeneous Is Better Than Large Homogeneous. In Proceedings of the 2008 Seventh International Conference on Machine Learning and Applications, San Diego, CA, USA, 11–13 December 2008; pp. 900–905. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a Convolutional Neural Network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Neo, Y.T.; Chia, W.Y.; Lim, S.S.; Ngan, C.L.; Kurniawan, T.A.; Chew, K.W. Smart Systems in Producing Algae-Based Protein to Improve Functional Food Ingredients Industries. Food Res. Int. 2023, 165, 112480. [Google Scholar] [CrossRef]
- Gayathri, J.; Meenakshi, V.; Malathi, C.; Kanaga, G.; Radhika, S.; Kaveri, V.V. Generating an IOT Based Knowedgebase to Analyze The Microalgae Growth. In Proceedings of the 2024 10th International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 12–14 April 2024; pp. 104–108. [Google Scholar] [CrossRef]
- Shamayleh, A.; Awad, M.; Farhat, J. IoT Based Predictive Maintenance Management of Medical Equipment. J. Med. Syst. 2020, 44, 72. [Google Scholar] [CrossRef]
- Lowe, M.; Qin Ruwen, M.X. A Review on Machine Learning, Artificial Intelligence, and Smart Technology in Water Treatment and Monitoring. Water 2022, 14, 1384. [Google Scholar] [CrossRef]
- Tham, P.E.; Ng, Y.J.; Vadivelu, N.; Lim, H.R.; Khoo, K.S.; Chew, K.W.; Show, P.L. Sustainable Smart Photobioreactor for Continuous Cultivation of Microalgae Embedded with Internet of Things. Bioresour. Technol. 2022, 346, 126558. [Google Scholar] [CrossRef]
- Zambon, I.; Cecchini, M.; Egidi, G.; Saporito, M.G.; Colantoni, A. Revolution 4.0: Industry vs. Agriculture in a Future Development for SMEs. Processes 2019, 7, 36. [Google Scholar] [CrossRef]
- Giannino, F.; Esposito, S.; Diano, M.; Cuomo, S.; Toraldo, G. A Predictive Decision Support System (DSS) for a Microalgae Production Plant Based on Internet of Things Paradigm. Concurr. Comput. 2018, 30, e4476. [Google Scholar] [CrossRef]
- Bumbac, C.; Manea, E.; Banciu, A.; Stoica, C.; Ionescu, I.; Badescu, V.; Lazar, M.N. Identification of Physical, Morphological and Chemical Particularities of Mixed Microalgae-Bacteria Granules. Rev. Chim. 2019, 70, 275–277. [Google Scholar] [CrossRef]
- Liu, F.; Zhang, C.; Wang, Y.; Chen, G. A Review of the Current and Emerging Detection Methods of Marine Harmful Microalgae. Sci. Total Environ. 2022, 815, 152913. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Carleo, G.; Cirac, I.; Cranmer, K.; Daudet, L.; Schuld, M.; Tishby, N.; Vogt-Maranto, L.; Zdeborová, L. Machine Learning and the Physical Sciences. Rev. Mod. Phys. 2019, 91, 045002. [Google Scholar] [CrossRef]
- Giraldo-Zuluaga, J.H.; Salazar, A.; Diez, G.; Gomez, A.; Martínez, T.; Vargas, J.F.; Peñuela, M. Automatic Identification of Scenedesmus Polymorphic Microalgae from Microscopic Images. Pattern Anal. Appl. 2018, 21, 601–612. [Google Scholar] [CrossRef]
- Sonmez, M.E.; Eczacıoglu, N.; Gumuş, N.E.; Aslan, M.F.; Sabanci, K.; Aşikkutlu, B. Convolutional Neural Network-Support Vector Machine Based Approach for Classification of Cyanobacteria and Chlorophyta Microalgae Groups. Algal Res. 2022, 61, 102568. [Google Scholar] [CrossRef]
- Zheng, J.; Cole, T.; Zhang, Y.; Bayinqiaoge, N.; Yuan, D.; Tang, S.Y. An Automated and Intelligent Microfluidic Platform for Microalgae Detection and Monitoring. Lab Chip 2023, 24, 244–253. [Google Scholar] [CrossRef]
- Ansari, F.A.; Nasr, M.; Rawat, I.; Bux, F. Artificial Neural Network and Techno-Economic Estimation with Algae-Based Tertiary Wastewater Treatment. J. Water Process Eng. 2021, 40, 101761. [Google Scholar] [CrossRef]
- Onay, A. Theoretical Models Constructed by Artificial Intelligence Algorithms for Enhanced Lipid Production: Decision Support Tools. Bitlis Eren Üniversitesi Fen Bilim. Derg. 2023, 12, 1195–1211. [Google Scholar] [CrossRef]
- Reimann, R.; Zeng, B.; Jakopec, M.; Burdukiewicz, M.; Petrick, I.; Schierack, P.; Rödiger, S. Classification of Dead and Living Microalgae Chlorella Vulgaris by Bioimage Informatics and Machine Learning. Algal Res. 2020, 48, 101908. [Google Scholar] [CrossRef]
- Hisham, S.D.; Mohamad, S.E.; Shapiai, M.I.; Iwamoto, K.; Hussin, A.A.; Abdullah, N.; Akhir, F.N.M. Comparison of Conventional CNN Sequential API and Functional API for Microalgae Identification. J. Adv. Res. Micro Nano Eng. 2024, 17, 96–104. [Google Scholar] [CrossRef]
- Hossain, S.M.Z.; Sultana, N.; Razzak, S.A.; Hossain, M.M. Modeling and Multi-Objective Optimization of Microalgae Biomass Production and CO2 Biofixation Using Hybrid Intelligence Approaches. Renew. Sustain. Energy Rev. 2022, 157, 112016. [Google Scholar] [CrossRef]
- Saini, D.K.; Rai, A.; Devi, A.; Pabbi, S.; Chhabra, D.; Chang, J.S.; Shukla, P. A Multi-Objective Hybrid Machine Learning Approach-Based Optimization for Enhanced Biomass and Bioactive Phycobiliproteins Production in Nostoc sp. CCC-403. Bioresour. Technol. 2021, 329, 124908. [Google Scholar] [CrossRef]
- Ching, P.M.L.; Mayol, A.P.; San Juan, J.L.G.; Calapatia, A.M.; So, R.H.Y.; Sy, C.L.; Ubando, A.T.; Culaba, A.B. AI Methods for Modeling the Vacuum Drying Characteristics of Chlorococcum Infusionum for Algal Biofuel Production. Process Integr. Optim. Sustain. 2021, 5, 247–256. [Google Scholar] [CrossRef]
- Sultana, N.; Hossain, S.M.Z.; Abusaad, M.; Alanbar, N.; Senan, Y.; Razzak, S.A. Prediction of Biodiesel Production from Microalgal Oil Using Bayesian Optimization Algorithm-Based Machine Learning Approaches. Fuel 2022, 309, 122184. [Google Scholar] [CrossRef]
- Sarkar, S.; Manna, M.S.; Bhowmick, T.K.; Gayen, K. Extraction of Chlorophylls and Carotenoids from Dry and Wet Biomass of Isolated Chlorella Thermophila: Optimization of Process Parameters and Modelling by Artificial Neural Network. Process Biochem. 2020, 96, 58–72. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, C. Using Genetic Algorithm to Optimize Artificial Neural Network: A Case Study on Earthquake Prediction. In Proceedings of the 2008 Second International Conference on Genetic and Evolutionary Computing, Jinzhou, China, 25–26 September 2008; pp. 128–131. [Google Scholar] [CrossRef]
- Mayol, A.P.; San Juan, J.L.G.; Sybingco, E.; Bandala, A.; Dadios, E.; Ubando, A.T.; Culaba, A.B.; Chen, W.H.; Chang, J.S. Environmental Impact Prediction of Microalgae to Biofuels Chains Using Artificial Intelligence: A Life Cycle Perspective. IOP Conf. Ser. Earth Environ. Sci. 2020, 463, 012011. [Google Scholar] [CrossRef]
- Jabbarzadeh, A.; Shamsi, M. Designing a Resilient and Sustainable Multi-Feedstock Bioethanol Supply Chain: Integration of Mathematical Modeling and Machine Learning. Appl. Energy 2025, 377, 123794. [Google Scholar] [CrossRef]
- Yang, C.T.; Kristiani, E.; Leong, Y.K.; Chang, J.S. Machine Learning in Microalgae Biotechnology for Sustainable Biofuel Production: Advancements, Applications, and Prospects. Bioresour. Technol. 2024, 413, 131549. [Google Scholar] [CrossRef]
- Jambol, D.D.; Sofoluwe, O.O.; Ukato, A.; Ochulor, O.J. Transforming Equipment Management in Oil and Gas with AI-Driven Predictive Maintenance. Comput. Sci. IT Res. J. 2024, 5, 1090–1112. [Google Scholar] [CrossRef]
- Khedr, A.M. Enhancing Supply Chain Management with Deep Learning and Machine Learning Techniques: A Review. J. Open Innov. Technol. Mark. Complex. 2024, 10, 100379. [Google Scholar] [CrossRef]
- Soori, M.; Arezoo, B.; Dastres, R. Digital Twin for Smart Manufacturing, A Review. Sustain. Manuf. Serv. Econ. 2023, 2, 100017. [Google Scholar] [CrossRef]
- Ali, S.; Abuhmed, T.; El-Sappagh, S.; Muhammad, K.; Alonso-Moral, J.M.; Confalonieri, R.; Guidotti, R.; Del Ser, J.; Díaz-Rodríguez, N.; Herrera, F. Explainable Artificial Intelligence (XAI): What We Know and What Is Left to Attain Trustworthy Artificial Intelligence. Inf. Fusion 2023, 99, 101805. [Google Scholar] [CrossRef]
- Kelly, S.; Kaye, S.A.; Oviedo-Trespalacios, O. What Factors Contribute to the Acceptance of Artificial Intelligence? A Systematic Review. Telemat. Inform. 2023, 77, 101925. [Google Scholar] [CrossRef]
- Balasubramaniam, N.; Kauppinen, M.; Rannisto, A.; Hiekkanen, K.; Kujala, S. Transparency and Explainability of AI Systems: From Ethical Guidelines to Requirements. Inf. Softw. Technol. 2023, 159, 107197. [Google Scholar] [CrossRef]
- Murikah, W.; Nthenge, J.K.; Musyoka, F.M. Bias and Ethics of AI Systems Applied in Auditing—A Systematic Review. Sci. Afr. 2024, 25, e02281. [Google Scholar] [CrossRef]
- Regona, M.; Yigitcanlar, T.; Hon, C.; Teo, M. Artificial Intelligence and Sustainable Development Goals: Systematic Literature Review of the Construction Industry. Sustain. Cities Soc. 2024, 108, 105499. [Google Scholar] [CrossRef]
- Plathottam, S.J.; Rzonca, A.; Lakhnori, R.; Iloeje, C.O. A Review of Artificial Intelligence Applications in Manufacturing Operations. J. Adv. Manuf. Process. 2023, 5, e10159. [Google Scholar] [CrossRef]
- Aldoseri, A.; Al-Khalifa, K.N.; Hamouda, A.M. Re-Thinking Data Strategy and Integration for Artificial Intelligence: Concepts, Opportunities, and Challenges. Appl. Sci. 2023, 13, 7082. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| AI/ML Algorithms | Merits | Demerits |
|---|---|---|
| Support Vector Machine | Flexible Capable of managing high-dimensional data Excellent precision Well-suited for tasks involving binary classification | Sensitive to nonlinear kernel functions Requiring greater computational resources Time consuming in processing large datasets Low training efficiency |
| Genetic Algorithm | Avoiding local minima Versatile Optimize problems involving multiple variables No need for data pre-processing | Risk of premature convergence Requiring greater computational resources Time consuming |
| K-Nearest Neighbor | Simple implementation Well-suited for multi-layered data | Needs distance computation |
| Decision Tree | Simpler for handling quantitative and specific data Data scaling is not required Missing data can be handled | Requiring larger dataset Risk of overfitting Challenging to control the size of the tree |
| Random Forest | Highly flexible Resistant to overfitting Quicker to train Efficient for nonlinear data | Not ideal for small-sized data variables Computationally intensive Inadequate convergence |
| Artificial Neural Network | Highly adaptive Fault-tolerant system Skilled at capturing complex, multilayered interactions Helps mitigate process disturbances | Risk of overfitting Requiring data pre-processing Time-consuming training Complexity of ANN architectures |
| Process | AI/ML Algorithms | Application | Strain | Accuracy | Reference |
|---|---|---|---|---|---|
| Classification | RF | Classifying dead or alive microalgae populations | Chlorella vulgaris | 94.50% | [97] |
| CNN | Classification | Acutodesmus obliquus, Monoraphidium sp., Spirullina sp., Tetradesmus deserticola, Desmodesmus perforatus | 89.00% | [98] | |
| ANN | Classification | Chlorella, Scenedesmus, Haematococcus, Synechococcus, Chlamydopodium, and Docystidium | 97.27% | [70] | |
| SVM | Classification | Cyanobacteria and Chlorophyta | 99.66% | [93] | |
| k-NN | Classification | Chlorella vulgaris FSP-E, Chlamydomonas reinhardtii, and Spirulina platensis | 96.93% | [58] | |
| Upstream microalgae processes | ANN | Optimization of wastewater concentration, chitinase, and lysozyme for lipid content | Chlorella minutissima | 96.34% | [96] |
| ANN | Optimization of temperature, pH, DO, EC, NO3−, and PO43− to predict dry cell weight | Scenedesmus sp., and Chlorella sp. | 98.30% | [95] | |
| SVR | Examination of the effects of temperature, light–dark cycles, and nitrogen–phosphorus ratios on the CO2 biofixation | Chlorella vulgaris | 91.10% | [99] | |
| GA-ANFIS | Evaluation of temperature, pH, CO2, and nitrogen and phosphorus levels to predict CO2 fixation rates | Various algal strains | 98.46% | [23] | |
| CNN-GA | Optimization of BG-11 media components and pH to maximize PBP production and cell growth | Nostoc sp. CCC-403 | - | [100] | |
| Downstream microalgae processes | ANN | Evaluation of temperature, pressure, and moisture content to predict the efficiency of the vacuum drying process | Chlorococcum infusionum | - | [101] |
| SVR | Examination of the catalyst dosage, reaction time, reaction temperature, and oil-to-methanol ratio to predict biodiesel yields | Nannochloropsis oculate | 99.10% | [102] | |
| ANN | Optimization of extraction parameters to predict the yields of chlorophylls and carotenoids | Chlorella thermophila | 98.30% | [103] | |
| RSM-ANN-GA | Optimization of temperature, time, and methanol/oil molar ratio to predict conversion yield in transesterification | Chlorella CG12 | 99.16% | [39] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Imamoglu, E. Artificial Intelligence and/or Machine Learning Algorithms in Microalgae Bioprocesses. Bioengineering 2024, 11, 1143. https://doi.org/10.3390/bioengineering11111143
Imamoglu E. Artificial Intelligence and/or Machine Learning Algorithms in Microalgae Bioprocesses. Bioengineering. 2024; 11(11):1143. https://doi.org/10.3390/bioengineering11111143
Chicago/Turabian StyleImamoglu, Esra. 2024. "Artificial Intelligence and/or Machine Learning Algorithms in Microalgae Bioprocesses" Bioengineering 11, no. 11: 1143. https://doi.org/10.3390/bioengineering11111143
APA StyleImamoglu, E. (2024). Artificial Intelligence and/or Machine Learning Algorithms in Microalgae Bioprocesses. Bioengineering, 11(11), 1143. https://doi.org/10.3390/bioengineering11111143