2. Methods
The authors strictly adhered to the TRIPOD (transparent reporting of a multivariable prediction model for individual prognosis or diagnosis) and STROBE (strengthening the reporting of observational studies in epidemiology) reporting guidelines.
2.1. Participants and Data Source
For this cohort study, we analyzed data prospectively collected from patients with aneurysmal subarachnoid hemorrhage (aSAH) who were admitted to the neurosurgical intensive care unit at the University Hospital of Zurich between October 2016 and November 2022. The data collection was carried out via a CNS data collector (Moberg ICU Solutions, Ambler, PA, USA) and the high-resolution data were processed and stored by “ICU Cockpit”, our dedicated information technology infrastructure [
11]. The study received approval from the ethics committee of Kanton Zurich (Basec Nr. 2016-01101), Switzerland. Patients were included in the study after written consent had been obtained from patients or their legal representatives.
2.2. Diagnostics and Treatment
Clinical management was based on the guidelines of the American Heart Association [
12,
13]. Magnetic resonance imaging (MRI) or computed tomography (CT) scans including CT angiography/perfusion were performed if patients met the following criteria: delayed neurological deterioration (DND) defined as a >2-point change in Glasgow Coma Scale (GCS) or a new focal neurological deficit lasting >1 h and not associated with aneurysmal coiling or clipping [
14]. Transcranial Doppler sonography with measurements of mean blood flow velocities were performed daily. In unconscious or sedated patients, multimodal neuromonitoring brain tissue oxygen measurements and cerebral microdialysis were performed. In these patients, a decrease in ptiO2 <20 mmHg and/or an increase in the lactate/pyruvate coefficient above 40 led to one of the abovementioned imaging techniques. Hypertensive therapy was induced with DND and vasospasm in CT-angiography or CT perfusion deficit, respectively, as first line therapy. If patients did not improve or worsened neurologically, or if values from multimodal monitoring did not improve, neuroradiological interventional therapy with intraarterial nimodipine instillation and/or percutaneous balloon angioplasty was performed as second line therapy.
2.3. Prediction Target
The outcome, i.e., prediction target, was the first occurrence of delayed cerebral ischemia (DCI). DCI was defined as new infarctions in MRI or CT scans, and/or a confirmed perfusion deficit detected in perfusion CT or MRI between day 4 and day 14 after the onset of symptoms (not present on imaging performed within 24 to 48 h after aneurysm occlusion and not attributable to other causes). We focused only on the first occurrence of DCI excluding any successive instances to avoid the consequent lack of explainability arising from interfering, overlapping DCI symptoms, and predictors.
2.4. Predictors
The dataset comprised 30 laboratory findings and 15 values from blood gas analysis, routinely measured in aSAH patients, as well as routinely collected demographics consisting of age, gender, Glasgow Coma Scale, and comorbidities, such as diabetes, cardio-vascular disease, and hypertension. Additionally, standard SAH gradings were considered, including the Hunt and Hess scale, modified Fisher scale, World Federation of Neurosurgical Societies grading system, and the Barrow Neurological Institute grading scale [
15,
16,
17,
18]. Data used in this study were collected based on the ICU Cockpit IT infrastructure [
11].
2.5. Pre-Processing and Missing Data
In a first step, the longitudinal data of each patient were individually aligned with respect to the time of symptom onset and resampled to a sampling time of one per hour. Forward filling was employed to address gaps in the resampled time series caused by the intermittent data collection of laboratory and blood gas analysis results, thereby always considering the latest value as the current value for each predictor.
Clinical data were acquired prospectively. In case of missing data, during retrospective supplementation of the clinical data, care was taken that patients had a complete set of patient characteristics and SAH gradings where possible. Moreover, by only including commonly measured laboratory findings and blood gas analysis results as longitudinal predictors, missing data could be kept to a minimum. Nonetheless, to allow for incomplete predictor vectors also at time of prediction, all model pipelines evaluated in this study included a simple median imputer as a pre-processing step.
2.6. Data Modeling
The modeling task was divided into two sub-tasks: modeling predictors that remained constant after recording at admission and time-varying predictors that changed during the ICU stay (i.e., laboratory findings, blood gas analysis results, with age as the only exception). Separate groups of models were developed for each task and subsequently evaluated using 10-fold nested cross-validation. These two groups of models are referred to as static and dynamic models, respectively. The cross-validation folds were stratified to ensure equal DCI prevalence, and the stratification grouped the data in such a way that information from a specific patient appeared only in a single fold. The primary metric used for model evaluation was the area under the receiver operating characteristics curve (ROC AUC), which was also utilized in the optimization procedures during model training.
For both groups of models, the modeling task was framed as a classification problem. For static models, the task was to distinguish between patients that eventually experienced a DCI from those that did not. For the dynamic models, the goal was to differentiate between patients that would or would not experience a DCI during the subsequent 48 h. For the latter, we used the first DCI event as an anchor following an approach presented by Megjhani et al. [
10]. For patients with no DCI event, the anchor was set to the median time between symptom onset and first DCI occurrence, the latter calculated from patients with DCI. Importantly, for each patient, we included all 48 data points (hourly predictor vectors) leading up to the anchor in the development dataset. This was done to account for the varying degree of variation in the dynamic predictor values over the considered 48 h time window before the anchors.
The evaluated static models, i.e., models trained only on static predictors, comprised Logistic Regression models with L1 and L2 penalty, Support Vector Classifier, Random Forests, Extremely Randomized Trees, and Histogram-based Gradient Boosting Classification Tree. For the Logistic Regression and Support Vector Classifier models, the predictors were centered around zero and scaled to have unit variance. Class weights were adjusted in ensemble models to balance the dataset. Furthermore, hyperparameter tuning was performed and sequential feature selection was evaluated in comparison with a set of baseline models based on default parameters and all predictors.
The dynamic models included Logistic Regression models, Extremely Randomized Trees, and Histogram-based Gradient Boosting Classification Tree. As optimization routes, we explored Principal Component Analysis (PCA), Feature Selection based on Gini-Importance (FS from Model), and Recurrent Feature Elimination (RFE) in combination with hyperparameter tuning. Again, class weights were adjusted in training ensemble models to balance the dataset.
Finally, we also evaluated a model combining the static and the dynamic models in a voting model. The voting model computed its output score as the arithmetic average of the static and dynamic scores and was not separately trained.
The data modelling was performed using Python 3.9.12 and the machine learning module scikit-learn version 1.1.1.
2.7. Leave-One-Out Simulation
In addition to the anchored ROC analysis, leave-one-out (LOO) simulation was conducted to evaluate the model’s ability to predict DCI in a scenario more closely resembling the clinical setting in which the models would regularly produce new risk assessments. Due to the considerable amount of time required to train all the different evaluated classifiers, we restricted the LOO simulation analysis to the best performing models in the anchored analysis. For each run of the LOO simulation, a single patient was excluded from the development set and the models were re-trained on the data of the remaining patients. We then used these newly trained models to predict hourly risk scores for the left-out patient for their entire ICU stay. The procedure was repeated until we had computed hourly risk scores for all patients. Finally, time-dependent ROC analyses were performed to evaluate and summarize the performance of the models trained on the leave-one-out datasets.
In a first approach, the overall ability of the models to differentiate between the two groups of patients with and without eventual DCI occurrence was studied. The output scores of the models were plotted for the two groups together with the time-dependent ROC AUC values.
Next, the focus was shifted from classification regarding eventual DCI occurrence towards DCI occurrence in the following 48 h. The latter being arguably the clinically more relevant question to be answered by a prediction tool. To this end, we evaluated whether the scores during the 48 h period before a DCI occurrence were significantly higher compared to the periods before or in patients with no DCI at all. This comparison was first carried out by pooling all the hourly risk scores from the entire ICU stays and a second time in a time-resolved manner in order to study the performance of the prediction model as function of time starting with the time of symptom onset. For the latter, the considered time frame from day 2 to day 14 was divided into 5 intervals of equal proportions of time-points that were followed by a DCI.
Importantly, when analyzing the predictions for the next 48 h, the risk set, i.e., the patients being assessed, was continuously adjusted to contain solely patients who had not experienced a DCI event. In other words, once patients suffered from a DCI, they were excluded from the set of analyzed patients.
2.8. Statistical Analysis
The Mann–Whitney U-test was used for comparing continuous and ordinal variables and the Fisher exact test for binary variables. Statistical significance was assumed at p < 0.05. Effect size was quantified using the ROC AUC value, where a value above 0.5 indicates a positive association and below 0.5 a negative association with the outcome. Confidence intervals for the ROC AUC values in the time-dependent ROC analysis were computed via bootstrapping.
3. Results
3.1. Participants
In total, the data of 222 patients were analyzed. Of these patients, 218 patients had data in the relevant time frame for DCI occurrence between day 4 and 14 and were included in the development set. DCI occurred in 89 (41%) of patients. An overview of the patient characteristics is shown in
Table 1. With a median age of 57 years and a higher proportion of females (63.8%), this cohort is representative of typical subarachnoid hemorrhage patients. The severity of subarachnoid hemorrhage, as assessed by clinical scales (WFNS, Hunt and Hess), showed no significant association with the development of DCI in our cohort. In contrast, the severity classification based on imaging findings (mFS, BNI) yielded different results. Statistical analysis revealed that only the Barrow Neurological Institute (BNI) grading scale was significantly associated with DCI occurrence.
3.2. Model Development and Model Specification
From the 218 patients in the development set, 10,470 predictor vectors were sampled for the 48 h before the anchor, each containing a total of 60 static and dynamic parameters. On average, 3.6% and 7.2% of the static and dynamic parameters were missing, respectively. The dataset was sightly unbalanced with 41% of the patients experiencing at least one DCI event. 14 static and 19 dynamic model pipelines of different complexity were defined and evaluated.
3.3. Performance of Model Building Pipelines (Cross-Validation)
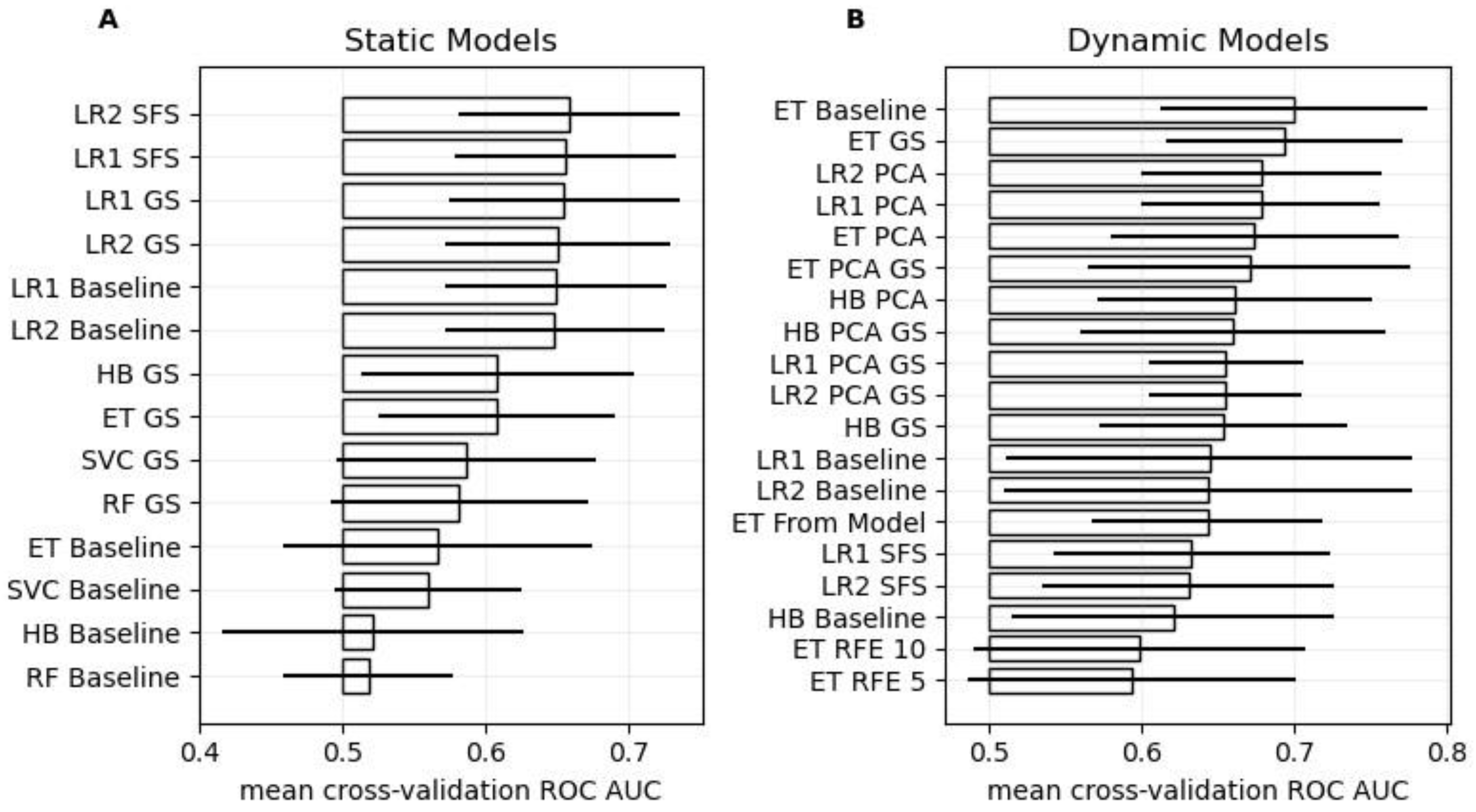
The results of the cross-validation results are presented and summarized in
Figure 1.
Among the static models, hyper-parameter tuning improved model performance across all models. The simple Logistic Regression models outperformed the more complex machine learning models. Specifically, the Logistic Regression model with Sequential Feature Selection and the L2 loss-function showed the best performance (ROC AUC: 0.66 ± 0.08). When trained on the entire development set, this pipeline selected the BNI grading scale, the WFNS, diabetes, hypertension, and cardiovascular disease as predictors, along with a high regularization parameter (C = 10) during hyper-parameter tuning.
Regarding the dynamic models, the baseline Extremely Randomized Trees (ET) model achieved the best performance (ROC AUC: 0.70 ± 0.09), while the ET GS model with hyper-parameter tuning ranked second (ROC AUC: 0.69 ± 0.08). Consequently, the ET GS model was used in the combined model as well as in subsequent leave-one-out analysis, as it shows a similar performance as the ET baseline model, while having its model parameters learnt from the data. When trained on the entire development set, the optimized parameters of the ET GS model for the maximal tree depth and the number of selectable features at the decision nodes were determined as 8 and 10, respectively.
Using the best static and the selected optimized dynamic model in a combined model resulted in a superior model achieving a ROC AUC of 0.73 ± 0.05.
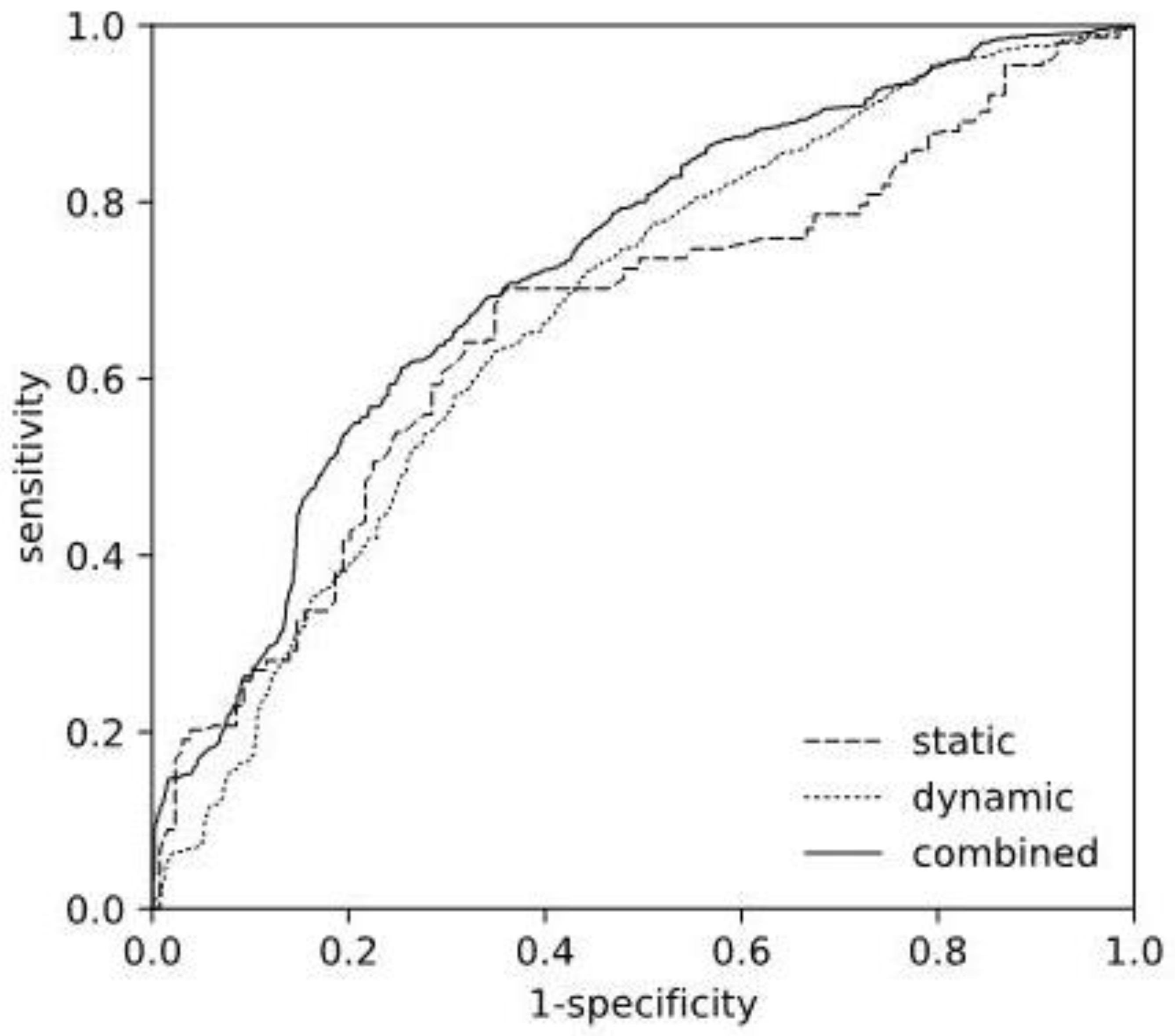
Figure 2 depicts the corresponding ROC curves of the selected static and dynamic models, as well as the resulting combined model. The ROC curve computations were based on the cross-validation scores, thus, represent an average over the individual models fitted during cross-validation.
3.4. Model Performance (Leave-One-Out)
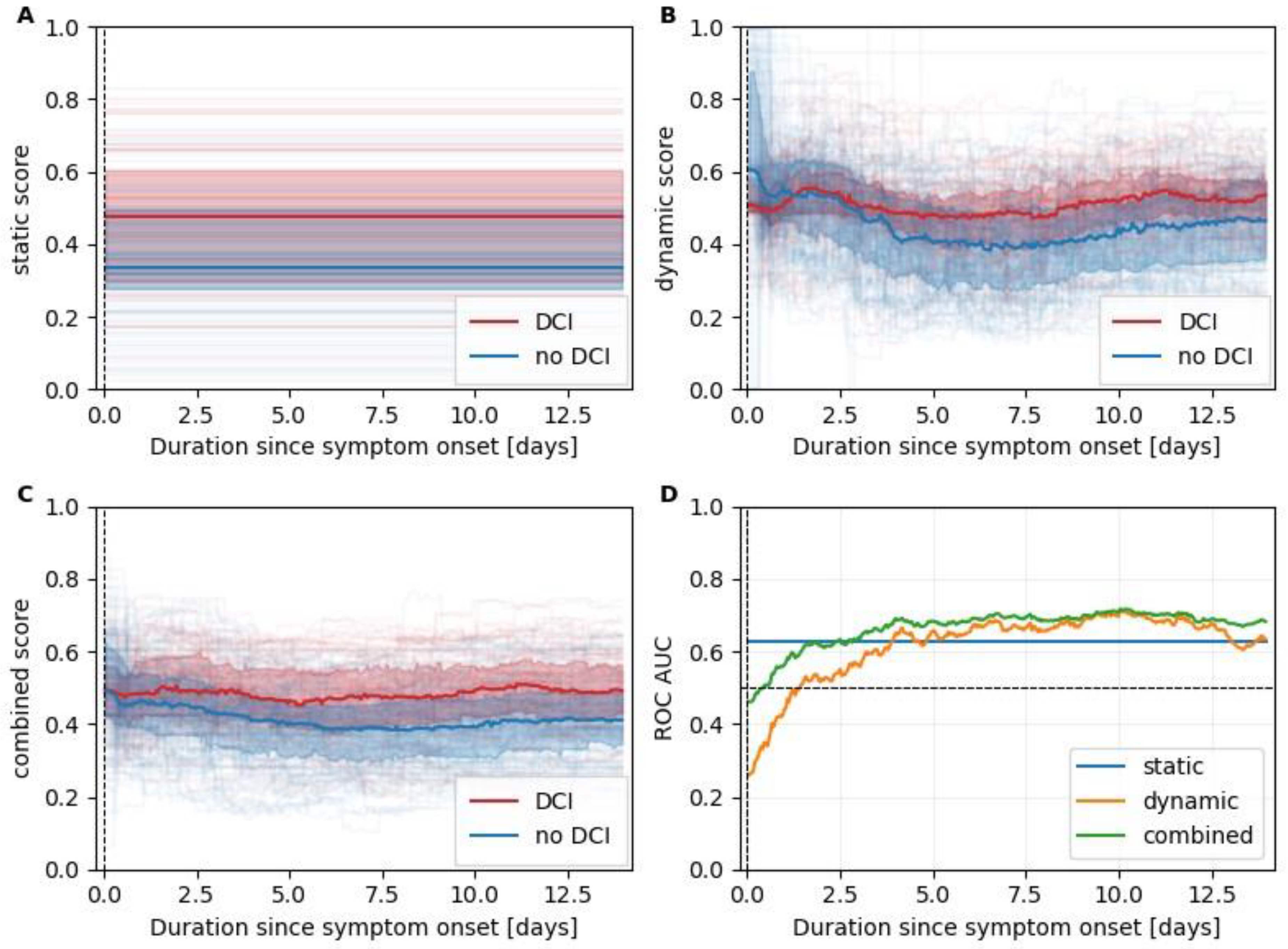
Figure 3 shows the scores of the selected static, dynamic and the resulting combined models as computed in the LOO simulation. While the output of the static model naturally stayed constant over the entire stay, with scores higher for the patients in the DCI group, the outputs of the dynamic and combined model changed continuously. After day 2, the scores of the dynamic DCI group visibly surpass the ones of the static DCI group and show a ROC AUC value above 0.5, further increasing until day 6 when it starts saturating at around 0.67, reaching a maximum of 0.715 on day 10.
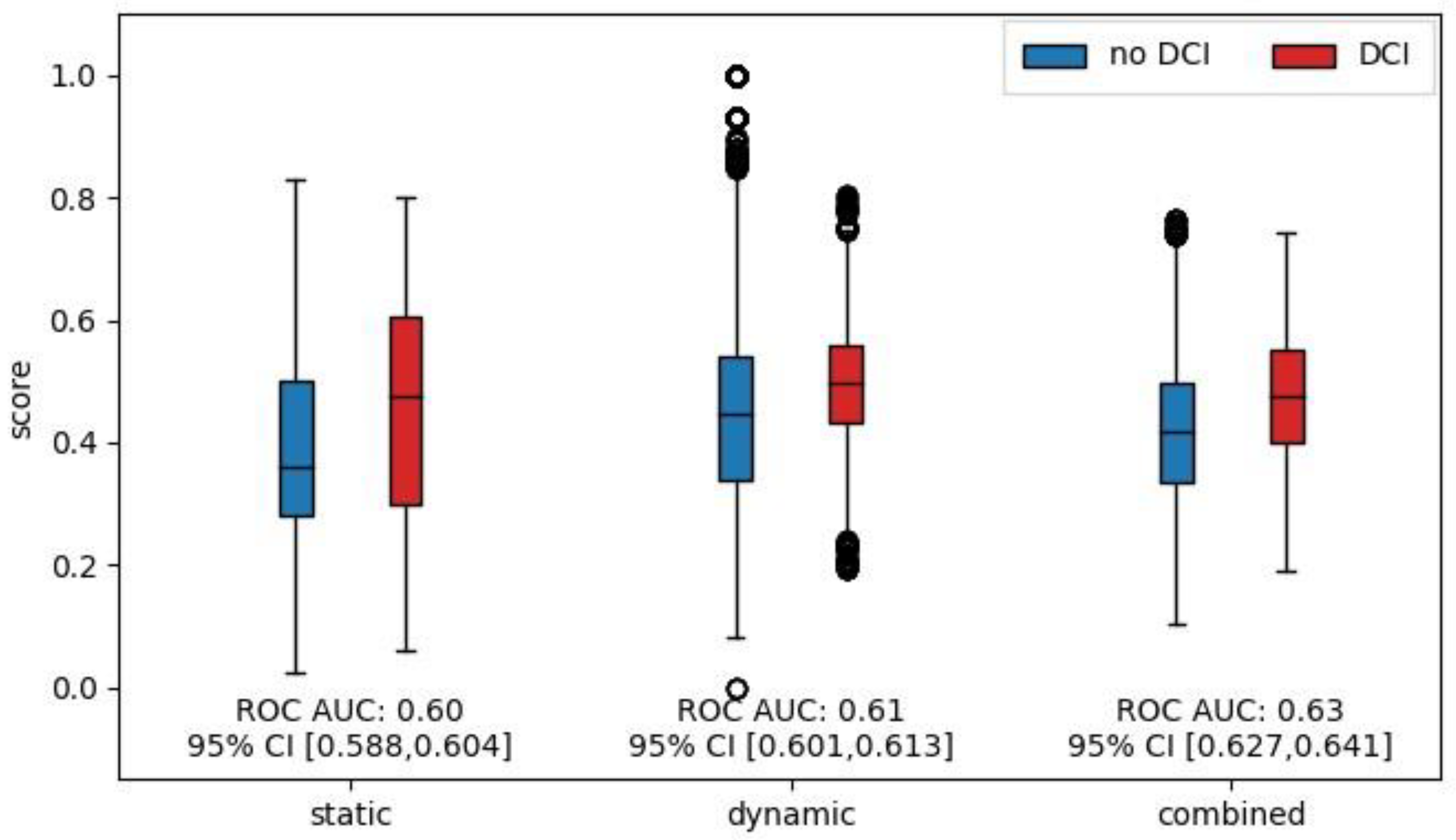
When analyzing the performance of DCI prediction for the following 48 h, we found that the risk scores were significantly higher for all three models during the 48 h leading up to a DCI occurrence compared to when no DCI occurred. Corresponding boxplots are shown in
Figure 4. The effect sizes measured by the ROC AUC were 0.60, 0.61, and 0.63 for the static, dynamic, and combined model, respectively.
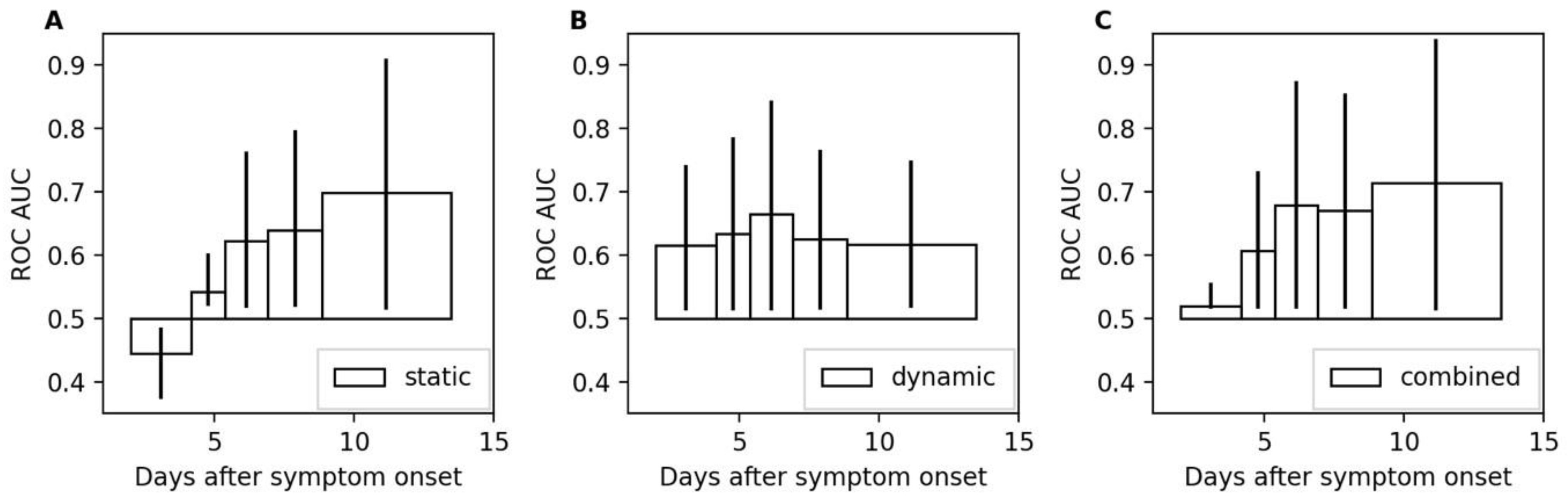
To study the time-dependence of the model performances, five time-intervals were computed with equal numbers of samples (e.g., hours) followed by a DCI during subsequent 48 h. The intervals were (i) day 2 until day 4.2, (ii) day 4.2 until day 5.4, (iii) day 5.4 until day 6.9, (iv) day 6.9 until day 8.8, and (v) day 8.8 until day 14. The different lengths stemmed from the uneven distribution of DCI occurrences after SAH. The ROC AUC values for all three models are shown in
Figure 5. The static model showed the strongest time dependence with a ROC AUC that was below 0.5 in the first interval. The dynamic model is more stable, achieving ROC AUC values between 0.62 and 0.67. The dynamic model is the best-performing model for the first two intervals until day 5.4. From day 5.4 onwards, the combined model shows the best performances with ROC AUC values of 0.68, 0.67, and 0.71 for the third, fourth, and fifth intervals, respectively.
To make the scores more interpretable, thresholds were computed that achieve a sensitivity level of 80%.
Table 2 presents these thresholds along with the corresponding specificity for each interval. The thresholds depend on the considered time intervals and increase together with the corresponding ROC AUC value.
4. Discussion
Numerous scoring systems exist for risk stratification in aSAH patients. However, a critical need persists for continuously updating clinical support tools that enhance situational awareness. Recently, Megjhani et al. presented a set of machine learning models trained on vital sign parameters and patient demographics using DCI occurrence as an anchor to train binary classifiers [
10]. While their models demonstrated robust performance when applied to other centers, their analysis was limited to anchored data. In addition, there is the ongoing problem that models developed are not validated on live data streams. These limitations hinder the assessment of their applicability in real-world clinical practice, where the anchor is unknown, and data are aligned with symptom onset or hospital/ICU admission.
Adopting the anchoring approach in building our development dataset, we trained well-performing static and dynamic models evaluating a range of machine learning model types. Furthermore, disentangling static and dynamic parameters allowed us to come up with a more transparent combined model that permits reasoning about the different model contributions.
To justify the anchoring approach used and to evaluate the resulting models within a scenario closely resembling clinical practice, we conducted time-dependent ROC analysis using scores generated through a leave-one-out simulation. This allowed us to investigate the performance not anchored to the DCI events anymore but to symptom onset, which is what a clinician would experience in clinical practice. Our time-dependent analysis of the scores showed that the dynamic model does indeed produce highly time-dependent results. Interestingly, when grouping patients by eventual DCI occurrence, the median dynamic score initially trended even higher in the patients without eventual DCI before declining below the DCI patients around day 4, indicating that the correlations learned by the dynamic model from the anchored dataset are not indicative for DCI in the early phase of the patient’s ICU stay.
Moreover, focusing on the 48 h before DCI onset, we confirmed significantly higher scores for all models compared to other periods. Additionally, partitioning the time interval up to day 14 into five intervals revealed that model performance strongly depends on the duration from symptom onset. While temporal variation in the static model’s performance is influenced by changes in the risk set, the dynamic model’s performance is governed by disease progression and corresponding fluctuations in laboratory and blood gas analysis results.
These temporal variations in model performance underscore the challenges associated with longitudinal models, including the need to adapt threshold interpretation over time to maintain consistent sensitivity. Furthermore, selecting the appropriate model or sub-model is crucial for achieving optimal risk assessment. The recommended strategy is to utilize the dynamic model until day 5.4 and then switch to the combined model.
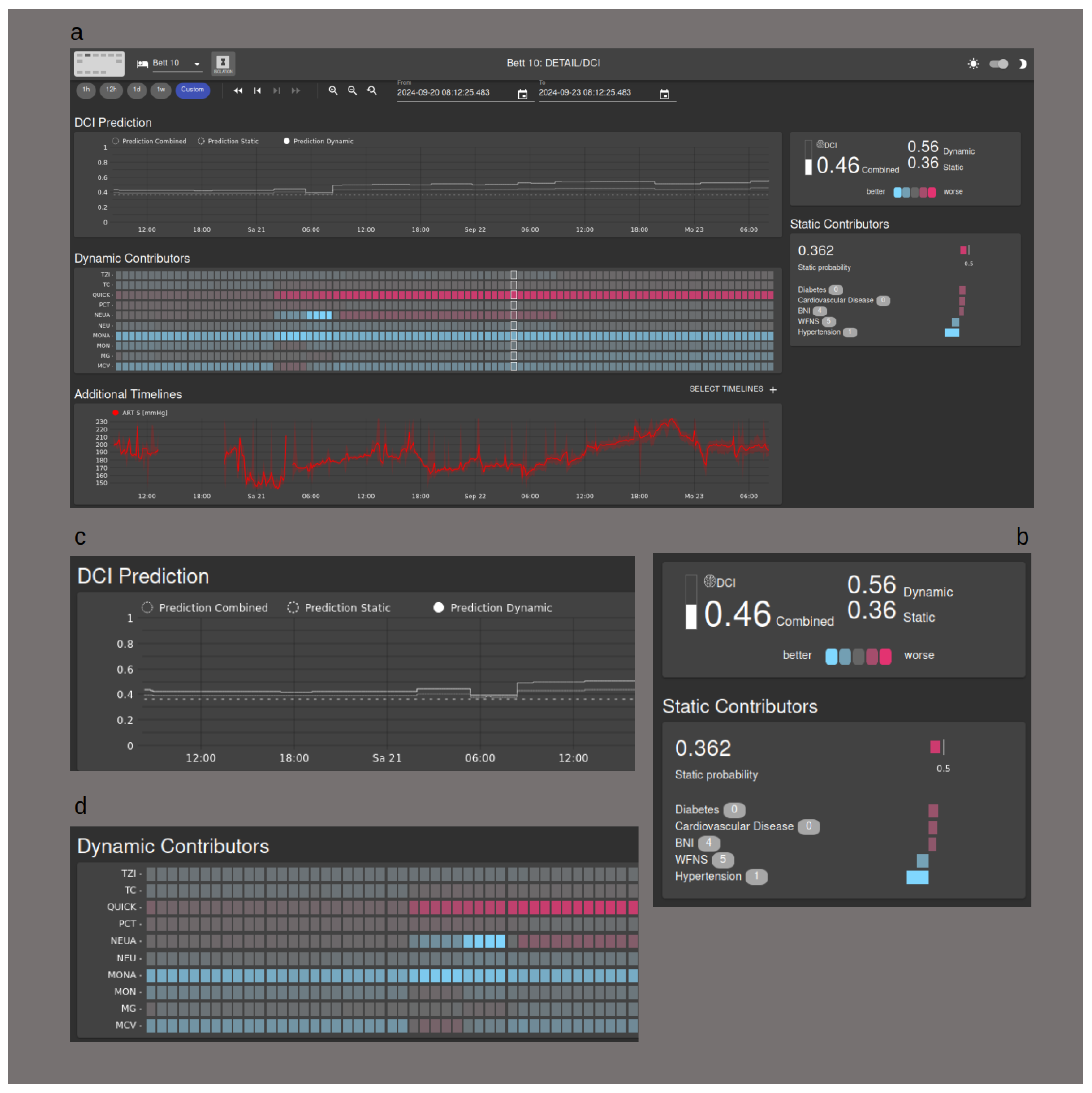
A key objective for our team is to obtain direct clinical experience with our support system. To facilitate this, we deliberately selected models that allow for visualization, thereby offering a degree of interpretability for medical personnel.
Figure 6 demonstrates the implementation of the visualization tool. A waterfall plot illustrates the influence of individual parameters on the static score, while a heat map depicts the impact of laboratory chemical values on the dynamic score. Additionally, the combined score can be visualized over time using a separate graph. In a future clinical study, the goal will be to to equip medical staff with interpretative tools that may foster trust in the algorithms.
However, this study has several limitations, including the small sample size and data collected at a single center. Given the limited sample size, we opted for a simple voting approach instead of learning model combination weights from the data. Additionally, the lack of data from multiple centers prevents us from investigating the transferability of our models to different healthcare settings.
We only implemented laboratory parameters and values from the blood gas analyses in our dynamic model. Several considerations were made prior to this decision. As early as 2010, Kasius et al. were able to show a correlation between an increase in platelet and leucocyte counts and the occurrence of DCI [
19]. Other correlations, for example via serum D-dimers or C-reactive protein, have also followed in more recent publications [
20]. A further reason for excluding vital parameters or measured values of extended diagnostics is based on the consideration that these imply a high degree of false measurements. This may be due to artefacts or interventionally altered values as a result of specific treatment. In addition, laboratory and blood gas analyses are ubiquitously available, even in smaller hospitals or in countries with less data processing power.
The definition of delayed cerebral ischemia as an endpoint remains difficult, especially in unconscious patients, where clinical examination is limited. We therefore confirmed the endpoint in all patients with imaging evidence of new infarction and/or evidence of perfusion deficit. From a clinical point of view, it is therefore not possible to correctly determine the time of DCI onset, especially in unconscious patients, which affects the time frame of the dynamic model in both training and validation.


 and
and 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}