

Leveraging Interpretable Feature Representations for Advanced Differential Diagnosis in Computational Medicine


Abstract
:
1. Introduction
- We developed a method leveraging extensive clinical data to assist clinicians in recommending differential diagnoses that require discernment. This clinical necessity has historically remained inadequately addressed.
- Our proposed machine learning framework is fully processable through interpretable representations and visualizations, allowing doctors understanding the reasons and processes behind the recommended differential diagnoses, achieving full-process white-box computation for traceability in evidence-based medicine scenarios.
- In our framework, we use the LDA [5] topic model. Facing the challenge of determining reasonable topic numbers without prior knowledge, we propose an interpretable representation method to assess the quality of topic models and optimize topic numbers, achieving precise optimization of model quality.
2. Related Work
3. Methods
4. Interpretable Textual Medical Record Representation
5. Optimal Topic Number Calculation Methods for Interpretable Topic Models
- The number of topics should be as large as possible within an allowable range; too few topics definitely cannot express enough interpretable meaning.
- Each topic should express an independent theme as much as possible. This can be understood as follows: if each topic is mapped to a semantic space, the larger the distance between topics, the better; situations where two topics are very close (similar) should be avoided as much as possible.
- The words expressing semantics within a topic should have semantics as independent as possible. This can be understood as having as few synonyms as possible. Due to the randomness in the training process of topic models, some words may have the same semantic representation in topic expression, which may potentially share the representation ability of a certain semantic dimension within the topic.
6. Discriminative Diagnosis Recommendation Calculation Based on Interpretable Representations
- The closer the topic coordinate is to the x-axis, the more representative the topic is in the medical record compared to the current clinical diagnosis. If the topic has a larger weight in the topic distribution of the medical record, it can be used as a key interpretative topic to prove that the current diagnosis is not the differential diagnosis of the medical record.
- The closer the topic coordinate is to the y-axis, the more representative the topic is in the clinical diagnosis compared to the current medical record. If the topic has a larger weight in the topic distribution of the medical record, it can be used as a key interpretative topic to prove that the current diagnosis is not the differential diagnosis of the medical record.
- The closer the topic is to the bisector of the coordinate system, the more it has equal proof reference value for the current diagnosis and medical record, and it may be a very important basis for judging the possibility of differential diagnosis.
- The farther the topic is from the origin, the more important the feature is in calculating the differential diagnosis recommendation.
7. Experiment
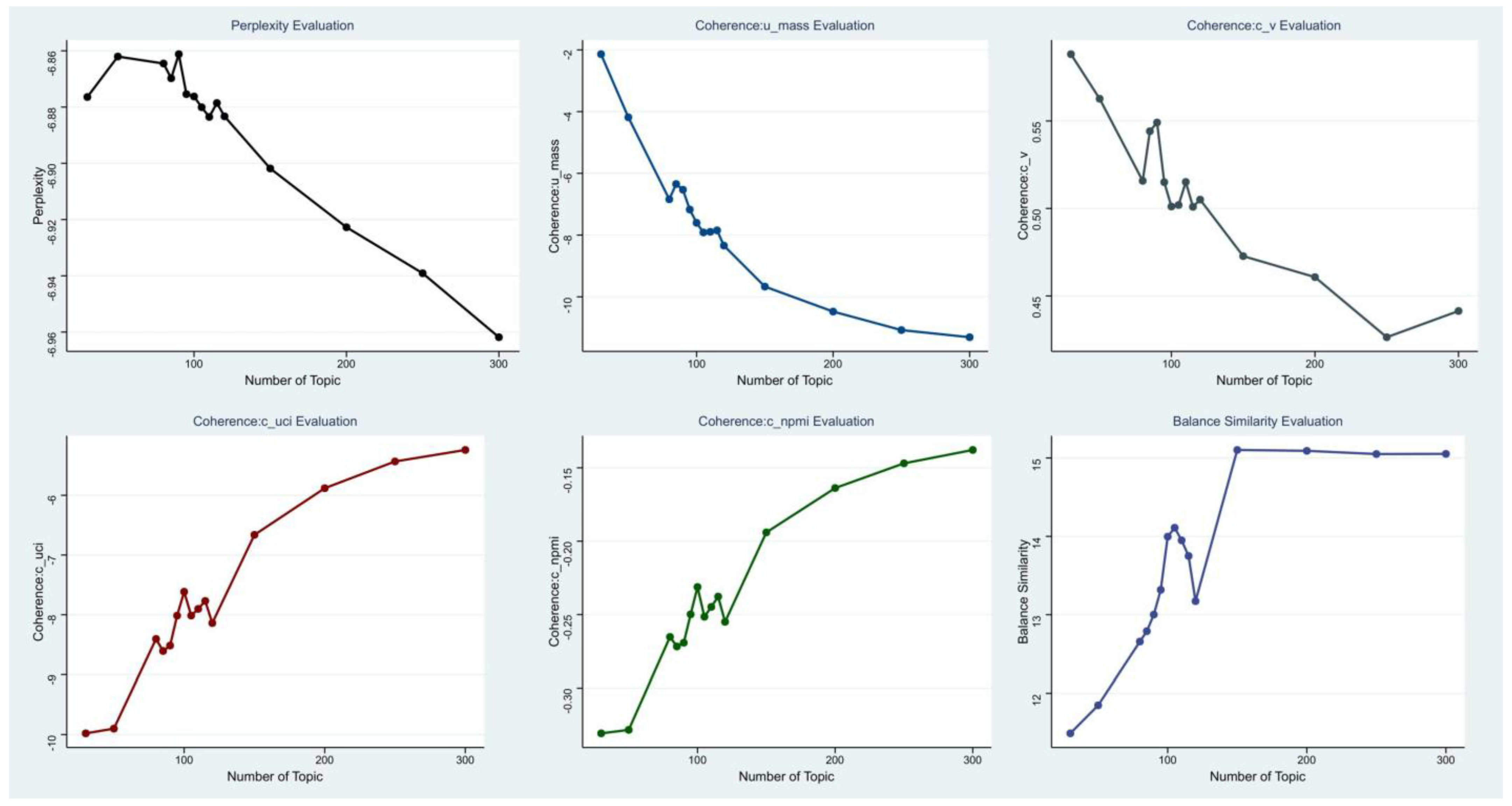
7.1. Experiment 1: Optimal Solution Experiment for the Number of Topics in Topic Modeling
7.2. Experiment 2: Efficacy Assessment of Differential Diagnosis Computation
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arter, J.A.; Jenkins, J.R. Differential diagnosis—Prescriptive teaching: A critical appraisal. Rev. Educ. Res. 1979, 49, 517–555. [Google Scholar]
- Brito, M.C.; Bentinjane, A.; Dietlein, T. 1. Definition, Classification, Differential Diagnosis. Child. Glaucoma 2013, 9, 1. [Google Scholar]
- Davis, C. “Report Highlights Public Health Impact of Serious Harms from Diagnostic Error in U.S.” Hopkinsmedicine, July 2023. Available online: https://www.hopkinsmedicine.org/news/newsroom/news-releases/2023/07/report-highlights-public-health-impact-of-serious-harms-from-diagnostic-error-in-us (accessed on 3 December 2023).
- Ma, G. “Health Pilgrimage” United Nations Children’s Fund, June 2006. Available online: https://www.unicef.cn/stories/urge-health (accessed on 2 December 2023).
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Velickovski, F.; Ceccaroni, L.; Roca, J.; Burgos, F.; Galdiz, J.B.; Marina, N.; Lluch-Ariet, M. Clinical Decision Support Systems (CDSS) for preventive management of COPD patients. J. Transl. Med. 2014, 12, S9. [Google Scholar] [CrossRef] [PubMed]
- Guimarães, P.; Finkler, H.; Reichert, M.C.; Zimmer, V.; Grünhage, F.; Krawczyk, M.; Lammert, F.; Keller, A.; Casper, M. Artificial-intelligence-based decision support tools for the differential diagnosis of colitis. Eur. J. Clin. Investig. 2023, 53, e13960. [Google Scholar] [CrossRef] [PubMed]
- Cha, D.; Pae, C.; Lee, S.A.; Na, G.; Hur, Y.K.; Lee, H.Y.; Cho, A.R.; Cho, Y.J.; Han, S.G.; Kim, S.H.; et al. Differential Biases and Variabilities of Deep Learning-Based Artificial Intelligence and Human Experts in Clinical Diagnosis: Retrospective Cohort and Survey Study. JMIR Med. Inform. 2021, 9, e33049. [Google Scholar] [CrossRef] [PubMed]
- Miyachi, Y.; Ishii, O.; Torigoe, K. Design, implementation, and evaluation of the computer-aided clinical decision support system based on learning-to-rank: Collaboration between physicians and machine learning in the differential diagnosis process. BMC Med. Inform. Decis. Mak. 2023, 23, 26. [Google Scholar] [CrossRef] [PubMed]
- Brown, C.; Nazeer, R.; Gibbs, A.; Le Page, P.; Mitchell, A.R.J. Breaking Bias: The Role of Artificial Intelligence in Improving Clinical Decision-Making. Cureus 2023, 15, e36415. [Google Scholar] [CrossRef] [PubMed]
- Harada, Y.; Katsukura, S.; Kawamura, R.; Shimizu, T. Effects of a Differential Diagnosis List of Artificial Intelligence on Differential Diagnoses by Physicians: An Exploratory Analysis of Data from a Randomized Controlled Study. Int. J. Environ. Res. Public Health 2021, 18, 5562. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhang, Y.; Jin, R.; Zhou, Z.H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Minka, T. Estimating a Dirichlet Distribution. 2000. Available online: https://tminka.github.io/papers/dirichlet/minka-dirichlet.pdf (accessed on 18 December 2023).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Goldberger; Gordon; Greenspan. An efficient image similarity measure based on approximations of KL-divergence between two Gaussian mixtures. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 1, pp. 487–493. [Google Scholar]
- Merchant, A.; Rahimtoroghi, E.; Pavlick, E.; Tenney, I. What happens to bert embeddings during fine-tuning? arXiv 2020, arXiv:2004.14448. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, 18–20 October 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 194–206. [Google Scholar]
- Xue, Y.; Liang, H.; Wu, X.; Gong, H.; Li, B.; Zhang, Y. Effects of electronic medical record in a Chinese hospital: A time series study. Int. J. Med. Inform. 2012, 81, 683–689. [Google Scholar] [CrossRef] [PubMed]
- George, E.I.; McCulloch, R.E. Variable selection via Gibbs sampling. J. Am. Stat. Assoc. 1993, 88, 881–889. [Google Scholar] [CrossRef]
- Bernardo, J.M.; Smith, A.F.M. Bayesian Theory; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Horgan, J. From complexity to perplexity. Sci. Am. 1995, 272, 104–109. [Google Scholar] [CrossRef]
- Röder, M.; Both, A.; Hinneburg, A. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, New York, NY, USA, 2–6 February 2015; pp. 399–408. [Google Scholar]
- Teh, Y.; Jordan, M.; Beal, M.; Blei, D. Sharing clusters among related groups: Hierarchical Dirichlet processes. Adv. Neural Inf. Process. Syst. 2004, 17, 1385–1392. [Google Scholar]
- Řehůřek, R.; Sojka, P. Gensim—Statistical Semantics in Python. 2011. Available online: https://radimrehurek.com/gensim/ (accessed on 18 December 2023).
- BMJ Best Practice Homepage. Available online: https://bestpractice.bmj.com/info/ (accessed on 20 October 2023).
- Elsevier Digital Solutions Page. Available online: https://www.elsevier.com/solutions (accessed on 20 October 2023).
- Wallach, H.; Mimno, D.; McCallum, A. Rethinking LDA: Why priors matter. Adv. Neural Inf. Process. Syst. 2009, 22. [Google Scholar]
- Roller, S.; Im Walde, S.S. A multimodal LDA model integrating textual, cognitive and visual modalities. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1146–1157. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Topic | Perplexity | Coherence:u_mass | Coherence:c_v | Coherence:c_uci | Coherence:c_npmi | Balance Similarity |
|---|---|---|---|---|---|---|
| 30 | −6.87642242 | −2.139474262 | 0.588161857 | −9.979548551 | −0.330698141 | 11.4901489 |
| 50 | −6.862041251 | −4.184983578 | 0.562690422 | −9.900777162 | −0.328332816 | 11.84762616 |
| 80 | −6.864519644 | −6.840832494 | 0.515771135 | −8.404860552 | −0.265222598 | 12.65740147 |
| 85 | −6.869757555 | −6.346085892 | 0.544138848 | −8.606396274 | −0.27173602 | 12.78981896 |
| 90 | −6.861197461 | −6.530789839 | 0.549113873 | −8.515818674 | −0.269195885 | 13.00116799 |
| 95 | −6.875413719 | −7.172518292 | 0.515011299 | −8.014896144 | −0.249829264 | 13.31727989 |
| 100 | −6.876245633 | −7.603171697 | 0.501090594 | −7.615493666 | −0.231214409 | 13.99658663 |
| 105 | −6.880070013 | −7.914200582 | 0.501966873 | −8.013731995 | −0.251481734 | 14.10978418 |
| 110 | −6.88351449 | −7.894659788 | 0.515126344 | −7.902379583 | −0.244774822 | 13.94907584 |
| 115 | −6.878557852 | −7.847522271 | 0.500918626 | −7.769326132 | −0.237740792 | 13.74945148 |
| 120 | −6.883310092 | −8.340739443 | 0.505031677 | −8.139187027 | −0.254968395 | 13.17306891 |
| 150 | −6.901836329 | −9.669419994 | 0.472740124 | −6.662310787 | −0.194020836 | 15.10260948 |
| 200 | −6.922738856 | −10.47846721 | 0.460747388 | −5.88178047 | −0.163788813 | 15.09132694 |
| 250 | −6.939098209 | −11.078098 | 0.426396054 | −5.433815865 | −0.146954779 | 15.05041287 |
| 300 | −6.961840108 | −11.30937244 | 0.441389928 | −5.241178775 | −0.137830459 | 15.05255057 |
| Number of Hits/Total Differential Diagnosis Number | Recall | |
|---|---|---|
| Top 5 | 3186/3645 | 0.916 |
| 0.874 | ||
| Top 10 | 3397/3645 | 0.997 |
| 0.932 |
| Recall (Number of Topic = 90) | Recall (Number of Topic = 150) | Recall (Number of Topic = 105) | |
|---|---|---|---|
| Top 5 | 3186/3645 | 3051/3645 | 0.916 |
| 0.874 | 0.837 | ||
| Top 10 | 3397/3645 | 3404/3645 | 0.997 |
| 0.932 | 0.934 |
| Recall (Cosine Similarity by Topic Model) | Recall (Proposal Method) | |
|---|---|---|
| Top 5 | 2994/3645 | 0.916 |
| 0.821 | ||
| Top 10 | 3259/3645 | 0.997 |
| 0.894 |
| Training Dataset (Amount of Training Data = 15,972) | Test Dataset (Amount of Testing Data = 1500) | ||
|---|---|---|---|
| Gender | 0.183 | ||
| Male | 8349 (52.27%) | 811 (54.07%) | |
| Female | 7623 (47.73%) | 689 (45.93%) | |
| Age | 52 (17.97) | 54 (23.89) | 0.654 |
| Marital Status | 0.125 | ||
| Single | 4178 (26.16%) | 406 (27.07%) | |
| Married | 9473 (59.31%) | 880 (58.67%) | |
| Widowed | 360 (2.25%) | 46 (3.06%) | |
| Divorced | 1961 (12.28%) | 168 (11.2%) | |
| Other | 0 (0%) | (0%) | |
| Blood Type | 0.997 | ||
| A | 4481 (28.06%) | 417 (27.80%) | |
| B | 3829 (23.97%) | 360 (24.00%) | |
| O | 6548 (41.00%) | 618 (41.20%) | |
| AB | 1114 (6.97%) | 105 (7.00%) | |
| Rh | |||
| Negative | 8 (0.05%) | 0 (0%) | 1.000 |
| Positive | 15,964 (99.95%) | 1500 (100%) |
| Group | Age (Mean ± Std) | Test Dataset (Amount of Testing Data = 1500) | Proposal Method: Differential Diagnosis Recall (Top 5) | |
|---|---|---|---|---|
| 0–18 & Male | 8.05 ± 5.66 | 197 (13.13%) | <0.001 | 0.899 |
| 0–18 & Female | 7.73 ± 5.15 | 209 (13.93%) | <0.001 | 0.887 |
| 19–65 & Male | 40.42 ± 13.19 | 441 (29.40%) | <0.001 | 0.921 |
| 19–65 & Female | 40.17 ± 13.24 | 402 (26.80%) | <0.001 | 0.933 |
| 66+ & Male | 73.85 ± 6.16 | 124 (8.27%) | <0.001 | 0.913 |
| 66+ & Female | 74.64 ± 6.04 | 127 (8.47%) | <0.001 | 0.908 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, G.; Cheng, W.; Cai, W.; Zhang, X.; Liu, J. Leveraging Interpretable Feature Representations for Advanced Differential Diagnosis in Computational Medicine. Bioengineering 2024, 11, 29. https://doi.org/10.3390/bioengineering11010029
Zhao G, Cheng W, Cai W, Zhang X, Liu J. Leveraging Interpretable Feature Representations for Advanced Differential Diagnosis in Computational Medicine. Bioengineering. 2024; 11(1):29. https://doi.org/10.3390/bioengineering11010029
Chicago/Turabian StyleZhao, Genghong, Wen Cheng, Wei Cai, Xia Zhang, and Jiren Liu. 2024. "Leveraging Interpretable Feature Representations for Advanced Differential Diagnosis in Computational Medicine" Bioengineering 11, no. 1: 29. https://doi.org/10.3390/bioengineering11010029
APA StyleZhao, G., Cheng, W., Cai, W., Zhang, X., & Liu, J. (2024). Leveraging Interpretable Feature Representations for Advanced Differential Diagnosis in Computational Medicine. Bioengineering, 11(1), 29. https://doi.org/10.3390/bioengineering11010029