


Mask-Transformer-Based Networks for Teeth Segmentation in Panoramic Radiographs

Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Datasets
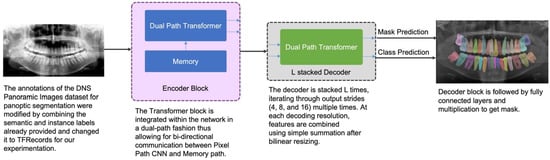
3.2. Network Architecture
3.2.1. Architecture Formulation
3.2.2. Transformer Block
3.2.3. Attention Mechanisms
- Memory-to-pixel (M2P) attention: This type allows the model to attend to the memory from the pixel path. It computes attention weights for each position in the input feature map, based on its similarity to the memory.
- Memory-to-memory (M2M) self-attention: This type allows the model to attend to the memory from the memory path. It computes attention weights for each position in the memory, based on its similarity to other positions in the memory.
- Pixel-to-memory (P2M) feedback attention: This type allows the model to attend to the memory from the pixel path, but also allows the memory to attend back to the pixel path. It computes attention weights for each position in the memory, based on its similarity to the input feature map.
- Pixel-to-pixel (P2P) self-attention: This type allows the model to attend to the input feature map from the pixel path. It computes attention weights for each position in the input feature map, based on its similarity to other positions in the input feature map. In the network, P2P self-attention is implemented as axial-attention blocks, which are more efficient than global 2D attention on high-resolution feature maps.
3.2.4. Decoder Block and Output Heads
3.2.5. Combining Outputs for Panoptic Segmentation
3.3. Loss Function
3.4. Experimental Setup
3.4.1. Training
3.4.2. Evaluation Parameters
4. Results
4.1. Ablation Study
4.2. Qualitative Analysis
4.3. Comparison with State-of-the-Art Models
4.4. Limitations
5. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nomir, O.; Abdel-Mottaleb, M. Computer-aided diagnostic tool for early detection of periodontal diseases using digital panoramic dental images. Proc. SPIE Int. Soc. Opt. Eng. 2007, 6511, 65111I. [Google Scholar]
- Huang, T.L.; Huang, T.H.; Hsieh, Y.H.; Lee, C.W. Tooth segmentation on dental meshes using morphologic skeleton. Comput. Methods Programs Biomed. 2013, 109, 69–78. [Google Scholar]
- Van Dessel, J.; Nicolielo, L.P.; Huang, Y.; Coudyzer, W.; Salmon, B.; Lambrichts, I.; Maes, F.; Jacobs, R. Automated segmentation of teeth and interproximal contact points from cone beam computed tomography images. Dento Maxillo Facial Radiol. 2015, 44, 20140315. [Google Scholar]
- Al, A.; Ijaz, U.; Song, Y.J.; Lee, S.; Park, S.; Lee, K.W.; Seo, W.B.; Park, K.W.; Han, J.W.; Lee, H. Deep learning for segmentation of 49 regions in 2D and 3D panoramic dental X-ray images. Dento Maxillo Facial Radiol. 2018, 47, 20170389. [Google Scholar]
- Chen, Y.; Mapar, M.; Mohamed, W.A.; Cohen, L.; Jacobs, R.; Huang, T.H.; RamachandraRao, S. Dental biometrics: Human identification using dental radiographs. Proc. IEEE 2017, 105, 387–398. [Google Scholar]
- Khocht, A.; Janal, M.; Turner, B.; Rams, T.E.; Haffajee, A.D. Assessment of periodontal bone level revisited: A controlled study on the diagnostic accuracy of clinical evaluation methods and intra-oral radiography. J. Clin. Periodontol. 2008, 35, 776–784. [Google Scholar]
- Silva, B.; Pinheiro, L.; Oliveira, L.; Pithon, M. A study on tooth segmentation and numbering using end-to-end deep neural networks. In Proceedings of the 2020 33rd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Porto de Galinhas, Brazil, 7–10 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 164–171. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Xu, X.; Chiu, M.T.; Huang, T.S.; Shi, H. Deep affinity net: Instance segmentation via affinity. arXiv 2020, arXiv:2003.06849. [Google Scholar]
- Singh, N.K.; Raza, K. Progress in deep learning-based dental and maxillofacial image analysis: A systematic review. Expert Syst. Appl. 2022, 199, 116968. [Google Scholar] [CrossRef]
- Jader, G.; Fontineli, J.; Ruiz, M.; Abdalla, K.; Pithon, M.; Oliveira, L. Deep instance segmentation of teeth in panoramic X-ray images. In Proceedings of the 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Parana, Brazil, 29 October–1 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 400–407. [Google Scholar]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9404–9413. [Google Scholar]
- Li, X.; Chen, D. A survey on deep learning-based panoptic segmentation. Digit. Signal Process. 2022, 120, 103283. [Google Scholar] [CrossRef]
- Chuang, Y.; Zhang, S.; Zhao, X. Deep learning-based panoptic segmentation: Recent advances and perspectives. IET IMage Process. 2023. [Google Scholar] [CrossRef]
- Li, Z.; Wang, W.; Xie, E.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P.; Lu, T. Panoptic segformer: Delving deeper into panoptic segmentation with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1280–1289. [Google Scholar]
- Xiong, Y.; Liao, R.; Zhao, H.; Hu, R.; Bai, M.; Yumer, E.; Urtasun, R. Upsnet: A unified panoptic segmentation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8818–8826. [Google Scholar]
- Grandio, J.; Riveiro, B.; Lamas, D.; Arias, P. Multimodal deep learning for point cloud panoptic segmentation of railway environments. Autom. Constr. 2023, 150, 104854. [Google Scholar] [CrossRef]
- Cheng, B.; Collins, M.D.; Zhu, Y.; Liu, T.; Huang, T.S.; Adam, H.; Chen, L.C. Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12475–12485. [Google Scholar]
- Tang, C.; Liu, X.; Zheng, X.; Li, W.; Xiong, J.; Wang, L.; Zomaya, A.Y.; Longo, A. DeFusionNET: Defocus blur detection via recurrently fusing and refining discriminative multi-scale deep features. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 955–968. [Google Scholar] [CrossRef] [PubMed]
- Tang, C.; Liu, X.; An, S.; Wang, P. BR2 Net: Defocus Blur Detection Via a Bidirectional Channel Attention Residual Refining Network. IEEE Trans. Multimed. 2020, 23, 624–635. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H. Conditional convolutions for instance segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 282–298. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Dey, M.S.; Chaudhuri, U.; Banerjee, B.; Bhattacharya, A. Dual-path morph-UNet for road and building segmentation from satellite images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Cheng, Y.; Wei, F.; Bao, J.; Chen, D.; Zhang, W. Adpl: Adaptive dual path learning for domain adaptation of semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9339–9356. [Google Scholar] [CrossRef]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual path networks. Adv. Neural Inf. Process. Syst. 2017, 30, 4470–4478. [Google Scholar]
- Wang, Y.; Chen, C.; Ding, M.; Li, J. Real-time dense semantic labeling with dual-Path framework for high-resolution remote sensing image. Remote Sens. 2019, 11, 3020. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Silva, G.; Oliveira, L.; Pithon, M. Automatic segmenting teeth in X-ray images: Trends, a novel data set, benchmarking and future perspectives. Expert Syst. Appl. 2018, 107, 15–31. [Google Scholar] [CrossRef]
- Lin, P.L.; Lai, Y.H.; Huang, P.W. An effective classification and numbering system for dental bitewing radiographs using teeth region and contour information. Pattern Recognit. 2010, 43, 1380–1392. [Google Scholar] [CrossRef]
- Lin, P.L.; Lai, Y.H.; Huang, P.W. Dental biometrics: Human identification based on teeth and dental works in bitewing radiographs. Pattern Recognit. 2012, 45, 934–946. [Google Scholar] [CrossRef]
- Chandran, V.; Nizar, G.S.; Simon, P. Segmentation of dental radiograph images. In Proceedings of the Third International Conference on Advanced Informatics for Computing Research, Shimla, India, 15–16 June 2019; pp. 1–5. [Google Scholar]
- Shin, S.; Kim, Y. A Study on Automatic Tooth Root Segmentation For Dental CT Images. J. Soc. e-Bus. Stud. 2014, 19, 45–60. [Google Scholar] [CrossRef]
- Gan, Y.; Xia, Z.; Xiong, J.; Zhao, Q.; Hu, Y.; Zhang, J. Toward accurate tooth segmentation from computed tomography images using a hybrid level set model. Med. Phys. 2015, 42, 14–27. [Google Scholar] [CrossRef] [PubMed]
- Nomir, O.; Abdel-Mottaleb, M. Fusion of matching algorithms for human identification using dental X-ray radiographs. IEEE Trans. Inf. Forensics Secur. 2008, 3, 223–233. [Google Scholar] [CrossRef]
- Wanat, R.; Frejlichowski, D. A problem of automatic segmentation of digital dental panoramic X-ray images for forensic human identification. In Proceedings of the CESCG 2011: The 15th Central European Seminar on Computer Graphics, Vinicné, Slovakia, 2–4 May 2011; pp. 1–8. [Google Scholar]
- Ullah, Z.; Usman, M.; Latif, S.; Khan, A.; Gwak, J. SSMD-UNet: Semi-supervised multi-task decoders network for diabetic retinopathy segmentation. Sci. Rep. 2023, 13, 9087. [Google Scholar] [CrossRef]
- Ullah, Z.; Usman, M.; Gwak, J. MTSS-AAE: Multi-task semi-supervised adversarial autoencoding for COVID-19 detection based on chest X-ray images. Expert Syst. Appl. 2023, 216, 119475. [Google Scholar] [CrossRef]
- Usman, M.; Rehman, A.; Shahid, A.; Latif, S.; Byon, S.S.; Kim, S.H.; Khan, T.M.; Shin, Y.G. MESAHA-Net: Multi-Encoders based Self-Adaptive Hard Attention Network with Maximum Intensity Projections for Lung Nodule Segmentation in CT Scan. arXiv 2023, arXiv:2304.01576. [Google Scholar]
- Hossain, M.S.; Al-Hammadi, M.; Muhammad, G. Automatic fruit classification using deep learning for industrial applications. IEEE Trans. Ind. Inform. 2018, 15, 1027–1034. [Google Scholar] [CrossRef]
- Usman, M.; Lee, B.D.; Byon, S.S.; Kim, S.H.; Lee, B.i.; Shin, Y.G. Volumetric lung nodule segmentation using adaptive roi with multi-view residual learning. Sci. Rep. 2020, 10, 12839. [Google Scholar] [CrossRef]
- Rehman, A.; Usman, M.; Shahid, A.; Latif, S.; Qadir, J. Selective Deeply Supervised Multi-Scale Attention Network for Brain Tumor Segmentation. Sensors 2023, 23, 2346. [Google Scholar] [CrossRef]
- Usman, M.; Shin, Y.G. DEHA-Net: A Dual-Encoder-Based Hard Attention Network with an Adaptive ROI Mechanism for Lung Nodule Segmentation. Sensors 2023, 23, 1989. [Google Scholar] [CrossRef] [PubMed]
- Shi, Z.; Zhang, L.; Sun, Y.; Ye, Y. Multiscale multitask deep NetVLAD for crowd counting. IEEE Trans. Ind. Inform. 2018, 14, 4953–4962. [Google Scholar] [CrossRef]
- Usman, M.; Latif, S.; Asim, M.; Lee, B.D.; Qadir, J. Retrospective motion correction in multishot MRI using generative adversarial network. Sci. Rep. 2020, 10, 4786. [Google Scholar] [CrossRef] [PubMed]
- Latif, S.; Asim, M.; Usman, M.; Qadir, J.; Rana, R. Automating motion correction in multishot MRI using generative adversarial networks. arXiv 2018, arXiv:1811.09750. [Google Scholar]
- Usman, M.; Rehman, A.; Shahid, A.; Latif, S.; Byon, S.S.; Lee, B.D.; Kim, S.H.; Lee, B.I.; Shin, Y.G. MEDS-Net: Self-Distilled Multi-Encoders Network with Bi-Direction Maximum Intensity projections for Lung Nodule Detection. arXiv 2022, arXiv:2211.00003. [Google Scholar]
- Latif, S.; Usman, M.; Manzoor, S.; Iqbal, W.; Qadir, J.; Tyson, G.; Castro, I.; Razi, A.; Boulos, M.N.K.; Weller, A.; et al. Leveraging data science to combat COVID-19: A comprehensive review. IEEE Trans. Artif. Intell. 2020, 1, 85–103. [Google Scholar] [CrossRef]
- Koch, T.L.; Perslev, M.; Igel, C.; Brandt, S.S. Accurate segmentation of dental panoramic radiographs with U-Nets. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 15–19. [Google Scholar]
- Wirtz, A.; Mirashi, S.G.; Wesarg, S. Automatic teeth segmentation in panoramic X-ray images using a coupled shape model in combination with a neural network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 712–719. [Google Scholar]
- Zhang, K.; Wu, J.; Chen, H.; Lyu, P. An effective teeth recognition method using label tree with cascade network structure. Comput. Med. Imaging Graph. 2018, 68, 61–70. [Google Scholar] [CrossRef]
- Lee, J.H.; Han, S.S.; Kim, Y.H.; Lee, C.; Kim, I. Application of a fully deep convolutional neural network to the automation of tooth segmentation on panoramic radiographs. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2020, 129, 635–642. [Google Scholar] [CrossRef]
- Muresan, M.P.; Barbura, A.R.; Nedevschi, S. Teeth Detection and Dental Problem Classification in Panoramic X-Ray Images using Deep Learning and Image Processing Techniques. In Proceedings of the 2020 IEEE 16th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 457–463. [Google Scholar]
- Zhao, Y.; Li, P.; Gao, C.; Liu, Y.; Chen, Q.; Yang, F.; Meng, D. TSASNet: Tooth segmentation on dental panoramic X-ray images by Two-Stage Attention Segmentation Network. Knowl.-Based Syst. 2020, 206, 106338. [Google Scholar] [CrossRef]
- Kong, Z.; Xiong, F.; Zhang, C.; Fu, Z.; Zhang, M.; Weng, J.; Fan, M. Automated Maxillofacial Segmentation in Panoramic Dental X-Ray Images Using an Efficient Encoder-Decoder Network. IEEE Access 2020, 8, 207822–207833. [Google Scholar] [CrossRef]
- Arora, S.; Tripathy, S.K.; Gupta, R.; Srivastava, R. Exploiting multimodal CNN architecture for automated teeth segmentation on dental panoramic X-ray images. Proc. Inst. Mech. Eng. Part H J. Eng. Med. 2023, 237, 395–405. [Google Scholar] [CrossRef] [PubMed]
- Almalki, A.; Latecki, L.J. Self-Supervised Learning with Masked Image Modeling for Teeth Numbering, Detection of Dental Restorations, and Instance Segmentation in Dental Panoramic Radiographs. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 5594–5603. [Google Scholar]
- Hou, S.; Zhou, T.; Liu, Y.; Dang, P.; Lu, H.; Shi, H. Teeth U-Net: A segmentation model of dental panoramic X-ray images for context semantics and contrast enhancement. Comput. Biol. Med. 2023, 152, 106296. [Google Scholar] [CrossRef]
- Shubhangi, D.; Gadgay, B.; Fatima, S.; Waheed, M. Deep Learning and Image Processing Techniques applied in Panoramic X-Ray Images for Teeth Detection and Dental Problem Classification. In Proceedings of the 2022 International Conference on Emerging Trends in Engineering and Medical Sciences (ICETEMS), Nagpur, India, 18–19 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 64–68. [Google Scholar]
- Datta, S.; Chaki, N.; Modak, B. A novel technique for dental radiographic image segmentation based on neutrosophic logic. Decis. Anal. J. 2023, 7, 100223. [Google Scholar] [CrossRef]
- Wang, H.; Zhu, Y.; Adam, H.; Yuille, A.L.; Chen, L. MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers. arXiv 2020, arXiv:2012.00759. [Google Scholar]
- Liu, C.; Chen, L.C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Fei-Fei, L. Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 82–92. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Fatima, A.; Shafi, I.; Afzal, H.; Mahmood, K.; Díez, I.d.l.T.; Lipari, V.; Ballester, J.B.; Ashraf, I. Deep Learning-Based Multiclass Instance Segmentation for Dental Lesion Detection. Healthcare 2023, 11, 347. [Google Scholar] [CrossRef]
- Karaoglu, A.; Ozcan, C.; Pekince, A.; Yasa, Y. Numbering teeth in panoramic images: A novel method based on deep learning and heuristic algorithm. Eng. Sci. Technol. Int. J. 2023, 37, 101316. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors, Year | Technique | Contribution/Advantages | Limitations |
|---|---|---|---|
| Jader et al. [11], 2018 | Instance segmentation for panoramic X-ray images | Introduced a new instance segmentation technique for teeth segmentation with promising results. | Struggles with overlapping and adjacent teeth. |
| Zhang et al. [52], 2018 | Label tree with cascade network structure for teeth recognition | Improved teeth recognition using a novel label tree and cascade network structure. | Inefficient with teeth suffering from severe pathologies. |
| Koch et al. [50], 2019 | U-Nets for dental panoramic radiographs segmentation | Developed an accurate tooth segmentation technique based on U-Nets. Demonstrated improved performance. | Difficulty in segmenting teeth with complex structures or deformities. |
| Lee et al. [53], 2020 | Deep convolutional neural network for tooth segmentation automation | Employed a deep convolutional neural network for automated tooth segmentation. Enhanced both efficiency and accuracy. | Limitations when dealing with noisy or poor-quality images. |
| Muresan et al. [54], 2020 | Deep learning and image processing techniques for teeth detection and dental problem classification | Introduced a novel approach using deep learning and image processing techniques for teeth detection and dental problem classification. | Struggles with dental problems underrepresented in the training data. |
| Zhao et al. [55], 2020 | TSASNet: Two-Stage Attention Segmentation Network for tooth segmentation | Developed TSASNet, a Two-Stage Attention Segmentation Network for tooth segmentation, showing enhanced results. | Inefficient with teeth of unusual shapes or sizes. |
| Kong et al. [56], 2020 | Efficient encoder–decoder network for automated maxillofacial segmentation | Proposed an automated segmentation method for maxillofacial regions in dental X-ray images. Showed improved efficiency and accuracy. | Difficulty with radiographs containing artifacts or of poor quality. |
| Shubhangi et al. [60], 2022 | CNNs combined with classical image processing methods | Performed teeth segmentation and numbering using a histogram-based plurality vote process. | Computationally expensive, posing challenges for real-time applications. |
| Arora et al. [57], 2023 | Multimodal encoder-based architecture | Achieved superior teeth segmentation performance. | Limited to semantic segmentation. |
| Datta et al. [61], 2023 | Combination of neutrosophic logic and a fuzzy c-means algorithm | Demonstrated competitive performance. | Relies on conventional image processing techniques, which might lack robustness. |
| Almalki et al. [58], 2023 | Self-supervised learning methods (i.e., SimMIM and UM-MAE) for dental panoramic radiographs | SimMIM, a masking-based method, outperformed UM-MAE and supervised and random initialization methods for teeth and dental restoration detection and instance segmentation. | Parameter fine-tuning, including mask ratio and pre-training epochs, substantially influence segmentation performance. |
| Hou et al. [59], 2023 | UNet with dense skip connection and attention units | Used dense skip connections and attention units to handle the irregular shape of teeth. Introduced Multi-scale Aggregation Attention Block (MAB) and Dilated Hybrid self-Attentive Block (DHAB) at the bottleneck layer. | Lacks performance analysis on public datasets, making a fair comparison challenging. |
| Category | Restoration | Appliance | Teeth Numbers | Image Numbers |
|---|---|---|---|---|
| 1 | ✓ | ✓ | 32 | 73 |
| 2 | ✓ | – | 32 | 220 |
| 3 | – | ✓ | 32 | 45 |
| 4 | – | – | 32 | 140 |
| 5 | – | – | 18 | 120 |
| 6 | – | – | 37 | 170 |
| 7 | ✓ | ✓ | 27 | 115 |
| 8 | ✓ | – | 29 | 457 |
| 9 | – | ✓ | 28 | 45 |
| 10 | – | – | 28 | 115 |
| Total | – | – | – | 1500 |
| Category | 32 Teeth | Restoration | Appliance | Number and Instance Segmentation | Segmentation |
|---|---|---|---|---|---|
| 1 | ✓ | ✓ | ✓ | 23 | 57 |
| 2 | ✓ | ✓ | – | 174 | 80 |
| 3 | ✓ | – | ✓ | 42 | 11 |
| 4 | ✓ | – | – | 92 | 68 |
| 7 | – | ✓ | ✓ | 36 | 87 |
| 8 | – | ✓ | – | 128 | 355 |
| 9 | – | – | ✓ | 14 | 33 |
| 10 | – | – | – | 34 | 87 |
| Total | – | – | – | 543 | 778 |
| Component Removed | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|
| None (Full model) | 97.25 | 93.47 | 95.13 | 93.92 |
| Transformer Block | 95.68 | 91.34 | 92.81 | 90.53 |
| Stacked Decoder | 95.04 | 90.12 | 91.57 | 88.84 |
| Output Heads | 94.12 | 88.90 | 90.36 | 87.66 |
| Pixel-to-Memory | 95.32 | 90.77 | 92.20 | 89.48 |
| Memory-to-Pixel | 95.56 | 91.22 | 92.62 | 89.97 |
| Method | Accuracy | Specificity | Precision | Recall | F1-Score | mAvP | AvP50 | AvP75 |
|---|---|---|---|---|---|---|---|---|
| Mask R-CNN [30] | 92.08 | 96.12 | 83.73 | 76.19 | 79.44 | 66.4 ± 0.7 | 96.9 ± 0.2 | 85.1 ± 1.0 |
| TSAS-Net [55] | 96.94 | 97.81 | 94.97 | 93.77 | 92.72 | 70.9 ± 0.1 | 97.7 ± 0.1 | 89.7 ± 0.5 |
| PANet [7] | 96.7 | 98.7 | 94.4 | 89.1 | 91.6 | 71.3 ± 0.3 | 97.5 ± 0.3 | 88.0 ± 0.2 |
| HTC | 96 | 98.5 | 93.7 | 85.9 | 89.6 | 63.7 ± 1.4 | 97.0 ± 0.0 | 82.2 ± 2.0 |
| UNet | 96.04 | 97.68 | 89.89 | 90.18 | 89.33 | 67.0 ± 0.5 | 96.3 ± 0.2 | 87.7 ± 0.9 |
| Ours | 97.25 | 97.65 | 95.13 | 93.92 | 93.47 | 71.5 ± 0.2 | 98.1 ± 0.4 | 89.2 ± 0.1 |
| Method | Accuracy | Specificity | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Wirtz et al. [51] | – | – | 79 | 82.7 | 80.3 |
| Lee et al. [53] | – | – | 85.8 | 89.3 | 87.5 |
| Arora et al. [57] | 96.06 | 99.92 | 95.01 | 93.06 | 91.6 |
| Fatima et al. [68] | – | – | 86 | 87 | 84 |
| Karaoglu et al. [69] | – | – | 93.33 | 93.33 | 93.16 |
| Proposed Method | 97.25 | 97.65 | 95.13 | 93.92 | 93.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kanwal, M.; Ur Rehman, M.M.; Farooq, M.U.; Chae, D.-K. Mask-Transformer-Based Networks for Teeth Segmentation in Panoramic Radiographs. Bioengineering 2023, 10, 843. https://doi.org/10.3390/bioengineering10070843
Kanwal M, Ur Rehman MM, Farooq MU, Chae D-K. Mask-Transformer-Based Networks for Teeth Segmentation in Panoramic Radiographs. Bioengineering. 2023; 10(7):843. https://doi.org/10.3390/bioengineering10070843
Chicago/Turabian StyleKanwal, Mehreen, Muhammad Mutti Ur Rehman, Muhammad Umar Farooq, and Dong-Kyu Chae. 2023. "Mask-Transformer-Based Networks for Teeth Segmentation in Panoramic Radiographs" Bioengineering 10, no. 7: 843. https://doi.org/10.3390/bioengineering10070843
APA StyleKanwal, M., Ur Rehman, M. M., Farooq, M. U., & Chae, D.-K. (2023). Mask-Transformer-Based Networks for Teeth Segmentation in Panoramic Radiographs. Bioengineering, 10(7), 843. https://doi.org/10.3390/bioengineering10070843