


Deep-Learning-Based Segmentation of Extraocular Muscles from Magnetic Resonance Images

 , ,
, , 

Abstract
1. Introduction
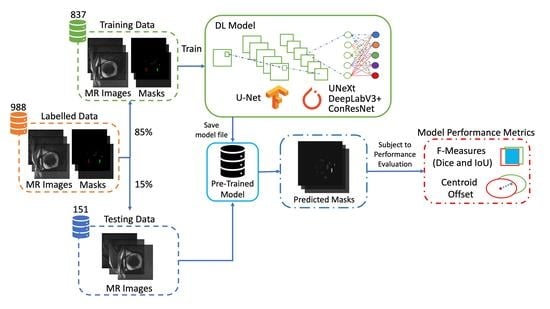
2. Materials and Methods
2.1. Dataset
2.2. Pre-Processing
2.3. Deep-Learning-Based Image Segmentation
2.4. DL Model Configuration
2.5. Evaluation Metrics Methods
3. Results
3.1. Assessment of Segmentation Accuracy
3.2. Assessment of EOM Centroid Estimation
3.3. Cross-Validation
3.4. Analysis of T-2 Weighted MRI Images
3.5. Impact of MRI Slice Location on Segmentation Accuracy
3.6. Impact of MRI Slice Location on Estimated EOM Centroids
3.7. Computation Costs of DL Models
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Tegegne, M.M.; Fekadu, S.A.; Assem, A.S. Prevalence of Strabismus and Its Associated Factors among School-Age Children Living in Bahir Dar City: A Community-Based Cross-Sectional Study. Clin. Optom. 2021, 13, 103–112. [Google Scholar] [CrossRef]
- Assaye, A.K.; Tegegn, M.T.; Assefa, N.L.; Yibekal, B.T. Knowledge towards Strabismus and Associated Factors among Adults in Gondar Town, Northwest Ethiopia. J. Ophthalmol. 2020, 2020, e3639273. [Google Scholar] [CrossRef]
- Walton, M.M.G.; Pallus, A.; Fleuriet, J.; Mustari, M.J.; Tarczy-Hornoch, K. Neural mechanisms of oculomotor abnormalities in the infantile strabismus syndrome. J. Neurophysiol. 2017, 118, 280–299. [Google Scholar] [CrossRef]
- Miller, J.M. Functional anatomy of normal human rectus muscles. Vis. Res. 1989, 29, 223–240. [Google Scholar] [CrossRef]
- Demer, J.L.; Oh, S.Y.; Poukens, V. Evidence for active control of rectus extraocular muscle pulleys. Investig. Opthalmol. Vis. Sci. 2000, 41, 1280–1290. (In English) [Google Scholar]
- Clark, R.A.; Miller, J.M.; Demer, J.L. Location and stability of rectus muscle pulleys. Muscle paths as a function of gaze. Investig. Ophthalmol. Vis. Sci. 1997, 38, 227–240. (In English) [Google Scholar]
- Clark, R.A.; Miller, J.M.; Demer, J.L. Three-dimensional location of human rectus pulleys by path inflections in secondary gaze positions. Investig. Opthalmol. Vis. Sci. 2000, 41, 3787–3797. (In English) [Google Scholar]
- Chaudhuri, Z.; Demer, J.L. Sagging eye syndrome: Connective tissue involution as a cause of horizontal and vertical strabismus in older patients. JAMA Ophthalmol. 2013, 131, 619–625. [Google Scholar] [CrossRef]
- Hamwood, J.; Schmutz, B.; Collins, M.J.; Allenby, M.C.; Alonso-Caneiro, D. A deep learning method for automatic segmentation of the bony orbit in MRI and CT images. Sci. Rep. 2021, 11, 13693. (In English) [Google Scholar] [CrossRef]
- Firbank, M.J.; Coulthard, A. Evaluation of a technique for estimation of extraocular muscle volume using 2D MRI. Br. J. Radiol. 2000, 73, 1282–1289. (In English) [Google Scholar] [CrossRef]
- Comerci, M.; Elefante, A.; Strianese, D.; Senese, R.; Bonavolonta, P.; Alfano, B.; Brunetti, A. Semiautomatic Regional Segmentation to Measure Orbital Fat Volumes in Thyroid-Associated Ophthalmopathy. Neuroradiol. J. 2013, 26, 373–379. [Google Scholar] [CrossRef] [PubMed]
- Xing, Q.; Li, Y.; Wiggins, B.; Demer, J.L.; Wei, Q. Automatic Segmentation of Extraocular Muscles Using Superpixel and Normalized Cuts; Springer International Publishing: Cham, Switzerland, 2015; pp. 501–510. [Google Scholar]
- Cao, C.; Liu, F.; Tan, H.; Song, D.; Shu, W.; Li, W.; Zhou, Y.; Bo, X.; Xie, Z. Deep Learning and Its Applications in Biomedicine. Genom. Proteom. Bioinform. 2018, 16, 17–32. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2017, 7, 87–93. (In English) [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870v3. [Google Scholar]
- Zhu, F.; Gao, Z.; Zhao, C.; Zhu, Z.; Tang, J.; Liu, Y.; Tang, S.; Jiang, C.; Li, X.; Zhao, M.; et al. Semantic segmentation using deep learning to extract total extraocular muscles and optic nerve from orbital computed tomography images. Optik 2021, 244, 167551. [Google Scholar] [CrossRef]
- Shanker, R.R.B.J.; Zhang, M.H.; Ginat, D.T. Semantic Segmentation of Extraocular Muscles on Computed Tomography Images Using Convolutional Neural Networks. Diagnostics 2022, 12, 1553. [Google Scholar] [CrossRef] [PubMed]
- Yin, X.-X.; Sun, L.; Fu, Y.; Lu, R.; Zhang, Y. U-Net-Based Medical Image Segmentation. J. Health Eng. 2022, 2022, 4189781. [Google Scholar] [CrossRef] [PubMed]
- Valanarasu, J.M.J.; Patel, V.M. UNeXt: MLP-Based Rapid Medical Image Segmentation Network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; pp. 23–33. [Google Scholar]
- Minhaz, A.T.; Sevgi, D.D.; Kwak, S.; Kim, A.; Wu, H.; Helms, R.W.; Bayat, M.; Wilson, D.L.; Orge, F.H. Deep Learning Segmentation, Visualization, and Automated 3D Assessment of Ciliary Body in 3D Ultrasound Biomicroscopy Images. Transl. Vis. Sci. Technol. 2022, 11, 3. [Google Scholar] [CrossRef] [PubMed]
- Azad, R.; Asadi-Aghbolaghi, M.; Fathy, M.; Escalera, S. Attention Deeplabv3+: Multi-level Context Attention Mechanism for Skin Lesion Segmentation. In ECCV 2020 Workshop on BioImage Computing; Springer: Cham, Switzerland, 2020; pp. 251–266. [Google Scholar]
- Zhang, J.; Xie, Y.; Wang, Y.; Xia, Y. Inter-Slice Context Residual Learning for 3D Medical Image Segmentation. IEEE Trans. Med. Imaging 2020, 40, 661–672. [Google Scholar] [CrossRef]
- Müller, D.; Soto-Rey, I.; Kramer, F. Towards a guideline for evaluation metrics in medical image segmentation. BMC Res. Notes 2022, 15, 210. [Google Scholar] [CrossRef]
- Kono, R.; Clark, R.A.; Demer, J.L. Active pulleys: Magnetic resonance imaging of rectus muscle paths in tertiary gazes. Investig. Opthalmol. Vis. Sci. 2002, 43, 2179–2188. [Google Scholar]
- Liu, C.-F.; Hsu, J.; Xu, X.; Ramachandran, S.; Wang, V.; Miller, M.I.; Hillis, A.E.; Faria, A.V.; Wintermark, M.; Warach, S.J.; et al. Deep learning-based detection and segmentation of diffusion abnormalities in acute ischemic stroke. Commun. Med. 2021, 1, 1–18. (In English) [Google Scholar] [CrossRef] [PubMed]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Nalepa, J.; Adamski, S.; Kotowski, K.; Chelstowska, S.; Machnikowska-Sokolowska, M.; Bozek, O.; Wisz, A.; Jurkiewicz, E. Segmenting pediatric optic pathway gliomas from MRI using deep learning. Comput. Biol. Med. 2022, 142, 105237. [Google Scholar] [CrossRef] [PubMed]
- Zoetmulder, R.; Gavves, E.; Caan, M.; Marquering, H. Domain- and task-specific transfer learning for medical segmentation tasks. Comput. Methods Programs Biomed. 2021, 214, 106539. [Google Scholar] [CrossRef]
- Valverde, J.M.; Imani, V.; Abdollahzadeh, A.; De Feo, R.; Prakash, M.; Ciszek, R.; Tohka, J. Transfer Learning in Magnetic Resonance Brain Imaging: A Systematic Review. J. Imaging 2021, 7, 66. [Google Scholar] [CrossRef]
- Chlap, P.; Min, H.; Vandenberg, N.; Dowling, J.; Holloway, L.; Haworth, A. A review of medical image data augmentation techniques for deep learning applications. J. Med. Imaging Radiat. Oncol. 2021, 65, 545–563. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, X.; Yang, D.; Sanford, T.; Harmon, S.; Turkbey, B.; Wood, B.J.; Roth, H.; Myronenko, A.; Xu, D.; et al. Generalizing Deep Learning for Medical Image Segmentation to Unseen Domains via Deep Stacked Transformation. IEEE Trans. Med. Imaging 2020, 39, 2531–2540. [Google Scholar] [CrossRef]
- Fabian, Z.; Heckel, R.; Soltanolkotabi, M. Data augmentation for deep learning based accelerated MRI reconstruction with limited data. arXiv 2021, arXiv:2106.14947. [Google Scholar]
- Wei, Q.; Mutawak, B.; Demer, J.L. Biomechanical modeling of actively controlled rectus extraocular muscle pulleys. Sci. Rep. 2022, 12, 5806. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Eyes | Number of Images | Percentage | |
|---|---|---|---|
| Training | 64 | 837 | 85% |
| Testing | 12 | 151 | 15% |
| Total | 76 | 988 |
| U-Net | U-NeXt | DeepLabV3+ | ConResNet | |
|---|---|---|---|---|
| Epochs | 200 | 100 | 25 | 15 |
| Activation Function | ReLU/Softmax | ReLU/GELU | ReLU | ReLU |
| Loss Function | Categorical Loss Entropy | Cross Entropy and Dice | Cross Entropy | Cross Entropy |
| Optimizer | Adam | Adam | Adam | Adam |
| Number of Trainable Parameters | 1,940,902 | 1,471,989 | 65,197,632 | 22,169,272 |
| U-Net | U-NeXt | DeepLabV3+ | ConResNet | ||
|---|---|---|---|---|---|
| IoU (mean ± SD) | MR | 0.86 ± 0.13 | 0.83 ± 0.14 | 0.82 ± 0.14 | 0.84 ± 0.09 |
| SO | 0.70 ± 0.23 | 0.64 ± 0.25 | 0.65 ± 0.23 | 0.54 ± 0.27 | |
| IR | 0.83 ± 0.15 | 0.78 ± 0.21 | 0.78 ± 0.17 | 0.80 ± 0.16 | |
| SR | 0.71 ± 0.23 | 0.68 ± 0.23 | 0.68 ± 0.21 | 0.69 ± 0.16 | |
| LR | 0.75 ± 0.26 | 0.72 ± 0.26 | 0.72 ± 0.25 | 0.65 ± 0.29 | |
| Averaged | 0.77 ± 0.20 | 0.73 ± 0.22 | 0.73 ± 0.21 | 0.70 ± 0.19 | |
| Dice (mean ± SD) | MR | 0.92 ± 0.11 | 0.90 ± 0.13 | 0.89 ± 0.13 | 0.91 ± 0.06 |
| SO | 0.79 ± 0.21 | 0.74 ± 0.26 | 0.76 ± 0.23 | 0.66 ± 0.27 | |
| IR | 0.90 ± 0.12 | 0.85 ± 0.20 | 0.87 ± 0.15 | 0.88 ± 0.14 | |
| SR | 0.80 ± 0.24 | 0.78 ± 0.23 | 0.78 ± 0.21 | 0.80 ± 0.14 | |
| LR | 0.82 ± 0.25 | 0.80 ± 0.26 | 0.80 ± 0.25 | 0.74 ± 0.27 | |
| Averaged | 0.85 ± 0.19 | 0.81 ± 0.21 | 0.82 ± 0.21 | 0.80 ± 0.18 |
| U-Net | U-NeXt | DeepLabV3+ | ConResNet | ||
|---|---|---|---|---|---|
| Centroid Error (mm) | MR | 0.23 ± 0.33 | 0.25 ± 0.26 | 0.25 ± 0.29 | 0.37 ± 0.92 |
| SO | 0.41 ± 0.77 | 0.46 ± 0.62 | 0.36 ± 0.36 | 0.56 ± 0.69 | |
| IR | 0.25 ± 0.37 | 0.29 ± 0.31 | 0.29 ± 0.38 | 0.72 ± 2.70 | |
| SR | 0.41 ± 0.35 | 0.50 ± 0.43 | 0.44 ± 0.39 | 1.02 ± 2.06 | |
| LR | 0.40 ± 0.59 | 0.53 ± 1.59 | 0.42 ± 0.54 | 1.09 ± 2.60 | |
| Averaged | 0.34 ± 0.52 | 0.40 ± 0.81 | 0.35 ± 0.40 | 0.76 ± 2.03 |
| Average Performance U-Net (200 eps) | ||||||
|---|---|---|---|---|---|---|
| Split 1 (Reported in Table 3 and Table 4) | Split 2 | Split 3 | Split 4 | Split 5 | Split 6 | |
| IoU (mean ± SD) | 0.77 ± 0.20 | 0.79 ± 0.18 | 0.78 ± 0.20 | 0.77 ± 0.21 | 0.77 ± 0.20 | 0.79 ± 0.19 |
| Dice (mean ± SD) | 0.85 ± 0.19 | 0.87 ± 0.17 | 0.85 ± 0.18 | 0.87 ± 0.21 | 0.85 ± 0.19 | 0.86 ± 0.18 |
| Centroid Error(mean mm ± SD) | 0.34 ± 0.52 | 0.27 ± 0.34 | 0.31 ± 0.49 | 0.29 ± 0.35 | 0.30 ± 0.45 | 0.33 ± 0.76 |
| IoU (Mean ± SD) | Dice (Mean ± SD) | Centroid Error (mm) (Mean ± SD) | |
|---|---|---|---|
| MR | 0.85 ± 0.13 | 0.91 ± 0.12 | 0.18 ± 0.16 |
| SO | 0.66 ± 0.21 | 0.77 ± 0.21 | 0.38 ± 0.29 |
| IR | 0.79 ± 0.20 | 0.86 ± 0.20 | 0.28 ± 0.32 |
| SR | 0.74 ± 0.24 | 0.82 ± 0.24 | 0.36 ± 0.30 |
| LR | 0.80 ± 0.16 | 0.88 ± 0.14 | 0.35 ± 0.65 |
| Averaged | 0.77 ± 0.19 | 0.85 ± 0.18 | 0.31 ± 0.34 |
| U-Net | U-NeXt | DeepLabV3+ | ConResNet | |
|---|---|---|---|---|
| Number of Epochs | 200 | 100 | 25 | 15 |
| Time for One Epoch (second) | 0.97 | 1.08 | 2.09 | 0.29 |
| Total Training Time (second) | 197 | 108 | 52.25 | 4.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qureshi, A.; Lim, S.; Suh, S.Y.; Mutawak, B.; Chitnis, P.V.; Demer, J.L.; Wei, Q. Deep-Learning-Based Segmentation of Extraocular Muscles from Magnetic Resonance Images. Bioengineering 2023, 10, 699. https://doi.org/10.3390/bioengineering10060699
Qureshi A, Lim S, Suh SY, Mutawak B, Chitnis PV, Demer JL, Wei Q. Deep-Learning-Based Segmentation of Extraocular Muscles from Magnetic Resonance Images. Bioengineering. 2023; 10(6):699. https://doi.org/10.3390/bioengineering10060699
Chicago/Turabian StyleQureshi, Amad, Seongjin Lim, Soh Youn Suh, Bassam Mutawak, Parag V. Chitnis, Joseph L. Demer, and Qi Wei. 2023. "Deep-Learning-Based Segmentation of Extraocular Muscles from Magnetic Resonance Images" Bioengineering 10, no. 6: 699. https://doi.org/10.3390/bioengineering10060699
APA StyleQureshi, A., Lim, S., Suh, S. Y., Mutawak, B., Chitnis, P. V., Demer, J. L., & Wei, Q. (2023). Deep-Learning-Based Segmentation of Extraocular Muscles from Magnetic Resonance Images. Bioengineering, 10(6), 699. https://doi.org/10.3390/bioengineering10060699