
Artificial Intelligence Procedure for the Screening of Genetic Syndromes Based on Voice Characteristics

 , , , ,
, , , ,  ,
,  and
and
Abstract
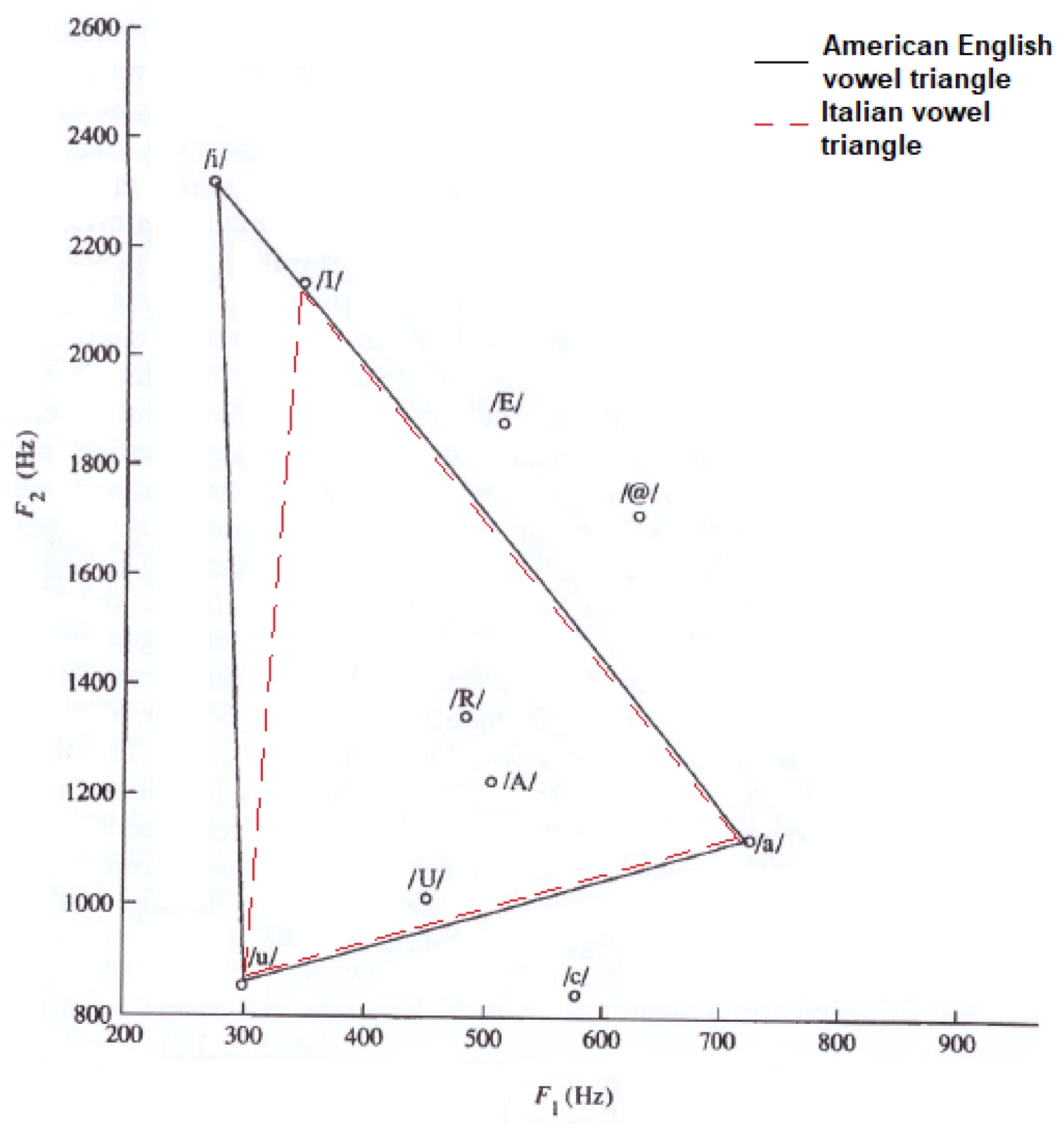
:1. Introduction
- The fundamental frequency (F0), which describes the vibration frequency of the vocal folds;
- The first formant (F1), which is related to the constriction of the anterior half of the oral cavity; the larger the cavity, the lower the F1. F1 is also raised by the constriction of the pharyngeal tract;
- The second formant (F2) (linked to tongue movements), which is lowered by posterior tongue constriction and raised by anterior tongue constriction;
- The third formant (F3), which depends on the rounding of the lips; the more this configuration is accentuated, the lower the F3;
- F0 and formants F1–F3, which are inversely proportional to the size and thickness of the vocal folds and the length of the vocal tract.
2. Background
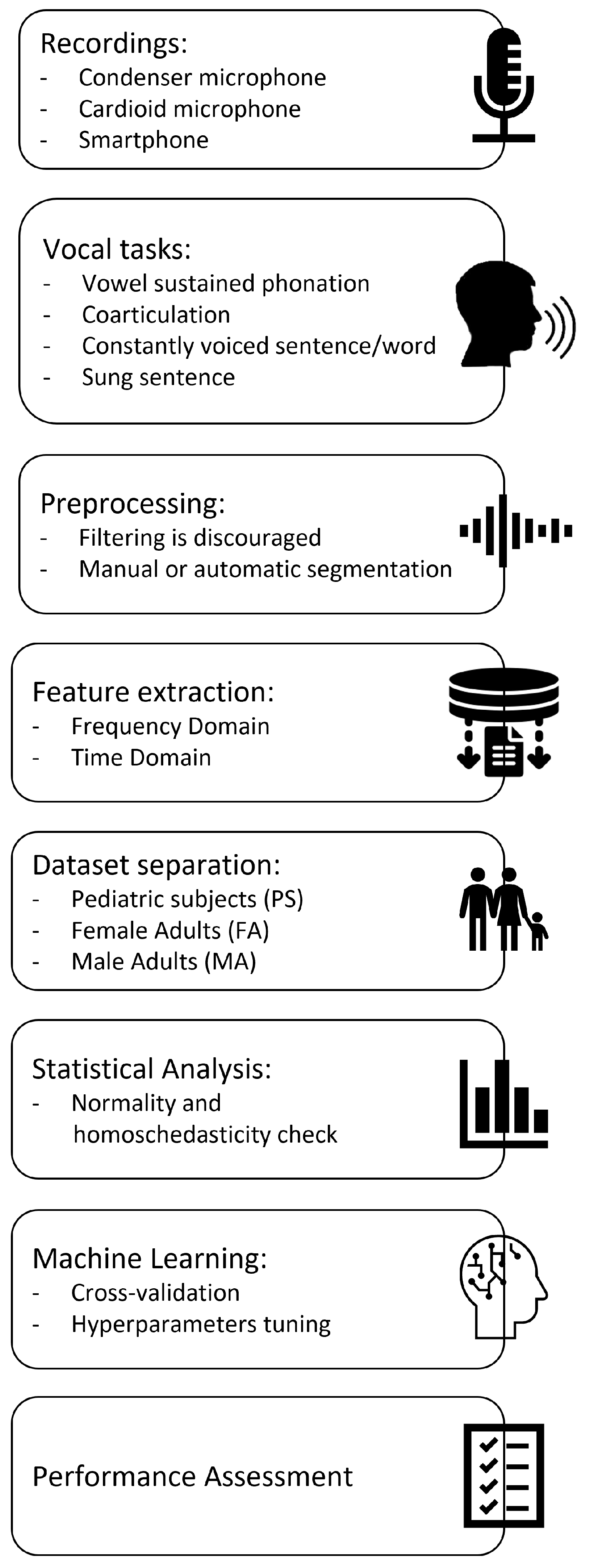
2.1. Audio Recordings
- Flat frequency response;
- Noise level at least 15 dB lower than the sound level of the softest phonation;
- Dynamic-range upper limit higher than the sound level of the loudest phonation;
- Distance between the microphone and source for which the maximally flat frequency response occurs.
2.2. Vocal Tasks
2.3. Preprocessing of Audio Samples
2.4. Acoustical Feature Extraction
2.5. Machine Learning
3. Materials and Methods
3.1. Recordings
3.2. Vocal Tasks
- List of numbers from 1 to 10;
- Word /aiuole/ (IPA transcription: «a’jwɔle»; English translation: «flowerbeds»);
- Vowels /a/, /e/, /I/, /o/, and /u/, sustained for at least 3 s;
- Sentence “io amo le aiuole della mamma” (IPA transcription: «’io ‘amo ‘le a’jwɔle ‘del:a ‘mam:a»; English translation: “I love mother’s flowerbeds”);
- Sung sentence “Fra Martino campanaro, dormi tu” (Italian version of the first sentence of the well-known European traditional song Frère Jacques).
3.3. Preprocessing of Audio Samples
3.4. Acoustical Analysis
3.5. Dataset Separation
3.6. Machine Learning
- For the KNN classifier, between 2 and 27 neighbors (k) were evaluated. The considered distance metrics were “cityblock”, “Chebyshev”, “correlation”, “cosine”, “Euclidean”, “Hamming”, “Jaccard”, “Mahalanobis”, “Minkowski”, “seuclidean”, and “Spearman”. The distance weight was selected among “equal”, “inverse”, and “squared inverse”.
- For the SVM classifier, coding was selected between “one vs. one” and “one vs. all”. The box constraint and kernel scale were evaluated between 10 and 10. The kernel function was set as Gaussian.
- For the random forest, the minimum number of leaves was selected among 2 and 27; the maximum number of splits was selected among 2 and 27; the split criterion was selected among “deviance”, “gdi”, and “twoing”; and the number of variables to sample was selected between 1 and 55.
3.7. Statistical Analysis
3.8. Procedural Validation
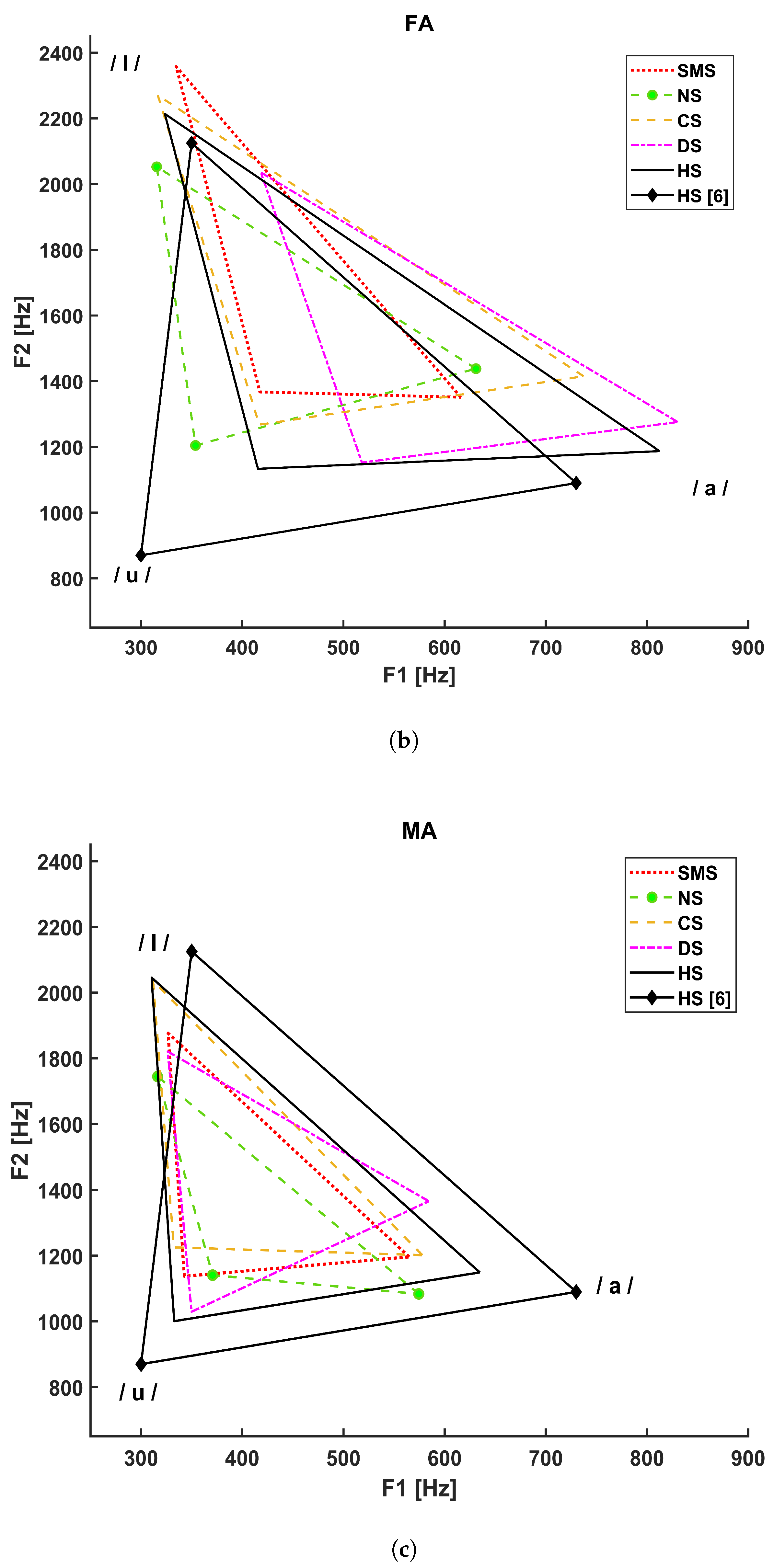
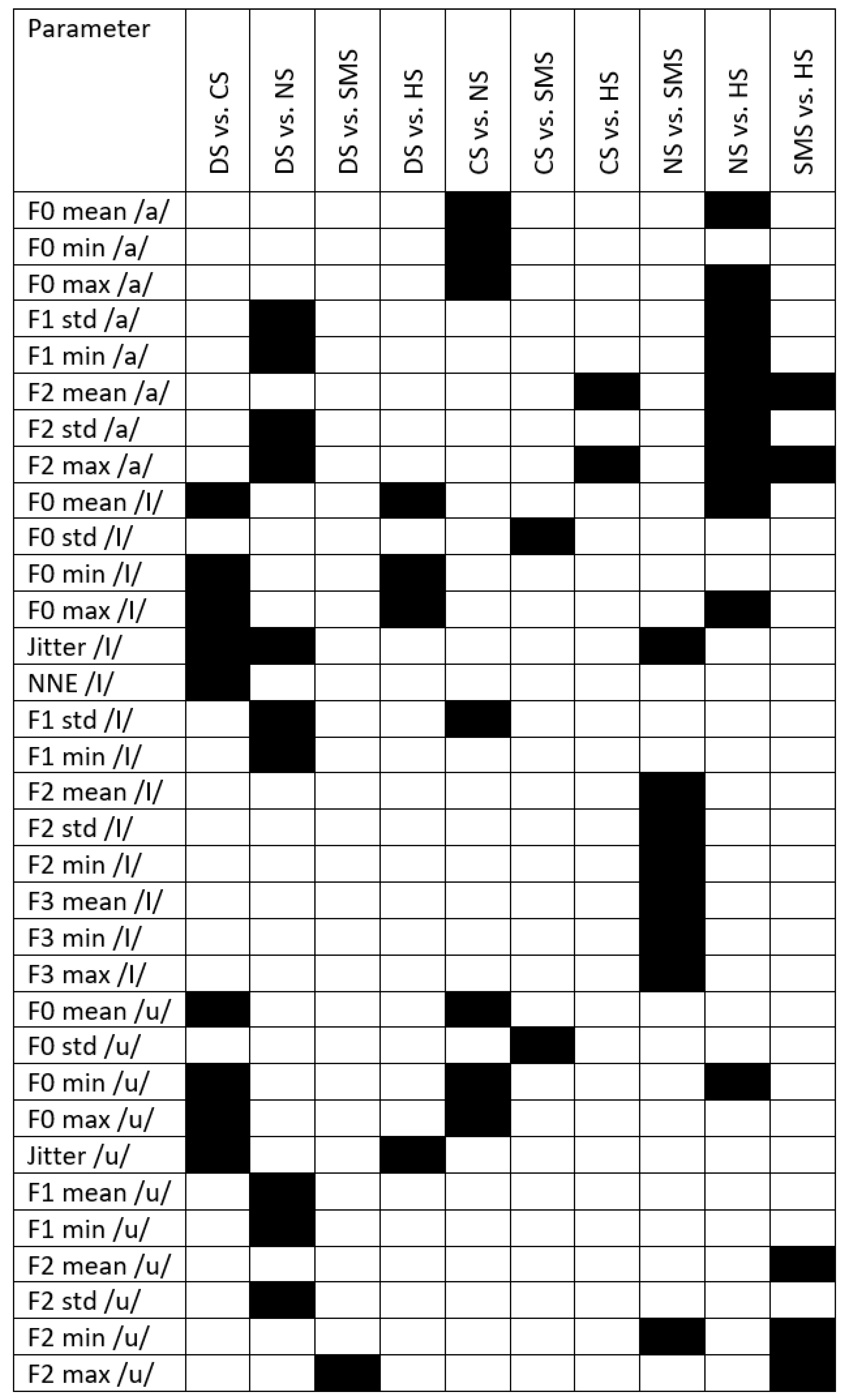
4. Results
- The dotted line refers to SMS patients;
- The dashed line with circle markers refers to NS patients;
- The simple dashed line refers to CS patients;
- The dash–dotted line refers to DS patients.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
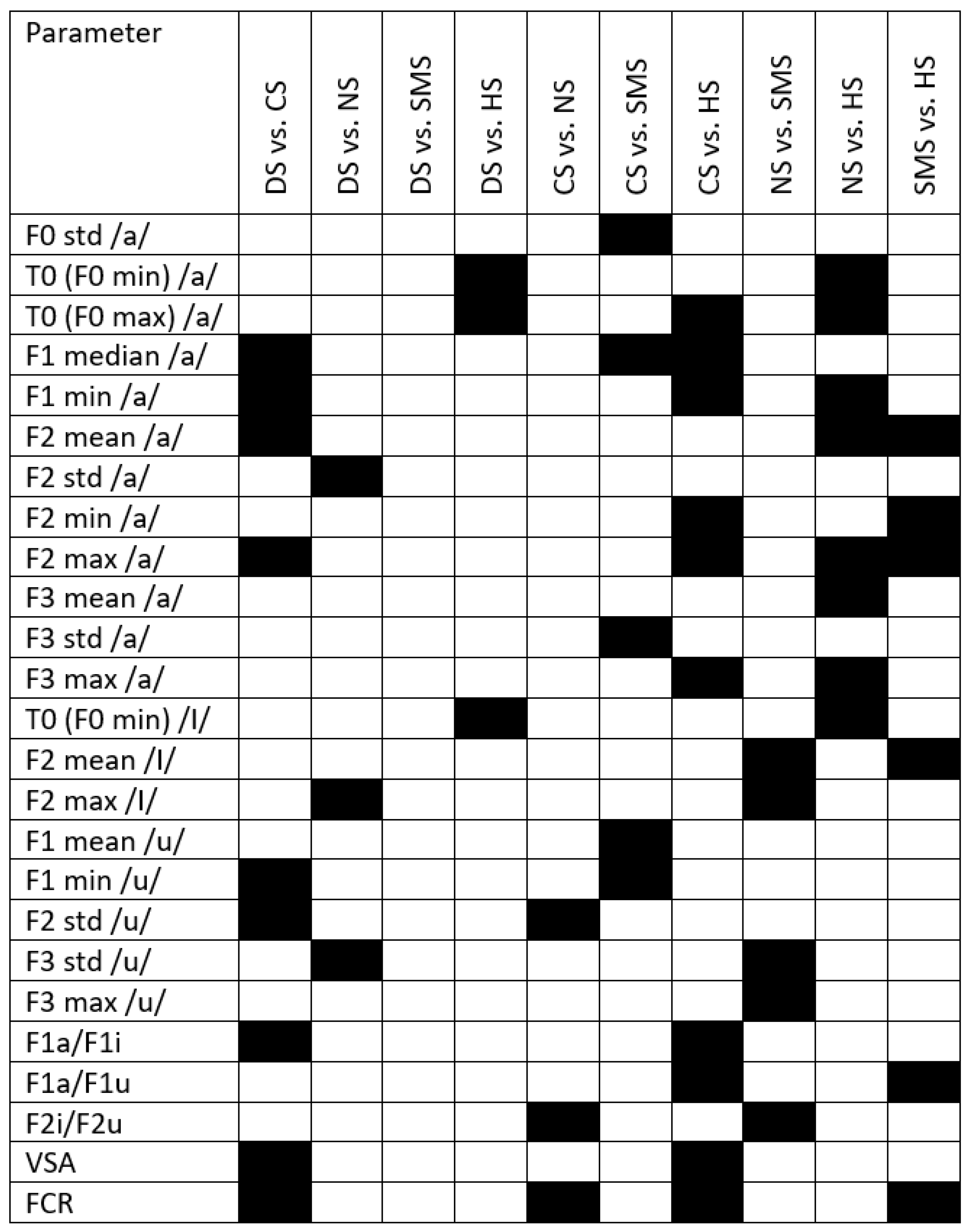
Appendix B
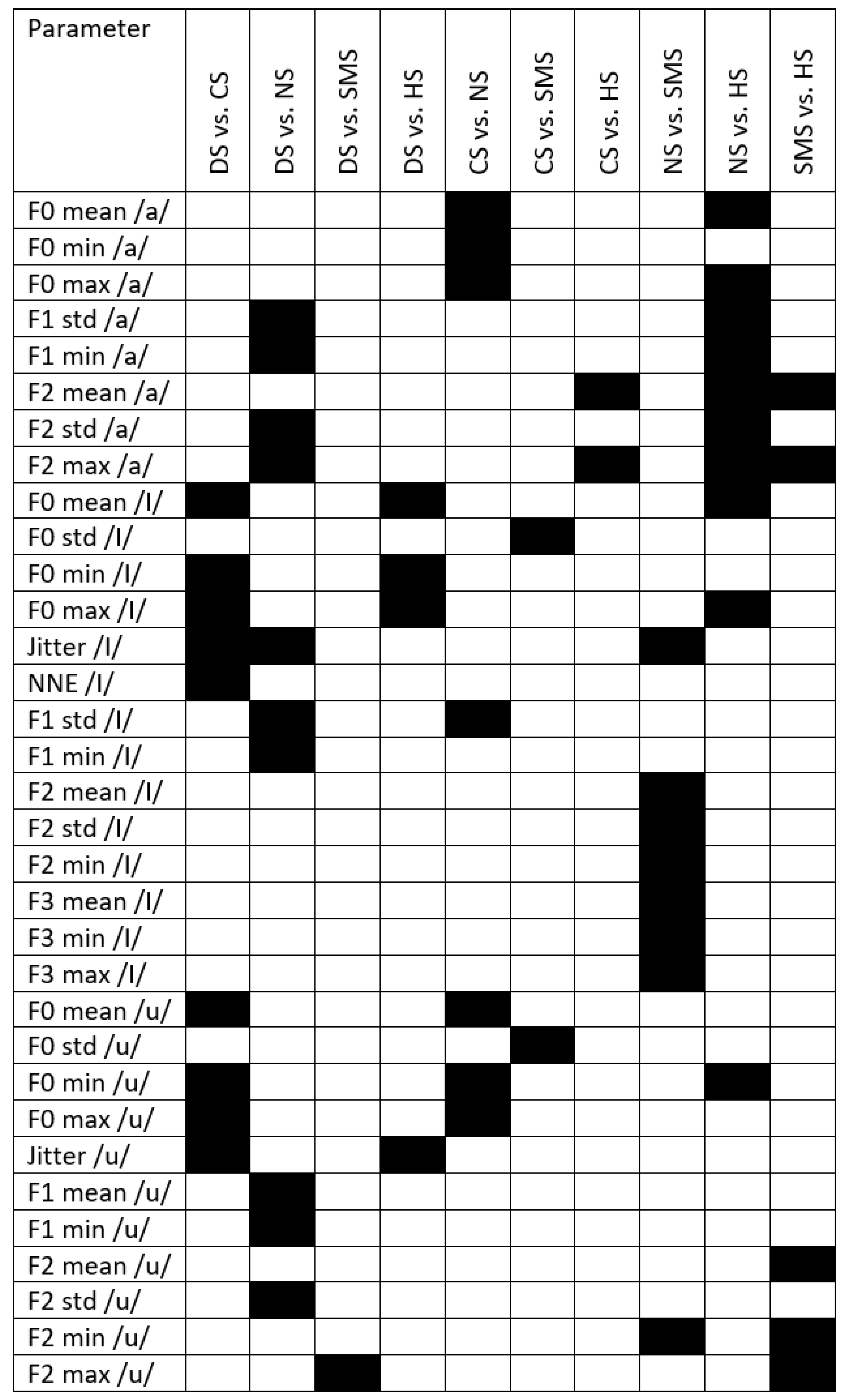
Appendix C
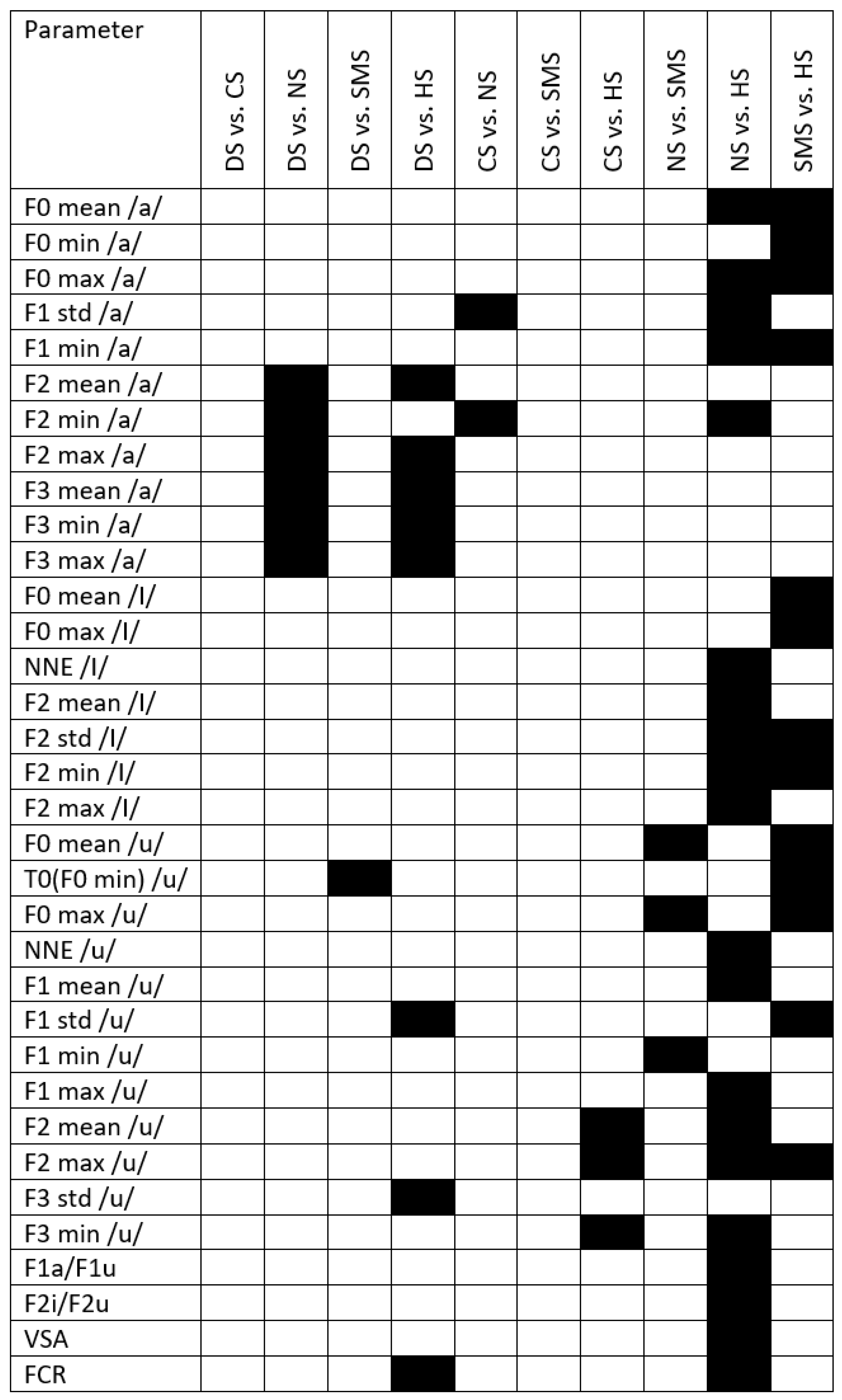
References
- Harar, P.; Galaz, Z.; Alonso-Hernandez, J.B.; Mekyska, J.; Burget, R.; Smekal, Z. Towards robust voice pathology detection: Investigation of supervised deep learning, gradient boosting, and anomaly detection approaches across four databases. Neural Comput. Appl. 2020, 32, 15747–15757. [Google Scholar] [CrossRef]
- Verde, L.; De Pietro, G.; Sannino, G. Voice disorder identification by using machine learning techniques. IEEE Access 2018, 6, 16246–16255. [Google Scholar] [CrossRef]
- Arora, S.; Venkataraman, V.; Zhan, A.; Donohue, S.; Biglan, K.M.; Dorsey, E.R.; Little, M.A. Detecting and monitoring the symptoms of Parkinson’s disease using smartphones: A pilot study. Park. Relat. Disord. 2015, 21, 650–653. [Google Scholar] [CrossRef] [PubMed]
- Sajal, M.S.R.; Ehsan, M.T.; Vaidyanathan, R.; Wang, S.; Aziz, T.; Mamun, K.A.A. Telemonitoring Parkinson’s disease using machine learning by combining tremor and voice analysis. Brain Inform. 2020, 7, 1–11. [Google Scholar] [CrossRef]
- Deller, J.R., Jr. Discrete-Time Processing of Speech Signals; Macmillan Publishing Co: New York, NY, USA, 1993; p. 908. [Google Scholar]
- Gripp, K.W.; Morse, L.A.; Axelrad, M.; Chatfield, K.C.; Chidekel, A.; Dobyns, W.; Doyle, D.; Kerr, B.; Lin, A.E.; Schwartz, D.D.; et al. Costello syndrome: Clinical phenotype, genotype, and management guidelines. Am. J. Med. Genet. Part A 2019, 179, 1725–1744. [Google Scholar] [CrossRef]
- Moura, C.P.; Cunha, L.M.; Vilarinho, H.; Cunha, M.J.; Freitas, D.; Palha, M.; Pueschel, S.M.; Pais-Clemente, M. Voice parameters in children with Down syndrome. J. Voice 2008, 22, 34–42. [Google Scholar] [CrossRef]
- Bunton, K.; Leddy, M. An evaluation of articulatory working space area in vowel production of adults with Down syndrome. Clin. Linguist. Phon. 2011, 25, 321–334. [Google Scholar] [CrossRef]
- Türkyilmaz, M.; Tokgöz Yılmaz, S.; Özcebe, E.; Yüksel, S.; Süslü, N.; Tekin, M. Voice characteristics of children with noonan syndrome Noonan sendromu olan çocuklarda ses özellikleri. Turk. Klin. J. Med Sci. 2014, 34, 165–169. [Google Scholar]
- Wilson, M.; Dyson, A. Noonan syndrome: Speech and language characteristics. J. Commun. Disord. 1982, 15, 347–352. [Google Scholar] [CrossRef]
- Hidalgo-De la Guía, I.; Garayzábal-Heinze, E.; Gómez-Vilda, P. Voice characteristics in smith—Magenis syndrome: An acoustic study of laryngeal biomechanics. Languages 2020, 5, 31. [Google Scholar] [CrossRef]
- Hidalgo-De la Guía, I.; Garayzábal-Heinze, E.; Gómez-Vilda, P.; Martínez-Olalla, R.; Palacios-Alonso, D. Acoustic Analysis of Phonation in Children With Smith—Magenis Syndrome. Front. Hum. Neurosci. 2021, 15, 661392. [Google Scholar] [CrossRef] [PubMed]
- Hillenbrand, J.; Houde, R.A. Acoustic correlates of breathy vocal quality: Dysphonic voices and continuous speech. J. Speech Lang. Hear. Res. 1996, 39, 311–321. [Google Scholar] [CrossRef] [PubMed]
- Tartaglia, M.; Gelb, B.D.; Zenker, M. Noonan syndrome and clinically related disorders. Best Pract. Res. Clin. Endocrinol. Metab. 2011, 25, 161–179. [Google Scholar] [CrossRef] [PubMed]
- Zin, T.T.; Htet, Y.; Akagi, Y.; Tamura, H.; Kondo, K.; Araki, S.; Chosa, E. Real-time action recognition system for elderly people using stereo depth camera. Sensors 2021, 21, 5895. [Google Scholar] [CrossRef]
- Gurovich, Y.; Hanani, Y.; Bar, O.; Nadav, G.; Fleischer, N.; Gelbman, D.; Basel-Salmon, L.; Krawitz, P.M.; Kamphausen, S.B.; Zenker, M.; et al. Identifying facial phenotypes of genetic disorders using deep learning. Nat. Med. 2019, 25, 60–64. [Google Scholar] [CrossRef]
- Dejonckere, P.H.; Bradley, P.; Clemente, P.; Cornut, G.; Crevier-Buchman, L.; Friedrich, G.; Van De Heyning, P.; Remacle, M.; Woisard, V. A basic protocol for functional assessment of voice pathology, especially for investigating the efficacy of (phonosurgical) treatments and evaluating new assessment techniques: Guideline elaborated by the Committee on Phoniatrics of the European Laryngological Society (ELS). Eur. Arch. Oto-Rhino-Laryngol. 2001, 258, 77–82. [Google Scholar]
- Svec, J.G.; Granqvist, S. Guidelines for selecting microphones for human voice production research. Am. J. Speech Lang Pathol. 2010, 19, 356–368. [Google Scholar] [CrossRef]
- Hidalgo, I.; Vilda, P.G.; Garayzábal, E. Biomechanical Description of phonation in children affected by Williams syndrome. J. Voice 2018, 32, 515.e15–515.e28. [Google Scholar] [CrossRef]
- Corrales-Astorgano, M.; Escudero-Mancebo, D.; González-Ferreras, C. Acoustic characterization and perceptual analysis of the relative importance of prosody in speech of people with Down syndrome. Speech Commun. 2018, 99, 90–100. [Google Scholar] [CrossRef]
- Flanagan, O.; Chan, A.; Roop, P.; Sundram, F. Using acoustic speech patterns from smartphones to investigate mood disorders: Scoping review. JMIR mHealth uHealth 2021, 9, e24352. [Google Scholar] [CrossRef]
- Yoon, H.; Gaw, N. A novel multi-task linear mixed model for smartphone-based telemonitoring. Expert Syst. Appl. 2021, 164, 113809. [Google Scholar] [CrossRef]
- Amir, O.; Anker, S.D.; Gork, I.; Abraham, W.T.; Pinney, S.P.; Burkhoff, D.; Shallom, I.D.; Haviv, R.; Edelman, E.R.; Lotan, C. Feasibility of remote speech analysis in evaluation of dynamic fluid overload in heart failure patients undergoing haemodialysis treatment. ESC Heart Fail. 2021, 8, 2467–2472. [Google Scholar] [CrossRef] [PubMed]
- Manfredi, C.; Lebacq, J.; Cantarella, G.; Schoentgen, J.; Orlandi, S.; Bandini, A.; DeJonckere, P.H. Smartphones offer new opportunities in clinical voice research. J. Voice 2017, 31, 111.e1–111.e7. [Google Scholar] [CrossRef] [PubMed]
- Cavalcanti, J.C.; Englert, M.; Oliveira, M., Jr.; Constantini, A.C. Microphone and audio compression effects on acoustic voice analysis: A pilot study. J. Voice 2021, 37, 162–172. [Google Scholar] [CrossRef] [PubMed]
- Glover, M.; Duhamel, M.F. Assessment of Two Audio-Recording Methods for Remote Collection of Vocal Biomarkers Indicative of Tobacco Smoking Harm. Acoust. Aust. 2023, 51, 39–52. [Google Scholar] [CrossRef]
- Frassineti, L.; Zucconi, A.; Calà, F.; Sforza, E.; Onesimo, R.; Leoni, C.; Rigante, M.; Manfredi, C.; Zampino, G. Analysis of vocal patterns as a diagnostic tool in patients with genetic syndromes. In Models and Analysis of Vocal Emissions for Biomedical Applications: 12th International Workshop, Firenze, Italy, 14–17 December 2021; Firenze University Press: Florence, Italy, 2021; pp. 83–86. [Google Scholar]
- Suppa, A.; Costantini, G.; Asci, F.; Di Leo, P.; Al-Wardat, M.S.; Di Lazzaro, G.; Scalise, S.; Pisani, A.; Saggio, G. Voice in Parkinson’s disease: A machine learning study. Front. Neurol. 2022, 13, 831428. [Google Scholar] [CrossRef] [PubMed]
- Lenoci, G.; Celata, C.; Ricci, I.; Chilosi, A.; Barone, V. Vowel variability and contrast in childhood apraxia of speech: Acoustics and articulation. Clin. Linguist. Phon. 2021, 35, 1011–1035. [Google Scholar] [CrossRef]
- Gómez-García, J.; Moro-Velázquez, L.; Arias-Londoño, J.D.; Godino-Llorente, J.I. On the design of automatic voice condition analysis systems. Part III: Review of acoustic modelling strategies. Biomed. Signal Process. Control 2021, 66, 102049. [Google Scholar] [CrossRef]
- Alpan, A.; Maryn, Y.; Kacha, A.; Grenez, F.; Schoentgen, J. Multi-band dysperiodicity analyses of disordered connected speech. Speech Commun. 2011, 53, 131–141. [Google Scholar] [CrossRef]
- Seok, J.; Ryu, Y.M.; Jo, S.A.; Lee, C.Y.; Jung, Y.S.; Ryu, J.; Ryu, C.H. Singing voice range profile: New objective evaluation methods for voice change after thyroidectomy. Clin. Otolaryngol. 2021, 46, 332–339. [Google Scholar] [CrossRef]
- Kohler, M.; Vellasco, M.M.; Cataldo, E.; Mendoza, L.F. Analysis and classification of voice pathologies using glottal signal parameters. J. Voice 2016, 30, 549–556. [Google Scholar]
- Gómez-Vilda, P.; Fernández-Baillo, R.; Nieto, A.; Díaz, F.; Fernández-Camacho, F.J.; Rodellar, V.; Álvarez, A.; Martínez, R. Evaluation of voice pathology based on the estimation of vocal fold biomechanical parameters. J. Voice 2007, 21, 450–476. [Google Scholar] [CrossRef] [PubMed]
- Gripp, K.W.; Lin, A.E. Costello syndrome: A Ras/mitogen activated protein kinase pathway syndrome (rasopathy) resulting from HRAS germline mutations. Genet. Med. 2012, 14, 285–292. [Google Scholar] [CrossRef] [PubMed]
- Kent, R.D.; Vorperian, H.K. Speech impairment in Down syndrome: A review. J. Speech Lang Hear. Res. 2013, 56, 178–210. [Google Scholar] [CrossRef] [PubMed]
- Torres, G.X.; Santos, E.d.S.; César, C.P.H.A.R.; Irineu, R.d.A.; Dias, I.R.R.; Ramos, A.F. Clinical orofacial and myofunctional manifestations in an adolescent with Noonan Syndrome: A case report. Rev. CEFAC 2020, 22, e16519. [Google Scholar] [CrossRef]
- Rinaldi, B.; Villa, R.; Sironi, A.; Garavelli, L.; Finelli, P.; Bedeschi, M.F. Smith-magenis syndrome—Clinical review, biological background and related disorders. Genes 2022, 13, 335. [Google Scholar] [CrossRef] [PubMed]
- Bandini, A.; Giovannelli, F.; Orlandi, S.; Barbagallo, S.D.; Cincotta, M.; Vanni, P.; Chiaramonti, R.; Borgheresi, A.; Zaccara, G.; Manfredi, C. Automatic identification of dysprosody in idiopathic Parkinson’s disease. Biomed. Signal Process. Control 2015, 17, 47–54. [Google Scholar] [CrossRef]
- Vieira, M.N.; McInnes, F.R.; Jack, M.A. On the influence of laryngeal pathologies on acoustic and electroglottographic jitter measures. J. Acoust. Soc. Am. 2002, 111, 1045–1055. [Google Scholar] [CrossRef]
- Morelli, M.S.; Manfredi, S.O.C. BioVoice: A multipurpose tool for voice analysis. In Proceedings of the 11th International Workshop Models and Analysis of Vocal Emissions for Biomedical Applications, MAVEBA 2019, Firenze, Italy, 17–19 December 2019; Firenze University Press: Firenze, Italy, 2019; pp. 261–264. [Google Scholar]
- Boersma, P.; Van Heuven, V. Speak and unSpeak with PRAAT. Glot Int. 2001, 5, 341–347. [Google Scholar]
- Bur, A.M.; Shew, M.; New, J. Artificial intelligence for the otolaryngologist: A state of the art review. Otolaryngol. Head Neck Surg. 2019, 160, 603–611. [Google Scholar] [CrossRef]
- Costantini, G.; Di Leo, P.; Asci, F.; Zarezadeh, Z.; Marsili, L.; Errico, V.; Suppa, A.; Saggio, G. Machine Learning based Voice Analysis in Spasmodic Dysphonia: An Investigation of Most Relevant Features from Specific Vocal Tasks. In Proceedings of the BIOSIGNALS, Vienna, Austria, 11–13 February 2021; pp. 103–113. [Google Scholar]
- Lebacq, J.; Schoentgen, J.; Cantarella, G.; Bruss, F.T.; Manfredi, C.; DeJonckere, P. Maximal ambient noise levels and type of voice material required for valid use of smartphones in clinical voice research. J. Voice 2017, 31, 550–556. [Google Scholar] [CrossRef]
- Carrón, J.; Campos-Roca, Y.; Madruga, M.; Pérez, C.J. A mobile-assisted voice condition analysis system for Parkinson’s disease: Assessment of usability conditions. Biomed. Eng. Online 2021, 20, 1–24. [Google Scholar] [CrossRef]
- Schroder, C. The Book of Audacity: Record, Edit, Mix, and Master with the Free Audio Editor; No Starch Press: San Francisco, CA, USA, 2011. [Google Scholar]
- Kent, R.D.; Kim, Y.J. Toward an acoustic typology of motor speech disorders. Clin. Linguist. Phon. 2003, 17, 427–445. [Google Scholar] [CrossRef]
- Sapir, S.; Ramig, L.O.; Spielman, J.L.; Fox, C. Formant centralization ratio: A proposal for a new acoustic measure of dysarthric speech. J. Speech Lang Hear. Res. 2010, 53, 114–125. [Google Scholar] [CrossRef]
- Blog, C. Effects of Intensive Voice Treatment (LSVT) on Vowel Articulation in Dysarthric Individuals with Idiopathic Parkinson Disease: Acoustic and Perceptual Findings Shimon Sapir, Jennifer L. Spielman, Lorraine O. Ramig, Brad H. Story, and Cynthia Fox. J. Speech Lang. Hear. Res. 2018, 50, 899–912. [Google Scholar]
- Maccarini, L.R.; Lucchini, E. La valutazione soggettiva e oggettiva della disfonia. Il Protocollo SIFEL, Relazione Ufficiale al XXXVI Congresso Nazionale della Società Italiana di Foniatria e Logopedia. Acta Phoniatr. Lat. 2002, 24, 13–42. [Google Scholar]
- Choi, N.; Ko, J.M.; Shin, S.H.; Kim, E.K.; Kim, H.S.; Song, M.K.; Choi, C.W. Phenotypic and genetic characteristics of five Korean patients with Costello syndrome. Cytogenet. Genome Res. 2019, 158, 184–191. [Google Scholar] [CrossRef]
- De Smet, H.J.; Catsman-Berrevoets, C.; Aarsen, F.; Verhoeven, J.; Mariën, P.; Paquier, P.F. Auditory-perceptual speech analysis in children with cerebellar tumours: A long-term follow-up study. Eur. J. Paediatr. Neurol. 2012, 16, 434–442. [Google Scholar] [CrossRef]
- Lee, S.H.; Yu, J.F.; Hsieh, Y.H.; Lee, G.S. Relationships between formant frequencies of sustained vowels and tongue contours measured by ultrasonography. Am. J. Speech-Lang. Pathol. 2015, 24, 739–749. [Google Scholar] [CrossRef]
- Yellon, R.F. Prevention and management of complications of airway surgery in children. Pediatr. Anesth. 2004, 14, 107–111. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| F0 mean (Hz) | Mean fundamental frequency |
| F0 median (Hz) | Median fundamental frequency |
| F0 std (Hz) | Standard deviation of the fundamental frequency |
| F0 min (Hz) | Minimum fundamental frequency |
| T0 (F0 min) (s) | Time instant at which the minimum of F0 occurs |
| F0 max (Hz) | Maximum fundamental frequency |
| T0 (F0 max) (Hz) | Time instant at which the maximum of F0 occurs |
| Jitter (%) | Frequency variation of F0 |
| NNE (dB) | Normalized noise energy |
| F1 mean (Hz) | Mean value of the first formant |
| F1 median (Hz) | Median value of the first formant |
| F1 std (Hz) | Standard deviation of the first formant |
| F1 min (Hz) | Minimum value of the first formant |
| F1 max (Hz) | Maximum value of the first formant |
| F2 mean (Hz) | Mean value of the second formant |
| F2 median (Hz) | Median value of the second formant |
| F2 std (Hz) | Standard deviation of the second formant |
| F2 min (Hz) | Minimum value of the second formant |
| F2 max (Hz) | Maximum value of the second formant |
| F3 mean (Hz) | Mean value of the third formant |
| F3 median (Hz) | Median value of the third formant |
| F3 std (Hz) | Standard deviation of the third formant |
| F3 min (Hz) | Minimum value of the third formant |
| F3 max (Hz) | Maximum value of the third formant |
| Signal duration (s) | Total audio file duration |
| % voiced | Percentage of voiced parts inside the whole signal |
| Voiced duration (s) | Total duration of voiced parts |
| Number units | Number of voiced parts |
| Duration mean (s) | Mean duration of voiced parts |
| Duration std (s) | Standard deviation of the duration of voiced parts |
| Duration min (s) | Minimum duration of voiced parts |
| Duration max (s) | Maximum duration of voiced parts |
| Number pauses | Total number of pauses in the audio file |
| Pause duration mean (s) | Mean duration of pauses |
| Pause duration std (s) | Standard deviation of the duration of pauses |
| Pause duration min (s) | Minimum duration of pauses |
| Pause duration max (s) | Maximum duration of pauses |
| VSA | Vowel space area |
| FCR | Formant centralization ratio |
| F ratio | Formant ratio between F1 of /a/ and F1 of /I/ |
| F ratio | Formant ratio between F1 of /a/ and F1 of /u/ |
| F ratio | Formant ratio between F2 of /I/ and F2 of /u/ |
| PS | FA | MA | |
|---|---|---|---|
| CS | 9.9 (2.0) [9] | 16.4 (4.3) [15] | 29.5 (2.1) [6] |
| DS | 7.2 (3.6) [18] | 21.2 (11.7) [12] | 18.3 (2.2) [9] |
| NS | 10.7 (2.3) [15] | 22.4 (7.7) [18] | 23.7 (8.4) [18] |
| SMS | 8.0 (2.0) [24] | 17.5 (1.3) [15] | 16.3 (1.5) [9] |
| HS | 8.9 (3.1) [21] | 18.3 (6.8) [9] | 21.3 (6.4) [18] |
| Parameter | Kruskal–Wallis H Statistic | p Value |
|---|---|---|
| F0 std /a/ | 11.58 | 0.021 |
| T0 (F0 min) /a/ * | 19.68 | <0.001 |
| T0 (F0 max) /a/ * | 23.40 | <0.001 |
| NNE /a/ | 11.14 | 0.025 |
| F1 median /a/ * | 20.02 | <0.001 |
| F1 min /a/ * | 21.56 | <0.001 |
| F1 max /a/ * | 16.50 | 0.002 |
| F2 mean /a/ * | 20.29 | <0.001 |
| F2 std /a/ | 13.27 | 0.01 |
| F2 min /a/ * | 13.84 | 0.008 |
| F2 max /a/ * | 29.77 | <0.001 |
| F3 mean /a/ * | 10.80 | 0.029 |
| F3 std /a/ | 22.01 | <0.001 |
| F3 min /a/ * | 10.09 | 0.039 |
| F3 max /a/ * | 15.69 | 0.003 |
| T0 (F0 min) /I/ * | 19.58 | <0.001 |
| T0 (F0 max) /I/ | 10.75 | 0.03 |
| F2 mean /I/ * | 20.62 | <0.001 |
| F2 max /I/ | 17.44 | 0.002 |
| F1 mean /u/ | 10.93 | 0.027 |
| F1 std /u/ | 10.44 | 0.034 |
| F1 min /u/ | 15.70 | 0.003 |
| F2 std /u/ | 14.29 | 0.006 |
| F2 max /u/ | 10.93 | 0.027 |
| F3 std /u/ | 12.80 | 0.012 |
| F3 max /u/ | 10.50 | 0.033 |
| F ratio * | 18.14 | 0.001 |
| F ratio * | 18.07 | 0.002 |
| F ratio | 11.94 | 0.018 |
| VSA * | 17.53 | 0.002 |
| FCR * | 26.98 | <0.001 |
| Parameter | Kruskal–Wallis H Statistic | p Value |
|---|---|---|
| F0 mean /a/ * | 18.70 | <0.001 |
| F0 min /a/ | 14.76 | 0.005 |
| F0 max /a/ * | 17.37 | 0.002 |
| NNE /a/ | 11.50 | 0.022 |
| F1 mean /a/ | 14.07 | 0.007 |
| F1 std /a/ * | 18.53 | <0.001 |
| F1 min /a/ * | 18.14 | 0.001 |
| F2 mean /a/ * | 19.01 | <0.001 |
| F2 std /a/ * | 16.00 | 0.003 |
| F2 min /a/ | 10.20 | 0.04 |
| F2 max /a/ * | 24.78 | <0.001 |
| F0 mean /I/ * | 18.70 | <0.001 |
| F0 std /I/ | 11.07 | 0.026 |
| F0 min /I/ * | 13.05 | 0.011 |
| F0 max /I/ * | 19.55 | <0.001 |
| Jitter /I/ | 21.09 | <0.001 |
| NNE /I/ | 10.41 | 0.034 |
| F1 std /I/ | 15.94 | 0.003 |
| F1 min /I/ | 13.07 | 0.011 |
| F2 mean /I/ | 14.13 | 0.007 |
| F2 std /I/ | 12.57 | 0.014 |
| F2 min /I/ | 15.65 | 0.004 |
| F3 mean /I/ | 17.60 | 0.001 |
| F3 min /I/ | 14.07 | 0.007 |
| F3 max /I/ | 15.14 | 0.004 |
| F0 mean /u/ | 17.24 | 0.002 |
| F0 std /u/ | 12.73 | 0.013 |
| F0 min /u/ * | 19.72 | <0.001 |
| F0 max /u/ | 11.87 | 0.018 |
| Jitter /u/ * | 11.77 | 0.019 |
| F1 mean /u/ | 17.38 | 0.002 |
| F1 min /u/ | 17.77 | 0.001 |
| F2 mean /u/ * | 13.89 | 0.008 |
| F2 std /u/ | 14.65 | 0.005 |
| F2 min /u/ * | 13.38 | 0.01 |
| F2 max /u/ * | 17.54 | 0.002 |
| F3 std /u/ | 10.50 | 0.033 |
| Parameter | Kruskal–Wallis H Statistic | p Value |
|---|---|---|
| F0 mean /a/ * | 22.61 | <0.001 |
| F0 min /a/ * | 21.28 | <0.001 |
| F0 max /a/ * | 22.29 | <0.001 |
| F1 std /a/ * | 23.17 | <0.001 |
| F1 min /a/ * | 14.70 | 0.005 |
| F2 mean /a/ * | 20.67 | <0.001 |
| F2 min /a/ * | 29.86 | <0.001 |
| F2 max /a/ * | 15.38 | 0.004 |
| F3 mean /a/ * | 19.49 | <0.001 |
| F3 min /a/ * | 18.36 | 0.001 |
| F3 max /a/ * | 18.19 | 0.001 |
| F0 mean /I/ * | 18.31 | 0.001 |
| F0 max /I/ * | 21.74 | <0.001 |
| NNE /I/ * | 24.75 | <0.001 |
| F2 mean /I/ * | 15.58 | 0.004 |
| F2 std /I/ * | 13.60 | 0.009 |
| F2 min /I/ * | 16.94 | 0.002 |
| F2 max /I/ * | 11.81 | 0.019 |
| F0 mean /u/ * | 25.06 | <0.001 |
| T0(F0 min) /u/ * | 15.99 | 0.003 |
| F0 max /u/ * | 24.86 | <0.001 |
| NNE /u/ * | 16.51 | 0.002 |
| F1 mean /u/ * | 11.67 | 0.02 |
| F1 std /u/ * | 17.51 | 0.002 |
| F1 min /u/ | 14.64 | 0.006 |
| F1 max /u/ * | 12.66 | 0.013 |
| F2 mean /u/ * | 16.32 | 0.003 |
| F2 min /u/ | 10.08 | 0.039 |
| F2 max /u/ * | 27.40 | <0.001 |
| F3 mean /u/ | 11.58 | 0.021 |
| F3 std /u/ * | 12.71 | 0.013 |
| F3 min /u/ * | 18.99 | <0.001 |
| F ratio * | 10.27 | 0.036 |
| F ratio * | 23.07 | <0.001 |
| VSA * | 22.82 | <0.001 |
| FCR * | 19.33 | <0.001 |
| PS | |||||
|---|---|---|---|---|---|
| Parameter | SMS | NS | CS | DS | HS |
| Precision | 88 ± 19% | 88 ± 23% | 100 ± 0% | 93 ± 14% | 100 ± 0% |
| Recall | 100 ± 0% | 80 ± 42% | 50 ± 53% | 100 ± 0% | 100 ± 0% |
| Specificity | 92 ± 14% | 96 ± 10% | 100 ± 0% | 95 ± 11% | 100 ± 0% |
| F1 Score | 93 ± 12% | 92 ± 15% | 100 ± 24% | 96 ± 8% | 100 ± 0% |
| AUC | 99 ± 1% | 97 ± 3% | 85 ± 4% | 81 ± 10% | 99 ± 0% |
| Validation Accuracy | 87 ± 9% | ||||
| FA | |||||
| Parameter | SMS | NS | CS | DS | HS |
| Precision | 60 ± 33% | 88 ± 34% | 100 ± 0% | 100 ± 0% | 100 ± 0% |
| Recall | 90 ± 32% | 70 ± 48% | 60 ± 52% | 90 ± 32% | 100 ± 0% |
| Specificity | 70 ± 23% | 100 ± 11% | 100 ± 0% | 100 ± 0% | 100 ± 0% |
| F1 Score | 77 ± 19% | 100 ± 0% | 100 ± 0% | 100 ± 0% | 100 ± 0% |
| AUC | 95 ± 5% | 96 ± 2% | 79 ± 9% | 93 ± 8% | 100 ± 0% |
| Validation Accuracy | 77 ± 19% | ||||
| MA | |||||
| Parameter | SMS | NS | CS | DS | HS |
| Precision | 78 ± 36% | 89 ± 33% | 94 ± 17% | 100 ± 0% | 100 ± 0% |
| Recall | 89 ± 33% | 89 ± 33% | 90 ± 32% | 80 ± 42% | 80 ± 30% |
| Specificity | 88 ± 19% | 97 ± 11% | 95 ± 16% | 100 ± 0% | 100 ± 0% |
| F1 Score | 92 ± 15% | 100 ± 0% | 96 ± 11% | 100 ± 0% | 87 ± 17% |
| AUC | 93 ± 5% | 97 ± 2% | 100 ± 0% | 100 ± 0% | 94 ± 5% |
| Validation Accuracy | 84 ± 17% | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calà, F.; Frassineti, L.; Sforza, E.; Onesimo, R.; D’Alatri, L.; Manfredi, C.; Lanata, A.; Zampino, G. Artificial Intelligence Procedure for the Screening of Genetic Syndromes Based on Voice Characteristics. Bioengineering 2023, 10, 1375. https://doi.org/10.3390/bioengineering10121375
Calà F, Frassineti L, Sforza E, Onesimo R, D’Alatri L, Manfredi C, Lanata A, Zampino G. Artificial Intelligence Procedure for the Screening of Genetic Syndromes Based on Voice Characteristics. Bioengineering. 2023; 10(12):1375. https://doi.org/10.3390/bioengineering10121375
Chicago/Turabian StyleCalà, Federico, Lorenzo Frassineti, Elisabetta Sforza, Roberta Onesimo, Lucia D’Alatri, Claudia Manfredi, Antonio Lanata, and Giuseppe Zampino. 2023. "Artificial Intelligence Procedure for the Screening of Genetic Syndromes Based on Voice Characteristics" Bioengineering 10, no. 12: 1375. https://doi.org/10.3390/bioengineering10121375
APA StyleCalà, F., Frassineti, L., Sforza, E., Onesimo, R., D’Alatri, L., Manfredi, C., Lanata, A., & Zampino, G. (2023). Artificial Intelligence Procedure for the Screening of Genetic Syndromes Based on Voice Characteristics. Bioengineering, 10(12), 1375. https://doi.org/10.3390/bioengineering10121375