1. Introduction
Parkinson’s Disease (PD) is a neurodegenerative disorder caused by the gradual death of dopaminergic neurons in the substantia nigra [
1]. The impact of this neurodegenerative condition on speech is characterised by a reduced vocal loudness, a monotonous voice, a reduced fundamental frequency range, imprecise consonants and vowels, breathiness, and inappropriate pauses [
2]. These symptoms are collectively known as hypokinetic dysarthria, and typically appear early in most patients with PD [
3]. As a result, speech-based and voice-based assessments of PD have become an essential research topic for providing early diagnoses of PD. The primary advantage of automatic PD screening tools lies in their ability to offer a non-invasive diagnosis, which can enable timely screening applications and facilitate remote health monitoring [
4].
In recent years, extensive work has been published, suggesting the potential of voice and speech characteristics as biomarkers for the development of automatic screening tools for PD. Among the state-of-the-art contributions are those based on traditional machine learning approaches, such as support vector machines, random forests, k-nearest neighbours, regression trees, and naïve Bayes [
4,
5,
6,
7,
8,
9,
10]. These methods were trained using both acoustic features (including certain variants of the jitter, shimmer, and harmonic-to-noise ratio) and complexity measurements to model the influence of PD on patient phonation [
11]. However, recent studies that incorporate Mel-frequency cepstral coefficients have significantly improved the accuracy and specificity of classification [
12].
In addition to traditional machine learning algorithms, deep learning (DL) approaches are gaining considerable popularity because of their ability to exploit high-level abstract representations from not only the voice, but also the speech. DL techniques reported for PD detection include mappings from handcrafted acoustic features to output labels (PD/healthy) [
13,
14,
15,
16], as well as end-to-end systems that offer the advantage of directly mapping the raw speech signal or time–frequency spectrograms to output labels [
6,
17,
18,
19,
20,
21,
22]. In this respect, several architectures have been successfully used, such as multilayer perceptrons (MLPs) [
13,
15], a combination of convolutional neural networks (CNNs) and MLPs [
6,
17,
18], recurrent neural networks (RNNs) [
19], a combination of CNNs and long short-term memory (LSTM) networks [
16,
20], or combinations of time-distributed 2D-CNN and 1D-CNN [
21,
22]. Furthermore, some of these architectures have been implemented by following a transfer learning (TL) strategy to adapt models from the already-grained storing knowledge on similar problems [
18,
23,
24,
25,
26].
Most reported DL methods have shown valuable results in the binary categorisation between healthy controls (HCs) and PD when trained with a single dataset. However, even though end-to-end DL approaches have shown promising results in extracting abstract and discriminative features, the available corpora with voice/speech material from PD patients usually contain a small number of speakers (usually less than 100 subjects). This has led researchers focused on applying DL methods to combine data from several sources, which were recorded in different conditions and from speakers with different demographic characteristics (including their mother tongue). To this respect, and in order to address the generalisation capabilities of trained models, the authors in [
21,
27,
28] presented cross-dataset experiments, reporting significant drops in precision of more than 20 absolute points when using different corpora for testing and training. As shown in [
29,
30], although the combination of multiple datasets is intended to model the representation space better and to avoid overfitting due to data scarcity, it can also induce certain unwanted behaviours, since DL approaches typically make use of shortcut learning strategies capable of reducing the training loss function by learning characteristics associated with the dataset (e.g., the language, microphone, recording equipment, acoustic environment, etc.) but not necessarily related with the specific phenomenon under analysis (i.e., the presence of PD). Despite this fact, which highlights a significant limitation of DL methods, also demonstrating a noticeable degradation in their discriminative capabilities across corpora, the most recent work continues to compare models based solely on their accuracy in a single corpus.
Thus, as reported for other applications [
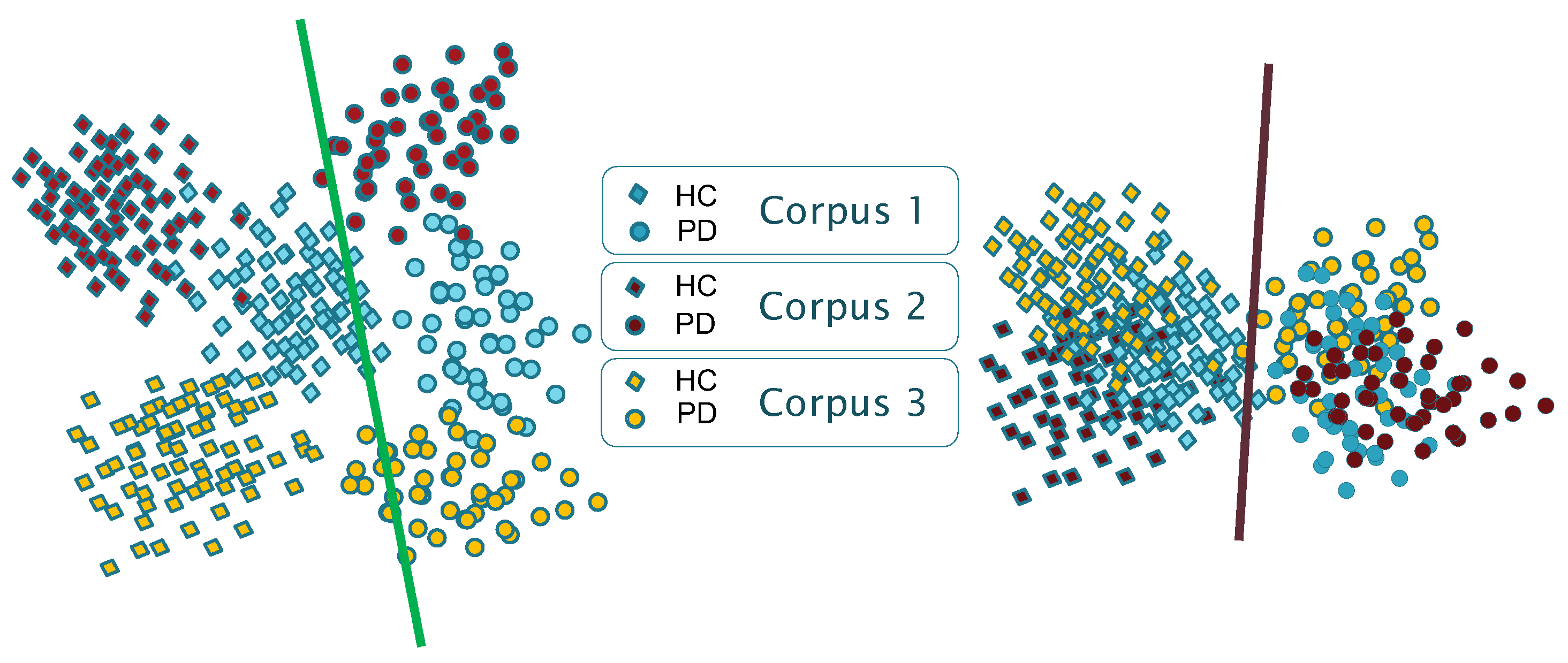
29], the results presented in the state-of-the-art suggest that the available models suffer from certain biases and shortcuts. As schematically shown in
Figure 1, models show corpus-dependent clusterings when data from different datasets are combined for training. This is mainly due to the small size of the corpora typically used, but also due to the specific language and channel characteristics of each corpus (differences in the recording equipment, recording parameters, room acoustics, ambient noise, external sounds, etc.). Consequently, a reasonable assumption is that each database encapsulates specific characteristics that could be associated with a distinct domain (including the language), and that DL architectures follow shortcut learning strategies to model the specific conditions of the available corpora. This suggests that trained models capture, in part, distinguishing characteristics between domains (i.e., corpora) rather than only capturing generic features that effectively discriminate the underlying pathology (which is supposed to be corpus and language independent).
As a result, robust model representations are needed to mitigate these undesired factors. We argue that an embedding domain adaptation strategy applied to the learning representation process would narrow the existing gap between different corpora. The goal is to train discriminative and invariant models to domain changes. From now on, we will talk about the domain in reference to a certain corpus.
In view of the aforementioned, this work focuses on studying the potential of domain adversarial (DA) training methods [
30,
31] to provide more generic and reliable models for the automatic screening of PD using voice and speech. Results are expected to be independent of the specific characteristics of the corpus. Although with a different strategy to identify the domain, the DA training has been explored in other speech applications, such as automatic speech recognition [
32], speech emotion recognition [
33,
34], spoken language identification [
35], accent speech recognition [
36], and voice conversion [
37]. In the context of PD screening, a first attempt of applying domain adaptation was presented in [
38], which used speaker identity-invariant representations from a single database (i.e., each domain is assumed to correspond to one speaker), but excluding multi-dataset scenarios.
For this purpose, this paper presents a comparison of three DL architectures widely used in the literature, but trained following DA methods, under the assumption that each corpus corresponds to a different domain. This is carried out using four corpora, which contain speakers with different mother tongue, demographic, and dialectal variations, and who were recorded under different recording conditions.
The main contributions of this work are enumerated next:
The development of more generalizable methods for the screening of PD by refining the existing end-to-end DL approaches using voice and speech.
The integration of DA training as a viable strategy to develop models that retain their discriminative capacity to detect PD using the voice/speech from diverse datasets.
The development of artificial models for the screening of a PD invariant to the mother tongue, demographic, and dialectal variations, as well as corpus recording conditions.
The reduction in existing learning shortcuts due to the domain (i.e., the corpus) for the screening of PD from voice/speech.
The reduction in the variability and inter-domain divergence computed within each class (i.e., voice/speech from PD or HC speakers).
The paper is organised as follows.
Section 2 introduces the material and methods used in this paper.
Section 3 mainly describes the results and an analysis of the different experiments.
Section 4 presents a discussion of the results. And
Section 5 ends with the conclusions.
2. Materials and Methods
This section provides detailed information on the materials and stages involved in the methodology.
The acoustic material used in this work is the sustained phonation of the vowel /a/, and a classic diadochokinetic (DDK) exercise (repetition of the syllable sequence /pa-ta-ka/). This acoustic material is available in the four corpora employed. The differences between the utterances of speakers from the different datasets are supposed to be mainly due to language or dialectal variations.
For modelling, three deep learning (DL) models were chosen based on their promising results presented in previous studies [
21,
26,
39]. For each architecture, a baseline model was developed by selecting the best hyperparameters for a binary categorisation of healthy and pathological voices using a database of voice disorders. The networks trained with this dataset were later adjusted to detect PD, following a TL strategy. For this purpose, the first layer was frozen, and each model was re-trained for the new task. The performance of these three baseline networks was evaluated within each corpus and with combined datasets. Finally, the accuracy of the baseline architectures was compared with their DA counterparts.
2.1. Corpora
The four PD databases employed in this work have been widely used in the literature. In the following, they are referred to as PD-GITA [
40], PD-Neurovoz [
27], PD-Czech [
41], and PD-German [
42]. Each database includes both PD patients and HC subjects, with patients diagnosed and labelled by neurologists following the Unified Parkinson’s Disease Rating Scale (UPDRS) and the Hoehn and Yahr scale (H&Y). These databases vary in demographics and sizes, as summarised in
Table 1. In all cases, the data recordings were conducted under controlled ambient conditions, with the staff instructing each participant to perform various speech tasks, including the sustained phonation of vowel /a/ and a DDK exercise. They have a reasonably good balance of age and sex.
These databases were freely available or transferred for research purposes by the respective authors. A brief description of each database is given below.
Table 1.
Demographic information, including gender, mean age (standard deviation), and age ranges, for the PD-GITA, PD-Neurovoz, PD-Czech, and PD-German corpora.
Table 1.
Demographic information, including gender, mean age (standard deviation), and age ranges, for the PD-GITA, PD-Neurovoz, PD-Czech, and PD-German corpora.
| Corpus | Subjects | Age (Years) | Age Range (Years) |
|---|
|
Female
|
Male
|
Female
|
Male
|
Female
|
Male
|
|---|
|
PD
|
HC
|
PD
|
HC
|
PD
|
HC
|
PD
|
HC
|
PD
|
HC
|
PD
|
HC
|
|---|
| PD-GITA | 25 | 25 | 25 | 25 | 60.1 (7.8) | 60.7 (7.7) | 62.2 (11.2) | 61.2 (11.3) | 44–75 | 43–76 | 33–77 | 31–86 |
| PD-Neurovoz | 21 | 23 | 23 | 24 | 70.0 (8.6) | 69.5 (7.4) | 67.0 (10.2) | 61.0 (7.5) | 56–86 | 58–86 | 41–80 | 53–77 |
| PD-Geman | 41 | 44 | 47 | 44 | 67.2 (9.7) | 62.6 (15.2) | 66.7 (8.7) | 63.8 (12.7) | 27–84 | 28–85 | 44–82 | 26–83 |
| PD-Czech | 20 | 20 | 30 | 30 | 60.1 (8.7) | 63.5 (11.1) | 65.3 (9.6) | 60.3 (11.5) | 41–72 | 40–79 | 43–82 | 41–77 |
2.1.1. PD-GITA
A total of one hundred native Colombian Spanish speakers (50 HC and 50 PD) were recruited to create the PD-GITA speech database. They were recorded at Clínica Noel in Medellín, Colombia. The recording protocol included various tasks, such as sustained phonations of the vowels (/a/, /e/, /i/, /o/, and /u/), diadochokinetic evaluation, repetition of different words, both complex and simple sentence repetitions, reading a text, and delivering a monologue. The recordings were sampled at 44.1 kHz with 16-bits of resolution, using a dynamic omnidirectional microphone (Shure, SM 63L). More details about the database are given in [
40].
2.1.2. PD-Neurovoz
Ninety-one adult speakers (44 HC and 57 PD), native speakers of Castilian Spanish, were recruited for the speech recordings in this database. The samples were collected by the Otorhinolaryngology and Neurology Departments of Gregorio Marañón Hospital in Madrid, Spain. This corpus includes recordings of sustained vowels, DDK tests, six fixed sentences, and running speech describing a picture. Speech signals were recorded using an AKG C420 headset microphone connected to a phantom power preamplifier. The sampling rate was 44.1 kHz, and the quantisation was carried out with 16-bits. Detailed information about this database can be found in [
27,
43].
2.1.3. PD-German
A total of one hundred seventy-six German native speakers were recruited to create this database (88 HC and 88 PD). The speech recordings were collected at a hospital in Bochum, Germany. They were engaged in various speech tasks, including sustained vowels, DDK tests, reciting five sentences, reading an 81-word text, and delivering a monologue. The recording samples were obtained using a headset microphone (Plantronics Audio 550 DSP; Plantronics Inc., Santa Cruz, CA, USA), placed 5 cm from the participant’s mouth, with a sampling rate of 44.1 kHz and 16-bits of resolution. More detailed information about the PD-German database can be found in [
42].
2.1.4. PD-Czech
A total of one hundred native Czech speakers participated in this study (50 HC and 50 PD). The PD-Czech database was compiled at the General University Hospital in Prague, Czech Republic. The speech tasks included in this corpus consist of the sustained phonation of vowel /a/, DDK tests, reading of a set of 80 distinct Czech words, and delivering a monologue. All samples were recorded using an external condenser microphone positioned approximately 15 cm from the participants’ mouth. The sampling rate was 48 kHz with a 16-bit resolution. For additional information about this corpus, please refer to [
41].
2.1.5. Saarbrücken Voice Disorders Database
The Saarbrücken Voice Disorders Database (SVDD) [
44] was used to train the initial models that were later adapted using a TL strategy. This database was compiled by personnel from the Institute of Phonetics at the University of Saarland in Germany. The corpus contains voice recordings from 687 healthy controls and 1355 individuals with different pathological conditions. All of them are native German speakers. The SVDD includes recordings of the sustained vowels /a/, /i/, and /u/ under four different loudness conditions (normal, high, low, and low–high–low), vowels with rising–falling pitch, and one sentence. All samples were recorded at 50 kHz with 16-bits of resolution. The SVDD database is available online at [
44].
2.2. Data Pre-Processing
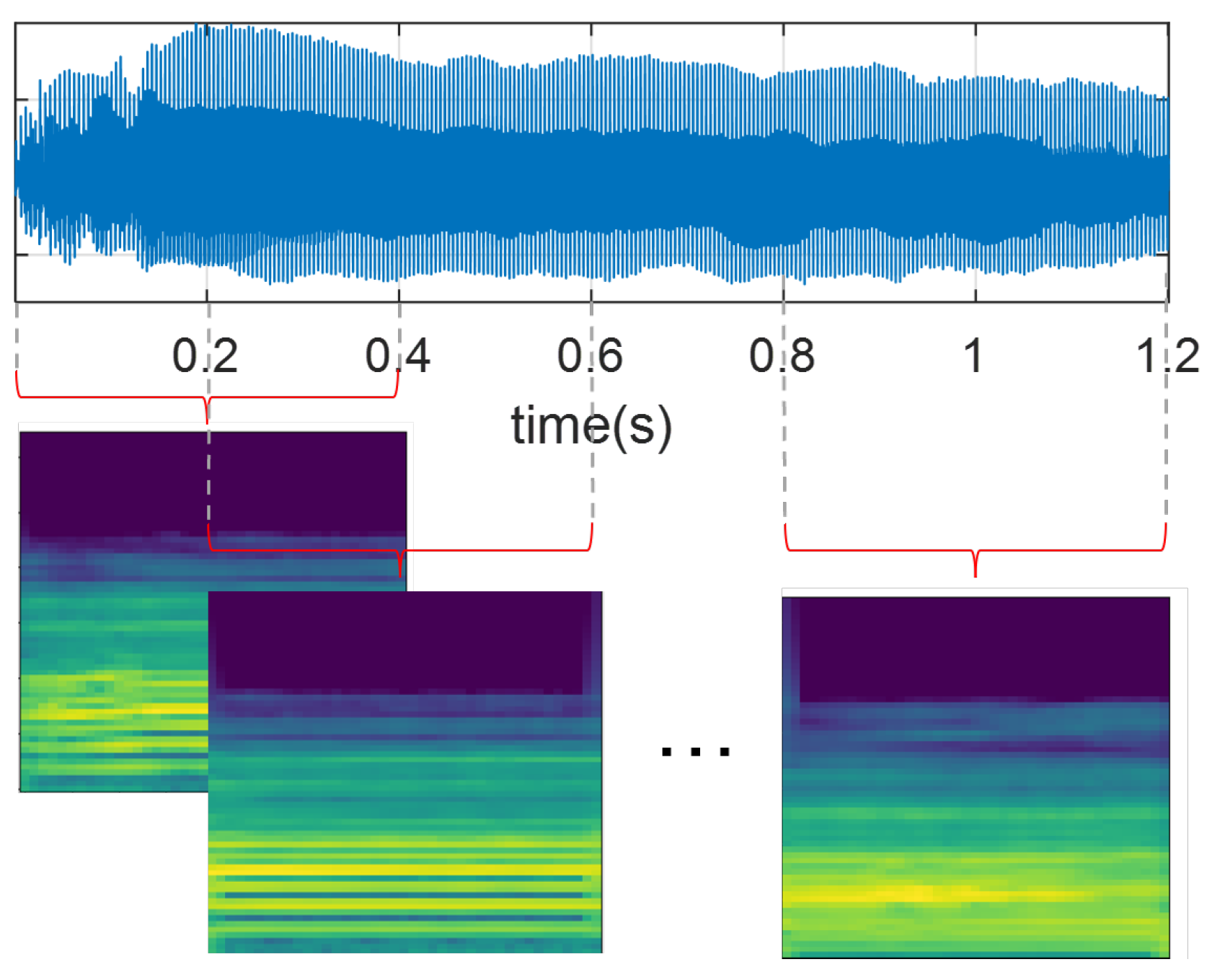
All audio recordings from the PD-Czech and SVDD databases were resampled at 44.1 kHz to ensure a consistent sampling rate concerning PD-GITA and PD-Neurovoz. Signals were then segmented into 400 ms segments with a 50% of overlap, as illustrated in
Figure 2. The window size was selected to preserve all subject recordings, considering that some recordings of vowel /a/ in the PD-GITA dataset have a maximum duration of 490 ms. Additionally, all speech signals were normalised based on the maximum absolute amplitude values.
Subsequently, all recordings were transformed into the time–frequency domain using Mel-scale spectrograms [
20,
21,
38]. For this study, we computed the Mel-scale representations using windows that were 40 ms long for the sustained phonation of vowel /a/ to preserve the quasi-stationarity assumption and ensure independence from the location of pitch pulses within the segment, as discussed in [
45]. For DDK tests, fifteen-millisecond-long frames were extracted, which yielded optimal results in a previous study [
46]. In both cases, the hop length was set to 10 ms, and the number of Mel bands was set to 65. Finally, the resulting Mel-scale spectrogram images (with their amplitude in dBs), each sized 65 × 41 pixels, were normalised following a z-score scaling.
2.3. Domain Adversarial Networks
Figure 3 illustrates the three DL architectures adapted for DA training: 2D-CNN, Time-CNN-LSTM, and 1D-CNN. The choice of these base architectures is strongly motivated by their success in classifying PD from voice and speech, as demonstrated in [
6,
16,
17,
20,
21,
26]. Additionally, their requirements in terms of memory and graphics processing unit (GPU) are reasonable, and they are well documented and well understood. The choice of these architectures is also motivated by a potential comparison of the results with previous works in the state-of-the-art.
Each architecture was adapted, following the DA neural network framework proposed in [
31]. Consequently, all architectures consist of three modules: a feature extractor, a PD detector, and a domain detector (i.e., a corpus detector). The feature generator serves as a shared network between both the PD and the domain detectors, receiving the Mel spectrograms as input. The PD detector’s role is to discriminate the primary learning task (i.e., binary classification between PD and HC), trying to minimise the classification error. However, the domain detector aims to maximise the error due to the dataset to which the observation belongs, i.e., it promotes the information extracted from the spectrograms to be unable to discriminate among corpora. The domain detector is linked to the feature extractor through a gradient reversal layer (GRL), which maintains the input’s integrity during forward propagation and reverses the gradient by multiplying it with a negative scalar during backpropagation, as outlined in [
30]. The application of the gradient reversal ensures that the feature distributions across the four domains (datasets) become more similar, which would lead to the generation of domain-invariant features.
In order to obtain more generalisable results, a TL strategy was also followed from other models created using large corpora trained for similar classification tasks. To this respect, the baseline architecture (consisting of both the feature extraction module and the PD detection module) underwent a pretraining to classify healthy speakers and patients with voice disorders. This is carried out using the vowels available in the SVDD database. Despite the fact that this dataset contains voices associated with various pathologies, previous research has shown that a similar strategy can significantly improve the accuracy of PD detection [
18,
23,
24,
25,
26]. TL was implemented herein through freezing only the initial layer of the feature extractor (highlighted in grey in
Figure 3). The freezing of more layers was refrained to ensure an adequate number of parameters that could be used for the fine-tuning stage during the DA training.
In the three networks, the architecture of the PD detector and the domain detector is similar, consisting of two fully connected layers with a dropout layer in between to regularise the weights. ReLu activation was used in the first hidden layers, and a softmax activation function was applied for classification. Regarding the feature extractor module, this component varies among the architectures. A brief description of them and their specific configurations is presented below.
2.3.1. 2D-CNN Network
CNN is a well-known architecture for classifying data presented as a multi-dimensional array, such as greyscale and colour images, time–frequency representations of audio, and videos [
47]. Therefore, CNNs have been widely employed for the screening of PD, converting the audio signals into time–frequency representations [
6,
17,
18,
21,
26,
39]. The CNN architecture implemented in this work is illustrated in
Figure 3a. This network comprises two-dimensional convolutional layers, where each convolutional layer is followed by a batch normalisation, a ReLU activation function, max pooling (filter size: 3 × 3), and a dropout layer. Subsequently, the dynamic features obtained by the first module are flattened to connect with the first fully connected layer of both the PD detector and the domain detector. Since similar architectures have been used in the literature but with varying filter sizes, in this work, they are set using the cross-validation strategy discussed in
Section 2.4. The 2D-CNN network architecture takes one Mel-scale spectrogram as input at a time. To determine the ultimate patient classification, a post-processing stage calculates the joint probability for all spectrograms obtained from a single patient and assigns the patient to the class with the highest joint probability.
2.3.2. Time-CNN-LSTM Network
The combination of time-distributed CNN and LSTM networks enables the mapping of time-varying features from a multi-dimensional source [
48]. In this architecture, the input is treated as a temporal sequence, where a time-distributed convolution layer applies the same transformation to each input frame. The role of the LSTM is to extract global temporal features. In this study, the architectural configuration is illustrated in
Figure 3b. Unlike the 2D-CNN network architecture, in this case, the input is a sequence of
n consecutive frames of Mel spectrograms from the same recording, with zero padding applied when the signal lengths are insufficient to complete
n frames; a masking strategy removes the zeros during the processing phase. Hence, this network comprehensively analyses all patient information in a single forward pass, eliminating the necessity for any post-processing to arrive at a final prediction for the patient. The initial stage comprises two time-distributed 2D-CNN layers. Similarly to the previous network, each convolutional layer is followed by batch normalisation, a ReLU activation function, max pooling (with a filter size of 3 × 3), and a dropout layer. Subsequently, the flattened outputs of the time-distributed CNN serve as the input sequential features for a bidirectional LSTM. The hidden states of the LSTM cells are used as input features for both the PD and the domain detector. Similar to the previous architecture, the size of the convolutional filters is set during the experimental phase.
2.3.3. 1D-CNN Network
This architecture was proposed in [
49]. It consists of several 1D-CNN layers, and its temporal output is summarised through a convolutional attention mechanism, as illustrated in the scheme in
Figure 3c. The first layer of the network corresponds to a flatten operator aiming to fit together the 2D spectrogram inputs with the 1D convolutional layers. The network comprises three convolutional blocks with kernel sizes of 5, 11, and 21, respectively, with max pooling layers (kernel size of 6) in between. Each convolutional block includes a one-dimensional convolution, followed by batch normalisation, a ReLU activation function, and a dropout layer. In the last 1D-CNN layer, half of the filters are subjected to a time-wise softmax activation, which functions as an attention mechanism for the other half of the filters [
49]. Subsequently, the attention output serves as input features for both the PD and the domain detector. Similar to the 2D-CNN network, a post-processing stage to obtain the ultimate prediction per patient is also used.
2.4. The Experimental Setup
For all experiments, the training and evaluation were performed following a stratified speaker-independent 10-fold cross-validation strategy, ensuring that there was no overlap of speakers across different folds. First, the hyperparameters of the baseline architectures were tuned using Talos [
50] with 10-folds extracted from the SVDD dataset.
Table 2 summarises the hyperparameter search space. The model with the best performance on the validation set among the 10 folds was selected for all experiments, including for the DA training, where the domain detector network parameters were set to the same values as the PD detection network parameters. All models were evaluated in terms of accuracy, sensitivity, specificity, and F1 score.
The different architectures were trained using the Stochastic Gradient Descent (SGD) algorithm with cross-entropy as the loss function. When training with imbalanced datasets, such as the SVDD corpus and for the domain detector, a weighted cross-entropy loss function was used, where the weights were automatically set to compensate for the data imbalance. A learning rate schedule was used, initialised as 0.1.
The models were trained using a workstation equipped with two NVIDIA GeForce RTX3090 GPUs with 24 gigabytes of VRAM memory each.
4. Discussion
DL methods have shown promise in extracting discriminative features for the detection of PD from voice and speech. However, due to ethical constraints and the large amount of resources needed to collect the required corpora, existing studies often suffer from limited training data, leading researchers to combine recordings from different sources. However, this mixing of datasets results in a loss of precision when networks are trained with one dataset and tested on another. This is attributed to certain biases and shortcuts learnt by DL networks related to dataset-specific characteristics, which include not only the language of the speakers, but also the channel characteristics of each corpus (i.e., recording equipment, recording parameters, room acoustics, ambient noise, external sounds, etc.).
On the other hand, previous analyses of end-to-end DL architectures for PD classification using voice and speech recordings have mainly relied on comparing architectures trained with a single corpus. However, the experiments conducted on individual and multiple datasets reveal that the models obtained lack generalisability: although they demonstrate high performance when trained on a single database, their performance drops significantly when trained using multiple corpora.
A detailed analysis of the results provided in the state-of-the-art shows that traditional end-to-end DL architectures are not able to learn the expected corpus-independent characteristics of PD. This is due to the presence of shortcuts in the learning process, which are manifested as corpus-dependent clusterings of the features extracted. As aforementioned, they are mainly explained not only due to the small size of the corpora used, but also due to language differences, demographics of the population, and variances in the channel characteristics of each corpus.
In order to address these issues, this work explores the use of DA training as a strategy to develop new artificial models capable of detecting PD from voice and speech by combining data from different corpora. In this regard, this paper uses three off-the-shelf DL architectures and their DA counterparts, the latter developed under the assumption that each corpus corresponds to a different domain. The architectures developed were evaluated with sustained vowels and DDK recordings extracted from four different corpora with a variety of dialects or languages, demographics, and channel characteristics. Additionally, in order to obtain more robust models, this work combines DA training with a TL approach.
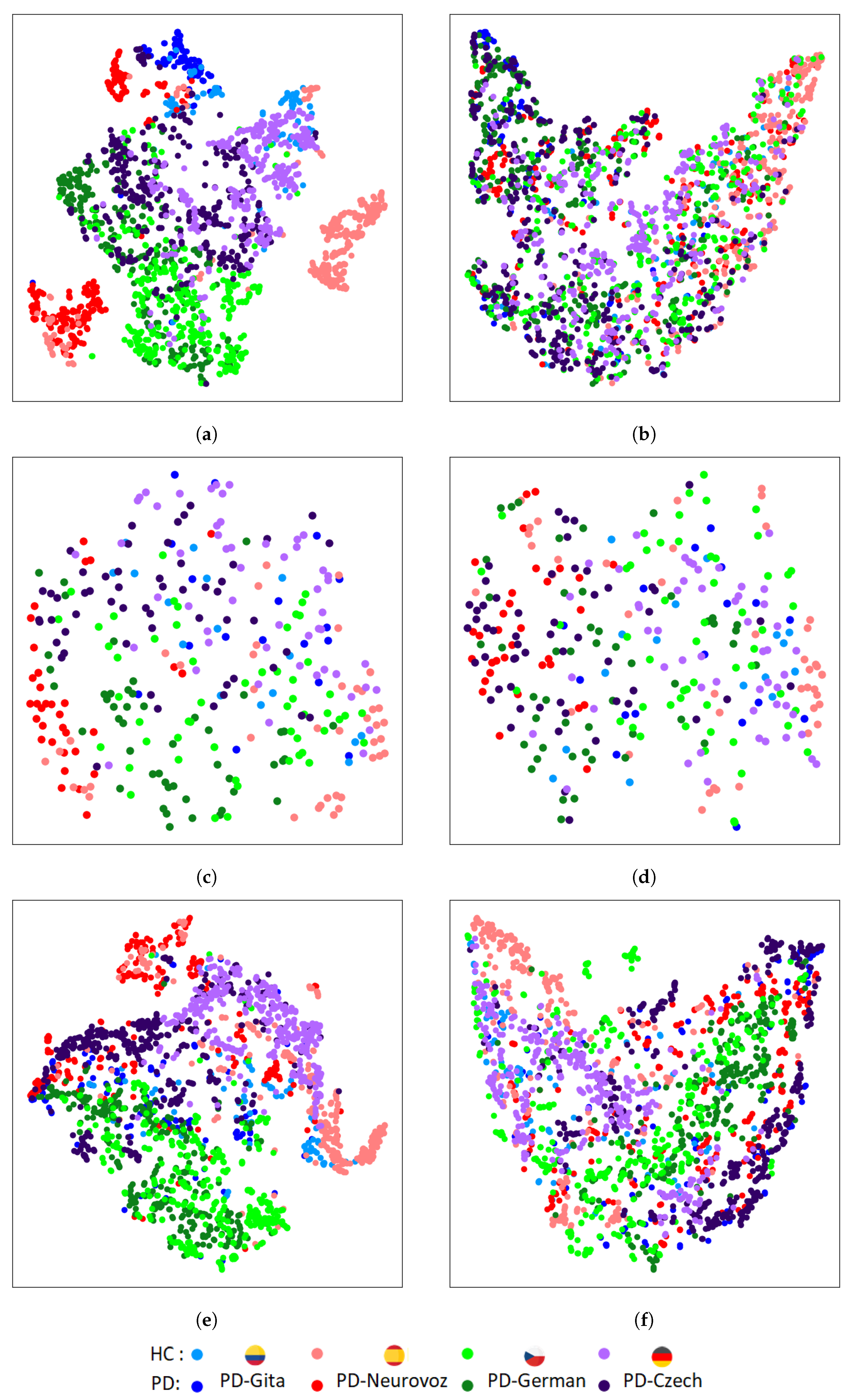
The results reported based on the objective distance metrics used in this article (KL divergence between the intra-class domain feature distributions, and TCM for the intra-class domain features) and based on the t-SNE plots of the features extracted from the baseline architectures trained using several datasets evidence the aforementioned extremes. They show a clear clustering related to the variability of the domain (i.e., the corpus), rather than a clustering based only on discriminatory characteristics of PD. It is important to note that this limitation is more evident for 2D-CNN, which has been widely used for the detection of PD [
6,
23,
24,
25,
26].
On the other hand, results reported based on the objective distance metrics used and based on the t-SNE plots extracted from the DA networks show that learnt features from the four corpora follow a similar clustering for both classes considered (i.e., HC and PD). Such clustering has demonstrated to be corpus independent and does not rely on language differences and potential variances in the channel characteristics.
These results align with our preliminary work in which we implemented a DA CNN trained with DDK recordings extracted from PD-GITA and PD-Neurovoz [
54]. The new experiments presented in this paper, including new corpora, different tasks, and new architectures, provide new evidence that DA training improves the generalisability of the models obtained.
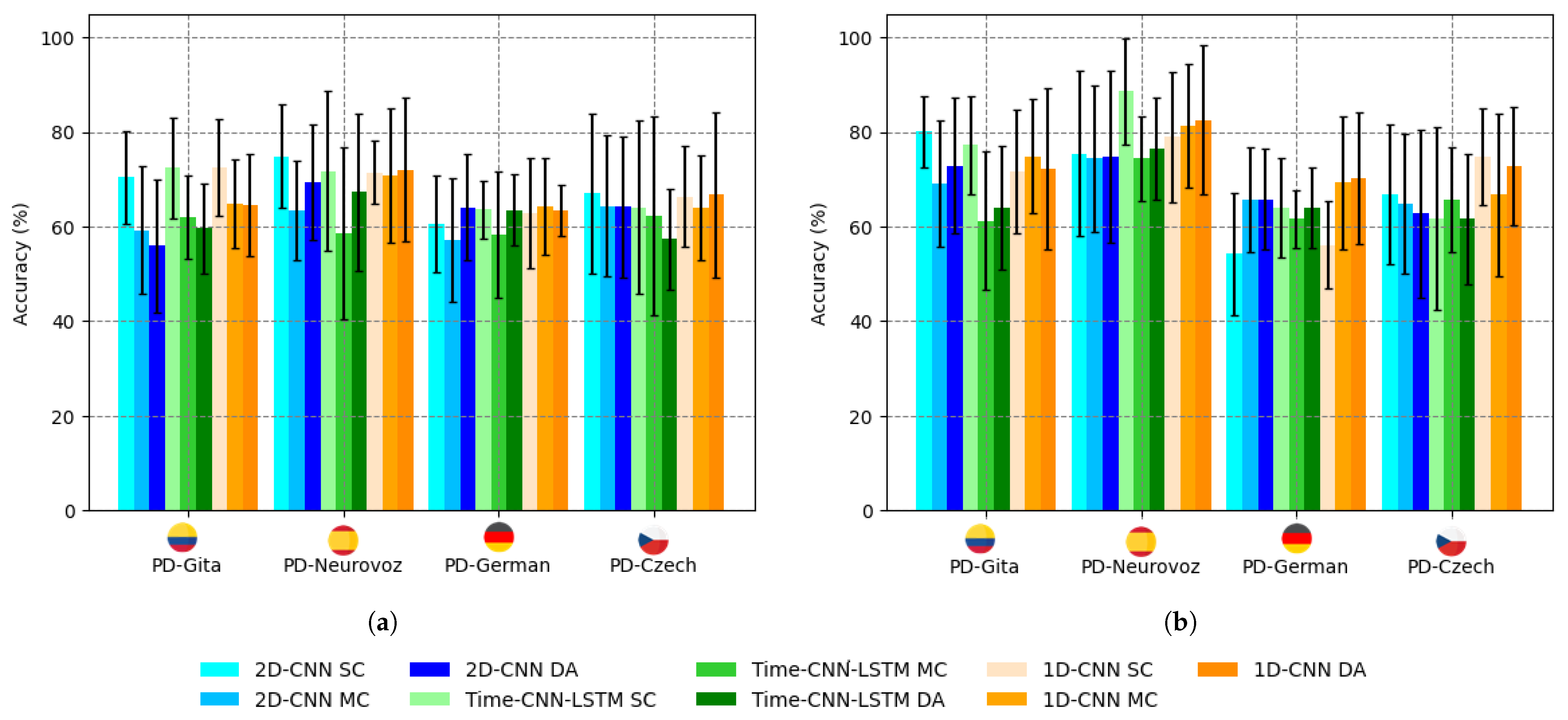
On a different note, the study also indicates that architectures trained using sustained vowels are less efficient compared to those trained with DDK tests. These findings are consistent with the research in [
46], which emphasises the importance of articulation for the automatic detection of PD. The absence of articulatory information from sustained vowels explains why the accuracy is below 70% (
Figure 4a) for standard training or 75% using a TL approach (
Table 3).
The results suggest that DA training introduces a certain degree of interpretability in the artificial models, but this technique still relies on DL architectures with limited explainability. On the other hand, despite the encouraging results obtained, the corpora used are still too small to ensure that the results could be extrapolated to larger datasets.
5. Conclusions
We discussed some challenges in developing accurate PD screening models using voice and speech data, particularly when combining training data from different sources. In this regard, we suggest DA training as a potential solution to mitigate shortcut learning effects and dataset-specific biases, as well as to improve model generalisation across different corpora. This makes the models developed more interpretable, thus improving the possibility of transfer to clinical practice.
This study investigates three end-to-end DL approaches, along with their respective DA networks, for the detection of PD in a multi-corpus scenario. Our analysis of the extracted features revealed that traditional DL methods perform corpus-dependent clusterings of the features, hindering the generalisation capabilities of DL models for PD detection. On the other hand, the study provides evidence suggesting that DA strategies mitigate this effect.
In light of these findings, we consider DA to be an effective approach for creating robust corpus-independent PD detection models from voice and speech. Our exploration has highlighted the potential of DA methods as a promising approach to accomplish this objective. Thus, they provide a practical pathway toward creating language-independent and corpus-invariant PD detection models.
This research contributes to ongoing efforts to improve the detection of PD and paves the way for further investigations into domain adaptation techniques in medical speech analysis. We believe that the insights gained from this study will be valuable for the advancement of the field.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


 PD-GITA
PD-GITA PD-Neurovoz
PD-Neurovoz PD-German
PD-German PD-Czech
PD-Czech