
Pixel Diffuser: Practical Interactive Medical Image Segmentation without Ground Truth

 , , , , and
, , , , and 
Abstract
:1. Introduction
- In this work, we present an innovative interactive medical segmentation model called PixelDiffuser. Unlike traditional approaches, our model does not necessitate specialized training on medical segmentation datasets. Instead, we leverage a simple autoencoder trained on general image data.
- The PixelDiffuser operates interactively by initiating the segmentation process from a single click point. This strategic approach ensures that the model gradually identifies the target mask, thereby mitigating the risk of overstepping the actual ground truth region. Consequently, the need for excessive user inputs is significantly reduced.
- Through comprehensive experiments, we showcase the remarkable efficiency of our proposed algorithm. With only a minimal number of clicks, our approach outperforms alternative methods in achieving accurate target segmentation.
2. Related Works
2.1. Medical Image Segmentation
2.2. Medical Interactive Image Segmentation
3. Motivation
3.1. The Reconstruction Noises
3.2. From the Reconstruction Noises to Segmentation Mask
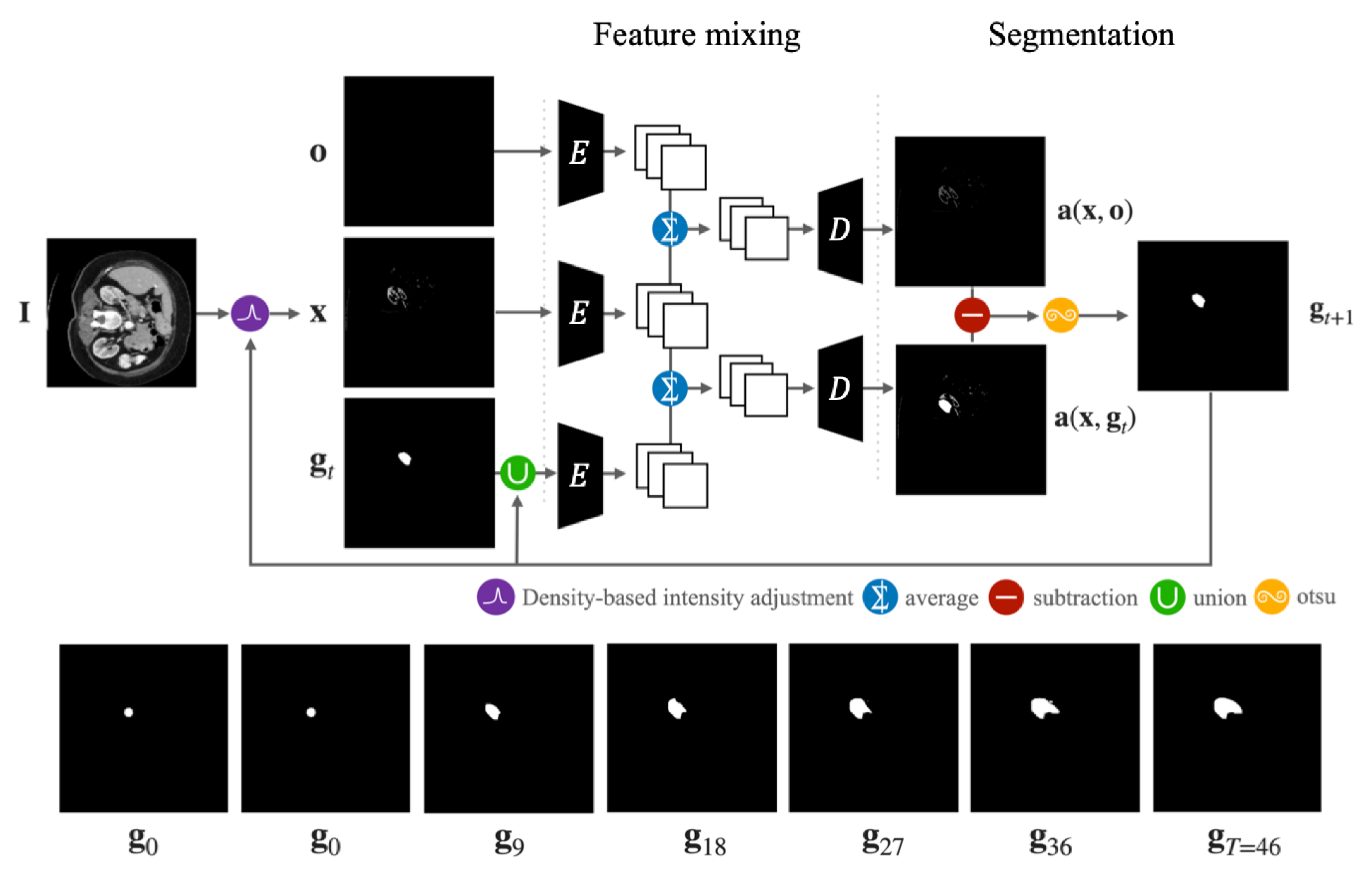
4. The PixelDiffuser
4.1. Initial Segmentation Process
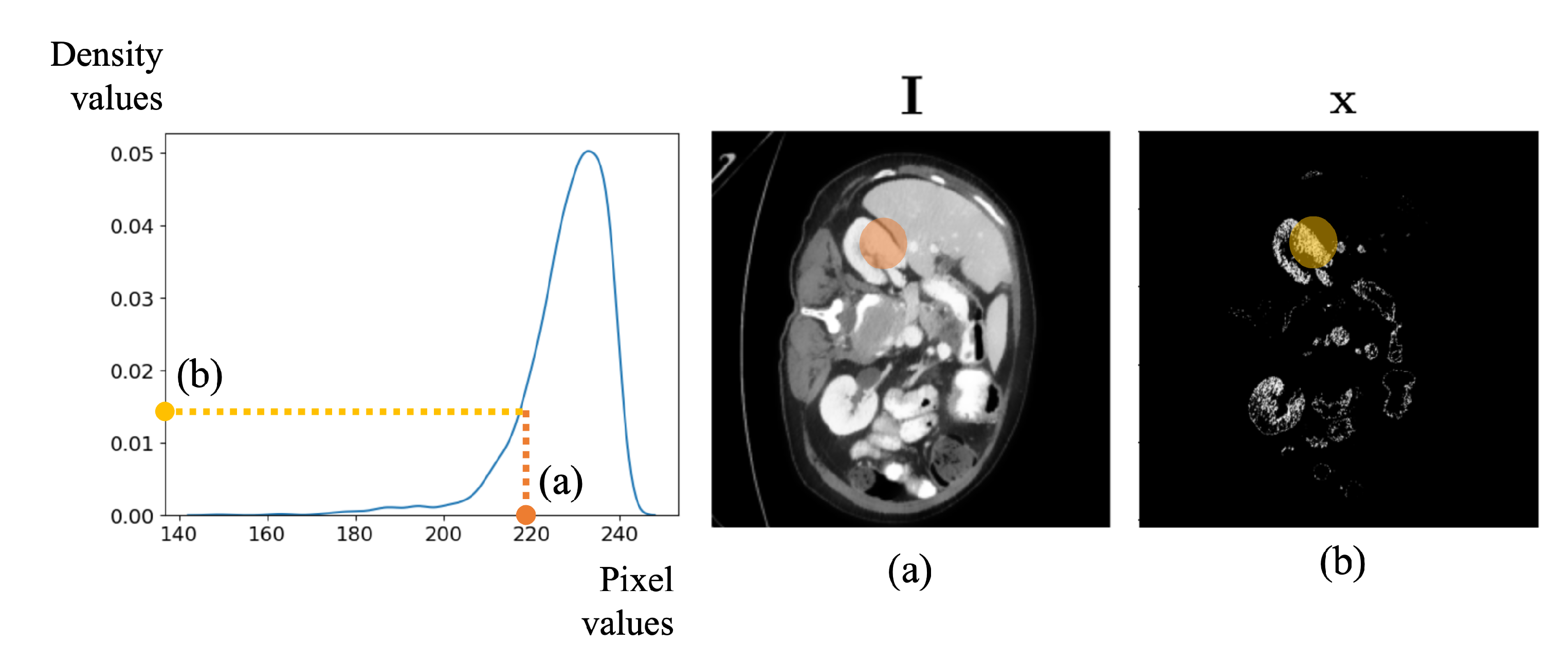
4.1.1. Density-Based Intensity Adjustment
4.1.2. Feature Mixing
4.1.3. Segmentation
4.2. Refinement Process
5. Experiments
5.1. Dataset
5.1.1. BTCV
5.1.2. CHAOS
5.2. User Interaction
5.3. Implementation Details
5.4. Description of Other Methods
5.4.1. RITM
5.4.2. SimpleClick
5.4.3. SAM
5.4.4. FastSAM
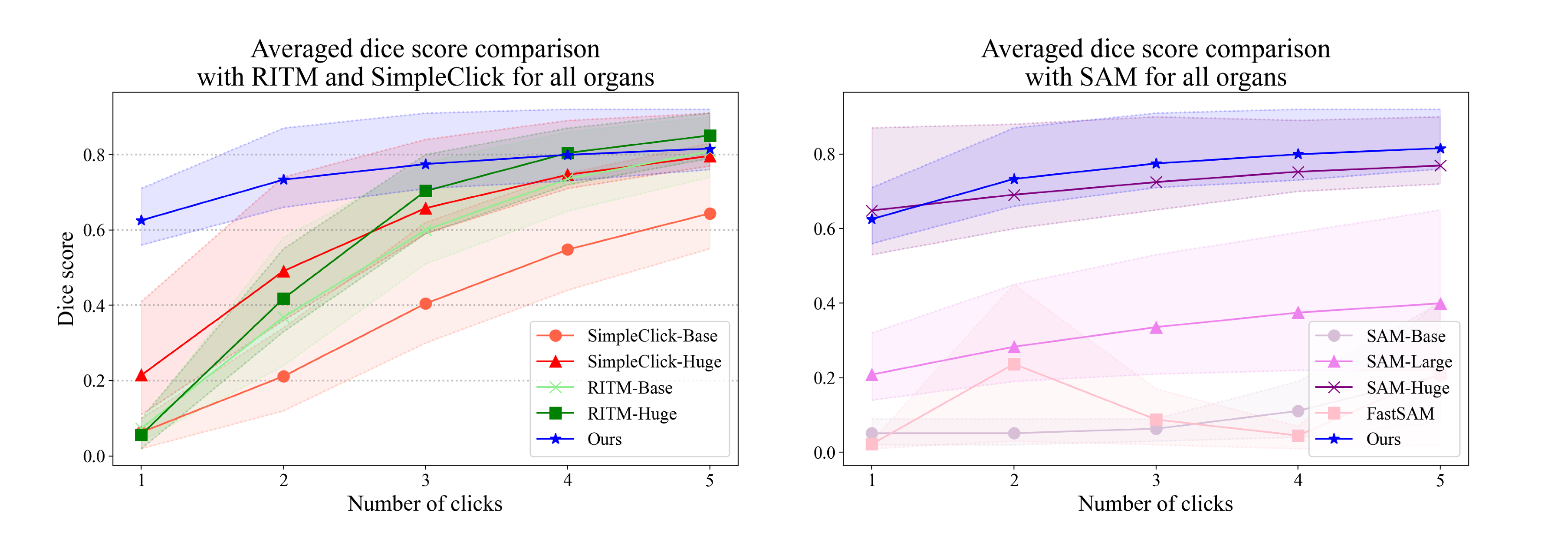
5.5. Qualitative Evaluation
5.6. Quantitative Evaluation
5.7. Limitations
5.7.1. Failure Cases Analysis
5.7.2. Inference Time Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. Unetr: Transformers for 3d medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.R.; Xu, D. Swin Unetr: Swin transformers for semantic segmentation of brain tumors in MRI images. In Proceedings of the International MICCAI Brainlesion Workshop, Virtual Event, 27 September 2021; pp. 272–284. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Wang, G.; Li, W.; Zuluaga, M.A.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; David, A.L.; Deprest, J.; Ourselin, S.; et al. Interactive medical image segmentation using deep learning with image-specific fine tuning. IEEE Trans. Med. Imaging 2018, 37, 1562–1573. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Zuluaga, M.A.; Li, W.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; David, A.L.; Deprest, J.; Ourselin, S.; et al. DeepIGeoS: A deep interactive geodesic framework for medical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1559–1572. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Wang, G.; Song, T.; Zhang, J.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T.; Zhang, S. MIDeepSeg: Minimally interactive segmentation of unseen objects from medical images using deep learning. Med. Image Anal. 2021, 72, 102102. [Google Scholar] [CrossRef]
- Sofiiuk, K.; Petrov, I.A.; Konushin, A. Reviving Iterative Training with Mask Guidance for Interactive Segmentation. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3141–3145. [Google Scholar]
- Liu, Q.; Xu, Z.; Bertasius, G.; Niethammer, M. SimpleClick: Interactive Image Segmentation with Simple Vision Transformers. arXiv 2022, arXiv:2210.11006. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Landman, B.; Xu, Z.; Igelsias, J.; Styner, M.; Langerak, T.; Klein, A. MICCAI multi-atlas labeling beyond the cranial vault–workshop and challenge. In Proceedings of the MICCAI Multi-Atlas Labeling beyond Cranial Vault—Workshop Challenge, Munich, Germany, 5–9 October 2015; Volume 5, p. 12. [Google Scholar]
- Kavur, A.E.; Gezer, N.S.; Barış, M.; Aslan, S.; Conze, P.H.; Groza, V.; Pham, D.D.; Chatterjee, S.; Ernst, P.; Özkan, S.; et al. CHAOS challenge-combined (CT-MR) healthy abdominal organ segmentation. Med. Image Anal. 2021, 69, 101950. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Wang, B. Segment anything in medical images. arXiv 2023, arXiv:2304.12306. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Thambawita, V.; Hicks, S.A.; Halvorsen, P.; Riegler, M.A. Divergentnets: Medical image segmentation by network ensemble. arXiv 2021, arXiv:2107.00283. [Google Scholar]
- Zhou, L.; Wang, S.; Sun, K.; Zhou, T.; Yan, F.; Shen, D. Three-dimensional affinity learning based multi-branch ensemble network for breast tumor segmentation in MRI. Pattern Recognit. 2022, 129, 108723. [Google Scholar] [CrossRef]
- Dang, T.; Luong, A.V.; Liew, A.W.C.; McCall, J.; Nguyen, T.T. Ensemble of deep learning models with surrogate-based optimization for medical image segmentation. In Proceedings of the 2022 IEEE Congress on Evolutionary Computation (CEC), Padua, Italy, 18–23 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Georgescu, M.I.; Ionescu, R.T.; Miron, A.I. Diversity-Promoting Ensemble for Medical Image Segmentation. In Proceedings of the 38th ACM/SIGAPP Symposium on Applied Computing, Tallinn, Estonia, 27–31 March 2023; pp. 599–606. [Google Scholar]
- Xu, C.; Prince, J.L. Snakes, shapes, and gradient vector flow. IEEE Trans. Image Process. 1998, 7, 359–369. [Google Scholar] [PubMed]
- Rother, C.; Kolmogorov, V.; Blake, A. GrabCut: Interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. (TOG) 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Boykov, Y.Y.; Jolly, M.P. Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV 2001), Vancouver, BC, Canada, 7–14 July 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 1, pp. 105–112. [Google Scholar]
- Grady, L. Random walks for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1768–1783. [Google Scholar] [CrossRef] [PubMed]
- Vezhnevets, V.; Konouchine, V. GrowCut: Interactive multi-label ND image segmentation by cellular automata. In Proceedings of the Graphicon. Citeseer, Novosibirsk Akademgorodok, Russia, 20–24 June 2005; Volume 1, pp. 150–156. [Google Scholar]
- Criminisi, A.; Sharp, T.; Blake, A. Geos: Geodesic image segmentation. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 99–112. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Otsu, N. A threshold selection method from gray level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Scott, D.W. Multivariate Density Estimation: Theory, Practice, and Visualization; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Wang, Z.; Zhao, L.; Chen, H.; Li, A.; Zuo, Z.; Xing, W.; Lu, D. Texture Reformer: Towards Fast and Universal Interactive Texture Transfer. arXiv 2021, arXiv:2112.02788. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Zhao, X.; Ding, W.; An, Y.; Du, Y.; Yu, T.; Li, M.; Tang, M.; Wang, J. Fast Segment Anything. arXiv 2023, arXiv:2306.12156. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Glenn, J.; Chaurasia, A.; Qiu, J. YOLOv8-seg by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 October 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encoder | Decoder |
|---|---|
| Conv 0 (3, 3, 1, 1, 0) Conv 1_1 (3, 64, 3, 1, 0) Conv 1_2 (64, 64, 3, 1, 0) MaxPool (2, 2) | Conv 3_1 (256, 128, 3, 1, 0) Upsampling (2) |
| Conv 2_1 (64, 128, 3, 1, 0) Conv 2_2 (128, 128, 3, 1, 0) MaxPool (2, 2) | Conv 2_2 (128, 128, 3, 1, 0) Conv 2_1 (128, 64, 3, 1, 0) Upsampling (2) |
| Conv 3_1 (128, 256, 3, 1, 0) | Conv 1_2 (64, 64, 3, 1, 0) |
| Spleen | Right Kidney | Left Kidney | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dice Score per Click | |||||||||||||||
| Methods | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 |
| RITM-HRNet-18 | 0.09 | 0.57 | 0.82 | 0.90 | 0.93 | 0.09 | 0.46 | 0.76 | 0.86 | 0.90 | 0.09 | 0.68 | 0.84 | 0.89 | 0.91 |
| RITM-HRNet-32 | 0.10 | 0.59 | 0.85 | 0.91 | 0.94 | 0.06 | 0.43 | 0.80 | 0.89 | 0.92 | 0.05 | 0.49 | 0.78 | 0.87 | 0.91 |
| SimpleClick-Base | 0.08 | 0.33 | 0.58 | 0.75 | 0.84 | 0.07 | 0.41 | 0.64 | 0.77 | 0.84 | 0.06 | 0.34 | 0.62 | 0.77 | 0.83 |
| SimpleClick-Huge | 0.15 | 0.60 | 0.82 | 0.89 | 0.91 | 0.54 | 0.78 | 0.86 | 0.89 | 0.91 | 0.51 | 0.80 | 0.87 | 0.89 | 0.91 |
| SAM-base | 0.09 | 0.09 | 0.09 | 0.11 | 0.15 | 0.05 | 0.05 | 0.07 | 0.19 | 0.48 | 0.05 | 0.05 | 0.05 | 0.08 | 0.16 |
| SAM-Large | 0.30 | 0.45 | 0.56 | 0.64 | 0.67 | 0.29 | 0.44 | 0.52 | 0.58 | 0.64 | 0.32 | 0.45 | 0.53 | 0.59 | 0.65 |
| SAM-Huge | 0.88 | 0.91 | 0.91 | 0.92 | 0.92 | 0.87 | 0.88 | 0.86 | 0.84 | 0.86 | 0.87 | 0.87 | 0.86 | 0.84 | 0.86 |
| FastSAM | 0.03 | 0.45 | 0.10 | 0.04 | 0.41 | 0.02 | 0.60 | 0.19 | 0.05 | 0.57 | 0.02 | 0.66 | 0.15 | 0.02 | 0.62 |
| Ours | 0.81 | 0.91 | 0.93 | 0.94 | 0.94 | 0.65 | 0.81 | 0.87 | 0.94 | 0.94 | 0.68 | 0.84 | 0.89 | 0.91 | 0.92 |
| Gallbladder | Esophagus | Liver | |||||||||||||
| Dice Score per Click | |||||||||||||||
| Methods | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 |
| RITM-HRNet-18 | 0.04 | 0.24 | 0.54 | 0.73 | 0.82 | 0.08 | 0.44 | 0.66 | 0.77 | 0.83 | 0.21 | 0.32 | 0.56 | 0.74 | 0.84 |
| RITM-HRNet-32 | 0.03 | 0.43 | 0.76 | 0.84 | 0.88 | 0.03 | 0.55 | 0.74 | 0.82 | 0.86 | 0.22 | 0.42 | 0.73 | 0.85 | 0.89 |
| SimpleClick-Base | 0.02 | 0.11 | 0.39 | 0.56 | 0.66 | 0.04 | 0.15 | 0.33 | 0.48 | 0.59 | 0.21 | 0.31 | 0.49 | 0.66 | 0.78 |
| SimpleClick-Huge | 0.18 | 0.47 | 0.65 | 0.76 | 0.81 | 0.09 | 0.36 | 0.59 | 0.71 | 0.77 | 0.27 | 0.55 | 0.77 | 0.87 | 0.91 |
| SAM-base | 0.02 | 0.02 | 0.02 | 0.03 | 0.07 | 0.02 | 0.02 | 0.05 | 0.14 | 0.25 | 0.23 | 0.23 | 0.26 | 0.28 | 0.40 |
| SAM-Large | 0.12 | 0.18 | 0.23 | 0.27 | 0.31 | 0.18 | 0.20 | 0.21 | 0.21 | 0.22 | 0.42 | 0.52 | 0.58 | 0.63 | 0.66 |
| SAM-Huge | 0.62 | 0.66 | 0.70 | 0.74 | 0.76 | 0.49 | 0.57 | 0.64 | 0.70 | 0.73 | 0.84 | 0.88 | 0.90 | 0.89 | 0.90 |
| FastSAM | 0.01 | 0.04 | 0.05 | 0.02 | 0.05 | 0.00 | 0.01 | 0.00 | 0.00 | 0.01 | 0.12 | 0.24 | 0.17 | 0.09 | 0.27 |
| Ours | 0.71 | 0.79 | 0.81 | 0.83 | 0.84 | 0.56 | 0.66 | 0.71 | 0.73 | 0.76 | 0.70 | 0.87 | 0.92 | 0.94 | 0.94 |
| Stomach | Aorta | Inferior Vena Cava | |||||||||||||
| Dice Score per Click | |||||||||||||||
| Methods | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 |
| RITM-HRNet-18 | 0.16 | 0.58 | 0.77 | 0.85 | 0.88 | 0.06 | 0.59 | 0.78 | 0.85 | 0.89 | 0.06 | 0.30 | 0.57 | 0.74 | 0.83 |
| RITM-HRNet-32 | 0.13 | 0.55 | 0.76 | 0.85 | 0.89 | 0.05 | 0.64 | 0.83 | 0.87 | 0.90 | 0.02 | 0.39 | 0.73 | 0.84 | 0.88 |
| SimpleClick-Base | 0.15 | 0.43 | 0.63 | 0.75 | 0.82 | 0.10 | 0.26 | 0.51 | 0.68 | 0.77 | 0.02 | 0.12 | 0.33 | 0.52 | 0.65 |
| SimpleClick-Huge | 0.41 | 0.74 | 0.84 | 0.89 | 0.91 | 0.23 | 0.62 | 0.79 | 0.85 | 0.88 | 0.11 | 0.46 | 0.69 | 0.80 | 0.85 |
| SAM-base | 0.10 | 0.10 | 0.12 | 0.18 | 0.29 | 0.03 | 0.03 | 0.06 | 0.21 | 0.42 | 0.02 | 0.02 | 0.03 | 0.08 | 0.19 |
| SAM-Large | 0.37 | 0.46 | 0.49 | 0.52 | 0.54 | 0.24 | 0.34 | 0.47 | 0.57 | 0.60 | 0.14 | 0.20 | 0.25 | 0.30 | 0.33 |
| SAM-Huge | 0.67 | 0.73 | 0.80 | 0.84 | 0.86 | 0.90 | 0.90 | 0.92 | 0.92 | 0.90 | 0.68 | 0.72 | 0.75 | 0.79 | 0.81 |
| FastSAM | 0.04 | 0.34 | 0.09 | 0.23 | 0.16 | 0.01 | 0.43 | 0.20 | 0.03 | 0.40 | 0.01 | 0.15 | 0.13 | 0.01 | 0.15 |
| Ours | 0.46 | 0.61 | 0.68 | 0.73 | 0.76 | 0.87 | 0.91 | 0.91 | 0.92 | 0.92 | 0.64 | 0.71 | 0.75 | 0.78 | 0.81 |
| Portal Vein and Splenic Vein | Pancreas | Right Adrenal Gland | |||||||||||||
| Dice Score per Click | |||||||||||||||
| Methods | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 |
| RITM-HRNet-18 | 0.04 | 0.23 | 0.46 | 0.62 | 0.71 | 0.03 | 0.27 | 0.51 | 0.65 | 0.74 | 0.00 | 0.03 | 0.21 | 0.44 | 0.58 |
| RITM-HRNet-32 | 0.02 | 0.33 | 0.59 | 0.71 | 0.77 | 0.03 | 0.27 | 0.57 | 0.72 | 0.79 | 0.00 | 0.17 | 0.50 | 0.64 | 0.71 |
| SimpleClick-Base | 0.03 | 0.12 | 0.28 | 0.41 | 0.52 | 0.04 | 0.13 | 0.30 | 0.44 | 0.55 | 0.00 | 0.02 | 0.08 | 0.16 | 0.25 |
| SimpleClick-Huge | 0.11 | 0.35 | 0.53 | 0.63 | 0.70 | 0.17 | 0.48 | 0.64 | 0.73 | 0.78 | 0.01 | 0.06 | 0.22 | 0.37 | 0.49 |
| SAM-base | 0.02 | 0.02 | 0.04 | 0.09 | 0.15 | 0.03 | 0.03 | 0.03 | 0.04 | 0.08 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 |
| SAM-Large | 0.15 | 0.19 | 0.21 | 0.22 | 0.21 | 0.15 | 0.20 | 0.24 | 0.27 | 0.29 | 0.01 | 0.01 | 0.02 | 0.02 | 0.03 |
| SAM-Huge | 0.59 | 0.62 | 0.65 | 0.69 | 0.71 | 0.53 | 0.60 | 0.65 | 0.70 | 0.72 | 0.14 | 0.22 | 0.30 | 0.37 | 0.41 |
| FastSAM | 0.01 | 0.13 | 0.04 | 0.07 | 0.08 | 0.01 | 0.03 | 0.02 | 0.02 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Ours | 0.60 | 0.70 | 0.74 | 0.76 | 0.78 | 0.56 | 0.69 | 0.75 | 0.78 | 0.80 | 0.33 | 0.40 | 0.45 | 0.49 | 0.53 |
| Left Adrenal Gland | |||||||||||||||
| Dice Score per Click | |||||||||||||||
| Methods | 1 | 2 | 3 | 4 | 5 | ||||||||||
| RITM-HRNet-18 | 0.00 | 0.08 | 0.31 | 0.52 | 0.65 | ||||||||||
| RITM-HRNet-32 | 0.00 | 0.17 | 0.50 | 0.64 | 0.72 | ||||||||||
| SimpleClick-Base | 0.00 | 0.02 | 0.08 | 0.17 | 0.27 | ||||||||||
| SimpleClick-Huge | 0.01 | 0.11 | 0.28 | 0.42 | 0.52 | ||||||||||
| SAM-base | 0.00 | 0.00 | 0.00 | 0.01 | 0.02 | ||||||||||
| SAM-Large | 0.02 | 0.04 | 0.05 | 0.05 | 0.04 | ||||||||||
| SAM-Huge | 0.35 | 0.42 | 0.48 | 0.54 | 0.56 | ||||||||||
| FastSAM | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ||||||||||
| Ours | 0.56 | 0.63 | 0.66 | 0.68 | 0.69 | ||||||||||
| SC-Huge | SC-Base | SAM-Huge | SAM-Base | FastSAM | Ours | |
|---|---|---|---|---|---|---|
| params | 662,184,793 | 98,025,513 | 641,090,608 | 93,735,472 | 72,234,149 | 7,010,959 |
| Liver | |||||
|---|---|---|---|---|---|
| Dice score per click | |||||
| Methods | 1 | 2 | 3 | 4 | 5 |
| RITM-HRNet-18 | 0.23 | 0.35 | 0.57 | 0.76 | 0.85 |
| RITM-HRNet-32 | 0.25 | 0.48 | 0.77 | 0.88 | 0.91 |
| SimpleClick-Base | 0.24 | 0.33 | 0.51 | 0.68 | 0.79 |
| SimpleClick-Huge | 0.28 | 0.56 | 0.79 | 0.89 | 0.93 |
| SAM-base | 0.26 | 0.27 | 0.30 | 0.38 | 0.52 |
| SAM-Large | 0.51 | 0.62 | 0.68 | 0.71 | 0.74 |
| SAM-Huge | 0.80 | 0.89 | 0.91 | 0.90 | 0.91 |
| FastSAM | 0.14 | 0.45 | 0.12 | 0.14 | 0.44 |
| Ours | 0.73 | 0.89 | 0.93 | 0.95 | 0.96 |
| Liver | Right Kidney | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dice Score per Click | ||||||||||
| Methods | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 |
| RITM-HRNet-18 | 0.22 | 0.45 | 0.71 | 0.83 | 0.88 | 0.05 | 0.37 | 0.63 | 0.74 | 0.81 |
| RITM-HRNet-32 | 0.22 | 0.38 | 0.70 | 0.84 | 0.90 | 0.05 | 0.20 | 0.60 | 0.75 | 0.82 |
| SimpleClick-Base | 0.23 | 0.30 | 0.50 | 0.70 | 0.81 | 0.05 | 0.28 | 0.58 | 0.74 | 0.83 |
| SimpleClick-Huge | 0.31 | 0.74 | 0.87 | 0.91 | 0.93 | 0.12 | 0.66 | 0.81 | 0.87 | 0.90 |
| SAM-base | 0.23 | 0.23 | 0.24 | 0.27 | 0.36 | 0.05 | 0.06 | 0.06 | 0.06 | 0.08 |
| SAM-Large | 0.38 | 0.44 | 0.47 | 0.48 | 0.50 | 0.17 | 0.21 | 0.25 | 0.27 | 0.30 |
| SAM-Huge | 0.74 | 0.82 | 0.86 | 0.86 | 0.88 | 0.78 | 0.82 | 0.85 | 0.85 | 0.86 |
| FastSAM | 0.09 | 0.14 | 0.09 | 0.05 | 0.17 | 0.02 | 0.12 | 0.02 | 0.03 | 0.10 |
| Ours | 0.42 | 0.60 | 0.71 | 0.77 | 0.81 | 0.56 | 0.69 | 0.76 | 0.79 | 0.82 |
| Left Kidney | Spleen | |||||||||
| Dice Score per Click | ||||||||||
| Methods | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 |
| RITM-HRNet-18 | 0.05 | 0.24 | 0.55 | 0.70 | 0.79 | 0.07 | 0.35 | 0.66 | 0.80 | 0.86 |
| RITM-HRNet-32 | 0.05 | 0.22 | 0.61 | 0.75 | 0.82 | 0.07 | 0.39 | 0.72 | 0.84 | 0.89 |
| SimpleClick-Base | 0.06 | 0.31 | 0.67 | 0.79 | 0.85 | 0.08 | 0.27 | 0.60 | 0.75 | 0.83 |
| SimpleClick-Huge | 0.17 | 0.61 | 0.81 | 0.87 | 0.90 | 0.13 | 0.56 | 0.78 | 0.86 | 0.90 |
| SAM-base | 0.05 | 0.06 | 0.06 | 0.09 | 0.16 | 0.08 | 0.08 | 0.08 | 0.10 | 0.14 |
| SAM-Large | 0.24 | 0.27 | 0.33 | 0.37 | 0.36 | 0.20 | 0.29 | 0.33 | 0.38 | 0.37 |
| SAM-Huge | 0.76 | 0.82 | 0.84 | 0.86 | 0.86 | 0.76 | 0.78 | 0.82 | 0.84 | 0.85 |
| FastSAM | 0.02 | 0.16 | 0.04 | 0.07 | 0.11 | 0.03 | 0.18 | 0.02 | 0.11 | 0.10 |
| Ours | 0.56 | 0.70 | 0.75 | 0.78 | 0.81 | 0.51 | 0.69 | 0.77 | 0.81 | 0.84 |
| Liver | Right Kidney | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dice Score per Click | ||||||||||
| Methods | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 |
| RITM-HRNet-18 | 0.23 | 0.44 | 0.69 | 0.82 | 0.88 | 0.06 | 0.57 | 0.78 | 0.85 | 0.89 |
| RITM-HRNet-32 | 0.24 | 0.42 | 0.71 | 0.84 | 0.89 | 0.06 | 0.42 | 0.78 | 0.85 | 0.89 |
| SimpleClick-Base | 0.28 | 0.38 | 0.61 | 0.76 | 0.83 | 0.21 | 0.41 | 0.64 | 0.75 | 0.83 |
| SimpleClick-Huge | 0.33 | 0.61 | 0.83 | 0.90 | 0.92 | 0.63 | 0.83 | 0.89 | 0.92 | 0.93 |
| SAM-base | 0.28 | 0.29 | 0.30 | 0.33 | 0.39 | 0.08 | 0.08 | 0.10 | 0.14 | 0.22 |
| SAM-Large | 0.51 | 0.57 | 0.62 | 0.65 | 0.67 | 0.54 | 0.62 | 0.67 | 0.73 | 0.74 |
| SAM-Huge | 0.64 | 0.76 | 0.82 | 0.85 | 0.87 | 0.80 | 0.86 | 0.86 | 0.88 | 0.89 |
| FastSAM | 0.12 | 0.28 | 0.12 | 0.09 | 0.31 | 0.02 | 0.67 | 0.14 | 0.09 | 0.56 |
| Ours | 0.45 | 0.63 | 0.74 | 0.79 | 0.83 | 0.79 | 0.87 | 0.90 | 0.91 | 0.91 |
| Left Kidney | Spleen | |||||||||
| Dice Score per Click | ||||||||||
| Methods | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 |
| RITM-HRNet-18 | 0.05 | 0.43 | 0.72 | 0.83 | 0.88 | 0.08 | 0.54 | 0.80 | 0.87 | 0.91 |
| RITM-HRNet-32 | 0.05 | 0.46 | 0.76 | 0.85 | 0.88 | 0.09 | 0.66 | 0.84 | 0.89 | 0.91 |
| SimpleClick-Base | 0.33 | 0.56 | 0.71 | 0.80 | 0.86 | 0.39 | 0.64 | 0.79 | 0.86 | 0.90 |
| SimpleClick-Huge | 0.66 | 0.83 | 0.88 | 0.90 | 0.92 | 0.64 | 0.83 | 0.88 | 0.92 | 0.93 |
| SAM-base | 0.07 | 0.08 | 0.09 | 0.13 | 0.24 | 0.11 | 0.11 | 0.13 | 0.16 | 0.23 |
| SAM-Large | 0.55 | 0.63 | 0.70 | 0.76 | 0.76 | 0.41 | 0.52 | 0.64 | 0.68 | 0.69 |
| SAM-Huge | 0.78 | 0.82 | 0.86 | 0.87 | 0.87 | 0.86 | 0.89 | 0.90 | 0.90 | 0.92 |
| FastSAM | 0.02 | 0.73 | 0.12 | 0.08 | 0.59 | 0.04 | 0.65 | 0.09 | 0.06 | 0.55 |
| Ours | 0.79 | 0.88 | 0.90 | 0.91 | 0.91 | 0.70 | 0.84 | 0.88 | 0.90 | 0.91 |
| Infer Time (s) | RITM | SimpleClick | SAM | FastSAM | PixelDiffuser |
|---|---|---|---|---|---|
| Best | 0.1134 | 0.7258 | 1.0502 | 0.0898 | 2.0513 |
| Worst | 0.1230 | 0.7708 | 1.0519 | 0.7536 | 5.6538 |
| Mean | 0.1183 | 0.7383 | 1.0508 | 0.1438 | 3.2868 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, M.; Yang, J.; Lee, J.; Lee, M.; Ji, J.; Kim, Y. Pixel Diffuser: Practical Interactive Medical Image Segmentation without Ground Truth. Bioengineering 2023, 10, 1280. https://doi.org/10.3390/bioengineering10111280
Ju M, Yang J, Lee J, Lee M, Ji J, Kim Y. Pixel Diffuser: Practical Interactive Medical Image Segmentation without Ground Truth. Bioengineering. 2023; 10(11):1280. https://doi.org/10.3390/bioengineering10111280
Chicago/Turabian StyleJu, Mingeon, Jaewoo Yang, Jaeyoung Lee, Moonhyun Lee, Junyung Ji, and Younghoon Kim. 2023. "Pixel Diffuser: Practical Interactive Medical Image Segmentation without Ground Truth" Bioengineering 10, no. 11: 1280. https://doi.org/10.3390/bioengineering10111280
APA StyleJu, M., Yang, J., Lee, J., Lee, M., Ji, J., & Kim, Y. (2023). Pixel Diffuser: Practical Interactive Medical Image Segmentation without Ground Truth. Bioengineering, 10(11), 1280. https://doi.org/10.3390/bioengineering10111280