
An Optimal Approach for Heart Sound Classification Using Grid Search in Hyperparameter Optimization of Machine Learning

Abstract
1. Introduction
2. Materials and Methods
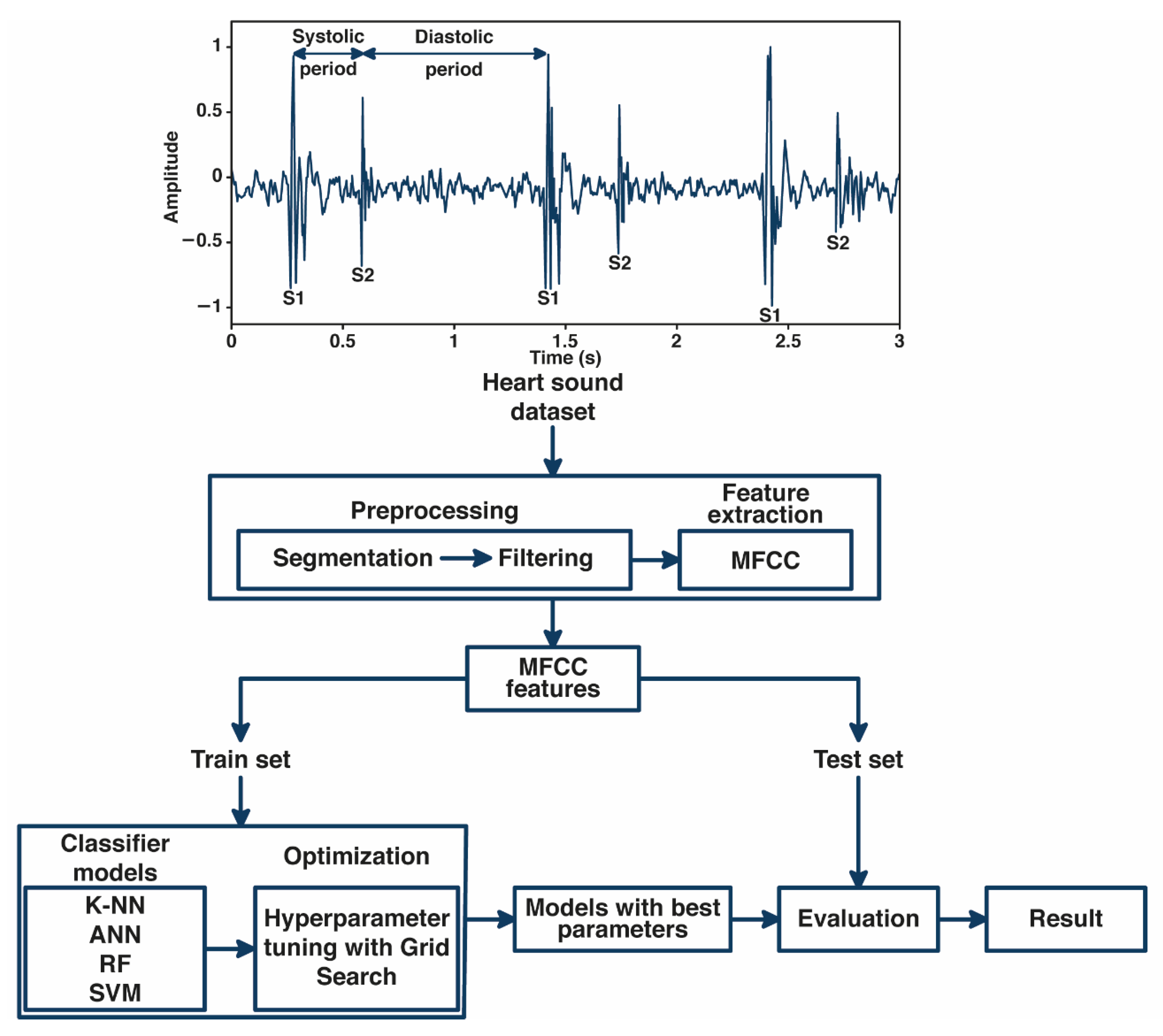
2.1. Database and Preprocessing
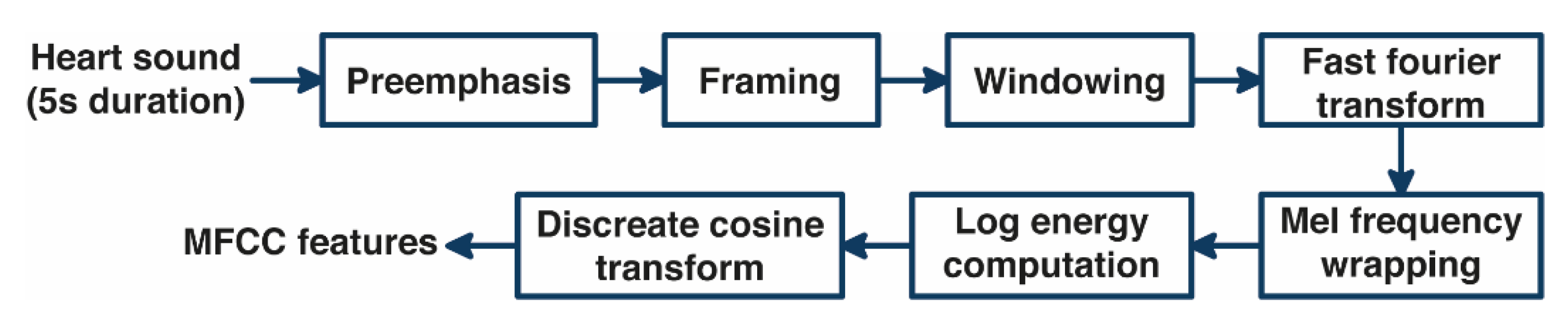
2.2. Feature Extraction Using MFCC
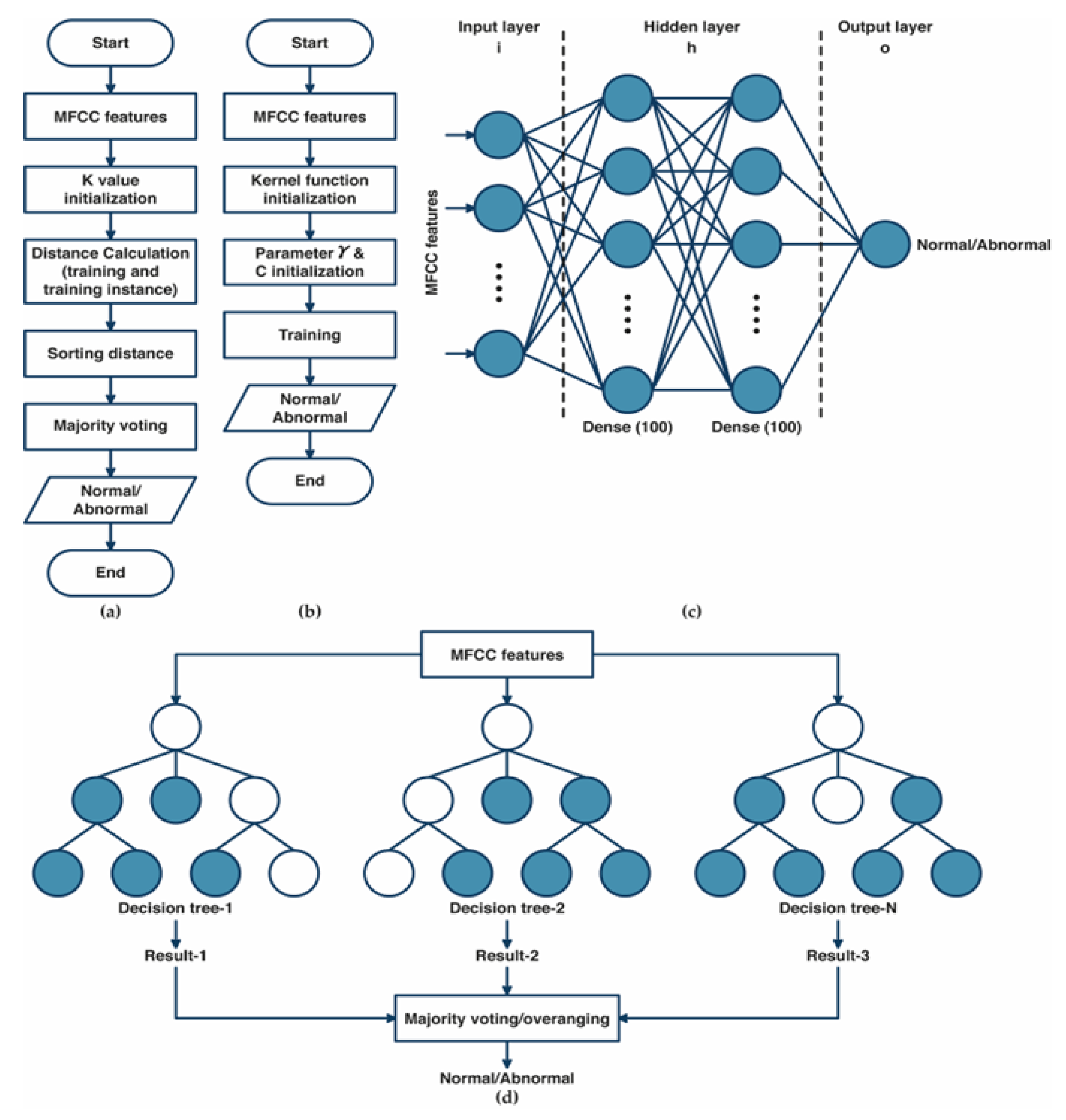
2.3. The Grid Search Based of Machine Learning Optimization
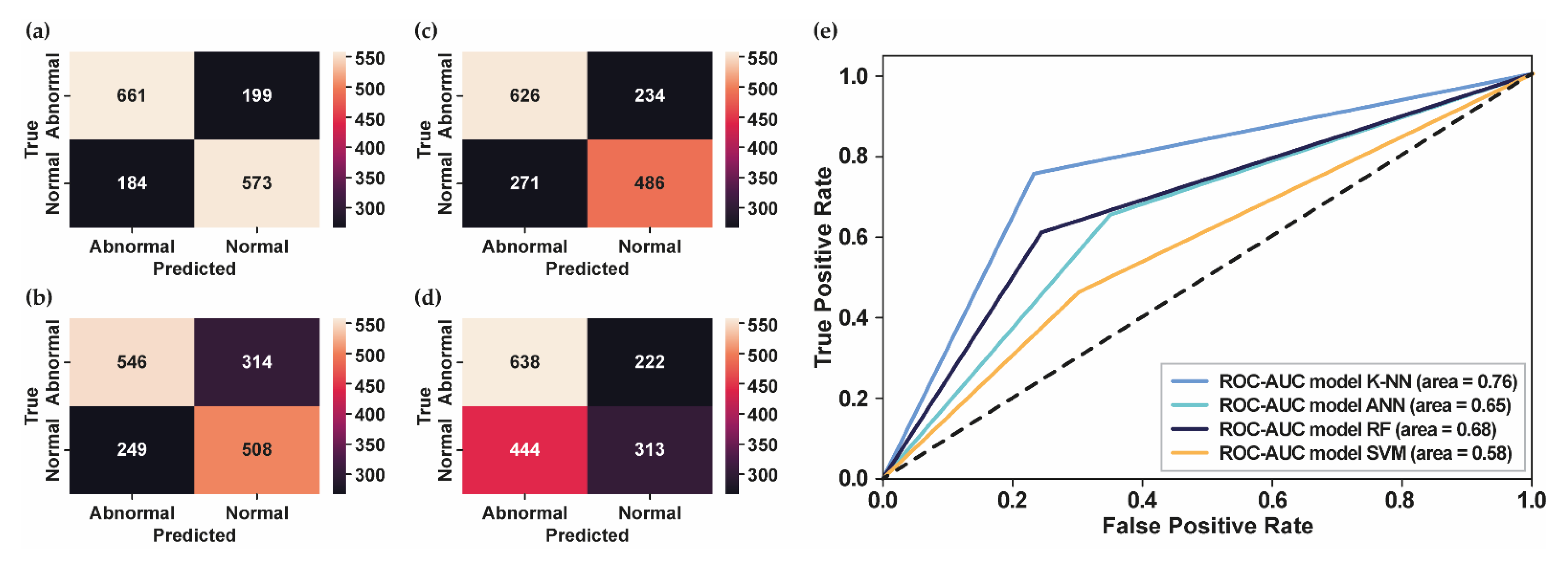
2.4. System Performance
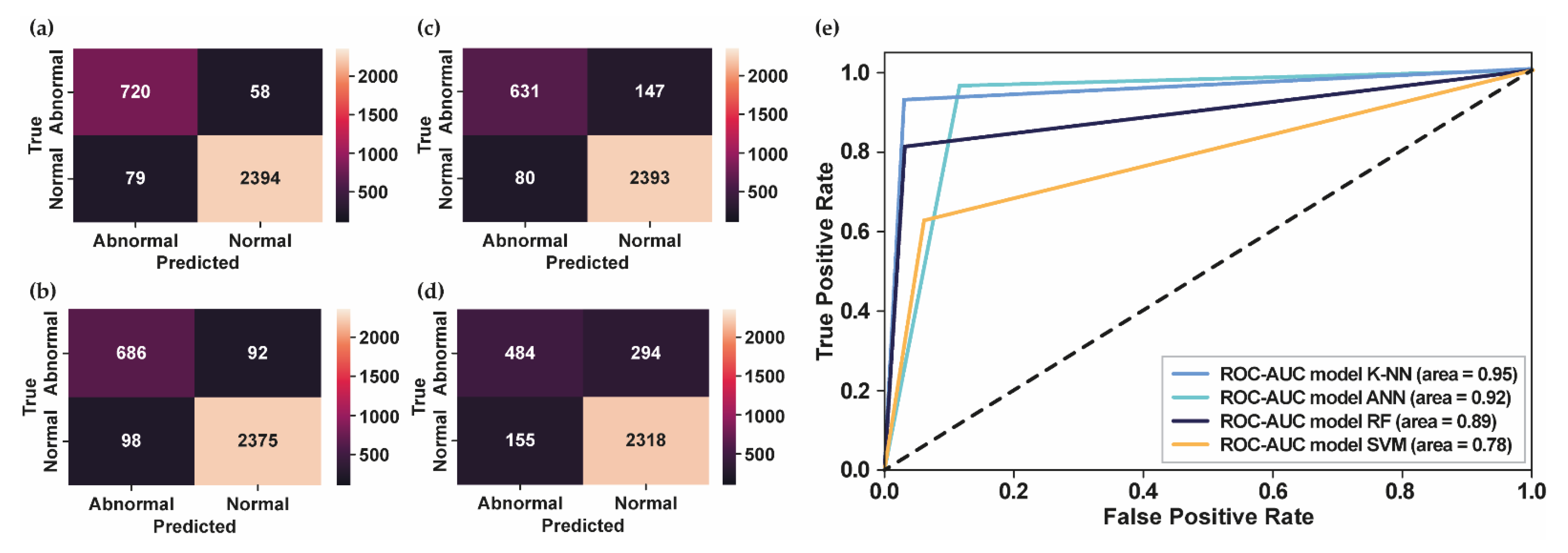
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, W.; Sun, Q.; Chen, X.; Xie, G.; Wu, H.; Xu, C. Deep learning methods for heart sounds classification: A systematic review. Entropy 2021, 23, 667. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Syeda-Mahmood, T.; Beymer, D. Finding disease similarity by combining ECG with heart auscultation sound. Comput. Cardiol. 2007, 34, 261–264. [Google Scholar] [CrossRef]
- Zhang, W.; Han, J.; Deng, S. Heart sound classification based on scaled spectrogram and tensor decomposition. Expert Syst. Appl. 2017, 84, 220–231. [Google Scholar] [CrossRef]
- Clark, D.; Ahmed, M.I.; Dell’Italia, L.J.; Fan, P.; Mcgiffin, D.C. An argument for reviving the disappearing skill of cardiac auscultation. Cleve. Clin. J. Med. 2012, 79, 536–538. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Narváez, P.; Gutierrez, S.; Percybrooks, W.S. Automatic segmentation and classification of heart sounds using modified empirical wavelet transform and power features. Appl. Sci. 2020, 10, 4791. [Google Scholar] [CrossRef]
- Herzig, J.; Bickel, A.; Eitan, A.; Intrator, N. Monitoring Cardiac Stress Using Features Extracted From S1 Heart Sounds. IEEE Trans. Biomed. Eng. 2015, 62, 1169–1178. [Google Scholar] [CrossRef]
- Kobat, M.A.; Kivrak, T.; Barua, P.D.; Tuncer, T.; Dogan, S.; Tan, R.S.; Ciaccio, E.J.; Acharya, U.R. Automated COVID-19 and heart failure detection using dna pattern technique with cough sounds. Diagnostics 2021, 11, 1962. [Google Scholar] [CrossRef]
- Barua, P.D.; Karasu, M.; Kobat, M.A.; Balık, Y.; Kivrak, T.; Baygin, M.; Dogan, S.; Demir, F.B.; Tuncer, T.; Tan, R.S.; et al. An accurate valvular heart disorders detection model based on a new dual symmetric tree pattern using stethoscope sounds. Comput. Biol. Med. 2022, 146, 105599. [Google Scholar] [CrossRef]
- Tuncer, T.; Dogan, S.; Tan, R.S.; Acharya, U.R. Application of Petersen graph pattern technique for automated detection of heart valve diseases with PCG signals. Inf. Sci. 2021, 565, 91–104. [Google Scholar] [CrossRef]
- Patidar, S.; Pachori, R.B. Segmentation of cardiac sound signals by removing murmurs using constrained tunable-Q wavelet transform. Biomed. Signal Process. Control 2013, 8, 559–567. [Google Scholar] [CrossRef]
- Patidar, S.; Pachori, R.B. Classification of cardiac sound signals using constrained tunable-Q wavelet transform. Expert Syst. Appl. 2014, 41, 7161–7170. [Google Scholar] [CrossRef]
- Patidar, S.; Pachori, R.B.; Garg, N. Automatic diagnosis of septal defects based on tunable-Q wavelet transform of cardiac sound signals. Expert Syst. Appl. 2015, 42, 3315–3326. [Google Scholar] [CrossRef]
- Sawant, N.K.; Patidar, S.; Nesaragi, N.; Acharya, U.R. Automated detection of abnormal heart sound signals using Fano-factor constrained tunable quality wavelet transform. Biocybern. Biomed. Eng. 2021, 41, 111–126. [Google Scholar] [CrossRef]
- Rubin, J.; Abreu, R.; Ganguli, A.; Nelaturi, S.; Matei, I.; Sricharan, K. Classifying heart sound recordings using deep convolutional neural networks and mel-frequency cepstral coefficients. Comput. Cardiol. 2016, 43, 813–816. [Google Scholar] [CrossRef]
- Nogueira, D.M.; Ferreira, C.A.; Gomes, E.F.; Jorge, A.M. Classifying Heart Sounds Using Images of Motifs, MFCC and Temporal Features. J. Med. Syst. 2019, 43, 1–13. [Google Scholar] [CrossRef]
- Xiao, B.; Xu, Y.; Bi, X.; Zhang, J.; Ma, X. Heart sounds classification using a novel 1-D convolutional neural network with extremely low parameter consumption. Neurocomputing 2020, 392, 153–159. [Google Scholar] [CrossRef]
- Li, F.; Tang, H.; Shang, S.; Mathiak, K.; Cong, F. Classification of heart sounds using convolutional neural network. Appl. Sci. 2020, 10, 3956. [Google Scholar] [CrossRef]
- Krishnan, P.T.; Balasubramanian, P.; Umapathy, S. Automated heart sound classification system from unsegmented phonocardiogram (PCG) using deep neural network. Phys. Eng. Sci. Med. 2020, 43, 505–515. [Google Scholar] [CrossRef]
- Al-Naami, B.; Fraihat, H.; Gharaibeh, N.Y.; Al-Hinnawi, A.R.M. A Framework Classification of Heart Sound Signals in PhysioNet Challenge 2016 Using High Order Statistics and Adaptive Neuro-Fuzzy Inference System. IEEE Access 2020, 8, 224852–224859. [Google Scholar] [CrossRef]
- Faiq Ahmad, K.; Anam, A.; Muhammad Salman, K. Automatic heart sound classification from segmented/unsegmented phonocardiogram signals using time and frequency features. Inst. Phys. Eng. Med. 2020, 41, 11–14. [Google Scholar]
- He, Y.; Li, W.; Zhang, W.; Zhang, S.; Pi, X.; Liu, H. Research on segmentation and classification of heart sound signals based on deep learning. Appl. Sci. 2021, 11, 651. [Google Scholar] [CrossRef]
- Jeong, Y.; Kim, J.; Kim, D.; Kim, J.; Lee, K. Methods for improving deep learning-based cardiac auscultation accuracy: Data augmentation and data generalization. Appl. Sci. 2021, 11, 4544. [Google Scholar] [CrossRef]
- Monteiro, S.; Fred, A.; Plácido da Silva, H. Detection of Heart Sound Murmurs and Clinical Outcome with Bidirectional Long Short-Term Memory Networks. In Proceedings of the 49th Computing in Cardiology Conference, Tampere, Finland, 4–7 September 2022; Available online: https://cinc.org/2022/Program/accepted/153_Preprint.pdf (accessed on 10 November 2022).
- Ballas, A.; Papapanagiotou, V.; Delopoulos, A.; Diou, C. Listen2YourHeart: A Self-Supervised Approach for Detecting Murmur in Heart-Beat Sounds. arXiv 2022, arXiv:2208.14845v4. [Google Scholar]
- Liu, C.; Springer, D.; Li, Q.; Moody, B.; Juan, R.A.; Chorro, F.J.; Castells, F.; Roig, J.M.; Silva, I.; Johnson, A.E.W.; et al. An open access database for the evaluation of heart sound algorithms. Physiol. Meas. 2016, 37, 2181–2213. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, J.; Portucalense, U.; Henrique, I.D.; Antonio, R.; de Almeida, B.; Renna, F.; Costa, P.D.; Nogueira, M.; Frias, R.R.; Oliveira, C.; et al. The CirCor DigiScope Dataset: From Murmur Detection to Murmur Classification. IEEE J. Biomed. Health Inform. 2022, 26, 2524–2535. [Google Scholar] [CrossRef] [PubMed]
- Hasan, R.; Hossain, Z. How many Mel-frequency cepstral coefficients to be utilized in speech recognition? A study with the Bengali language. J. Eng. 2021, 12, 817–827. [Google Scholar] [CrossRef]
- Elgeldawi, E.; Sayed, A.; Galal, A.R.; Zaki, A.M. Hyperparameter tuning for machine learning algorithms used for arabic sentiment analysis. Informatics 2021, 8, 79. [Google Scholar] [CrossRef]
- Belete, D.M.; Huchaiah, M.D. Grid search in hyperparameter optimization of machine learning models for prediction of HIV/AIDS test results. Int. J. Comput. Appl. 2021, 44, 875–886. [Google Scholar] [CrossRef]
- Gressling, T. 84 Automated machine learning. In Data Science in Chemistry; Springer Publishing Company Incorporated: New York, NY, USA, 2020; ISBN 9783030053178. [Google Scholar]
- Uddin, S.; Haque, I.; Lu, H.; Moni, M.A.; Gide, E. Comparative performance analysis of K-nearest neighbour (KNN) algorithm and its different variants for disease prediction. Sci. Rep. 2022, 12, 1–11. [Google Scholar] [CrossRef]
- Fuadah, Y.N.; Lim, K.M. Optimal Classification of Atrial Fibrillation and Congestive Heart Failure Using Machine Learning. Front. Physiol. 2022, 12, 1–9. [Google Scholar] [CrossRef]
- Muzzammel, R.; Raza, A. A support vector machine learning-based protection technique for MT-HVDC systems. Energies 2020, 13, 6668. [Google Scholar] [CrossRef]
- Toledo-Pérez, D.C.; Rodríguez-Reséndiz, J.; Gómez-Loenzo, R.A.; Jauregui-Correa, J.C. Support Vector Machine-based EMG signal classification techniques: A review. Appl. Sci. 2019, 9, 4402. [Google Scholar] [CrossRef]
- Magidi, J.; Nhamo, L.; Mpandeli, S.; Mabhaudhi, T. Application of the random forest classifier to map irrigated areas using google earth engine. Remote Sens. 2021, 13, 876. [Google Scholar] [CrossRef]
- Suhail, Y.; Upadhyay, M.; Chhibber, A.; Kshitiz. Machine learning for the diagnosis of orthodontic extractions: A computational analysis using ensemble learning. Bioengineering 2020, 7, 55. [Google Scholar] [CrossRef] [PubMed]
- Reyna, M.A.; Elola, A.; Oliveira, J.; Renna, F.; Gu, A.; Sadr, N.; Alday, E.A.P.; Kiarashinejad, Y.; Mattos, S.; Coimbra, M.T.; et al. Heart Murmur Detection from Phonocardiogram Recordings: The George B. Moody PhysioNet Challenge 2022. medRxiv 2022. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | MFCC Features | PhysioNet Challenge 2016 | PhysioNet Challenge 2022 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | W.acc | -Score | AUC | AUPRC | Acc | W.acc | -Score | AUC | AUPRC | ||
| K-NN | 13 | 93.44% | 0.90 | 0.93 | 0.91 | 0.88 | 68.76% | 0.70 | 0.69 | 0.69 | 0.75 |
| 25 | 94.80% | 0.91 | 0.95 | 0.93 | 0.90 | 71.98% | 0.73 | 0.72 | 0.72 | 0.77 | |
| 42 | 95.78% | 0.93 | 0.96 | 0.95 | 0.92 | 76.31% | 0.78 | 0.76 | 0.76 | 0.81 | |
| ANN | 13 | 92.43% | 0.88 | 0.93 | 0.90 | 0.88 | 63.38% | 0.65 | 0.65 | 0.63 | 0.75 |
| 25 | 92.77% | 0.90 | 0.94 | 0.91 | 0.90 | 65.18% | 0.68 | 0.69 | 0.65 | 0.76 | |
| 42 | 94.16% | 0.91 | 0.94 | 0.92 | 0.91 | 64.81% | 0.67 | 0.68 | 0.65 | 0.76 | |
| RF | 13 | 92.83% | 0.91 | 0.93 | 0.90 | 0.88 | 64.81% | 0.66 | 0.65 | 0.64 | 0.71 |
| 25 | 93.35% | 0.91 | 0.93 | 0.90 | 0.88 | 68.76% | 0.69 | 0.69 | 0.68 | 0.74 | |
| 42 | 93.47% | 0.91 | 0.93 | 0.90 | 0.88 | 68.46% | 0.68 | 0.69 | 0.68 | 0.74 | |
| SVM | 13 | 83.97% | 0.77 | 0.84 | 0.75 | 0.69 | 58.81% | 0.59 | 0.58 | 0.58 | 0.64 |
| 25 | 84.44% | 0.78 | 0.84 | 0.75 | 0.69 | 58.44% | 0.58 | 0.58 | 0.58 | 0.63 | |
| 42 | 86.19% | 0.79 | 0.85 | 0.77 | 0.71 | 58.62% | 0.59 | 0.58 | 0.58 | 0.64 | |
| Authors | Preprocessing | Feature Extraction | Classifier | Accuracy |
|---|---|---|---|---|
| Rubin et al. (2016) [14] | Heart-sound segmentation using springer algorithm, selected 3 s duration of heart sound | Extracted 13 MFCC features, converted into 2D feature maps | 2D CNN | 84% |
| Nogueira et al. (2019) [15] | Logistic regression-HSMM-based heart-sound segmentation | Extracted MFCC features, converted into 2D feature maps | SVM | 82.33% |
| Xiao et al. (2019) [16] | Resample 2000 Hz, BPF, sliding window with 3 s patches and 1 s stride | 1D time series signal | 1D CNN | 93% |
| Li et al. (2020) [17] | HPF and HSMM | Multi feature extraction | 1D CNN | 86.80% |
| Khrisnan et al. (2020) [18] | Down-sampled to 500 Hz and selected 6 s heart-sound duration | 1D time series signal | FNN | 85.65% |
| Al-Naami et al. (2020) [19] | Band pass notch filter, BPF, and selected 5 s heart-sound duration | Higher order statistics | ANFIS | 89% |
| Khan et al. (2021) [20] | Logistic regression-HSMM-based heart-sound segmentation | MFCC features | LSTM | 91.39% |
| He et al. (2021) [21] | Normalization, HPF and LPF | Hilbert envelope, homomorphic environment map, wavelet envelope, and power spectral density envelope (512 data points) | 1D CNN | 87.30% |
| Jeong et al. (2021) [22] | BPF, selected 5 s heart-sound duration | STFT | CNN | 91% |
| Monteiro et al. (2022) [23] | Selected 4 s heart-sound duration | Homomorphic, Hilbert, power spectral density, and wavelet envelopes | BiLSTM | 75.1% |
| Ballas et al. (2022) [24] | Selected 5 s heart-sound duration, data augmentation | - | 1D CNN | 73.7% |
| Our Method (PhysioNet Challenge 2016) | Selected 5 s heart-sound duration | Extracted MFCC features | K-NN, ANN, RF, and SVM | 95.78%, 94.16%, 93.47%, and 86.19% |
| Our Method (PhysioNet Challenge 2022) | Selected 5 s heart-sound duration | Extracted MFCC features | K-NN, RF, ANN, and SVM | 76.31%, 68.76% 65.18%, and 58.81% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fuadah, Y.N.; Pramudito, M.A.; Lim, K.M. An Optimal Approach for Heart Sound Classification Using Grid Search in Hyperparameter Optimization of Machine Learning. Bioengineering 2023, 10, 45. https://doi.org/10.3390/bioengineering10010045
Fuadah YN, Pramudito MA, Lim KM. An Optimal Approach for Heart Sound Classification Using Grid Search in Hyperparameter Optimization of Machine Learning. Bioengineering. 2023; 10(1):45. https://doi.org/10.3390/bioengineering10010045
Chicago/Turabian StyleFuadah, Yunendah Nur, Muhammad Adnan Pramudito, and Ki Moo Lim. 2023. "An Optimal Approach for Heart Sound Classification Using Grid Search in Hyperparameter Optimization of Machine Learning" Bioengineering 10, no. 1: 45. https://doi.org/10.3390/bioengineering10010045
APA StyleFuadah, Y. N., Pramudito, M. A., & Lim, K. M. (2023). An Optimal Approach for Heart Sound Classification Using Grid Search in Hyperparameter Optimization of Machine Learning. Bioengineering, 10(1), 45. https://doi.org/10.3390/bioengineering10010045