
Stochastic Analysis of the Marginal and Dependence Structure of Streamflows: From Fine-Scale Records to Multi-Centennial Paleoclimatic Reconstructions

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. Methodology
2.1. Second-Order Dependence Structure Metrics
2.2. Marginal Structure Metrics
2.3. Global-Scale Data Extraction and Processing
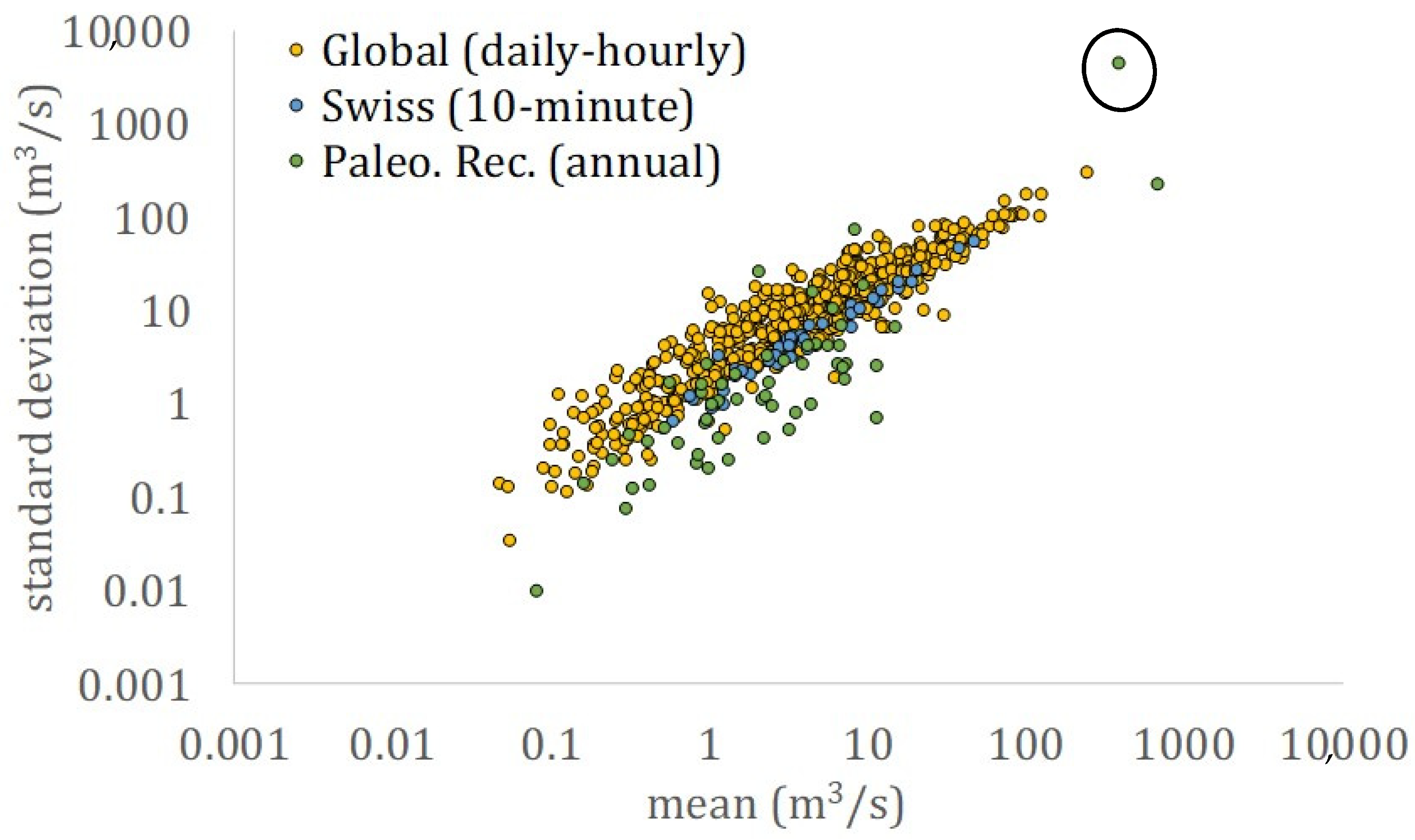
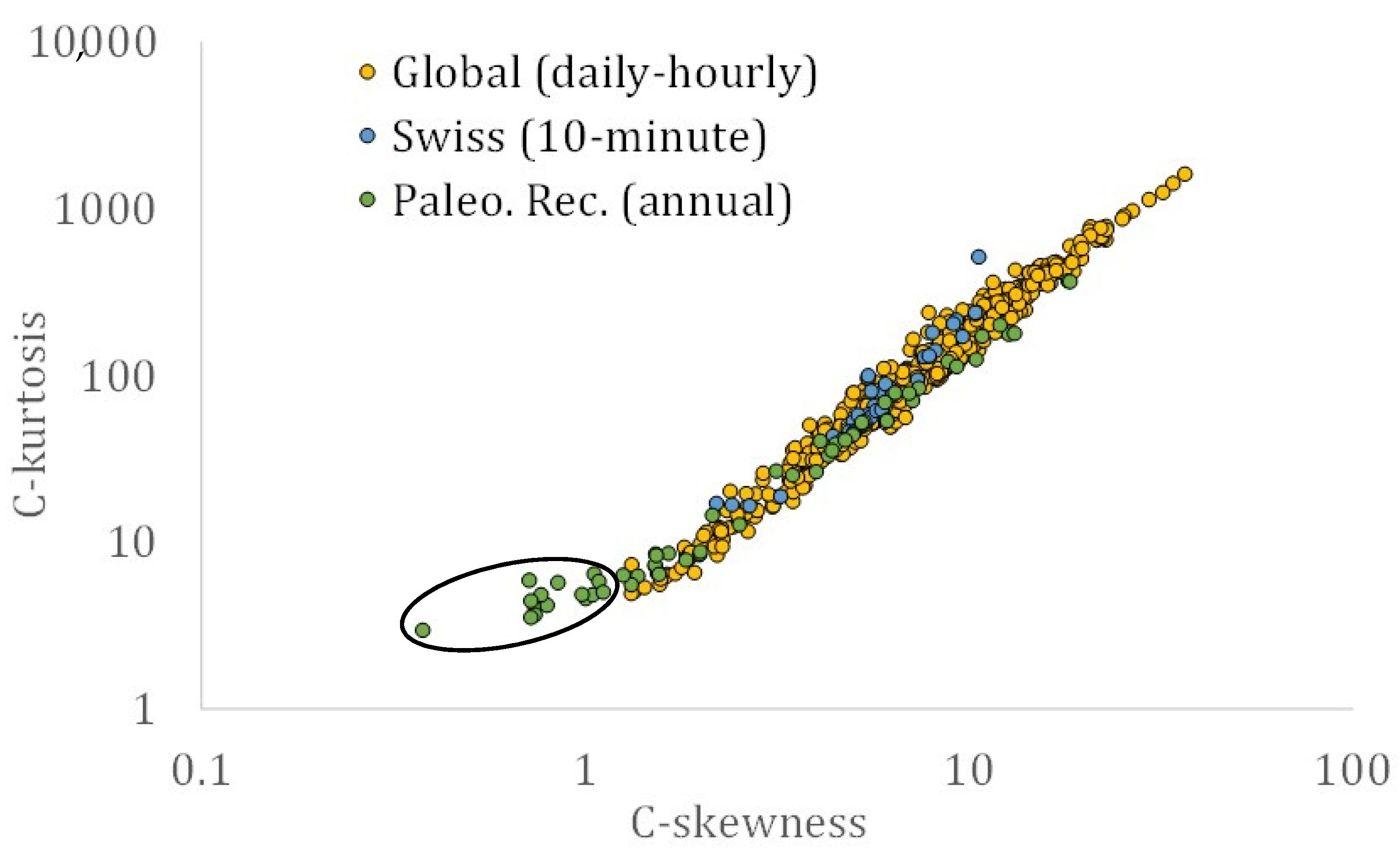
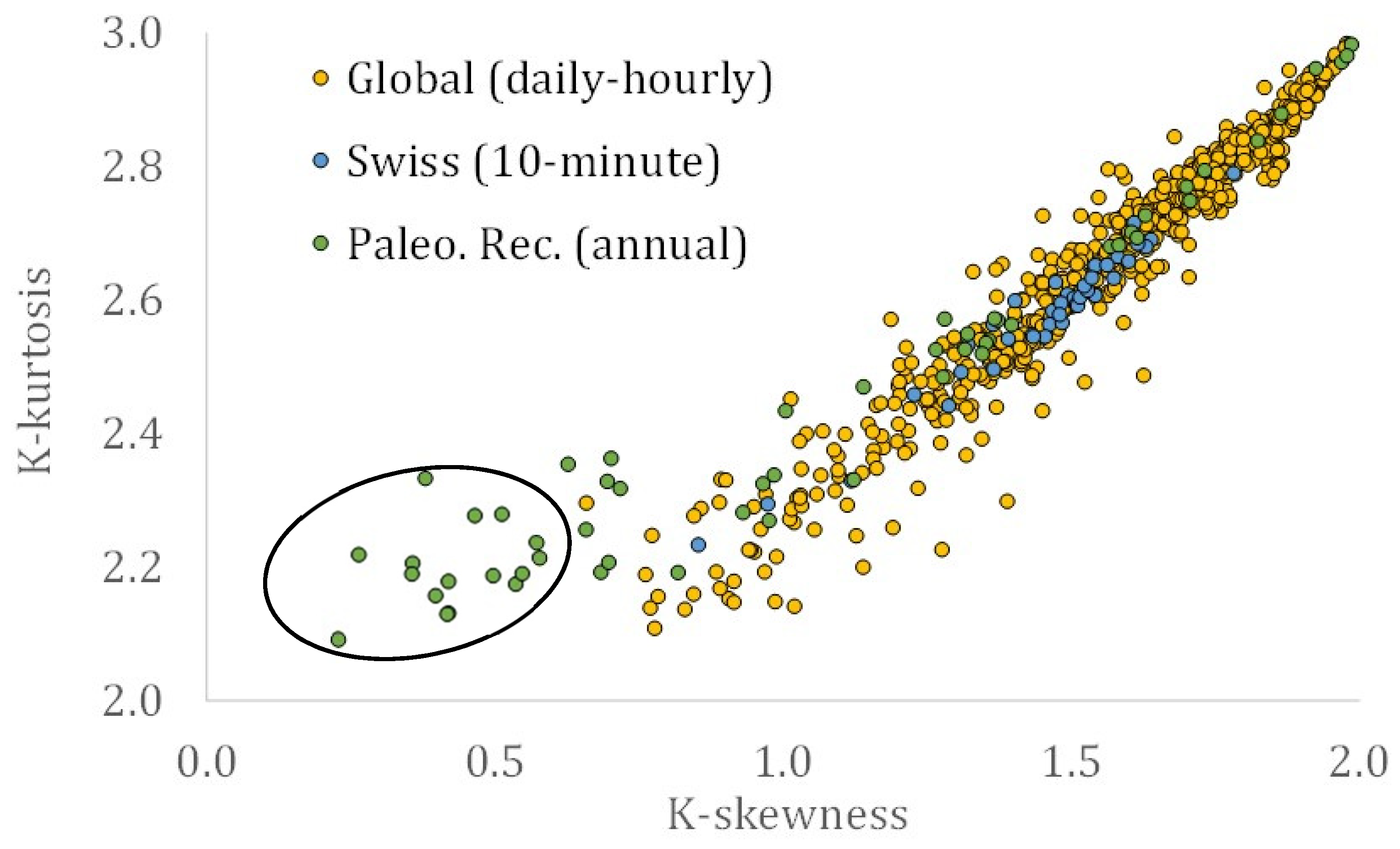
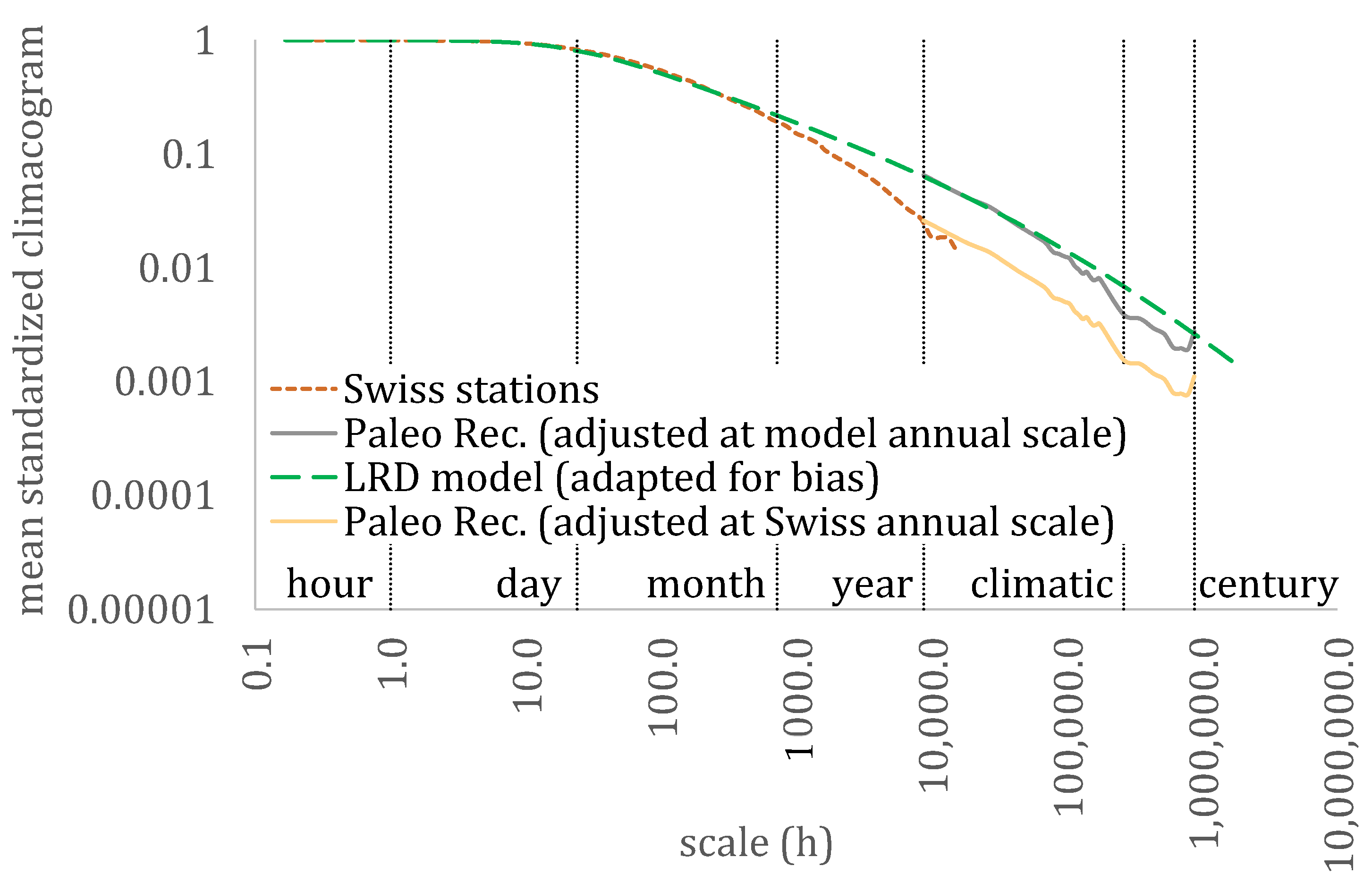
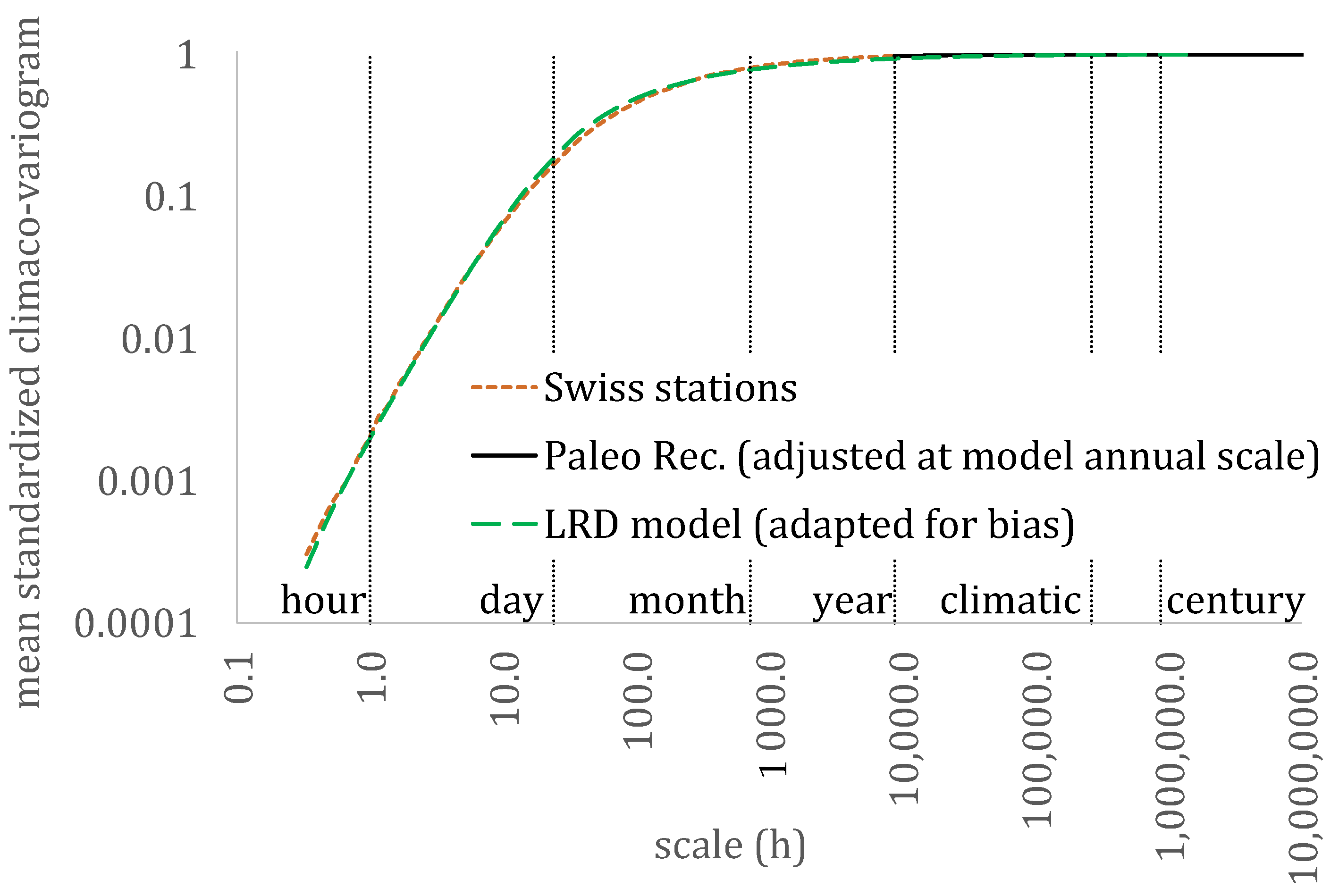
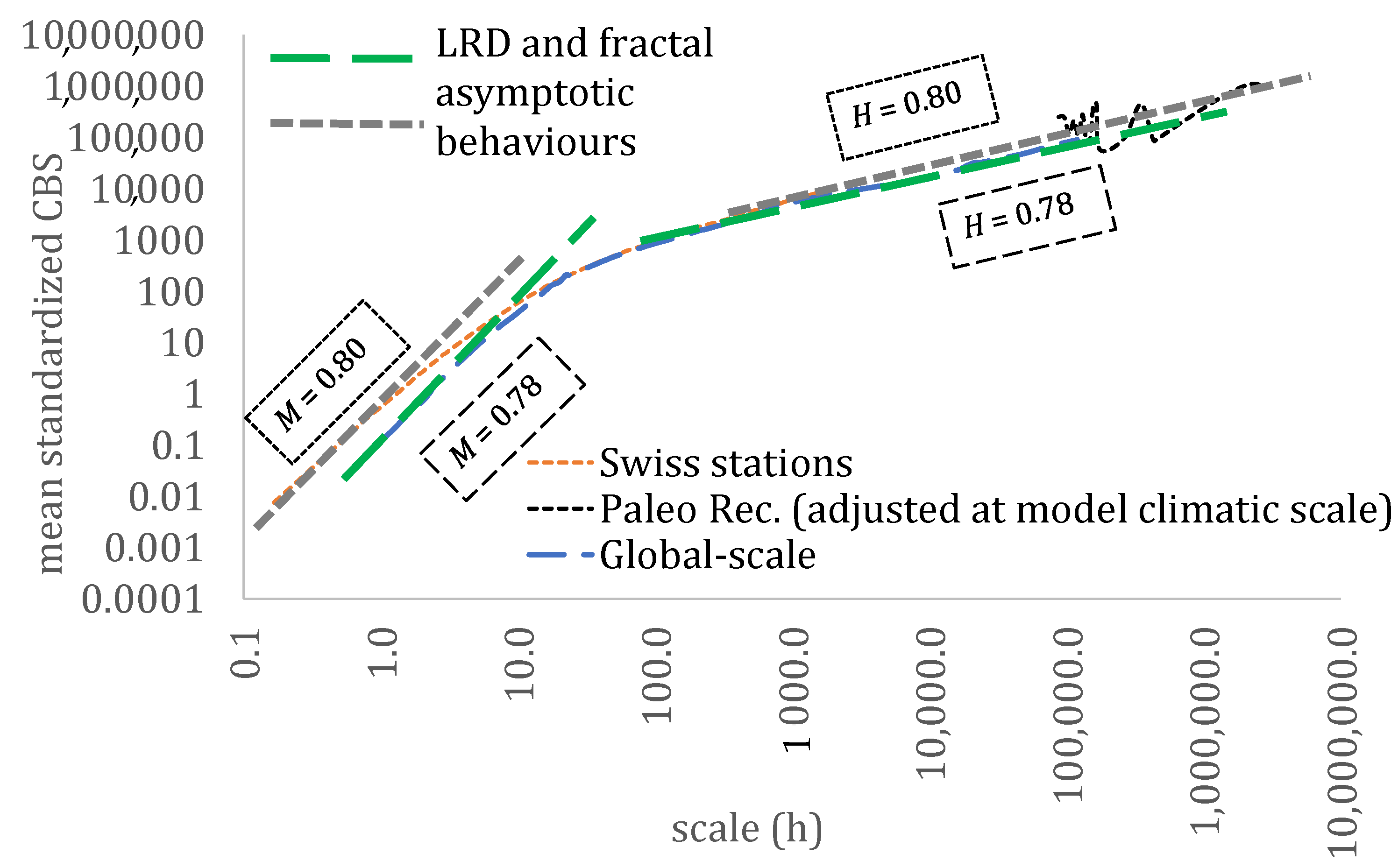
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
 This research was also supported by the COST Action CA16219, “HARMONIOUS-Harmonization of UAS techniques for agricultural and natural ecosystems monitoring”.
This research was also supported by the COST Action CA16219, “HARMONIOUS-Harmonization of UAS techniques for agricultural and natural ecosystems monitoring”.Data Availability Statement
Conflicts of Interest
References
- Manfreda, S.; McCabe, M.F.; Miller, P.E.; Lucas, R.; Pajuelo Madrigal, V.; Mallinis, G.; Ben Dor, E.; Helman, D.; Estes, L.; Ciraolo, G.; et al. On the Use of Unmanned Aerial Systems for Environmental Monitoring. Remote Sens. 2018, 10, 641. [Google Scholar] [CrossRef] [Green Version]
- Perks, M.T.; Dal Sasso, S.F.; Hauet, A.; Jamieson, E.; Le Coz, J.; Pearce, S.; Peña-Haro, S.; Pizarro, A.; Strelnikova, D.; Tauro, F.; et al. Towards harmonisation of image velocimetry techniques for river surface velocity observations. Earth Syst. Sci. Data 2020, 12, 1545–1559. [Google Scholar] [CrossRef]
- Hurst, H.E. Long-Term Storage Capacity of Reservoirs. Trans. Am. Soc. Civ. Eng. 1951, 116, 770–799. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Hurst-Kolmogorov dynamics and uncertainty. J. Am. Water Resour. Assoc. 2011, 47, 481–495. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Revisiting the global hydrological cycle: Is it intensifying? Hydrol. Earth Syst. Sci. 2020, 24, 3899–3932. [Google Scholar] [CrossRef]
- Dimitriadis, P.; Koutsoyiannis, D.; Iliopoulou, T.; Papanicolaou, P. A Global-Scale Investigation of Stochastic Similarities in Marginal Distribution and Dependence Structure of Key Hydrological-Cycle Processes. Hydrology 2021, 8, 59. [Google Scholar] [CrossRef]
- Dimitriadis, P.; Koutsoyiannis, D. Climacogram versus autocovariance and power spectrum in stochastic modelling for Markovian and Hurst–Kolmogorov processes. Stoch. Environ. Res. Risk Assess. 2015, 29, 1649–1669. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Stochastics of Hydroclimatic Extremes—A Cool Look at Risk; Kallipos: Athens, Greece, 2021; 333p, ISBN 978-618-85370-0-2. Available online: https://repository.kallipos.gr/handle/11419/6522 (accessed on 1 April 2022).
- Koutsoyiannis, D. Hurst-Kolmogorov dynamics as a result of extremal entropy production. Phys. A 2011, 390, 1424–1432. [Google Scholar] [CrossRef]
- Ljungqvist, F.C.; Piermattei, A.; Seim, A.; Krusic, P.J.; Büntgen, U.; He, M.; Kirdyanov, A.V.; Luterbacher, J.; Schneider, L.; Seftigen, K.; et al. Ranking of tree-ring based hydroclimate reconstructionsof the past millennium. Quat. Sci. Rev. 2020, 230, 106074. [Google Scholar] [CrossRef]
- Nasreen, S.; Součková, M.; Vargas Godoy, M.R.; Singh, U.; Markonis, Y.; Kumar, R.; Rakovec, O.; Hanel, M. A 500-year runoff reconstruction for European catchments. Earth Syst. Sci. Data Discuss. 2021. [Google Scholar]
- Formetta, G.; Tootle, G.; Bertoldi, G. Streamflow Reconstructions Using Tree-Ring Based Paleo Proxies for the Upper Adige River Basin (Italy). Hydrology 2022, 9, 8. [Google Scholar] [CrossRef]
- Cox, D.R. Long-Range Dependence: A review, Statistics: An Appraisal. In Proceedings of the 50th Anniversary Conference, Bridlington, UK, 1–2 June 1984; David, H.A., David, H.T., Eds.; Iowa State University Press: Ames, IA, USA, 1984; pp. 55–74. [Google Scholar]
- Bloschl, G.; Sivapalan, M. Scale issues in hydrological modelling: A review. In Scale Issues in Hydrological Modelling; Kalma, J.D., Sivapalan, M., Eds.; John Wiley: New York, NY, USA, 1995; pp. 9–48. [Google Scholar]
- Cohn, T.A.; Lins, H.F. Nature’s style—Naturally trendy. Geophys. Res. Lett. 2005, 32. [Google Scholar] [CrossRef] [Green Version]
- Mudelsee, M. Long memory of rivers from spatial aggregation. Water Resour. Res. 2007, 43. [Google Scholar] [CrossRef]
- Hirpa, F.A.; Gebremichael, M.; Over, T.M. River flow fluctuation analysis: Effect of watershed area. Water Resour. Res. 2010, 46, 12. [Google Scholar] [CrossRef] [Green Version]
- Gudmundsson, L.; Tallaksen, L.M.; Stahl, K.; Fleig, A.K. Low-frequency variability of European runoff. Hydrol. Earth Syst. Sci. 2011, 15, 2853–2869. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Zhou, Y.; Singh, V.P.; Chen, X. The influence of dam and lakes on the Yangtze River streamflow: Long-range correlation and complexity analyses. Hydrol. Process. 2012, 26, 436–444. [Google Scholar] [CrossRef]
- O’Connell, P.; Koutsoyiannis, D.; Lins, H.F.; Markonis, Y.; Montanari, A.; Cohn, T. The scientific legacy of Harold Edwin Hurst (1880–1978). Hydrol. Sci. J. 2016, 61, 1571–1590. [Google Scholar] [CrossRef] [Green Version]
- Serinaldi, F.; Kilsby, C.G. Irreversibility and complex network behavior of stream flow fluctuations. Phys. A Stat. Mech. Appl. 2016, 450, 585–600. [Google Scholar] [CrossRef] [Green Version]
- Graves, T.; Gramacy, R.; Watkins, N.; Franzke, C. A Brief History of Long Memory: Hurst, Mandelbrot and the Road to ARFIMA, 1951–1980. Entropy 2017, 19, 437. [Google Scholar] [CrossRef] [Green Version]
- Iliopoulou, T.; Aguilar, C.; Arheimer, B.; Bermúdez, M.; Bezak, N.; Ficchì, A.; Koutsoyiannis, D.; Parajka, J.; Polo, M.J.; Thirel, G.; et al. A large sample analysis of European rivers on seasonal river flow correlation and its physical drivers. Hydrol. Earth Syst. Sci. 2019, 23, 73–91. [Google Scholar] [CrossRef] [Green Version]
- Dimitriadis, P.; Iliopoulou, T.; Sargentis, G.-F.; Koutsoyiannis, D. Spatial Hurst–Kolmogorov Clustering. Encyclopedia 2021, 1, 1010–1025. [Google Scholar] [CrossRef]
- Hosking, J.R.M. L-Moments: Analysis and Estimation of Distributions Using Linear Combinations of Order Statistics. J. R. Stat. Soc. Ser. B Stat. Methodol. 1990, 52, 105–124. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. HESS opinions, A random walk on water. Hydrol. Earth Syst. Sci. 2010, 14, 585–601. [Google Scholar] [CrossRef] [Green Version]
- Beran, J. Statistical Methods for Data with Long-Range Dependence. Stat. Sci. 1992, 7, 404–416. [Google Scholar]
- Koutsoyiannis, D. Generic and parsimonious stochastic modelling for hydrology and beyond. Hydrol. Sci. J. 2016, 61, 225–244. [Google Scholar] [CrossRef]
- Dimitriadis, P.; Koutsoyiannis, D. Stochastic synthesis approximating any process dependence and distribution. Stoch. Environ. Res. Risk A 2018, 32, 1493–1515. [Google Scholar] [CrossRef]
- Koutsoyiannis, D.; Dimitriadis, P. Towards generic simulation for demanding stochastic processes. Science 2021, 3, 34. [Google Scholar] [CrossRef]
- Vavoulogiannis, S.; Iliopoulou, T.; Dimitriadis, P.; Koutsoyiannis, D. Multi-scale temporal irreversibility of streamflow and its stochastic modelling. Hydrology 2021, 8, 63. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Knowable moments for high-order stochastic characterization and modelling of hydrological processes. Hydrol. Sci. J. 2019, 64, 19–33. [Google Scholar] [CrossRef] [Green Version]
- Ho, M.; Lall, U.; Cook, E.R. Can a paleo-drought record be used to reconstruct streamflow? A case-study for the Missouri River Basin. Water Resour. Res. 2016, 52, 5195–5212. [Google Scholar] [CrossRef] [Green Version]
- Meko, D.M.; Therrell, M.D.; Baisan, C.H.; Hughes, M.K. Sacramento River flow reconstructed to A. D. 869 from tree rings. J. Am. Water Resour. Assoc. 2001, 37, 1029–1040. [Google Scholar] [CrossRef]
- Meko, D.M. Sacramento River Annual Flow Reconstruction. International Tree-Ring Data Bank. IGBP PAGES/World Data Center for Paleoclimatology Data Contribution Series #2006-105; NOAA/NGDC Paleoclimatology Program: Boulder, CO, USA, 2006. [Google Scholar]
- Vogel, R.M.; Tsai, Y.; Limbrunner, J.F. The regional persistence and variability of annual streamflow in the United States. Water Resour. Res. 1998, 34, 3445–3459. [Google Scholar] [CrossRef] [Green Version]
- Koutsoyiannis, D.; Yao, H.; Georgakakos, A. Medium-range flow prediction for the Nile: A comparison of stochastic and deterministic methods. Hydrol. Sci. J. 2008, 53, 142–164. [Google Scholar] [CrossRef]
- Szolgayová, E.; Laaha, G.; Blöschl, G.; Bucher, C. Factors influencing long range dependence in streamflow of European rivers. Hydrol. Process. 2013, 28, 1573–1586. [Google Scholar] [CrossRef]
- Markonis, Y.Y.; Moustakis, C.; Nasika, P.; Sychova, P.; Dimitriadis, M.; Hanel, P.; Máca; Papalexiou, S.M. Global estimation of long-term persistence in annual river runoff. Adv. Water Resour. 2018, 113, 1–12. [Google Scholar] [CrossRef]
- Dimitriadis, P.; Koutsoyiannis, D.; Tzouka, K. Predictability in dice motion: How does it differ from hydrometeorological processes? Hydrol. Sci. J. 2016, 61, 1611–1622. [Google Scholar] [CrossRef] [Green Version]
- Papacharalampous, G.; Tyralis, H.; Pechlivanidis, I.G.; Grimaldi, S.; Volpi, E. Massive feature extraction for explaining and foretelling hydroclimatic time series forecastability at the global scale. Geosci. Front. 2022, 13, 101349. [Google Scholar] [CrossRef]
- Iliopoulou, T.; Koutsoyiannis, D. Revealing hidden persistence in maximum rainfall records. Hydrol. Sci. J. 2019, 64, 1673–1689. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. Simple stochastic simulation of time irreversible and reversible processes. Hydrol. Sci. J. 2020, 65, 536–551. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
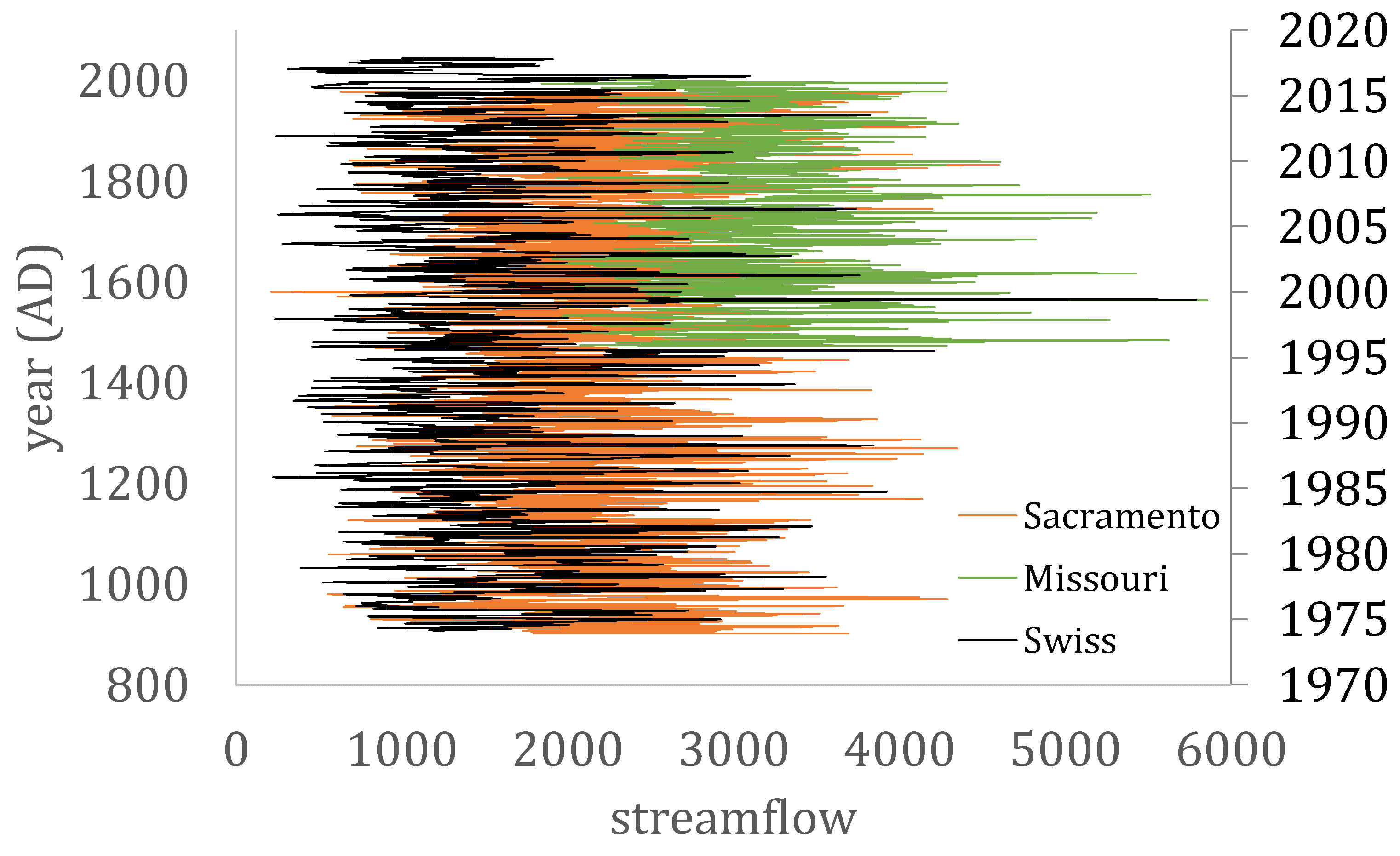
| Number of Stations | Temporal Resolution | Total Record Values/Station | Time Period | Location | Type | Database | |
|---|---|---|---|---|---|---|---|
| Swiss dataset | 39 | 10 min | 2.3 × 106 | 1974–2017 | Switzerland | Stations | Hyperlink |
| Missouri paleoclimatic reconstruction dataset | 55 | Annual | 533 | 1473–2005 | Missouri river basin, USA | Reconstructions | Hyperlink |
| Sacramento reconstruction timeseries | 1 | Annual | 1077 | 901–1977 | Sacramento River, USA | Reconstruction | Hyperlink |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pizarro, A.; Dimitriadis, P.; Iliopoulou, T.; Manfreda, S.; Koutsoyiannis, D. Stochastic Analysis of the Marginal and Dependence Structure of Streamflows: From Fine-Scale Records to Multi-Centennial Paleoclimatic Reconstructions. Hydrology 2022, 9, 126. https://doi.org/10.3390/hydrology9070126
Pizarro A, Dimitriadis P, Iliopoulou T, Manfreda S, Koutsoyiannis D. Stochastic Analysis of the Marginal and Dependence Structure of Streamflows: From Fine-Scale Records to Multi-Centennial Paleoclimatic Reconstructions. Hydrology. 2022; 9(7):126. https://doi.org/10.3390/hydrology9070126
Chicago/Turabian StylePizarro, Alonso, Panayiotis Dimitriadis, Theano Iliopoulou, Salvatore Manfreda, and Demetris Koutsoyiannis. 2022. "Stochastic Analysis of the Marginal and Dependence Structure of Streamflows: From Fine-Scale Records to Multi-Centennial Paleoclimatic Reconstructions" Hydrology 9, no. 7: 126. https://doi.org/10.3390/hydrology9070126
APA StylePizarro, A., Dimitriadis, P., Iliopoulou, T., Manfreda, S., & Koutsoyiannis, D. (2022). Stochastic Analysis of the Marginal and Dependence Structure of Streamflows: From Fine-Scale Records to Multi-Centennial Paleoclimatic Reconstructions. Hydrology, 9(7), 126. https://doi.org/10.3390/hydrology9070126