
Reservoir Sizing at Draft Level of 75% of Mean Annual Flow Using Drought Magnitude Based Method on Canadian Rivers


Abstract
1. Introduction
2. Sequent Peak Algorithm (SPA) and Drought Magnitude (DM)-Based Procedures

{kind=link}
{kind=link}
{kind=link}
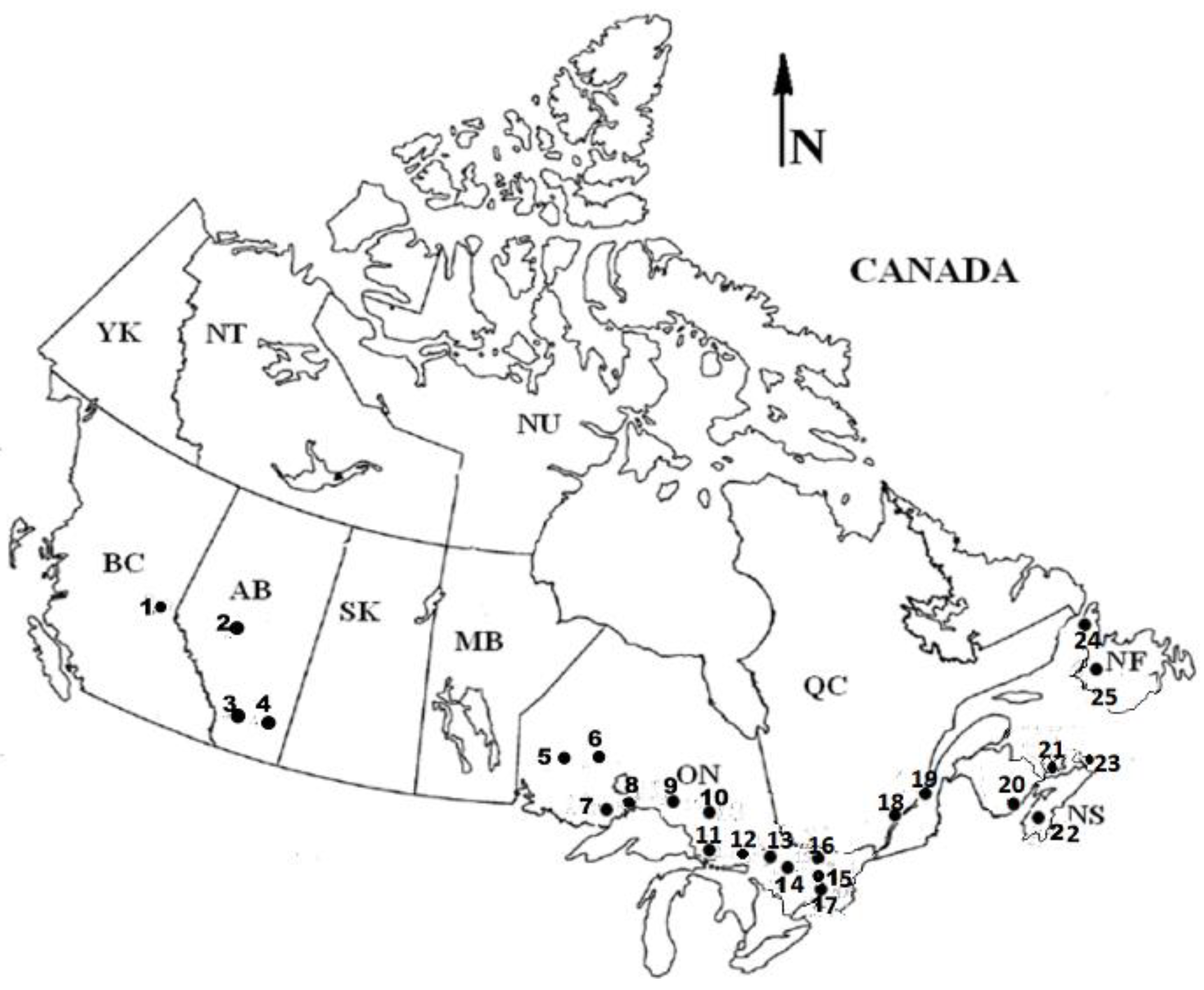
| Name, Location, and the Numeric Identifier of the River in Figure 1 | Years of Data (Period) | Mean (m3/s) | cva, cvav, cvm, cvo, cvow | ρa, ρma1, ρma2 |
|---|---|---|---|---|
| 1. Fraser at Shelley, BC08KB001 | 67 (1951–17) | 808.89 | 0.14, 0.28, 0.65, 0.84, 0.89 | −0.04,0.50, 0.75 |
| (54°00′13″ N, 122°37′29″ W), 32,400 km2 | ||||
| 2. Athabasca River at Athabasca, AB07BE001 | 67 (1952–18) | 426.21 | 0.23, 0.35, 0.80, 0.90, 0.97 | 0.19, 0.60, 0.83 |
| (54°43′20″N, 113°17′10″ W), 74,600 km2 | ||||
| 3. Bow at Banff, AB05BB001 | 106 (1911–16) | 38.96 | 0.13, 0.24, 0.79, 1.05, 1.11 | 0.07, 0.50, 0.76 |
| (51°10′30″ N, 115°34′10″ W), 2210 km2 | ||||
| 4. South Saskatchewan, AB05JA001 | 59 (1960–18) | 167.64 | 0.35, 0.52, 1.85, 1.07, 1.16 | 0.20, 0.64, 0.83 |
| (50°03′00″ N, 110°40′00″ W), 56,369 km2 | ||||
| 5. English River, ON05QA002 | 97 (1922–18) | 58.6 | 0.32, 0.51, 0.95, 0.74, 0.77 | 0.21, 0.76, 0.88 |
| (49°52’ 30”’ N, 91°27’30” W), 6230 km2 | ||||
| 6. Pipestone at Karl Lake, ON04DA001 | 50 (1967–16) | 54.4 | 0.40, 0.56, 1.17, 0.95, 1.05 | 0.32, 0.58, 0.79 |
| (52°34′50″ N, 90°11′12″ W), 5960 km2 | ||||
| 7. Neebing at Thunder Bay, ON02AB008 | 64 (1954–17) | 1.62 | 0.37, 0.81, 2.14, 1.48, 1.87 | 0.24, 0.43, 0.73 |
| (48°23′00″ N, 89°18′23″ W), 187 km2 | ||||
| 8. Pic River near Marathon, ON02BB003 | 50 (1968–17) | 22.2 | 0.20, 0.56, 1.22, 1.02, 1.24 | 0.02, 0.41, 0.71 |
| (48°46′26″ N, 86°17′49″ W), 4270 km2 | ||||
| 9. Pagwachaun at highway#11, ON04JD005 | 51 (1968–18) | 24.6 | 0.22, 0.62, 1.47, 1.17, 1.44 | 0.08, 0.36, 0.69 |
| (49°46′00″ N, 85°14′00″ W), 2020 km2 | ||||
| 10. Nagagami at highway#11, ON04JC002 | 51 (1968–18) | 23.05 | 0.25, 0.48, 1.07, 1.01,1.11 | 0.06, 0.49, 0.74 |
| (49°46′44″ N, 84°31′48″ W), 2410 km2 | ||||
| 11. Batchwana at Batchwana, ON02BF001 | 48 (1971–18) | 50.21 | 0.24, 0.55, 1.35, 1.05, 1.11 | 0.13, 0.28, 0.65 |
| (49°59′36″ N, 84°31′31″ W), 1190 km2 | ||||
| 12. Shekak at highway #11, ON04JC003 | 36 (1951–86) | 35.94 | 0.18, 0.43, 1.22, 1.07, 1.20 | −0.10, 0.45, 0.73 |
| (49°49′47″ N, 84°30′33″ W), 3290 km2 | ||||
| 13. Goulis near Searchmont, ON02BF002 | 50 (1968–17) | 18.16 | 0.22, 0.58, 1.32, 1.05, 1.32 | 0.06, 0.32, 0.66 |
| (46°51′37″ N, 83°38′18″ W), 1160 km2 | ||||
| 14. Whitson at Chelmsford, ON02CF007 | 58 (1961–18) | 2.98 | 0.27, 0.54, 1.58, 1.19, 1.50 | 0.13, 0.39, 0.70 |
| (46°34′56″ N, 81°11′59″ W) 243 km2 | ||||
| 15. North French near Mouth, ON04MF001 | 51 (1967–18) | 95.51 | 0.21, 0.55, 1.30, 1.05, 1.29 | −0.04, 0.34, 0.66 |
| (51°05′00″ N, 80°46′00″ W), 6680 km2 | ||||
| 16. Commanda at Commanda, ON02DD015 | 44 (1975–18) | 1.76 | 0.23, 0.53, 1.02, 0.95, 1.21 | −0.12, 0.34, 0.70 |
| (45°56′55″ N, 79°36′24″ W), 106 km2 | ||||
| 17. North Magnetwan, ON02EA010 | 51(1968–18) | 2.85 | 0.24, 0.54, 0.99, 0.93,1.25 | 0.10, 0.29, 0.69 |
| (45°42′13″ N, 79°18′31″ W), 155 km2 | ||||
| 18. Becancour A Lyster QC02PL001 | 46 (1923–68) | 30.6 | 0.20, 0.62, 1.27, 1.08, 1.32 | 0.03, 0.26, 0.65 |
| (46°22′08″ N, 71°37′21″ W), 1410 km2 | ||||
| 19. Beaurivage Sainte Entiene, QC02PJ007 | 75 (1926–00) | 14.19 | 0.26, 0.62, 1.32, 1.19, 1.47 | 0.19, 0.24, 0.64 |
| (46°39′33″ N, 71°17′19″ W), 709 km2 | ||||
| 20. Lepreau River at Lepreau, NB01AQ001 | 100 (1919–18) | 7.41 | 0.22, 0.59, 0.78, 0.81, 1.08 | 0.10, 0.23, 0.62 |
| (45°10′11″ N, 66°28′05″ W), 239 km2 | ||||
| 21. Carruther at Saint Anthony, PE01CA003 | 56 (1962–17) | 0.97 | 0.21, 0.57, 1.27, 1.05, 1.34 | 0.04, 0.22, 0.62 |
| (46°44′44″ N, 64°10′39″ W), 46.8 km2 | ||||
| 22. Bevearbank at Kinsac, NS01DG003 | 96 (1922–17) | 3.04 | 0.19, 0.60, 0.74, 0.80, 1.10 | −0.20, 0.13, 0.55 |
| (44°51′04″ N, 63°39′50″ W), 97 km2 | ||||
| 23. North Margaree, NS01FB001 | 90 (1929–18) | 17.03 | 0.14, 0.48, 1.00, 0.76, 0.96 | 0.17, 0.17, 0.56 |
| (46°22′08″ N, 60°58′31″ W, 368 km2 | ||||
| 24. Upper Humber, NF02YL001 | 65 (1953–17) | 79.72 | 0.12, 0.44, 0.85, 0.87, 1.07 | 0.16, 0.13, 0.56 |
| (49°14′34″ N, 57°21′36″ W), 2210 km2 | ||||
| 25. Torrent at Bristol pool, NF02YC001 | 59 (1960–18) | 24.81 | 0.15, 0.44, 1.15, 0.88, 1.07 | 0.18, 0.16, 0.59 |
| (50°36′26″ N, 57°09′05″ W), 624 km2 |

2.1. Strategies for Truncating the Non-Stationary (Monthly) Flow Sequences
2.2. Computation of Drought Magnitude (MT-o) by the DM-Based Counting Method
2.3. Estimation of Drought Magnitude (MT-e) by the DM-Based Analytical Method
3. Data Set and Computations of Reservoir Volumes by the SPA and DM-Based Methods
3.1. Inter-Comparison of Reservoir (VR) and Deficit (‘DT-o) Volumes for the Draft of 0.75 µo at Varying Time Scales
3.2. Implementation of the DM-Based Counting and Estimation Methods
4. Results and Discussion
4.1. Comparison of VR’ and MT-o at Monthly Scale with SHIo as Cutoff: By Counting Method
4.2. Comparison of VR’ and MT-e (Equation (2)) at the Monthly Scale with SHIo as Cutoff
4.3. Comparison of VR’ and MT-e (Equation (1)) at Monthly Scale with SHIo as Cutoff
4.4. Comparison of VR’ and MT-e (Equation (1)) at Monthly Scale with SHIm and SHIav as Cutoff
4.5. Relative Difference between Deficit Volume (DT-e) and Reservoir Volume (VR)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Thomas, H.A.; Burden, R.P. Operation Research in Water Quality Management; Division of Engineering and Applied Physics, Harvard University: Cambridge, MA, USA, 1963. [Google Scholar]
- McMahon, T.A.; Mein, R.G. Reservoir Capacity and Yield; Development in Water Science #9, Elsevier: Amsterdam, The Netherlands, 1978; p. 78. [Google Scholar]
- Loucks, D.P.; Stedinger, J.R.; Haith, D.A. Water Resources Systems Planning and Analysis; Prentice-Hall: Englewood Cliffs, NJ, USA, 1981. [Google Scholar]
- McMahon, T.A.; Mein, R.G. River and Reservoir Yield; Water Resources Publications: Littleton, CO, USA, 1986. [Google Scholar]
- Linsley, R.K.; Franzini, J.B.; Freyburg, D.L.; Tchobanoglous, G. Water Resources Engineering, 4th ed.; Irwin McGraw-Hill: New York, NY, USA, 1992; p. 192. [Google Scholar]
- McMahon, T.A.; Adeloye, A.J. Water Resources Yield; Water Resources Publications: Littleton, CO, USA, 2005. [Google Scholar]
- Parks, Y.P.; Gustard, A. A reservoir storage yield analysis for arid and semiarid climate. IAHS Optim. Alloc. Water Resour. 1982, 135, 49–57. [Google Scholar]
- Lele, S.M. Improved algorithms for reservoir capacity calculation incorporating storage-dependent and reliability norms. Water Resour. Res. 1987, 23, 1819–1823. [Google Scholar] [CrossRef]
- Phien, H.N. Reservoir storage capacity with gamma inflows. J. Hydrol. 1993, 146, 383–389. [Google Scholar] [CrossRef]
- Adeloye, A.J.; Lallemand, F.; McMahon, T.A. Regression models for within-year capacity adjustment in reservoir planning. Hydrol. Sci. J. 2003, 48, 539–552. [Google Scholar] [CrossRef][Green Version]
- Yevjevich, V. Stochastic Processes in Hydrology; Water Resources Publications: Littleton, CO, USA, 1972; pp. 179–211. [Google Scholar]
- Yevjevich, V. Methods for determining statistical properties of droughts. In Coping with Droughts; Yevjevich, V., da Cunha, L., Vlachos, E., Eds.; Water Resources Publications: Littleton, CO, USA, 1983; pp. 22–43. [Google Scholar]
- Sen, Z. Statistical analysis of hydrological critical droughts. ASCE J. Hydraul. Eng. 1980, 106, 99–115. [Google Scholar]
- Sen, Z. Applied Drought Modelling, Prediction and Mitigation; Elsevier Inc.: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Guven, O. A simplified semi-empirical approach to probabilities of extreme hydrological droughts. Water Resour. Res. 1983, 19, 441–453. [Google Scholar] [CrossRef]
- Sharma, T.C. Estimation of drought severity on independent and dependent hydrologic series. Water Resour. Manag. 1997, 11, 35–49. [Google Scholar] [CrossRef]
- Tallaksen, L.M.; Madsen, H.; Clausen, B. On the definition and modeling of streamflow drought duration and deficit volume. Hydrol. Sci. J. 1997, 42, 15–33. [Google Scholar] [CrossRef]
- Salas, J.; Fu, C.; Cancelliere, A.; Dustin, D.; Bode, D.; Pineda, A.; Vincent, E. Characterizing the severity and risk of droughts of the Poudre River, Colorado. ASCE J. Water Resour. Plan. Manag. 2005, 131, 383–393. [Google Scholar] [CrossRef]
- Vicente-Serrano, S.M. Differences in spatial patterns of drought on different time scales: An analysis of the Iberian Peninsula. Water Resour. Manag. 2006, 20, 37–60. [Google Scholar] [CrossRef]
- Fleig, A.K.; Tallaksen, L.M.; Hisdal, H.; Demuth, S. A global evaluation of streamflow drought characteristics. Hydrol. Earth Syst. Sci. 2006, 10, 535–552. [Google Scholar] [CrossRef]
- Nalbantis, I.; Tsakiris, G. Assessment of hydrological drought revisited. Water Resour. Manag. 2009, 23, 881–897. [Google Scholar] [CrossRef]
- Lopez-Moreno, J.I.; Vicente-Serrano, S.M.; Beguria, S.; Garcia-Ruiz, J.M.; Portela, M.M.; Almeida, A.B. Dam effect on drought magnitude and duration in a transboundary basin: The lower River Tagus, Spain and Portugal. Water Resour. Res. 2009, 45, W02405. [Google Scholar] [CrossRef]
- Sharma, T.C.; Panu, U.S. Analytical procedures for weekly hydrological droughts: A case of Canadian rivers. Hydrol. Sci. J. 2010, 55, 79–92. [Google Scholar] [CrossRef]
- Sharma, T.C.; Panu, U.S. A simplified model for predicting drought magnitudes: A case of streamflow droughts in Canadian prairies. Water Resour. Manag. 2014, 28, 1597–1611. [Google Scholar] [CrossRef]
- Akyuz, D.E.; Bayazit, M.; Onoz, B. Markov chain models for hydrological drought characteristics. J. Hydrometeorol. 2012, 13, 298–309. [Google Scholar] [CrossRef]
- Sharma, T.C.; Panu, U.S. A drought magnitude-based method for reservoir sizing: A case of annual and monthly flows from Canadian rivers. J. Hydrol. Reg. Stud. 2021. in print. [Google Scholar]
- McMahon, T.A.; Pegram, G.G.S.; Vogel, R.M.; Peel, M.C. Revisiting reservoir storage–yield relationships using a global streamflow database. Adv. Water Resour. 2007, 30, 1858–1872. [Google Scholar] [CrossRef]
- Todorovic, P.; Woolhiser, D.A. A stochastic model of n day precipitation. J. Appl. Meteorol. 1975, 14, 125–127. [Google Scholar] [CrossRef]
- Cramer, H.; Leadbetter, M.R. Stationary and Related Stochastic Processes; John Wiley and Sons Inc.: New York, NY, USA, 1967. [Google Scholar]
- Adamowski, K. Plotting formula for flood frequency. Water Resour. Assoc. 1981, 17, 197–202. [Google Scholar] [CrossRef]
- Viessman, W.; Lewis, G.L. Introduction to Hydrology., 5th ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 2003; p. 59. [Google Scholar]
- Chow, V.T.; Maidment, D.R.; Mays, L.W. Applied Hydrology; McGraw-Hill: New York, NY, USA, 1988; p. 367. [Google Scholar]
- Environment Canada. HYDAT CD-ROM Version 96-1.04 and HYDAT CD-ROM User’s Manual. In Surface Water and Sediment Data Water Survey of Canada; Government of Canada: Ottawa, ON, Canada, 2018. [Google Scholar]
- Kotz, S.; Neumann, J. On the distribution of precipitation amounts for periods of increasing length. J. Geophys. Res. 1963, 68, 3635–3640. [Google Scholar] [CrossRef]


| Parameter | Months | Remarks | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| µ | 9.05 | 8.21 | 7.77 | 10.54 | 50.10 | 124.68 | 104.74 | 64.69 | 38.83 | 23.82 | 14.52 | 10.59 | Overall µ = µo = 38.96 † |
| σ | 1.22 | 1.15 | 0.92 | 3.15 | 20.35 | 30.71 | 26.28 | 13.15 | 7.44 | 4.72 | 2.61 | 1.55 | σav = 9.44, σo = 40.85 † σmax = 30.71 |
| cv | 0.14 | 0.14 | 0.12 | 0.30 | 0.41 | 0.25 | 0.25 | 0.20 | 0.19 | 0.20 | 0.18 | 0.15 | cvo = 1.05 |
| SHIx | −1.85 | −1.78 | −2.11 | −0.84 | −0.62 | −1.11 | 1.00 | −1.23 | −1.30 | −1.26 | −1.39 | −1.39 | |
| α’ | 0.97 | 0.97 | 0.97 | 0.93 | 0.90 | 0.94 | 0.94 | 0.95 | 0.95 | 0.95 | 0.96 | 0.97 | Mean of α’ = 0.95 |
| River No. | Time Scale of the Analysis | Increase in VR (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Annual | Monthly | Weekly | ||||||||||
| SHIo | VR (m3) | ‘DT-o(m3) | SHIo | VR(m3) | ‘DT-o(m3) | SHIo | VR (m3) | ‘DT-o(m3) | ||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Month (%) | Week (%) | |
| 1. | −1.87 | 1.33 × 109 | 1.33 × 109 | −0.30 | 7.21 × 109 | 7.21 × 109 | −0.28 | 7.75 × 109 | 7.34 × 109 | 483 * | 7.5 ** | |
| 2. | −1.10 | 2.59 × 109 | 2.59 × 109 | −0.28 | 6.15 × 109 | 4.17 × 109 | −0.26 | 6.27 × 109 | 4.41 × 109 | 137 | 1.9 | |
| 3. | −1.87 | 4.18 × 107 | 4.18 × 107 | −0.24 | 4.01 × 108 | 3.99 × 108 | −0.23 | 4.25 × 108 | 4.25 × 108 | 854 | 6.0 | |
| 4. | −0.70 | 5.89 × 109 | 4.06 × 109 | −0.24 | 6.75 × 109 | 4.45 × 109 | −0.22 | 6.88 × 109 | 2.48 × 109 | 15 | 1.9 | |
| 5. | −0.77 | 1.54 × 109 | 1.54 × 109 | −0.34 | 2.04 × 109 | 1.36 × 109 | −0.32 | 2.07 × 109 | 1.39 × 109 | 33 | 1.5 | |
| 6. | −0.79 | 1.25 × 109 | 1.25 × 109 | −0.26 | 1.61 × 109 | 0.71 × 109 | −0.24 | 1.68 × 109 | 0.73 × 109 | 29 | 4.3 | |
| 7. | −0.68 | 3.61 × 107 | 3.61 × 107 | −0.17 | 5.69 × 107 | 3.57 × 107 | −0.13 | 5.81 × 107 | 3.70 × 107 | 58 | 2.1 | |
| 8. | −1.05 | 5.39 × 108 | 5.39 × 108 | −0.25 | 8.39 × 108 | 7.38 × 108 | −0.20 | 8.71 × 108 | 7.60 × 108 | 56 | 3.8 | |
| 9. | −1.00 | 2.23 × 108 | 2.23 × 108 | −0.21 | 4.63 × 108 | 3.65 × 108 | −0.17 | 4.92 × 108 | 3.70 × 108 | 107 | 6.3 | |
| 10. | −1.14 | 2.44 × 108 | 2.44 × 108 | −0.25 | 3.44 × 108 | 3.40 × 108 | −0.19 | 3.65 × 108 | 3.40 × 108 | 41 | 6.1 | |
| 11. | −1.25 | 0.74 × 108 | 0.74 × 108 | −0.24 | 3.37 × 108 | 2.92 × 108 | −0.21 | 3.44 × 109 | 3.04 × 109 | 355 | 2.1 | |
| 12. | −1.41 | 1.22 × 108 | 1.22 × 108 | −0.24 | 4.78 × 108 | 3.75 × 108 | −0.20 | 4.95 × 108 | 4.95 × 108 | 292 | 3.6 | |
| 13. | −1.17 | 1.31 × 108 | 1.31 × 108 | −0.24 | 2.61 × 108 | 2.61 × 108 | −0.19 | 2.70 × 108 | 2.70 × 108 | 161 | 3.5 | |
| 14. | −1.07 | 2.96 × 107 | 2.96 × 107 | −0.21 | 6.57 × 107 | 3.53 × 107 | −0.17 | 6.70 × 107 | 4.31 × 107 | 122 | 2.1 | |
| 15. | −1.21 | 1.09 × 109 | 1.09 × 109 | −0.24 | 1.72 × 109 | 1.17 × 109 | −0.23 | 1.79 × 109 | 0.88 × 109 | 58 | 4.1 | |
| 16. | −1.10 | 0.58 × 107 | 0.58 × 107 | −0.26 | 2.45 × 107 | 2.21 × 107 | −0.19 | 2.51 × 107 | 2.01 × 107 | 287 | 2.5 | |
| 17. | −1.06 | 1.37 × 107 | 1.37 × 107 | −0.27 | 3.76 × 107 | 3.31 × 107 | −0.23 | 3.80 × 107 | 3.55 × 107 | 174 | 1.1 | |
| 18. | −1.22 | 0.80 × 108 | 0.80 × 108 | −0.23 | 3.95 × 108 | 3.95 × 108 | −0.26 | 4.10 × 108 | 3.01 × 108 | 393 | 1.0 | |
| 19. | −0.98 | 1.17 × 108 | 1.17 × 108 | −0.21 | 2.42 × 108 | 1.90 × 108 | −0.24 | 2.41 × 108 | 1.88 × 108 | 107 | 0.0 | |
| 20. | −1.12 | 0.58 × 108 | 0.58 × 108 | −0.31 | 1.16 × 108 | 0.77 × 108 | −0.23 | 1.21 × 108 | 0.79 × 108 | 100 | 4.3 | |
| 21. | −1.20 | 0.75 × 107 | 0.75 × 107 | −0.24 | 1.38 × 107 | 1.15 × 107 | −0.19 | 1.44 × 107 | 1.21 × 107 | 84 | 4.3 | |
| 22. | −1.34 | 1.92 × 107 | 1.92 × 107 | −0.31 | 3.52 × 107 | 3.09 × 107 | −0.23 | 3.66 × 107 | 3.38 × 107 | 83 | 4.0 | |
| 23. | −1.74 | 0 storage | 0 volume | −0.33 | 1.28 × 108 | 1.28 × 108 | −0.26 | 1.33 × 108 | 1.05 × 108 | -- | 3.9 | |
| 24. | −2.03 | 0 storage | 0 volume | −0.29 | 8.74 × 108 | 8.74 × 108 | −0.23 | 9.28 × 108 | 5.38 × 108 | -- | 6.2 | |
| 25. | −1.70 | 0.38 × 108 | 3.80 × 107 | −0.29 | 2.49 × 108 | 2.49 × 108 | −0.23 | 2.56 × 108 | 2.09 × 108 | 555 | 2.8 | |
| Mean | 199% | 3.3% | ||||||||||
| River | SHIx | VR’, ρm1 | Counting Method | Analytical Method | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MT-o MA1 | MT-o MA2 | MT-e MA1 Equation (2) | MT-e MA2 Equation (2) | MT-e MA1 Φ = 0 | MT-e MA1 Φ = 0.5 | MT-e MA1 (mix Φ = 0, 0.5) | MT-e MA2 Φ = 0 | MT-e MA2 Φ = 0.5 | MT-e Φ = 0.5 (mix MA1, MA2) | |||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| Cutoff (SHIx) = SHIo | ||||||||||||
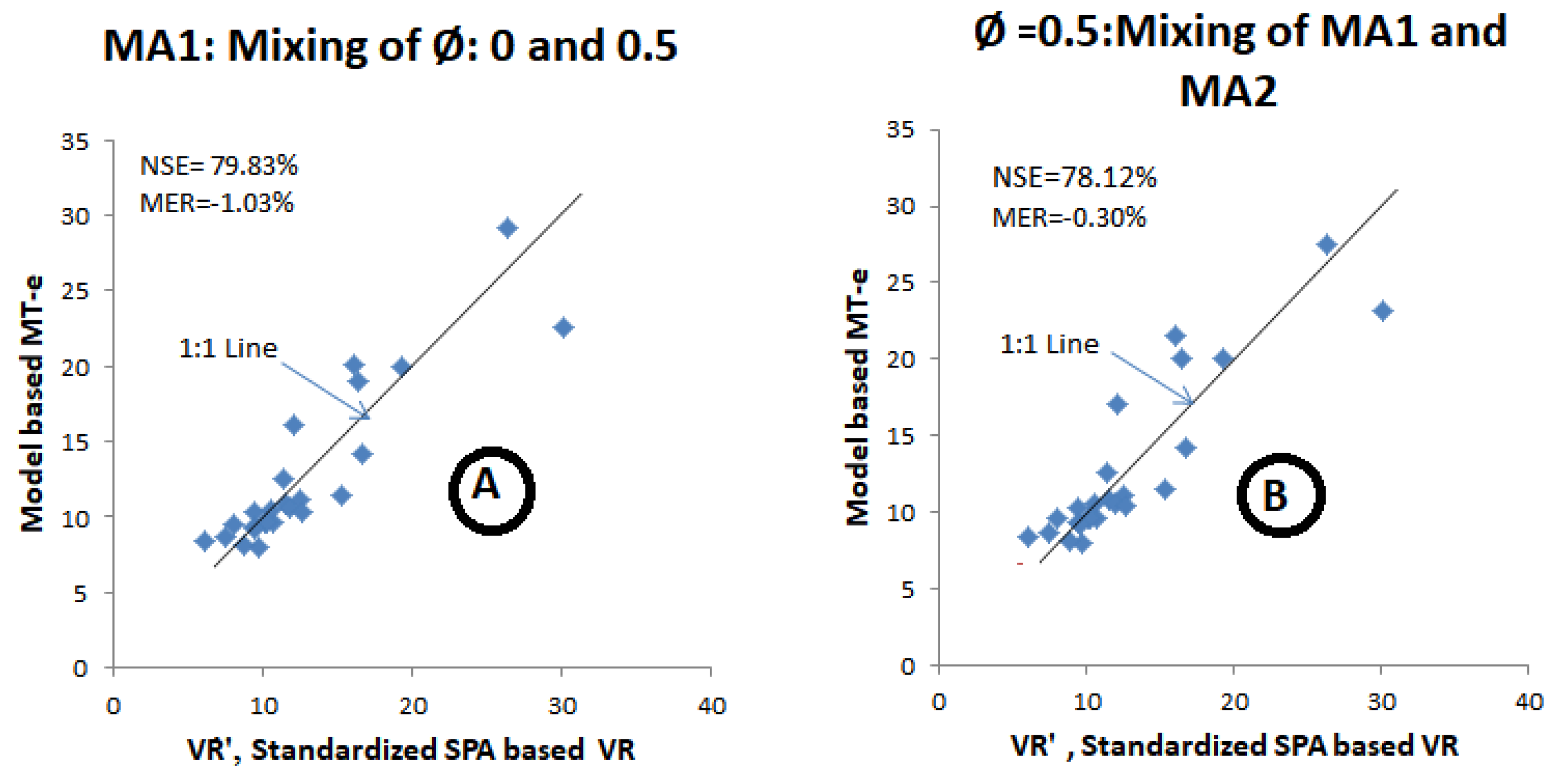
| 3. | −0.24 | 16.39, 0.50 | 17.22 | 20.25 | 9.58 | 13.95 | 19.05 | 12.85 | 19.05 | 29.94 | 19.99 | 19.99 |
| 5. | −0.32 | 26.36, 0.76 | 35.13 | 38.20 | 13.53 | 18.37 | 29.21 | 19.52 | 29.21 | 41.65 | 27.55 | 27.55 |
| 8. | −0.25 | 11.42, 0.41 | 10.85 | 13.61 | 8.58 | 12.38 | 15.95 | 10.90 | 10.90 | 24.86 | 16.87 | 16.87 |
| 11. | −0.24 | 10.65, 0.28 | 11.04 | 17.09 | 7.82 | 11.53 | 14.18 | 9.69 | 9.69 | 22.78 | 15.46 | 9.69 |
| 20. | −0.31 | 10.26, 0.23 | 5.69 | 8.35 | 7.65 | 11.51 | 14.22 | 9.65 | 9.65 | 23.45 | 15.76 | 9.65 |
| 25. | −0.29 | 8.84, 0.16 | 9.53 | 12.15 | 6.47 | 9.81 | 11.76 | 8.08 | 8.08 | 19.56 | 13.28 | 8.08 |
| NSE (%) | 59.44 | 53.83 | 42.95 | 45.77 | 76.11 | 61.72 | 79.82 | 71.79 | 79.42 | 78.12 | ||
| MER (%) | −1.41 | 15.18 | −32.09 | −0.19 | 26.87 | −13.69 | −1.03 | 99.23 | 34.61 | −0.30 | ||
| Mean of the relative difference between MT-e and VR’ (%) | 0.77% | mean | 1.52% | |||||||||
| Standard error of the relative difference between MT-e and VR’ (%) | 17.11% | standard error | 18.36% | |||||||||
| Cutoff (SHIx) = SHIm | ||||||||||||
| 3. | −0.32 | 16.39, 0.50 | 16.03 | 19.04 | 8.65 | 12.73 | 17.51 | 11.84 | 17.51 | 27.73 | 18.52 | 18.52 |
| 5. | −0.27 | 26.36, 0.50 | 35.74 | 40.69 | 14.79 | 19.94 | 31.46 | 21.02 | 31.46 | 44.68 | 29.57 | 29.57 |
| 8. | −0.21 | 11.42, 0.41 | 11.41 | 14.13 | 9.10 | 13.09 | 26.02 | 16.73 | 16.73 | 26.02 | 17.65 | 16.73 |
| 11. | −0.24 | 10.65, 0.28 | 11.56 | 17.97 | 8.46 | 12.42 | 15.11 | 10.30 | 10.30 | 24.18 | 16.40 | 10.30 |
| 20. | −0.32 | 10.26, 0.23 | 5.59 | 8.25 | 7.51 | 11.32 | 14.00 | 9.51 | 9.51 | 23.13 | 15.55 | 9.51 |
| 25. | −0.22 | 8.84, 0.16 | 10.27 | 12.82 | 7.15 | 10.75 | 12.77 | 8.73 | 8.73 | 21.08 | 14.03 | 8.73 |
| NSE (%) | 51.92 | 45.72 | 50.32 | 58.81 | 80.95 | 67.77 | 85.44 | 81.10 | 78.29 | 85.89 | ||
| MER (%) | −7.62 | 20.52 | −29.84 | 2.17 | 12.86 | −4.48 | 2.26 | 106.15 | 89.05 | 2.84 | ||
| Mean of the relative difference between MT-e and VR’ (%) | 3.75% | mean | 4.36% | |||||||||
| Standard error of the relative difference between MT-e and VR’ (%) | 16.49% | standard error | 17.00% | |||||||||
| Cutoff (SHIx) = SHIav | ||||||||||||
| 3. | −1.03 | 16.39, 0.50 | 6.46 | 8.94 | 4.15 | 8.35 | 9.15 | 6.33 | 9.15 | 17.74 | 12.20 | 12.20 |
| 5. | −0.49 | 26.36, 0.76 | 29.84 | 32.83 | 11.32 | 19.89 | 25.03 | 16.74 | 25.03 | 24.05 | 15.80 | 15.80 |
| 8. | −0.44 | 11.42, 0.41 | 8.40 | 11.04 | 6.41 | 9.50 | 12.53 | 8.63 | 8.63 | 19.89 | 13.52 | 8.63 |
| 11. | −0.45 | 10.65, 0.28 | 8.88 | 10.90 | 5.64 | 8.60 | 10.83 | 7.49 | 7.49 | 17.81 | 12.13 | 7.49 |
| 20. | −0.43 | 10.26, 0.23 | 4.74 | 7.20 | 6.36 | 9.77 | 12.23 | 8.36 | 8.36 | 20.48 | 13.79 | 8.36 |
| 25. | −0.57 | 8.84, 0.16 | 6.41 | 9.31 | 4.24 | 6.85 | 8.28 | 5.80 | 5.80 | 14.38 | 9.83 | 5.80 |
| NSE (%) | 55.70 | 38.89 | 32.24 | 41.70 | 58.70 | 47.80 | 76.39 | 62.96 | 58.01 | 79.74 | ||
| MER (%) | −41.81 | −17.32 | −51.97 | −26.62 | −4.52 | −34.38 | −25.49 | 55.25 | 5.24 | −23.28 | ||
| Mean of the relative difference between MT-e and VR’ (%) | −23.78% | mean | −21.90% | |||||||||
| Standard error of the relative difference between MT-e and VR’ (%) | 14.25% | standard error | 13.99% | |||||||||
| Number of Samples | Combination-A, Cutoff = SHIo | Combination-B, Cutoff = SHIo | ||||||
| NSE (%) | MER (%) | µre (%) | σre (%) | NSE (%) | MER (%) | µre (%) | σre (%) | |
| 25 | 79.82 | −1.03 | 0.77 | 17.11 | 79.12 | −0.30 | 1.52 | 18.36 |
| 37 | 83.34 | 3.36 | 3.91 | 18.40 | 76.70 | 1.70 | 3.10 | 19.31 |
| Number of Samples | Combination-A, Cutoff = SHIm | Combination-B, Cutoff = SHIm | ||||||
| 25 | 85.43 | 2.26 | 3.75 | 16.49 | 85.89 | 2.84 | 4.36 | 17.00 |
| 37 | 72.61 | −0.24 | 3.95 | 21.05 | 70.00 | −1.28 | 3.39 | 21.38 |
| Reservoir Capacity Estimation Method | Reservoir Capacity at 0.75 µ (MAF) |
|---|---|
| 1. Rippl method | 1100 × 106 m3 |
| 2. Residual mass curve method | 1100 × 106 m3 |
| 3. Sequent peak algorithm (SPA) | 1100 × 106 m3 |
| 4. Alexander method (cited in McMahon and Mein,1978) | 1200 × 106 m3 |
| 5. Dincer method (cited in McMahon and Mein,1978) | 1200 × 106 m3 |
| 6. Gould Gamma Method (cited in McMahon and Mein,1978) | 866 × 106 m3 |
| 7. Behaviour analysis method (finite reservoir, at 5% probability of failure) | 825 × 106 m3 |
| 8. Behaviour analysis method (infinite reservoir, at 5% probability of failure) | 900 × 106 m3 |
| 9. Drought Magnitude (DM) method (this article) | 984 × 106 m3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, T.C.; Panu, U.S. Reservoir Sizing at Draft Level of 75% of Mean Annual Flow Using Drought Magnitude Based Method on Canadian Rivers. Hydrology 2021, 8, 79. https://doi.org/10.3390/hydrology8020079
Sharma TC, Panu US. Reservoir Sizing at Draft Level of 75% of Mean Annual Flow Using Drought Magnitude Based Method on Canadian Rivers. Hydrology. 2021; 8(2):79. https://doi.org/10.3390/hydrology8020079
Chicago/Turabian StyleSharma, Tribeni C., and Umed S. Panu. 2021. "Reservoir Sizing at Draft Level of 75% of Mean Annual Flow Using Drought Magnitude Based Method on Canadian Rivers" Hydrology 8, no. 2: 79. https://doi.org/10.3390/hydrology8020079
APA StyleSharma, T. C., & Panu, U. S. (2021). Reservoir Sizing at Draft Level of 75% of Mean Annual Flow Using Drought Magnitude Based Method on Canadian Rivers. Hydrology, 8(2), 79. https://doi.org/10.3390/hydrology8020079