1. Introduction
Water quality is routinely assessed in streams, rivers, lakes, and reservoirs, especially when there are significant industrial activities and human populations in these areas. Naturally, in other contexts, water quality assessment is a process that contributes to environmental and ecosystem monitoring. The analysis and monitoring of water quality through systematic and scientifically established procedures provide important information on the status of these basins, while also helping official entities target their decision-making processes toward supported policy options. For instance, in a hydrological basin, this information can be used to build an understanding of the dynamic of the basin and how nutrients and other contaminants behave over time, namely, by monitoring both seasonal changes and long-term trends.
In the European Union (EU), the management of water resources is regulated by EU directives and their transposition into national legislation. For instance, in Portugal, the Law n. 58/2005 (Law of Water) ensures implementation into national law of the Directive n. 2000/60/CE—the Water Framework Directive, WFD—(
https://eur-lex.europa.eu/legal-content/En/TXT/?uri=CELEX:32000L0060), which creates the institutional framework for the sustainable management of surface, interior, transitional, coastal, and even groundwater. The Decree-Law n. 77/2006 complements the WFD by characterizing the waters of a river basin. A regulatory instrument establishes the status of surface waters and groundwater and their ecological potential [
1].
On the one hand, the monitoring of water resources has the purpose of evaluating the water status (surveillance monitoring); on the other hand, it allows the assessment of implemented programs that include measures for identifying water resources at risk of failing to meet environmental objectives (operational monitoring).
Many disciplines study processes and parameters, including water quality, that underlie freshwater ecosystem functions, ranging from hydrology to ecology, and a panoply of models is availble to simulate their behavior [
2]. In this context, many water quality variables are regularly assessed, including, among others, nutrient concentrations, temperature, conductivity, pH, dissolved oxygen, and total suspended solids.
Since data are collected by sampling, statistical methods are the most applied analysis techniques in the monitoring and analysis of water quality variables, namely: regression models (linear and nonlinear) and time series models, as well as data analysis techniques, such as correlation analysis, multivariate statistical techniques (cluster analysis, principal component analysis), among others. In [
3], principal component analysis, regression analysis, and cluster analysis were applied to 26 water quality parameters in Sukhnag stream, one of the major inflow streams of Lake Wular. In [
4], linear regression, principal component analysis, and cluster analysis were applied to analyze a voluminous and complex dataset of Vishav stream, which had been acquired during 1-year monitoring program of 21 parameters at five different sites. In [
5], cluster analysis, principal component analysis, factor analysis, and discriminant analysis were used for the assessment of spatial and temporal variations of a large complex water-quality dataset of the Songkhram River Basin, generated during 15 years (1995–2009) by monitoring 17 parameters at five different sites. In [
6], generalized additive models of location, scale, and shape (GAMLSS) were applied to characterize model uncertainty, due to incomplete understanding of physical processes, in an Atlantic coastal plain watershed system. In [
7], extreme learning machine (ELM) and wavelet-extreme learning machine hybrid (WA-ELM) models were applied to forecast multi-step-ahead electrical conductivity (EC)—a water quality indicator that is useful for estimating the mineralization and salinity of water—and to employ an integrated method to combine the advantages of WA-ELM models, which utilized the boosting ensemble method. Control charts were developed by [
8] to treat the case of a French river, for which the parameter of interest, the dissolved oxygen concentration (DO), was characterized by a non-stationary and seasonal time evolution. A range of statistical techniques, discussed in [
9], can be used to detect gradual or abrupt changes in hydrochemistry, including parametric, non-parametric, and signal decomposition methods.
Considering the time structure of data collected over time, other authors have adopted time series models in order to model and analyze water quality variables. In [
10], a time series analysis approach was applied to model and predict univariate dissolved oxygen and temperature time series for four water quality assessment stations at Stillaguamish River located in the state of Washington. Cluster analysis and linear models were used by [
11,
12] to describe a hydrological space-time series of quality variables and to detect changes in surface water quality data collected in the River Ave hydrological basin, located in the northwest region of Portugal. In [
1], the case study of the hydrological basin of the river Vouga, in Portugal was presented. A discrimination analysis of water monitoring sites, using the monthly dissolved oxygen concentration, was proposed by [
13], performing the extraction of both trend and seasonal components in a linear mixed-effect state-space model. Linear state-space models were applied by [
14] as an improvement of the linear regression model, since these models allow the incorporation of a constructed hydro-meteorological covariate.
In the massive data collection era, the use of computational intelligence (CI) approaches has been increasing in different hydrological contexts, with emphasis on modeling techniques in hydrologic engineering. In hydrology, one of the most employed CI approaches is based on artificial neural networks (ANNs), with applications ranging from groundwater modeling [
15] to rainfall-runoff modeling [
16,
17], among others. In [
18], an integrated variable fuzzy evaluation model was proposed to assess river water quality based on theory of variable fuzzy sets and fuzzy binary comparison method. ANN and extreme learning machine was used by [
19] to compare the performance of modular models against global models in predicting the total flow in different small- to medium-sized watersheds in the northern United States. In [
20] can be found the relevant CI used in the context of flood and waste management.
The study of water quality variables is extremely important in order to assure the benefits that water provides to the ecosystem and to human society. Furthermore, water quality has a direct relationship with water quantity, in particular, with the flow in a waterway or the volume in a water body. Flow is a fundamental property of streams that affects everything from temperature of the water and concentration of various substances in the water to the distribution of habitats and organisms throughout the stream.
Several works relating water quality parameters and water flow can be found in the literature. For instance, in [
21], the interactions between DO and flow in the river Waihou catchment, New Zealand, were evaluated with the purpose of supplying minimum flow and flow variability requirements for instream ecology, in order to provide a more holistic framework for defining flow requirements in the catchment area. In [
22], the relationship between some water quality parameters, including DO, and flow rates at several sites in the Vltava River catchment in the Czech Republic were evaluated. The results indicated that concentrations of nitrates, suspended solids, and dissolved oxygen are in direct relation to flow rate. In [
23], the effects of flow releases from Roanoke Rapids Dam on DO concentrations were evaluated, including percentages of saturation and deficit levels, in the Roanoke River between Roanoke Rapids and Jamesville, North Carolina, during May–November from 2005 to 2009. Interannual, intraannual, daily, and hourly streamflow, precipitation, and water quality data were used in the analysis to determine if discernible quantitative or qualitative patterns linked Roanoke River instream DO levels to releases at Roanoke Rapids Dam. In [
24], a longitudinal profile of DO was obtained to quantify the shift of the water quality under low flow conditions in the urban section of the urban river Nanfei (Hefei, China). It was used to establish an overarching budget of DO to identify the main sources and sinks with an oxygen model and to provide a basis for general mitigation strategies and policy recommendations for oxygen depression of urban rivers in transitional regions.
In a water resource management framework, several water quality parameters are being measured to indicate the water status of a river and to guide decision makers about environmental and water policies. Among the most important parameter is the dissolved oxygen concentration as an indicator of river health, which is used by regulators as part of the classification for good chemical status [
25]. This parameter directly indicates the status of an aquatic ecosystem and its ability to sustain aquatic life. In the presence of extreme low DO values, the aquatic ecosystems become unbalanced, leading to environmental problems, such as fish mortality. In fact, the dissolved oxygen concentration in aquatic systems can be critical to habitat quality and can have cascading impacts on redox-sensitive nutrient and metal cycling [
26]. In this context, DO modeling and forecasting becomes a relevant research topic, and it has been addressed with different approaches in the literature, ranging from differential equations [
27] to ANN modeling [
28]. In a time series analysis perspective, since DO concentration presents both time correlation and seasonality, models such as linear regression models and linear state-space models are simple and valid alternatives for the modeling and forecasting of this variable. Moreover, these models have desirable statistical properties which allow inferences.
The main research hypothesis of this work is that the usual linear regression models, and their variants for time series data, are more able to forecast the dissolved oxygen concentration to a future instant, while dynamic linear models are more appropriate to a monitoring procedure in an in-sample or online approach. The research hypothesis was assessed through a competitive study of time series models, which were used to model and forecast the dissolved oxygen concentration, taking into account the usual characteristics of this type of variable, such as the existence of trends, seasonality, and temporal correlation. Despite the fact that these models are based on linear models, the temporal correlation present in the environmental data is introduced and statistically treated in different ways. Time series models are presented with a discussion of their assumptions, as well as their main stochastic properties and added-value for the monitoring of this type of variable. These models allow the water quality variable analysis over a mid-term period. However, two of these models incorporate a time correlation structure that facilitates monitoring in real time, in the sense that these models allow forecasting and assessing of the predictability of observations through forecasting and filtered confidence intervals.
The models were assessed based on their performance in modeling and forecasting the dissolved oxygen (DO) concentration (mg/L), since this is a variable largely measured by the monitoring procedures, and the amount of dissolved oxygen has been considered a relevant indicator of water quality, since it is affected by set of environmental factors. Although the DO concentration analysis is the main objective of this work, the monitoring of water is usually performed with a more complete approach that connects chemical and biological analyses. However, the analysis of the model more appropriate to monitor or forecast water quality variables must be performed for each type of variable, since each variable can be affected in different ways from several conditions, such as hydro-meteorological conditions, untreated effluent discharges from industrial activities, etc.
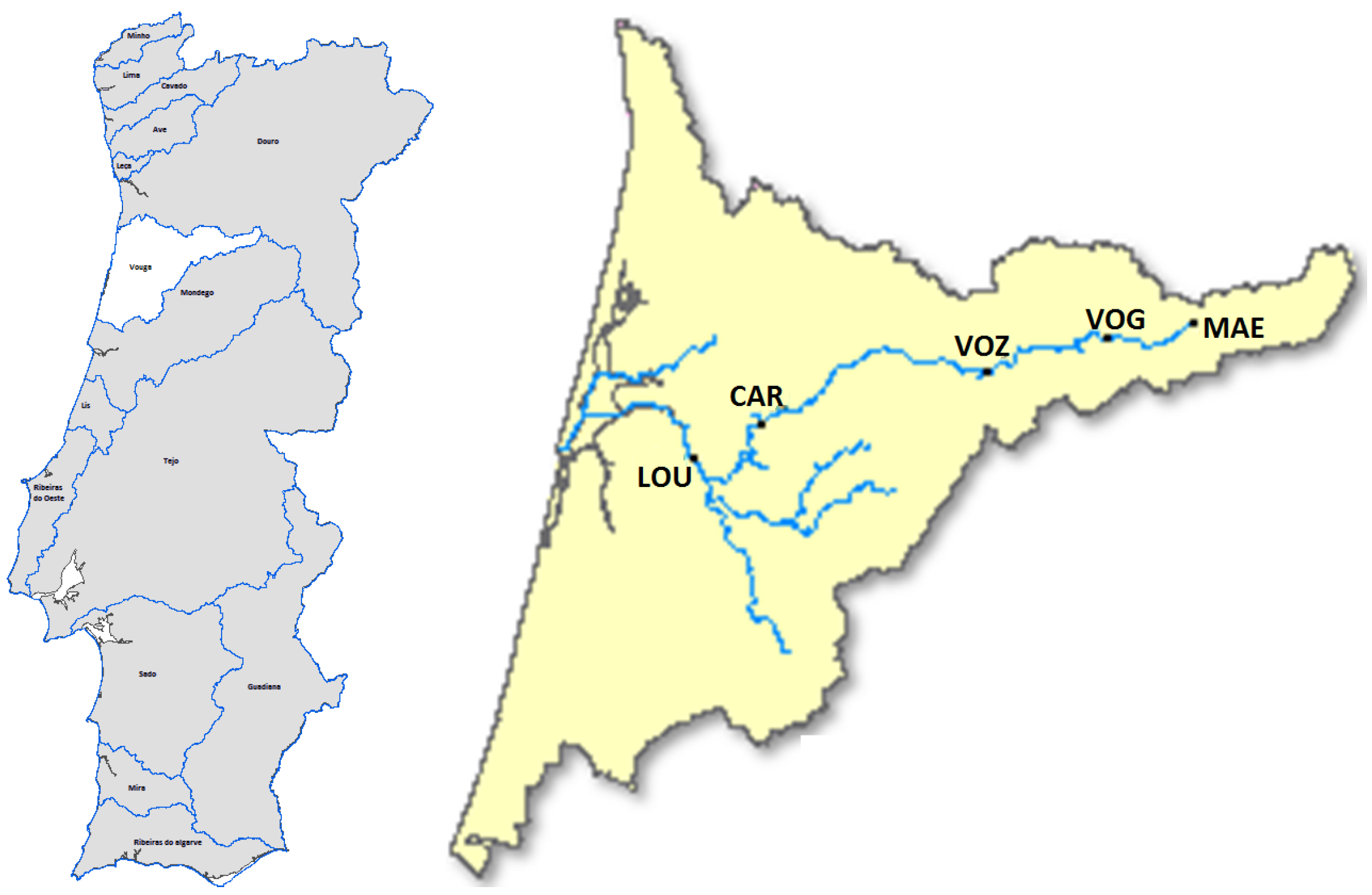
The study was performed using the monthly data of the dissolved oxygen concentration, collected during the period from January 2002 to May 2015, in water quality stations located in the Vouga river basin in Portugal. The choice of this basin results from the fact that the University of Aveiro (UA) is located in the Vouga river basin region, and the university is a neighbor of the ria de Aveiro lagoon, which has great territorial, environmental, economic, and social expression; besides that, the University of Aveiro is committed to facilitating the provision of scientific knowledge on this lagoon area.
When working with data collected by other entities, there are additional constraints/challenges upstream the modeling process. In the years after 2015, the data are more sparse both in the periodicity of their collection, as well as in the number of locations for which these measurements are available; for instance, after this period, there were some financial cuts that originated a change in the water monitoring plan. Furthermore, in the majority of the monitoring sites, there was a small percentage of missing observations until 2015, which requires special attention.
3. Results
Since the DO concentration series has a seasonal behavior, at a preliminary stage, we considered a linear regression model (MI) that accounts for the seasonal behavior of the DO concentration during the year, as well as for the increase in DO concentration that may occur at different rates according to the month.
Table 3 presents the ordinary least squares (OLS) estimates obtained in the adjustment of the above-described linear model (MI) of the monthly DO concentration data for the water monitoring sites under study.
For each location, the estimates of the coefficients and the respective
p-values, as well as the determinant coefficient values,
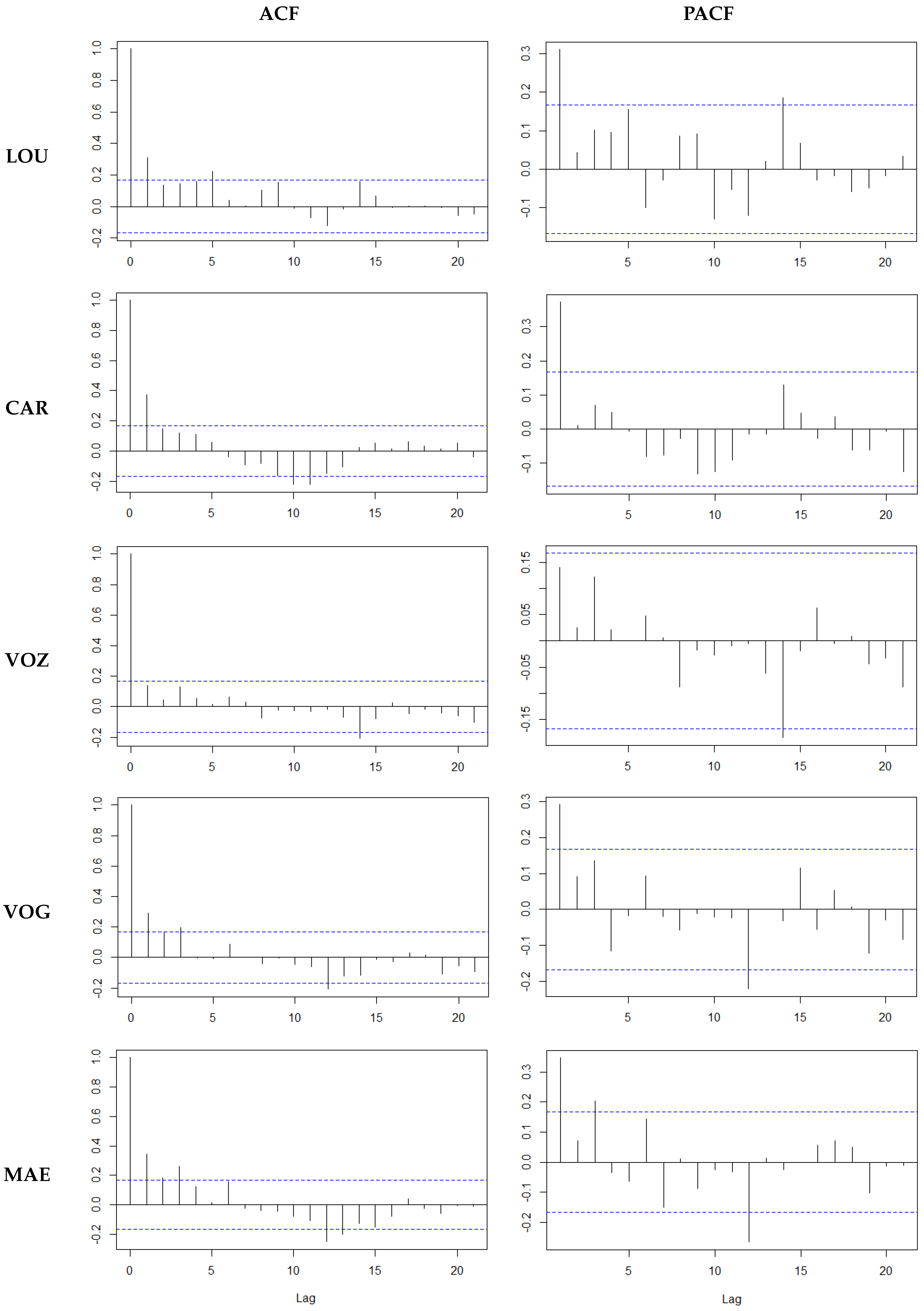
, are presented. The data indicate a good fit for all five models. Moreover, for all series, the residual series of the adjusted model MI presents a weak time correlation. In fact, if the linear model fits well to data, the residual series has white noise behavior, that is, both the sample autocorrelation function (ACF) and the sample partial autocorrelation function (PACF) have values statistically insignificant at a 5% level. The time correlation structure can be generally described by an autoregressive processes of order 1, AR(1), as can be seen from the analysis of the ACF and the PACF displayed in
Figure 2, due to the ACF decreasing exponentially to zero, while the PACF has a significant value on lag 1. So, in order to assess the statistically significant parameters, the corrected
p-values are also presented in
Table 3, as well as the AR(1) parameter estimates considered in the
p-values correction.
From the analysis of the estimation results, for each monitoring site, the estimates of all intercepts are statistically significant, considering a significance level of 10%. For monthly slopes, at least one parameter estimate is statistically significant for each monitoring site model. In the LOU station series, significant slope parameters are associated with June and September. In the CAR monitoring site is a significant slope parameter for May, while, in VOZ, it is the November slope parameter. In the VOG site model case, the significant slope parameters are associated with July, August, and November, and in the model of station MAE, only the August slope parameter is statistically significant. Note that all significant slope estimates are negative, indicating that, during those months, DO concentration was decreasing.
Due to the existence of temporal correlation in the residues, the MI model is not adequate to describe the behavior of the underlying process, so the MII (2)–(3) and MIII (5)–(6) models were used as possible alternatives. Furthermore, only significantly monthly slopes in
Table 3 were considered in these models.
Table 4 presents the OLS estimates of the parameters of model MII (2)–(3). Note that monthly slope estimates are all negative values, indicating that, in these cases, there are decreasing trends in those months. Furthermore, note that the months with the lowest intercept estimated values are, in the majority of the location sites, the summer months, and it is in the VOZ location that the lowest values can be found.
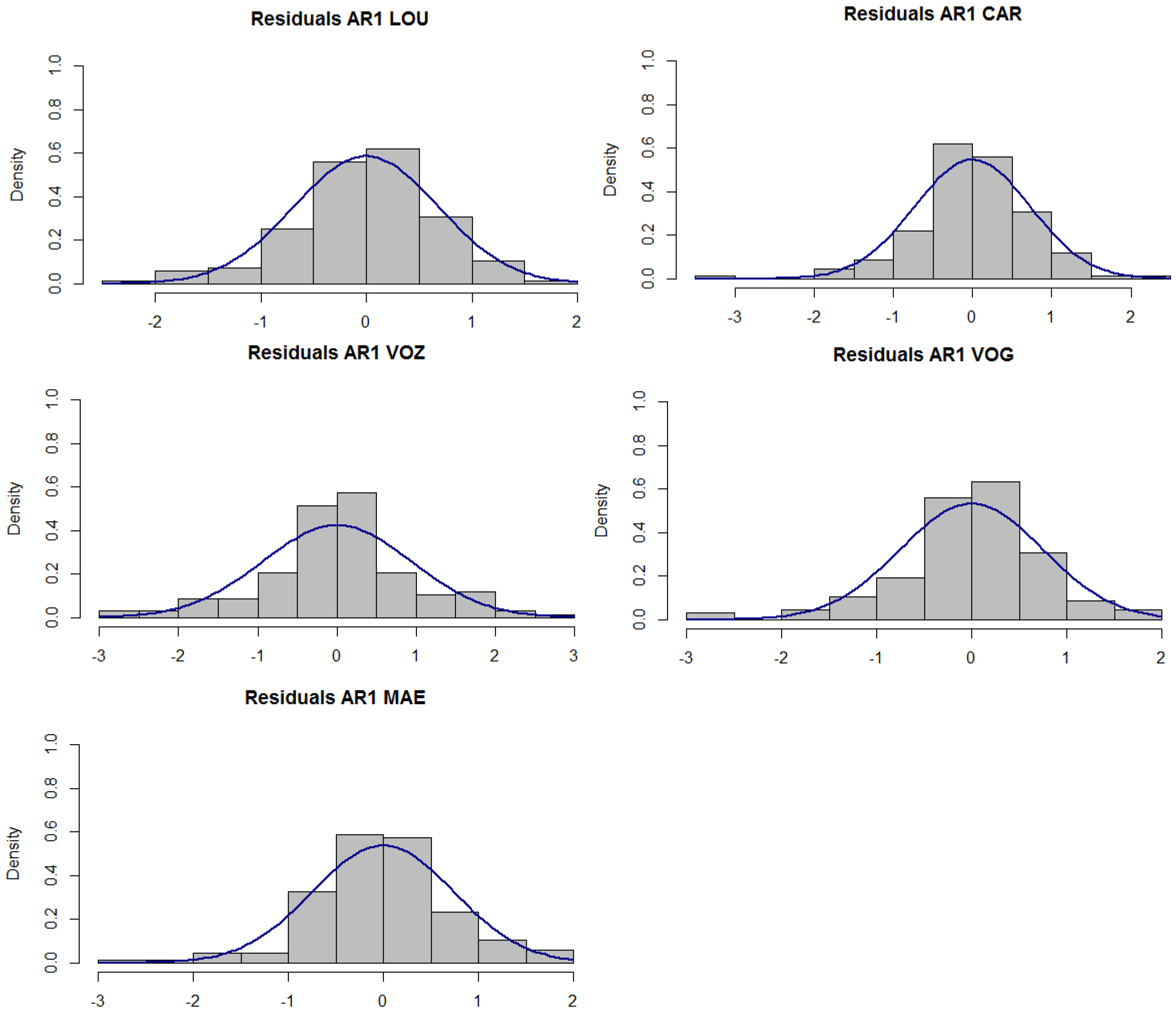
For the model MII (2)–(3), the residuals of the models did not present a significant time correlation; their histograms, after applying the Lunj-Box test with different lags, can be seen in
Figure 3. The graphs do not seem to be far from the normal curve and, with the exception of the CAR monitoring site, they do not reject the normality assumption at the 1% significance level through the Kolmogorov–Smirnov test (K–S). This test is usually applied when the series dimension is large. The Jarque–Bera test, which compares the empirical skewness and kurtosis with the correspondent Gaussian values, was also applied, and the results pointed in the same direction: residuals normality was not rejected.
Regarding the calibration model MIII (5)–(6), the parameters of the regression component were already estimated using OLS (
Table 4), and they were considered as known in order to apply the ML method to estimate the parameters associated with the calibration process. Hence, for each monitoring site, estimation results are presented in
Table 5, along with the coefficients of determination. These values are, with the exception of the LOU station, equal to or slightly better than the calibration models. As expected, the state processes are all stationary, with means around one, since, accounting for the respective standard errors, all estimates of
are less then one.
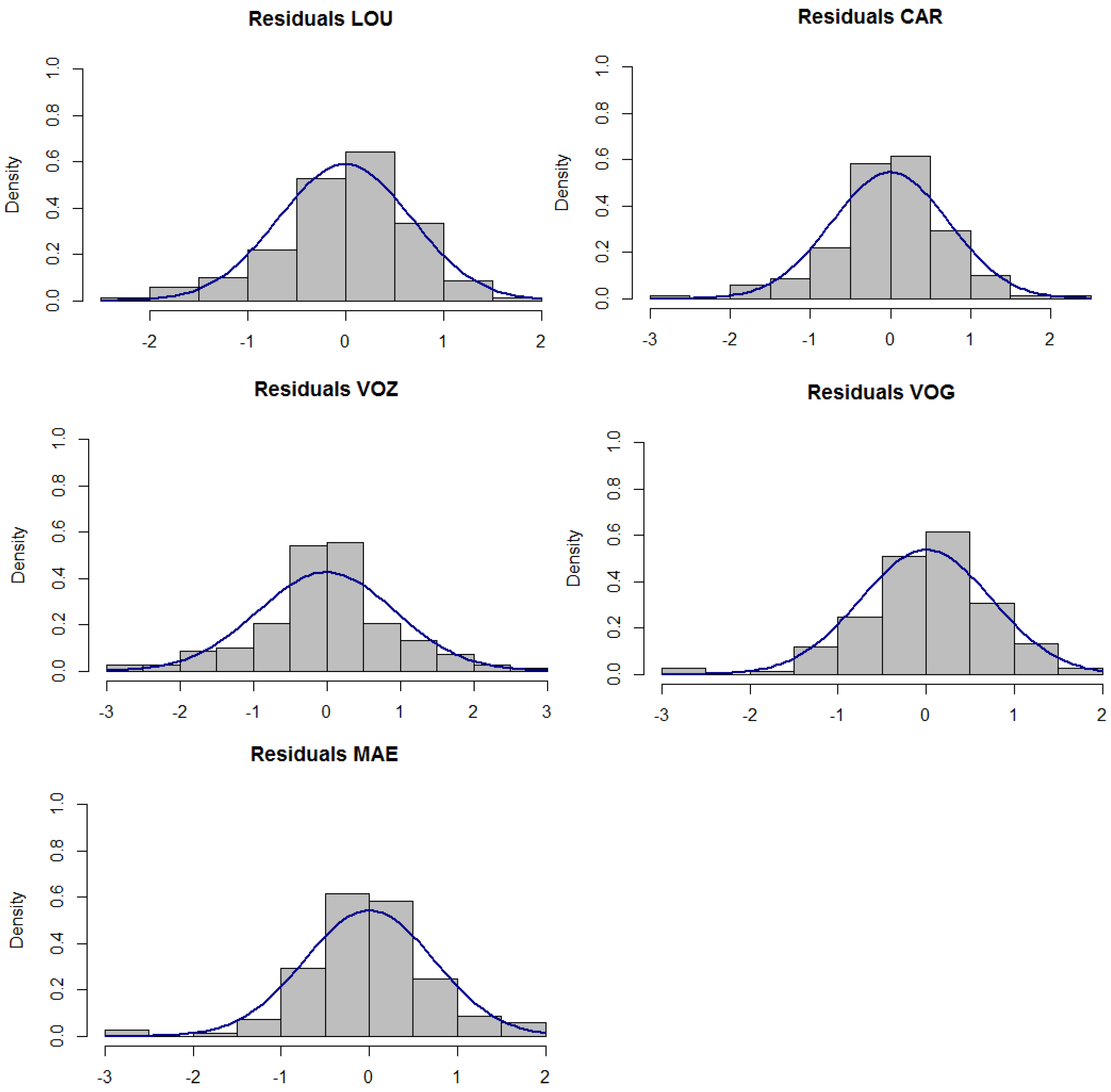
Concerning the residual analysis, both sample ACF and PACF of the residual series have behavior similar to white noise. In fact, the Lunj-Box test for the non-correlation hypothesis does not reject, using up to 30 different lags in all the locations under study, and
Figure 4 presents the histograms of the residuals that resemble the normal curve.
Furthermore, with the exception of the CAR location, the residuals of the calibration model do not reject (at a 1% significance level) the normality assumption using the Jarque–Bera test or the Kolmogorov–Smirnov test; the K–S
p-values are presented in
Table 5.
4. Discussion
The models proposed have different statistical properties, since they can be applied according to the analysis’s objectives. In fact, mainly models MII (2)–(3) and MIII (5)–(6), which were statistically validated, assume that the time correlation is incorporated in the linear model in different ways, despite both models considering an autoregressive model of order 1.
In the case of model MII (2)–(3), the process AR(1) is additive, that is, the time-dependence is added to the deterministic component, which is based on a linear regression model. This approach considers that time correlation is not influenced by the deterministic component (trend and seasonality), it only incorporates the past as a Markovian variable, in the sense that time t only depends on the last value in time .
Model III (5)–(6) has the same deterministic component of trend and seasonality as model MII, but, in this case, the autoregressive process is incorporated as a factor, that is, in a multiplicative way. In this case, the mean value of the process is 1. So, the process can be interpreted as an index, where a value less than 1 means that, in that month, the measurement of the water quality variable is lower than the expected value based on the deterministic component. If assumes a value greater than 1, in that month, the observed value is greater than the expected value, based on the deterministic component. This interpretation allows us to identify the model MIII as a calibration model.
Thus, models II and III have the same basis model which incorporates trend and seasonal components, but they incorporate the time correlation in different ways, thus allowing different interpretations and information.
Based on empirical data, model comparison is performed from two points of view: predictions one-step ahead in sample, and h-step ahead forecasts in future accuracy. However, as the model MI, the basis model, was not validated from the statistical point of view, and since the residual series has serial correlation, only models MII (2)–(3) and MIII (5)–(6) were compared.
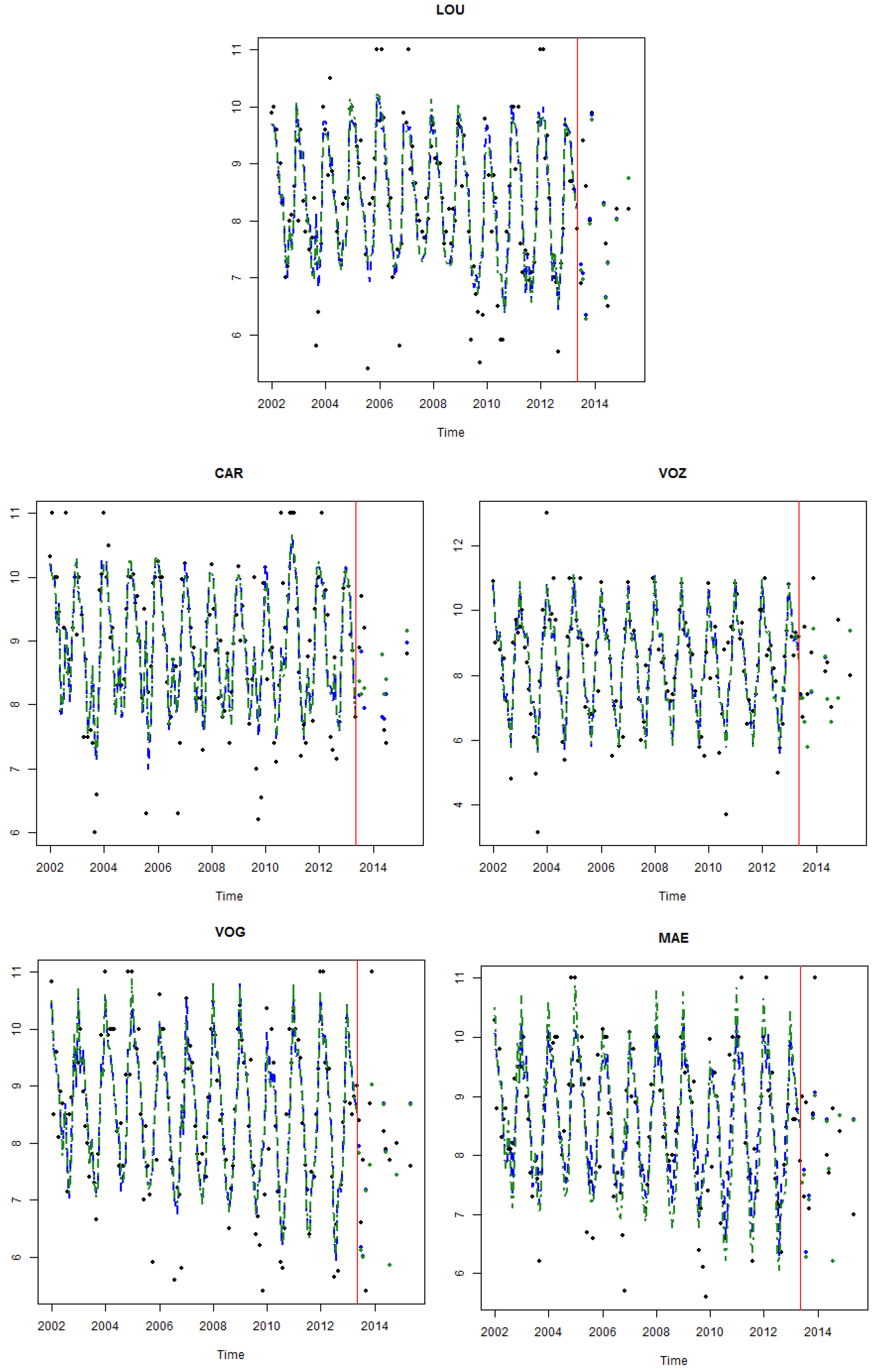
Figure 5 presents graphically, for each DO time series, the observations which correspond to the full period under consideration and the DO predictions—in-sample and forecasted out-of-sample—for both models under analysis. The period from June 2013 to May 2015 was used to evaluate the forecast ability; however, for each site, there are few available values in this period. Globally, both models fit very well in the period of estimation. However, as it was expected, the one-step ahead forecasts in both models did not pick up the extreme values (large or small values), since the linear regression model estimates the conditional expectation of the dependent variable given the independent variables, that is, the average value of the dependent variable when the independent variables are fixed.
Table 6 presents the mean square error (MSE) for each monitoring site for both models MII (2)–(3) and MIII (5)–(6) from the one-step ahead perspective (in-sample) and also from the forecasted point of view. The number of available DO observations in the considered forecast period for each time series is indicated by the
column. Therefore, the predictive ability is assessed taking into account only the observed available data, assuming that the last observation (
n) is the DO value in May 2013.
In the one-step-ahead in-sample, the considered model MII’s predictions of the DO concentration have an MSE between in LOU and in VOZ. Since MSE is given in squared units, we computed their square root (RMSE), obtaining values between and mg/L. However, these values increase to values of RMSE between and mg/L in the h-ahead forecasts, as expected, since the uncertainty in forecast is greater than in the one-step ahead prediction. These results should be analyzed with caution because the number of observations in the period left of the forecast is reduced.
According to
Table 6, with the exception of the CAR location, the calibration model MIII (5)–(6) slightly outperforms the model MII (2)–(3) from a modeling point of view, since this model presents lower MSE values for the other four monitoring sites. However, when it comes to forecasting, the model MII (2)–(3) performs slightly better than the calibration model for all monitoring stations, with the exception of the VOZ location. In this location, the DO concentration series presents greater variability when compared with the other monitoring sites. Since predictions are based on expected values, greater variability increases the difficulty of correctly predicting DO values that are far from the mean value.
These results can be explained by taking into account that the calibration model MIII (5)–(6) assumes a latent process, which is predicted through the Kalman filter algorithm, that is optimal in the filtering procedure. So, model III allows better predictions in an online framework compared to an h-step ahead forecast framework. When there is no additional information, which is the case for the forecast, the calibration model cannot update the state and therefore cannot correctly calibrate the fixed regression component of the model, hence justifying its lower performance when compared with model MII (2)–(3).
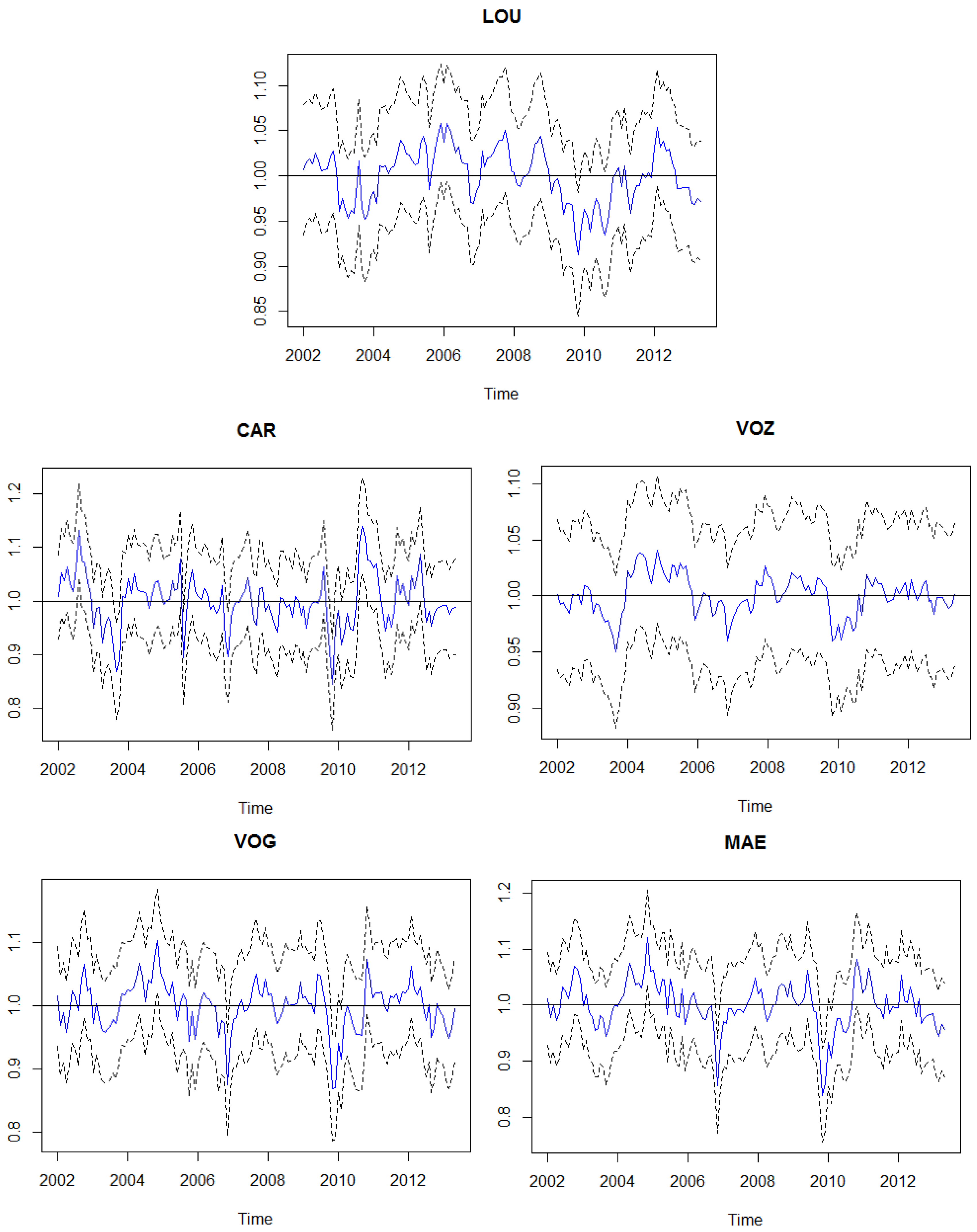
In this context, the calibration model MIII with the Kalman filter algorithm can obtain the filtered calibration factors,
, for each month. These estimates with the associated confidence intervals can be interpreted as indicators of the water monitoring procedure. In fact, considering the empirical
confidence intervals:
where
is the mean square error obtained by the Kalman filter algorithm.
Figure 6 presents filtered estimates of the calibration factor
for all site locations with
empirical confidence intervals. These intervals can be used for month-to-month evaluatations if the DO concentration measurement is an expected statistical value, considering that if
, the measurement is unexpected. So, these procedures can be used in order to identify possible extreme values or exogenous conditions that influence DO concentration. For instance, in the LOU water monitoring site in November 2009 (
), the calibration factor was estimated to be
but
. So, in this month, the observed DO concentration was
lower than the expected value for that month, considering trend and seasonality components.
5. Conclusions
Empirical results show that models based on linear regression have good performances when monitoring water quality variables, both in the modeling and in the forecast approach; for instance, in the modeling framework, the coefficients of determination vary approximately from to . However, the statistical inference in the regression models has some assumptions that are not verified for the water quality variables. In fact, the monitoring of water quality is often based on a periodic collection of water samples, from which several biochemical variables are analyzed. So, this type of data usually has a time correlation structure that must be incorporated both in model formulation and in inference procedures.
The incorporation of a time series model, as in the AR(1) process, the error process allows a suitable adjustment of models if all assumptions are globally satisfied. Furthermore, this improvement in the initial linear regression model implies an adequate computation of standard errors of the regression parameters, considering that time correlation allows a more accurate statistical procedure. This model is revealed to be more accurate from the forecast point of view.
Additionally, the calibration approach applied to the regression model proves to have a better performance when the main objective is water monitoring using an online approach, favoring the detection of changes in the expected behavior of the variable by interpreting the calibration factor predictions. It is noteworthy that in a certain month t, if the calibration factor prediction is less than 1, then, in the correspondent month, the observed value is lower than the expected value based on the analyzed period. The an opposite interpretation applies if is greater than 1.
The comparative study of the linear models was based on a DO concentration series, which is considered a good indicator of water status. As topic of future research, it is important to analyze whether the results remain valid for other physical/chemical parameters which are equally important for the characterization of water status. Furthermore, the models under analysis are univariate, hence, a multivariate time series model comparison will be a topic for future research.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}